Hdfs儲存策略
一、磁碟選擇策略
1.1、介紹
在HDFS中,所有的資料都是存在各個DataNode上的.而這些DataNode上的資料都是存放於節點機器上的各個目錄中的,而一般每個目錄我們會對應到1個獨立的盤,以便我們把機器的儲存空間基本用上.這麼多的節點,這麼多塊盤,HDFS在進行寫操作時如何進行有效的磁碟選擇呢
HDFS目前的2套磁碟選擇策略都是圍繞著"資料均衡"的目標設計的:RoundRobinVolumeChoosingPolicy和AvailableSpaceVolumeChoosingPolicy
1.2、RoundRobinVolumeChoosingPolicy
名稱可以拆成2個單詞,RoundRobin和VolumeChoosingPolicy,VolumeChoosingPolicy理解為磁碟選擇策略,RoundRobin這個是一個專業術語,叫做"輪詢",類似的還有一些別的類似的術語,Round-Robin Scheduling(輪詢排程),Round-Robin 演演算法等.RoundRobin輪詢的意思用最簡單的方式翻譯就是一個一個的去遍歷,到尾巴了,再從頭開始。
理論上來說這種策略是蠻符合資料均衡的目標的,因為一個個的寫嗎,每塊盤寫入的次數都差不多,不存在哪塊盤多寫少寫的現象,但是唯一的不足之處在於每次寫入的資料量是無法控制的,可能我某次操作在A盤上寫入了512位元組的資料,在輪到B盤寫的時候我寫了128M的資料,資料就不均衡了,所以說輪詢策略在某種程度上來說是理論上均衡但還不是最好的。
實現很簡單:
volumes 引數其實就是通過 dfs.datanode.data.dir 設定的目錄。blockSize 就是咱們副本的大小。RoundRobinVolumeChoosingPolicy 策略先輪詢的方式拿到下一個 volume ,如果這個 volume 的可用空間比需要存放的副本大小要大,則直接返回這個 volume 用於存放資料;如果當前 volume 的可用空間不足以存放副本,則以輪詢的方式選擇下一個 volume,直到找到可用的 volume,如果遍歷完所有的 volumes 還是沒有找到可以存放下副本的 volume,則丟擲 DiskOutOfSpaceException 異常。
從上面的策略可以看出,這種輪詢的方式雖然能夠保證所有磁碟都能夠被使用,但是如果 HDFS 上的檔案存在大量的刪除操作,可能會導致磁碟資料的分佈不均勻,比如有的磁碟儲存得很滿了,而有的磁碟可能還有很多儲存空間沒有得到利用。
1.3、AvailableSpaceVolumeChoosingPolicy
剩餘可用空間磁碟選擇策略.這個磁碟選擇策略比第一種設計的就精妙很多了,首選他根據1個閾值,將所有的磁碟分為了2大類,高可用空間磁碟列表和低可用空間磁碟列表.然後通過1個亂數概率,會比較高概率下選擇高剩餘磁碟列表中的塊,然後對這些磁碟列表進行輪詢策略的選擇。
可用空間磁碟選擇策略是從 Hadoop 2.1.0 開始引入的(詳情參見:HDFS-1804)。這種策略優先將資料寫入具有最大可用空間的磁碟(通過百分比計算的)。在實現上可用空間選擇策略內部用到了上面介紹的輪詢磁碟選擇策略,具體的實現程式碼在 org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy 類中,核心實現如下:
areAllVolumesWithinFreeSpaceThreshold 函數的作用是先計算所有 volumes 的最大可用空間和最小可用空間,然後使用最大可用空間減去最小可用空間得到的結果和 balancedSpaceThreshold(通過 dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold 引數進行設定,預設值是 10G) 進行比較。
可用空間策略會以下面三種情況進行處理:
1、如果所有的 volumes 磁碟可用空間都差不多,那麼這些磁碟得到的最大可用空間和最小可用空間差值就會很小,這時候就會使用輪詢磁碟選擇策略來存放副本。
2、如果 volumes 磁碟可用空間相差比較大,那麼可用空間策略會將 volumes 設定中的磁碟按照一定的規則分為 highAvailableVolumes 和 lowAvailableVolumes。具體分配規則是先獲取 volumes 設定的磁碟中最小可用空間,加上 balancedSpaceThreshold(10G),然後將磁碟空間大於這個值的 volumes 放到 highAvailableVolumes 裡面;小於等於這個值的 volumes 放到 lowAvailableVolumes 裡面。
比如我們擁有5個磁碟組成的 volumes,編號和可用空間分別為 1(1G)、2(50G)、3(25G)、4(5G)、5(30G)。按照上面的規則,這些磁碟的最小可用空間為 1G,然後加上 balancedSpaceThreshold,得到 11G,那麼磁碟編號為1、4的磁碟將會放到 lowAvailableVolumes 裡面,磁碟編號為2,3和5將會放到 highAvailableVolumes 裡面。
到現在 volumes 裡面的磁碟已經都分到 highAvailableVolumes 和 lowAvailableVolumes 裡面了。
2.1、如果當前副本的大小大於 lowAvailableVolumes 裡面所有磁碟最大的可用空間(mostAvailableAmongLowVolumes,在上面例子中,lowAvailableVolumes 裡面最大磁碟可用空間為 5G),那麼會採用輪詢的方式從 highAvailableVolumes 裡面獲取相關 volumes 來存放副本。
