Elasticsearch 在地理資訊空間索引的探索和演進
vivo 網際網路伺服器團隊- Shuai Guangying
本文梳理了Elasticsearch對於數值索引實現方案的升級和優化思考,從2015年至今數值索引的方案經歷了多個版本的迭代,實現思路從最初的字串模擬到KD-Tree,技術越來越複雜,能力越來越強大,應用場景也越來越豐富。從地理位置資訊建模到多維座標,資料檢索到資料分析洞察都可以看到Elasticsearch的身影。
一、業務背景
LBS服務是當前網際網路重要的一環,涉及餐飲、娛樂、打車、零售等場景。在這些場景中,有很重要的一項基礎能力:搜尋附近的POI。比如搜尋附近的美食,搜尋附近的電影院,搜尋附近的專車,搜尋附近的門店。例如:以某個座標點為中心查詢出1km半徑範圍的POI座標,如下圖所示:
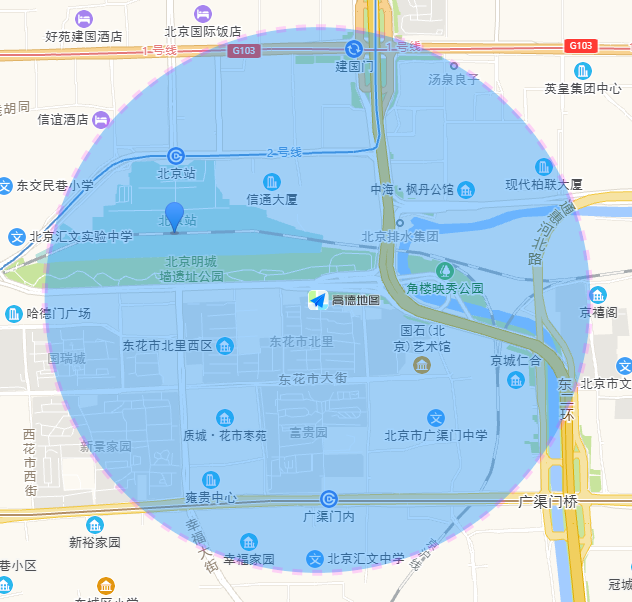
Elasticsearch在地理位置資訊檢索上具備了毫秒級響應的能力,而毫秒級響應對於使用者體驗至關重要。上面的問題使用Elasticsearch,只需用到geo_distance查詢就可以解決業務問題。使用Elasticsearch的查詢語法如下:
GET /my_locations/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "1km",
"pin.location": {
"lat": 40,
"lon": 116
}
}
}
}
}
}
工具的使用是一個非常簡單的事情,更有意思在於工具解決問題背後的思想。理解了處理問題的思想,就可以超然於工具本身,做到舉一反三。本文基於在海量資料背景下,如何實現毫秒級搜尋附近的POI這個問題,探討了Elasticsearch的實現方案,以及實現地理位置索引技術的演進過程。
二、背景知識
在介紹Elasticsearch的處理方案前,我們首先需要介紹一些背景知識,主要是3個問題。
- 如何精確定位一個地址?
由經度、緯度和相對高度組成的地理座標系,能夠明確標示出地球上的任何一個位置。地球上的經度範圍[-180, 180],緯度範圍[-90,90]。通常以本初子午線(經度為0)、赤道(緯度為0)為分界線。對於大多數業務場景,由經緯度組成的二維座標已經足以應對業務問題,可能重慶山城會有些例外。
- 如何計算兩個地址距離?
對於平面座標系,由勾股定理可以方便計算出兩個點的距離。但是由於地球是一個不完美球體,且不同位置有不同海拔高度,所以精確計算兩個距離位置是一個非常複雜的問題。在不考慮高度的情況下,二維座標距離通常使用Haversine公式。
這個公式非常簡單,只需用到arcsin和cos兩個高中數學公式。其中φ和λ表示兩個點緯度和經度的弧度制度量。其中d即為所求兩個點的距離,對應的數學公式如下(參考維基百科):
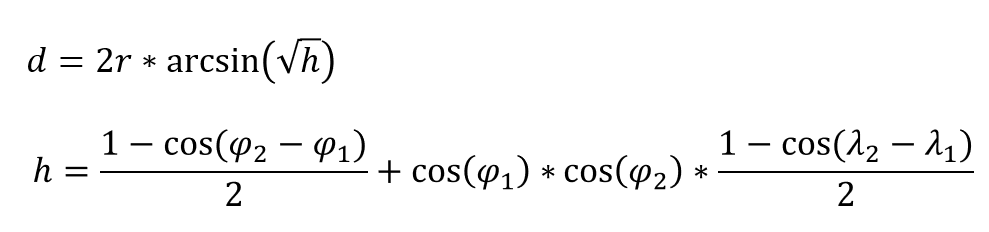
程式設計師更喜歡看程式碼,對照程式碼理解公式更簡單。相應的程式碼如下:
// 程式碼摘自lucene-core-8.2.0, SloppyMath工具類
/**
* Returns the Haversine distance in meters between two points
* given the previous result from {@link #haversinSortKey(double, double, double, double)}
* @return distance in meters.
*/
public static double haversinMeters(double sortKey) {
return TO_METERS * 2 * asin(Math.min(1, Math.sqrt(sortKey * 0.5)));
}
/**
* Returns a sort key for distance. This is less expensive to compute than
* {@link #haversinMeters(double, double, double, double)}, but it always compares the same.
* This can be converted into an actual distance with {@link #haversinMeters(double)}, which
* effectively does the second half of the computation.
