MySQL約束與多表查詢基礎詳解

推薦學習:
1.約束
概述
概念:約束是作用於表中欄位上的規則,用於限制儲存在表中的資料。
目的:保證資料庫中資料的正確、有效性和完整性。
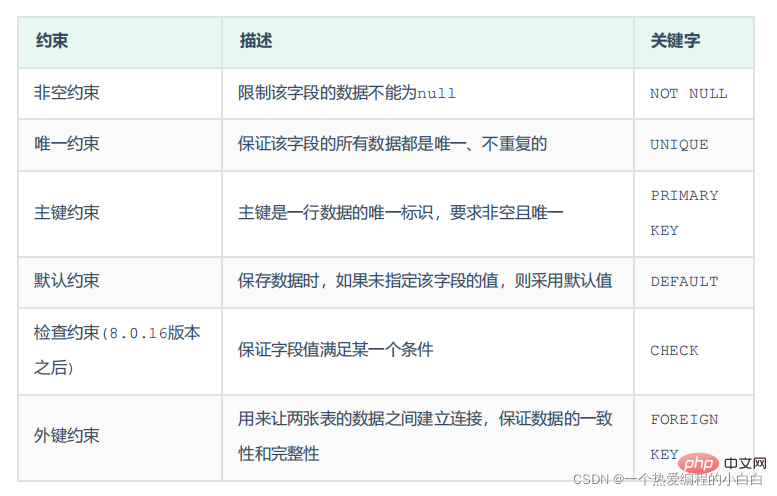
注意:約束是作用於表中欄位上的,可以在建立表/修改表的時候新增約束。
約束演示
上面我們介紹了資料庫中常見的約束,以及約束涉及到的關鍵字,那這些約束我們到底如何在建立表、
修改表的時候來指定呢,接下來我們就通過一個案例,來演示一下。
案例需求: 根據需求,完成表結構的建立。需求如下:
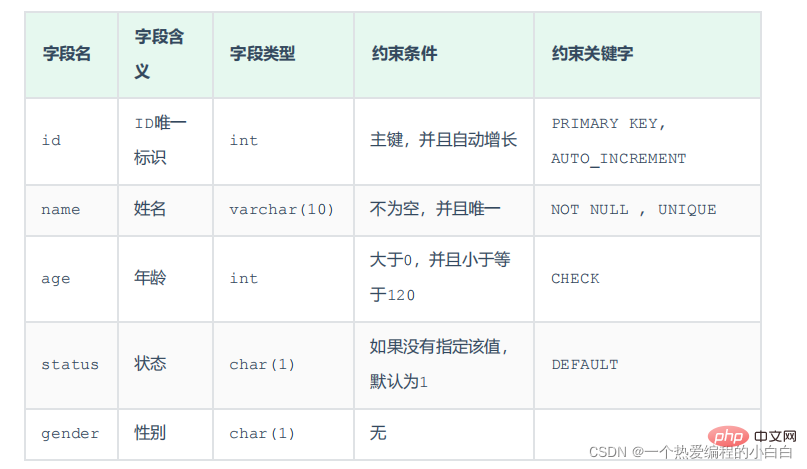
對應的建表語句為:
CREATE TABLE tb_user
(
id int AUTO_INCREMENT PRIMARY KEY COMMENT 'ID唯一標識',
name varchar(10) NOT NULL UNIQUE COMMENT '姓名',
age tinyint unsigned COMMENT '年齡',
status char(1) default '1' COMMENT '狀態',
gender char(1) COMMENT '性別'
);如果你的Mysql是8版本之後 age可以這樣建立
age int check (age > 0 && age <= 120) COMMENT '年齡' ,
在為欄位新增約束時,我們只需要在欄位之後加上約束的關鍵字即可,需要關注其語法。我們執行上面的SQL把表結構建立完成,然後接下來,就可以通過一組資料進行測試,從而驗證一下,約束是否可以生效。
insert into tb_user(name, age, status, gender)
values ('Tom1', 19, '1', '男'),
('Tom2', 25, '0', '男');
insert into tb_user(name, age, status, gender)
values ('Tom3', 19, '1', '男');
insert into tb_user(name, age, status, gender)
values (null, 19, '1', '男');
insert into tb_user(name, age, status, gender)
values ('Tom3', 19, '1', '男');
insert into tb_user(name, age, status, gender)
values ('Tom4', 80, '1', '男');
insert into tb_user(name, age, status, gender)
values ('Tom5', -1, '1', '男');
insert into tb_user(name, age, status, gender)
values ('Tom5', 121, '1', '男');
insert into tb_user(name, age, gender)
values ('Tom5', 120, '男');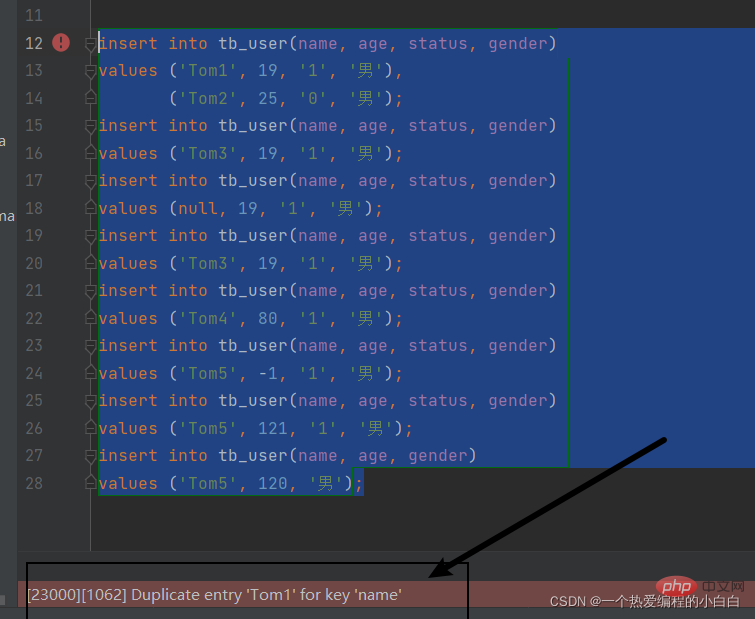

可見 對於我們設定name的約束: 非空 且唯一 生效。
上面,我們是通過編寫SQL語句的形式來完成約束的指定,那加入我們是通過圖形化介面來建立表結構時,又該如何來指定約束呢? 只需要在建立表的時候,根據我們的需要選擇對應的約束即可。
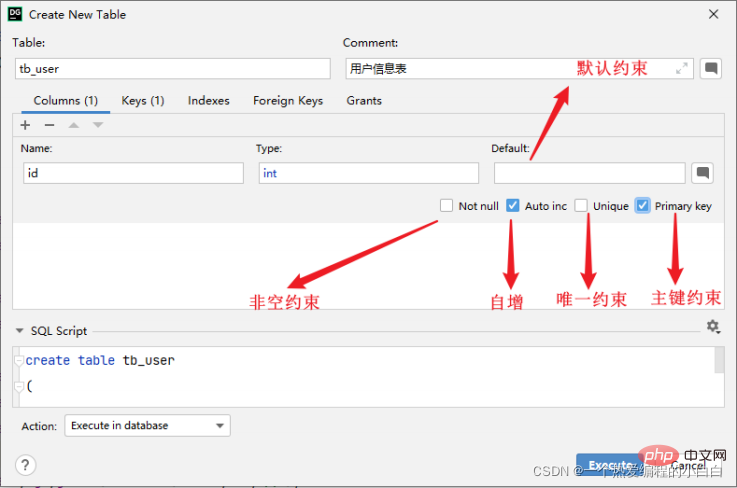
外來鍵約束
介紹
外來鍵:用來讓兩張表的資料之間建立連線,從而保證資料的一致性和完整性。
我們來看一個例子:
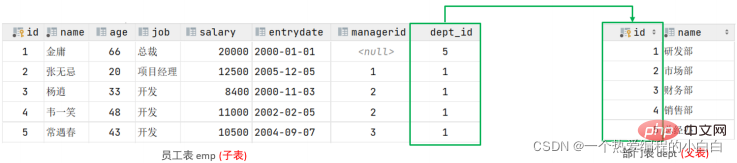
左側的emp表是員工表,裡面儲存員工的基本資訊,包含員工的ID、姓名、年齡、職位、薪資、入職日 期、上級主管ID、部門ID,在員工的資訊中儲存的是部門的ID dept_id,而這個部門的ID是關聯的部門表dept的主鍵id,那emp表的dept_id就是外來鍵,關聯的是另一張表的主鍵。
注意:目前上述兩張表,只是在邏輯上存在這樣一層關係;在資料庫層面,並未建立外來鍵關聯,所以是無法保證資料的一致性和完整性的。
沒有資料庫外來鍵關聯的情況下,能夠保證一致性和完整性呢,我們來測試一下。
準備資料
create table dept
(
id int auto_increment comment 'ID' primary key,
name varchar(50) not null comment '部門名稱'
) comment '部門表';