2.2、剩下的情況會以 75%(通過 dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction 引數進行設定,推薦將這個引數設定成 0.5 到 1.0 之間)的概率在 highAvailableVolumes 裡面以輪詢的方式 volumes 來存放副本;25% 的概率在 lowAvailableVolumes 裡面以輪詢的方式 volumes 來存放副本。
然而在一個長時間執行的叢集中,由於 HDFS 中的大規模檔案刪除或者通過往 DataNode 中新增新的磁碟仍然會導致同一個 DataNode 中的不同磁碟儲存的資料很不均衡。即使你使用的是基於可用空間的策略,卷(volume)不平衡仍可導致較低效率的磁碟I/O。比如所有新增的資料塊都會往新增的磁碟上寫,在此期間,其他的磁碟會處於空閒狀態,這樣新的磁碟將會是整個系統的瓶頸
1.4、相關設定
dfs.datanode.fsdataset.volume.choosing.policy:The class name of the policy for choosing volumes in the list of directories. Defaults to org.apache.hadoop.hdfs.server.datanode.fsdataset.RoundRobinVolumeChoosingPolicy. If you would like to take into account available disk space, set the value to "org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy".。這兩種磁碟選擇策略都是對 org.apache.hadoop.hdfs.server.datanode.fsdataset.VolumeChoosingPolicy 介面進行實現。
dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold:預設值(10737418240:10G)只有在AvailableSpaceVolumeChoosingPolicy設定下才生效,
dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction:預設值(0.75f)只有在AvailableSpaceVolumeChoosingPolicy設定下才生效
參考網址:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
https://blog.csdn.net/weixin_41076809/article/details/80047557
https://blog.csdn.net/androidlushangderen/article/details/50531760
二、儲存策略
2.1、儲存型別
DISK:預設的儲存型別,磁碟儲存
ARCHIVE:具有儲存密度高(PB級),但計算能力小的特點,可用於支援檔案儲存。
SSD:固態硬碟
RAM_DISK:DataNode中的記憶體空間
HDFS中是定義了這4種型別,SSD,DISK一看就知道是什麼意思,這裡看一下其餘的2個,RAM_DISK,其實就是Memory記憶體,而ARCHIVE並沒有特指哪種儲存媒介,主要的指的是高密度儲存資料的媒介來解決資料量的容量擴增的問題.這4類是被定義在了StorageType類中:
public enum StorageType { // sorted by the speed of the storage types, from fast to slow RAM_DISK(true), SSD(false), DISK(false), ARCHIVE(false); ...
旁邊的true或者false代表的是此類儲存型別是否是transient特性的.transient的意思是指轉瞬即逝的,並非持久化的.在HDFS中,如果沒有主動宣告資料目錄儲存型別的,預設都是DISK,設定屬性dfs.datanode.data.dir中進行本地對應儲存目錄的設定,同時帶上一個儲存型別標籤,宣告此目錄用的是哪種型別的儲存媒介,例子如下:
[SSD]file:///grid/dn/ssd0
如果目錄前沒有帶上[SSD]/[DISK]/[ARCHIVE]/[RAM_DISK]這4種中的任何一種,則預設是DISK型別.
2.2、儲存原理
-
DataNode通過心跳彙報自身資料儲存目錄的StorageType給NameNode,
-
隨後NameNode進行彙總並更新叢集內各個節點的儲存型別情況
-
待複製檔案根據自身設定的儲存策略資訊向NameNode請求擁有此型別儲存媒介的DataNode作為候選節點
2.3、儲存型別選擇策略
HDFS中提供熱、暖、冷、ALL_SSD、One_SSD、Lazy_Persistence等儲存策略。為了根據不同的儲存策略將檔案儲存在不同的儲存型別中,引入了一種新的儲存策略概念。HDFS支援以下儲存策略:
6種策略:
- Hot - for both storage and compute. The data that is popular and still being used for processing will stay in this policy. When a block is hot, all replicas are stored in DISK.