*/
public static double haversinSortKey(double lat1, double lon1, double lat2, double lon2) {
double x1 = lat1 * TO_RADIANS;
double x2 = lat2 * TO_RADIANS;
double h1 = 1 - cos(x1 - x2);
double h2 = 1 - cos((lon1 - lon2) * TO_RADIANS);
double h = h1 + cos(x1) * cos(x2) * h2;
// clobber crazy precision so subsequent rounding does not create ties.
return Double.longBitsToDouble(Double.doubleToRawLongBits(h) & 0xFFFFFFFFFFFFFFF8L);
}
// haversin
// TODO: remove these for java 9, they fixed Math.toDegrees()/toRadians() to work just like this.
public static final double TO_RADIANS = Math.PI / 180D;
public static final double TO_DEGREES = 180D / Math.PI;
// Earth's mean radius, in meters and kilometers; see http://earth-info.nga.mil/GandG/publications/tr8350.2/wgs84fin.pdf
private static final double TO_METERS = 6_371_008.7714D; // equatorial radius
private static final double TO_KILOMETERS = 6_371.0087714D; // equatorial radius
/**
* Returns the Haversine distance in meters between two points
* specified in decimal degrees (latitude/longitude). This works correctly
* even if the dateline is between the two points.
* <p>
* Error is at most 4E-1 (40cm) from the actual haversine distance, but is typically
* much smaller for reasonable distances: around 1E-5 (0.01mm) for distances less than
* 1000km.
*
* @param lat1 Latitude of the first point.
* @param lon1 Longitude of the first point.
* @param lat2 Latitude of the second point.
* @param lon2 Longitude of the second point.
* @return distance in meters.
*/
public static double haversinMeters(double lat1, double lon1, double lat2, double lon2) {
return haversinMeters(haversinSortKey(lat1, lon1, lat2, lon2));
}
- 如何方便在網際網路分享經緯度座標?
Geohash是2008-02-26由Gustavo Niemeyer在自己的個人部落格上公佈的演演算法服務。其初衷在於通過對經緯度的編碼對外提供簡短的URL標識地圖位置,方便在電子郵件、論壇和網站中使用。
實際上Geohash的價值不僅僅是提供簡短的URL,它更大的價值在於:
Geohash給地圖上每個座標提供了獨一無二的ID,這個唯一ID就相當於給每個地理位置提供了一個身份證。唯一ID在資料庫中應用場景非常豐富。
在資料庫中給座標點提供了另一種儲存方式,將二維的座標點轉化成為一維的字串,對於一維資料就可以藉助B樹等索引來加速查詢。
Geohash是一種字首編碼,位置相近的座標點字首相同。通過字首提供了高效能的鄰近位置POI查詢,而鄰近位置POI查詢是LBS服務的核心能力。
關於Geohash的編碼規則,這裡不展開。這裡最關鍵的點在於:
Geohash是一種字首編碼,位置相近的座標點字首相同。Geohash編碼長度不同,所覆蓋區域範圍不同。
在前面知識的鋪墊下,最簡單的求一個座標點指定半徑範圍內的座標集合的方案就出爐了。
- 暴力演演算法
中心座標點依次跟集合中每個座標點計算距離,篩選出符合半徑條件的座標點。
這個演演算法大家太熟悉了,就是最常見的暴力(Brute Force)演演算法。這個演演算法在海量資料背景下是沒法滿足毫秒級響應時間要求的,所以多用於離線計算。對於毫秒級響應的業務訴求,這個演演算法可以基於geohash進行改造。
- 二次篩選
基於座標中心點計算出geohash, 基於半徑確定geohash字首。
通過Geohash字首初篩出大致符合要求的座標點(需要將中心點所在Geohash塊周圍8個Geohash塊納入初篩範圍)。
對於初篩結果使用Haversine公式進行二次篩選。
除了上述方案,Elasticsearch在地理資訊處理上有哪些奇思妙想呢?
三、方案演進
Elasticsearch從2.0版本開始支援geo_distance查詢,到當前已更新到7.14版本。
從2015年至今已經經歷了6年的發展, 建設了如下的能力:
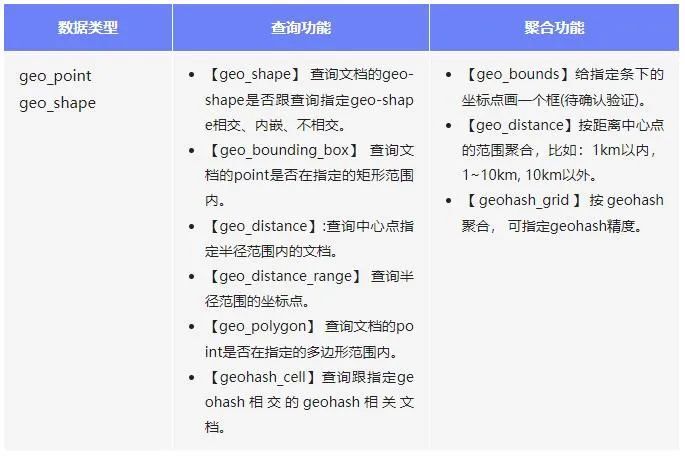
技術迭代大致可以分為3個階段:
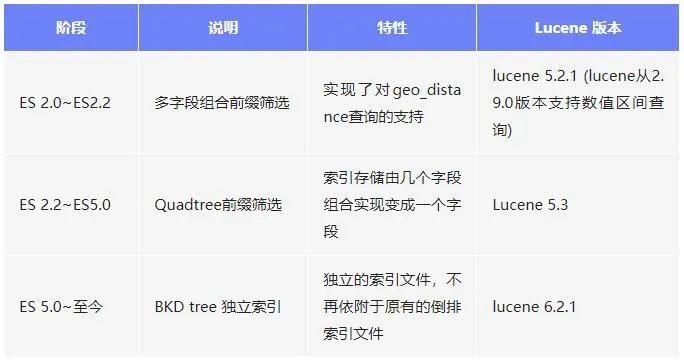
發展的成效顯著,從效能測試的結果可以略窺一二:
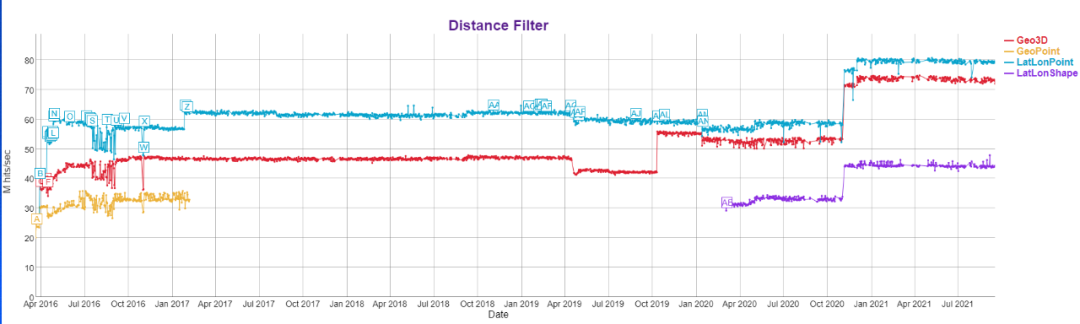
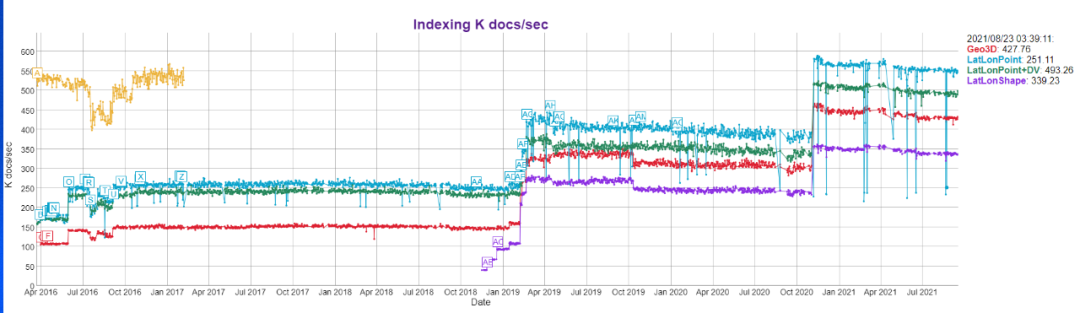
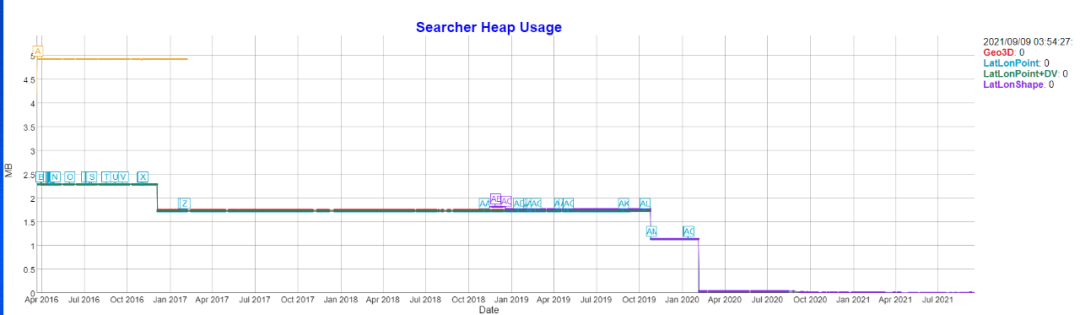