INSERT INTO dept (id, name)
VALUES (1, '研發部'),
(2, '市場部'),
(3, '財務部'),
(4, '銷售部'),
(5, '總經辦');
create table emp
(
id int auto_increment comment 'ID' primary key,
name varchar(50) not null comment '姓名',
age int comment '年齡',
job varchar(20) comment '職位',
salary int comment '薪資',
entrydate date comment '入職時間',
managerid int comment '直屬領導ID',
dept_id int comment '部門ID'
) comment '員工表';
INSERT INTO emp (id, name, age, job, salary, entrydate, managerid, dept_id)
VALUES (1, '金庸', 66, '總裁', 20000, '2000-01-01', null, 5),
(2, '張無忌', 20, '專案經理', 12500, '2005-12-05', 1, 1),
(3, '楊逍', 33, '開發', 8400, '2000-11-03', 2, 1),
(4, '韋一笑', 48, '開 發', 11000, '2002-02-05', 2, 1),
(5, '常遇春', 43, '開發', 10500, '2004-09-07', 3, 1),
(6, '小昭', 19, '程 序員鼓勵師', 6600, '2004-10-12', 2, 1);
接下來,我們可以做一個測試,刪除id為1的部門資訊。
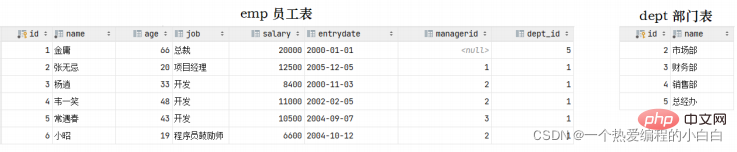
結果,我們看到刪除成功,而刪除成功之後,部門表不存在id為1的部門,而在emp表中還有很多的員工,關聯的為id為1的部門,此時就出現了資料的不完整性。 而要想解決這個問題就得通過資料庫的外來鍵約束。
語法
1). 新增外來鍵
CREATE TABLE 表名
(
欄位名 資料型別, ... [
CONSTRAINT] [
外來鍵名稱]
FOREIGN
KEY
(
外來鍵欄位名
) REFERENCES 主表
(
主表列名
) );ALTER TABLE 表名
ADD CONSTRAINT 外來鍵名稱 FOREIGN KEY (外來鍵欄位名) REFERENCES 主表 (主表列名);案例:
為emp表的dept_id欄位新增外來鍵約束,關聯dept表的主鍵id。
alter table emp
add constraint fk_emp_dept_id foreign key (dept_id) references dept (id);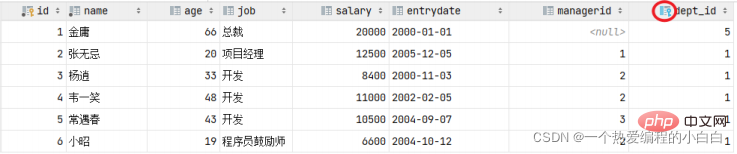
新增了外來鍵約束之後,我們再到dept表(父表)刪除id為1的記錄,然後看一下會發生什麼現象。 此時
將會報錯,不能刪除或更新父表記錄,因為存在外來鍵約束。

2). 刪除外來鍵
ALTER TABLE 表名 DROP FOREIGN KEY 外來鍵名稱;
案例:
刪除emp表的外來鍵fk_emp_dept_id
alter table emp drop foreign key fk_emp_dept_id; 1
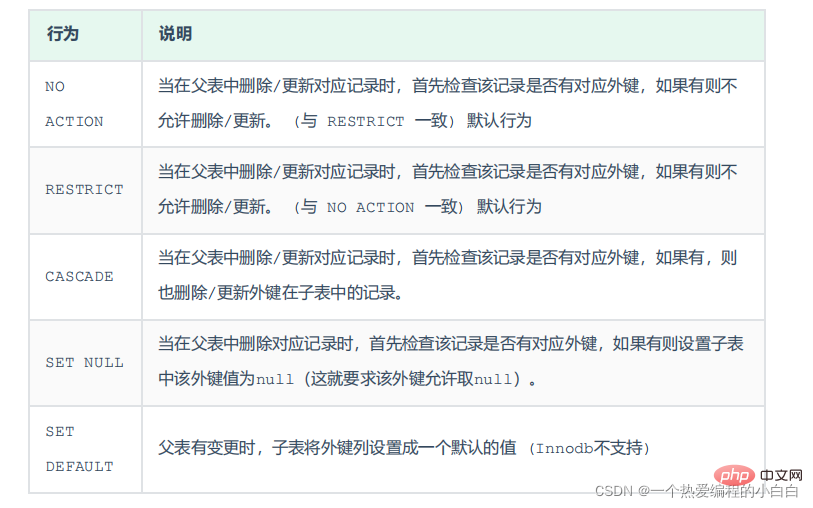
刪除/更新行為
新增了外來鍵之後,再刪除父表資料時產生的約束行為,我們就稱為刪除/更新行為。具體的刪除/更新行為有以下幾種:
具體語法為:
ALTER TABLE 表名
ADD CONSTRAINT 外來鍵名稱 FOREIGN KEY (外來鍵欄位) REFERENCES 主表名 (主表欄位名) ON UPDATE CASCADE ON DELETE CASCADE;演示如下:
由於NO ACTION 是預設行為,我們前面語法演示的時候,已經測試過了,就不再演示了,這裡我們再
演示其他的兩種行為:CASCADE、SET NULL。
1). CASCADE
alter table emp
add constraint fk_emp_dept_id foreign key (dept_id) references dept (id) on update cascade on delete cascade;A. 修改父表id為1的記錄,將id修改為6

我們發現,原來在子表中dept_id值為1的記錄,現在也變為6了,這就是cascade級聯的效果
在一般的業務系統中,不會修改一張表的主鍵值。
