FS2K人臉素描屬性識別
2022-06-28 18:01:07
人臉素描屬性識別
程式碼:https://github.com/linkcao/FS2K_extract
問題分析
- 需要根據FS2K資料集進行訓練和測試,實現輸入一張圖片,輸出該圖片的屬性特徵資訊,提取屬性特徵包括
hair(有無頭髮)、hair_color(頭髮顏色)、gender(影象人物性別)、earring(是否有耳環)、smile(是否微笑)、frontal_face(是否歪脖)、style(圖片風格),詳細資訊均可通過FS2K的anno_train.json和anno_test.json獲取,本質是一個多標籤分類問題。
處理方案
- 首先對於FS2K資料集用官方的資料劃分程式進行劃分,之後對劃分後的資料進行預處理,統一圖片字尾為jpg,之後自定義資料載入類,在資料載入過程中進行標籤編碼,對圖片大小進行統一,並轉成tensor,在處理過程中發現存在4個通道的圖片,採取取前3個通道的方案,之後再對影象進行標準化,可以加快模型的收斂,處理完成的資料作為模型的輸入,在深度學習模型方面,首先需要進行模型選擇,使用了三個模型,分別為VGG16,ResNet121以及DenseNet121,在通過pytorch預訓練模型進行載入,並修改模型輸出層,輸出數量為圖片屬性特徵數,之後在設定模型訓練的引數,包括Batch,學習率,epoch等,在每一輪訓練完成後,都需要對預測出的特徵進行處理,在二分類標籤設定概率閾值,多分類標籤特徵列則進行最大概率類別組合,取預測概率最大的類別作為當前屬性的預測結果,每一輪訓練都在測試集上進行效能評估,並根據F1指標擇優儲存模型。訓練完成後,在測試集上預測屬性提取結果,對每一個屬性進行效能評估,最後取平均,得到平均的效能指標。
整體的處理流程如下圖所示:
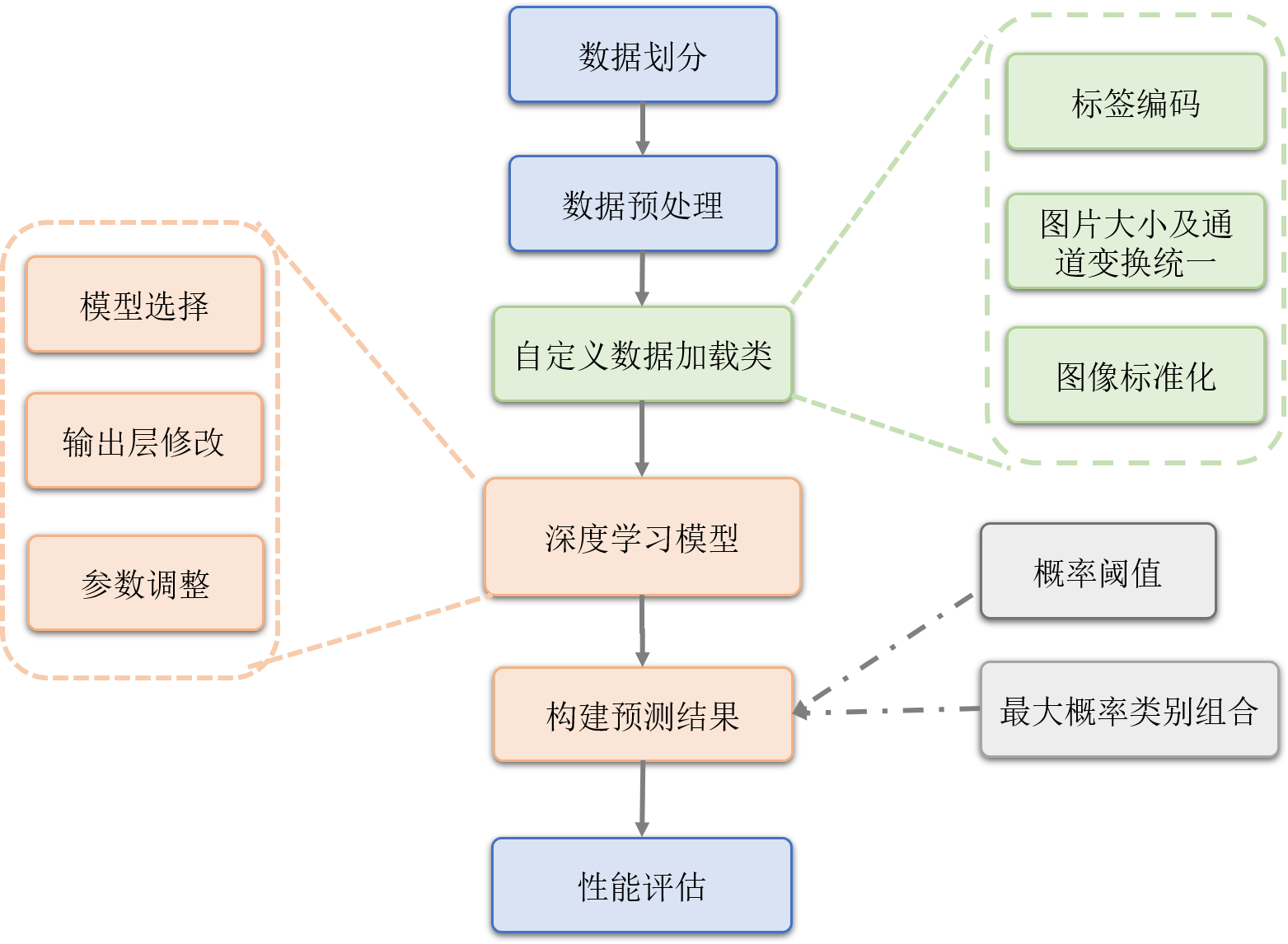
資料預處理
- 資料劃分,根據FS2K官方給出的資料劃分得到訓練集和測試集
- 統一圖片字尾為jpg,通道數為3
- 所給資料集分為三個資料夾,每個資料夾圖片的畫素各不相同,分別為250*250、475 *340、223 *318,這裡統一變換成256 * 256,便於後序處理
- 將圖片資料轉成tensor
- 逐channel的對影象進行標準化,可以加快模型的收斂
標籤編碼
- 由於目標屬性集中存在
hair_color、style兩個多分類標籤,因此對這兩個標籤做編碼處理 - 採用One_Hot編碼對多類別標籤進行處理
hair_color中0 對應 [1,0,0,0,0], 1對應[0,1,0,0,0], 2對應[0,0,1,0,0],以此類推,共5類style中 0 對應 [1,0,0],1對應[0,1,0], 2對應[0,0,1],以此類推,共3類