- Cold - only for storage with limited compute. The data that is no longer being used, or data that needs to be archived is moved from hot storage to cold storage. When a block is cold, all replicas are stored in ARCHIVE.
- Warm - partially hot and partially cold. When a block is warm, some of its replicas are stored in DISK and the remaining replicas are stored in ARCHIVE.
- All_SSD - for storing all replicas in SSD.
- One_SSD - for storing one of the replicas in SSD. The remaining replicas are stored in DISK.
- Lazy_Persist - for writing blocks with single replica in memory. The replica is first written in RAM_DISK and then it is lazily persisted in DISK.
熱(hot)
-
用於大量儲存和計算
-
當資料經常被使用,將保留在此策略中
-
當block是hot時,所有副本都儲存在磁碟中。
冷(cold)
-
僅僅用於儲存,只有非常有限的一部分資料用於計算
-
不再使用的資料或需要存檔的資料將從熱儲存轉移到冷儲存中
-
當block是cold時,所有副本都儲存在Archive中
溫(warm)
-
部分熱,部分冷
-
當一個塊是warm時,它的一些副本儲存在磁碟中,其餘的副本儲存在Archive中
全SSD
- 將所有副本儲存在SSD中
單SSD
- 在SSD中儲存一個副本,其餘的副本儲存在磁碟中。
懶持久
- 用於編寫記憶體中只有一個副本的塊。副本首先寫在RAM_Disk中,然後惰性地儲存在磁碟中。
HDFS儲存策略由以下欄位組成:
-
策略ID(Policy ID)
-
策略名稱(Policy Name)
-
塊放置的儲存型別列表(Block Placement)
-
用於建立檔案的後備儲存型別列表(Fallback storages for creation)
-
用於副本的後備儲存型別列表(Fallback storages for replication)
當有足夠的空間時,塊副本將根據#3中指定的儲存型別列表儲存。當列表#3中的某些儲存型別耗盡時,將分別使用#4和#5中指定的後備儲存型別列表來替換空間外儲存型別,以便進行檔案建立和副本。
以下是一個典型的儲存策略表格:
| Policy ID | Policy Name | Block Placement (n replicas) | Fallback storages for creation | Fallback storages for replication |
|---|---|---|---|---|
| 15 | Lazy_Persist | RAM_DISK: 1, DISK: n-1 | DISK | DISK |
| 12 | All_SSD | SSD: n | DISK | DISK |
| 10 | One_SSD | SSD: 1, DISK: n-1 | SSD, DISK | SSD, DISK |
| 7 | Hot (default) | DISK: n | ARCHIVE | |
| 5 | Warm | DISK: 1, ARCHIVE: n-1 | ARCHIVE, DISK | ARCHIVE, DISK |
| 2 | Cold | ARCHIVE: n | ||
| 1 | Provided | PROVIDED: 1, DISK: n-1 | PROVIDED, DISK | PROVIDED, DISK |
注意事項:
-
Lazy_Persistence策略僅對單個副本塊有用。對於具有多個副本的塊,所有副本都將被寫入磁碟,因為只將一個副本寫入RAM_Disk並不能提高總體效能。
-
對於帶條帶的擦除編碼檔案,合適的儲存策略是ALL_SSD、HOST、CORD。因此,如果使用者為EC檔案設定除上述之外的策略,在建立或移動塊時不會遵循該策略。
2.4、命令
hdfs storagepolicies -help
$ hdfs storagepolicies -help
[-listPolicies]
List all the existing block storage policies.
[-setStoragePolicy -path <path> -policy <policy>]
Set the storage policy to a file/directory.
<path> The path of the file/directory to set storage policy
<policy> The name of the block storage policy
[-getStoragePolicy -path <path>]
Get the storage policy of a file/directory.