總的來說,資源消耗降低的前提下搜尋和寫入資料效率都有大幅度提升。下面就詳細介紹Elasticsearch對地理資訊索引的思路。
3.1 史前時代
Elasticsearch是基於Lucene構建的搜尋引擎。Lucene最開始的設想是一個全文檢索工具箱,即支援字串檢索,並沒有考慮數值型別的處理。其核心思想非常簡單,將檔案分詞後,為每個詞構建一個term => array[docIds]的對映。
這樣使用者輸入關鍵詞只需要三步就可以獲得想要的結果:
第一步: 通過關鍵詞找到對應的倒排表。這一步簡單來說就是查詞典。例如:TermQuery.TermWeight 獲取該term的倒排表,讀取docId+freq資訊。
第二步: 根據倒排表得到的docId和詞頻資訊對檔案進行打分,返回給使用者分值最高的TopN結果。例如:TopScoreDocCollector -- collect()方法,基於小頂堆,保留分數最大的TopN檔案。
第三步: 基於docId查詢正排表獲取檔案欄位明細資訊。
這三步看起來簡單,但簡直是資料結構應用最佳戰場,它需要綜合考慮磁碟、記憶體、IO、資料結構時間複雜度,非常具有挑戰性。
例如:查詞典可以用很多資料結構實現,比如跳躍表,平衡樹、HashMap等,而Lucene的核心工程師Mike McCandless實現了一個只有他自己能懂的FST, 是綜合了有限自動機和字首樹的一種資料結構,用來平衡查詢複雜度和儲存空間,比HashMap慢,但是空間消耗低。檔案打分通常用小頂堆來維護分值最高的N個結果,如果有新的檔案打分超過堆頂,則替換堆頂元素即可。
問題:對於真實業務場景而言,只有字串匹配查詢是不夠的,字串和數值是應用最廣泛的兩種資料型別。如果需要進行區間查詢怎麼辦呢?這是一個資料庫產品非常基礎的能力。
Lucene提供了一種適配方案RangeQuery。就是用列舉來模擬數值查詢。簡單來說:RangeQuery=BooleanQuery+TermQuery,所以限制查詢是整數且區間最大不能超過1024。這種實現是可以說是非常雞肋的,好在Lucene 2.9.0版本真正支援數值查詢。
LUCENE-1470,LUCENE-1582,LUCENE-1602,LUCENE-1673,LUCENE-1701, LUCENE-1712
Added NumericRangeQuery and NumericRangeFilter, a fast alternative to RangeQuery/RangeFilter for numeric searches. They depend on a specific structure of terms in the index that can be created by indexing using the new NumericField or NumericTokenStream classes. NumericField can only be used for indexing and optionally stores the values as string representation in the doc store. Documents returned from IndexReader/IndexSearcher will return only the String value using the standard Fieldable interface. NumericFields can be sorted on and loaded into the FieldCache. (Uwe Schindler, Yonik Seeley, Mike McCandless)
這個實現很強大,支援了int/long/float/double/short/byte,也不限制查詢區間了。它的核心思路是將數值位元組陣列化,然後利用字首分層管理區間。
如下圖所示:
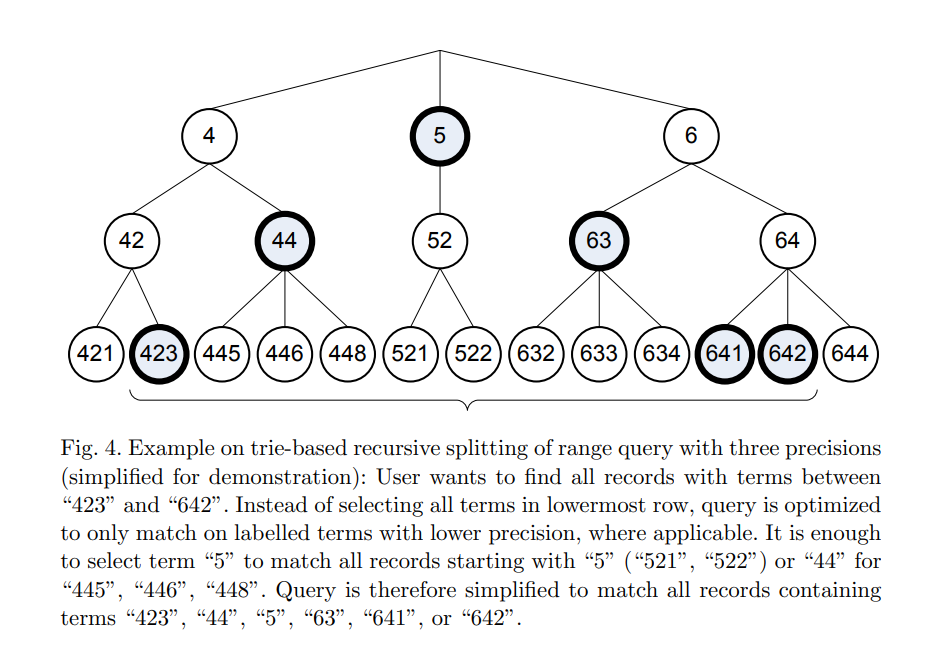
本質上還是RangeQuery=BooleanQuery+TermQuery,只不過在前面做了一層轉換:通過字首樹管理一個區間實現了匹配詞數量的縮減,而這個縮減是非常有效的。所以這裡就有一個專家引數:precisionStep。就是用來控制每個數值欄位在分詞是生成term的數量,生成term數量越多,區間控制粒度越細,佔用磁碟空間越大,查詢效率通常越高。
例如:如果precisionStep=8,則意味字首樹葉子節點的上層控制著255個葉子。那麼,當查詢範圍在1511時,由於跨了相鄰的2個非葉子節點,所以需要遍歷511個term。但是假如查詢範圍在0512,又只需遍歷2個term即可。這樣的實現用起來真的有過山車的感覺。
綜上,Elasticsearch核心的Lucene倒排索引是一種經典的以不變應萬變:字串和數值索引核心都是查倒排表。理解這個核心,對於後面理解地理位置資料儲存和查詢非常關鍵。接下來我們以geo_distance的實現思路為探索主線條,探索一下ES各個版本的實現思路。
3.2 Elasticsearch 2.0 版本
這個版本實現geo_distance查詢的思路非常樸素,是建立在數值區間查詢(NumericRangeQuery)的基礎上。它的geo_point型別欄位其實是一個複合欄位,或者說是一個結構體。在底層實現時分別用兩個獨立欄位索引來避免暴力掃描。即Elasticsearch的geo_point欄位在實現上是lat,lon,加上編碼成的geohash綜合提供檢索聚合功能。
欄位定義如下所示:
public static final class GeoPointFieldType extends MappedFieldType {
private MappedFieldType geohashFieldType;
private int geohashPrecision;
private boolean geohashPrefixEnabled;
private MappedFieldType latFieldType;
private MappedFieldType lonFieldType;
public GeoPointFieldType() {}
}
演演算法的執行分為三個階段:
第一步:根據中心點以及半徑計算出一個大致符合需求的矩形區域,然後利用矩形區域的最小最大經度得到一個數值區間查詢,利用矩形區域的最小最大緯度得到一個區間查詢。
核心程式碼如下圖所示:
// 計算經緯度座標+距離得到的矩形區域
// GeoDistance類
