簡述機器學習中的特徵工程
何為特徵工程?
特徵工程是利用資料領域的相關知識來建立能夠使機器學習演演算法達到最佳效能的特徵的過程,用一系列工程化的方式從原始資料中篩選出更好的資料特徵,以提升模型的訓練效果。業內有一句廣為流傳的話是:資料和特徵決定了機器學習的上限,而模型和演演算法是在逼近這個上限而已。由此可見,好的資料和特徵是模型和演演算法發揮更大的作用的前提。特徵工程通常包括資料預處理、特徵選擇、降維等環節。
特徵工程的重要性
- 特徵越好,靈活性越強
- 特徵越好,構建的模型越簡單
- 特徵越好,模型的效能越出色
一、資料預處理
資料預處理是特徵工程中最為重要的一個環節,良好的資料預處理可以使模型的訓練達到事半功倍的效果。資料預處理旨在通過資料淨化、歸一化、標準化、正則化等方式改進不完整、不一致、無法直接使用的資料。具體方法有:
-
去除唯一屬性
唯一屬性通常是一些id屬性,這些屬性並不能刻畫樣本自身的分佈規律,所以簡單地刪除這些屬性即可。
-
處理缺失值
1. 刪除資料:根據缺失情況,按行刪除或者按列刪除
2.度量填補缺失值:可以根據資料屬性,採用均值、中位數、眾數等中心度量值來填補缺失資料(字串型別資料一般採用眾數處理方式)
3.預測填補缺失值:可以將缺失屬性作為因變數,建立分類或迴歸模型,對缺失值進行建模填補
-
歸一化
歸一化是對資料集進行區間縮放,縮放到[0,1]的區間內,把有單位的資料轉化為沒有單位的資料,即統一資料的衡量標準,消除單位的影響。這樣方便了資料的處理,使資料處理更加快速、
敏捷。Skearn中最常用的歸一化的方法是:MinMaxScaler。此外還有對數函數轉換(log),反餘切轉換等。
-
標準化
標準化是在不改變原資料分佈的前提下,將資料按比例縮放,使之落入一個限定的區間,使資料之間具有可比性。但當個體特徵太過或明顯不遵從高斯正態分佈時,標準化表現的效果會比較差。標準化的目的是為了方便資料的下一步處理,比如:進行的資料縮放等變換。常用的標準化方法有z-score標準化、StandardScaler標準化等。
-
離散化
離散化是把連續型的數值型特徵分段,每一段內的資料都可以當做成一個新的特徵。具體又可分為等步長方式離散化和等頻率的方式離散化,等步長的方式比較簡單,等頻率的方式更加精準,會跟資料分佈有很大的關係。 程式碼層面,可以用pandas中的cut方法進行切分。總之,離散化的特徵能夠提高模型的執行速度以及準確率。
-
二值化
特徵的二值化處理是將數值型資料輸出為布林型別。其核心在於設定一個閾值,當樣本書籍大於該閾值時,輸出為1,小於等於該閾值時輸出為0。我們通常使用preproccessing庫的Binarizer類對資料進行二值化處理。
-
啞編碼
我們針對類別型的特徵,通常採用啞編碼(One_Hot Encodin)的方式。所謂的啞編碼,直觀的講就是用N個維度來對N個類別進行編碼,並且對於每個類別,只有一個維度有效,記作數位1 ;其它維度均記作數位0。但有時使用啞編碼的方式,可能會造成維度的災難,所以通常我們在做啞編碼之前,會先對特徵進行Hash處理,把每個維度的特徵編碼成詞向量。
以上介紹了幾種較為常見、通用的資料預處理方式,但只是浩大特徵工程中的冰山一角。往往很多特徵工程的方法需要我們在專案中不斷去總結積累比如:針對缺失值的處理,在不同的資料集中,用均值填充、中位數填充、前後值填充的效果是不一樣的;對於類別型的變數,有時我們不需要對全部的資料都進行啞編碼處理;對於時間型的變數有時我們有時會把它當作是離散值,有時會當成連續值處理等。所以很多情況下,我們要根據實際問題,進行不同的資料預處理。
二、特徵選擇
不同的特徵對模型的影響程度不同,我們要自動地選擇出對問題重要的一些特徵,移除與問題相關性不是很大的特徵,這個過程就叫做特徵選擇。特徵的選擇在特徵工程中十分重要,往往可以直接決定最後模型訓練效果的好壞。常用的特徵選擇方法有:過濾式(filter)、包裹式(wrapper)、嵌入式(embedding)等。
1 . 過濾方法(Filter approaches)
過濾方法,也被稱為分類器獨立的方法。它獨立於任何歸納演演算法,基於距離、資訊、依賴性和一致性四種不同的評價標準進行評價,利用資料的內在特徵對特徵進行評價和排序,根據訓練資料的共同特徵來選擇合適的特徵,而不涉及任何特定的學習器。
基於濾波器的方法可以分為單變數方法和多變數方法。在單變數中,特徵的重要性是單獨計算的,而忽略了特徵之間的關係,而在多變數中,將考慮特徵的相互作用和依賴關係。其優點是速度快、計算簡單、經濟,更適合於解決高維資料集問題。
最流行的為特徵相關性進行評分的標準之一是皮爾遜相關係數,計算公式為:
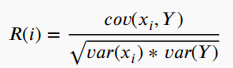
其中,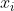 為第i個特徵,
為第i個特徵,