MySQL學習之一條SQL是如何執行的?聊聊執行流程
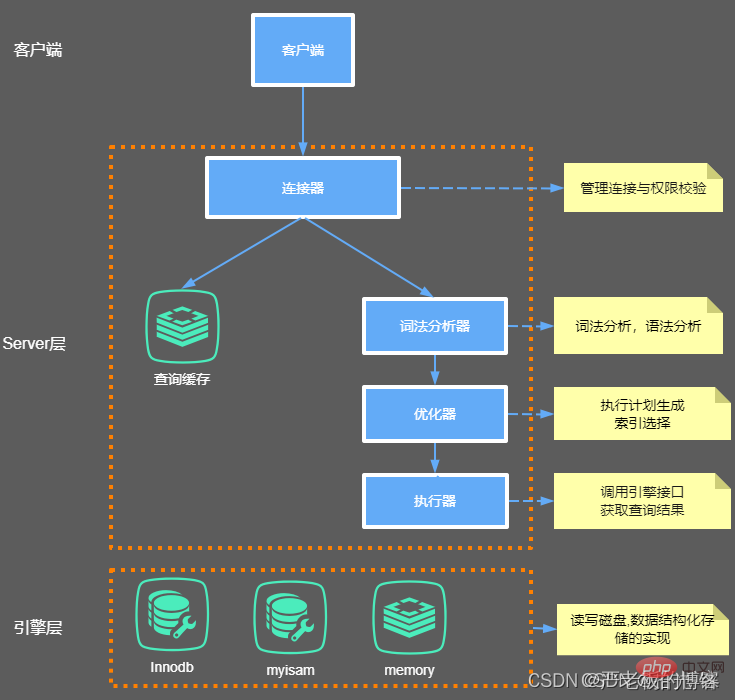
大體來說,MySQL 可以分為 Server 層和儲存引擎層兩部分。
Server層
主要包括聯結器、查詢快取、分析器、優化器、執行器等,涵蓋 MySQL 的大多數核心服務功能,以及所有的內建函數 (如日期、時間、數學和加密函數等),所有跨儲存引擎的功能都在這一層實現,比如儲存過程、觸發器、檢視等。
Store層
儲存引擎層負責資料的儲存和提取。其架構模式是外掛式的,支援 InnoDB、MyISAM、Memory 等多個儲存引擎。現在 最常用的儲存引擎是 InnoDB,它從 MySQL 5.5.5 版本開始成為了預設儲存引擎。也就是說如果我們在create table時不指定 表的儲存引擎型別,預設會給你設定儲存引擎為InnoDB。
本節課演示表的DDL:
CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
下面我們重點來分析聯結器、查詢快取、分析器、優化器、執行器分別主要乾了哪些事情。
1、聯結器
我們知道由於MySQL是開源的,他有非常多種類的使用者端:navicat,mysql front,jdbc,SQLyog等非常豐富的使用者端,這些 使用者端要向mysql發起通訊都必須先跟Server端建立通訊連線,而建立連線的工作就是有聯結器完成的。
第一步,你會先連線到這個資料庫上,這時候接待你的就是聯結器。聯結器負責跟使用者端建立連線、獲取許可權、維持和管 理連線。連線命令一般是這麼寫的:
[root@192 ~]# mysql ‐h host[資料庫地址] ‐u root[使用者] ‐p root[密碼] ‐P 3306
連線命令中的 mysql 是使用者端工具,用來跟伺服器端建立連線。在完成經典的 TCP 握手後,聯結器就要開始認證你的身份, 這個時候用的就是你輸入的使用者名稱和密碼。
1、如果使用者名稱或密碼不對,你就會收到一個"Access denied for user"的錯誤,然後使用者端程式結束執行。
2、如果使用者名稱密碼認證通過,聯結器會到許可權表裡面查出你擁有的許可權。之後,這個連線裡面的許可權判斷邏輯,都將依賴於此時讀到的許可權。
這就意味著,一個使用者成功建立連線後,即使你用管理員賬號對這個使用者的許可權做了修改,也不會影響已經存在連線的權 限。修改完成後,只有再新建的連線才會使用新的許可權設定。使用者的許可權表在系統表空間的mysql的user表中。

修改user密碼
mysql> CREATE USER 'username'@'host' IDENTIFIED BY 'password'; //建立新使用者 mysql> grant all privileges on *.* to 'username'@'%'; //賦許可權,%表示所有(host) mysql> flush privileges //重新整理資料庫 mysql> update user set password=password(」123456″) where user=’root’;(設定使用者名稱密碼) mysql> show grants for root@"%"; 檢視當前使用者的許可權