public static DistanceBoundingCheck distanceBoundingCheck(double sourceLatitude, double sourceLongitude, double distance, DistanceUnit unit) {
// angular distance in radians on a great circle
// assume worst-case: use the minor axis
double radDist = unit.toMeters(distance) / GeoUtils.EARTH_SEMI_MINOR_AXIS;
double radLat = Math.toRadians(sourceLatitude);
double radLon = Math.toRadians(sourceLongitude);
double minLat = radLat - radDist;
double maxLat = radLat + radDist;
double minLon, maxLon;
if (minLat > MIN_LAT && maxLat < MAX_LAT) {
double deltaLon = Math.asin(Math.sin(radDist) / Math.cos(radLat));
minLon = radLon - deltaLon;
if (minLon < MIN_LON) minLon += 2d * Math.PI;
maxLon = radLon + deltaLon;
if (maxLon > MAX_LON) maxLon -= 2d * Math.PI;
} else {
// a pole is within the distance
minLat = Math.max(minLat, MIN_LAT);
maxLat = Math.min(maxLat, MAX_LAT);
minLon = MIN_LON;
maxLon = MAX_LON;
}
GeoPoint topLeft = new GeoPoint(Math.toDegrees(maxLat), Math.toDegrees(minLon));
GeoPoint bottomRight = new GeoPoint(Math.toDegrees(minLat), Math.toDegrees(maxLon));
if (minLon > maxLon) {
return new Meridian180DistanceBoundingCheck(topLeft, bottomRight);
}
return new SimpleDistanceBoundingCheck(topLeft, bottomRight);
}
第二步:兩個查詢通過BooleanQuery組合成一個取交集的複合查詢,以實現初篩出在經緯度所示矩形區域內的docId集合。
核心程式碼如下圖所示:
public class IndexedGeoBoundingBoxQuery {
public static Query create(GeoPoint topLeft, GeoPoint bottomRight, GeoPointFieldMapper.GeoPointFieldType fieldType) {
if (!fieldType.isLatLonEnabled()) {
throw new IllegalArgumentException("lat/lon is not enabled (indexed) for field [" + fieldType.names().fullName() + "], can't use indexed filter on it");
}
//checks to see if bounding box crosses 180 degrees
if (topLeft.lon() > bottomRight.lon()) {
return westGeoBoundingBoxFilter(topLeft, bottomRight, fieldType);
} else {
return eastGeoBoundingBoxFilter(topLeft, bottomRight, fieldType);
}
}
private static Query westGeoBoundingBoxFilter(GeoPoint topLeft, GeoPoint bottomRight, GeoPointFieldMapper.GeoPointFieldType fieldType) {
BooleanQuery.Builder filter = new BooleanQuery.Builder();
filter.setMinimumNumberShouldMatch(1);
filter.add(fieldType.lonFieldType().rangeQuery(null, bottomRight.lon(), true, true), Occur.SHOULD);
filter.add(fieldType.lonFieldType().rangeQuery(topLeft.lon(), null, true, true), Occur.SHOULD);
filter.add(fieldType.latFieldType().rangeQuery(bottomRight.lat(), topLeft.lat(), true, true), Occur.MUST);
return new ConstantScoreQuery(filter.build());
}
private static Query eastGeoBoundingBoxFilter(GeoPoint topLeft, GeoPoint bottomRight, GeoPointFieldMapper.GeoPointFieldType fieldType) {
BooleanQuery.Builder filter = new BooleanQuery.Builder();
filter.add(fieldType.lonFieldType().rangeQuery(topLeft.lon(), bottomRight.lon(), true, true), Occur.MUST);
filter.add(fieldType.latFieldType().rangeQuery(bottomRight.lat(), topLeft.lat(), true, true), Occur.MUST);
