關於微服務
原創不易,求分享、求一鍵三連
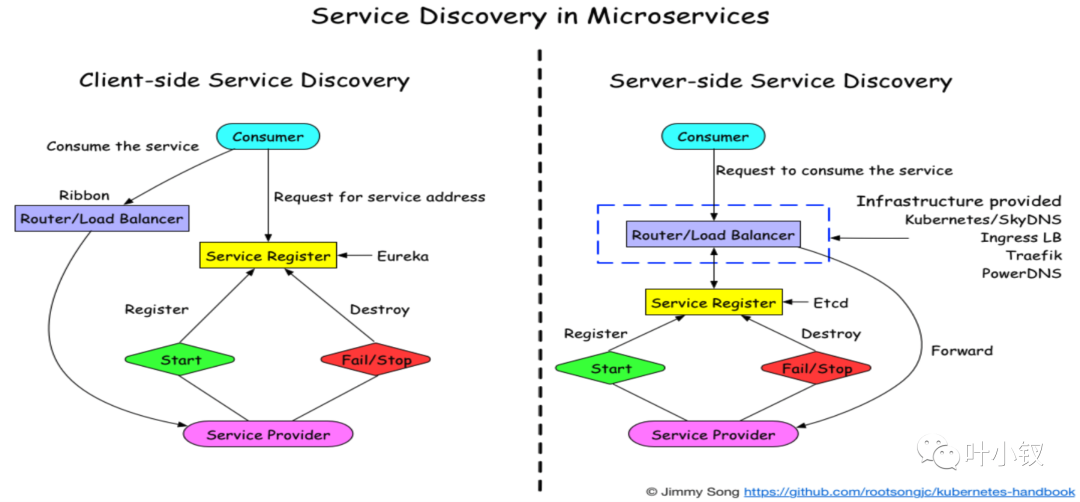
微服務會讓我們的應用變多,並且為了高可用一個服務會線上上部署多臺,那麼進行服務呼叫就存在節點之間的負載均衡和服務發現,負載均衡是為了讓各個節點的負載儘量平均,而服務發現是為了解耦服務中provider和consumer的發現和呼叫。
通常服務發現有兩種常用的方式:一種是伺服器端服務發現,服務發現的和請求路由實現邏輯放在伺服器端;另外一種是使用者端服務發現,因為這種發現和路由邏輯是由傳送請求的使用者端來實現的,像我們現在使用的kratos微服務架構就是用這種方式進行負載均衡的:
微服務進行服務發現和負載均衡中經常用到一個重要的元件就是註冊中心,接下來我們先說一下我們用到的註冊中心discovery(參考地址:https://github.com/bilibili/discovery/blob/master/doc/arch.md) 以下是discovery的架構圖:
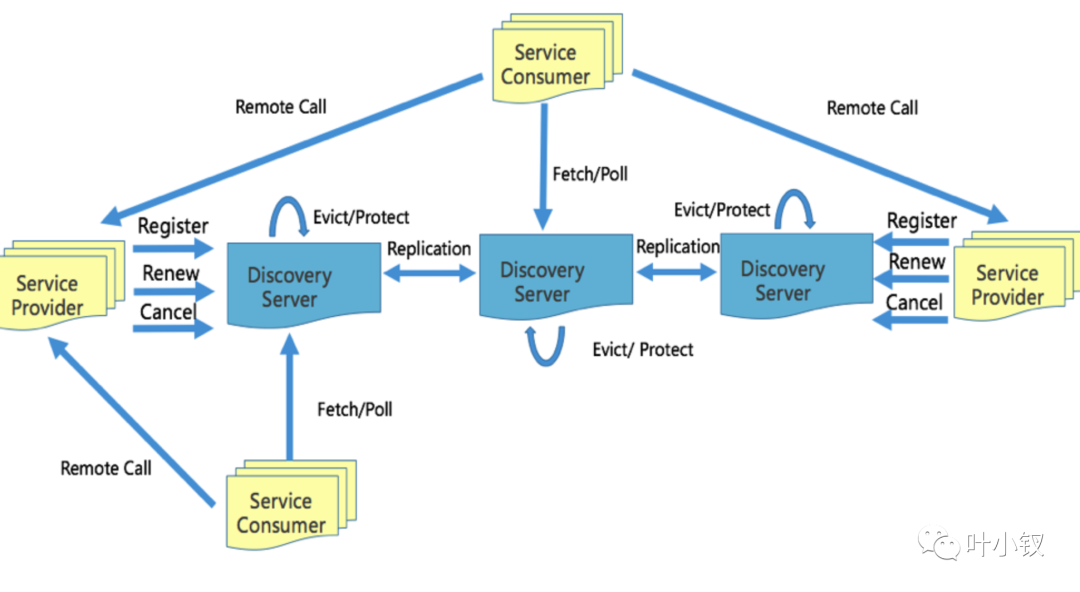
涉及三種角色:
- 提供服務的是service Provider;
- 服務訂閱是Service Consumer ;
- 註冊中心是Discovery Server;
接下來我們分別說一下注冊中心是如何來進行服務註冊、發現、註冊中心節點之間的資料同步、以及遇到一些問題是如何避免的。
服務註冊
當一個Provider啟動的時候,首先需要判斷服務是否啟動成功,一般會定一個監控檢測的介面,判斷專案執行的依賴是否正常比如:mysql、redis或者mq等。
檢測成功則會向discovery server發起register請求,請求成功之後,後續會以心跳的方式傳送renew請求保證該服務能在註冊中心續租成功,當服務下線會先將自己的健康檢測的healthcheck設定下線狀態,再傳送Cancel到註冊中心進行登出,將未處理的業務處理完成等待一段時候時間之後登出服務。
服務發現
discovry中consumer通過長輪詢的方式獲取使用的provider最新資料,有資料更新則進行本地資料變更,那麼來看下什麼是長輪詢(HTTP Long-Polling)
