C++ 練氣期之一文看懂字串
C++ 練氣期之細聊字串
1. 概念
程式不僅僅用於數位計算,現代企業級專案中更多流轉著充滿了煙火氣的人間話語。這些話語,在計算機語言稱為字串。
從字面上理解字串,類似於用一根竹籤串起了很多字元,讓人很容易想起冰糖葫蘆。
字串的基本組成元素是字元,可以認為字串就是字元型別的陣列。
量變總會引起質變,字串是由字元的量變演化出的新型別, 2 者在資料含義和儲存結構都有著本質上區別。
1.1 資料含義
C++把字元型別當成整型資料型別看待。如下程式碼,當把A賦值給myChar時, 編譯器先獲取A的底層 ASCII 編碼,然後再把編碼值賦值給myChar。
int myChar='A';
cout<<myChar;
//輸出:65
如下程式碼,編譯器先找到97對應的字元,然後再賦值給myChar,字元型別和整型型別語法層面有差異,在底層,C++一視同仁。
char myChar=97;
cout<<myChar;
//輸出:a
所以,用於整型資料型別的運運算元都可以用於char型別。
char myChar='B';
char myChar_='A';
int res=myChar+myChar_;
cout<<"加操作:"<<res<<endl;
res=myChar-myChar_;
cout<<"減操作:"<<res<<endl;
res=myChar*myChar_;
cout<<"乘操作:"<<res<<endl;
res=myChar/myChar_;
cout<<"除操作:"<<res<<endl;
bool is=myChar>myChar_;
cout<<"關係操作:"<<is<<endl;
輸出結果:
加操作:131
減操作:1
乘操作:4290
除操作:1
關係操作:1
雖然,字串可看成是字元組成的陣列,但是,應該把字串當成一個獨立的整體,其資料含義更貼近現實意義:
- 因
字元是單一詞,所能表達的語意非常有限。 字串則是由許多字元組成的語句,可用來表達豐富的語意。如:可以是姓名、可以是問候、可以情感表達、可以是提示……根據使用的上下文環境,字串有其自己特定的現實意義。
1.2 儲存結構
字元常數必須用單引號包起來,字元直接儲存在變數中。
char myChar='A';
字串的儲存方案比字元複雜很多,C++支援兩種字串的儲存方案:
C語言風格的儲存。C++語言的物件儲存。
下面深入瞭解這 2 種儲存方案的區別。
2. C 風格的字串
C++可以直接延用C語言中的2種字串儲存方案:
2.1 陣列
陣列儲存能較好地詮釋字串是由字元所組成的概念。
使用陣列儲存時,並不能簡單如下程式碼所示。對於開發者而言,可能想表達的是輸出一句HTLLO問候語。但在實際執行時,輸出時可能不僅只是HELLO。
char myStr[5]= {'H','E','L','L','O'};
cout<<myStr<<endl;
為什麼會輸出更多資訊?
因為cout底層邏輯在輸出字元陣列時,會以一個特定識別符號\0作為結束標誌。cout在輸出 myStr字元陣列的資料時,如果沒有遇到開發者提供的\0結束符號,則會在陣列的儲存範圍之外尋找\0符號。
上述程式碼雖然能得到HELLO,那是因為在未使用的儲存空間中,\0符號很常見。
顯然,不能總是去碰運氣。所以,在使用字元陣列時描述字串時,則需要在適當位置新增字串結束識別符號\0。
因結束符佔用了一個儲存位,HELLO需要5個儲存位,在宣告陣列時,需要注意陣列的實際長度為 6。
char myStr[6]= {'H','E','L','L','O','\0'};
cout<<myStr<<endl;
//輸出結果:HELLO
執行下面的程式碼,檢視輸出結果,想想為什麼輸出結果是HEL?