return new ConstantScoreQuery(filter.build());
}
}
第三步:利用FieldData快取(正向資訊)根據docId獲取矩形區域中每個座標點的經緯度,然後利用前面的Haversine公式計算跟中心座標點的距離,進行精確篩選,得到符合條件的檔案集合。
核心程式碼如下所示:
// GeoDistanceRangeQuery類的實現
@Override
public Weight createWeight(IndexSearcher searcher, boolean needsScores) throws IOException {
final Weight boundingBoxWeight;
if (boundingBoxFilter != null) {
boundingBoxWeight = searcher.createNormalizedWeight(boundingBoxFilter, false);
} else {
boundingBoxWeight = null;
}
return new ConstantScoreWeight(this) {
@Override
public Scorer scorer(LeafReaderContext context) throws IOException {
final DocIdSetIterator approximation;
if (boundingBoxWeight != null) {
approximation = boundingBoxWeight.scorer(context);
} else {
approximation = DocIdSetIterator.all(context.reader().maxDoc());
}
if (approximation == null) {
// if the approximation does not match anything, we're done
return null;
}
final MultiGeoPointValues values = indexFieldData.load(context).getGeoPointValues();
final TwoPhaseIterator twoPhaseIterator = new TwoPhaseIterator(approximation) {
@Override
public boolean matches() throws IOException {
final int doc = approximation.docID();
values.setDocument(doc);
final int length = values.count();
for (int i = 0; i < length; i++) {
GeoPoint point = values.valueAt(i);
if (distanceBoundingCheck.isWithin(point.lat(), point.lon())) {
double d = fixedSourceDistance.calculate(point.lat(), point.lon());
if (d >= inclusiveLowerPoint && d <= inclusiveUpperPoint) {
return true;
}
}
}
return false;
}
};
return new ConstantScoreScorer(this, score(), twoPhaseIterator);
}
};
}
這是一種非常簡單且直觀的思路實現了中心點指定半徑範圍POI的搜尋能力。
簡單總結一下要點:
利用中心點座標和半徑確定矩形區域邊界。
利用Bool查詢綜合兩個NumericRangeQuery查詢,實現矩形區域初篩。
利用Haversine公式計算中心點和矩形區域內每個座標點距離,進行第二階段過濾操作,篩選出最終符合條件的docId集合。
方案雖然簡單,但是畢竟實現了geo_distance的能力。又不是不能用,對吧?那麼該方案有什麼問題呢?
3.3 Elasticsearch 2.2 版本
ES2.0版本的實現有個問題, 就是沒有很好解決二維組合條件查詢的資料篩選。它是分別獲取符合緯度範圍條件的檔案集合和符合經度範圍條件的檔案集合然後進行交集,初篩了太多無效的檔案集合。
它的處理思路用一張圖表示如下:

即選擇了那麼多的記錄,最終只有經緯度範圍交匯的紅色區域是初篩的範圍。
針對上面的問題,ES 2.2版本引入特性:基於四元樹(Quadtree)的地理位置查詢(Lucene 5.3版本實現)。
Quadtree並非什麼複雜高深的資料結構,相比二元樹,多了兩個子節點。
作為一種基礎的資料結構,Quadtree應用場景非常廣泛,在影象處理、空間索引、碰撞檢測、人生遊戲模擬、分形影象分析等領域都可以看到它的身影。
在Elasticsearch地理位置空間索引問題上,Quadtree用來表示區間,可以視為字首樹的一種。
- Region quadtree
The region quadtree represents a partition of space in two dimensions by decomposing the region into four equal quadrants, subquadrants, and so on with each leaf node containing data corresponding to a specific subregion. Each node in the tree either has exactly four children, or has no children (a leaf node). The height of quadtrees that follow this decomposition strategy (i.e. subdividing subquadrants as long as there is interesting data in the subquadrant for which more refinement is desired) is sensitive to and dependent on the spatial distribution of interesting areas in the space being decomposed. The region quadtree is a type of trie.
