訓練一個影象分類器demo in PyTorch【學習筆記】
【學習源】Tutorials > Deep Learning with PyTorch: A 60 Minute Blitz > Training a Classifier
本文相當於對上面連結教學中自認為有用部分進行的擷取、翻譯和再註釋。便於日後複習、修正和補充。
邊寫邊查資料的過程中猛然發現這居然有中文檔案……不過中文檔案也是志願者翻譯的,僅僅是翻譯,也沒有對知識點的擴充,不耽誤我寫筆記。這篇筆記就繼續寫下去吧。附PyTorch 中文教學 & 檔案 > 訓練分類器
一、準備資料集
一般來說,當你不得不與影象、文字或者視訊資料打交道時,會選擇使用python的標準庫將原始資料載入轉化成numpy陣列,甚至可以繼續轉換成torch.*Tensor。
- 對圖片而言,可以使用Pillow庫和OpenCV庫
- 對視訊而言,可以使用scipy庫和librosa庫
- 對文字而言,可以使用基於原生Python或Cython載入,或NLTK和SpaCy等。
Pytorch特別針對視覺方面建立torchvision庫,其中包含能夠載入ImageNet、CIFAR10和MNIST等資料集的資料載入功能,對影象的資料增強功能,即 torchvision.datasets 和 torch.utils.data.DataLoader 。
這為大家搭建資料集提供了極大的便利,避免了需要自己寫樣板程式碼的情況。
本次我們使用CIFAR10資料集。這是一個含有「飛機」、「汽車」、「鳥」、「貓」、「鹿」、「狗」、「青蛙」、「馬」、「輪船」和「卡車」等10個分類的資料集。資料集中每張影象均為[C×H×W]=[3×32×32]即3通道的高32畫素寬32畫素的彩色影象。

二、訓練影象分類器
下面的步驟大概可以分成5個有序部分:
- 用 torchvision 載入(loading)並歸一化(normalize)CIFAR10訓練資料集和測試資料集
- 定義折積神經網路(CNN)
- 定義損失函數和優化器
- 訓練網路
- 測試網路
P.S. 以下給出的程式碼均為在CPU上執行的程式碼。但本人在pycharm中執行的為自己修改過的在GPU上訓練的程式碼,範例結果和截圖也都是GPU執行的結果。
2.1 載入並歸一化CIFAR10資料集
用torchvision載入CIFAR10
import torch
import torchvision
import torchvision.transforms as transforms
torchvision載入的資料集是PILImage,資料範圍[0,1]。我們需要使用transform函數將其歸一化(normalize)為[-1,1]。
細心的夥伴發現了我將英文的normalize翻譯成了「歸一化」而不是標準化,這是因為接下來的程式碼你會看到預處理階段transformer變數儲存的處理操作僅僅是運用了normalize的計算規則將資料範圍進行了縮放,並沒有改變資料的分佈,因此翻譯成「歸一化」更合理。
NOTE.(抄的原文,以防有小夥伴真的遇到這個意外問題)
If running on Windows and you get a BrokenPipeError,
try setting the num_worker of torch.utils.data.DataLoader() to 0。
--snip--
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 4
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
transform中的ToTensor和Normalize函數究竟在做什麼,以及為什麼要歸一化等問題感興趣的小夥伴可以閱讀附錄中的序號1~3文章,其中
- 博主「小研一枚」[1]通過原始碼為我們講解函數的計算行為定義等知識點
- 答主"Transformer"[2]通過知乎專欄為我們做了幾組程式碼範例。而我們則要看清文章、留言區爭論的核心與我們真正求索的問題之間的區別和聯絡,避免被爭論本身誤導
- 答主「JMD」[3]則為我們科普歸一化的相關知識
書歸正題,上述程式碼第一次執行的結果可能是這樣子的:
此時,我們可以使用numpy庫和matplotlib庫檢視資料集中的圖片和標籤。
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join(f'{classes[labels[j]]:5s}' for j in range(batch_size)))
但是如果你就這樣將程式碼copy+paste在pycharm中直接接續在載入資料的程式碼下面點選「執行」,有可能得到的是一個RuntimeError,並建議你按照慣例設定if __name__ == '__main__':
所以,我建議將目前為止的程式碼優化成下面的樣子:
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader # 如果torch.utils.data.DataLoader()有報錯提示「在 '__init__.py' 中找不到參照 'data'則增加此語句或者其他語句 」
import matplotlib.pyplot as plt
import numpy as np