char myStr[6]= {'H','E','L','\0','O','\0'};
cout<<myStr<<endl;
//輸出結果:HEL
原因很簡單,cout在遇到第一個 \0時,就認定字串到此結束了。
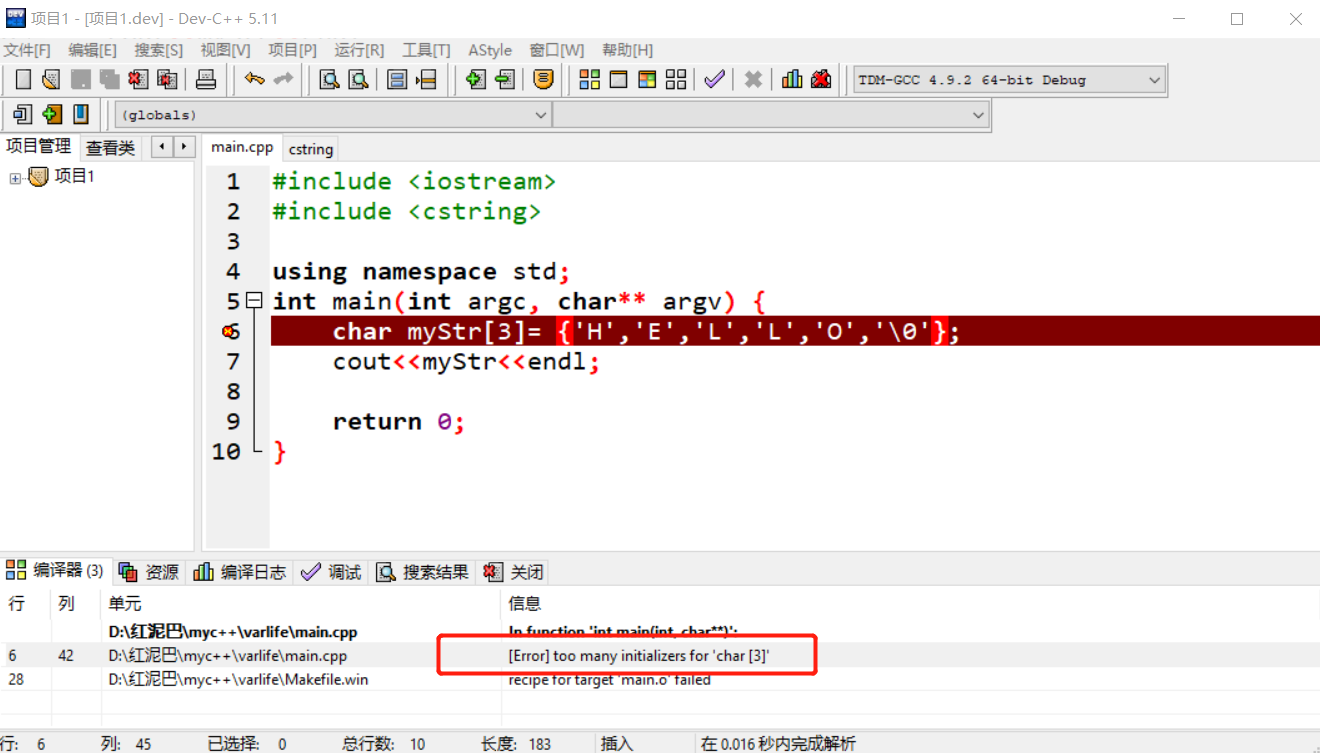
這裡有一個問題,如果實際的字元個數大於陣列宣告的長度,會出現什麼情況?