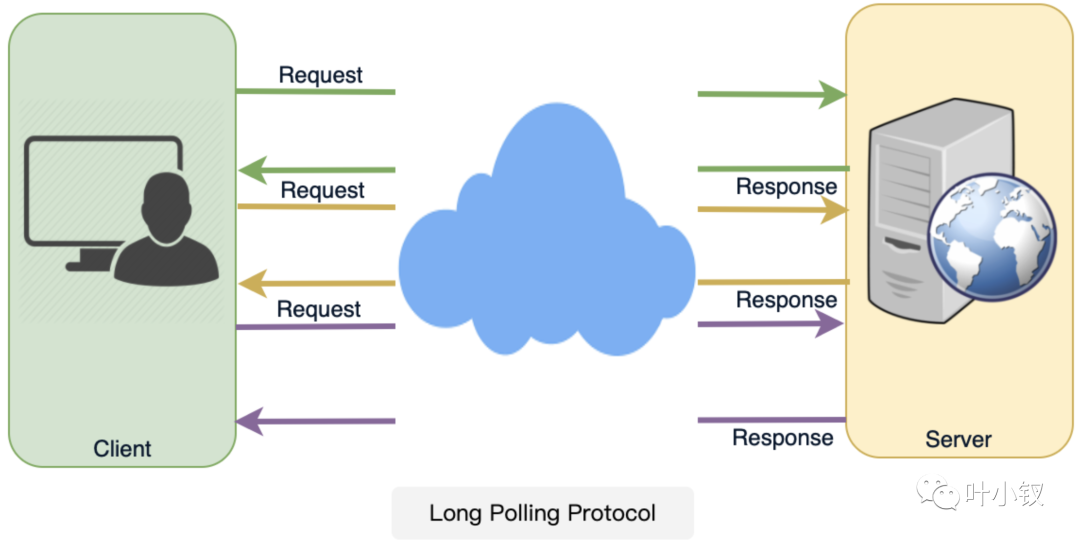
長輪詢通常被叫做「Hanging GET」,大致是這樣的:
如果伺服器沒有資料可供使用者端使用,則伺服器不會傳送空響應,而是保留請求並等待某些資料變為可用;一旦資料可用,將向用戶端傳送完整響應。
然後使用者端立即從伺服器端重新請求資訊,以便伺服器幾乎總是有一個可用的等待請求,它可以使用該請求來傳遞資料以響應事件。
使用HTTP長輪詢的應用程式的基本生命週期如下:
- 使用者端使用常規HTTP發出初始請求,然後等待響應
- 伺服器會延遲其響應,知道更新可用資料或者發生超時。
- 當更新可用時,伺服器會向用戶端傳送完整響應。
- 使用者端通常會在收到響應後立即傳送新的長輪詢請求,或者在暫停後傳送請求,以允許可接受的延遲期。
- 每個長輪詢請求都有一個超時。由於超時,使用者端必須在連結關閉後定期重新連結。
Discovery 節點的資料同步
當叢集中的discovery接收到provider節點的請求之後,會講請求轉發到其他discovery進行資料同步,保持每個節點都能保持全部的最新資料,這種同步會有一些延遲,後面會說到這種延遲對服務發現的註冊中心這種業務場景來說是影響不大的。
go-grpc內建的負載均衡
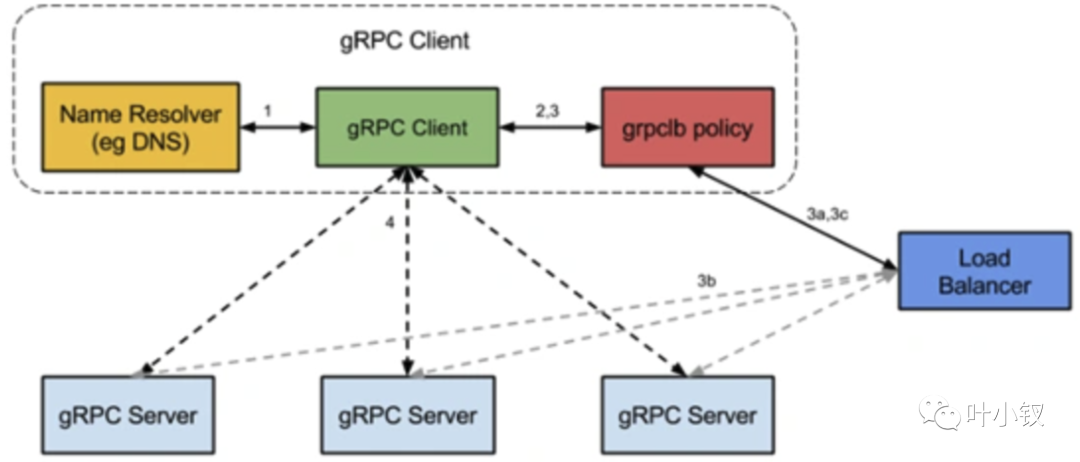
grpc在官網檔案中提供了實現LoadBalance的方法,不同語言的grpc程式碼API中也提供了命名解析和負載均衡介面供擴充套件。預設提供的是DNS resolver的實現,介面規範實現簡單,只需實現服務註冊和服務監聽和解析的邏輯就可以了,執行機制如下:
Resolver 解析器,用於從註冊中心實時獲取當前伺服器端的列表,同步傳送給Balancer;
當grpc註冊服務發現時,實際時註冊的resolver.Builder, Builder會開啟單獨的groutine,進行watch邏輯,當呼叫UpdateState 向ClientConn傳送服務地址表的更新;
resolver中的ClientConn結構提供了resolver通知ClientConn更新服務列表的回撥方法。
Balancer 平衡器,接收從Resolver傳送的伺服器端列表,建立維護長連結;client發起rpc呼叫時,按照一定的演演算法從連線池中選擇一個連線進行rpc呼叫;
Register 註冊,用於伺服器端初始化和線上時,將自己資訊上報到註冊中心,主要資訊包含Ip+埠。
grpc HealthCheck
grpc提供了一個標準的健康檢測協定,在grpc的所有語言實現中基本都提供了生成程式碼和用於設定執行狀態的功能。
主動健康檢查health check,可以在服務提供者服務不穩定時,被消費者感知,臨時從負載節點中移除,減少錯誤請求。
有了上面說到的服務註冊中心和負載均衡的支援,下面看如何實現平滑釋出和平滑下線。
平滑釋出
外接服務呼叫 Provider health check 介面,發現介面不通就不會註冊,發現通就會註冊,外掛有個旁者幫你去註冊。
一般服務啟動會進行一些資料初始化,環境初始化,等所有完成,然後將介面的 health check 介面狀態改為可用,這時候docker 容器就可以放流量進來了,這就是常用的外掛方式。
平滑下線
如果我們這時候有個新功能需要上線,這時候需要先下線走 捲動更新。
k8s 傳送 kill 程序id
go main 攔截 sigterm 訊號,先告訴服務發現註冊中心服務要登出,然後服務發現通知其他服務將自己原生的負載均衡連線池 close 掉,並且流量不要再傳送過去了。但是服務發現通知其他 consumer 需要一定的同步時間,所以下一步我們將自己服務的 health check 介面標記為 下線狀態。
最終我們一般要等到 2 個服務發現心跳週期,這是最差的情況,一般是實時的退出。
當然,不可避免依舊會遇到一些問題:
當註冊中心掛了會怎樣?
我們現在技術棧用的是B站開源的Kratos微服務架構,做的是使用者端負載均衡,會把用到的資料快取在使用者端記憶體裡,當註冊中心掛掉了,就無法獲取到註冊中心的provider節點變更資訊,這段時間不發版本,正常情況下就不會有大量的節點變更,註冊中心做好監控告警,快速恢復註冊中心。
當註冊的節點未全域性同步完成會怎樣?
