go-zero微服務實戰系列(八、如何處理每秒上萬次的下單請求)
在前幾篇的文章中,我們花了很大的篇幅介紹如何利用快取優化系統的讀效能,究其原因在於我們的產品大多是一個讀多寫少的場景,尤其是在產品的初期,可能多數的使用者只是過來檢視商品,真正下單的使用者非常少。但隨著業務的發展,我們就會遇到一些高並行寫請求的場景,秒殺搶購就是最典型的高並行寫場景。在秒殺搶購開始後用戶就會瘋狂的重新整理頁面讓自己儘早的看到商品,所以秒殺場景同時也是高並行讀場景。那麼應對高並行讀寫場景我們怎麼進行優化呢?
處理熱點資料
秒殺的資料通常都是熱點資料,處理熱點資料一般有幾種思路:一是優化,二是限制,三是隔離。
優化
優化熱點資料最有效的辦法就是快取熱點資料,我們可以把熱點資料快取到記憶體快取中。
限制
限制更多的是一種保護機制,當秒殺開始後用戶就會不斷地重新整理頁面獲取資料,這時候我們可以限制單使用者的請求次數,比如一秒鐘只能請求一次,超過限制直接返回錯誤,返回的錯誤儘量對使用者友好,比如 "店小二正在忙" 等友好提示。
隔離
秒殺系統設計的第一個原則就是將這種熱點資料隔離出來,不要讓1%的請求影響到另外的99%,隔離出來後也更方便對這1%的請求做針對性的優化。具體到實現上,我們需要做服務隔離,即秒殺功能獨立為一個服務,通知要做資料隔離,秒殺所呼叫的大部分是熱點資料,我們需要使用單獨的Redis叢集和單獨的Mysql,目的也是不想讓1%的資料有機會影響99%的資料。
流量削峰
針對秒殺場景,它的特點是在秒殺開始那一剎那瞬間湧入大量的請求,這就會導致一個特別高的流量峰值。但最終能夠搶到商品的人數是固定的,也就是不管是100人還是10000000人發起請求的結果都是一樣的,並行度越高,無效的請求也就越多。但是從業務角度來說,秒殺活動是希望有更多的人來參與的,也就是秒殺開始的時候希望有更多的人來重新整理頁面,但是真正開始下單時,請求並不是越多越好。因此我們可以設計一些規則,讓並行請求更多的延緩,甚至可以過濾掉一些無效的請求。