char myStr[3]= {'H','E','L','L','O','\0'};
cout<<myStr<<endl;
如果出現上述程式碼,說明,你的陣列沒有學太好。C++規定在使用{}進行字面值初始化陣列時,{}內的實際資料個數不能大於陣列宣告的長度。
當不確定字串的長度時,可以採用省略[]中數位的方案。
char myStr[]= {'H','E','L','L','O','\0'};
cout<<myStr<<endl;
陣列儲存方案同樣具有陣列所描述的操作能力,最典型的就是使用下標遍歷陣列。
char myStr[6]= {'H','E','L','L','O','\0'};
for(int i=0;i<6;i++){
cout<<myStr[i]<<endl;
}
輸出結果:
H
E
L
L
O
在使用上述程式碼時,有 2 個地方需要注意:
- 當下標定位到
\0資料位時,並不能識別\0是字串結束符,它只是純粹當成一個一個字元輸出,不具有字串語意。
char myStr[8]= {'H','E','L','L','O','\0','M','Y'};
for(int i=0;i<8;i++){
cout<<myStr[i]<<endl;
}
輸出結果:
H
E
L
L
O
M
Y
- 因是靜態陣列宣告方案,可以動態計算陣列的長度。
char myStr[8]= {'H','E','L','L','O','\0','M','Y'};
cout<<"陣列的長度:"<<sizeof(myStr)<<endl;
for(int i=0;i<sizeof(myStr);i++){
cout<<myStr[i]<<endl;
}
輸出結果:
陣列的長度:8
H
E
L
L
O
M
Y
使用
sizeof(myStr)計算出來的是建立陣列時指定的物理儲存長度。
所以,這裡要注意:
- 通過
結束符描述字串是編譯器層面上的約定。 - 遍歷時,實質是底層指標移動,這時,編譯層面的字串概念在這裡不復存在。也就是說不存在遇到
\0,就認為輸出結束。
2.2 字串常數
上述字串的描述方式,略顯繁瑣,因需要時時注意新增\0。C當然也會想到這一點,可以使用字串常數簡化字串陣列的建立過程。
char myStr[8]="HELLO";
cout<<myStr<<endl;
//輸出結果:HELLO
字串常數需要使用雙引號括起來。
當執行如下程式碼時,會出現錯誤。
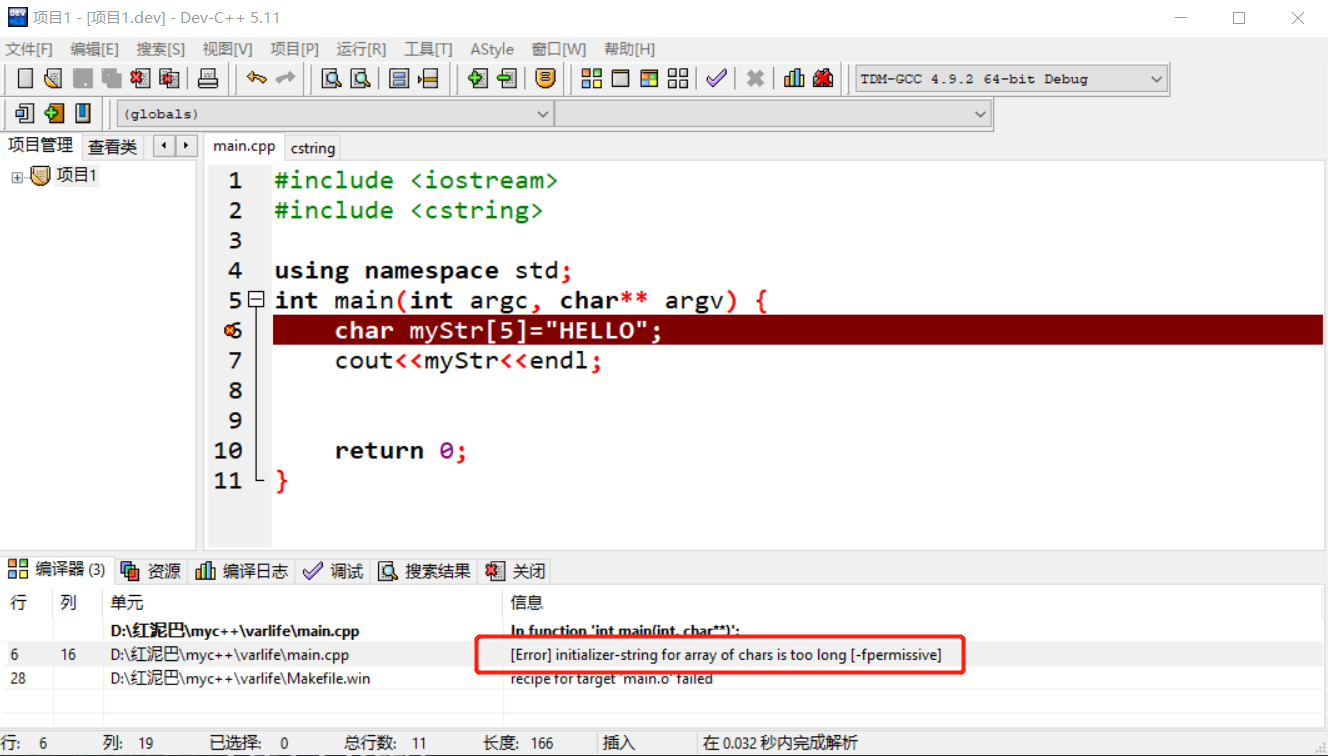
錯誤提示,陣列長度不夠儲存給定的資料。可能要問!
