簡單ELK設定實現生產級別的紀錄檔採集和查詢實踐
概述
生產問題
- 叢集規模如何規劃?
- 叢集中節點角色如何規劃?
- 叢集之腦裂問題如何避免?
- 索引分片如何規劃?
- 分片副本如何規劃?
叢集規劃
- 準備條件
- 先估算當前系統的資料量和資料增長趨勢情況。
- 現有伺服器的設定如CPU、記憶體、磁碟型別和容量的瞭解。
- 建議設定
- ElasticSearch推薦的最大JVM堆空間是30~32G,一般可以設定為30Gheap ,大概能處理的資料量 10 T。單個索引資料量建議不超過5T,如果有100T資料量可以部署20個節點。
- 官方建議:節點分片最好按照JVM記憶體來進行計算,每Gb記憶體可以為20個分片,假設我們的JVM設定為30G,那麼分片資料量最大600個。如果分片數量就是非常多,那麼整個叢集分片數量最好不要超過10萬。
- 叢集規劃滿足當前資料規模+一定估算適量增長規模,後續再按需擴充套件即可。
- 業務場景
- 用於構建垂直領域的搜尋的業務搜尋功能,一般的資料量級幾千萬到數十億量級,需要部署3-5臺ES節點的規模。
- 用於大規模資料的實時OLAP(聯機處理分析),經典的如ELK Stack,資料規模可能達到千億或更多,這是可能需要幾十到上百ES節點的規模。
叢集角色
ES為了處理大型資料集,實現容錯和高可用性,ES可執行多伺服器組成分散式環境下也稱為叢集;叢集內的節點的cluster.name相同,形成叢集的每個伺服器稱為節點。ES 為分配不同的任務,定義了以下幾個節點角色:Master,Data Node,Coordinating Node,Ingest Node:
-
主節點(Master Node):主要職責是負責叢集層面的相關操作,管理叢集變更,如建立或刪除索引,跟蹤哪些節點是群集的一部分,並決定哪些分片分配給相關的節點。
- 主節點也可作為資料節點,但穩定的主節點對叢集的健康是非常重要的,預設情況下任何一個叢集中的節點都有可能被選為主節點,索引資料和搜尋查詢等操作會佔用大量的cpu、記憶體、io資源,為了確保叢集穩定,特別是非小型規模的叢集(如10臺以內)分離主節點和資料節點是推薦做法。
- 通過設定node.master:true(預設)使節點具有被選舉為Master的資格。主節點全域性唯一併從有資格成為Master的節點中選舉。
# 設定如下,後續所有節點設定可以通過這三個切換設定 node.master: true node.data: false node.ingest: false -
資料節點(Data Node):主要是儲存索引資料的節點,執行資料相關操作:CRUD、搜尋,聚合操作等。
- 資料節點對cpu,記憶體,I/O要求較高, 在優化的時候需要監控資料節點的狀態,當資源不夠的時候,需要在叢集中新增新的節點。
- 通過設定node.data: true(預設來是一個節點成為資料節點)。
-