削峰本質上是要更多的延緩使用者請求的發出,以便減少和過濾掉一些無效的請求,它遵從請求數要儘量少的原則。我們最容易想到的解決方案是用訊息佇列來緩衝瞬時的流量,把同步的直接呼叫轉換成非同步的間接推播,中間通過一個佇列在一端承接瞬時的流量洪峰,在另一端平滑的將訊息推播出去,如下圖所示:
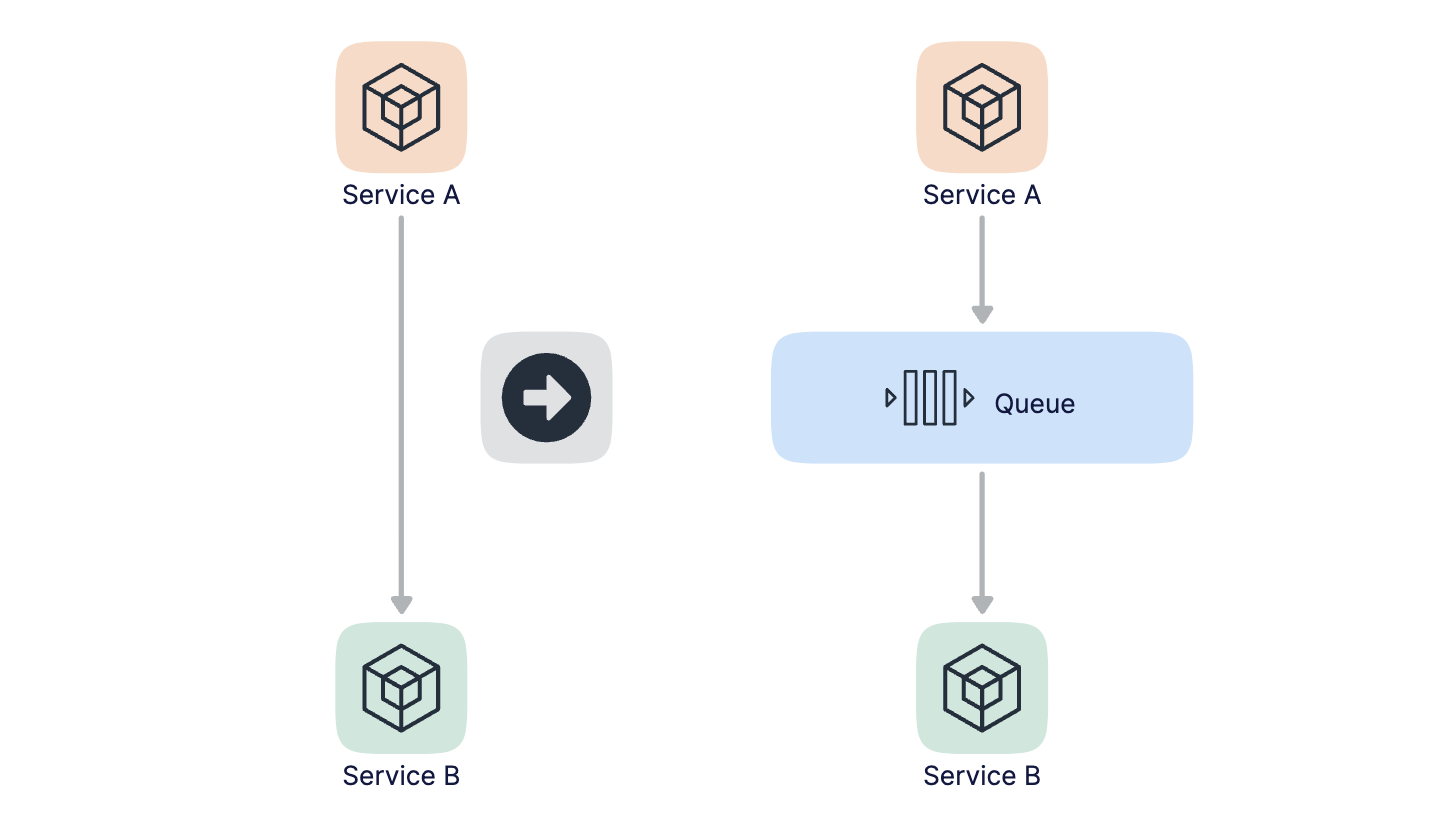
採用訊息佇列非同步處理後,那麼秒殺的結果是不太好同步返回的,所以我們的思路是當用戶發起秒殺請求後,同步返回響應使用者 "秒殺結果正在計算中..." 的提示資訊,當計算完之後我們如何返回結果給使用者呢?其實也是有多種方案的。
- 一是在頁面中採用輪詢的方式定時主動去伺服器端查詢結果,例如每秒請求一次伺服器端看看有沒有處理結果,這種方式的缺點是伺服器端的請求數會增加不少。
- 二是主動push的方式,這種就要求伺服器端和使用者端保持長連線了,伺服器端處理完請求後主動push給使用者端,這種方式的缺點是伺服器端的連線數會比較多。
還有一個問題就是如果非同步的請求失敗了該怎麼辦?我覺得對於秒殺場景來說,失敗了就直接丟棄就好了,最壞的結果就是這個使用者沒有搶到而已。如果想要儘量的保證公平的話,那麼失敗了以後也可以做重試。
如何保證訊息只被消費一次
kafka是能夠保證"At Least Once"的機制的,即訊息不會丟失,但有可能會導致重複消費,訊息一旦被重複消費那麼就會造成業務邏輯處理的錯誤,那麼我們如何避免訊息的重複消費呢?