註冊中心做了高可用會啟動多個節點,節點之間的資料同步會遵循 CAP 定理 一致性(Consistency)(等同於所有節點存取同一份最新的資料副本);
可用性(Availability)(每次請求都能獲取到非錯的響應——但是不保證獲取的資料為最新資料);
分割區容錯性(Partition tolerance)(以實際效果而言,分割區相當於對通訊的時限要求。系統如果不能在時限內達成資料一致性,就意味著發生了分割區的情況,必須就當前操作在C和A之間做出選擇);
分散式系統智慧滿足三項中的兩項不可能全部滿足。Discovry是一個ap系統,資料同步會出現同步不成功、同步延遲等問題,對於未同步到的節點會延遲同步,只有部分節點可能會收到延遲,但是最終會都會同步成功。
當登出的節點未下線掉會怎樣?
上面已經說到go-grpc支援健康檢查的機制,如果節點未下線,但在provider下線前將健康檢查介面置為不可用,則節點會從呼叫地址列表中移除,即使註冊中心延遲下線,也不會有影響。
discovry中的provider是定期傳送renew的方式進行續租,超過剔除心跳週期後,伺服器端會將對應的下線節點踢掉。
註冊中心新節點上線,記憶體無資料會怎樣?
新啟動一個discovery節點到叢集,這個時候新啟動記憶體中沒有其他節點的資料,discovery做了處理,在啟動2-3個心跳週期才能提供consumer節點發現的服務,等待其他節點的資料全部同步之後才能提供服務。
discovery內部的自保護機制。
如果provider叢集和discovery之間存在網路出現異常,但provider服務正常,只是心跳異常的情況,會啟到保護的作用。
網路閃斷和分割區時自我保護模式
60s內丟失大量(小於Instance總數20.85)心跳數,「好」「壞」Instance資訊都保留 所有node都會持續提供服務,單個node的註冊和發現功能不受影響 最大保護時間,防止分割區恢復後大量原先Instance真的已經不存在時,一直處於保護模式
參見(https://github.com/bilibili/discovery/blob/master/doc/arch.md)
染色環境(泳道環境)
為什麼需要泳道環境?
我們同時存在幾十個需求迭代同時開發,且不同的迭代可能會修改同一個專案,程式碼的衝突可以通過不同的分支解決,但開發階段的聯調都在同一個開發環境上的話會存在相互影響,造成開發效率低。
許多迭代的程式碼在同一個開發環境上聯調會造成許多問題,研發人員解決這些問題開銷的時間和精力成本很大。
這樣的環境管理時間一久便造成了開發環境的聯調不太穩定,研發人員轉而將開發階段的聯調放到了測試環境,從而汙染了測試環境,進而影響了測試階段的效率。我們期望保證研發同學能夠在不同的迭代情況下能夠獨立開發聯調,測試同學期望保證測試環境的穩定。
"泳道",顧名思義是可以讓不同的迭代開發能夠在其自己的"泳道"上玩,不會影響其他的"泳道"。
我們選擇了kratos框架,它本來就已經支援節點染色的功能,根據請求節點染色來進行負載能友好的解決上面提到的一些問題,在discovery註冊到的節點中有個metadata用來存放節點的一些擴充套件欄位,其中color就用來表示每個節點的染色環境:
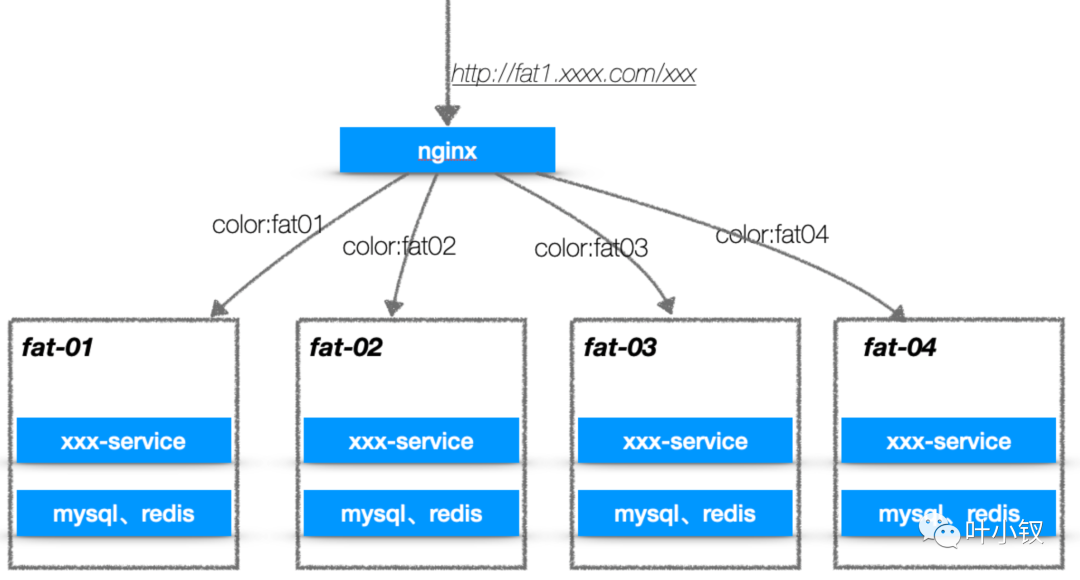
在傳送http請求的時候將需要存取的染色請求 設定到http header裡面,在interface層解析放到ctx中,當去呼叫其他provider服務的時候,client端進行負載均衡進行節點選擇,優先根據ctx中color選擇對應染色的節點,不存在則預設color為空的節點進行呼叫。
上面說的這種情況我們只需要一套測試的基準環境,所有服務的color都是空,當同一個服務不同的需求變更就部署不同的color的多個節點,就能根據上面的方式進行測試。
好了,今天的分享就到這,喜歡的同學可以四連支援:

想要更多交流可以加我微信:
