幾百行程式碼實現一個 JSON 解析器

前言
之前在寫 gscript時我就在想有沒有利用編譯原理實現一個更實際工具?畢竟真寫一個語言的難度不低,並且也很難真的應用起來。
一次無意間看到有人提起 JSON 解析器,這類工具充斥著我們的日常開發,運用非常廣泛。
以前我也有思考過它是如何實現的,過程中一旦和編譯原理扯上關係就不由自主的勸退了;但經過這段時間的實踐我發現實現一個 JSON 解析器似乎也不困難,只是運用到了編譯原理前端的部分知識就完全足夠了。
得益於 JSON 的輕量級,同時語法也很簡單,所以核心程式碼大概只用了 800 行便實現了一個語法完善的 JSON 解析器。
首先還是來看看效果:
import "github.com/crossoverJie/gjson"
func TestJson(t *testing.T) {
str := `{
"glossary": {
"title": "example glossary",
"age":1,
"long":99.99,
"GlossDiv": {
"title": "S",
"GlossList": {
"GlossEntry": {
"ID": "SGML",
"SortAs": "SGML",
"GlossTerm": "Standard Generalized Markup Language",
"Acronym": "SGML",
"Abbrev": "ISO 8879:1986",
"GlossDef": {
"para": "A meta-markup language, used to create markup languages such as DocBook.",
"GlossSeeAlso": ["GML", "XML", true, null]
},
"GlossSee": "markup"