我們只要保證即使消費到了重複的訊息,從消費的最終結果來看和只消費一次的結果等同就好了,也就是保證在訊息的生產和消費的過程是冪等的。什麼是冪等呢?如果我們消費一條訊息的時候,要給現有的庫存數量減1,那麼如果消費兩條相同的訊息就給庫存的數量減2,這就不是冪等的。而如果消費一條訊息後處理邏輯是將庫存的數量設定為0,或者是如果當前庫存的數量為10時則減1,這樣在消費多條訊息時所得到的結果就是相同的,這就是冪等的。說白了就是一件事無論你做多少次和做一次產生的結果都是一樣的,那麼這就是冪等性。
我們可以在訊息被消費後,把唯一id儲存在資料庫中,這裡的唯一id可以使用使用者id和商品id的組合,在處理下一條訊息之前先從資料庫中查詢這個id看是否被消費過,如果消費過就放棄。虛擬碼如下:
isConsume := getByID(id)
if isConsume {
return
}
process(message)
save(id)
還有一種方式是通過資料庫中的唯一索引來保證冪等性,不過這個要看具體的業務,在這裡不再贅述。
程式碼實現
整個秒殺流程圖如下:
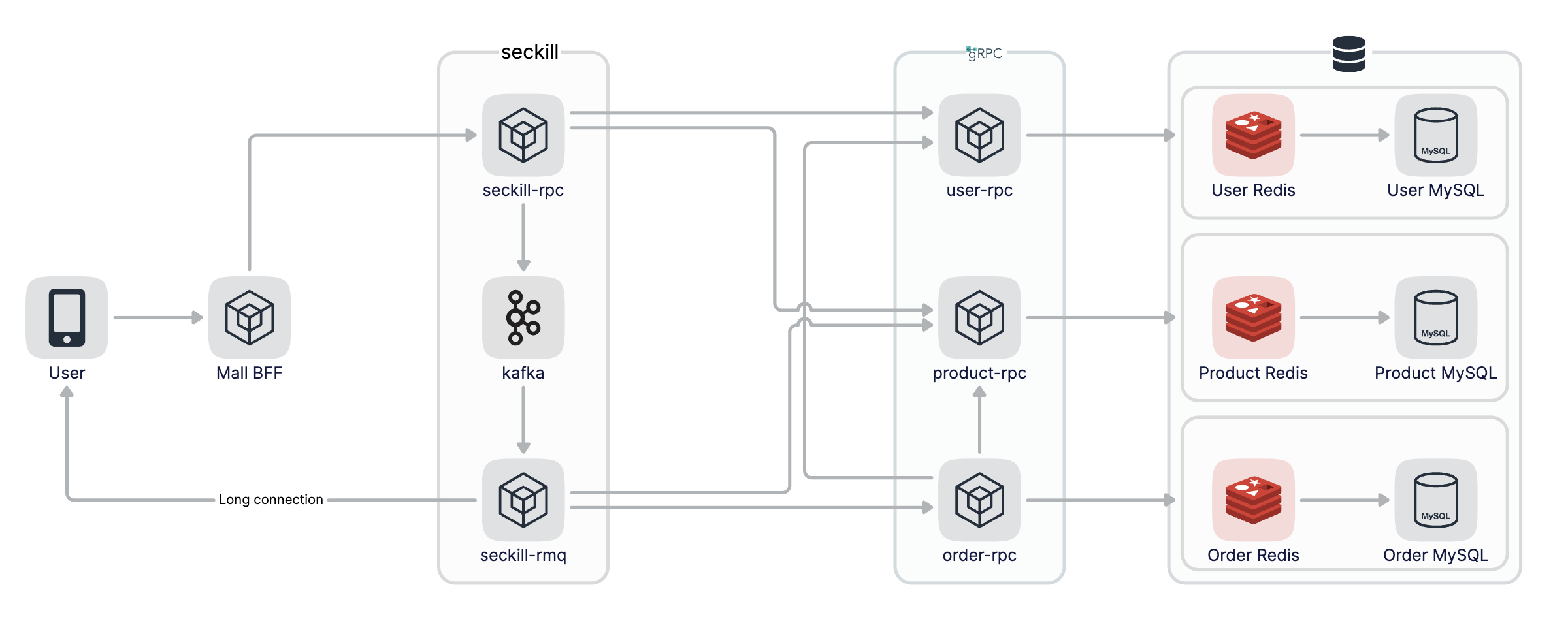
使用kafka作為訊息佇列,所以要先在本地安裝kafka,我使用的是mac可以用homebrew直接安裝,kafka依賴zookeeper也會自動安裝
brew install kafka
安裝完後通過brew services start啟動zookeeper和kafka,kafka預設偵聽在9092埠
brew services start zookeeper
brew services start kafka
seckill-rpc的SeckillOrder方法實現秒殺邏輯,我們先限制使用者的請求次數,比如限制使用者每秒只能請求一次,這裡使用go-zero提供的PeriodLimit功能實現,如果超出限制直接返回
code, _ := l.limiter.Take(strconv.FormatInt(in.UserId, 10))
if code == limit.OverQuota {
return nil, status.Errorf(codes.OutOfRange, "Number of requests exceeded the limit")
}