陣列長度是5,實際資料HELLO的長度也是5,不是剛剛好嗎。
別忘記了,完整的字串是包括結束符\0的。在使用字元常數賦值時,編譯器會在字串常數的尾部新增\0,再儲存到陣列中,所以陣列的長度至少是:字串常數的長度+1。
如下的程式碼方能正確編譯執行:
char myStr[6]="HELLO";
cout<<myStr<<endl;
//輸出:HELLO
字串常數只是上述{}賦值的語法簡法版,其它的操作都是相同的,如迴圈遍歷。
char myStr[6]="HELLO";
for(int i=0;i<sizeof(myStr);i++){
cout<<myStr[i]<<endl;
}
注意,如下的程式碼是錯誤的。
char myStr[6]="HELLO";
myStr[0]="S";
"S"表示一個字串,至少包括了'S'和'\0' 2 個字元,更重要的是 "S"返回的是記憶體地址。
2.3 字串操作
C語言風格的字串提供了cstring庫,此庫提供大量函數用來操作字串,常見函數如下:
strcat:字串拼接。strcpy:字串複製。strcmp:字串比較。strstr:字串查詢。- ……
下面介紹幾個字串的常見操作。
2.3.1 複製操作
C++中陣列之間是不能直接賦值的,如下是錯誤的:
char myStr[6]="HELLO";
char myStr_[6];
//錯誤
myStr_=myStr;
可以使用cstring庫中的 strcpy 函數:
#include <iostream>
#include <cstring>
using namespace std;
int main(int argc, char** argv) {
char myStr[6]="HELLO";
char myStr_[6];
strcpy(myStr_,myStr);
cout<<myStr_<<endl;
return 0;
}
strcpy需要 2 個引數:
- 目標字串指標。
- 源字串指標。
其作用是,把源字串複製給目標字串。
2.3.2 長度操作
使用 strlen函數計算字串的長度。
char myStr[10]="HELLO";
cout<<strlen(myStr)<<endl;
//輸出結果:5
和sizeof計算出來的長度區別:
sizeof建立陣列時,分配到的實際物理空/間的長度。
char myStr[10]="HEL\0LO";
cout<<sizeof(myStr)<<endl;
cout<<strlen(myStr)<<endl;
輸出結果:
10
3
strlen計算出的是字元陣列中字串的實際長度,即遇到\0結束符前所有字元的長度。如下程式碼:
char myStr[10]="HEL\0LO";
cout<<strlen(myStr)<<endl;
輸出結果是:3。\0結束前的字串是HEL。
2.3.3 拼接操作
字串常數之間可以使用空白(空格、換行符、製表符)字元自動完成拼接。
cout<<"this is a test" "hello world";
//輸出:this is a testhello world
需要注意的地方是,第一個字串常數和第二個字串常數的拼接處直接連線,中間不保留空白符。
使用strcat進行拼接。
#include <iostream>
#include <cstring>
using namespace std;
int main(int argc, char** argv) {
char names[10]="Hello";
char address[10]="changsha";
strcat(names,address);
cout<<names;
return 0;
}
//輸出:Hellochangsha
strcat是把第二字串連線到第一個字串後尾部。
2.3.4 字串比較
字元能夠直接比較,字串則不能。如果相互之間有比較的需求時,可以使用 strcmp 函數。
#include <iostream>
#include <cstring>
using namespace std;
int main(int argc, char** argv) {
char names[10]="zs";
char names_[10]="ls";
cout<<strcmp(names,names_);
return 0;
}
//輸出結果:1
返回值的語意:
- 如果返回值為小於
0,則names小於address。 - 如果返回值為 等於
0,則names等於address。 - 如果返回值大於
0,則names大於address。
2.3.5 子字串查詢
在原子符串中查詢給定的子字串出現的位置,返回此位置的指標地址。
#include <iostream>
#include <cstring>
using namespace std;
int main(int argc, char** argv) {
char srcStr[15]="Hello World";
char subStr[5]="llo";
cout<<strstr(srcStr,subStr);
return 0;
}
//輸出:llo World