B. 刪除父表id為6的記錄

我們發現,父表的資料刪除成功了,但是子表中關聯的記錄也被級聯刪除了。
2). SET NULL
在進行測試之前,我們先需要刪除上面建立的外來鍵 fk_emp_dept_id。然後再通過資料指令碼,將 emp、dept表的資料恢復了。
alter table emp
add constraint fk_emp_dept_id
foreign key (dept_id) references dept (id) on update set null on delete set null;接下來,我們刪除id為1的資料,看看會發生什麼樣的現象。
我們發現父表的記錄是可以正常的刪除的,父表的資料刪除之後,再開啟子表 emp,我們發現子表emp 的dept_id欄位,原來dept_id為1的資料,現在都被置為NULL了
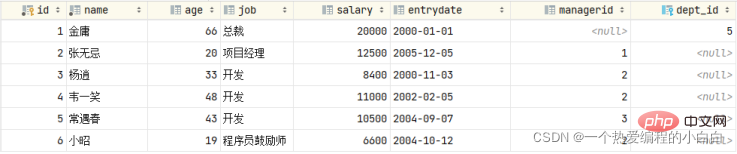
這就是SET NULL這種刪除/更新行為的效果。
2.多表查詢
我們之前在講解SQL語句的時候,講解了DQL語句,也就是資料查詢語句,但是之前講解的查詢都是單表查詢,而本章節我們要學習的則是多表查詢操作,主要從以下幾個方面進行講解。
多表關係
專案開發中,在進行資料庫表結構設計時,會根據業務需求及業務模組之間的關係,分析並設計表結 構,由於業務之間相互關聯,所以各個表結構之間也存在著各種聯絡,基本上分為三種:
一對多(多對一) 多對多 一對一
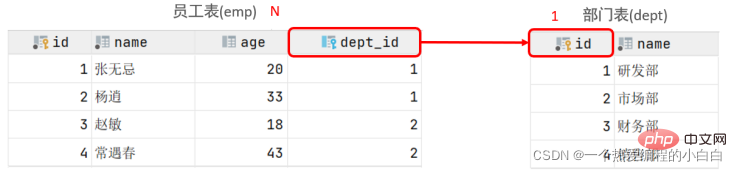
1.一對多
案例: 部門 與 員工的關係
關係: 一個部門對應多個員工,一個員工對應一個部門
實現: 在多的一方建立外來鍵,指向一的一方的主鍵
2.多對多
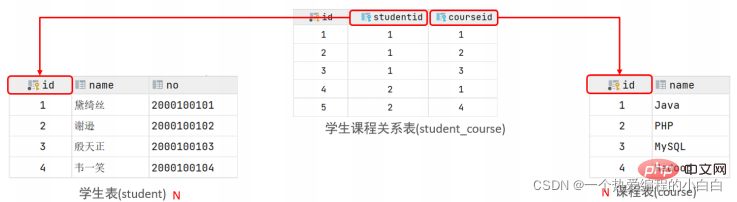
案例: 學生 與 課程的關係
關係: 一個學生可以選修多門課程,一門課程也可以供多個學生選擇
實現: 建立第三張中間表,中間表至少包含兩個外來鍵,分別關聯兩方主鍵
對應的SQL指令碼:
create table student
(
id int auto_increment primary key comment '主鍵ID',
name varchar(10) comment '姓名',
no varchar(10) comment '學號'
) comment '學生表';
insert into student
values (null, '黛綺絲', '2000100101'),
(null, '謝遜', '2000100102'),
(null, '殷天正', '2000100103'),
(null, '韋一笑', '2000100104');
create table course
(
id int auto_increment primary key comment '主鍵ID',
name varchar(10) comment '課程名稱'
) comment '課程表';
insert into course
values (null, 'Java'),
(null, 'PHP'),
(null, 'MySQL'),
(null, 'Hadoop');
create table student_course
(
id int auto_increment comment '主鍵' primary key,
studentid int not null comment '學生ID',
courseid int not null comment '課程ID',
constraint fk_courseid foreign key (courseid) references course (id),
constraint fk_studentid foreign key (studentid) references student (id)
) comment '學生課程中間表';
insert into student_course
values (null, 1, 1),
(null, 1, 2),
(null, 1, 3),
(null, 2, 2),
(null, 2, 3),
(null, 3, 4);3.一對一
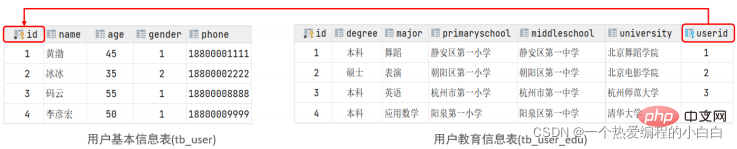
案例: 使用者與 使用者詳情的關係
關係: 一對一關係,多用於單表拆分,將一張表的基礎欄位放在一張表中,其他詳情欄位放在另一張表中,以提升操作效率
實現: 在任意一方加入外來鍵,關聯另外一方的主鍵,並且設定外來鍵為唯一的(UNIQUE)
對應的SQL指令碼:
create table tb_user
(