}
}
}
}
}`
decode, err := gjson.Decode(str)
assert.Nil(t, err)
fmt.Println(decode)
v := decode.(map[string]interface{})
glossary := v["glossary"].(map[string]interface{})
assert.Equal(t, glossary["title"], "example glossary")
assert.Equal(t, glossary["age"], 1)
assert.Equal(t, glossary["long"], 99.99)
glossDiv := glossary["GlossDiv"].(map[string]interface{})
assert.Equal(t, glossDiv["title"], "S")
glossList := glossDiv["GlossList"].(map[string]interface{})
glossEntry := glossList["GlossEntry"].(map[string]interface{})
assert.Equal(t, glossEntry["ID"], "SGML")
assert.Equal(t, glossEntry["SortAs"], "SGML")
assert.Equal(t, glossEntry["GlossTerm"], "Standard Generalized Markup Language")
assert.Equal(t, glossEntry["Acronym"], "SGML")
assert.Equal(t, glossEntry["Abbrev"], "ISO 8879:1986")
glossDef := glossEntry["GlossDef"].(map[string]interface{})
assert.Equal(t, glossDef["para"], "A meta-markup language, used to create markup languages such as DocBook.")
glossSeeAlso := glossDef["GlossSeeAlso"].(*[]interface{})
assert.Equal(t, (*glossSeeAlso)[0], "GML")
assert.Equal(t, (*glossSeeAlso)[1], "XML")
assert.Equal(t, (*glossSeeAlso)[2], true)
assert.Equal(t, (*glossSeeAlso)[3], "")
assert.Equal(t, glossEntry["GlossSee"], "markup")
}
從這個用例中可以看到支援字串、布林值、浮點、整形、陣列以及各種巢狀關係。
實現原理
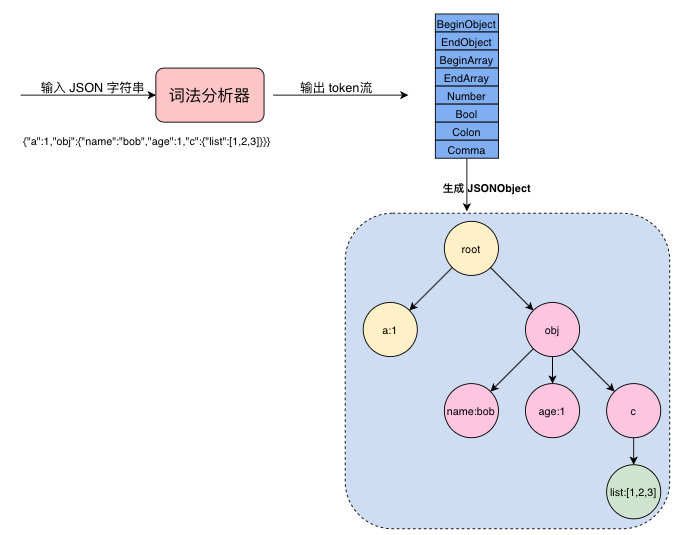
這裡簡要說明一下實現原理,本質上就是兩步:
- 詞法解析:根據原始輸入的
JSON字串解析出 token,也就是類似於"{" "obj" "age" "1" "[" "]"這樣的識別符號,只是要給這類識別符號分類。 - 根據生成的一組
token集合,以流的方式進行讀取,最終可以生成圖中的樹狀結構,也就是一個JSONObject。
下面來重點看看這兩個步驟具體做了哪些事情。
詞法分析
BeginObject {
String "name"
SepColon :
String "cj"
SepComma ,
String "object"
SepColon :
