【系統設計】鄰近服務
在本文中,我們將設計一個鄰近服務,用來發現使用者附近的地方,比如餐館,酒店,商場等。
設計要求
從一個小明去面試的故事開始。

面試官:你好,我想考察一下你的設計能力,如果讓你設計一個鄰近服務,用來搜尋使用者附近的商家,你會怎麼做?
小明:好的,使用者可以指定搜尋半徑嗎?如果搜尋範圍內沒有足夠的商家,系統是否支援擴大搜尋範圍?
面試官:對,使用者可以根據需要修改,大概有以下幾個選項,0.5km,1km,2km,5km,10km,20km。
小明:嗯,還有其他的系統要求嗎?
面試官:另外還需要考慮的是,系統的低延遲,高可用,和可延伸性,以及資料隱私。
小明:好的,瞭解了。
總結一下,需要做一個鄰近服務,可以根據使用者的位置(經度和緯度)以及搜尋半徑返回附近的商家,半徑可以修改。因為使用者的位置資訊是敏感資料,我們可能需要遵守資料隱私保護法。
高層次設計
高層次設計圖如下所示,系統包括兩部分:基於位置的服務 (location-based service)LBS 和業務(bussiness)相關的服務。
讓我們來看看系統的每個元件。
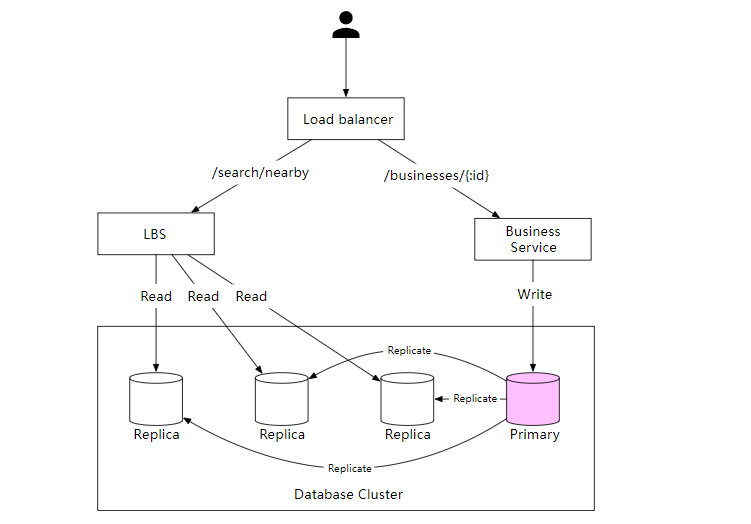
負載均衡器
負載均衡器可以根據路由把流量分配給多個後端服務。
基於位置的服務 (LBS)
LBS 服務是系統的核心部分,通過位置和半徑尋找附近的商家。LBS 具有以下特點:
- 沒有寫請求,但是有大量的查詢
- QPS 很高,尤其是在密集地區的高峰時段。
- 服務是無狀態的,支援水平擴充套件。
Business 服務
商戶建立,更新,刪除商家資訊,以及使用者檢視商家資訊。
資料庫叢集
資料庫叢集可以使用主從設定,提升可用性和效能。資料首先儲存到主資料庫,然後複製到從庫,主資料庫處理所有的寫入操作,多個從資料庫用於讀取操作。
接下來,我們具體討論位置服務 LBS 的實現。
1. 二維搜尋
這種方法簡單,有效,根據使用者的位置和搜尋半徑畫一個圓,然後找到圓圈內的所有商家,如下所示。
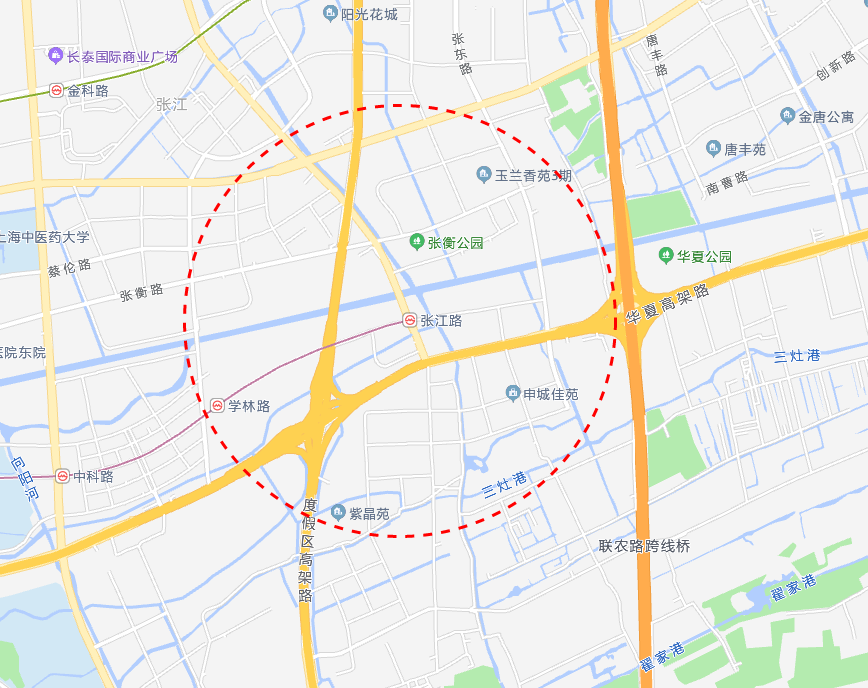
商家的緯度用 latitude 表示,經度用 longitude 表示。同樣的使用者的緯度和經度可以用 user_latitude 和 user_longitude 表示,半徑用 radius 表示。
上面的搜尋過程可以翻譯成下面的偽 SQL 。
SELECT business_id, latitude, longitude,
FROM business
WHERE
latitude >= (@user_latitude - radius) AND latitude < (@user_latitude + radius)
AND
longitude >= (@user_longitude - radius) AND longitude < (@user_longitude + radius)
這種方式可以實現我們的需求,但是實際上效率不高,因為我們需要掃描整個表。雖然我們可以對經緯度建立索引,效率有提升,但是並不夠,我們還需要對索引的結果計算取並集。
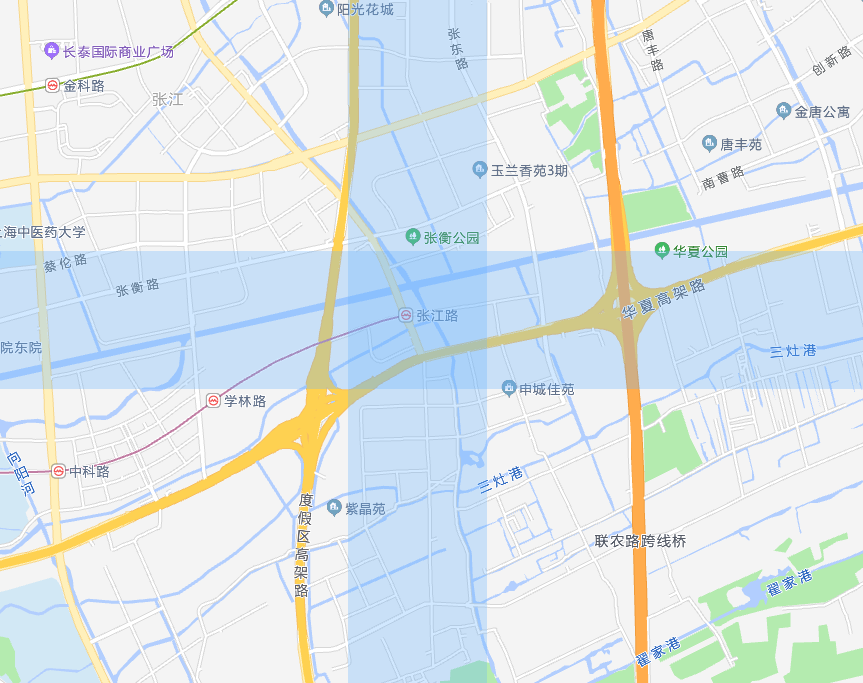
2. Geohash
我們上面說了,二維的經度和緯度做索引的效果並不明顯。而 Geohash 可以把二維的經度和緯度轉換為一維的字串,通過演演算法,每增加一位就遞迴地把世界劃分為越來越小的網格,讓我們來看看它是如何實現的。
首先,把地球通過本初子午線和赤道分成四個象限,如下
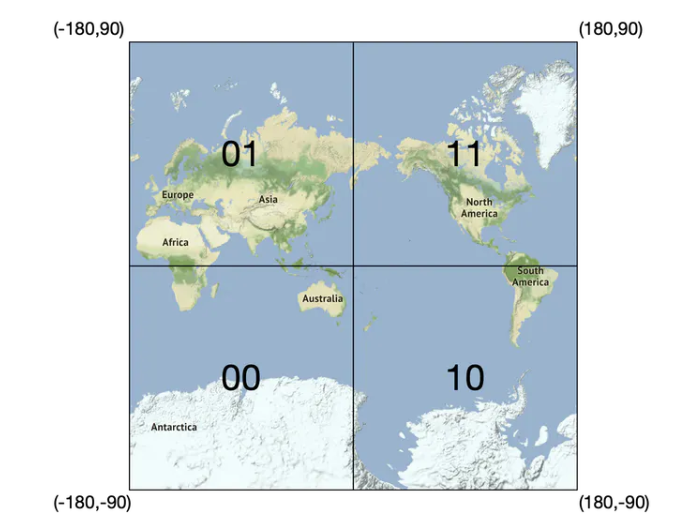
- 緯度範圍 [-90, 0] 用 0 表示
- 緯度範圍 [0, 90] 用 1 表示
- 經度範圍 [-180, 0] 用 0 表示
- 經度範圍 [0, 180] 用 1 表示
然後,再把每個網格分成四個小網格。
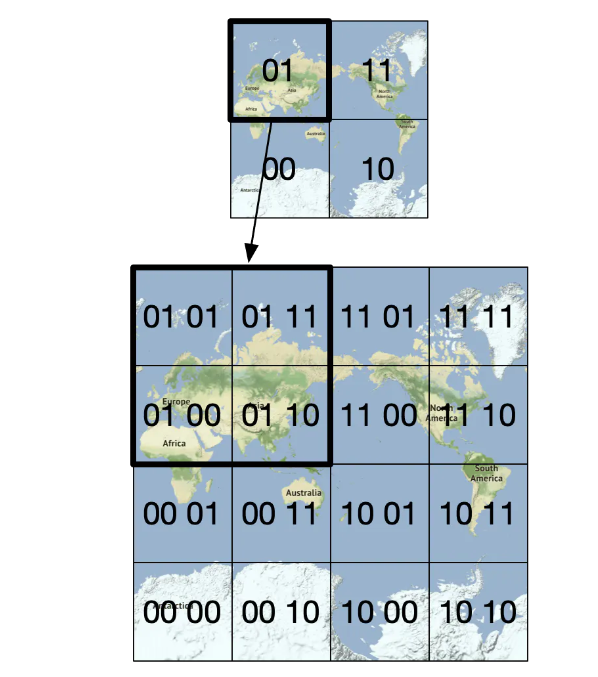
重複這個過程,直到網格的大小符合我們的需求,Geohash 通常使用 base32 表示。讓我們看兩個例子。
-
Google 總部的 Geohash(長度為 6):
1001 10110 01001 10000 11011 11010 (base32 convert) → 9q9hvu (base32) -
Facebook 總部的 Geohash(長度 為 6):
1001 10110 01001 10001 10000 10111 (base32 convert) → 9q9jhr (base32)
Geohash 有 12 個精度(也稱為級別), 它可以控制每個網格的大小,字串越長,拆分的網格就越小,如下

實際中,按照具體的場景選擇合適的 Geohash 精度。
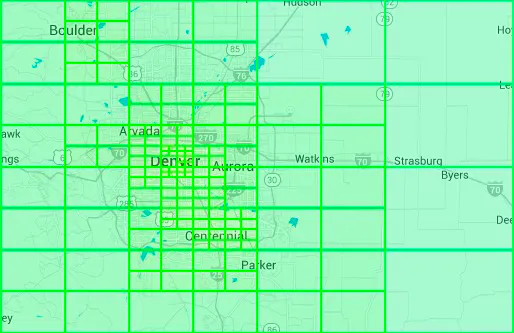
通過這種方式,最終把地圖分成了下面一個個小的網格,一個 Geohash 字串就表示了一個網格,這樣查詢每個網格內的商家資訊,搜尋是非常高效的。
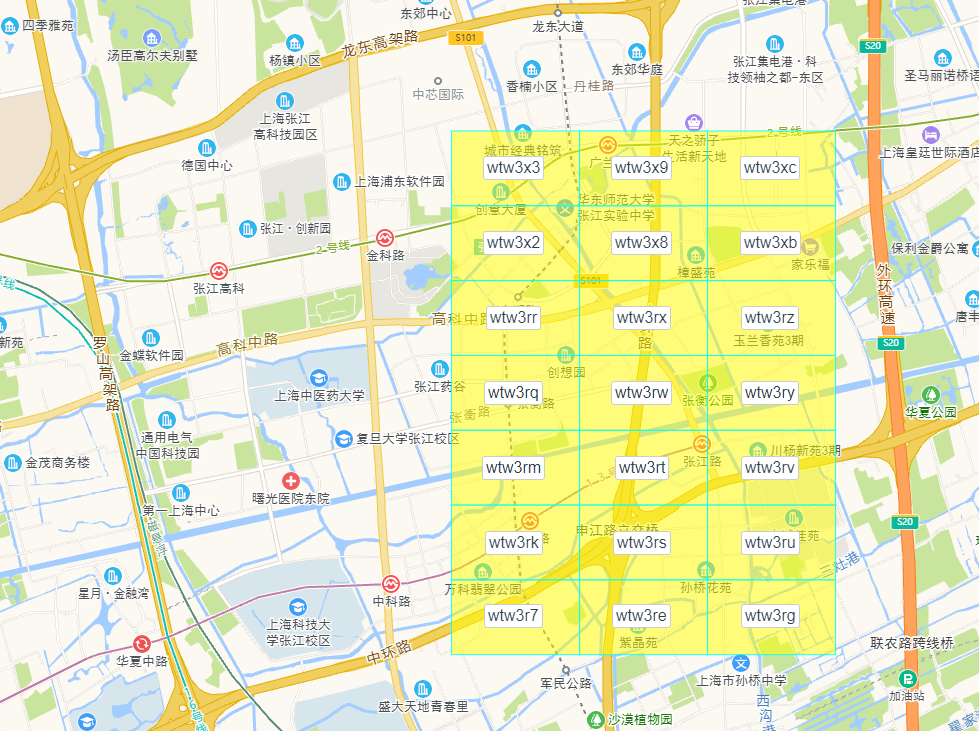
可能你已經發現了一些規律,上圖的每個網格中,它們都相同的字首 wtw3。是的,Geohash 的特點是,兩個網格的相同字首部分越長,就表示它們的位置是鄰近的。
反過來說,兩個相鄰的網格,它們的 Geohash 字串一定是相似的嗎?
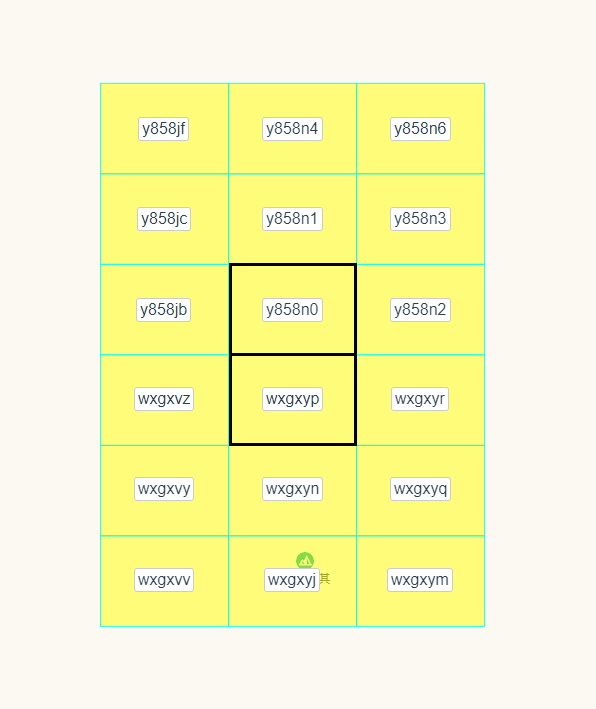
不一定,因為存在 邊界問題。當兩個網格都在邊緣時,雖然它們是相鄰的,但是 Geohash 的值從第一位就不一樣,如下圖,兩個紫色的點相鄰。
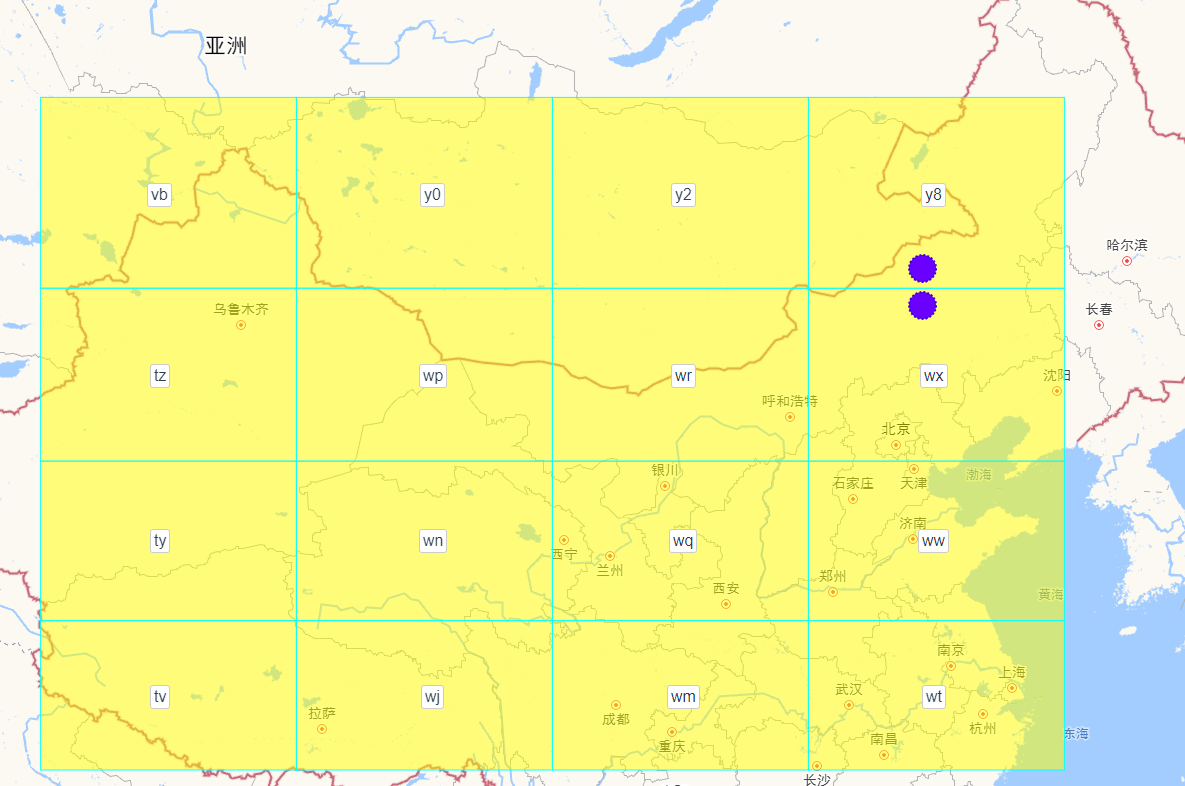
下面是一個精度比較高的網格,有些相鄰網格的 Geohash 的值是完全不一樣的。
還有一個邊界問題是,對於使用者(橙色)來說,隔壁網格的商家(紫色)可能比自己網格的商家(紫色)的距離還要近,如下圖
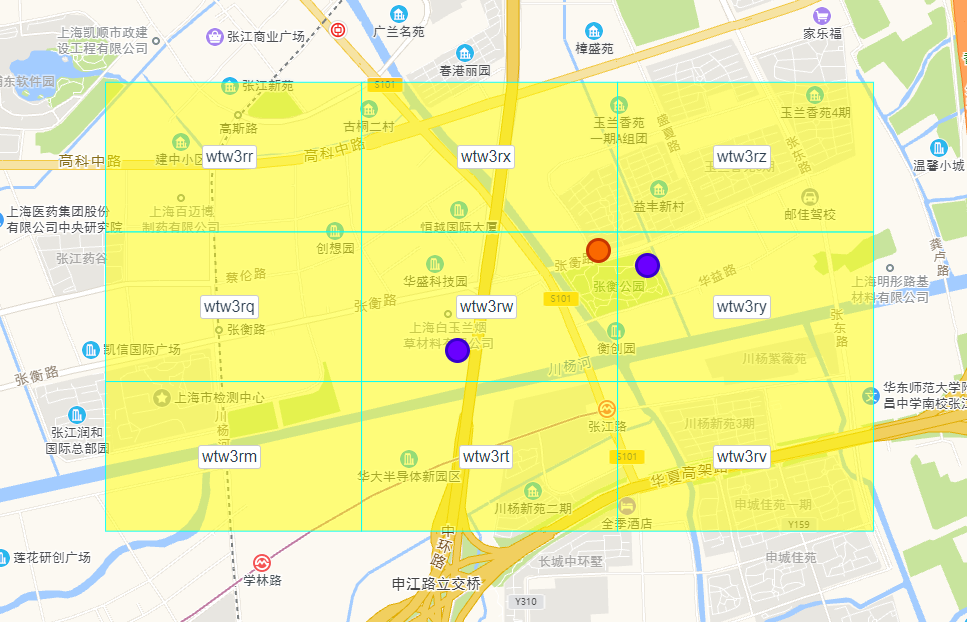
所以,在查詢附近的商家時,不能只侷限於使用者所在的網格,要擴大到使用者相鄰的4個或者9個網格,然後再計算距離,進行篩選,最終找到距離合適的商家。
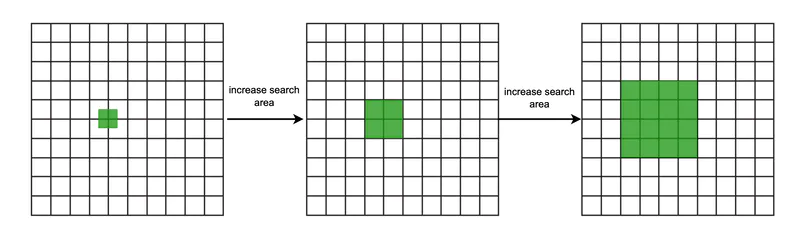
另外,當在使用者在偏遠的郊區時,我們可以按照下面的方式,擴大搜尋範圍,返回足夠數量的商家。
Geohash 的使用非常廣泛的,另外 Redis 和 MongoDB 都提供了相應的功能,可以直接使用。
3 . 四元樹
還有一種比較流行的解決方案是四元樹,這種方法可以遞迴地把二維空間劃分為四個象限,直到每個網格的商家數量都符合要求。
如下圖,比如確保每個網格的數量不超過10,如果超過,就拆分為四個小的網格。
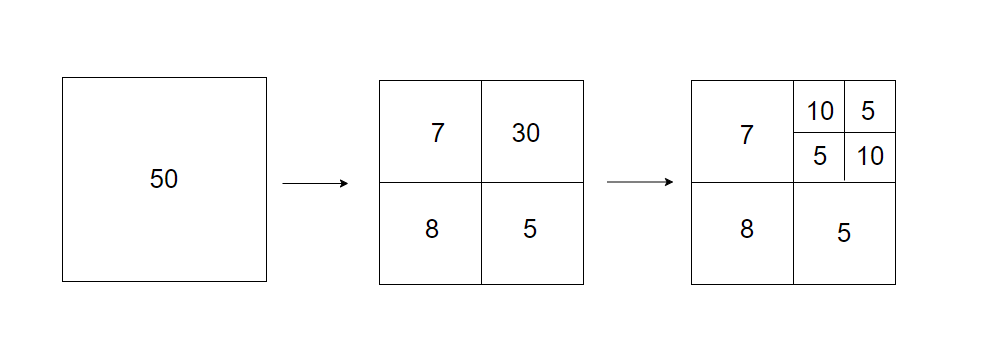
請注意,四元樹是一種記憶體資料結構,它不是資料庫解決方案。它執行在每個LBS 服務上,資料結構是在服務啟動時構建的。
接下來,看一下節點都儲存了哪些資訊?
內部節點
網格的左上角和右下角的座標,以及指向 4個 子節點的指標。
葉子節點
網格的左上角和右下角的座標,以及網格內的商家的 ID 陣列。
現實世界的四元樹範例
Yext 提供了一張圖片 ,顯示了其中一個城市構建的四元樹。我們需要更小、更細粒度的網格用在密集區域,而更大的網格用在偏遠的郊區。
谷歌 S2 和 希爾伯特曲線
Google S2 庫是這個領域的另一個重要參與者,和四元樹類似,它是一種記憶體解決方案。它基於希爾伯特曲線把球體對映到一維索引。
而 希爾伯特曲線 是一種能填充滿一個平面正方形的分形曲線(空間填充曲線),由大衛·希爾伯特在1891年提出,如下

希爾伯特曲線是怎麼生成的?
最簡單的一階希爾伯特曲線,先把正方形平均分成四個網格,然後從其中一個網格的正中心開始,按照方向,連線每一個網格。

二階的希爾伯特曲線, 每個網格都先生成一階希爾伯特曲線 , 然後把它們首尾相連。

三階的希爾伯特曲線

n階的希爾伯特曲線, 實現一條線連線整個平面。
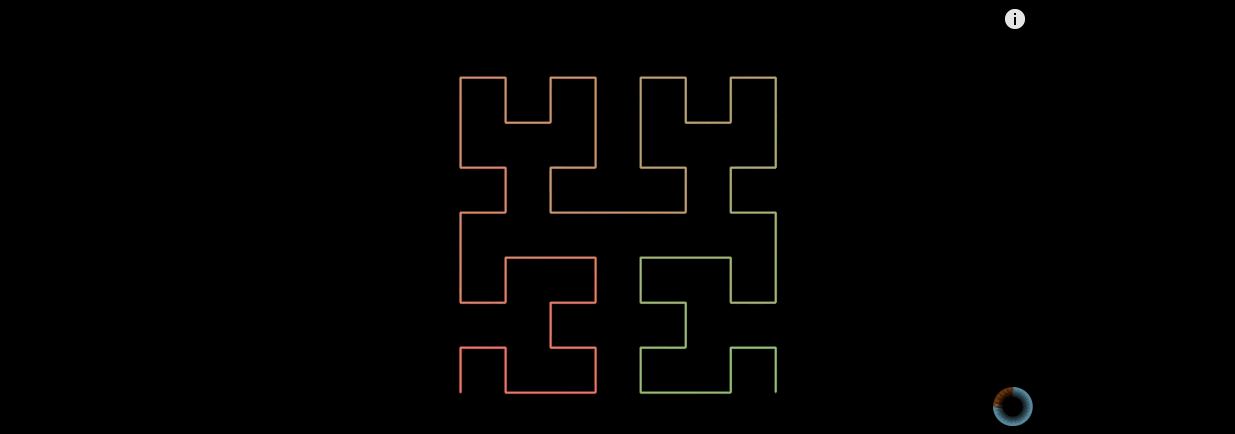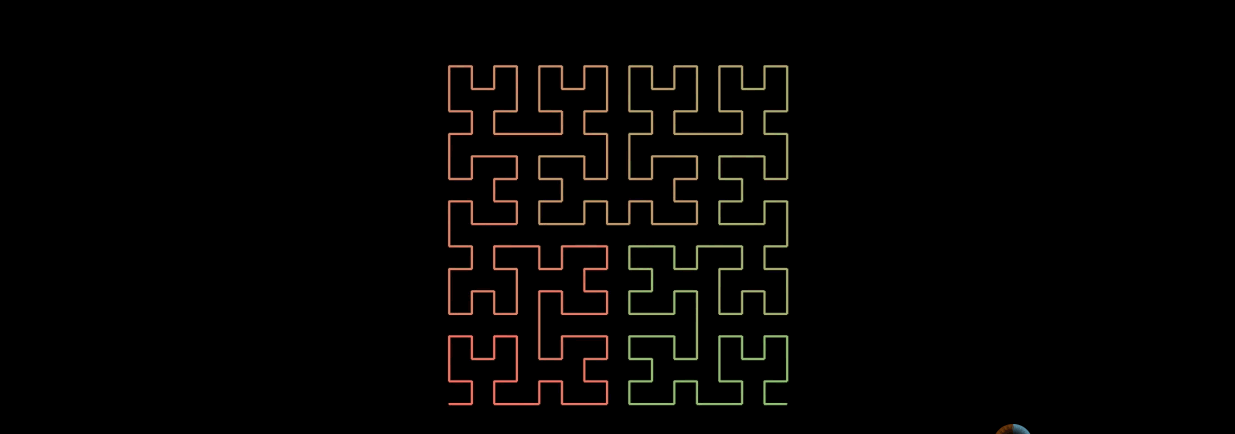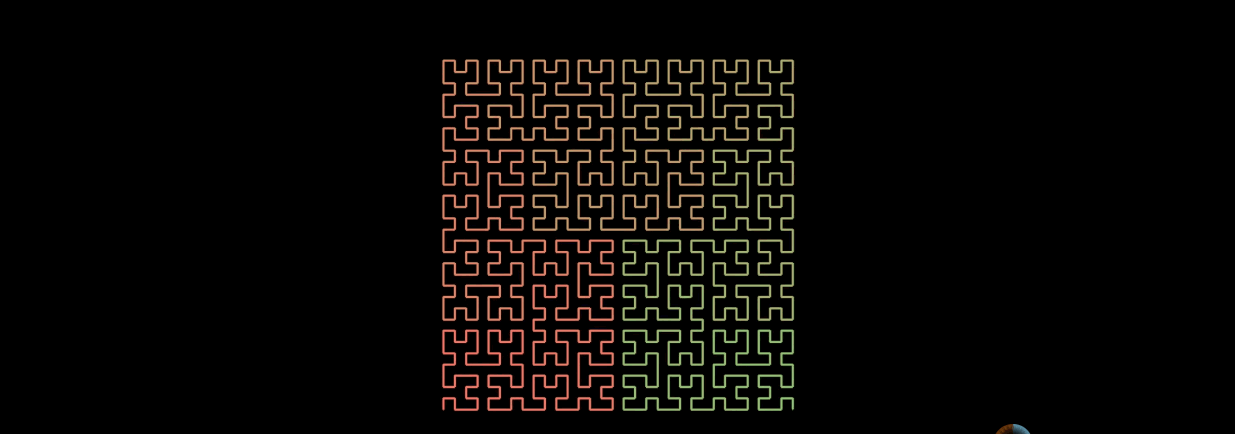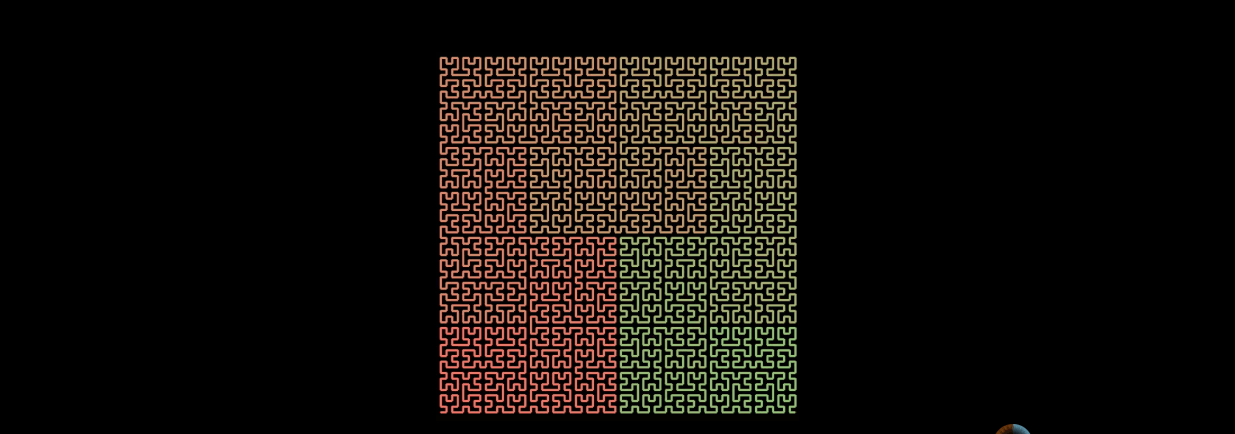
同樣,希爾伯特曲線也可以填充整個三維空間。

希爾伯特曲線的一個重要特點是 降維,可以把多維空間轉換成一維陣列,可以通過動畫看看它是如何實現的。

在一維空間上的搜尋比在二維空間上的搜尋效率高得多了。
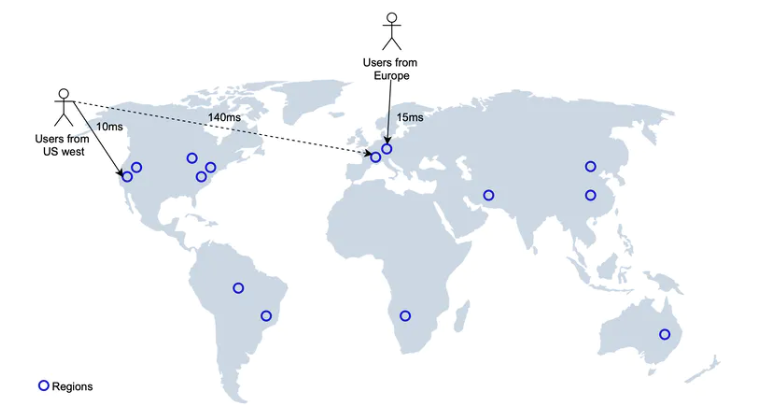
多資料中心和高可用
我們可以把 LBS 服務部署到多個區域,不同地區的使用者連線到最近的資料中心,這樣做可以提升存取速度以及系統的高可用,並根據實際的場景,進行擴充套件。
最終設計圖
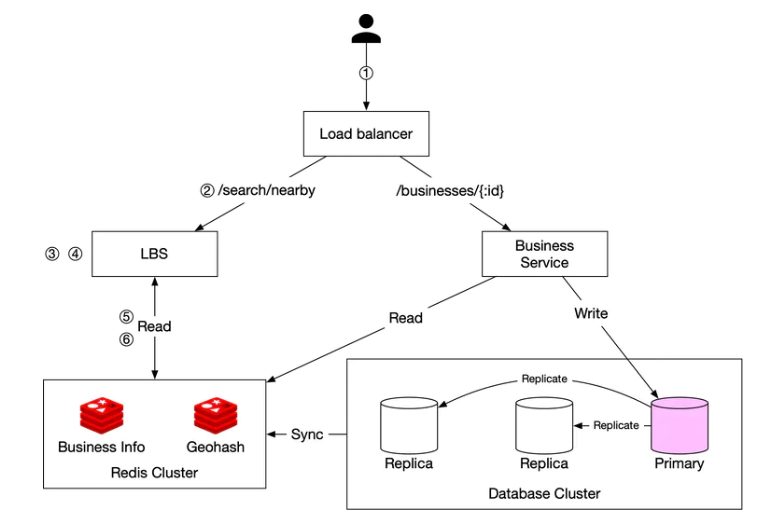
- 使用者需要尋找附近 500 米的餐館。使用者端把使用者位置(經度和緯度),半徑(500m)傳送給後端。
- 負載均衡器把請求轉發給 LBS。
- 基於使用者位置和半徑資訊,LBS 找到與搜尋匹配的 geohash 長度。
- LBS 計算相鄰的 Geohash 並將它們新增到列表中。
- 呼叫 Redis 服務獲取對應的商家 ID。
- LBS 根據返回的商家列表,計算使用者和商家之間的距離,並進行排名,然後返回給使用者端。
總結
在本文中,我們設計了一個鄰近服務,介紹了4種常見了實現方式,分別是二維搜尋,Geohash, 四元樹和 Google S2。它們有各自的優缺點,您可以根據實際的業務場景,選擇合適的實現。
Reference
https://halfrost.com/go_spatial_search/
https://www.amazon.com/System-Design-Interview-Insiders-Guide/dp/1736049119