id int auto_increment primary key comment '主鍵ID',
name varchar(10) comment '姓名',
age int comment '年齡',
gender char(1) comment '1: 男 , 2: 女',
phone char(11) comment '手機號'
) comment '使用者基本資訊表';
create table tb_user_edu
(
id int auto_increment primary key comment '主鍵ID',
degree varchar(20) comment '學歷',
major varchar(50) comment '專業',
primaryschool varchar(50) comment '小學',
middleschool varchar(50) comment '中學',
university varchar(50) comment '大學',
userid int unique comment '使用者ID',
constraint fk_userid foreign key (userid) references tb_user (id)
) comment '使用者教育資訊表';
insert into tb_user(id, name, age, gender, phone)
values (null, '黃渤', 45, '1', '18800001111'),
(null, '冰冰', 35, '2', '18800002222'),
(null, '碼雲', 55, '1', '18800008888'),
(null, '李彥宏', 50, '1', '18800009999');
insert into tb_user_edu(id, degree, major, primaryschool, middleschool, university, userid)
values (null, '本科', '舞蹈', '靜安區第一小學', '靜安區第一中學', '北京舞蹈學院', 1),
(null, '碩士', '表演', '朝陽區第一小學', '朝陽區第一中學', '北京電影學院', 2),
(null, '本科', '英語', '杭州市第一小學', '杭州市第一中學', '杭州師範大學', 3),
(null, '本科', '應用數學', '陽泉第一小學', '陽泉區第一中學', '清華大學', 4);3.多表查詢概述
1.資料準備
1). 刪除之前 emp, dept表的測試資料
2). 執行如下指令碼,建立emp表與dept表並插入測試資料
-- 建立dept表,並插入資料
create table dept
(
id int auto_increment comment 'ID' primary key,
name varchar(50) not null comment '部門名稱'
) comment '部門表';
INSERT INTO dept (id, name)
VALUES (1, '研發部'),
(2, '市場部'),
(3, '財務部'),
(4, '銷售部'),
(5, '總經辦'),
(6, '人事部');
-- 建立emp表,並插入資料
create table emp
(
id int auto_increment comment 'ID' primary key,
name varchar(50) not null comment '姓名',
age int comment '年齡',
job varchar(20) comment '職位',
salary int comment '薪資',
entrydate date comment '入職時間',
managerid int comment '直屬領導ID',
dept_id int comment '部門ID'
) comment '員工表';
-- 新增外來鍵
alter table emp
add constraint fk_emp_dept_id foreign key (dept_id) references dept (id);
INSERT INTO emp (id, name, age, job, salary, entrydate, managerid, dept_id)
VALUES (1, '金庸', 66, '總裁', 20000, '2000-01-01', null, 5),
(2, '張無忌', 20, '專案經理', 12500, '2005-12-05', 1, 1),
(3, '楊逍', 33, '開發', 8400, '2000-11-03', 2, 1),