# ①←後續如果繼續匯入packages,請直接在這裡插入程式碼
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 4
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def imshow(img):
"""顯示影象的函數"""
img = img / 2 + 0.5 # 去歸一化
npimg = img.numpy()
# 上面transform.ToTensor()操作後資料程式設計CHW[通道靠前模式],需要轉換成HWC[通道靠後模式]才能plt.imshow()
plt.imshow(np.transpose(npimg, (1, 2, 0))) # 轉置前將排在第0位的Channel(C)放在最後,所以是(1,2,0)
plt.show()
# ②←後續再有定義class、function等在此插入程式碼編寫
if __name__ == '__main__':
# 隨機輸出
dataiter_tr = iter(trainloader) # 取一個batch的訓練集資料
# images_tr, labels_tr = dataiter_tr.next() 根據你的python選擇迭代器呼叫語句
images_tr, labels_tr = next(dataiter_tr) # 切分資料和標籤
imshow(torchvision.utils.make_grid(images_tr)) # 生成網格圖
print(' '.join(f'{classes[labels_tr[j]]:5s}' for j in range(batch_size))) # 列印標籤值
# print(' '.join('%5s' % classes[labels_tr[j]] for j in range(batch_size))) 如果你使用python3.6之前的版本,那麼有可能無法使用f字串語句,只能使用.format()方法
# ③←後續的程式執行語句在此插入
輸出影象範例:

標籤輸出:bird cat deer ship
2.2 定義一個折積神經網路
可以將之前寫過的識別手寫數位MNIST的神經網路遷移到這裡來。
# 在①後插入import程式碼
import torch.nn as nn
import torch.nn.functional as F
# 在②後插入神經網路定義程式碼
class Net(nn.Module):
"""定義一個折積神經網路及前饋函數"""
def __init__(self):
"""初始化網路:定義折積層、池化層和全連結層"""
super().__init__() # 繼承父類別屬性。P.S. 如果看到super(Net, self).__init__()寫法亦可
self.conv1 = nn.Conv2d(3, 6, 5) # 使用2套折積核。輸入(B×3×32×32),輸出(B×6×28×28)
self.pool = nn.MaxPool2d(2, 2) # 最大池化操作,輸出時高、寬減半,(B×6×14×14) (B×16×5×5)
self.conv2 = nn.Conv2d(6, 16, 5) # 使用4套折積核,折積核大小為5×5。(B×16×10×10)
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全連結層。將資料扁平化成一維,共400個輸入,120個輸出
self.fc2 = nn.Linear(120, 84) # 全連結層。120個輸入,84個輸出
self.fc3 = nn.Linear(84, 10) # 全連結層。84個輸入,10個輸出用於分類
def forward(self, x):
"""前饋函數,規定資料正向傳播的規則"""
x = self.pool(F.relu(self.conv1(x))) # 輸入 > conv1折積 > ReLu啟用 > maxpool最大池化
x = self.pool(F.relu(self.conv2(x))) # > conv2折積 > ReLu啟用 > maxpool最大池化
# x = torch.flatten(x, 1) # 如果你不喜歡下一種寫法實現扁平化,可以使用這條語句代替
x = x.view(-1, 16 * 5 * 5) # 相當於numpy的reshape。此處是將輸入資料變換成不固定行數,因此第一個引數是-1,完成扁平化
x = F.relu(self.fc1(x)) # 扁平化資料 > fc1全連結層 > ReLu啟用
x = F.relu(self.fc2(x)) # > fc2全連結層 > ReLu啟用
x = self.fc3(x) # > fc3全連結層 > 輸出
return x
# 在③後插入神經網路範例化程式碼
net = Net() # 範例化神經網路
2.3 定義損失函數和優化器
我們使用多分類交叉熵損失函數(Classification Cross-Entropy loss)[4]和隨機梯度下降法(SGD)的動量改進版(momentum)[5][6]
# 在①後插入import程式碼
import torch.optim as optim
# 在③後插入程式碼
criterion = nn.CrossEntropyLoss() # 交叉熵損失函數
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
這裡必須做一個擴充套件。
在2.2中我們可以看到神經網路中,每個層的輸出都經過了啟用函數的啟用作用。但是在輸出層後卻缺少了啟用函數而貌似「直接作用了損失函數」。
簡單地說,原因就在於torch.nn.CrossEntropyLoss()將nn.LogSoftmax()啟用函數和nn.NLLLoss()負對數似然損失函數整合在一起。
logsoftmax是argmax => softargmax => softmax => logsoftmax逐步優化的求極大值的index的期望的方法。
負對數似然損失函數(Negtive Log Likehood)就是計算最小化真實分佈\(P(y|x)\)與模型輸出分佈\(P(\hat{y}|x)\)的距離,等價於最小化兩者的交叉熵。實際使用函數時,是one-hot編碼後的標籤與logsoftmax結果相乘再求均值再取反,這個過程博主「不願透漏姓名的王建森」在他的部落格中做過實驗[7]講解。
上述結論的詳盡說明請參考知乎上Cassie的創作《吃透torch.nn.CrossEntropyLoss()》[8]、知乎上Gordon Lee的創作《交叉熵和極大似然估計的再理解》 [9]。
P.S. 對於torch.nn.CrossEntropyLoss()的官網Doc中提到的"This is particularly useful when you have an unbalanced training set."關於如何處理不均衡樣品的幾個解決辦法,可以參考Quora上的問答《In classification, how do you handle an unbalanced training set?》[10]以及熱心網友對此問答的翻譯[11]
2.4 訓練神經網路
事情變得有趣起來了!我們只需要遍歷我們的迭代器,將其輸入進神經網路和優化器即可。
如果想在GPU上訓練請參考文章開頭給出的【學習源】連結中的末尾部分有教授如何修改程式碼的部分。
--snip--
# 在③後插入程式碼
for epoch in range(5): # 資料被遍歷的次數
running_loss = 0.0 # 每次遍歷前重新初始化loss值
for i, data in enumerate(trainloader, 0):
inputs, labels = data # 切分資料集
optimizer.zero_grad() # 梯度清零,避免上一個batch迭代的影響
# 前向傳遞 + 反向傳遞 + 權重優化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 輸出紀錄檔
running_loss += loss.item() # Tensor.item()方法是將tensor的值轉化成python number
if i % 2000 == 1999: # 每2000個mini batches輸出一次
# print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000)) 如果python3.6之前版本可以使用這個程式碼
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
print('Finished Training')
Out:
model will be trained on device: 'cuda:0'
某一次輸出結果紀錄檔整理一下如下表:
| mini batch → epoch ↓ |
loss | |||||
|---|---|---|---|---|---|---|
| 2000 | 4000 | 6000 | 8000 | 10000 | 12000 | |
| 1 | 2.219 | 1.978 | 1.754 | 1.600 | 1.517 | 1.469 |
| 2 | 1.405 | 1.363 | 1.356 | 1.323 | 1.293 | 1.280 |
| 3 | 1.234 | 1.228 | 1.204 | 1.186 | 1.179 | 1.183 |
| 4 | 1.111 | 1.095 | 1.135 | 1.119 | 1.119 | 1.105 |
| 5 | 0.995 | 1.043 | 1.048 | 1.060 | 1.064 | 1.042 |
Finished Training
將loss資料整理並畫圖(選做):
--snip--
x = np.linspace(2000, 12000, 6, dtype=np.int32)
# 資料每次訓練輸出都不一樣,給出畫圖程式碼,至於資料,大家寄幾填吧~
epoch_01 = np.array([...])
epoch_02 = np.array([...])
epoch_03 = np.array([...])
epoch_04 = np.array([...])
epoch_05 = np.array([...])
plt.plot(x, epoch_01, 'ro-.', x, epoch_02, 'bo-.', x, epoch_03, 'yo-.', x, epoch_04, 'ko-.', x, epoch_05, 'go-.')