接著檢視當前搶購商品的庫存,如果庫存不足就直接返回,如果庫存足夠的話則認為可以進入下單流程,發訊息到kafka,這裡kafka使用go-zero提供的kq庫,非常簡單易用,為秒殺新建一個Topic,設定初始化和邏輯如下:
Kafka:
Addrs:
- 127.0.0.1:9092
SeckillTopic: seckill-topic
KafkaPusher: kq.NewPusher(c.Kafka.Addrs, c.Kafka.SeckillTopic)
p, err := l.svcCtx.ProductRPC.Product(l.ctx, &product.ProductItemRequest{ProductId: in.ProductId})
if err != nil {
return nil, err
}
if p.Stock <= 0 {
return nil, status.Errorf(codes.OutOfRange, "Insufficient stock")
}
kd, err := json.Marshal(&KafkaData{Uid: in.UserId, Pid: in.ProductId})
if err != nil {
return nil, err
}
if err := l.svcCtx.KafkaPusher.Push(string(kd)); err != nil {
return nil, err
}
seckill-rmq消費seckill-rpc生產的資料進行下單操作,我們新建seckill-rmq服務,結構如下:
tree ./rmq
./rmq
├── etc
│ └── seckill.yaml
├── internal
│ ├── config
│ │ └── config.go
│ └── service
│ └── service.go
└── seckill.go
4 directories, 4 files
依然是使用kq初始化啟動服務,這裡我們需要註冊一個ConsumeHand方法,該方法用以消費kafka資料
srv := service.NewService(c)
queue := kq.MustNewQueue(c.Kafka, kq.WithHandle(srv.Consume))
defer queue.Stop()
fmt.Println("seckill started!!!")