在區間劃分上,Quadtree跟geohash的處理思路有些相似。在一維世界,二分可以無限迭代。同理,在二維世界,四分也可以無限迭代。下面這個圖可以非常形象展示Quadtree的區間劃分過程。
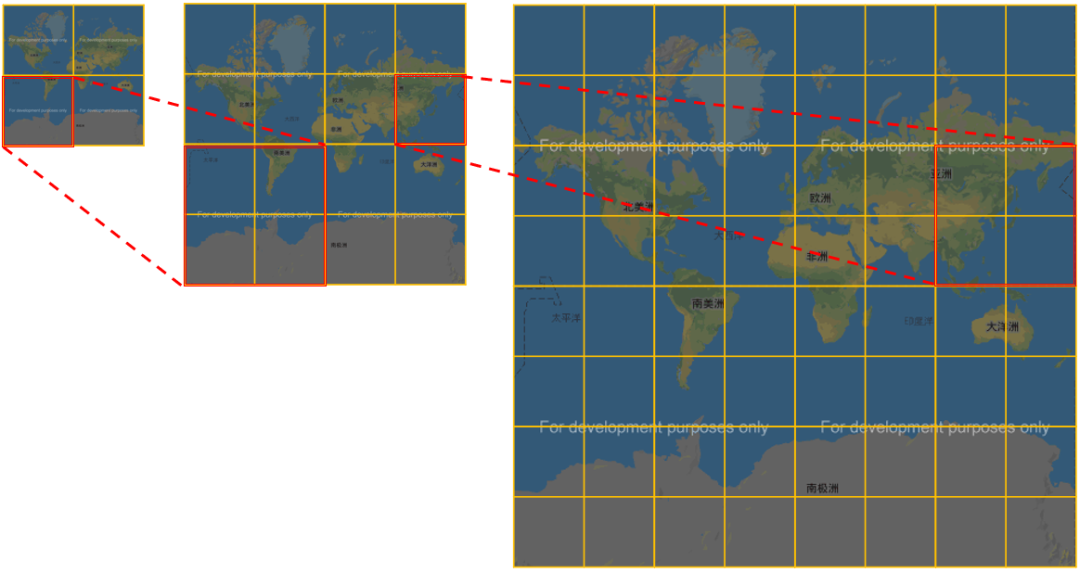
ES 2.2是如何使用Quadtree來實現geo_distance查詢呢?
通常我們使用一種資料結構,是先基於該資料結構儲存資料,然後查詢這個資料結構。ES這裡使用Quadtree的做法非常巧妙:儲存的時候沒有感覺用到Quadtree,查詢時卻用其查詢方式。
morton編碼:在理解ES的處理思路前,需要科普一個知識點,那就是morton編碼。關於morton編碼,跟geohash類似,是一種將二維資料按二進位制位交叉編碼成一維資料的一種網格編碼,其用法和特點跟geohash也是類似的。對於64位元的morton碼,其經緯度定位精度範圍控制到了釐米級別,對於地理位置場景而言,是非常非常高的精度了。
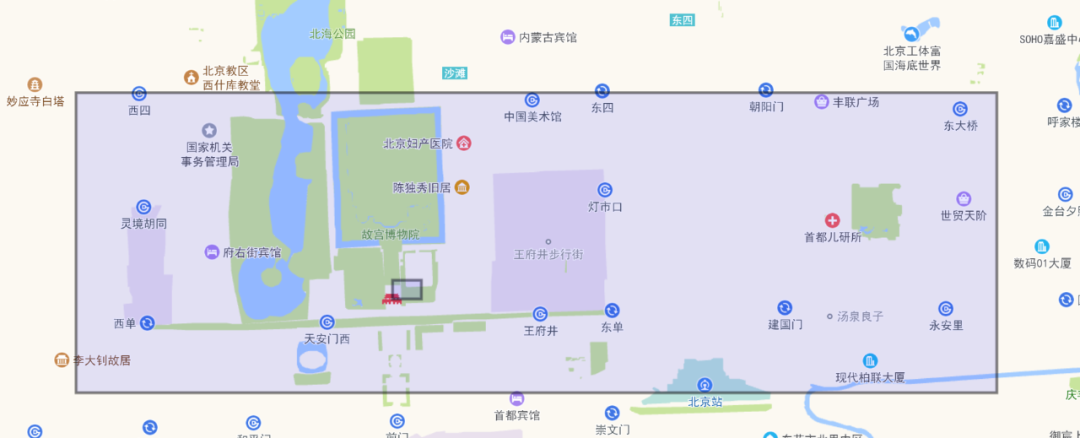
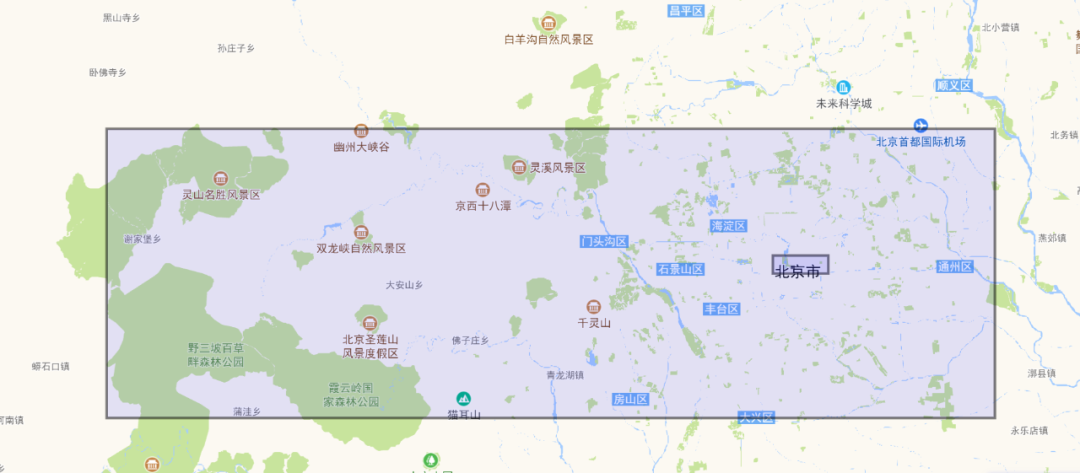
資料儲存:ES2.2版本之前一個經緯度座標需要三個欄位儲存:lat,lon,geohash。有了Quadtree後,只需要一個欄位儲存就可以了。具體的實現思路如下:將lat,lon座標進行對映,使得經緯度的取值範圍從[-180,180]/[-90,90]對映到[0,2147483520](整數好處理), 然後處理成一維的mortonHash數值。對於數值欄位的處理思路,就又回到了字首(trie)的思路,就又回到了熟悉的專家引數precisionStep。在這裡的字首該如何理解?對於一維資料,每個字首管理一段區間,對於二維資料每個字首管理一個二維網格區域。例如一個座標點利用precisionStep=9來劃分字首,其視覺化矩形區域如下:
(取shift=27,36)
(取shift=36,45)
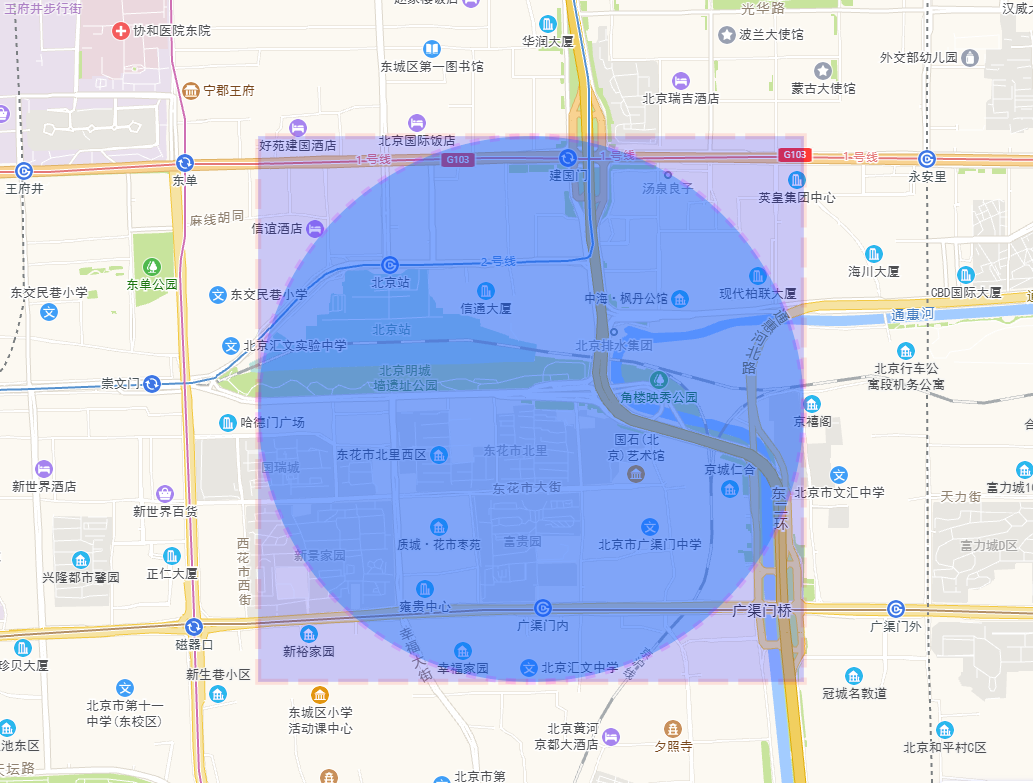
資料查詢:在查詢時,首先將查詢中心點座標轉換成一個矩形。這個處理思路我們延續了ES 2.0的做法,不陌生了。
例如:對於座標為(116.433322,39.900255),半徑為1km的點,生成的矩形如下所示:
double centerLon = 116.433322;
double centerLat = 39.900255;
double radiusMeters = 1000.0;
GeoRect geoRect = GeoUtils.circleToBBox(centerLon, centerLat, radiusMeters);
System.out.println( geoRect );
用高德API生成對應的視覺化圖形如下:
有了這個矩形後,後面的做法就跟ES 2.0有些不同了。ES 2.2版本的思路是利用Quadtree對整個世界地圖進行網格化。具體的流程如下:
- Quadtree處理流程
第一步: 以經緯度(0,0)為起始中心點,將整個世界切分成4個區塊。並判斷引數生成的矩形在哪個區塊。
第二步: 對於矩形區域不在的區域,略過。對於矩形區域所在的區塊,繼續四分,切成4個區塊。
第三步: 當滿足如下任一條件時,將相關的檔案集合收集起來,作為第一批粗篩的結果。