連線完成後,如果你沒有後續的動作,這個連線就處於空閒狀態,你可以在 show processlist 命令中看到它。文字中這個 圖是 show processlist 的結果,其中的 Command 列顯示為「Sleep」的這一行,就表示現在系統裡面有一個空閒連線。

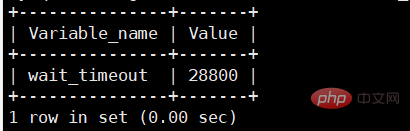
使用者端如果長時間不傳送command到Server端,聯結器就會自動將它斷開。這個時間是由引數 wait_timeout 控制的,預設值 是 8 小時。 檢視wait_timeout
mysql> show global variables like "wait_timeout"; mysql>set global wait_timeout=28800; 設定全域性伺服器關閉非互動連線之前等待活動的秒數
如果在連線被斷開之後,使用者端再次傳送請求的話,就會收到一個錯誤提醒: Lost connection to MySQL server during query。這時候如果你要繼續,就需要重連,然後再執行請求了。
資料庫裡面,長連線是指連線成功後,如果使用者端持續有請求,則一直使用同一個連線。短連線則是指每次執行完很少的幾次 查詢就斷開連線,下次查詢再重新建立一個。 開發當中我們大多數時候用的都是長連線,把連線放在Pool內進行管理,但是長連線有些時候會導致 MySQL 佔用記憶體漲得特別 快,這是因為 MySQL 在執行過程中臨時使用的記憶體是管理在連線物件裡面的。這些資源會在連線斷開的時候才釋放。所以如 果長連線累積下來,可能導致記憶體佔用太大,被系統強行殺掉(OOM),從現象看就是 MySQL 異常重新啟動了。 怎麼解決這類問題呢?
1、定期斷開長連線。使用一段時間,或者程式裡面判斷執行過一個佔用記憶體的大查詢後,斷開連線,之後要查詢再重連。
2、如果你用的是 MySQL 5.7 或更新版本,可以在每次執行一個比較大的操作後,通過執行 mysql_reset_connection 來重新初始化連線資 源。這個過程不需要重連和重新做許可權驗證,但是會將連線恢復到剛剛建立完時的狀態。
2、查詢快取
常用的一些操作
mysql>show databases; 顯示所有資料庫 mysql>use dbname; 開啟資料庫: mysql>show tables; 顯示資料庫mysql中所有的表; mysql>describe user; 顯示錶mysql資料庫中user表的列資訊);
連線建立完成後,你就可以執行 select 語句了。執行邏輯就會來到第二步:查詢快取。 MySQL 拿到一個查詢請求後,會先到查詢快取看看,之前是不是執行過這條語句。之前執行過的語句及其結果可能會以 key-value 對的形式,被直接快取在記憶體中。key 是查詢的語句,value 是查詢的結果。如果你的查詢能夠直接在這個快取中找 到 key,那麼這個 value 就會被直接返回給使用者端。
如果語句不在查詢快取中,就會繼續後面的執行階段。執行完成後,執行結果會被存入查詢快取中。你可以看到,如果查 詢命中快取,MySQL 不需要執行後面的複雜操作,就可以直接返回結果,這個效率會很高。
大多數情況查詢快取就是個雞肋,為什麼呢?
