小樣本利器2.文字對抗+半監督 FGSM & VAT & FGM程式碼實現
小樣本利器2.文字對抗+半監督 FGSM & VAT & FGM程式碼實現
上一章我們聊了聊通過一致性正則的半監督方案,使用大量的未標註樣本來提升小樣本模型的泛化能力。這一章我們結合FGSM,FGM,VAT看下如何使用對抗訓練,以及對抗訓練結合半監督來提升模型的魯棒性。本章我們會混著CV和NLP一起來說,VAT的兩篇是CV領域的論文,而FGM是CV遷移到NLP的實現方案,一作都是同一位作者大大。FGM的tensorflow實現詳見Github-SimpleClassification
我們會集中討論3個問題
- 對抗樣本為何存在
- 對抗訓練實現方案
- 對抗訓練為何有效
存在性

對抗訓練
下面我們看下如何在模型訓練過程中引入對抗樣本,並訓練模型給出正確的預測
監督任務
這裡的對抗訓練和GAN這類生成對抗訓練不同,這裡的對抗主要指微小擾動,在CV領域可以簡單解釋為肉眼不可見的輕微擾動(如下圖)

不過兩類對抗訓練的原理都可以被經典的min-max公式涵蓋
- max:對抗的部分通過計算delta來最大化損失
- min:訓練部分針對擾動後的輸入進行訓練最小化損失函數
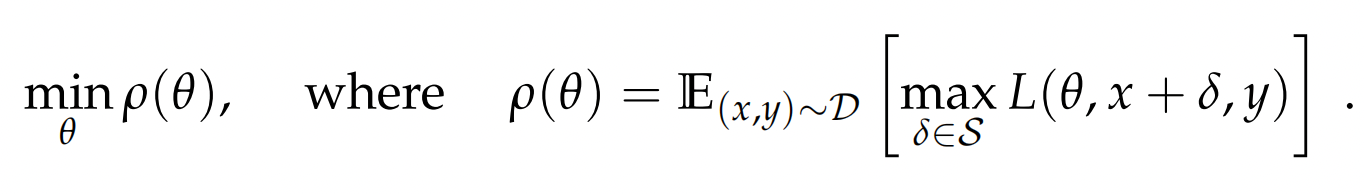
以上損失函數的視角,也可以切換成成極大似然估計的視角,也就是FGM中如下的公式,通過計算r,來使得擾動後y的條件概率最小化
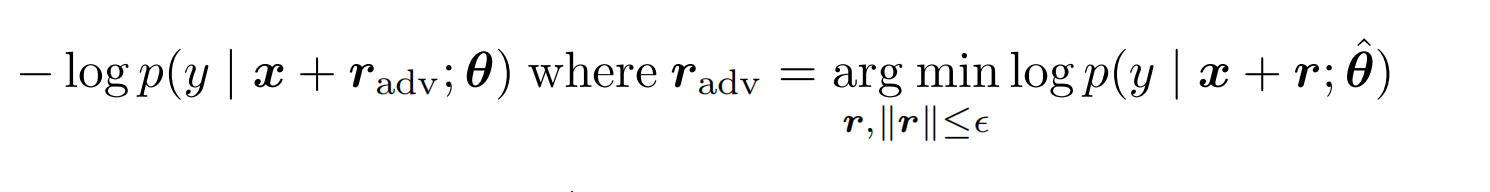
於是問題就被簡化成了如何計算擾動。最簡單的方案就是和梯度下降相同沿用當前位置的一階導數,梯度下降是沿graident去最小化損失,那沿反方向進行擾動不就可以最大化損失函數。不過因為梯度本身是對當前位置擬合曲線的線性化,所以需要控制步長來保證區域性的線性,反向傳播中我們用learning rate來控制步長,這裡則需要控制擾動的大小。同時對抗擾動本身也需要控制擾動的幅度,不然就不符合微小擾動這個前提,放到NLP可以理解為為了防止擾動造成語意本身產生變化。
FGSM使用了\(l_{\infty}\) norm來對梯度進行正則化,只保留了方向資訊丟棄了gradient各個維度上的scale
![]()
而FGM中作者選擇了l2 norm來對梯度進行正則化,在梯度上更多了更多的資訊,不過感覺在模型初始擬合的過程中也可能引入更多的噪音。
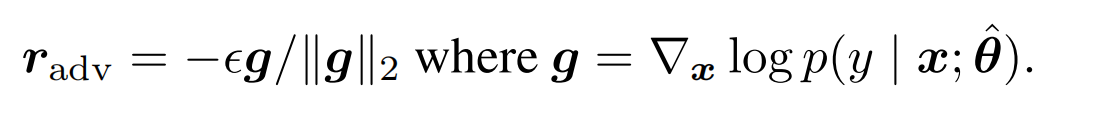
有了對抗樣本,下一步就是如何讓模型對擾動後的樣本給出正確的分類結果。所以最簡單的訓練方式就是結合監督loss,和施加擾動之後的loss。FGSM中作者簡單用0.5的權重來做融合。所以模型訓練的方式是樣本向前傳遞計算Loss,凍結梯度,計算擾動,對樣本施加擾動再計算Loss,兩個loss加權計算梯度。不過部分實現也有隻保留對抗loss的操作,不妨作為超參對不同任務進行調整~
![]()