(4, '韋一笑', 48, '開發', 11000, '2002-02-05', 2, 1),
(5, '常遇春', 43, '開發', 10500, '2004-09-07', 3, 1),
(6, '小昭', 19, '程式設計師鼓勵師', 6600, '2004-10-12', 2, 1),
(7, '滅絕', 60, '財務總監', 8500, '2002-09-12', 1, 3),
(8, '周芷若', 19, '會計', 48000, '2006-06-02', 7, 3),
(9, '丁敏君', 23, '出納', 5250, '2009-05-13', 7, 3),
(10, '趙敏', 20, '市場部總監', 12500, '2004-10-12', 1, 2),
(11, '鹿杖客', 56, '職員', 3750, '2006-10-03', 10, 2),
(12, '鶴筆翁', 19, '職員', 3750, '2007-05-09', 10, 2),
(13, '方東白', 19, '職員', 5500, '2009-02-12', 10, 2),
(14, '張三丰', 88, '銷售總監', 14000, '2004-10-12', 1, 4),
(15, '俞蓮舟', 38, '銷售', 4600, '2004-10-12', 14, 4),
(16, '宋遠橋', 40, '銷售', 4600, '2004-10-12', 14, 4),
(17, '陳友諒', 42, null, 2000, '2011-10-12', 1, null)dept表共6條記錄,emp表共17條記錄。
2.概述
多表查詢就是指從多張表中查詢資料。
原來查詢單表資料,執行的SQL形式為:select * from emp;
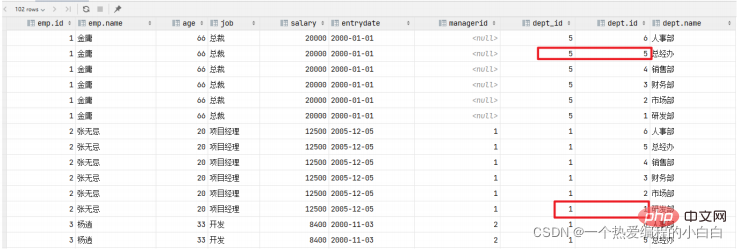
那麼我們要執行多表查詢,就只需要使用逗號分隔多張表即可,如: select * from emp , dept ; 具體的執行結果如下:
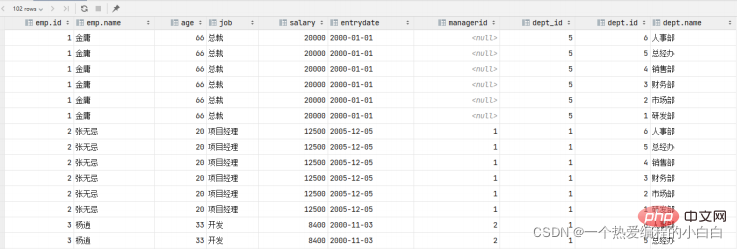
此時,我們看到查詢結果中包含了大量的結果集,總共102條記錄,而這其實就是員工表emp所有的記錄 (17) 與 部門表dept所有記錄(6) 的所有組合情況,這種現象稱之為笛卡爾積。接下來,就來簡單 介紹下笛卡爾積。
笛卡爾積: 笛卡爾乘積是指在數學中,兩個集合A集合 和 B集合的所有組合情況。
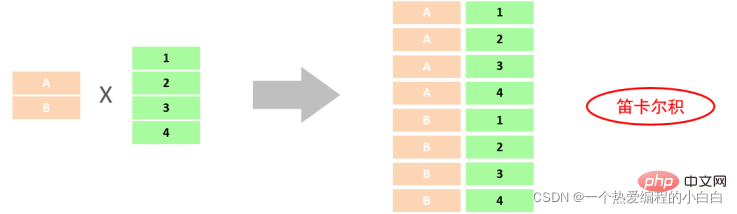
而在多表查詢中,我們是需要消除無效的笛卡爾積的,只保留兩張表關聯部分的資料。

在SQL語句中,如何來去除無效的笛卡爾積呢? 我們可以給多表查詢加上連線查詢的條件即可。
select * from emp , dept where emp.dept_id = dept.id;
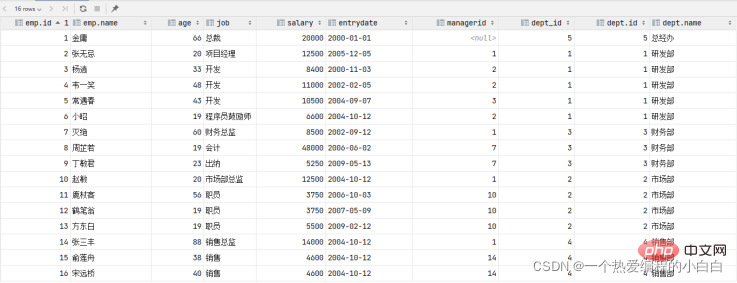
而由於id為17的員工,沒有dept_id欄位值,所以在多表查詢時,根據連線查詢的條件並沒有查詢到。
4.分類
連線查詢
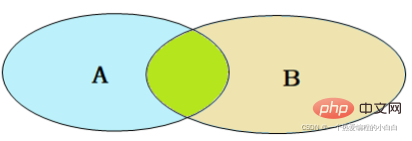
內連線:相當於查詢A、B交集部分資料
外連線:
左外連線:查詢左表所有資料,以及兩張表交集部分資料
右外連線:查詢右表所有資料,以及兩張表交集部分資料
自連線:當前表與自身的連線查詢,自連線必須使用表別名
子查詢
1.內連線
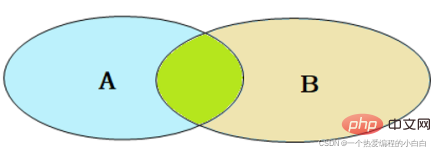
內連線查詢的是兩張表交集部分的資料。(也就是綠色部分的資料)
內連線的語法分為兩種: 隱式內連線、顯式內連線。先來學習一下具體的語法結構。
1). 隱式內連線
SELECT 欄位列表 FROM 表1 , 表2 WHERE 條件 ... ;
2). 顯式內連線
SELECT 欄位列表 FROM 表1 [ INNER ] JOIN 表2 ON 連線條件 ... ;
案例:
A. 查詢每一個員工的姓名 , 及關聯的部門的名稱 (隱式內連線實現)
表結構: emp , dept
連線條件: emp.dept_id = dept.id
select emp.name, dept.name
from emp,
dept
where emp.dept_id = dept.id;
-- 為每一張表起別名,簡化SQL編寫
select e.name,d.name from emp e , dept d where e.dept_id = d.id;B. 查詢每一個員工的姓名 , 及關聯的部門的名稱 (顯式內連線實現) --- INNER JOIN ...
ON ...
