避坑手冊 | JAVA編碼中容易踩坑的十大陷阱

JAVA編碼中存在一些容易被人忽視的陷阱,稍不留神可能就會跌落其中,給專案的穩定執行埋下隱患。此外,這些陷阱也是面試的時候面試官比較喜歡問的問題。
本文對這些陷阱進行了統一的整理,讓你知道應該如何避免落入陷阱中,下面就一起來了解下吧。
迴圈中操作目標list
遍歷List然後對list中符合條件的元素進行刪除操作,這是專案裡面非常常見的一個場景。
先看下兩種典型的錯誤寫法:
錯誤寫法1:
for (User user : userList) {
if ("男".equals(user.getSex())) {
userList.remove(user);
}
}
錯誤原因:
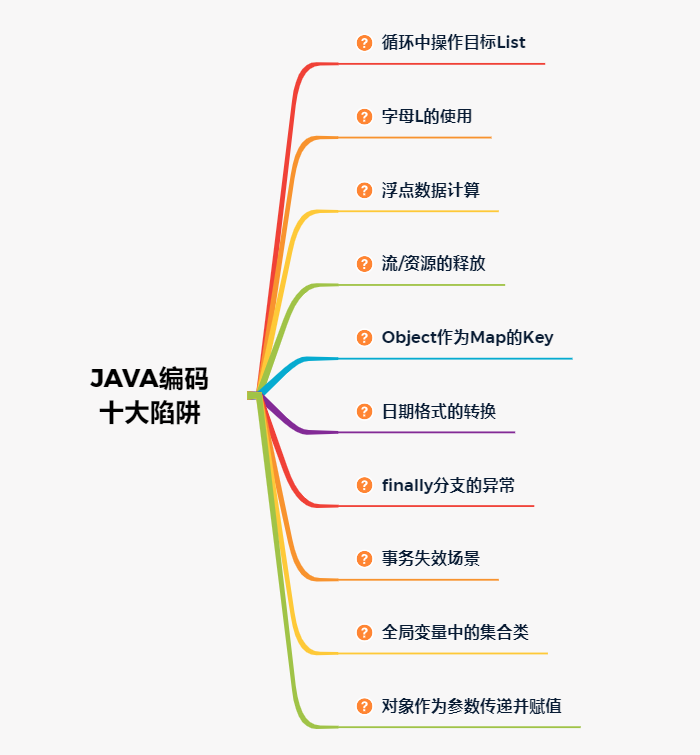
在迴圈或迭代時,會首先建立一個迭代範例,這個迭代範例的expectedModCount 賦值為集合的modCount。而每當迭代器使⽤ hashNext() / next() 遍歷下⼀個元素之前,都會檢測 modCount 變數與expectedModCount 值是否相等,相等的話就返回遍歷;否則就丟擲異常ConcurrentModificationException,終⽌遍歷。
如果在迴圈中新增或刪除元素,是直接呼叫集合的add(),remove()方法,導致了modCount增加或減少,但這些方法不會修改迭代範例中的expectedModCount,導致在迭代範例中expectedModCount與 modCount的值不相等,丟擲ConcurrentModificationException異常。
錯誤寫法2:
for (int i = 0; i < userList.size(); i++>) {
if ("男".equals(user.getSex())) {
userList.remove(i);
}
}
錯誤原因:
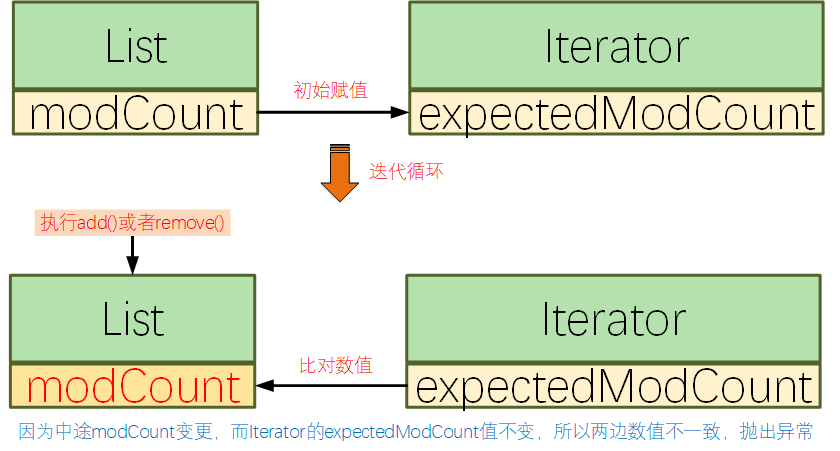
刪除元素之後,元素下標發生前移,但是指標是不變的,再處理下一個的時候,就可能會有部分元素被漏掉沒有處理。
那正確的方式應該如何處理呢?接著往下看。
正確寫法1:
// 使用迭代器來實現
Iterator iterator = userList.iterator();
while (iterator.hasNext()) {
if ("男".equals(user.getSex())) {
iterator.remove();
}
}
補充說明:
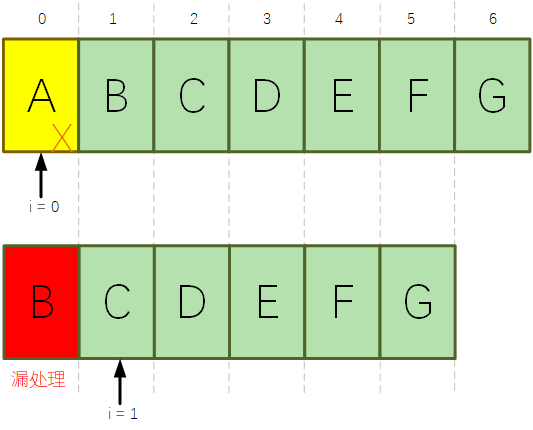
與前面的錯誤寫法1相對比,同樣都是基於迭代器的邏輯,為什麼這種寫法就對了呢?
這是因為迭代器中的remove(),add()方法,會在呼叫集合的remove(),add()方法後,將expectedModCount重新賦值為modCount,所以在迭代器中增加、刪除元素是可以正常執行的。
正確寫法2:
// 使用Lambda表示式實現
userList.removeIf(user -> "男".equals(user.getSex());
正確寫法3:
// 使用removeAll實現
List<User> maleUsers = new ArrayList<>();
for (User user : userList) {
if ("男".equals(user.getSex())) {
maleUsers.add(user);
}
}
userList.removeAll(maleUsers);
將物件作為引數傳遞並重新賦值
看個例子:
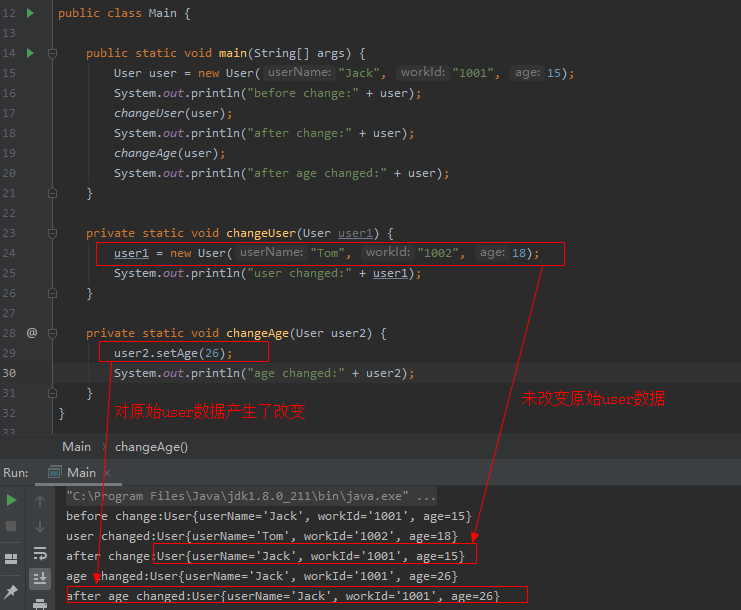
這裡涉及到JAVA中一個值傳遞和參照傳遞的概念。
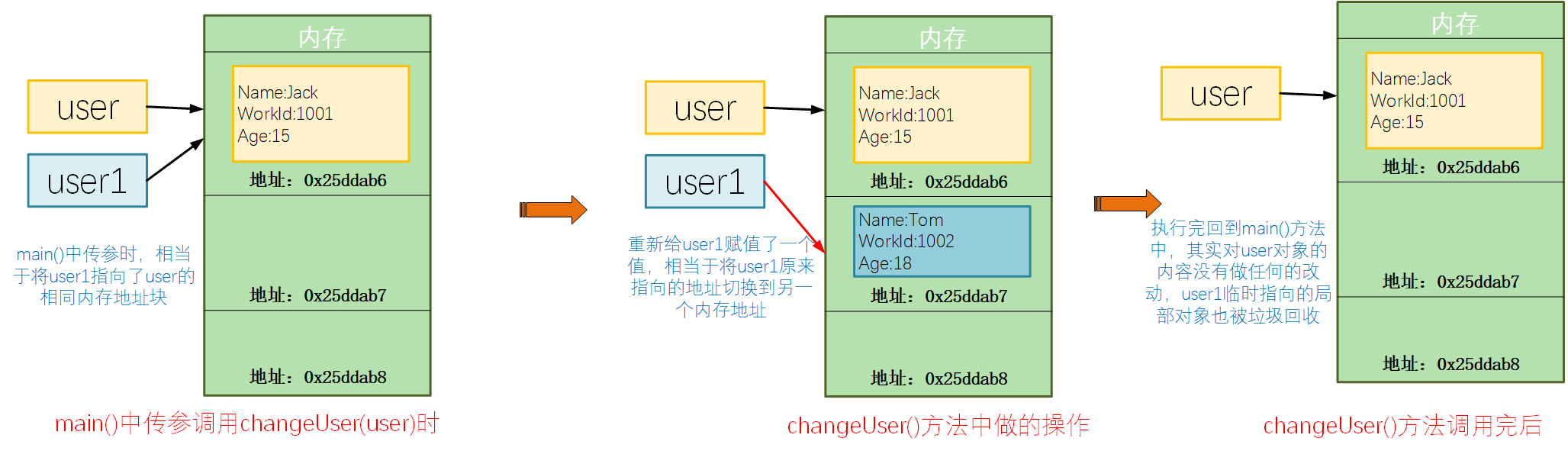
對於一個參照型別而言,引數傳遞的時候,本質上是將一個參照物件對應記憶體地址傳遞過去,引數物件與實際物件指向同一個記憶體塊。對於範例程式碼中的changeUser()方法,將入參重新賦值了一個新的物件,本質上其實是將user1對應指向的記憶體地址資訊更改了,對於原始的user而言,並沒有被改變。
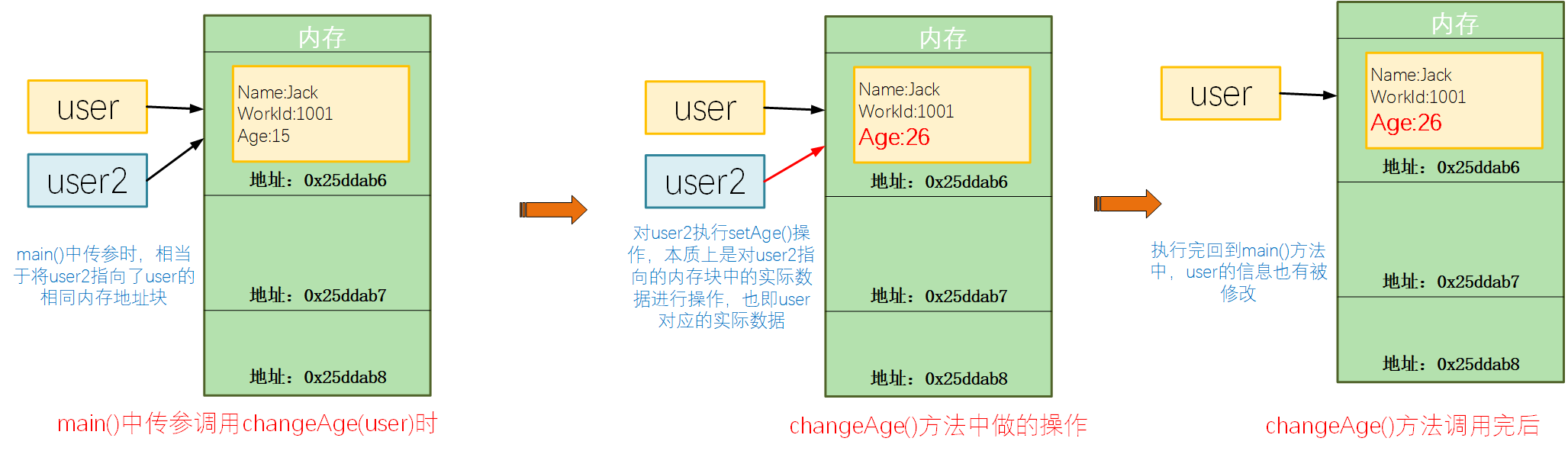
而對於chageAge()方法而言,對user2的操作,本質上是對user2所指向的具體記憶體物件進行操作,也即user對應的記憶體物件資料,所以這種情況下,變更是會生效的。
所以呢,編碼的時候,要注意不能在方法裡面對入參進行重新賦值,可以採用返回值的方式返回個新的結果物件,然後進行賦值操作。
字母L的使用
先看一個例子:
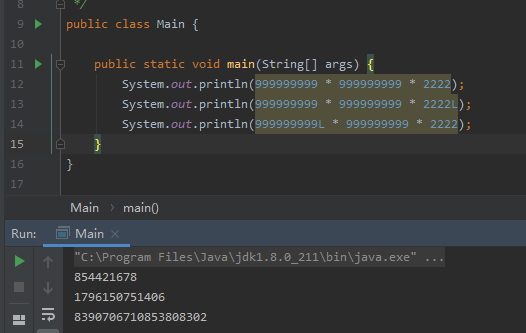
同樣相同的三個數位的相乘,L標識的位置不同,得到的結果也不一樣,那到底哪個是對的呢?
很明顯這個一個JAVA隱式型別轉換的問題。
- 第一個結果顯然是不對的,因為三個int值相乘之後結果明顯超出int長度範圍,所以截斷了。
- 第二個結果,前面兩個int相乘,在與第三個long型運算,結果會自動轉換為long型,但是根據運算順序,前面2個int值運算的中間結果也是int型別,且長度超出範圍被截斷了,截斷後的結果與最後一位long進行的運算,所以第二個結果也是錯的。
- 第三個結果是對的,因為long型放在前面,所以前兩位運算的時候就先轉為long型,再與第三個int運算後,結果依舊是long型,不會出現溢位的情況。

TIPS:
int運算轉long的時候,最好將第一個運算的數位標識為L(long)型,避免中途資料溢位。
再看個例子:
public static void main(String[] args) {
System.out.println(2 * 2l);
}
第一眼看完,想一下答案應該是幾?是42嗎?
其實結果是4,為什麼?因為第二個2後面的是個字母l。雖然這種寫法對於程式而言沒有問題,但是很容易讓開發人員混淆,造成認知上的錯誤。
TIPS:
long數位標識的時候,使用大寫字母L來表示。
流/資源的釋放
開啟的流或者連線,在用完之後需要可靠的退出。但是有一種迴圈中開啟流的場景,需要特別注意,筆者在多年的程式碼review經歷中發現,基本每個專案都會存在迴圈中開啟的流沒有全部可靠釋放的問題。

上面的範例程式碼中,雖然最後finally裡面也有執行流的關閉操作,但是try分支中,inputStream是在一個for迴圈裡面被多次建立了,而最終finally分支中僅關閉了最後一個,之前的流都處於未關閉狀態,造成資源的洩漏。
日期格式轉換的並行場景
很多的專案中都使用SimpleDateFormat來做日期的格式化操作,但是要注意SimpleDataFormat是非執行緒安全的,所以使用的時候需要注意。
但是實際使用的時候,如果每次需要格式化的時候,都去new SimpleDateFormat()物件,這個成本開銷有點大,會對整體的效能造成一定的影響。
所以使用的時候可以採取一些措施,保證執行緒安全的同時也兼顧其處理效能:

事務失效場景
JAVA開發中,經常會使用Spring的@Transactional註解來指定事務回滾的相關策略,但是有時候會發現@Transactional並沒有生效,下面介紹下可能的幾種情況。
finally分支的資料處理
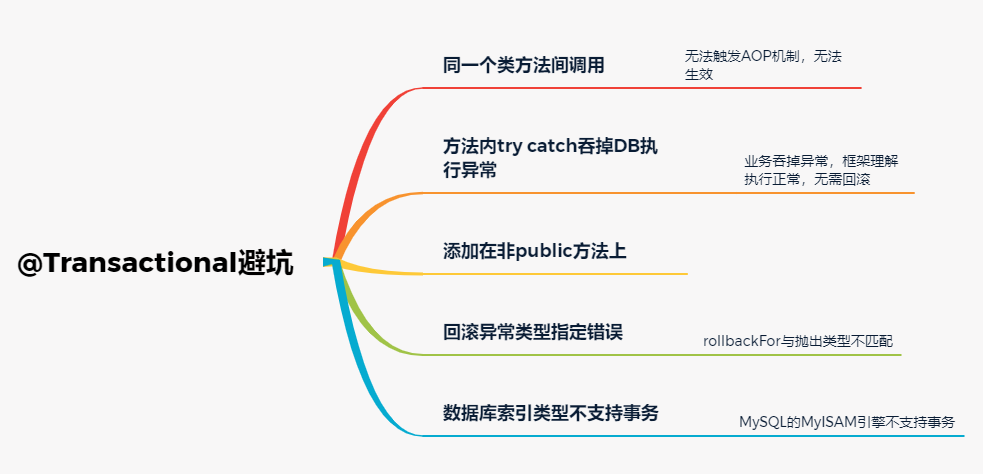
finally分支一般伴隨著try...catch語句一起使用,用來當所有操作退出前執行一些收尾處理邏輯,比如資源釋放、連線關閉等等。但是如果使用不當,也會造成我們的業務邏輯不按預期執行,所以使用的時候要注意。

finally分支中對返回值重新修改
先看下如下程式碼寫法,在try...catch分支中都有return操作,然後再finally中進行返回值修改,最終返回結果並不會被finally中的邏輯修改:
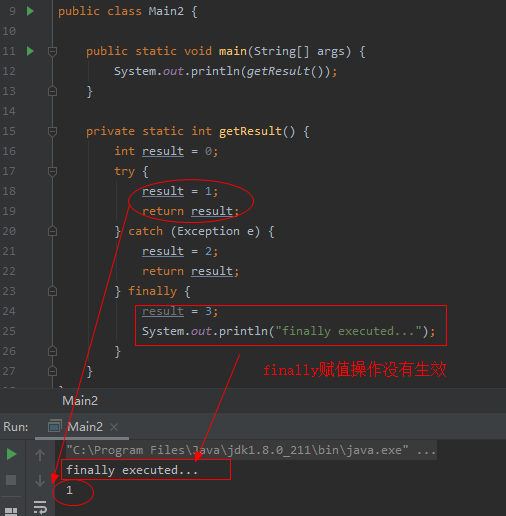
因為如果存在 finally 程式碼塊,try...catch中的return語句不會立馬返回撥用者,而是記錄下返回值的副本,待 finally程式碼塊執行完畢之後再向呼叫者返回其值,然後即使在finally中修改了返回值,也不會返回修改後的值。
再看另一種常見的寫法:
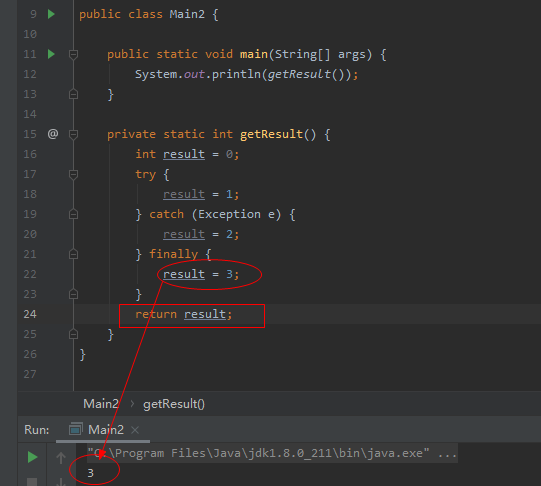
與上面的差異點在於,try...catch分支裡面並沒有return語句,而是finally外面統一執行返回操作,這種情況下就可以生效。其實也很好理解,try...catch...finally這個語句塊裡面沒有return操作,所以也就不會有暫存return副本的邏輯了。
finally分支中直接return
在finally分支裡面存在return語句是一個很不好的實踐。一般的IDEA中也會智慧提示finally裡面存return分支。
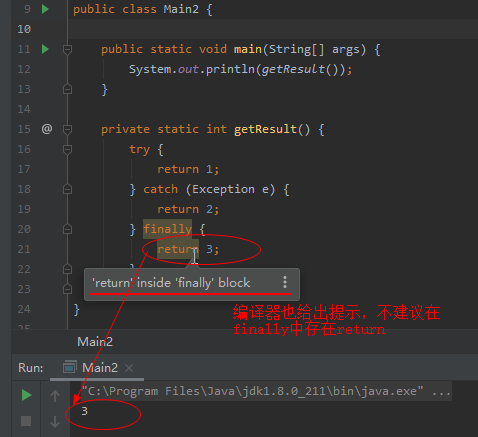
finally裡面如果存在return分支,則finally裡面的返回值會覆蓋掉try...catch邏輯中處理後計劃返回的結果,也即導致try...catch部分的邏輯失效,容易引起業務邏輯上的問題。
finally分支中丟擲異常
一般的編碼規範中,都會要求finally分支裡面的處理邏輯要增加catch保護,防止其丟擲異常。
原因說明:
相對而言,finally裡面執行的都是一些資源釋放類的操作,而try...catch部分則是業務維度的核心邏輯,人們更關心的是catch部分發生的業務層面的異常,如果finally裡面丟擲異常,會導致catch中原本應該要往外拋的異常被丟棄,可能會影響上層邏輯的後續處理。
全域性變數中的集合類
全域性型別的集合類,使用的時候需要注意兩個關鍵點:
- 注意下並行場景的執行緒安全性;
- 注意下資料的最大範圍、是否有資料淘汰機制,避免記憶體無限制增加,導致記憶體溢位。
參考下redis之類的依賴記憶體的快取中介軟體,都有一個繞不開的兜底策略,即資料淘汰機制。對於業務類編碼實現的時候,如果使用Map等容器類來實現全域性快取的時候,應該要結合實際部署情況,確定記憶體中允許的最巨量資料條數,並提供超出指定容量時的處理策略。比如我們可以基於LinkedHashMap來客製化一個基於LRU策略的快取Map,來保證記憶體資料量不會無限制增長。
public class FixedLengthLinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private static final long serialVersionUID = 1287190405215174569L;
private int maxEntries;
public FixedLengthLinkedHashMap(int maxEntries, boolean accessOrder) {
super(16, 0.75f, accessOrder);
this.maxEntries = maxEntries;
}
/**
* 自定義資料淘汰觸發條件,在每次put操作的時候會呼叫此方法來判斷下
*/
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxEntries;
}
}
浮點資料計算
看一段很簡單的程式碼:
public static void main(String[] args) {
System.out.println(0.1 + 0.2);
}
上面的執行後,輸出結果應該是多少?很明顯應該是0.3呀!然而實際上,執行之後,輸出結果為:
0.30000000000000004
這是因為浮點數是不精確的,因為浮點數是存在小數點位的,而十進位制的0.1換算為二進位制是一個無限迴圈小數,所以實際上儲存的其實是一個近似0.1的值、而不是精確的0.1。
也正是這個原因,一般實現中,判斷兩個float是否相等時,往往不用==,而是判斷兩個浮點數之差絕對值是否小於一個很小的數。
對於一些需要精確計算的場景,顯然是不能使用浮點數來運算的,比如一些銀行金融領域涉及金錢數額相關的場景,是絕對不允許使用float或者double進行運算,而是推薦使用BigDecimal來替代。
使用Object作為HashMap的key
大家都知道在JAVA中,HashMap的key是不可以重複的,相同的key對應值會進行覆蓋。但是,如果使用自定義物件作為HashMap的key,就要小心了,因為如果操作不當,很容易造成記憶體漏失的問題。
如果一定要使用,確保此Object一定是覆寫了hashCode()和equals()方法,並且保證覆寫的equals和hashCode方法中一定不能有頻繁易變更的欄位參與計算。
結語
好啦,關於JAVA中常見的十大陷阱,這裡就給大家分享到這裡。希望大家在實際編碼的時候可以注意提防,避免踩坑。
我是悟道,聊技術、又不僅僅聊技術~
如果覺得有用,請點個關注,也可以關注下我的公眾號【架構悟道】,獲取更及時的更新。
期待與你一起探討,一起成長為更好的自己。

本文來自部落格園,作者:架構悟道,歡迎關注公眾號[架構悟道]持續獲取更多幹貨,轉載請註明原文連結:https://www.cnblogs.com/softwarearch/p/16427413.html