因為查詢快取往往弊大於利。查詢快取的失效非常頻繁,只要有對一個表的更新,這個表上所有的查詢快取都會被清空。 因此很可能你費勁地把結果存起來,還沒使用呢,就被一個更新全清空了。對於更新壓力大的資料庫來說,查詢快取的命中率 會非常低。
一般建議大家在靜態表裡使用查詢快取,什麼叫靜態表呢?就是一般我們極少更新的表。比如,一個系統設定表、字典 表,那這張表上的查詢才適合使用查詢快取。好在 MySQL 也提供了這種「按需使用」的方式。你可以將my.cnf引數 query_cache_type 設定成 DEMAND。
my.cnf #query_cache_type有3個值 0代表關閉查詢快取OFF,1代表開啟ON,2(DEMAND)代表當sql語句中有SQL_CACHE 關鍵詞時才快取 query_cache_type=2
這樣對於預設的 SQL 語句都不使用查詢快取。而對於你確定要使用查詢快取的語句,可以用 SQL_CACHE 顯式指定,像下 面這個語句一樣:
mysql> select SQL_CACHE * from test where ID=5;
檢視當前mysql範例是否開啟快取機制
mysql> show global variables like "%query_cache_type%";
監控查詢快取的命中率:
mysql> show status like'%Qcache%'; //檢視執行的快取資訊
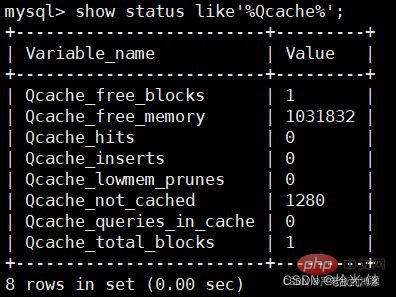
- Qcache_free_blocks:表示查詢快取中目前還有多少剩餘的blocks,如果該值顯示較大,則說明查詢快取中的記憶體碎片過多了,可能在一定的時間進行整理。
- Qcache_free_memory:查詢快取的記憶體大小,通過這個引數可以很清晰的知道當前系統的查詢記憶體是否夠用,是多了,還是不夠用,DBA可以根據實際情況做出調整。
- Qcache_hits:表示有多少次命中快取。我們主要可以通過該值來驗證我們的查詢快取的效果。數位越大,快取效果越 理想。
- Qcache_inserts: 表示多少次未命中然後插入,意思是新來的SQL請求在快取中未找到,不得不執行查詢處理,執行查詢處理後把結果insert到查詢快取中。這樣的情況的次數,次數越多,表示查詢快取應用到的比較少,效果也就不理想。當然系統剛啟動後,查詢快取是空的,這很正常。
- Qcache_lowmem_prunes:該引數記錄有多少條查詢因為記憶體不足而被移除出查詢快取。通過這個值,使用者可以適當的 調整快取大小。
- Qcache_not_cached: 表示因為query_cache_type的設定而沒有被快取的查詢數量。
- Qcache_queries_in_cache:當前快取中快取的查詢數量。
- Qcache_total_blocks:當前快取的block數量。
mysql8.0已經移除了查詢快取功能
3、分析器
如果沒有命中查詢快取,就要開始真正執行語句了。首先,MySQL 需要知道你要做什麼,因此需要對 SQL 語句做解析。 分析器先會做「詞法分析」。你輸入的是由多個字串和空格組成的一條 SQL 語句,MySQL 需要識別出裡面的字串分別是 什麼,代表什麼。 MySQL 從你輸入的"select"這個關鍵字識別出來,這是一個查詢語句。它也要把字串「T」識別成「表名 T」,把字元 串「ID」識別成「列 ID」。 做完了這些識別以後,就要做「語法分析」。根據詞法分析的結果,語法分析器會根據語法規則,判斷你輸入的這個 SQL 語句 是否滿足 MySQL 語法。 如果你的語句不對,就會收到「You have an error in your SQL syntax」的錯誤提醒,比如下面這個語句 from 寫成了 「fro」。
mysql> select * fro test where id=1; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds t o your MySQL server version for the right syntax to use near 'fro test where id=1' at line 1
詞法分析器原理
詞法分析器分成6個主要步驟完成對sql語句的分析
1、詞法分析 2、語法分析 3、語意分析 4、構造執行樹 5、生成執行計劃 6、計劃的執行
下圖是SQL詞法分析的過程步驟: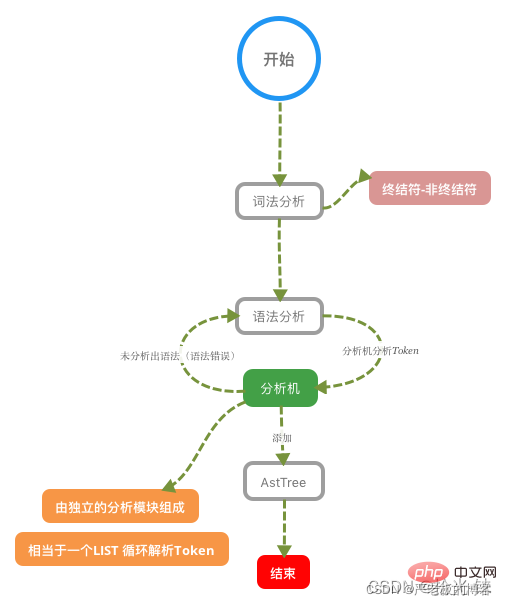
SQL語句的分析分為詞法分析與語法分析,mysql的詞法分析由MySQLLex[MySQL自己實現的]完成,語法分析由Bison生 成。關於語法樹大家如果想要深入研究可以參考這篇wiki文章:https://en.wikipedia.org/wiki/LR_parser。那麼除了Bison 外,Java當中也有開源的詞法結構分析工具例如Antlr4,ANTLR從語法生成一個解析器,可以構建和遍歷解析樹,可以在IDEA 工具當中安裝外掛:antlr v4 grammar plugin。外掛使用詳見課程 經過bison語法分析之後,會生成一個這樣的語法樹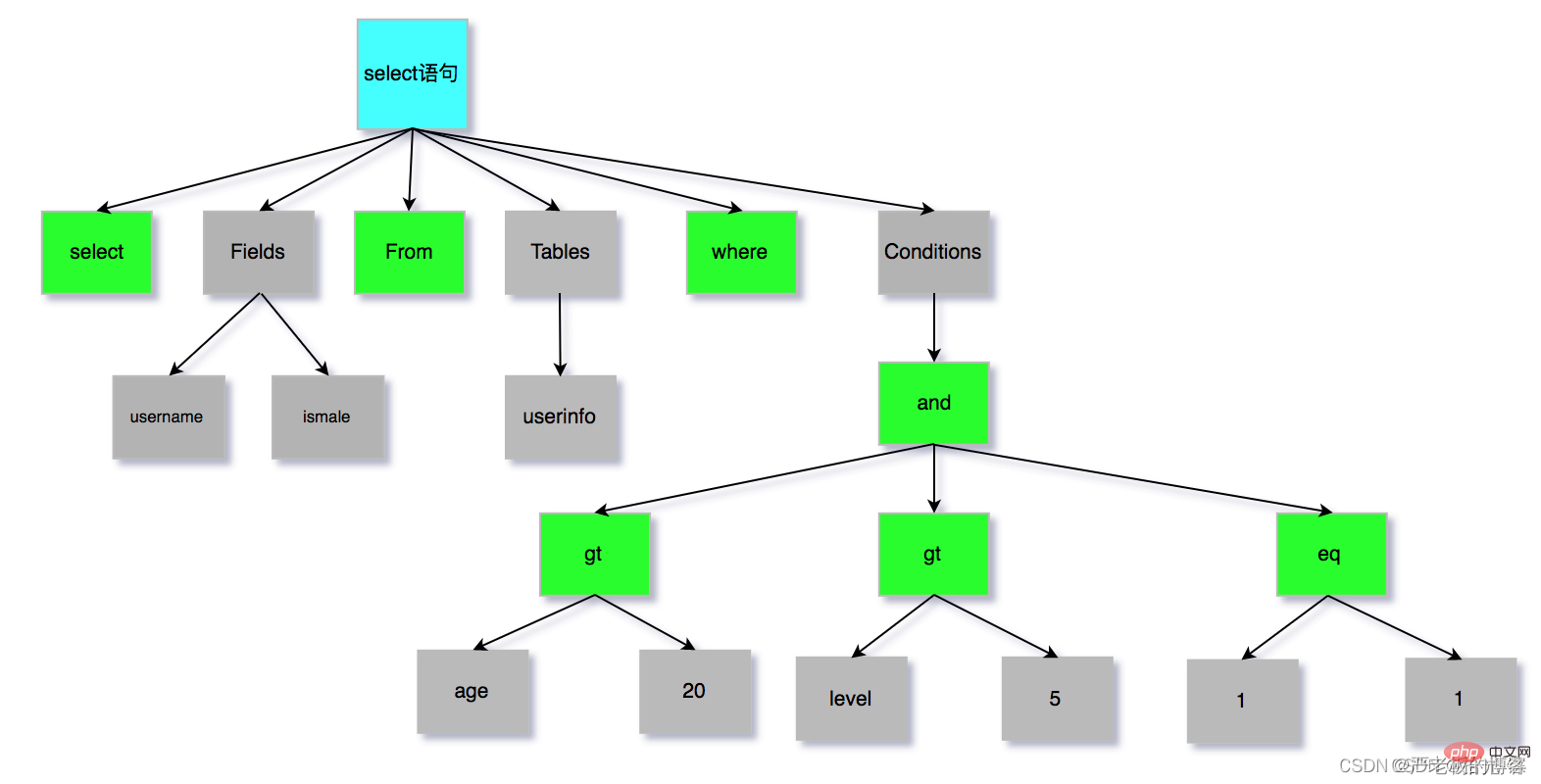
我們分析器的工作任務也基本圓滿了。接下來進入到優化器
4、優化器
經過了分析器,MySQL 就知道你要做什麼了。在開始執行之前,還要先經過優化器的處理。 優化器是在表裡面有多個索引的時候,決定使用哪個索引;或者在一個語句有多表關聯(join)的時候,決定各個表的連線 順序。比如你執行下面這樣的語句,這個語句是執行兩個表的 join:
mysql> select * from test1 join test2 using(ID) where test1.name=yangguo and test2.name=xiaol ongnv;
既可以先從表 test1 裡面取出 name=yangguo的記錄的 ID 值,再根據 ID 值關聯到表 test2,再判斷 test2 裡面 name的 值是否等於 yangguo。
也可以先從表 test2 裡面取出 name=xiaolongnv 的記錄的 ID 值,再根據 ID 值關聯到 test1,再判斷 test1 裡面 name 的值是否等於 yangguo。
這兩種執行方法的邏輯結果是一樣的,但是執行的效率會有不同,而優化器的作用就是決定選擇使用哪一個方案。優化器階段 完成後,這個語句的執行方案就確定下來了,然後進入執行器階段。如果你還有一些疑問,比如優化器是怎麼選擇索引的,有 沒有可能選擇錯等等。
5、執行器
開始執行的時候,要先判斷一下你對這個表 T 有沒有執行查詢的許可權,如果沒有,就會返回沒有許可權的錯誤,如下所示 (在工程實現上,如果命中查詢快取,會在查詢快取返回結果的時候,做許可權驗證。查詢也會在優化器之前呼叫 precheck 驗證許可權)。
mysql> select * from test where id=1;
如果有許可權,就開啟表繼續執行。開啟表的時候,執行器就會根據表的引擎定義,去使用這個引擎提供的介面。 比如我們這個例子中的表 test 中,ID 欄位沒有索引,那麼執行器的執行流程是這樣的:
呼叫 InnoDB 引擎介面取這個表的第一行,判斷 ID 值是不是 10,如果不是則跳過,如果是則將這行存在結果集中;
呼叫引擎介面取「下一行」,重複相同的判斷邏輯,直到取到這個表的最後一行。
執行器將上述遍歷過程中所有滿足條件的行組成的記錄集作為結果集返回給使用者端。
至此,這個語句就執行完成了。對於有索引的表,執行的邏輯也差不多。第一次呼叫的是「取滿足條件的第一行」這個介面,之後迴圈取「滿足條件的下一行」這個介面,這些介面都是引擎中已經定義好的。你會在資料庫的慢查詢紀錄檔中看到一個 rows_examined 的欄位,表示這個語句執行過程中掃描了多少行。這個值就是在執行器每次呼叫引擎獲取資料行的時候累加的。在有些場景下,執行器呼叫一次,在引擎內部則掃描了多行,因此引擎掃描行數跟 rows_examined 並不是完全相同的。
6、bin-log歸檔
刪庫是不需要跑路的,因為我們的SQL執行時,會將sql語句的執行邏輯記錄在我們的bin-log當中,什麼是bin-log呢? binlog是Server層實現的二進位制紀錄檔,他會記錄我們的cud操作。Binlog有以下幾個特點:
1、Binlog在MySQL的Server層實現(引擎共用) 2、Binlog為邏輯紀錄檔,記錄的是一條語句的原始邏輯 3、Binlog不限大小,追加寫入,不會覆蓋以前的紀錄檔
如果,我們誤刪了資料庫,可以使用binlog進行歸檔!要使用binlog歸檔,首先我們得記錄binlog,因此需要先開啟MySQL的 binlog功能。 設定my.cnf
設定開啟binlog
log‐bin=/usr/local/mysql/data/binlog/mysql‐bin
注意5.7以及更高版本需要設定本項:server‐id=123454(自定義,保證唯一性);
#binlog格式,有3種statement(記錄產生結果的過程的sql語句),row(記錄產生的結果),mixed binlog‐format=ROW #表示每1次執行寫入就與硬碟同步,會影響效能,為0時表示,事務提交時mysql不做刷盤操作,由系統決定 sync‐binlog=1
binlog命令
mysql> show variables like '%log_bin%'; 檢視bin‐log是否開啟 mysql> flush logs; 會多一個最新的bin‐log紀錄檔 mysql> show master status; 檢視最後一個bin‐log紀錄檔的相關資訊 mysql> reset master; 清空所有的bin‐log紀錄檔
檢視binlog內容
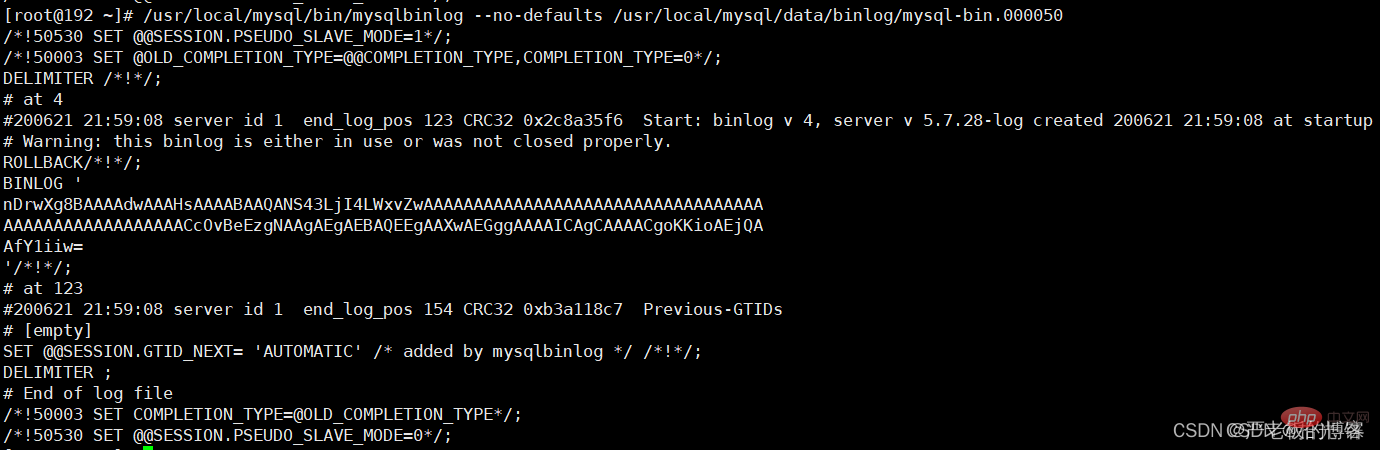
mysql> /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin. 000001 檢視binlog內容
binlog裡的內容不具備可讀性,所以需要我們自己去判斷恢復的邏輯點位,怎麼觀察呢?看重點資訊,比如begin,commit這種 關鍵詞資訊,只要在binlog當中看到了,你就可以理解為begin-commit之間的資訊是一個完整的事務邏輯,然後再根據位置 position判斷恢復即可。
binlog內容如下:
資料歸檔操作:
從bin‐log恢復資料 恢復全部資料 /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin.000001 |mysql ‐uroot ‐p tuling(資料庫名) 恢復指定位置資料 /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults ‐‐start‐position="408" ‐‐stop‐position="731" /usr/local/mysql/data/binlog/mysql‐bin.000001 |mysql ‐uroot ‐p tuling(資料庫) 恢復指定時間段資料 /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin.000001 ‐‐stop‐date= "2018‐03‐02 12:00:00" ‐‐start‐date= "2019‐03‐02 11:55:00"|mysql ‐uroot ‐p test(資料庫)
歸檔測試準
1、定義一個儲存過程,寫入資料
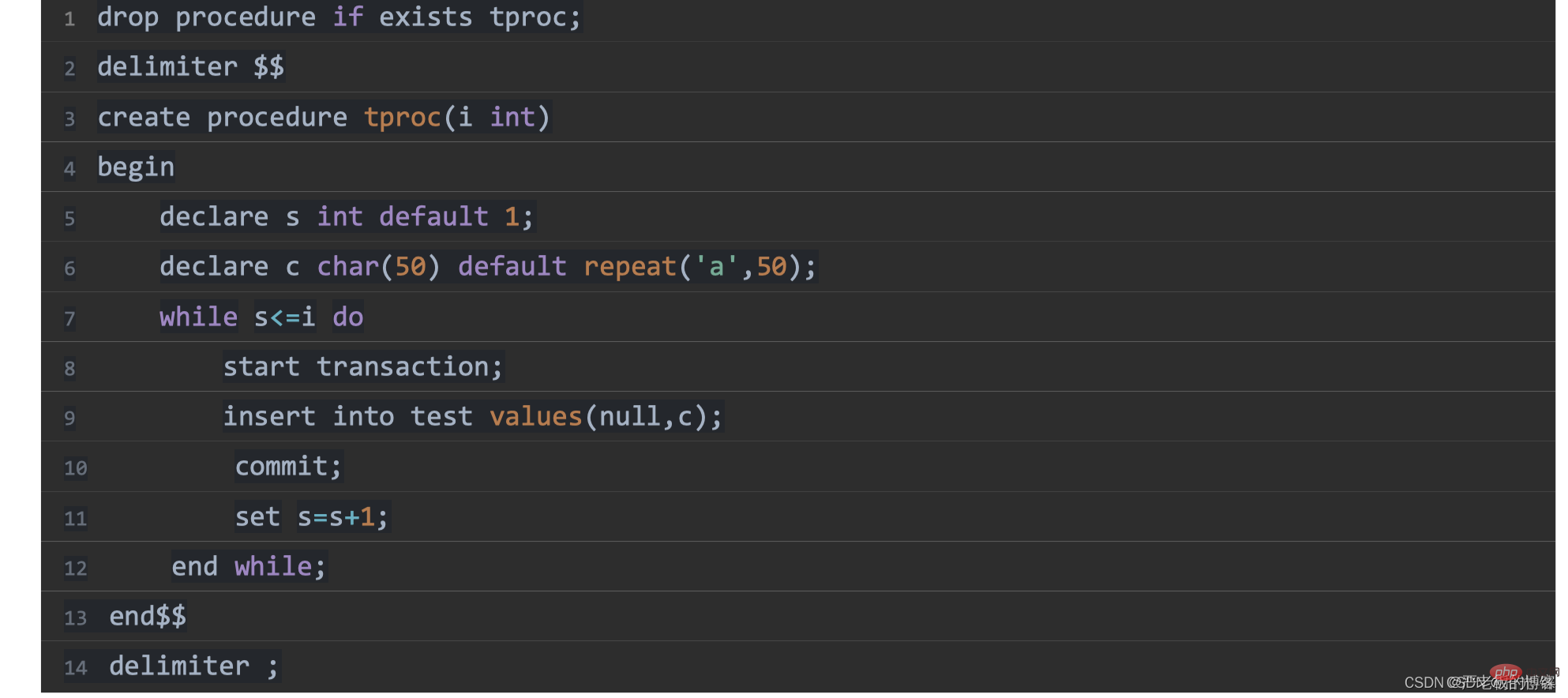
2、刪除資料
mysql> truncate test;
3、利用binlog歸檔
mysql> /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysqlbin.000001 |mysql ‐uroot ‐p tuling(資料庫名)
4、歸檔完畢,資料恢復
【相關推薦:】
以上就是MySQL學習之一條SQL是如何執行的?聊聊執行流程的詳細內容,更多請關注TW511.COM其它相關文章!