表結構: emp , dept
連線條件: emp.dept_id = dept.id
select e.name, d.name
from emp e
inner join dept d on e.dept_id = d.id;
-- 為每一張表起別名,簡化SQL編寫
select e.name, d.name from emp e join dept d on e.dept_id = d.id;表的別名:
①. tablea as 別名1 , tableb as 別名2 ;
②. tablea 別名1 , tableb 別名2 ;
注意事項:一旦為表起了別名,就不能再使用表名來指定對應的欄位了,此時只能夠使用別名來指定字段。
2.外連線
外連線分為兩種,分別是:左外連線 和 右外連線。具體的語法結構為:
1). 左外連線
SELECT 欄位列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 條件 ... ;
左外連線相當於查詢表1(左表)的所有資料,當然也包含表1和表2交集部分的資料。
2). 右外連線
SELECT 欄位列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 條件 ... ;
右外連線相當於查詢表2(右表)的所有資料,當然也包含表1和表2交集部分的資料。
案例:
A. 查詢emp表的所有資料, 和對應的部門資訊
由於需求中提到,要查詢emp的所有資料,所以是不能內連線查詢的,需要考慮使用外連線查詢。
表結構: emp, dept
連線條件: emp.dept_id = dept.id
select e.*, d.name
from emp e
left outer join dept d on e.dept_id = d.id;
select e.*, d.name
from emp e
left join dept d on e.dept_id = d.id; 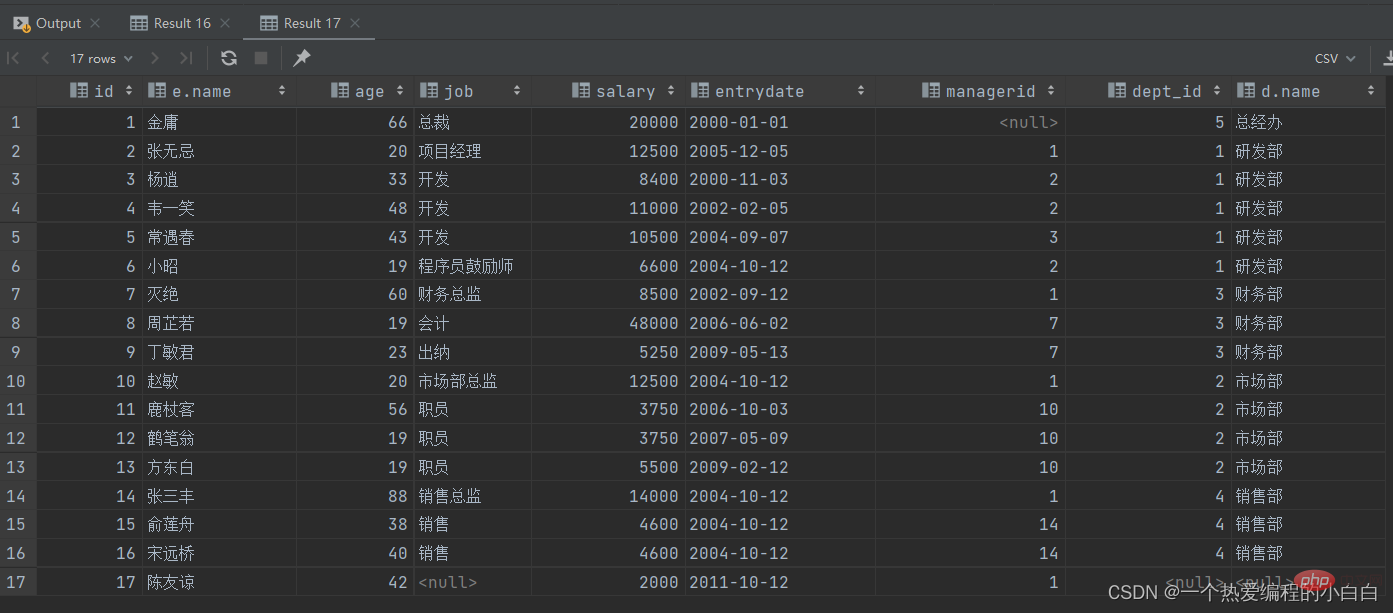
B. 查詢dept表的所有資料, 和對應的員工資訊(右外連線)
由於需求中提到,要查詢dept表的所有資料,所以是不能內連線查詢的,需要考慮使用外連線查詢。
表結構: emp, dept
連線條件: emp.dept_id = dept.id
select d.*, e.*
from emp e
right outer join dept d on e.dept_id = d.id;
select d.*, e.*
from dept d
left outer join emp e on e.dept_id = d.id;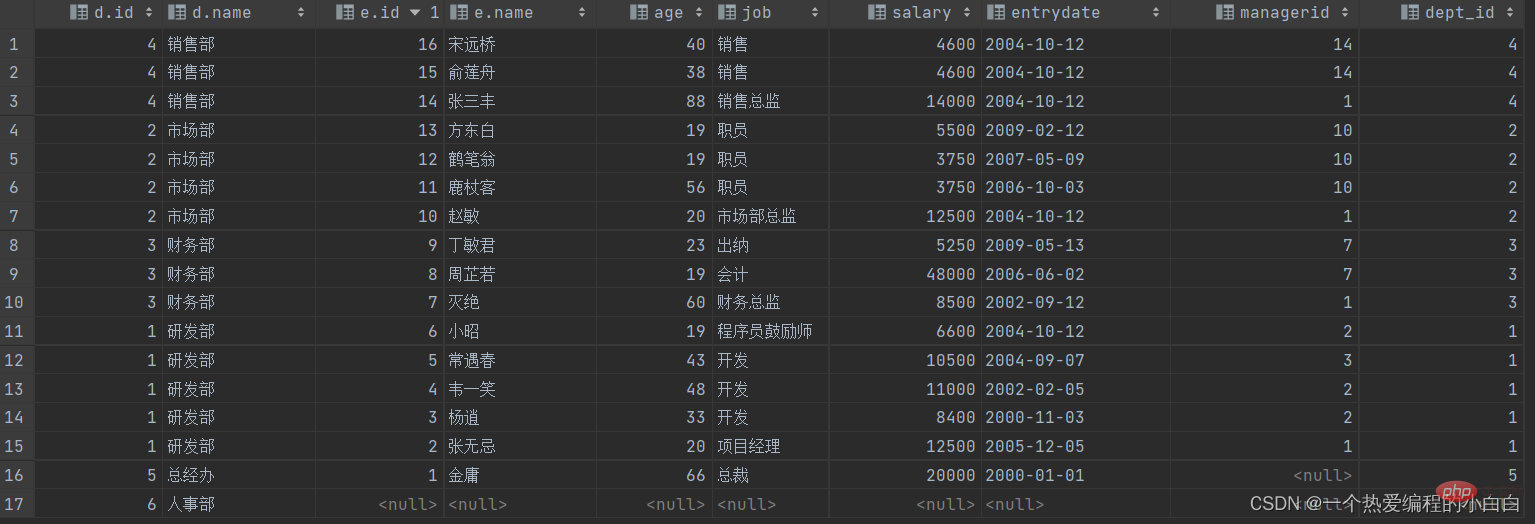
注意事項:
左外連線和右外連線是可以相互替換的,只需要調整在連線查詢時SQL中,表結構的先後順
序就可以了。而我們在日常開發使用時,更偏向於左外連線。
3.自連線
1.自連線查詢
自連線查詢,顧名思義,就是自己連線自己,也就是把一張表連線查詢多次。我們先來學習一下自連線的查詢語法:
SELECT 欄位列表 FROM 表A 別名A JOIN 表A 別名B ON 條件 ... ;而對於自連線查詢,可以是內連線查詢,也可以是外連線查詢
案例:
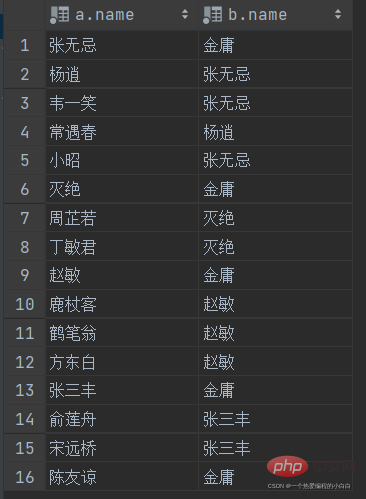
A. 查詢員工 及其 所屬領導的名字
表結構: emp
select a.name , b.name from emp a , emp b where a.managerid = b.id;
B. 查詢所有員工 emp 及其領導的名字 emp , 如果員工沒有領導, 也需要查詢出來
表結構: emp a , emp b
select a.name '員工', b.name '領導'
from emp a
left join emp b on a.managerid = b.id;注意事項:
在自連線查詢中,必須要為表起別名,要不然我們不清楚所指定的條件、返回的欄位,到底
是哪一張表的欄位。
2.聯合查詢
對於union查詢,就是把多次查詢的結果合併起來,形成一個新的查詢結果集。
SELECT 欄位列表 FROM 表A... UNION [ ALL ] SELECT 欄位列表 FROM 表B....;
對於聯合查詢的多張表的列數必須保持一致,欄位型別也需要保持一致。
union all 會將全部的資料直接合並在一起,union 會對合並之後的資料去重。
案例:
A. 將薪資低於 5000 的員工 , 和 年齡大於 50 歲的員工全部查詢出來.
當前對於這個需求,我們可以直接使用多條件查詢,使用邏輯運運算元 or 連線即可。 那這裡呢,我們 也可以通過union/union all來聯合查詢.
select * from emp where salary < 5000 union all select * from emp where age > 50;
union all查詢出來的結果,僅僅進行簡單的合併,並未去重。
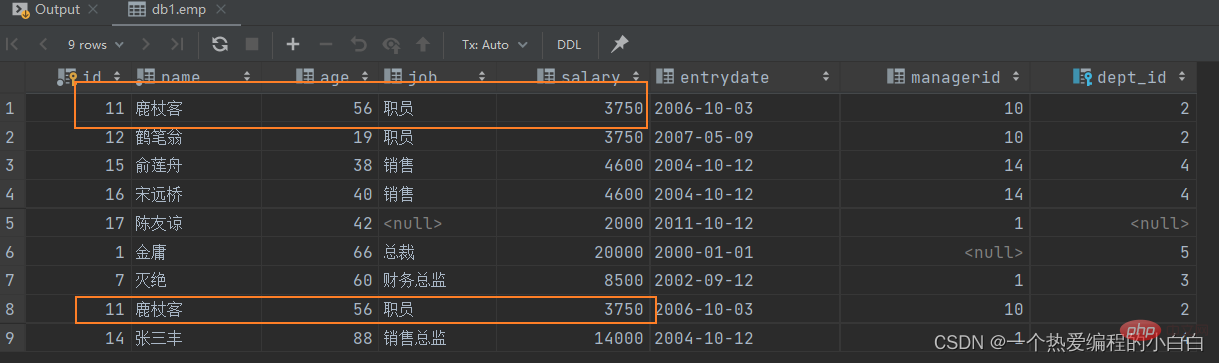
select * from emp where salary < 5000 union select * from emp where age > 50;
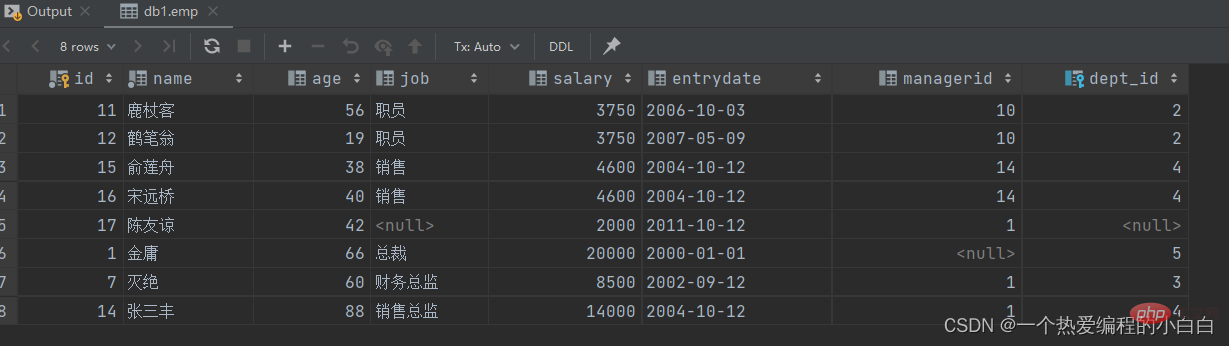
union 聯合查詢,會對查詢出來的結果進行去重處理。
注意:
如果多條查詢語句查詢出來的結果,欄位數量不一致,在進行union/union all聯合查詢時,將會報
錯。如:

4.子查詢
1.概述
1). 概念
SQL語句中巢狀SELECT語句,稱為巢狀查詢,又稱子查詢。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 );
子查詢外部的語句可以是INSERT / UPDATE / DELETE / SELECT 的任何一個。
2). 分類
根據子查詢結果不同,分為:
A. 標量子查詢(子查詢結果為單個值)
B. 列子查詢(子查詢結果為一列)
C. 行子查詢(子查詢結果為一行)
D. 表子查詢(子查詢結果為多行多列)
根據子查詢位置,分為:
A. WHERE之後
B. FROM之後
C. SELECT之後
2.標量子查詢
子查詢返回的結果是單個值(數位、字串、日期等),最簡單的形式,這種子查詢稱為標量子查詢。
常用的操作符:= <> > >= < <=
案例:
A. 查詢 "銷售部" 的所有員工資訊
完成這個需求時,我們可以將需求分解為兩步:
查詢 "銷售部" 部門ID
select id from dept where name = '銷售部';
根據 "銷售部" 部門ID, 查詢員工資訊
select * from emp where dept_id = (select id from dept where name = '銷售部');

B. 查詢在 "方東白" 入職之後的員工資訊
完成這個需求時,我們可以將需求分解為兩步:
查詢 方東白 的入職日期
select entrydate from emp where name = '方東白';
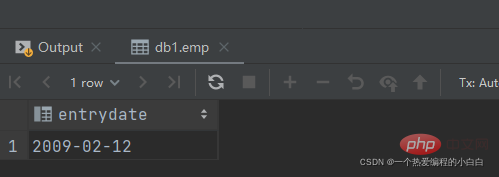
查詢指定入職日期之後入職的員工資訊
select * from emp where entrydate > (select entrydate from emp where name = '方東白');

3.列子查詢
子查詢返回的結果是一列(可以是多行),這種子查詢稱為列子查詢。
常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
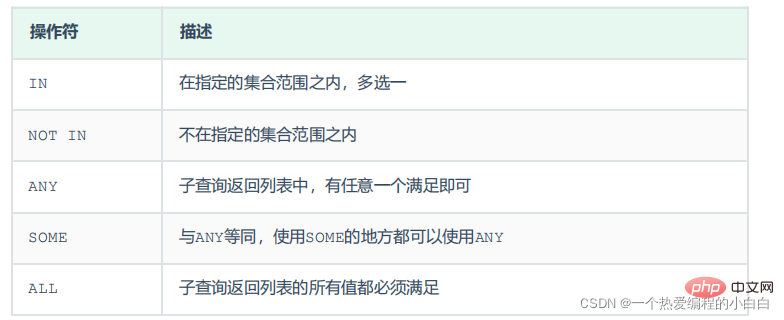
案例:
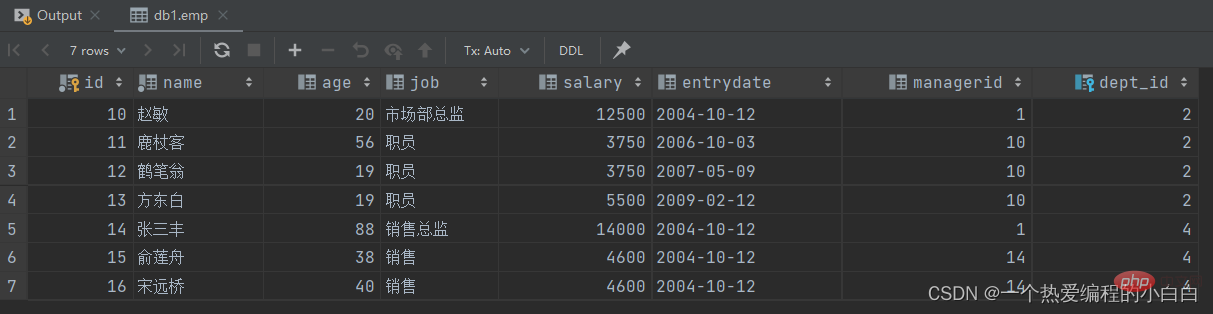
A. 查詢 "銷售部" 和 "市場部" 的所有員工資訊
分解為以下兩步:
查詢 "銷售部" 和 "市場部" 的部門ID
select id from dept where name = '銷售部' or name = '市場部';
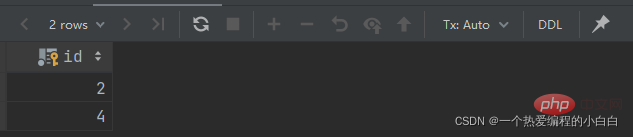
