為什麼不建議使用自定義Object作為HashMap的key?
此前部門內的一個線上系統上線後記憶體一路飆高、一段時間後直接佔滿。協助開發人員去分析定位,發現記憶體中某個Object的量遠遠超出了預期的範圍,很明顯出現記憶體漏失了。
結合程式碼分析發現,洩漏的這個物件,主要存在一個全域性HashMap中,是作為HashMap的Key值。第一反應就是這裡key對應類沒有去覆寫equals()和hashCode()方法,但對照程式碼仔細一看卻發現其實已經按要求提供了自定義的equals和hashCode方法了。進一步走讀業務實現邏輯,才發現了其中的玄機。
踩坑歷程回顧
鑑於專案程式碼相對保密,這裡舉個簡單的DEMO來輔助說明下。
場景:
記憶體中構建一個HashMap<User, List<Post>>對映集,用於儲存每個使用者最近的發帖資訊(只是個例子,實際工作中如果遇到這種使用者發帖快取的場景,一般都是用的集中快取,而不是單機快取)。
使用者資訊User類定義如下:
@Data
public class User {
// 使用者名稱稱
private String userName;
// 賬號ID
private String accountId;
// 使用者上次登入時間,每次登入的時候會自動更新DB對應時間
private long lastLoginTime;
// 其他欄位,忽略
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return lastLoginTime == user.lastLoginTime &&
Objects.equals(userName, user.userName) &&
Objects.equals(accountId, user.accountId);
}
@Override
public int hashCode() {
return Objects.hash(userName, accountId, lastLoginTime);
}
}
實際使用的時候,使用者發帖之後,會將這個貼文資訊新增到使用者對應的快取中。
/**
* 將發帖資訊加入到使用者快取中
*
* @param currentUser 當前使用者
* @param postContent 貼文資訊
*/
public void addCache(User currentUser, Post postContent) {
cache.computeIfAbsent(currentUser, k -> new ArrayList<>()).add(postContent);
}
當實際執行的時候,會發現問題就來了,Map中的記錄越來越多,遠超系統內實際的使用者數量。為什麼呢?仔細看下User類就可以知道了!
原來編碼的時候直接用IDE工具自動生成的equals和hashCode方法,裡面將lastLoginTime也納入計算邏輯了。這樣每次使用者重新登入之後,對應hashCode值也就變了,這樣發帖的時候判斷使用者是不存在Map中的,就會再往map中插入一條,隨著時間的推移,記憶體中資料就會越來越多,導致記憶體漏失。
這麼一看,其實問題很簡單。但是實際編碼的時候,很多人往往又會忽略這些細節、或者當時可能沒有這個場景,後面維護的人新增了點邏輯,就會出問題 —— 說白了,就是埋了個坑給後面的人踩上了。
hashCode覆寫的講究
hashCode,即一個Object的雜湊碼。HashCode的作用:
- 對於List、陣列等集合而言,HashCode用途不大;
- 對於HashMap\HashTable\HashSet等集合而言,HashCode有很重要的價值。
HashCode在上述HashMap等容器中主要是用於尋域,即尋找某個物件在集合中的區域位置,用於提升查詢效率。
一個Object物件往往會存在多個屬性欄位,而選擇什麼屬性來計算hashCode值,具有一定的考驗:
- 如果選擇的欄位太多,而HashCode()在程式執行中呼叫的非常頻繁,勢必會影響計算效能;
- 如果選擇的太少,計算出來的HashCode勢必很容易就會出現重複了。
為什麼hashCode和equals要同時覆寫
這就與HashMap的底層實現邏輯有關係了。
對於JDK1.8+版本中,HashMap底層的資料結構形如下圖所示,使用陣列+連結串列或者紅黑樹的結構形式:
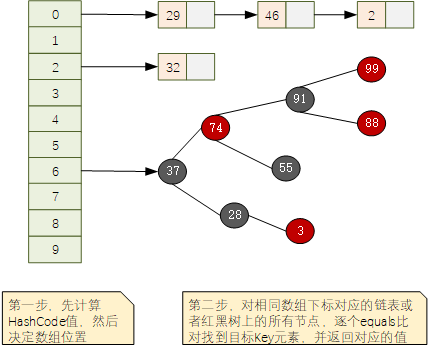
給定key進行查詢的時候,分為2步:
- 呼叫key物件的hashCode()方法,獲取hashCode值,然後換算為對應陣列的下標,找到對應下標位置;
- 根據hashCode找到的陣列下標可能會同時對應多個key(所謂的hash碰撞,不同元素產生了相同的hashCode值),這個時候使用key物件提供的equals()方法,進行逐個元素比對,直到找到相同的元素,返回其所對應的值。
根據上面的介紹,可以概括為:
- hashCode負責大概定位,先定位到對應片區
- equals負責在定位的片區內,精確找到預期的那一個
這裡也就明白了為什麼hashCode()和equals()需要同時覆寫。
資料退出機制的兜底
其實,說到這裡,全域性Map出現記憶體漏失,還有一點就是編碼實現的時候缺少對資料退出機制的考慮。
參考下redis之類的依賴記憶體的快取中介軟體,都有一個繞不開的兜底策略,即資料淘汰機制。
對於業務類編碼實現的時候,如果使用Map等容器類來實現全域性快取的時候,應該要結合實際部署情況,確定記憶體中允許的最巨量資料條數,並提供超出指定容量時的處理策略。比如我們可以基於LinkedHashMap來客製化一個基於LRU策略的快取Map,來保證記憶體資料量不會無限制增長,這樣即使程式碼出問題也只是這一個功能點出問題,不至於讓整個程序宕機。
public class FixedLengthLinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private static final long serialVersionUID = 1287190405215174569L;
private int maxEntries;
public FixedLengthLinkedHashMap(int maxEntries, boolean accessOrder) {
super(16, 0.75f, accessOrder);
this.maxEntries = maxEntries;
}
/**
* 自定義資料淘汰觸發條件,在每次put操作的時候會呼叫此方法來判斷下
*/
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxEntries;
}
}
總結
梳理下幾個要點:
- 最好不要使用Object作為HashMap的Key
- 如果不得已必須要使用,除了要覆寫equals和hashCode方法
- 覆寫的equals和hashCode方法中一定不能有頻繁易變更的欄位
- 記憶體快取使用的Map,最好對Map的資料記錄條數做一個強制約束,提供下資料淘汰策略。
好啦,關於這個問題的分享就到這裡咯,你是否有在工作中遇到此類相同或者相似的問題呢?歡迎一起分享討論下哦~
我是悟道,聊技術、又不僅僅聊技術~
如果覺得有用,請點個關注,也可以關注下我的公眾號【架構悟道】,獲取更及時的更新。
期待與你一起探討,一起成長為更好的自己。

本文來自部落格園,作者:架構悟道,歡迎關注公眾號[架構悟道]持續獲取更多幹貨,轉載請註明原文連結:https://www.cnblogs.com/softwarearch/p/16423496.html