在使用對抗擾動時有兩個需要注意的點
- 施加擾動的位置:對輸入層擾動更合理
- 擾動和擾動層的scale:擾動層歸一化
對於CV任務擾動位置有3個選擇,輸入層,隱藏層,或者輸出層,對於NLP任務因為輸入離散,所以輸入層被替換成look up之後的embedding層。
作者基於萬能逼近定理【簡單說就是一個線性層+隱藏層如果有unit足夠多可以逼近Rn上的任意函數0】指出因為輸出層本身不滿足萬能逼近定理條件,所以對輸出層(linear-softmax layer)擾動一般會導致模型underfit,因為模型會沒有足夠的能力來學習如何抵抗擾動。
而對於啟用函數範圍在[-inf, inf]的隱藏層進行擾動,會導致模型通過放大隱藏層scale來忽略擾動的影響。
因此一般是對輸入層進行擾動,在下面FGM的實現中作者對word embedding進行歸一化來規避上面scale的問題。不過這裡有一個疑問就是對BERT這類預訓練模型是不能對輸入向量進行歸一化的,那麼如何保證BERT在微調的過程中不會通過放大輸入層來規避擾動呢?後來想到的一個點是在探測Bert Finetune對向量空間的影響中提到的,微調對BERT各個層的影響是越接近底層影響越小的,所以從這個角度來說也是針對輸入層做擾動更合理些~
半監督任務
以上的對抗訓練只適用於標註樣本,因為需要通過loss來計算梯度方向,而未標註樣本無法計算loss,最簡單的方案就是用模型預估來替代真實label。於是最大化loss的擾動,變成使得預測分佈變化最大的擾動。
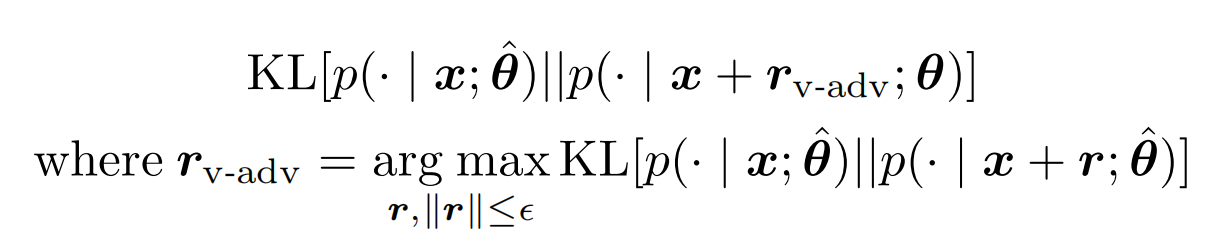
以上的虛擬擾動r無法直接計算,於是泰勒展開再次登場,不過這裡因為把y替換成了模型預估p,所以一階導數為0,於是最大化KL近似為最大化二階導數的部分
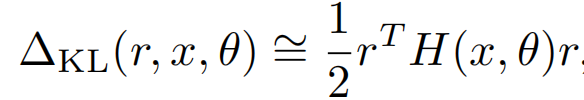
而以上r的求解,其實就是求解二階海森矩陣的最大特徵值對應的特徵向量,以下u就是最大特徵值對應的單位特徵向量
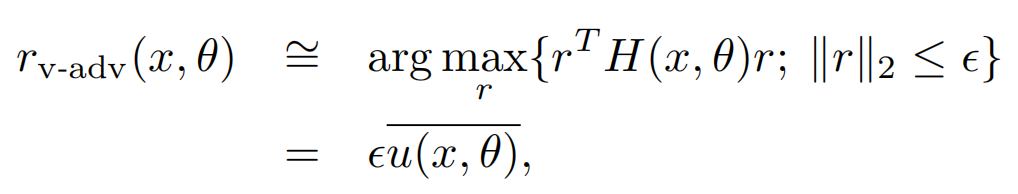
因為海森矩陣的計算複雜度較高,一般會採用迭代近似的方式來計算(詳見REF12),簡單說就是隨機向量d(和u非正交),通過反覆的下述迭代會趨近於u
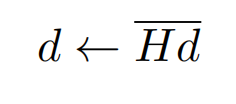
而以上Hd同樣可以被近似計算,因為上面KL的一階導數為0,所以我們可以用KL~rHr的一階差分來估計Hd,於是也就得了d的近似值
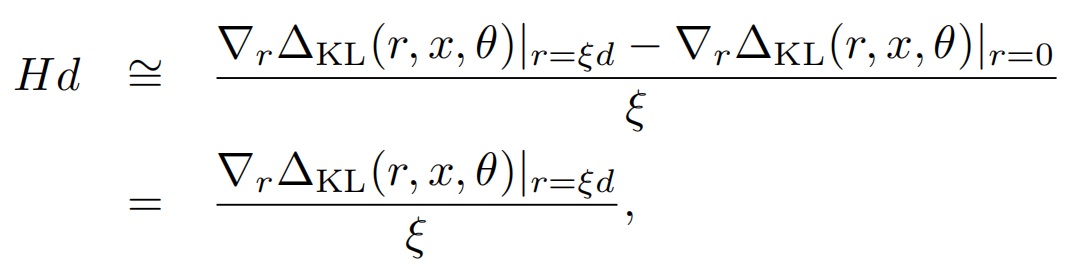
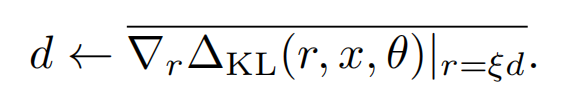
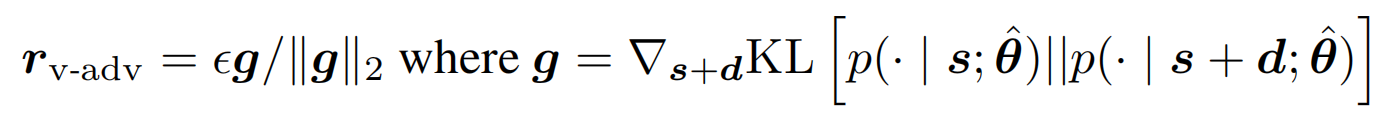
哈哈近似了一圈估計有的盆友們已經蒙圈了,可以對照著下面的計算方案再回來理解下上面的公式,計算虛擬擾動的演演算法如下(其中1~4可以多次迭代)
- 對embedding層施加隨機擾動d