如果沒有查詢到,則返回null。
cstring庫提供了大量處理字串的函數,如大小寫轉換函數tolower和toupper等。本文僅介紹幾個常用函數,需要時,可查閱檔案,其使用並不是很複雜。
3. C++字串物件
C++除了支援C風格的字串,因其物件導向程式設計的特性,內建有string類,可以使用此類建立字串物件。
string類定義在string標頭檔案中。
如下程式碼可以初始化字串物件:
//空字串
string str1;
//字串常數直接賦值
string str2="Hello";
string str3 {"this"};
string str4("Hi");
string為了支援uncode字元編碼,底層為每一個字元提供了1~4個位元組的儲存空間。
所以,可以用來儲存中文:
string str="中國人";
cout<<str<<endl;
//輸出:中國人
除了支援
char、還支援wchar_t、char16_t、char32_t資料型別。
在string類中封裝了很多處理字串的相關函數(方法),在cstring庫中可以找到對應的函數。因得益於類設計的優秀特性,string類中封裝的功能體相比較cstring庫,更豐富、更全面。
下面介紹幾個常用的功能,其它可以查閱檔案。
獲取字串的常規資訊:如長度、是否為空……
string str="Hello World";
cout<<str.size()<<endl;
cout<<str.length()<<endl;
//是否為空
cout<<str.empty()<<endl;
//能儲存的最大長度
cout<<str.max_size()<<endl;
//容量
cout<<str.capacity()<<endl;
輸出結果:
11
11
0
4611686018427387897
11
資料維護(增、刪除、改、查)方法:
clear:清除所有內容。
string str="Hello World";
str.clear();
cout<<str<<endl;
//沒有任何內容輸出
insert:插入字元。
string str="Hello World";
string str_="Hi";
//第一個引數指定插入位置,第二引數指定需要插入的字串
str.insert(3,str_);
cout<<str<<endl;
//輸出結果:HelHilo World
erase:刪除指定範圍內的所有字元。
string str="Hello World";
//第一個引數:指定刪除的起始位置,第二個引數:指定刪除的結束位置