- 在和其他的5個二分類標籤拼接組成標籤向量,共13維
實驗模型
VGG16
模型結構引數
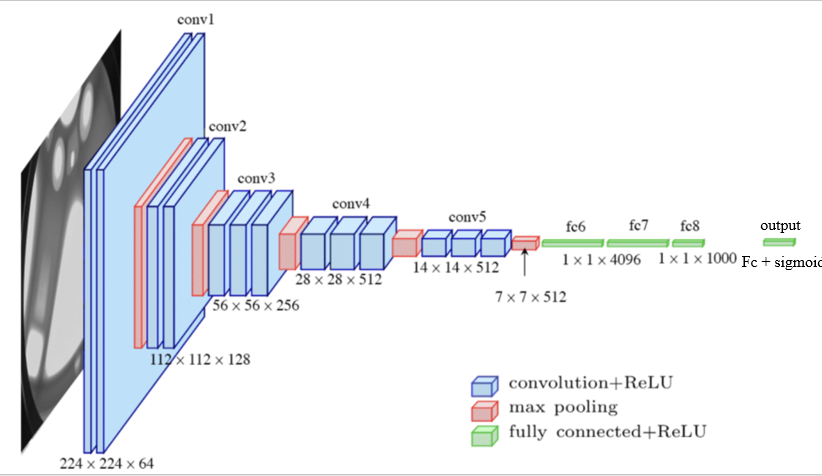
由於VGG16最後一層全連線輸出1000維特徵,因此在本題中需要在加一層全連線輸入1000維特徵,輸出13維特徵,最後再加上一層sigmoid啟用函數,在得到每一類預測的概率後,針對編碼過的hair_color、style的8列,對各自的編碼後的對應列計算概率最大的列下標,作為該屬性的預測值。
訓練引數
| batch | 64 |
|---|---|
| epoch | 20 |
| optimizer (優化器) | SGD(隨機梯度下降) |
| criterion (損失函數) | BCELoss(二分類交叉熵損失) |
| 學習率 | 0.01 |
photo資料集上模型訓練Loss
結果 「方法一」
| f1 | precision | recall | accuracy | |
|---|---|---|---|---|
| hair | 0.926064 | 0.903045 | 0.950287 | 0.950287 |
| gender | 0.598046 | 0.611282 | 0.59369 | 0.59369 |
| earring | 0.74061 | 0.674408 | 0.821224 | 0.821224 |
| smile | 0.513038 | 0.580621 | 0.639579 | 0.639579 |
| frontal_face | 0.758024 | 0.694976 | 0.833652 | 0.833652 |
| hair_color | 0.351596 | 0.387132 | 0.389101 | 0.389101 |
| style | 0.460469 | 0.526145 | 0.443595 | 0.443595 |
| average | 0.668481 | 0.672201 | 0.708891 | 0.708891 |
ResNet18
模型結構引數
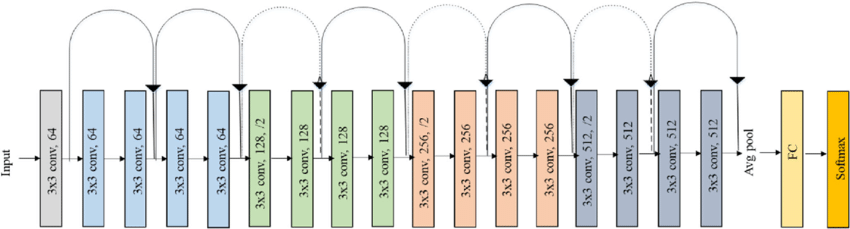
模型修改 ,模型最後加一層全連線輸入1000維特徵,輸出13維特徵,最後再加上一層sigmoid啟用函數
訓練引數
| batch | 64 |
|---|---|
| epoch | 20 |
| optimizer (優化器) | SGD(隨機梯度下降) |
| criterion (損失函數) | BCELoss(二分類交叉熵損失) |
| 學習率 | 0.01 |
photo資料集上模型訓練Loss
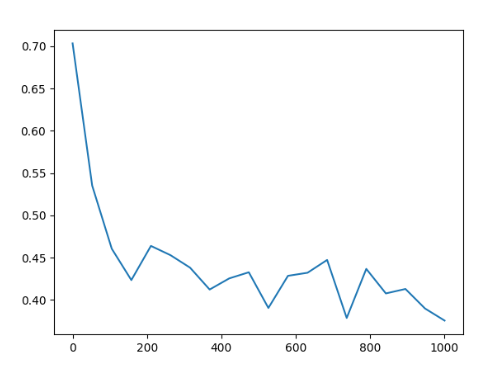
photo資料集結果 「方法二」
| f1 | precision | recall | accuracy | |
|---|---|---|---|---|
| hair | 0.926064 | 0.903045 | 0.950287 | 0.950287 |
| gender | 0.657874 | 0.657195 | 0.6587 | 0.6587 |
| earring | 0.744185 | 0.764809 | 0.821224 | 0.821224 |
| smile | 0.634135 | 0.63298 | 0.652008 | 0.652008 |
| frontal_face | 0.758024 | 0.694976 | 0.833652 | 0.833652 |
| hair_color | 0.498804 | 0.515916 | 0.546845 | 0.546845 |
| style | 0.508202 | 0.57917 | 0.482792 | 0.482792 |
| average | 0.715911 | 0.718511 | 0.743188 | 0.743188 |
Sketch資料集上模型訓練Loss
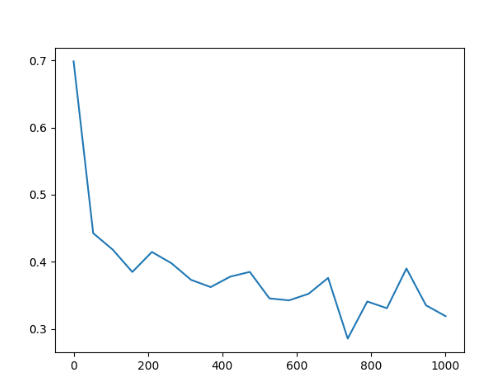
sketch資料集結果 「方法三」
| f1 | precision | recall | accuracy | |
|---|---|---|---|---|
| hair | 0.926064 | 0.903045 | 0.950287 | 0.950287 |
| gender | 0.811982 | 0.813721 | 0.814532 | 0.814532 |
| earring | 0.743495 | 0.720011 | 0.813576 | 0.813576 |
| smile | 0.573169 | 0.573085 | 0.614723 | 0.614723 |
| frontal_face | 0.758024 | 0.694976 | 0.833652 | 0.833652 |
| hair_color | 0.358576 | 0.339481 | 0.419694 | 0.419694 |
| style | 0.842575 | 0.942995 | 0.803059 | 0.803059 |
| average | 0.751736 | 0.748414 | 0.78119 | 0.78119 |
DenseNet121
模型結構引數
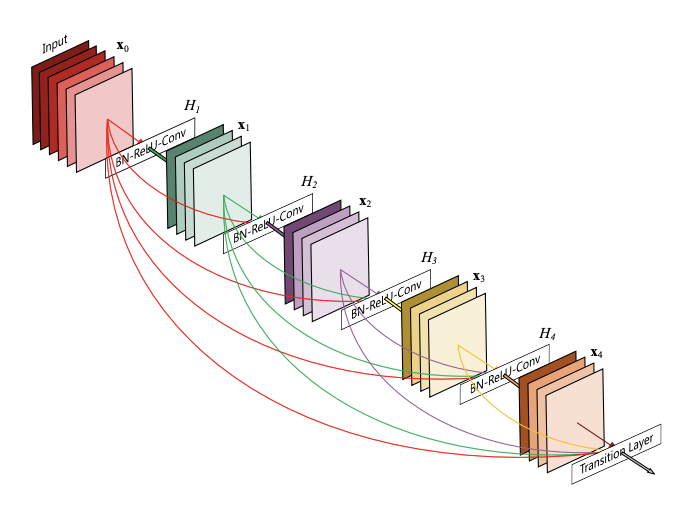
訓練引數
| batch | 64 |
|---|---|
| epoch | 20 |
| optimizer (優化器) | SGD(隨機梯度下降) |
| criterion (損失函數) | BCELoss(二分類交叉熵損失) |
| 學習率 | 0.01 |
photo資料集上模型訓練Loss
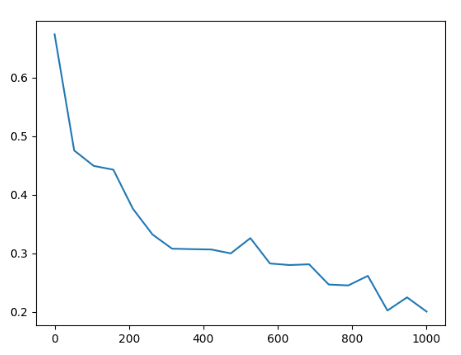
photo資料集結果 「方法四」
| f1 | precision | recall | accuracy | |
|---|---|---|---|---|
| hair | 0.926064 | 0.903045 | 0.950287 | 0.950287 |
| gender | 0.935669 | 0.936043 | 0.935946 | 0.935946 |
| earring | 0.837358 | 0.837194 | 0.853728 | 0.853728 |
| smile | 0.784984 | 0.787445 | 0.790631 | 0.790631 |
| frontal_face | 0.780436 | 0.832682 | 0.8413 | 0.8413 |
| hair_color | 0.685242 | 0.665904 | 0.718929 | 0.718929 |
| style | 0.515421 | 0.567896 | 0.497132 | 0.497132 |
| avg | 0.808147 | 0.816276 | 0.823494 | 0.823494 |
Sketch資料集上模型訓練Loss
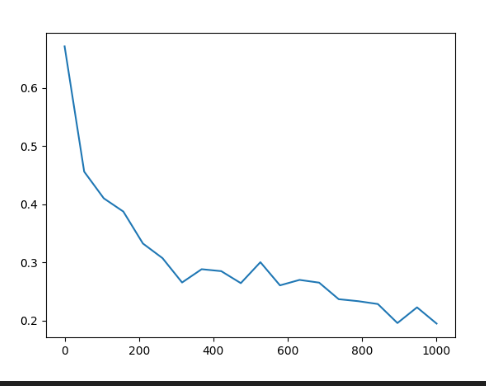
sketch資料集結果 「方法五」
| f1 | precision | recall | accuracy | |
|---|---|---|---|---|
| hair | 0.926064 | 0.903045 | 0.950287 | 0.950287 |
| gender | 0.883773 | 0.886639 | 0.885277 | 0.885277 |
| earring | 0.743196 | 0.734733 | 0.819312 | 0.819312 |
| smile | 0.610952 | 0.661847 | 0.671128 | 0.671128 |
| frontal_face | 0.758024 | 0.694976 | 0.833652 | 0.833652 |
| hair_color | 0.372596 | 0.360252 | 0.423518 | 0.423518 |
| style | 0.944535 | 0.96071 | 0.938815 | 0.938815 |
| avg | 0.779892 | 0.775275 | 0.815249 | 0.815249 |