預處理節點(Ingest Node):預處理操作執行在索引檔案之前,即寫入資料之前,通過事先定義好的一系列processors(處理器)和pipeline(管道),對資料進行某種轉換。
- processors和pipeline攔截bulk和index請求,在應用相關操作後將檔案傳回給index或bulk API。
- 如果想在某個節點上禁用ingest,則可以設定node.ingest: false。
-
協調節點(Coordinating Node):作為處理使用者端請求的節點,只作為接收請求、轉發請求到其他節點、彙總各個節點返回資料等功能的節點;使用者端請求可以傳送到叢集的任何節點(每個節點都知道任意檔案的位置),節點轉發請求並收集資料返回給使用者端。
- 協調節點將請求轉發給儲存資料的資料節點,每個資料節點則先在本地執行請求,並將結果返回給協調節點。協調節點收集完每個節點的資料後將結果合併為單個全域性結果,在這過程中的結果收集和排序可能需要很多CPU和記憶體資源。
- 上述三個節點角色設定為false則為協調節點。
一個節點可以充當一個或多個角色,預設三個角色都有。
- 叢集角色建議設定
- 小規模叢集,基本不需嚴格區分。
- 中大規模叢集(十個以上節點),應考慮單獨的角色充當。特別並行查詢量大,查詢的合併量大,可以增加獨立的協調節點。角色分開的好處是分工明確,互不影響。
腦裂問題
所謂腦裂問題,就是同一個叢集中的不同節點,對於叢集的狀態有了不一樣的理解,比如叢集中存在兩個master,正常情況下我們叢集中只能有一個master節點。如果因為網路的故障,導致一個叢集被劃分成了兩片,每片都有多個node,以及一個master,那麼叢集中就出現了兩個master了。但是因為master是叢集中非常重要的一個角色,主宰了叢集狀態的維護,以及shard的分配,因此如果有兩個master,可能會導致資料異常
- 建議設定
- 至少設定3個節點為主節點。
- Master 和 dataNode 角色分開,設定奇數個master,如3 、5、7。
- 新增最小數量的主節點設定,在elasticsearch.yml中設定屬性:discovery.zen.minimum_master_nodes,這個引數作用是告訴es直到有足夠的master候選節點支援時,才可以選舉出一個master,否則就不要選舉出一個master。官方的推薦值公式為:master候選資格節點數量 / 2 + 1,並在所有有資格成為master的節點都需要加上這個設定。例如在3個節點,三臺主節點通過在elasticsearch.yml中設定discovery.zen.minimum_master_nodes: 2,就可以避免腦裂問題的產生。
索引分片
分片數指定後不可變,除非重索引,分片對應的儲存實體是索引,分片並不是越多越好,分片多浪費儲存空間、佔用資源、影響效能。
- 分片過多的影響:
- 每個分片本質上就是一個Lucene索引, 因此會消耗相應的檔案控制程式碼, 記憶體和CPU資源。
- 每個搜尋請求會排程到索引的每個分片中. 如果分片分散在不同的節點倒是問題不太. 但當分片開始競爭相同的硬體資源時, 效能便會逐步下降。
- ES使用詞頻統計來計算相關性. 當然這些統計也會分配到各個分片上. 如果在大量分片上只維護了很少的資料, 則將導致最終的檔案相關性較差。
- 建議設定
- 每個分片處理資料量建議在30G-50G,如果是商品類搜尋場景推薦使用低值30G,然後再對分片數量做合理估算. 例如資料能達到200GB, 推薦分片最多分配5-7分片左右。
- 開始階段也可先根據節點數量按照1.5~3倍的原則來建立分片. 例如,如果你有3個節點, 則推薦你建立的分片數最多不超過9(3x3)個。當效能下降時,增加節點,ES會平衡分片的放置。
- 對於基於日期的索引需求, 並且對索引資料的搜尋場景非常少. 也許這些索引量將達到成百上千, 但每個索引的資料量只有1GB甚至更小. 對於這種類似場景, 建議只需要為索引分配1個分片。如紀錄檔管理就是一個日期的索引需求,日期索引會很多,但每個索引存放的紀錄檔資料量就很少。
分片副本
副本數是可以隨時調整的,副本的作用是備份資料保證高可用資料不丟失,高並行的時候參與資料查詢。
- 建議設定
- 一般一個分片有1-2個副本即可保證高可用,副本過多浪費儲存空間、佔用資源和影響效能。
- 要求叢集至少要有3個節點,來分開存放主分片、副本。如發現並行量大時,查詢效能會下降,可增加副本數,來提升並行查詢能力;新增副本時主節點會自動協調,然後拷貝資料到新增的副本節點。
ElasticSearch部署
部署規劃
這裡我們部署一個3個節點組成的ES叢集,因此也不單獨分節點型別部署,三臺伺服器分別為192.168.5.52 es-node-01、192.168.5.53 es-node-02、192.168.12.27 es-node-03,作業系統版本為CentOS 7.8。
部署方式
官網支援二進位制部署,也支援使用Docker和K8S部署方式,這裡我們使用二進位制部署方式,使用最新版本8.2.3
# 官方下載
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.2.3-linux-x86_64.tar.gz
# 三臺伺服器都準備好安裝包,進行解壓
tar -xvf elasticsearch-8.2.3-linux-x86_64.tar.gz
# 進入ES目錄,ES安裝包已自帶的JDK17,無需單獨下載安裝JDK
前置設定
在每一臺伺服器上先做下面環境設定
- 建立使用者(基於安全考慮ES預設不能用root啟動)
# 建立es使用者
useradd es
# 授權es使用者
chown -R es:es elasticsearch-8.2.3
- 調整程序最大開啟檔案數數量