BeginObject {
String "age"
SepColon :
Number 10
SepComma ,
String "sex"
SepColon :
String "girl"
EndObject }
SepComma ,
String "list"
SepColon :
BeginArray [
其實詞法解析就是構建一個有限自動機的過程(DFA),目的是可以生成這樣的集合(token),只是我們需要將這些 token進行分類以便後續做語法分析的時候進行處理。
比如 "{" 這樣的左花括號就是一個 BeginObject 代表一個物件宣告的開始,而 "}" 則是 EndObject 代表一個物件的結束。
其中 "name" 這樣的就被認為是 String 字串,以此類推 "[" 代表 BeginArray
這裡我一共定義以下幾種 token 型別:
type Token string
const (
Init Token = "Init"
BeginObject = "BeginObject"
EndObject = "EndObject"
BeginArray = "BeginArray"
EndArray = "EndArray"
Null = "Null"
Null1 = "Null1"
Null2 = "Null2"
Null3 = "Null3"
Number = "Number"
Float = "Float"
BeginString = "BeginString"
EndString = "EndString"
String = "String"
True = "True"
True1 = "True1"
True2 = "True2"
True3 = "True3"
False = "False"
False1 = "False1"
False2 = "False2"
False3 = "False3"
False4 = "False4"
// SepColon :
SepColon = "SepColon"
// SepComma ,
SepComma = "SepComma"
EndJson = "EndJson"
)
其中可以看到 true/false/null 會有多個型別,這點先忽略,後續會解釋。
以這段 JSON 為例:{"age":1},它的狀態扭轉如下圖:
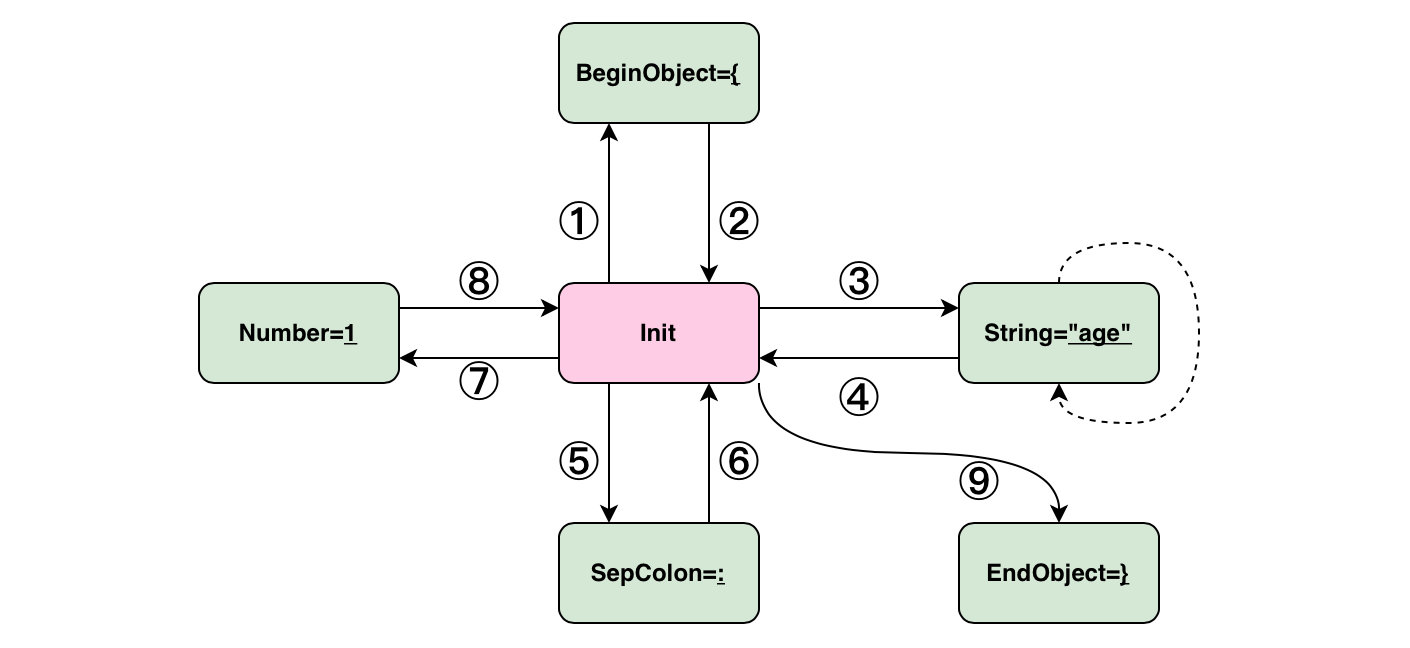
總的來說就是依次遍歷字串,然後更新一個全域性狀態,根據該狀態的值進行不同的操作。
部分程式碼如下:
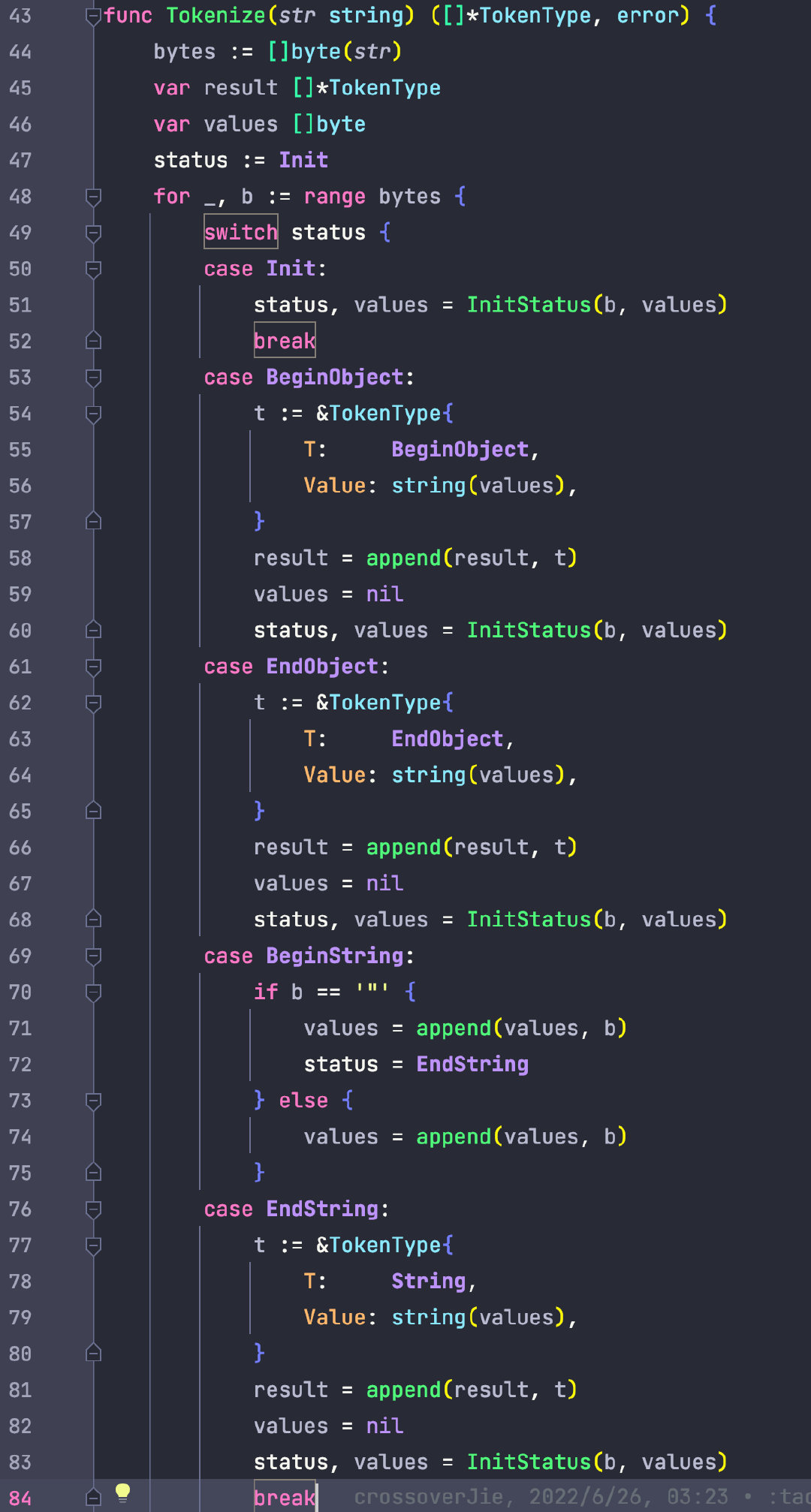

感興趣的朋友可以跑跑單例 debug 一下就很容易理解:
https://github.com/crossoverJie/gjson/blob/main/token_test.go
以這段 JSON 為例:
func TestInitStatus(t *testing.T) {
str := `{"name":"cj", "age":10}`
tokenize, err := Tokenize(str)
assert.Nil(t, err)
for _, tokenType := range tokenize {
fmt.Printf("%s %s\n", tokenType.T, tokenType.Value)
}
}
最終生成的 token 集合如下:
BeginObject {
String "name"
SepColon :
String "cj"
SepComma ,
String "age"
SepColon :
Number 10
EndObject }
提前檢查
由於 JSON 的語法簡單,一些規則甚至在詞法規則中就能校驗。
舉個例子:
JSON 中允許 null 值,當我們字串中存在 nu nul 這類不匹配 null 的值時,就可以提前丟擲異常。
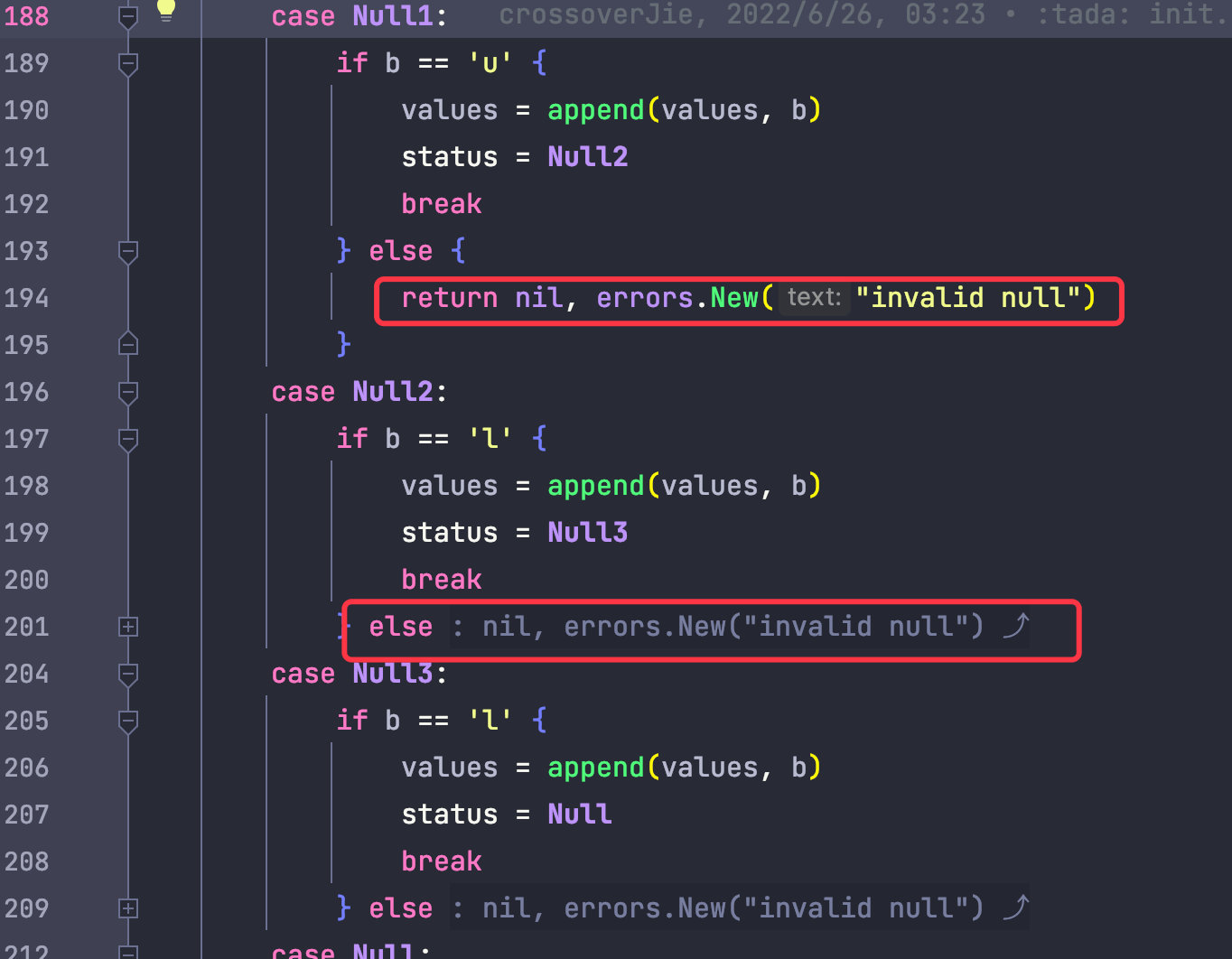
比如當檢測到第一個字串為 n 時,那後續的必須為 u->l->l 不然就丟擲異常。
浮點數同理,當一個數值中存在多個 . 點時,依然需要丟擲異常。
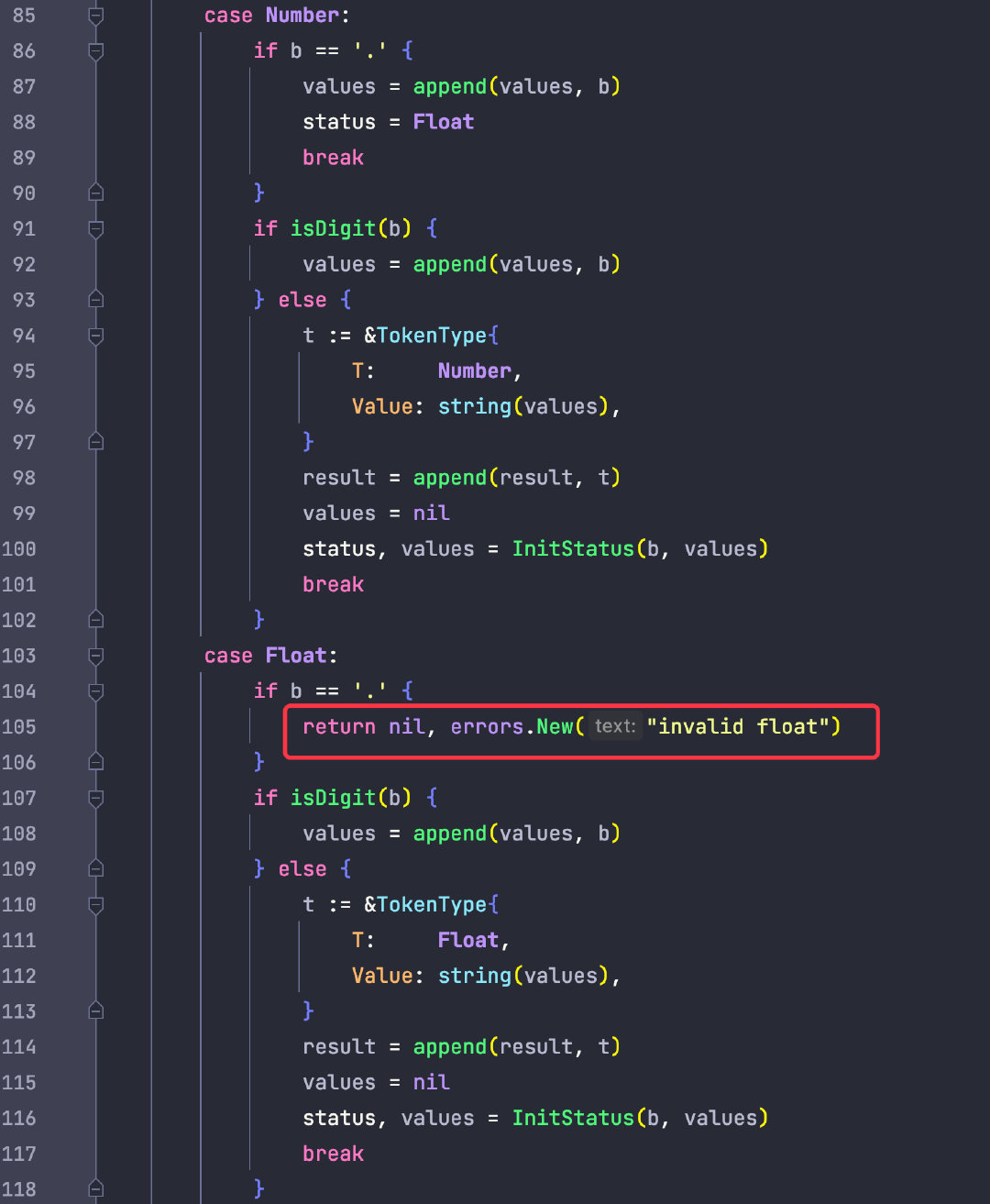
這也是前文提到 true/false/null 這些型別需要有多箇中間狀態的原因。
生成 JSONObject 樹
在討論生成 JSONObject 樹之前我們先來看這麼一個問題,給定一個括號集合,判斷是否合法。
[<()>]這樣是合法的。[<()>)而這樣是不合法的。
如何實現呢?其實也很簡單,只需要利用棧就能完成,如下圖所示:
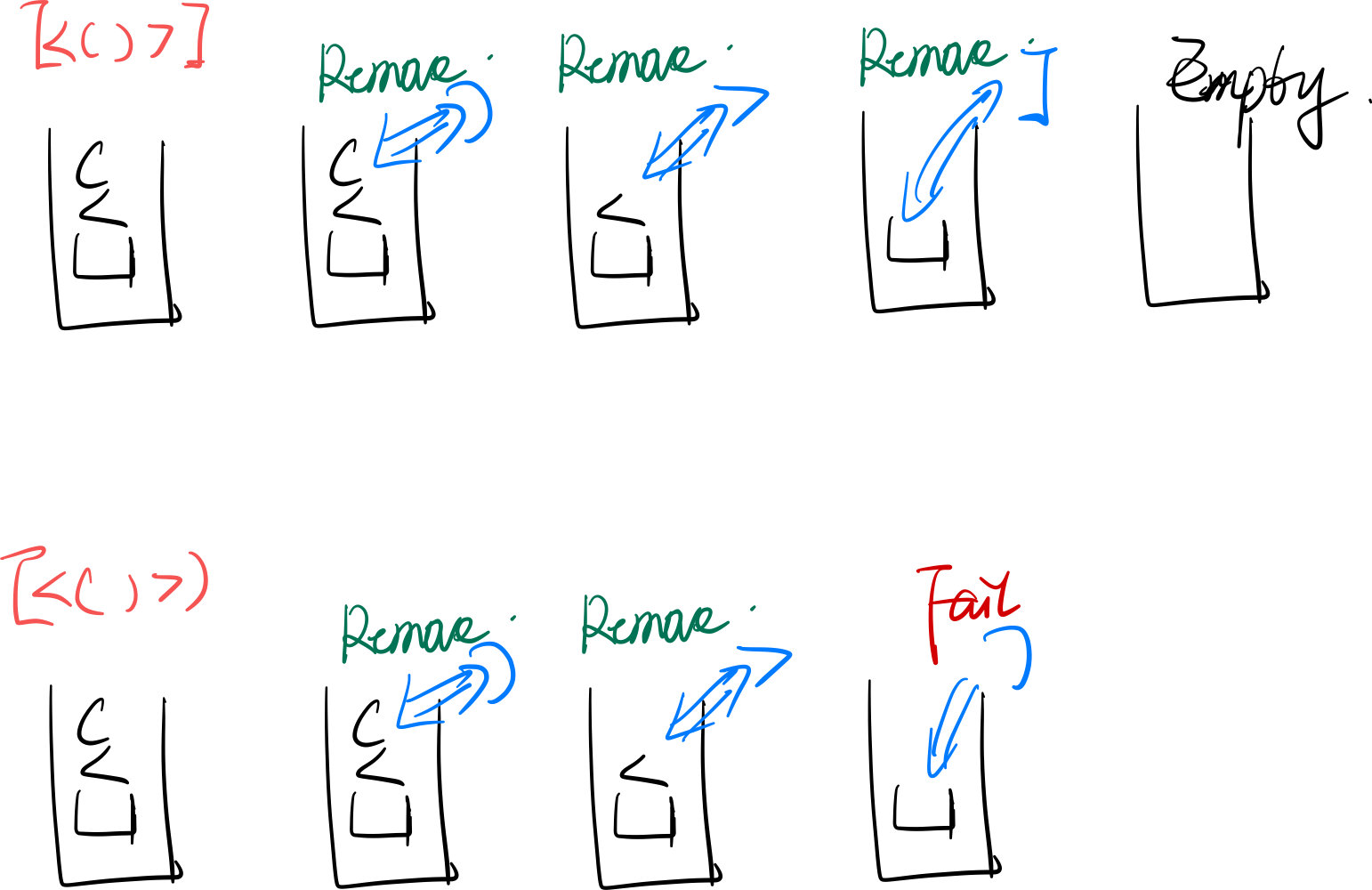
利用棧的特性,依次遍歷資料,遇到是左邊的符號就入棧,當遇到是右符號時就與棧頂資料匹配,能匹配上就出棧。
當匹配不上時則說明格式錯誤,資料遍歷完畢後如果棧為空時說明資料合法。
其實仔細觀察 JSON 的語法也是類似的:
{
"name": "cj",
"object": {
"age": 10,
"sex": "girl"
},
"list": [
{
"1": "a"
},
{
"2": "b"
}
]
}
BeginObject:{ 與 EndObject:} 一定是成對出現的,中間如論怎麼巢狀也是成對的。
而對於 "age":10 這樣的資料,: 冒號後也得有資料進行匹配,不然就是非法格式。
所以基於剛才的括號匹配原理,我們也能用類似的方法來解析 token 集合。
我們也需要建立一個棧,當遇到 BeginObject 時就入棧一個 Map,當遇到一個 String 鍵時也將該值入棧。
當遇到 value 時,就將出棧一個 key,同時將資料寫入當前棧頂的 map 中。
當然在遍歷 token 的過程中也需要一個全域性狀態,所以這裡也是一個有限狀態機。
舉個例子:當我們遍歷到 Token 型別為 String,值為 "name" 時,預期下一個 token 應當是 :冒號;
所以我們得將當前的 status 記錄為 StatusColon,一旦後續解析到 token 為 SepColon 時,就需要判斷當前的 status 是否為 StatusColon ,如果不是則說明語法錯誤,就可以丟擲異常。
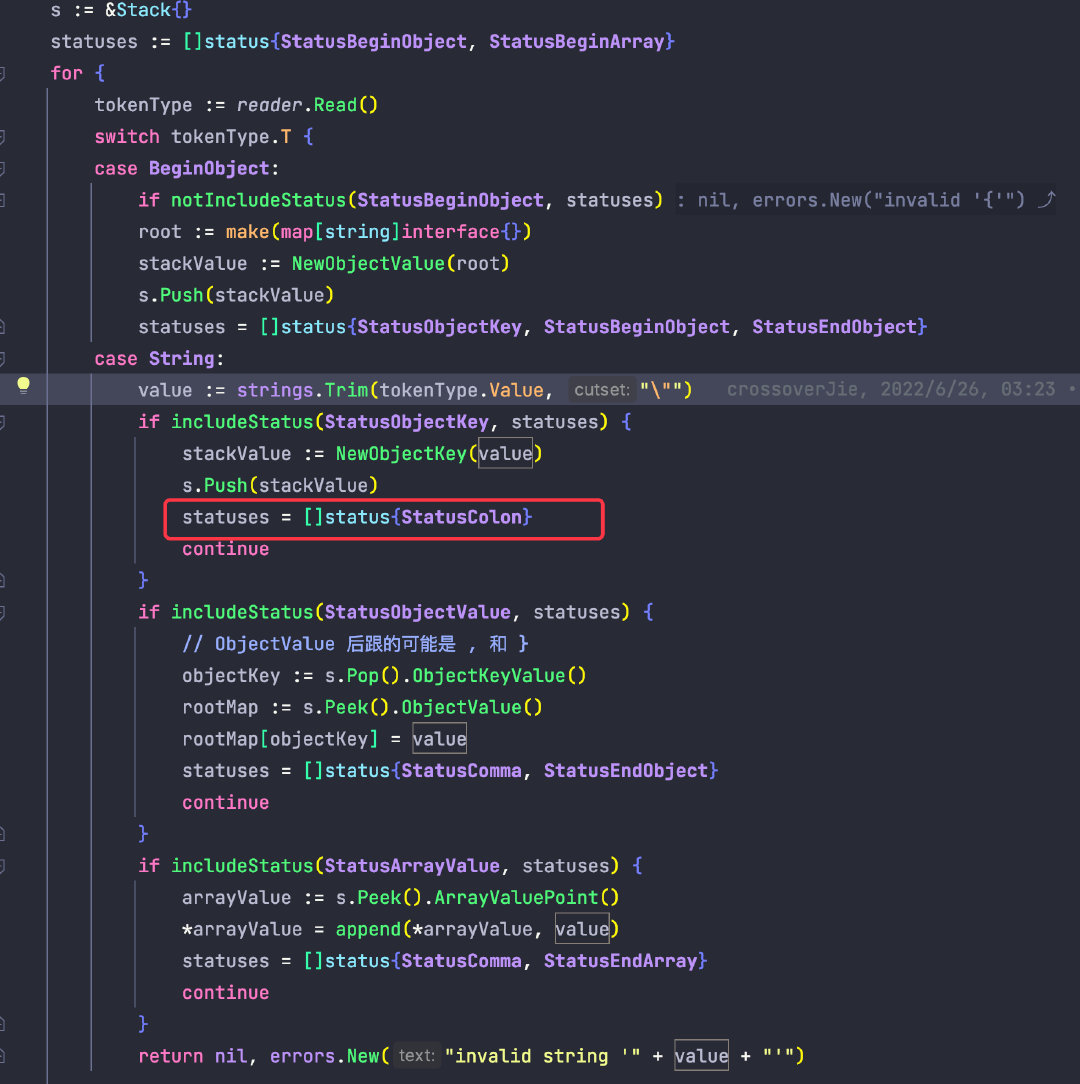

同時值得注意的是這裡的 status 其實是一個集合,因為下一個狀態可能是多種情況。
{"e":[1,[2,3],{"d":{"f":"f"}}]}
比如當我們解析到一個 SepColon 冒號時,後續的狀態可能是 value 或 BeginObject { 或 BeginArray [

因此這裡就得把這三種情況都考慮到,其他的以此類推。
具體解析過程可以參考原始碼:
https://github.com/crossoverJie/gjson/blob/main/parse.go
雖然是藉助一個棧結構就能將 JSON 解析完畢,不知道大家發現一個問題沒有:
這樣非常容易遺漏規則,比如剛才提到的一個冒號後面就有三種情況,而一個 BeginArray 後甚至有四種情況(StatusArrayValue, StatusBeginArray, StatusBeginObject, StatusEndArray)
這樣的程式碼讀起來也不是很直觀,同時容易遺漏語法,只能出現問題再進行修復。
既然提到了問題那自然也有相應的解決方案,其實就是語法分析中常見的遞迴下降演演算法。
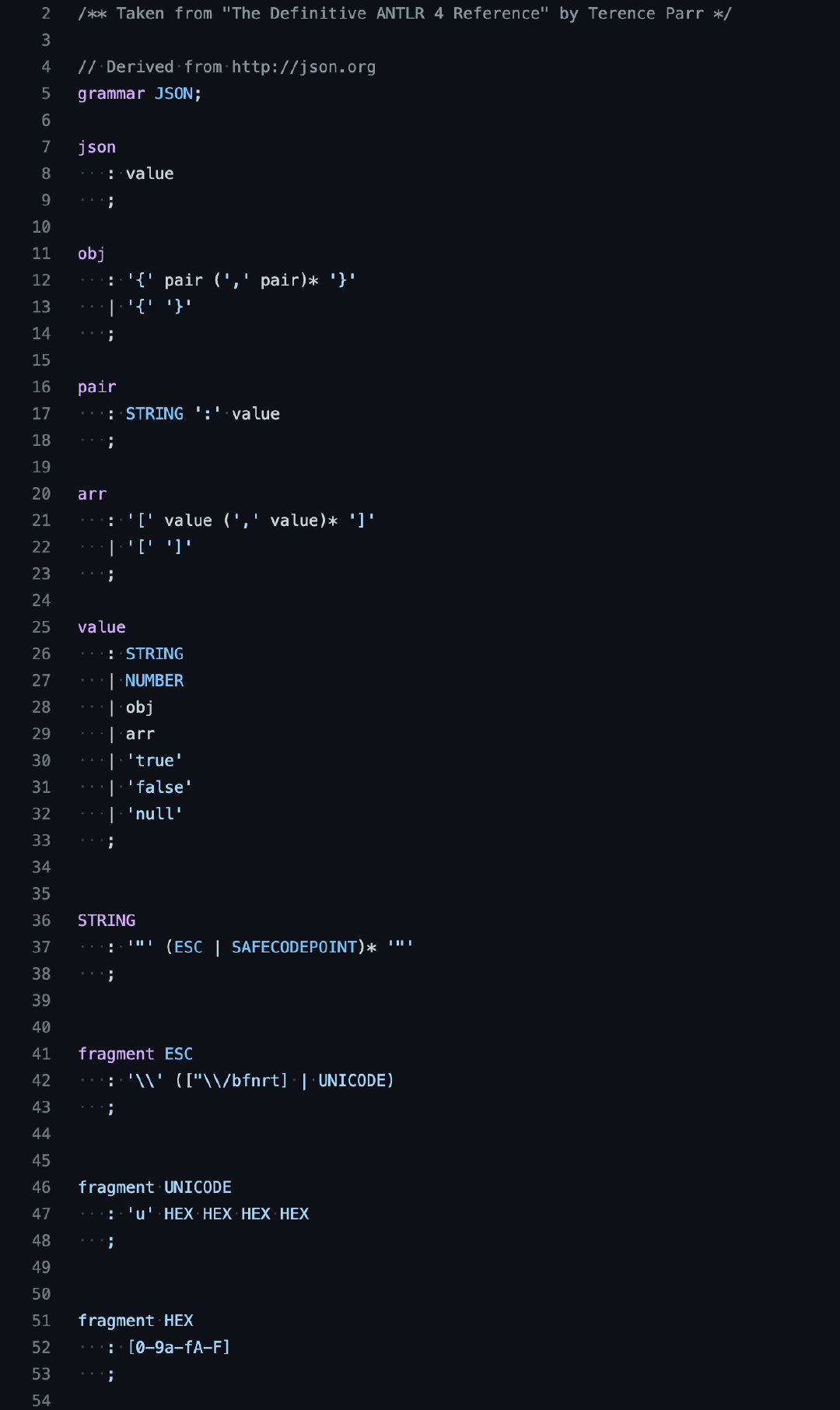
我們只需要根據 JSON 的文法定義,遞迴的寫出演演算法即可,這樣程式碼閱讀起來非常清晰,同時也不會遺漏規則。
完整的 JSON 語法檢視這裡:
https://github.com/antlr/grammars-v4/blob/master/json/JSON.g4
我也預計將下個版本改為遞迴下降演演算法來實現。
總結
當目前為止其實只是實現了一個非常基礎的 JSON 解析,也沒有做效能優化,和官方的 JSON 包對比效能差的不是一星半點。
cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
BenchmarkJsonDecode-12 372298 15506 ns/op 512 B/op 12 allocs/op
BenchmarkDecode-12 141482 43516 ns/op 30589 B/op 962 allocs/op
PASS
同時還有一些基礎功能沒有實現,比如將解析後的 JSONObject 可以反射生成自定義的 Struct,以及我最終想實現的支援 JSON 的四則運算:
gjson.Get("glossary.age+long*(a.b+a.c)")
目前我貌似沒有發現有類似的庫實現了這個功能,後面真的完成後應該會很有意思,感興趣的朋友請持續關注。
作者: crossoverJie

歡迎關注博主公眾號與我交流。
本文版權歸作者所有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出, 如有問題, 可郵件(crossoverJie#gmail.com)諮詢。