string str_= str.erase(1,3);
cout<<str_<<endl;
//輸出:Ho World
push_back、append追加字元和字串。
string str="Hello World";
//只能追加字串,不能追加字元
str.append("OK");
cout<<str<<endl;
//只能以字元為單位追加
str.push_back('O');
cout<<str<<endl;
//輸出結果:
//Hello WorldOK
//Hello WorldOKO
pop_back:刪除最後一個字元。
string str="Hello World";
str.pop_back();
cout<<str<<endl;
//輸出結果:Hello Worl
compare:比較兩個字串。
string str="Hello World";
string str_="Hello";
int res= str.compare(str_);
//返回值的語意和 `strcmp`一樣。
copy:字串的拷貝。
//源字串
string foo("quuuux");
//目標字串,陣列形式
char bar[7];
//第一個引數,目標字串,第二引數,向目標字串複製多少
foo.copy(bar, sizeof bar);
bar[6] = '\0';
cout << bar << '\n';
//輸出:quuuux
總結下來,字串的儲存方案有2 種:
- 陣列形式。
- 字串物件。
4. cin 輸入字串
如果需要使用互動輸入方式獲取使用者輸入的資料,可以直接使用 cin。
string str;
char bar[7];
cin>>str;
cin>>bar;
cout<<str<<endl;
cout<<bar<<endl;
如上程式碼,如果使用者輸入this is,因字串有空白字元。則會出現獲取到錯誤資料的問題。
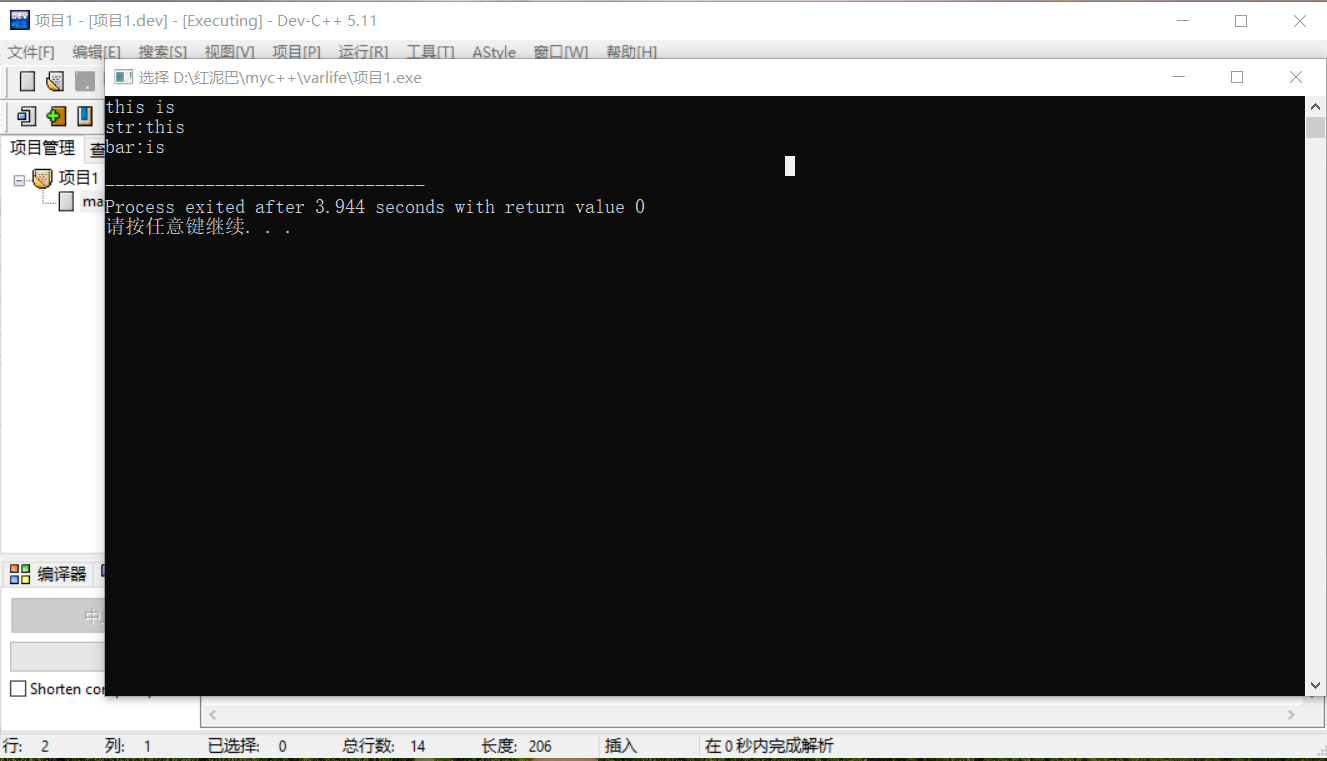
原因解析:
cin接受使用者輸入時,以使用者輸入的換行符作為結束標識。使用者輸入this is時,遇到字串的中間空白字元(空格、製表符、換行符)時,就認定輸入結束,僅把this儲存到str中,並不是this is。
cin內建有快取器,會把 is快取起來,也就是說 cin是以單詞為單位進行輸入的。
當再次使用cin接受使用者輸入時,cin會檢查到快取器中已經有資料,會直接把is賦值給 bar變數。
如果需要以行為單位進行輸入時,可以使用:
cin.get()方法。cin.getline()方法。
上述
2個方法主要用於字串陣列的賦值。
兩者在使用時,都可以接受 2 個引數:
- 目標字串。
- 用來限制輸入的大小。
char str[20];
cin.get(str,10);
cout<<str<<endl;
//輸入: this is 輸出:this is
如下程式碼,能實現相同的效果。
char str[20];
cin.getline(str,10);
cout<<str<<endl;
兩者也有區別,cin.get()不會丟棄使用者輸入字串時的結束符。在連續使用 cin.get有可能出現問題,如下程式碼:
char str[20];
char str_[20];
//第一次輸入
cin.get(str,10);
cout<<str<<endl;
//第二次輸入
cin.get(str_,10);
cout<<str_<<endl;
執行效果:
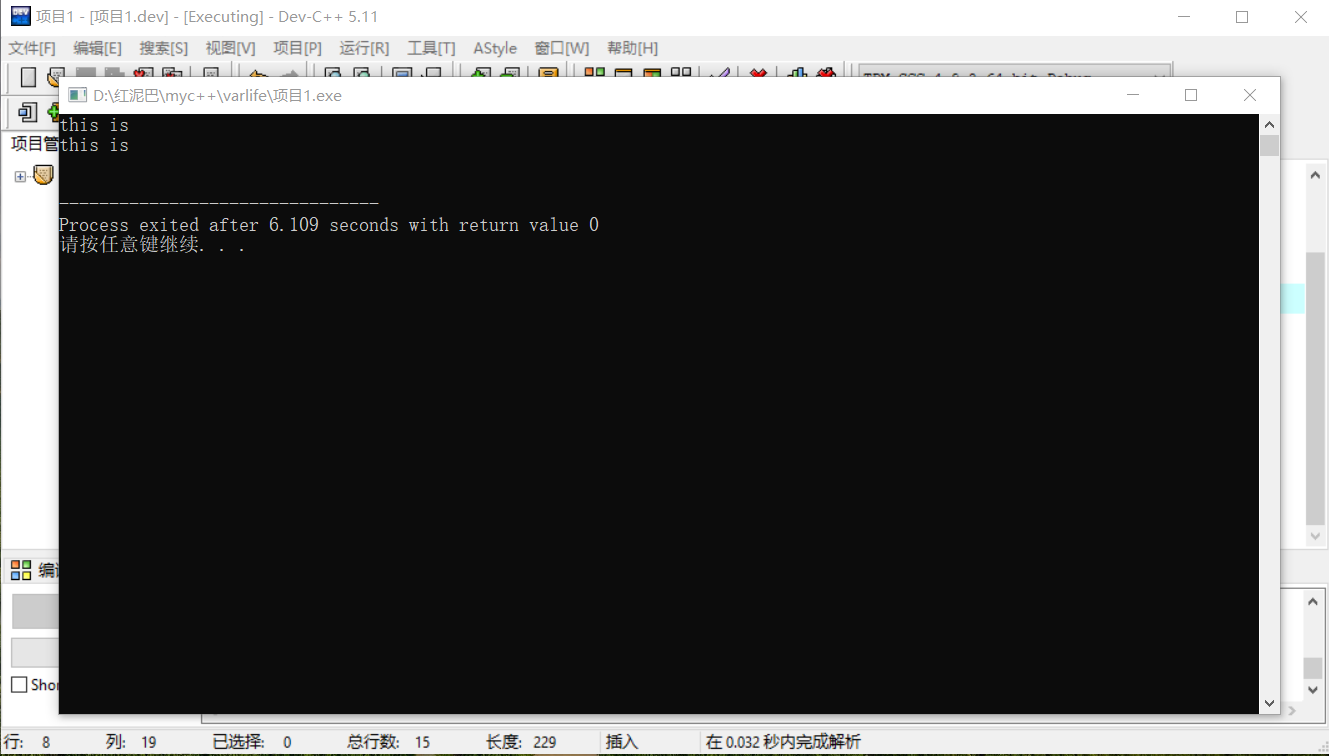
第二次接受使用者輸入的過程根本沒出現。
原因是第一次接受使用者輸入後,cin.get快取了使用者輸入的換行符。在第二次接受使用者輸入時,cin會首先檢查快取器中是否有資料,發現有換行符,直接結束輸入。
解決方案,手動清除快取器的資料。
char str[20];
char str_[20];
cin.get(str,10);
cout<<str<<endl;
//不帶引數的 get 方法可以清除資料
cin.get();
cin.get(str_,10);
cout<<str_<<endl;
cin.getline在接受使用者輸入後,不會保留換行符,所以可以用於連續輸入。如下程式碼:
char str[20];
char str_[20];
//第一次輸入
cin.getline(str,10);
cout<<"str:"<<str<<endl;
//第二次輸入
cin.getline(str_,10);
cout<<"str_:"<<str_<<endl;
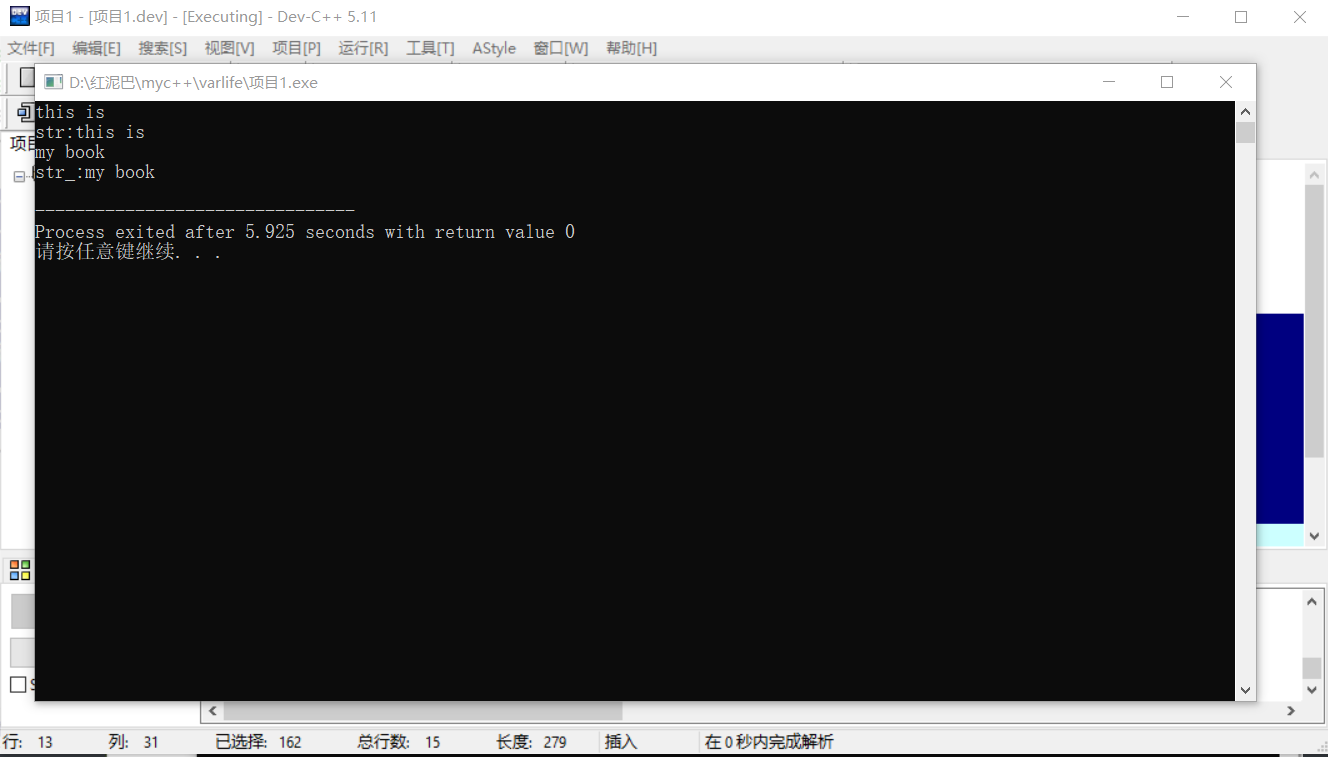
如果要使用cin輸入一行字串,並賦值給字串物件,則需要使用全域性 getline函數。
//字串物件
string str;
//第一個引數:cin物件 第二個引數:字串物件
getline(cin,str);
cout<<str<<endl;
5. 總結
本文主要講解了C++字串的2種儲存方案,一個是C語言風格的陣列儲存方案,一個是C++物件儲存方案。
因儲存方案不同,其操作函數的提供方式也不相同。