- 向前傳遞計算擾動後的logit
- 擾動logit和原始logit計算KL距離
- 對KL計算梯度
- 對梯度做歸一化得到虛擬擾動的近似
- 對embedding層施加虛擬擾動,再計算一遍KL作為虛擬對抗部分的loss
這裡暫時沒有實現VAT因為時間複雜度有些高,之後有需要再補上VAT的部分
合理性
對抗擾動可以理解為一種正則方案,核心是為了提高模型魯棒性,也就是樣本外的泛化能力,這裡給出兩個視角
- 對比L1正則

- 對比一致性正則
這裡和上一章我們提到的半監督之一致性正則有著相通之處,一致性正則強調模型應該對輕微擾動的樣本給出一致的預測,但並沒有對擾動本身進行太多的探討,而對抗訓練的核心在於如何對樣本進行擾動。但核心都是擴充標註樣本的覆蓋範圍,讓標註樣本的近鄰擁有一致的模型預測。
效果
FGM論文是在LSTM,Bi-LSTM上做的測試會有比較明顯的2%左右ErrorRate的下降。我在BERT上加入FGM在幾個測試集上嘗試指標效果並不明顯,不過這裡開源資料上測試集和訓練集相似度比較高,而FGM更多是對樣本外的泛化能力的提升。不過我在公司資料上使用FMG輸出的預測概率的置信度會顯著下降,一般bert微調會容易得到0.999這類高置信度預測,而加入FGM之後prob的分佈變得更加合理,這個效果更容易用正則來進行解釋。以下也給出了兩個比賽方案連結裡面都是用fgm做了優化也有一些insights,感興趣的朋友可能在你的測試集上也實驗下~
不過一言以蔽之,FGM的對抗方案,主要通過正則來約束模型學習,更多是錦上添花,想要學中送碳建議盆友們腳踏實地的去優化樣本,優化標註,以及確認你的任務目標定義是否合理~
Reference
- FGSM- Explaining and Harnessing Adversarial Examples, ICLR2015
- FGM-Adversarial Training Methods for Semi-Supervised Text Classification, ICLR2017
- VAT-Virtual adversarial training: a regularization method for supervised and semi-supervised learning
- VAT-Distributional Smoothing with Virtual Adversarial Training
- Min-Max公式 Towards Deep Learning Models Resistant to Adversarial Attacks
- FGM-TF實現
- VAT-TF實現
- NLP中的對抗訓練
- 蘇神yyds:對抗訓練淺談:意義、方法和思考(附Keras實現)
- 天池大賽疫情文字挑戰賽線上第三名方案分享
- 基於同音同形糾錯的問題等價性判別第二名方案
- Eigenvalue computation in the 20th century