<path> The path of the file/directory for getting the storage policy
1個設定命令,2個獲取命令,最簡單的使用方法是事先劃分好冷熱資料儲存目錄。設定好對應的Storage Policy,然後後續相應的程式在對應分類目錄下寫資料,自動繼承父目錄的儲存策略。在較新版的Hadoop釋出版本中增加了資料遷移工具(hdfs mover -help)。此工具的重要用途在於他會掃描HDFS上的檔案,判斷檔案是否滿足其內部設定的儲存策略,如果不滿足,就會重新遷移資料到目標儲存型別節點上。
列出所有儲存策略:hdfs storagepolicies -listPolicies
[root@node1 Examples]# hdfs storagepolicies -listPolicies
Block Storage Policies:
BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}
BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
設定儲存策略:hdfs storagepolicies -setStoragePolicy -path
| -path |
參照目錄或檔案的路徑 |
|---|---|
| -policy |
儲存策略的名稱 |
取消儲存策略:取消檔案或目錄的儲存策略。在執行unset命令之後,將應用當前目錄最近的祖先儲存策略,如果沒有任何祖先的策略,則將應用預設的儲存策略。
hdfs storagepolicies -unsetStoragePolicy -path
| -path |
參照目錄或檔案的路徑 |
|---|
獲取儲存策略:hdfs storagepolicies -getStoragePolicy -path
| -path |
參照目錄或檔案的路徑。 |
|---|
2.5、設定
-
dfs.storage.policy.enabled:啟用/禁用儲存策略功能。預設值是true
-
dfs.datanode.data.dir:在每個資料節點上,應當用逗號分隔的儲存位置標記它們的儲存型別。這允許儲存策略根據策略將塊放置在不同的儲存型別上。
磁碟上的DataNode儲存位置/grid/dn/disk 0應該設定為[DISK]file:///grid/dn/disk0
SSD上的DataNode儲存位置/grid/dn/ssd 0應該設定為 [SSD]file:///grid/dn/ssd0
存檔上的DataNode儲存位置/grid/dn/Archive 0應該設定為 [ARCHIVE]file:///grid/dn/archive0
將RAM_磁碟上的DataNode儲存位置/grid/dn/ram0設定為[RAM_DISK]file:///grid/dn/ram0
如果DataNode儲存位置沒有顯式標記儲存型別,它的預設儲存型別將是磁碟。
2.6、冷熱溫三階段資料儲存
為了更加充分的利用儲存資源,我們可以將資料分為冷、熱、溫三個階段來儲存。
| /data/hdfs-test/data_phase/hot | 熱階段資料 |
|---|---|
| /data/hdfs-test/data_phase/warm | 溫階段資料 |
| /data/hdfs-test/data_phase/cold | 冷階段資料 |
設定儲存目錄:
進入到Hadoop設定目錄,編輯hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file:///export/server/hadoop-3.1.4/data/datanode,ARCHIVE]file:///export/server/hadoop-3.1.4/data/archive</value>
<description>DataNode儲存名稱空間和事務紀錄檔的本地檔案系統上的路徑</description>
</property>
然後分發到其他節點,再重啟hdfs。
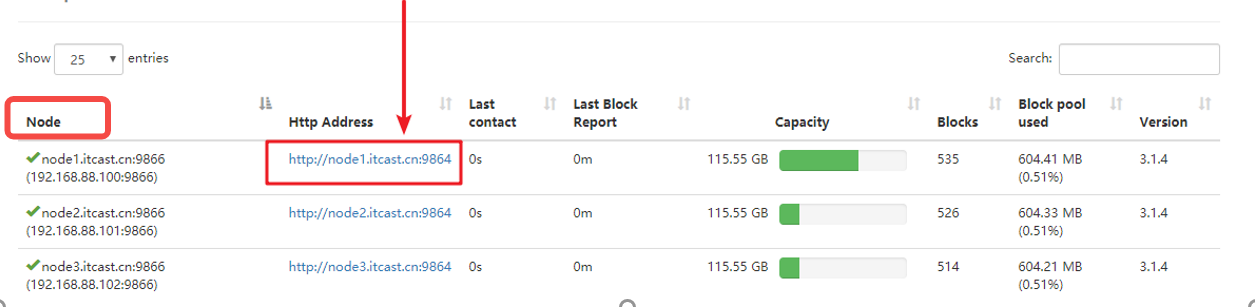
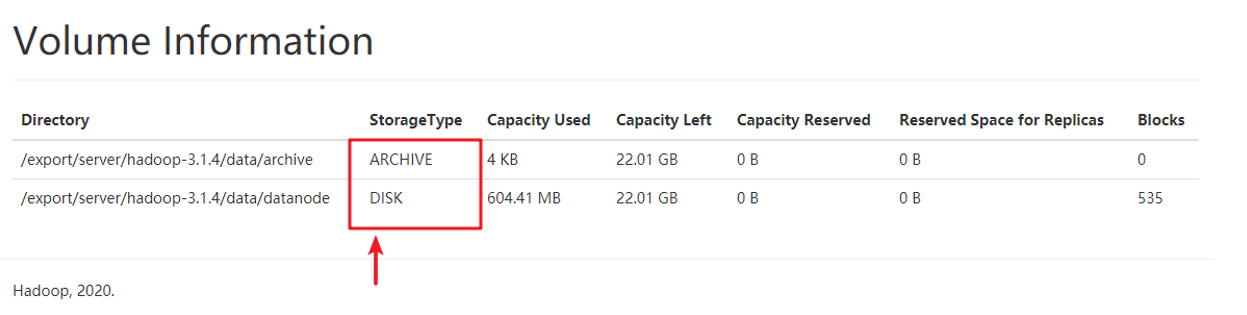
可以看到,現在設定的是兩個目錄,一個StorageType為ARCHIVE、一個Storage為DISK。
設定策略:
- 建立目錄
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/hot
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/warm
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/cold
- 檢視當前HDFS支援的儲存策略
[root@node1 Examples]# hdfs storagepolicies -listPolicies
Block Storage Policies:
BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}
BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
- 分別設定三個目錄的儲存策略
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/hot -policy HOT
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/warm -policy WARM
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/cold -policy COLD
- 檢視三個目錄的儲存策略
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/hot
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/warm
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/cold
- 測試
分別上傳檔案
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/hot
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/warm
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/cold
檢視不同儲存策略檔案的block位置
hdfs fsck /data/hdfs-test/data_phase/hot/profile -files -blocks -locations
[root@node1 hadoop]# hdfs fsck /data/hdfs-test/data_phase/hot/profile -files -blocks -locations
Connecting to namenode via http://node1.itcast.cn:9870/fsck?ugi=root&files=1&blocks=1&locations=1&path=%2Fdata%2Fhdfs-test%2Fdata_phase%2Fhot%2Fprofile
FSCK started by root (auth:SIMPLE) from /192.168.88.100 for path /data/hdfs-test/data_phase/hot/profile at Sun Oct 11 22:03:05 CST 2020
/data/hdfs-test/data_phase/hot/profile 3158 bytes, replicated: replication=3, 1 block(s): OK
0. BP-538037512-192.168.88.100-1600884040401:blk_1073742535_1750 len=3158 Live_repl=3 [DatanodeInfoWithStorage[192.168.88.101:9866,DS-96feb29a-5dfd-4692-81ea-9e7f100166fe,DISK], DatanodeInfoWithStorage[192.168.88.100:9866,DS-79739be9-5f9b-4f96-a005-aa5b507899f5,DISK], DatanodeInfoWithStorage[192.168.88.102:9866,DS-e28af2f2-21ae-4aa6-932e-e376dd04ddde,DISK]]
hdfs fsck /data/hdfs-test/data_phase/warm/profile -files -blocks -locations
/data/hdfs-test/data_phase/warm/profile 3158 bytes, replicated: replication=3, 1 block(s): OK
0. BP-538037512-192.168.88.100-1600884040401:blk_1073742536_1751 len=3158 Live_repl=3 [DatanodeInfoWithStorage[192.168.88.102:9866,DS-636f34a0-682c-4d1b-b4ee-b4c34e857957,ARCHIVE], DatanodeInfoWithStorage[192.168.88.101:9866,DS-ff6970f8-43e0-431f-9041-fc440a44fdb0,ARCHIVE], DatanodeInfoWithStorage[192.168.88.100:9866,DS-79739be9-5f9b-4f96-a005-aa5b507899f5,DISK]]
hdfs fsck /data/hdfs-test/data_phase/cold/profile -files -blocks -locations
/data/hdfs-test/data_phase/cold/profile 3158 bytes, replicated: replication=3, 1 block(s): OK
0. BP-538037512-192.168.88.100-1600884040401:blk_1073742537_1752 len=3158 Live_repl=3 [DatanodeInfoWithStorage[192.168.88.102:9866,DS-636f34a0-682c-4d1b-b4ee-b4c34e857957,ARCHIVE], DatanodeInfoWithStorage[192.168.88.101:9866,DS-ff6970f8-43e0-431f-9041-fc440a44fdb0,ARCHIVE], DatanodeInfoWithStorage[192.168.88.100:9866,DS-ca9759a0-f6f0-4b8b-af38-d96f603bca93,ARCHIVE]]
我們可以看到:
-
hot目錄中的block,3個block都在DISK磁碟
-
warm目錄中的block,1個block在DISK磁碟,另外兩個在archive磁碟
-
cold目錄中的block,3個block都在archive磁碟
參考:https://blog.csdn.net/androidlushangderen/article/details/51105876
2.7、記憶體儲存
介紹
-
HDFS支援寫入由DataNode管理的堆外記憶體
-
DataNode非同步地將記憶體中資料重新整理到磁碟,從而減少代價較高的磁碟IO操作,這種寫入稱之為懶持久寫入
-
HDFS為懶持久化寫做了較大的永續性保證。在將副本儲存到磁碟之前,如果節點重新啟動,有非常小的機率會出現資料丟失。應用程式可以選擇使用懶持久化寫,以減少寫入延遲
該特性從ApacheHadoop 2.6.0開始支援。
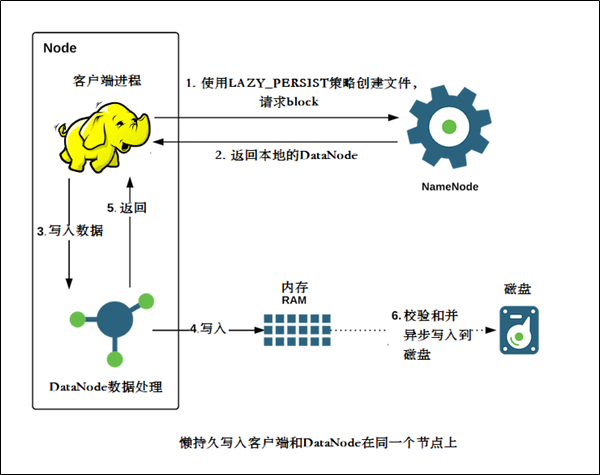
適用場景
-
比較適用於,當應用程式需要往HDFS中以低延遲的方式寫入相對較低資料量(從幾GB到十幾GB(取決於可用記憶體)的資料量時
-
記憶體儲存適用於在叢集內執行,且執行的使用者端與HDFS DataNode處於同一節點的應用程式。使用記憶體儲存可以減少網路傳輸的開銷
-
如果記憶體不足或未設定,使用懶持久化寫入的應用程式將繼續工作,會繼續使用磁碟儲存。
設定
1、確定用於儲存在記憶體中的副本記憶體量
- 在指定DataNode的hdfs-site.xml設定dfs.datanode.max.locked.memory ,這個引數和快取共用
- DataNode將確保懶持久化的記憶體不超過dfs.datanode.max.locked.memory
- 例如,為記憶體中的副本預留32 GB
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>34359738368</value>
</property>
在設定此值時,請記住,還需要記憶體中的空間來處理其他事情,例如資料節點和應用程式JVM堆以及作業系統頁快取。如果在與資料節點相同的節點上執行YARN節點管理器程序,則還需要YARN容器的記憶體
2、設定datanode
-
在每個DataNode節點上初始化一個RAM磁碟
-
通過選擇RAM磁碟,可以在DataNode程序重新啟動時保持更好的資料永續性
下面的設定可以在大多數Linux發行版上執行,目前不支援在其他平臺上使用RAM磁碟。
選擇tmpfs(VS ramfs)
-
Linux支援使用兩種型別的RAM磁碟-tmpfs和ramfs
-
tmpfs的大小受linux核心的限制,而ramfs可以使用所有系統可用的記憶體
-
tmpfs可以在記憶體不足情況下交換到磁碟上。但是,許多對效能要求很高的應用執行時都禁用記憶體磁碟交換
-
HDFS當前支援tmpfs分割區,而對ramfs的支援正在開發中
掛載RAM磁碟
- 使用Linux中的mount命令來掛載記憶體磁碟。例如:掛載32GB的tmpfs分割區在/mnt/dn-tmpfs
sudo mount -t tmpfs -o size=32g tmpfs /mnt/dn-tmpfs/
-
建議在/etc/fstab建立一個入口,在DataNode節點重新啟動時,將自動重新建立RAM磁碟
-
另一個可選項是使用/dev/shm下面的子目錄。這是tmpfs預設在大多數Linux發行版上都可以安裝
-
確保掛載的大小大於或等於dfs.datanode.max.locked.memory,或者寫入到/etc /fstab
-
不建議使用多個tmpfs對懶持久化寫入的每個DataNode節點進行分割區
設定RAM_DISK儲存型別tmpfs標籤
-
標記tmpfs目錄中具有RAM_磁碟儲存型別的目錄
-
在hdfs-site.xml中設定dfs.datanode.data.dir。例如,在具有三個硬碟卷的DataNode上,/grid /0, /grid /1以及 /grid /2和一個tmpfs掛載在 /mnt/dn-tmpfs, dfs.datanode.data.dir必須設定如下:
<property>
<name>dfs.datanode.data.dir</name>
<value>/grid/0,/grid/1,/grid/2,[RAM_DISK]/mnt/dn-tmpfs</value>
</property>
- 這一步至關重要。如果沒有RAM_DISK標記,HDFS將把tmpfs卷作為非易失性儲存,資料將不會儲存到持久儲存,重新啟動節點時將丟失資料
其他設定
-
確保啟用儲存策略:確保全域性設定中的儲存策略是已啟用的。預設情況下,此設定是開啟的
-
使用記憶體儲存
-
使用懶持久化儲存策略
-
指定HDFS使用LAZY_PERSIST策略,可以對檔案使用懶持久化寫入
可以通過以下三種方式之一進行設定:
-
在目錄上設定㽾策略,將使其對目錄中的所有新檔案生效
-
這個HDFS儲存策略命令可以用於設定策略.
hdfs storagepolicies -setStoragePolicy -path <path> -policy LAZY_PERSIST #命令方式
fs.setStoragePolicy(path, "LAZY_PERSIST"); //程式設計方式
三、副本放置策略
3.1、介紹
目前在HDFS中現有的副本放置策略類有2大繼承子類,分別為BlockPlacementPolicyDefault, BlockPlacementPolicyWithNodeGroup,
最經典的3副本策略用的就是BlockPlacementPolicyDefault策略類.3副本如何存放在這個策略中得到了非常完美的實現.在BlockPlacementPolicyDefault類中的註釋具體解釋了3個副本的存放位置:
The class is responsible for choosing the desired number of targets for placing block replicas. The replica placement strategy is that if the writer is on a datanode, the 1st replica is placed on the local machine, otherwise a random datanode. The 2nd replica is placed on a datanode that is on a different rack. The 3rd replica is placed on a datanode which is on a different node of the rack as the second replica.
簡要概況起來3點:
1st replica. 如果寫請求方所在機器是其中一個datanode,則直接存放在本地,否則隨機在叢集中選擇一個datanode.
2nd replica. 第二個副本存放於不同第一個副本的所在的機架.
3rd replica.第三個副本存放於第二個副本所在的機架,但是屬於不同的節點
3.2、BlockPlacementPolicyDefault
策略核心方法chooseTargets
在預設放置策略方法類中,核心方法就是chooseTargets,但是在這裡有2種同名實現方法,唯一的區別是有無favoredNodes引數.favoredNodes的意思是偏愛,喜愛的節點,只要分為如下三個步驟:
-
初始化操作:計算每個機架所允許最大副本數,建立節點黑名單
-
選擇目標節點:將所選節點加入到結果列表中,同時加入到移除列表中,意為已選擇過的節點
-
排序目標節點列表,形成pipeline
Pipeline節點的形成:整個過程就是傳入目標節點列表引數,經過getPipeline方法的處理,然後返回此pipeline.先來看getPipeline的註釋:
Return a pipeline of nodes. The pipeline is formed finding a shortest path that starts from the writer and traverses all nodes This is basically a traveling salesman problem.
關鍵是這句The pipeline is formed finding a shortest path that
starts from the writer,就是說從writer所在節點開始,總是尋找相對路徑最短的目標節點,最終形成pipeline,學習過演演算法的人應該知道,這其實也是經典的TSP旅行商問題
一句話概況來說,就是選出一個源節點,根據這個節點,遍歷當前可選的下一個目標節點,找出一個最短距離的節點,作為下一輪選舉的源節點,這樣每2個節點之間的距離總是最近的,於是整個pipeline節點間的距離和就保證是足夠小的了.那麼現在另外一個問題還沒有解決,如何定義和計算2個節點直接的距離: 要計算其中的距離,我們首先要了解HDFS中如何定義節點間的距離,其中涉及到了拓撲邏輯結構的概念,結構圖如下:
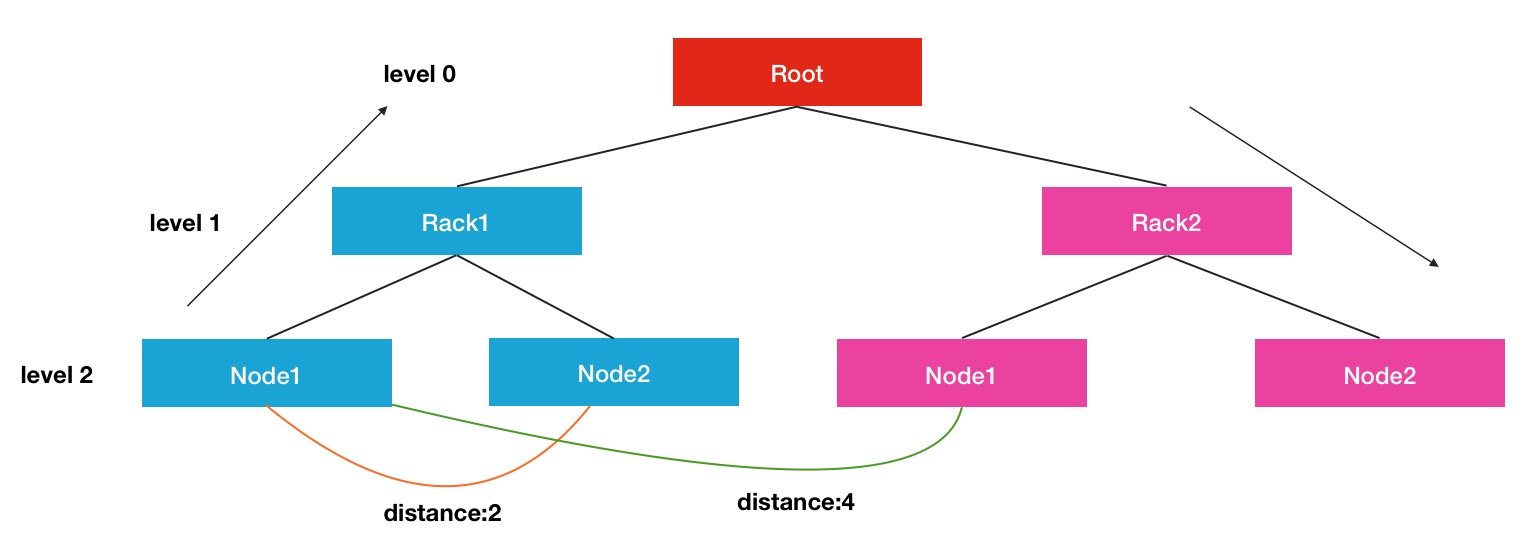
這裡顯示的是一個三層結構的樹形效果圖,Root可以看出是一個大的叢集,下面劃分出了許多個機架,每個機架下面又有很多屬於此機架的節點.在每個連線點中,是通過交換機和路由器進行連線的.每個節點間的距離計算方式是通過尋找最近的公共祖先所需要的距離作為最終的結果.比如Node1到Node2的距離是2,就是Node1->Rack1, Rack1->Node2.同理,Rack1的Node1到Rack2的Node1的距離就是4.
chooseTarget方法主邏輯:
final Node localNode = chooseTarget(numOfReplicas, writer, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storagePolicy, EnumSet.noneOf(StorageType.class), results.isEmpty());
numOfReplicas, 額外需要複製的副本數
excludedNodes,移除節點集合,此集合內的節點不應被考慮作為目標節點
results,當前已經選擇好的目標節點集合
storagePolicy,儲存型別選擇策略
首節點的選擇:
-
如果writer請求方本身位於叢集中的一個datanode之上,則第一個副本的位置就在本地節點上,很好理解,這樣直接就是本地寫操作了.
-
如果writer請求方純粹來源於外界使用者端的寫請求時,則從已選擇好的目標節點result列表中挑選第一個節點作為首個節點.
-
如果result列表中還是沒有任何節點,則會從叢集中隨機挑選1個node作為第一個localNode
經典的3副本存放位置,多餘的副本隨機存放的原理即可.當然在其間選擇的過程中可能會發生異常,因為有的時候我們沒有設定機架感知,叢集中都屬於一個預設機架的default-rack,則會導致chooseRemoteRack的方法出錯,因為沒有滿足條件的其餘機架,這時需要一些重試策略.
chooseLocalStorage,chooseLocalRack,chooseRemoteRack和chooseRandom方法,四個選擇目標節點位置的方法其實是一個優先順序漸漸降低的方法,首先選擇本地儲存位置.如果沒有滿足條件的,再選擇本地機架的節點,如果還是沒有滿足條件的,進一步降級選擇不同機架的節點,最後隨機選擇叢集中的節點
目標節點儲存判斷好壞條件:
-
storage的儲存型別是要求給定的儲存型別
-
storage不能是READ_ONLY唯讀的
-
storage不能是壞的
-
storage所在機器不應該是已下線或下線中的節點
-
storage所在節點不應該是舊的,一段時間內沒有更新心跳的節點
-
節點內保證有足夠的剩餘空間能滿足寫Block要求的大小
-
要考慮節點的IO負載繁忙程度
-
要滿足同機架內最大副本數的限制
參考:https://blog.csdn.net/androidlushangderen/article/details/51178253
出處:https://www.cnblogs.com/zsql/
如果您覺得閱讀本文對您有幫助,請點選一下右下方的推薦按鈕,您的推薦將是我寫作的最大動力!
版權宣告:本文為博主原創或轉載文章,歡迎轉載,但轉載文章之後必須在文章頁面明顯位置註明出處,否則保留追究法律責任的權利。