queue.Start()
在Consume方法中,消費到資料後先反序列化,然後呼叫product-rpc檢視當前商品的庫存,如果庫存足夠的話我們認為可以下單,呼叫order-rpc進行建立訂單操作,最後再更新庫存
func (s *Service) Consume(_ string, value string) error {
logx.Infof("Consume value: %s\n", value)
var data KafkaData
if err := json.Unmarshal([]byte(value), &data); err != nil {
return err
}
p, err := s.ProductRPC.Product(context.Background(), &product.ProductItemRequest{ProductId: data.Pid})
if err != nil {
return err
}
if p.Stock <= 0 {
return nil
}
_, err = s.OrderRPC.CreateOrder(context.Background(), &order.CreateOrderRequest{Uid: data.Uid, Pid: data.Pid})
if err != nil {
logx.Errorf("CreateOrder uid: %d pid: %d error: %v", data.Uid, data.Pid, err)
return err
}
_, err = s.ProductRPC.UpdateProductStock(context.Background(), &product.UpdateProductStockRequest{ProductId: data.Pid, Num: 1})
if err != nil {
logx.Errorf("UpdateProductStock uid: %d pid: %d error: %v", data.Uid, data.Pid, err)
return err
}
// TODO notify user of successful order placement
return nil
}
在建立訂單過程中涉及到兩張表orders和orderitem,所以我們要使用本地事務進行插入,程式碼如下:
func (m *customOrdersModel) CreateOrder(ctx context.Context, oid string, uid, pid int64) error {
_, err := m.ExecCtx(ctx, func(ctx context.Context, conn sqlx.SqlConn) (sql.Result, error) {
err := conn.TransactCtx(ctx, func(ctx context.Context, session sqlx.Session) error {
_, err := session.ExecCtx(ctx, "INSERT INTO orders(id, userid) VALUES(?,?)", oid, uid)
if err != nil {
return err
}
_, err = session.ExecCtx(ctx, "INSERT INTO orderitem(orderid, userid, proid) VALUES(?,?,?)", "", uid, pid)
return err
})
return nil, err
})
return err
}
訂單號生成邏輯如下,這裡使用時間加上自增數進行訂單生成
var num int64
func genOrderID(t time.Time) string {
s := t.Format("20060102150405")
m := t.UnixNano()/1e6 - t.UnixNano()/1e9*1e3
ms := sup(m, 3)
p := os.Getpid() % 1000
ps := sup(int64(p), 3)
i := atomic.AddInt64(&num, 1)
r := i % 10000
rs := sup(r, 4)
n := fmt.Sprintf("%s%s%s%s", s, ms, ps, rs)
return n
}
func sup(i int64, n int) string {
m := fmt.Sprintf("%d", i)
for len(m) < n {
m = fmt.Sprintf("0%s", m)
}
return m
}
最後分別啟動product-rpc、order-rpc、seckill-rpc和seckill-rmq服務還有zookeeper、kafka、mysql和redis,啟動後我們呼叫seckill-rpc進行秒殺下單
grpcurl -plaintext -d '{"user_id": 111, "product_id": 10}' 127.0.0.1:9889 seckill.Seckill.SeckillOrder
在seckill-rmq中列印了消費記錄,輸出如下
{"@timestamp":"2022-06-26T10:11:42.997+08:00","caller":"service/service.go:35","content":"Consume value: {\"uid\":111,\"pid\":10}\n","level":"info"}
這個時候檢視orders表中已經建立了訂單,同時商品庫存減一

結束語
本質上秒殺是一個高並行讀和高並行寫的場景,上面我們介紹了秒殺的注意事項以及優化點,我們這個秒殺場景相對來說比較簡單,但其實也沒有一個通用的秒殺的框架,我們需要根據實際的業務場景進行優化,不同量級的請求優化的手段也不盡相同。這裡我們只展示了伺服器端的相關優化,但對於秒殺場景來說整個請求鏈路都是需要優化的,比如對於靜態資料我們可以使用CDN做加速,為了防止流量洪峰我們可以在前端設定答題功能等等。
希望本篇文章對你有所幫助,謝謝。
每週一、週四更新
程式碼倉庫: https://github.com/zhoushuguang/lebron
專案地址
https://github.com/zeromicro/go-zero
歡迎使用 go-zero 並 star 支援我們!
微信交流群
關注『微服務實踐』公眾號並點選 交流群 獲取社群群二維條碼。