plt.legend(['Epoch_1', 'Epoch_2', 'Epoch_3', 'Epoch_4', 'Epoch_5'])
plt.xlabel('number of mini-batches')
plt.ylabel('loss')
plt.title('Loss during CIFAR-10 training procedure in Convolution Neural Networks')
plt.show()
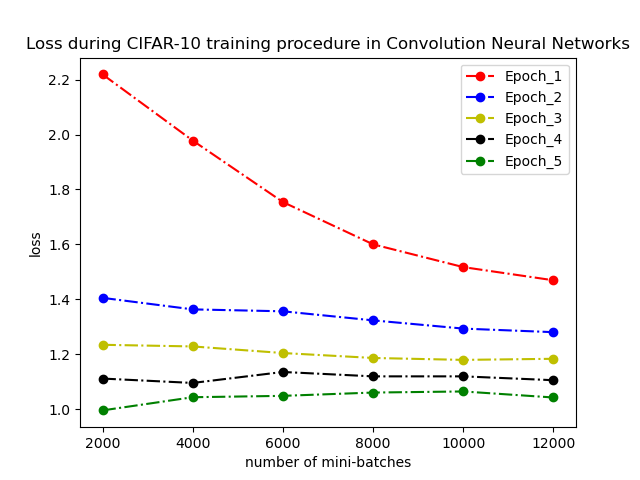
通過資料我們可以看出loss的下降趨勢:
- 第一個epoch的最明顯
- 第二個epoch繼續降低,但趨勢更平緩
- 後三個epoch在開始較前一個epoch有較明顯下降,但下降幅度遞減
- *後三個epoch在該epoch內下降趨勢平緩,或出現小幅震盪並保持低於前一個epoch
現在我們可以快速儲存訓練完成的模型到指定的路徑。
--snip--
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
儲存的檔案
2.5 測試神經網路
我們已經用訓練集資料將神經網路訓練了5次(epoches=5)。但我們還需要核實神經網路是否真的學到了什麼。
我們將以神經網路預測的類別標籤和真實標籤進行對比核實。如果預測正確,則將樣本新增到正確預測列表中。
首先我們像檢視訓練集的一個mini batch影象一樣,看一下一部分測試集影象。
--snip--
dataiter_te = iter(testloader)
images_te, labels_te = next(dataiter_te) # 另一種備用寫法參考訓練集部分
imshow(torchvision.utils.make_grid(images_te))
print('GroundTruth: ', ' '.join('%5s' % classes[labels_te[j]] for j in range(batch_size))) # 另一種備用寫法參考訓練集部分

Out:
GroundTruth: cat ship ship plane
下面,我們載入之前儲存的模型(注:儲存和再載入模型不是必要步驟,這裡這麼做是為了演示這些操作):
--snip--
net = Net()
net.load_state_dict(torch.load(PATH))
OK,現在讓我們看看神經網路如何看待這些影象的分類的:
--snip--
outputs = net(images) # 看一下神經網路對上述展示圖片的預測結果
輸出的是10個分類的「能量(energy)」。某個分類的能量越高,意味著神經網路認為該影象越符合該分類。因此我們可以獲得那個能量的索引。
--snip--
_, predicted = torch.max(outputs, 1) # torch.max(input, dim)返回按照dim方向的最大值和其索引
print('Predicted: ', ' '.join(f'{classes[predicted[j]]:5s}' for j in range(batch_size)))
Out:
Predicted: cat ship ship ship
看起來不錯。下面就試一試在全部測試集上的表現:
correct = 0
total = 0
# 由於這不是在訓練模型,因此對輸出不需要計算梯度等反向傳播過程
with torch.no_grad():
for data in testloader:
images_pre, labels_pre = data
outputs = net(images_pre) # 資料傳入神經網路,計算輸出
_, predicted = torch.max(outputs.data, 1) # 獲取最大能量的索引
total += labels_pre.size(0) # 計算預測次數
correct += (predicted == labels_pre).sum().item() # 計算正確預測次數
print(f'Accuracy of the network on the 10000 test images: {100 * correct // total} %')
Out:
Accuracy of the network on the 10000 test images: 61 %

感覺預測的準確率比隨機從10個類中蒙一個類(概率10%)要高,看來神經網路確實學到了一些東西。
當然,我們還可以看一下對於不同的類的學習效果:
--snip--
# 生成兩個dict,分別用來存放預測正確數量和總數量的個數
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
# 啟動預測過程,無需計算梯度等
with torch.no_grad():
for data in testloader:
images_cl, labels_cl = data
outputs = net(images_cl)
_, predictions = torch.max(outputs, 1)
# 開始計數
for label, prediction in zip(labels_cl, predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
# 分類別列印預測準確率
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f'Accuracy for class: {classname:5s} is {accuracy:.1f} %')
Out:
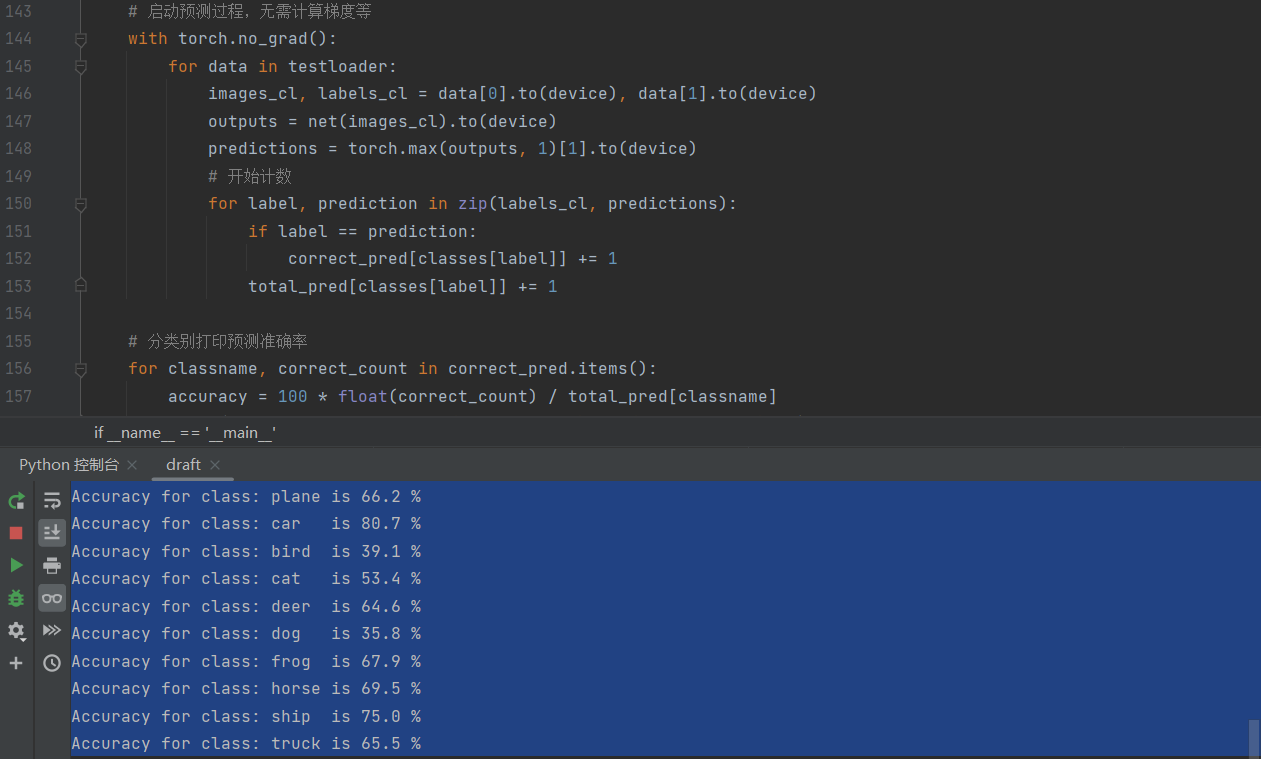
Accuracy for class: plane is 66.2 %
Accuracy for class: car is 80.7 %
Accuracy for class: bird is 39.1 %
Accuracy for class: cat is 53.4 %
Accuracy for class: deer is 64.6 %
Accuracy for class: dog is 35.8 %
Accuracy for class: frog is 67.9 %
Accuracy for class: horse is 69.5 %
Accuracy for class: ship is 75.0 %
Accuracy for class: truck is 65.5 %
至此,我們完成了練習!
在結束前,讓我們反思一下準確率為何會呈現上述樣子,我推測:
- 資料集本身缺陷,如圖片太小(32×32)不足以讓折積神經網路提取到足夠特徵,類別劃分不合理(汽車&卡車,以及飛機&鳥等較其他類別而言是否太過相似),各類別影象數量和影象本身質量等
- 資料的預處理不足,預處理階段對資料的增強不夠,是否可以加入旋轉/映象/透視、裁剪、亮度調節、噪聲/平滑等處理
- 神經網路本身的結構、引數設定等是否合理,如折積/全連結層數的規定、折積核相關的定義、損失函數的選擇、batch size/epoch的平衡等(希望可以通過學習後續的Alexnet、VGG、Resnet、FastRCNN、YOLO等受到啟發)
- 避免偶然。不能以單次的結果去評價,評價應當建立在若干次重複試驗的基礎上
三、總結
通過本次練習,我們做到了:
- 熟悉了編寫神經網路的結構、前饋/反饋等必要功能,編寫並實現了訓練、測試過程等
- 對官網和中文檔案做了適當擴充和一些細微調整
- 查閱學習了涉及歸一化、隨機梯度下降法極其改進演演算法、交叉熵和極大似然在多分類中的應用等
- 對訓練過程和結果做出了小結.
最後,希望各位給出建議與批評~ 共同交流學習~