vim /etc/security/limits.conf
# 直接末尾新增限制
es soft nofile 65536
es hard nofile 65536
- 調整程序最大虛擬記憶體區域數量
echo vm.max_map_count=262144>> /etc/sysctl.conf
sysctl -p
- 防火牆設定,我這裡就簡單停掉防火牆,線上環境則根據埠進行相應防火牆規則設定
systemctl stop firewalld
systemctl disable firewalld
- 新增伺服器名解析
cat > /etc/hosts << EOF
192.168.5.52 es-node-01
192.168.5.53 es-node-02
192.168.12.27 es-node-03
EOF
組態檔
先建立logs和data目錄;ES的叢集名稱設定一樣es-cluster,三臺ES節點的node.name分別為 es-node-01、es-node-02、es-node-03,network.host設定為各自本機的IP地址。修改組態檔資訊為如下vi config/elasticsearch.yml
cluster.name: es-cluster
node.name: es-node-01
node.attr.rack: r1
path.data: /home/commons/elasticsearch-8.2.3/data
path.logs: /home/commons/elasticsearch-8.2.3/logs
network.host: 192.168.5.52
discovery.seed_hosts: ["192.168.5.52", "192.168.5.53", "192.168.12.27"]
cluster.initial_master_nodes: ["192.168.5.52", "192.168.5.53","192.168.12.27"]
xpack.security.enabled: false
xpack.security.transport.ssl.enabled: false
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,X-Requested-With,Content-Type,Content-Length
啟動
# 依次啟動三臺伺服器的ES服務
./bin/elasticsearch -d
存取3臺伺服器9200埠,http://192.168.5.52:9200/ ,如果都看到如下資訊則代表ES啟動成功
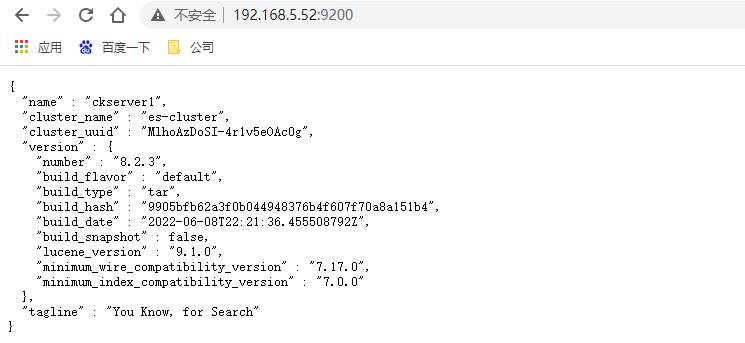
再次檢視叢集的健康狀態,http://192.168.5.52:9200/_cat/health

Kibana部署
下載
Kibana的版本與ES版本保持一致,也是使用最新的8.2.3。我們在192.168.5.52上部署
# Kibana下載
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.2.3-linux-x86_64.tar.gz
# 解壓檔案
tar -xvf kibana-8.2.3-linux-x86_64.tar.gz
# 授權
chown -R es:es kibana-8.2.3
# 進入Kibana的目錄
cd kibana-8.2.3
設定
vim config/kibana.yml
# 直接再末尾新增以下設定
# 伺服器地址
server.host: "0.0.0.0"
# ES服務IP
elasticsearch.hosts: ["http://192.168.5.52:9200/"]
# 設定中文
i18n.locale: "zh-CN"
啟動
# 後臺啟動kibana
nohup ./bin/kibana > logs/kibana.log 2>&1 &
存取Kibana控制檯頁面,http://192.168.5.52:5601/
部署IK分詞器
預設分詞器是不支援中文分詞,我們可以安裝IK分詞器實現中文的分詞
# IK分詞器在GitHub上,下載最新版本8.2.0
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.2.0/elasticsearch-analysis-ik-8.2.0.zip
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.2.0/elasticsearch-analysis-ik-8.2.0.zip
# 解壓到elasticsearch目錄下的plugins/ik目錄
unzip elasticsearch-analysis-ik-8.2.0.zip -d ./plugins/ik
由於ik的版本與ES版本不一致,修改解壓目錄到ik下的 plugin-descriptor.properties 檔案中的
elasticsearch.version=8.2.3

如果版本一致也可以直接線上安裝
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.2.0/elasticsearch-analysis-ik-8.2.0.zip
ES索引管理
索引宣告週期策略
- ES可用於索引紀錄檔類資料,在此場景下,資料是源源不斷地被寫入到索引中。為了使索引的檔案不會過多,查詢的效能更好,我們希望索引可以根據大小、檔案數量或索引已建立時長等指標進行自動回滾,可以自定義將超過一定時間的資料進行自動刪除。ES為我們提供了索引的生命週期管理來幫助處理此場景下的問題。
- 索引的生命週期分為四個階段:HOT->WARM->COLD->DELETE。
- Hot:索引可寫入,也可查詢。
- Warm:索引不可寫入,但可查詢。
- Cold:索引不可寫入,但很少被查詢,查詢的慢點也可接受。
- Delete:索引可被安全的刪除。
- 索引的每個生命週期階段都可以設定不同的個階段都可以設定不同的
轉化行為(Action)。下面我們看下幾個常用的Action:- Rollover 當寫入索引達到了一定的大小,檔案數量或建立時間時,Rollover可建立一個新的寫入索引,將舊的寫入索引的別名去掉,並把別名賦給新的寫入索引。所以便可以通過切換
別名控制寫入的索引是誰。它可用於Hot階段。 - Shrink 減少一個索引的主分片數,可用於
Warm階段。需要注意的是當shink完成後索引名會由原來的<origin-index-name>變為shrink-<origin-index-name>. - Force merge 可觸發一個索引分片的segment merge,同時釋放掉被刪除檔案的佔用空間。用於
Warm階段。 - Allocate 可指定一個索引的副本數,用於
warm, cold階段。
- Rollover 當寫入索引達到了一定的大小,檔案數量或建立時間時,Rollover可建立一個新的寫入索引,將舊的寫入索引的別名去掉,並把別名賦給新的寫入索引。所以便可以通過切換
- HOT為必須的階段外,其他為非必須階段,可以任意選擇設定。在紀錄檔類場景下不需要WARN和COLD階段,下文只設定了HOT與DELETE階段。
設定索引生命週期策略和索引模板即可以通過Kibana視覺化介面設定也可以通過ES提供的Rest API介面進行設定,我們先通過Kibaba頁面來設定,首先通過點選左側選單的Management-Stack Management,然後左側選單再點選索引生命週期策略
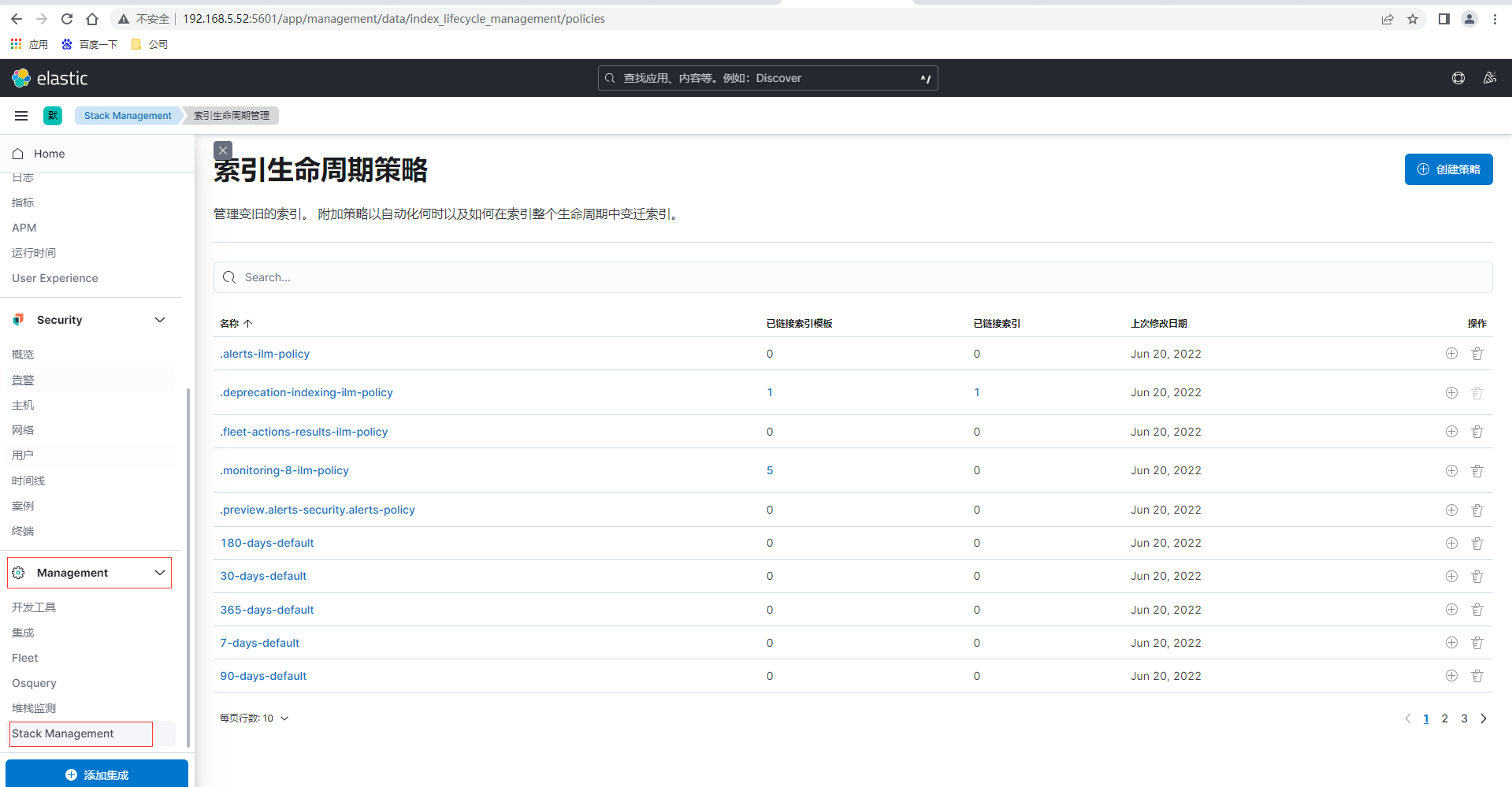
點選索引生命週期策略頁面的右上角建立策略
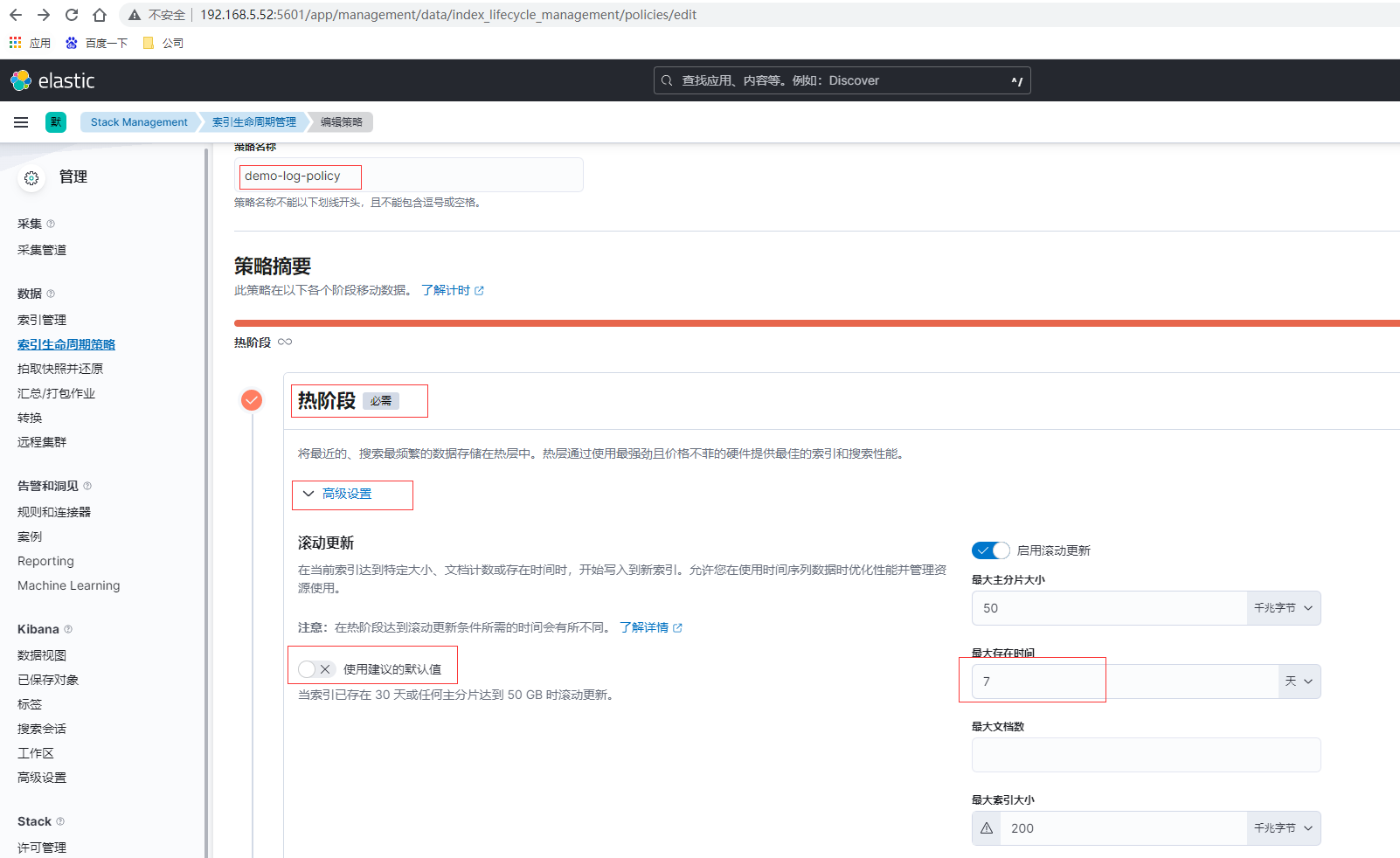
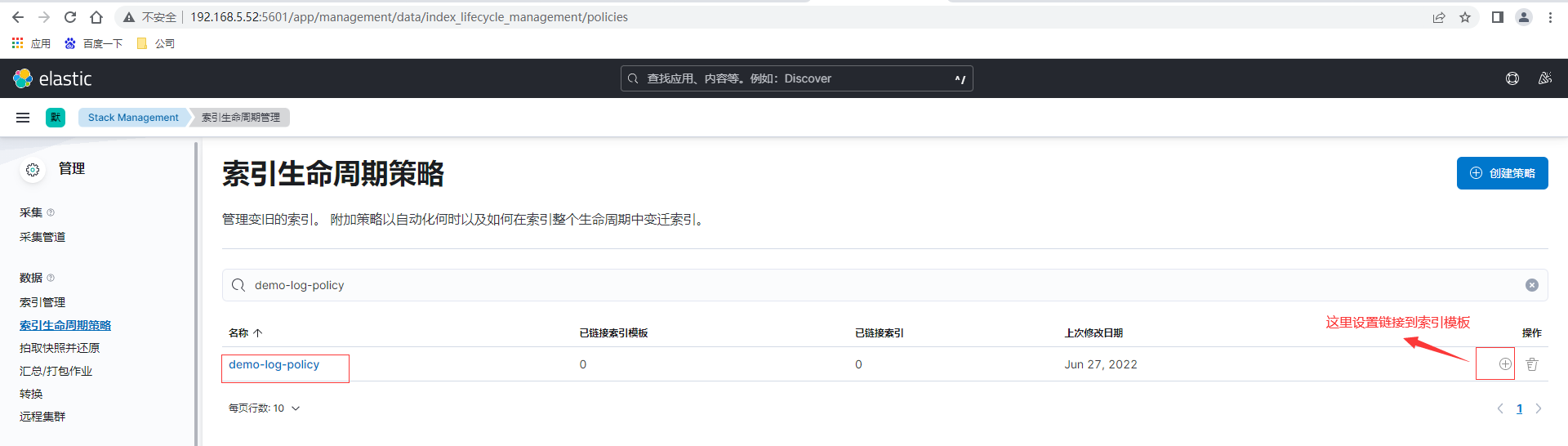
這裡如果是測試可以將存在時間設定為分鐘級別,便於觀察,建立完畢後檢視剛建立的demo-log-policy
也可以通過ES提供的Rest API介面進行設定,通過Kibana點選左側選單的Management-開發工具進入控制檯tab頁,然後輸入如下生命週期設定策略,返回結果
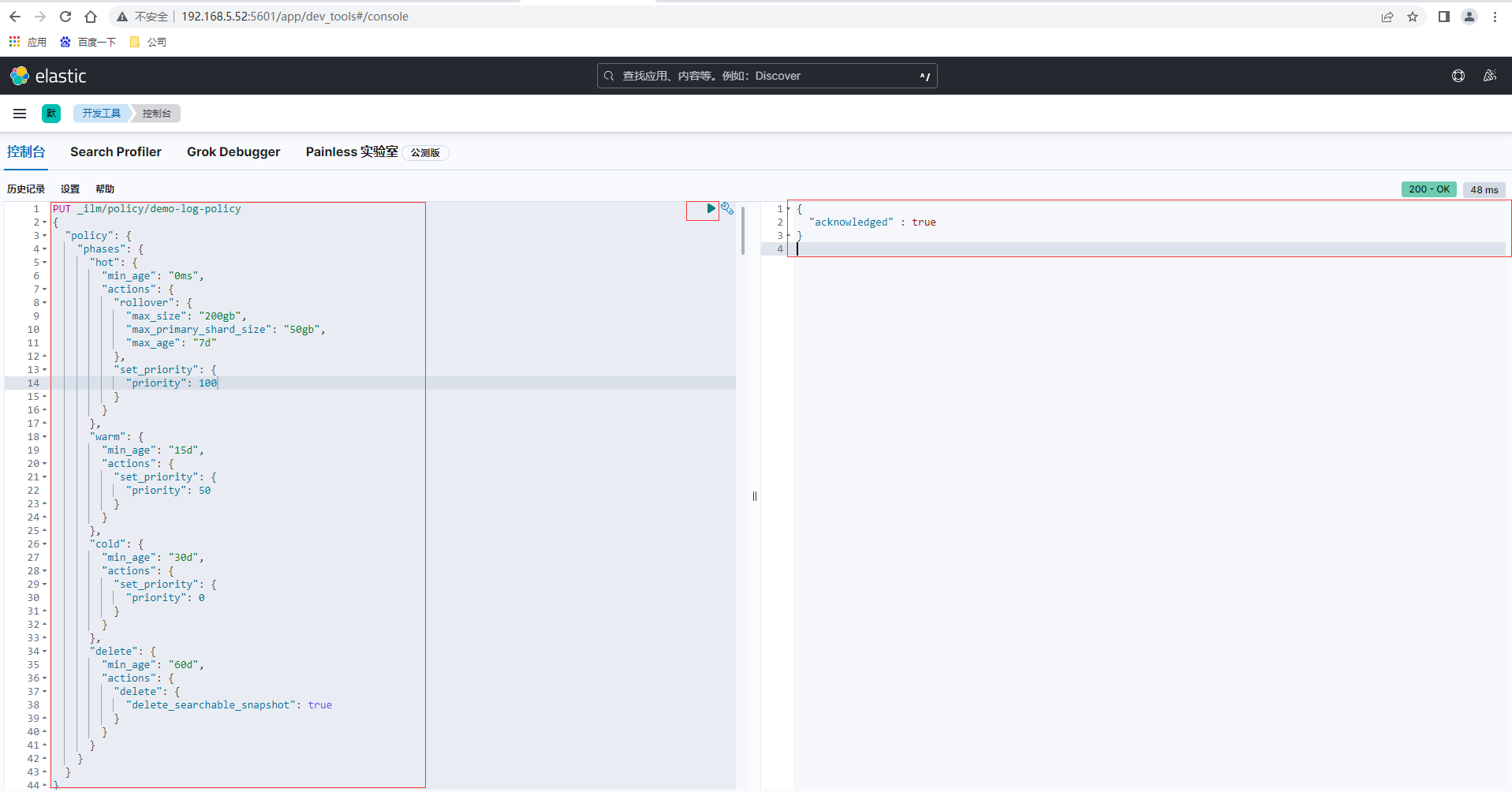
PUT _ilm/policy/demo-log-policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_size": "200gb",
"max_primary_shard_size": "50gb",
"max_age": "7d"
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "15d",
"actions": {
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"set_priority": {
"priority": 0
}
}
},
"delete": {
"min_age": "60d",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}
索引模板
點選索引管理-索引模板,建立模板
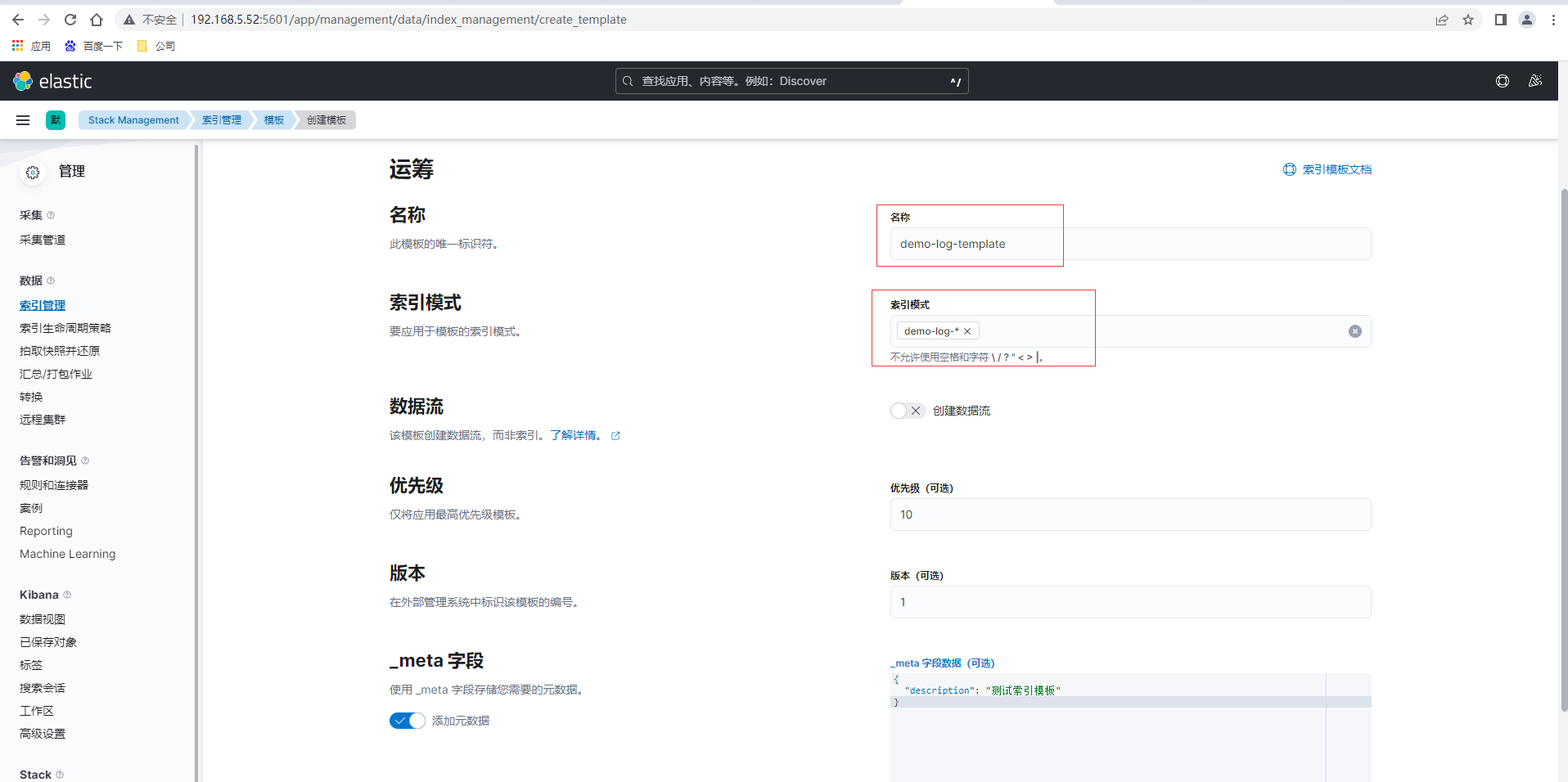
驗證模板後提交檢視已建立的模板,建立完成後可以通過在索引宣告週期系結模板,也可以直接在模板裡增加繫結語句設定
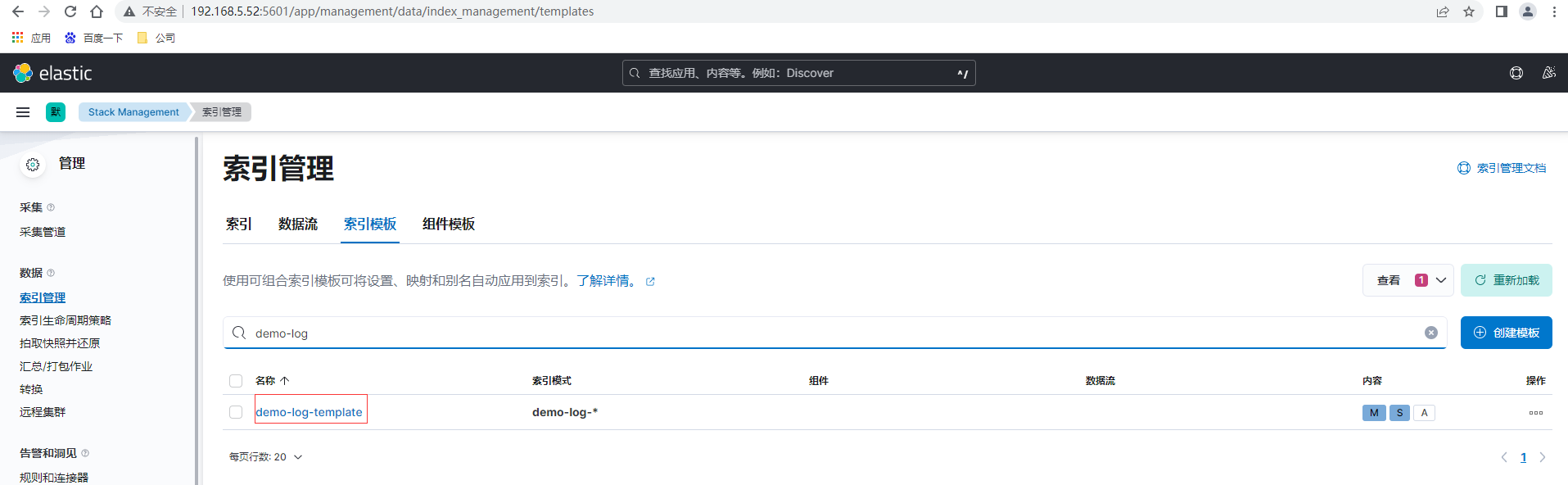
當然也可以通過ES提供的Rest API介面進行設定
PUT _index_template/demo-log-template
{
"version": 1,
"priority": 10,
"template": {
"settings": {
"index": {
"lifecycle": {
"name": "demo-log-policy",
"rollover_alias": "demo-log"
},
"number_of_shards": "2",
"number_of_replicas": "1"
}
},
"mappings": {
"_source": {
"excludes": [],
"includes": [],
"enabled": true
},
"_routing": {
"required": false
},
"dynamic": true,
"numeric_detection": false,
"date_detection": true,
"dynamic_date_formats": [
"strict_date_optional_time",
"yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z"
],
"dynamic_templates": []
}
},
"index_patterns": [
"demo-log-*"
],
"_meta": {
"description": "測試索引模板"
}
}
索引
先建立初始索引
PUT demo-log-000001
{
"aliases": {
"demo-log": {
"is_write_index": true
}
}
}
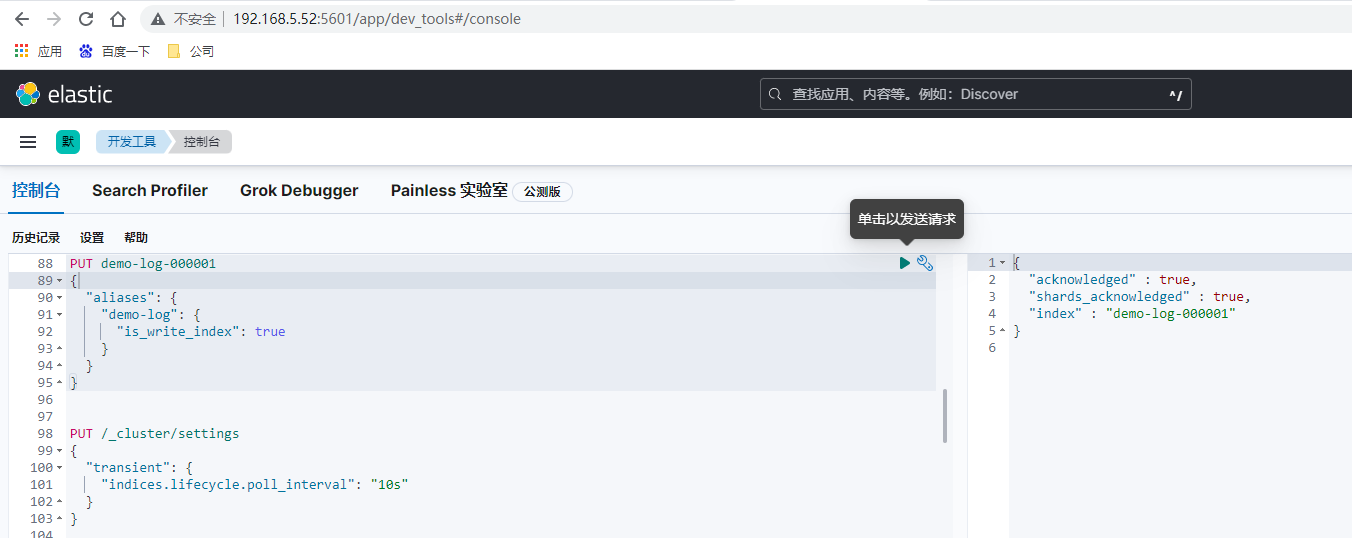
如果前面索引生命週期模板的各個週期保留時間設定較短如為分鐘,手動提交紀錄檔到索引和檢視,需要實時檢視其效果則可以增加如下設定和演示操作
PUT /_cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval": "10s"
}
}
POST /demo-log/_doc
{
"message":"world2"
}
GET /demo-log/_search
{
"query": {
"match_all": {}
}
}
Logstash
修改設定和啟動,vi config/logstash.conf
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://192.168.5.52:9200","http://192.168.5.53:9200","http://192.168.12.27:9200"]
index => "%{app_id}"
}
}
FileBeat
FileBeat和Logstash部署和設定可以詳細檢視前面的文章《數倉選型必列入考慮的OLAP列式資料庫ClickHouse(中)》,修改設定和啟動, parsers.multiline實現多行合併一行設定,比如Java異常堆疊紀錄檔列印合並在一行。
vi filebeat.yml
filebeat.inputs:
- type: filestream
id: demo-log
enabled: true
paths:
# Filebeat處理檔案的絕對路徑
- /home/itxs/demo/logs/*.log
# 使用 fields 模組新增欄位
fields:
app_id: demo-log
# 將新增的欄位放在頂級
fields_under_root: true
parsers:
- multiline:
type: pattern
pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}'
negate: true
match: after
processors:
- drop_fields:
fields: ["log","input","agent","ecs"]
output.logstash:
hosts: ["192.168.12.28:5044"]
採集/home/itxs/demo/logs/目錄的資料,由App產生紀錄檔,然後通過Kibana的資料檢視-建立資料檢視,匹配我們前面建立的索引和別名
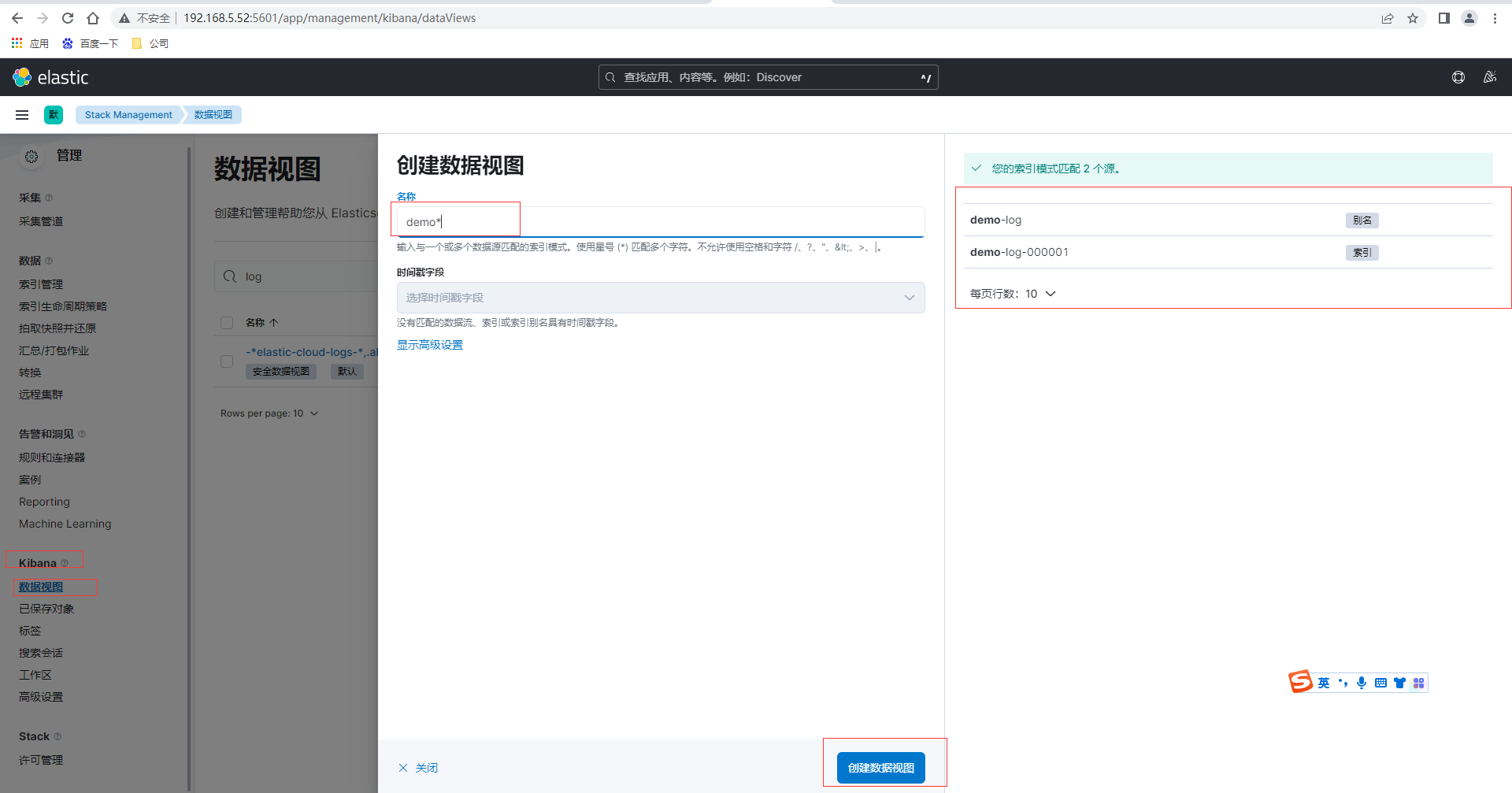
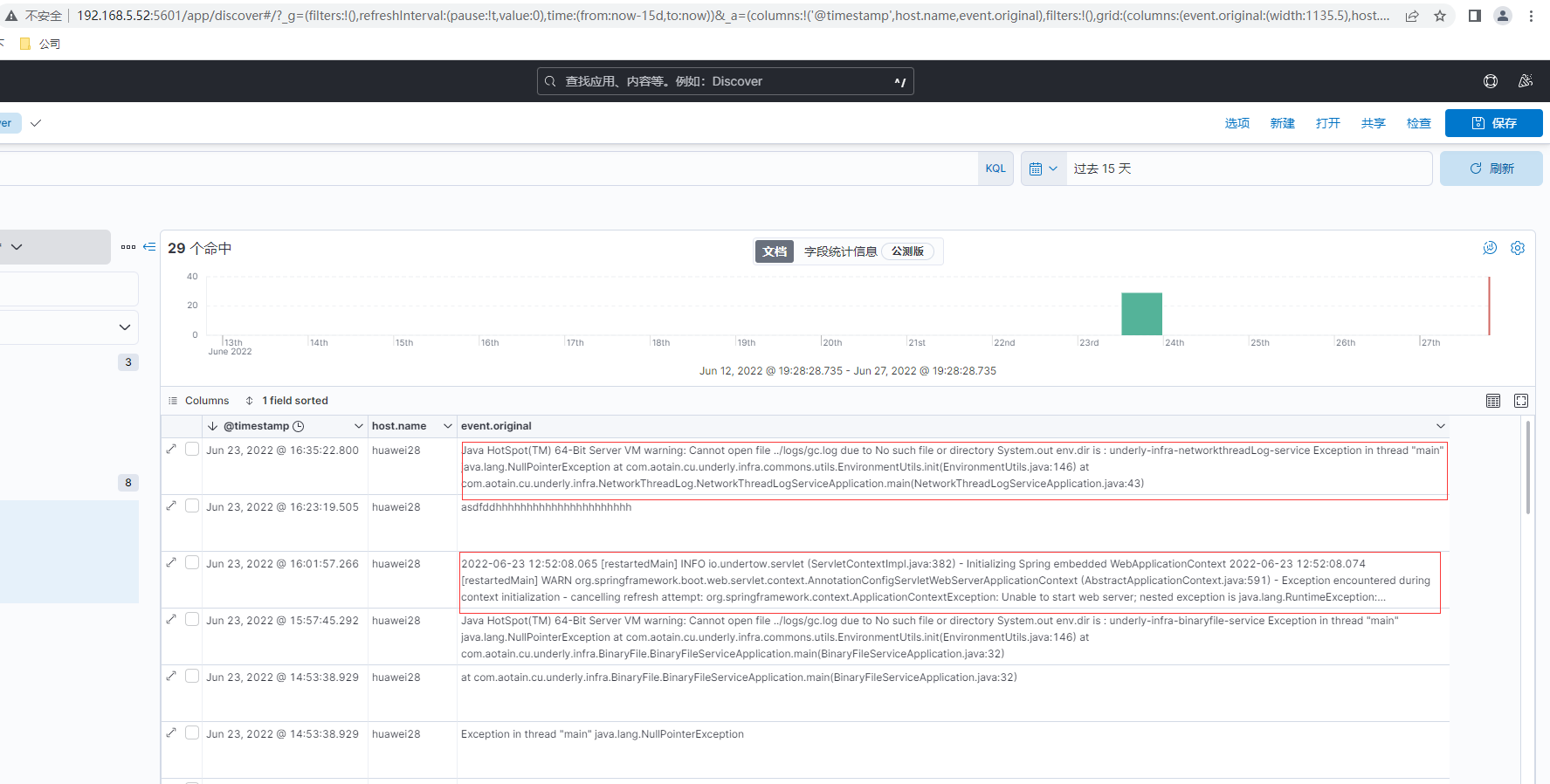
最後通過Kibana左側選單的Analytics-Discover選擇demo檢視然後可以搜尋紀錄檔,最後紀錄檔查詢結果如下
**本人部落格網站 **IT小神 www.itxiaoshen.com