條件一:切分到正好跟字首的precisionStep契合,並且quad-cell在矩形內部時。
條件二:切分到最小層級(level=13)時且quad-cell跟矩形區域有交集時。
第四步: 利用lucene的doc_values快取機制,獲取每個docId對應的經緯度,利用距離公式計算是否在半徑範圍內,得到最終的結果。(這個操作也是常規思路了)
另外ES在處理時進行了版本相容。
例如:ES 2.2版本對於geo_distance的實現關鍵點,判斷索引版本是否是V_2_2_0版本以後建立,如果是則直接用Lucene的GeoPointDistanceQuery查詢類,否則沿用ES 2.0版本的GeoDistanceRangeQuery。
IndexGeoPointFieldData indexFieldData = parseContext.getForField(fieldType);
final Query query;
if (parseContext.indexVersionCreated().before(Version.V_2_2_0)) {
query = new GeoDistanceRangeQuery(point, null, distance, true, false, geoDistance, geoFieldType, indexFieldData, optimizeBbox);
} else {
distance = GeoUtils.maxRadialDistance(point, distance);
query = new GeoPointDistanceQuery(indexFieldData.getFieldNames().indexName(), point.lon(), point.lat(), distance);
}
if (queryName != null) {
parseContext.addNamedQuery(queryName, query);
}
核心程式碼參考:GeoPointDistanceQuery、GeoPointRadiusTermsEnum
3.4 Elasticsearch 5.0 版本
方案優化的探索是沒有沒有止境的,Lucene的核心工程師 Michael McCandless受到論文《Bkd-Tree: A Dynamic Scalable kd-Tree》啟發,基於BKD tree再次升級了地理位置資料索引建模和查詢功能。
這個資料結構不僅僅是用於解決地理位置查詢問題,更是數值類資料索引建模的通用方案。它可以處理一維的數值,從byte到BigDecimal, IPv6地址等等;它也可以處理二維乃至於N維的資料檢索問題。
- LUCENE-6825
This can be used for very fast 1D range filtering for numerics, removing the 8 byte (long/double) limit we have today, so e.g. we could efficiently support BigInteger, BigDecimal, IPv6 addresses, etc.
It can also be used for > 1D use cases, like 2D (lat/lon) and 3D (x/y/z with geo3d) geo shape intersection searches.