根據部門ID, 查詢員工資訊
select * from emp where dept_id in (select id from dept where name = '銷售部' or name = '市場部');
B. 查詢比 財務部 所有人工資都高的員工資訊
分解為以下兩步:
查詢所有 財務部 人員工資
select salary from emp where dept_id = (select id from dept where name = '財務部');
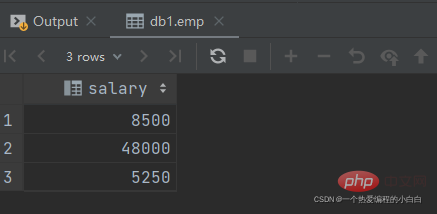
比 財務部 所有人工資都高的員工資訊
select * from emp where salary > all (select salary from emp where dept_id = (select id from dept where name = '財務部'));
C. 查詢比研發部其中任意一人工資高的員工資訊
分解為以下兩步:
查詢研發部所有人工資
select salary from emp where dept_id = (select id from dept where name = '研發部');
比研部其中任意一人工資高的員工資訊
select * from emp where salary > any (select salary from emp where dept_id = (select id from dept where name = '研發部'));
4.行子查詢
子查詢返回的結果是一行(可以是多列),這種子查詢稱為行子查詢。
常用的操作符:= 、<> 、IN 、NOT IN
案例:
A. 查詢與 "張無忌" 的薪資及直屬領導相同的員工資訊 ;
這個需求同樣可以拆解為兩步進行:
查詢 "張無忌" 的薪資及直屬領導
select salary, managerid from emp where name = '張無忌';
查詢與 "張無忌" 的薪資及直屬領導相同的員工資訊 ;
select * from emp where (salary, managerid) = (select salary, managerid from emp where name = '張無忌');

5.表子查詢
子查詢返回的結果是多行多列,這種子查詢稱為表子查詢。
常用的操作符:IN
案例:
A. 查詢與 "鹿杖客" , "宋遠橋" 的職位和薪資相同的員工資訊
分解為兩步執行:
查詢 "鹿杖客" , "宋遠橋" 的職位和薪資
select job, salary from emp where name = '鹿杖客' or name = '宋遠橋';
查詢與 "鹿杖客" , "宋遠橋" 的職位和薪資相同的員工資訊
select * from emp where (job, salary) in (select job, salary from emp where name = '鹿杖客' or name = '宋遠橋');
B. 查詢入職日期是 "2006-01-01" 之後的員工資訊 , 及其部門資訊
分解為兩步執行:
入職日期是 "2006-01-01" 之後的員工資訊
select * from emp where entrydate > '2006-01-01';
.查詢這部分員工, 對應的部門資訊;
select e.*, d.*
from (select * from emp where entrydate > '2006-01-01') e
left join dept d on e.dept_id = d.id;推薦學習:
以上就是MySQL約束與多表查詢基礎詳解的詳細內容,更多請關注TW511.COM其它相關文章!