...
It should give sizable performance gains (smaller index, faster searching) over what we have today, and even over what auto-prefix with efficient numeric terms would do.
在前面的版本中,對於數值區間查詢的處理思路本質上都是term匹配,通過字首實現了一個term管理一個區間,從而降低了區間查詢需要遍歷的term數量。而從ES 5.0版本開始,徹底優化了數值查詢(從一維到N維),其底層是Lucene 6.0版本實現的BKD tree的獨立索引。其實現不僅降低了記憶體開銷,而且提升了檢索和索引速度。
關於bkd-tree的原理,其大體思路如下。在面對數值查詢區間查詢的問題上,大體分為兩個層次:
【優化記憶體查詢】:BST(binary-search-tree) > Self-balanced BST > kd-tree。
【優化外存(硬碟)查詢】:B-tree > K-D-B-tree > BKD tree。
kd-tree其實就是多維的BST。例如:
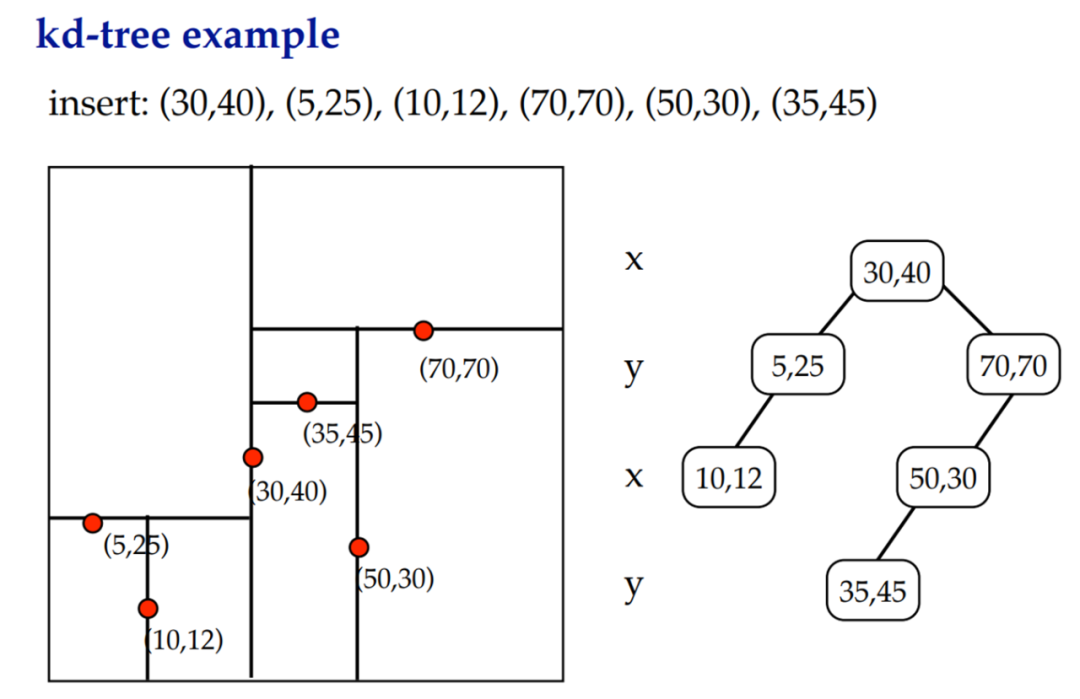
【資料儲存】:BKD tree的核心思路是非常簡單的,將N維點集合形成的矩形空間(southWest,northEast)遞迴分割成更小的矩形空間。跟常見的kd-tree不同,當分割到網格區域裡面座標點的數量小於一定數量(比如1024)就停止了。
例如:
通過區域的分割,確保每個區域POI的數量大致相等。
【資料查詢】:搜尋的時候,就不再是像Quadtree從整個世界開始定位,而是基於當前的點集合形成的空間來查詢。例如以geo_distance查詢為例。
其流程如下:
第一步: 中心點座標+半徑生成一個矩形(shape boundary)。這一步是常規操作了,前面的版本也都是這麼做的。
第二步:該矩形跟BKD tree 葉子節點形成的矩形(cell)進行intersect運算,所謂intersect運算,就是計算兩個矩形的位置關係:相交、內嵌還是不相關。query和bkd-tree形成的區域有三種關係。
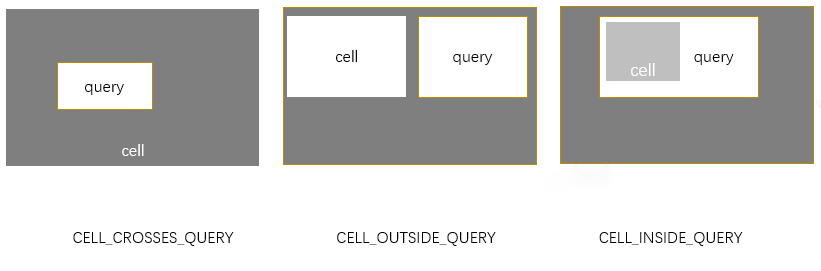
對於CELL_CROSSES_QUERY,如果是葉子節點,則需要判斷cell中的每個POI是否符合query的查詢條件;否則查詢子區間;對於CELL_OUTSIDE_QUERY,直接略過;對於CELL_INSIDE_QUERY,整個cell中的POI都滿足查詢條件。
核心程式碼:LatLonPoint/LatLonPointDistanceQuery
3.5 後續發展
Geo查詢能力的迭代和變遷,其實也是Elasticsearch作為一個資料庫對數值查詢能力的升級和優化,擴充套件產品的適用場景,讓使用者打破對Elasticsearch只能做全文檢索的偏見。從全文檢索資料庫擴充套件到分析型資料庫,Elasticsearch還有很長的路要走。
按照 Michael McCandless的設想,當前的多維資料只能是單個點,但是有些場景需要將形狀作為一個維度進行索引。在這種需求下,需要通過一種更普適化的k-d tree ,即R-Tree來實現。
路漫漫其修遠兮,ES從2.0版本支援geo-spatial開始經歷6年的發展,已經走了很遠,然而依然有很多值得探索的領域和場景。
參考: