論文解讀(LG2AR)《Learning Graph Augmentations to Learn Graph Representations》
論文資訊
論文標題:Learning Graph Augmentations to Learn Graph Representations
論文作者:Kaveh Hassani, Amir Hosein Khasahmadi
論文來源:2022, arXiv
論文地址:download
論文程式碼:download
1 Introduction
我們引入了 LG2AR,學習圖增強來學習圖表示,這是一個端到端自動圖增強框架,幫助編碼器學習節點和圖級別上的泛化表示。LG2AR由一個學習增強引數上的分佈的概率策略和一組學習增強引數上的分佈的概率增強頭組成。我們表明,與之前線上性和半監督評估協定下的無監督模型相比,LG2AR在20個圖級和節點級基準中的18個上取得了最先進的結果。
2 Method
整體框架如下:
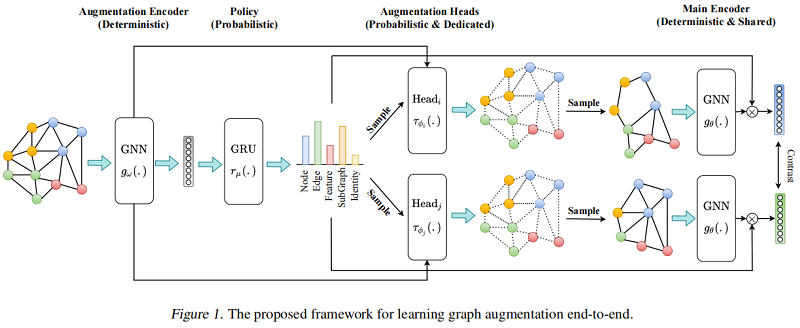
2.1 Augmentation Encoder
增強編碼器 $g_{\omega}(.): \mathbb{R}^{|\mathcal{V}| \times d_{x}} \times \mathbb{R}^{|\mathcal{E}|} \longmapsto \mathbb{R}^{|\mathcal{V}| \times d_{h}} \times \mathbb{R}^{d_{h}}$ 基於圖 $G_{k}$ 產生節點表示 $\mathbf{H}_{v} \in \mathbb{R}^{|\mathcal{V}| \times d_{h}}$ 和圖表示 $h_{g} \in \mathbb{R}^{d_{h}}$ 。
增強編碼器 $g_{\omega}(.)$ 的組成:
-
- GNN Encoder;
- Readout function;
- Two MLP projection head;
2.2 Policy
Policy $r_{\mu}(.): \mathbb{R}^{|\mathcal{B}| \times d_{h}} \longmapsto \mathbb{R}^{|\tau|}$ 是一個概率模組,接收一批從增強編碼器得到的圖級表示 $\mathbf{H}_{g} \in \mathbb{R}^{|\mathcal{B}| \times d_{h}}$ ,構造一個增強分佈 $\mathcal{T}$,然後取樣兩個資料增強 $\tau_{\phi_{i}}$ 和 $\tau_{\phi_{j}}$。由於在整個資料集上進行增強取樣代價昂貴,本文選則小批次的處理方式來近似。
此外,Policy 必須對批次處理內表示的順序保持不變,所以本文嘗試了兩種策略:
- a policy instantiated as a deep set where representations are first projected and then aggregated into a batch representation.
- a policy instantiated as an RNN where we impose an order on the representations by sorting them based on their L2-norm and then feeding them into a GRU.
本文使用最後一個隱藏狀態作為批次處理表示形式。我們觀察到GRU政策表現得更好。該策略模組自動化了特別的試錯增強選擇過程。為了讓梯度流回策略模組,我們使用了一個跳躍連線,並將最終的圖表示乘以策略預測的增強概率。
2.3 Augmentations
Topological augmentations:
-
- node dropping
- edge perturbation
- subgraph inducing
Feature augmentation:
-
- feature masking
Identity augmentation
與之前的工作中,增強的引數是隨機或啟發式選擇的,我們選擇端到端學習它們。例如,我們不是隨機丟棄節點或計算與中心性度量成比例的概率,而是訓練一個模型來預測圖中所有節點的分佈,然後從它中抽取樣本來決定丟棄哪些節點。與 Policy 模組不同,增強功能以單個圖為條件。我們為每個增強使用一個專用的頭,建模為一個兩層MLP,學習增強引數的分佈。頭部的輸入是原始圖 $G$ 和表示來自增強編碼器的 $\mathbf{H}_{v}$ 和 $h_{G}$。我們使用 Gumbel-Softmax 技巧對學習到的分佈進行取樣。
Node Dropping Head
以節點和圖表示為條件,以決定刪除圖中的哪些節點。
它接收節點和圖表示作為輸入,並預測節點上的分類分佈。然後使用 Gumbel-Top-K技巧,使用比率超引數對該分佈進行取樣。我們也嘗試了伯努利抽樣,但我們觀察到它在最初的幾個時期積極地減少節點,模型在以後無法恢復。為了讓梯度從增廣圖迴流到頭部,我們在增廣圖上引入了邊權值,其中一個邊權值 $w_{i j}$ 被計算為 $p\left(v_{i}\right)+p\left(v_{j}\right)$,而 $p\left(v_{i}\right)$ 是分配給節點 $v_{i}$ 的概率。
演演算法如下:

Edge Perturbation Head
以頭部和尾部節點為條件,以決定新增/刪除哪些邊。
首先隨機取樣 $|\mathcal{E}|$ 個負邊( $\overline{\mathcal{E}}$ ),形成一組大小為 $2|\mathcal{E}|$ 的負邊和正邊集合 $\mathcal{E} \cup \overline{\mathcal{E}}$。邊表示為 $\left[h_{v_{i}}+h_{v_{j}} \| \mathbb{1}_{\mathcal{E}}\left(e_{i j}\right)\right]$ ( $h_{v_{i}}$ 和 $h_{v_{j}}$ 分別代表邊 $e_{i j}$ 的頭和尾部節點的表示,$\mathbb{1}_{\mathcal{E}}\left(e_{i j}\right)$ 用於判斷邊是屬於positivate edge 或者 negative edge )輸入 Heads 去學習伯努利分佈。我們使用預測的概率 $p\left(e_{i j}\right)$ 作為邊權重,讓梯度流回頭部。
演演算法如下:

以節點和圖表示為條件來決定中心節點。
它接收節點和圖表示(即 $\left[h_{v} \| h_{g}\right]$ )的連線作為輸入,並學習節點上的分類分佈。然後對分佈進行取樣,為每個圖選擇一箇中心節點,圍繞該節點使用具有 $K-hop$ 的廣度優先搜尋(BFS)誘導一個子圖。我們使用類似的技巧來實現節點刪除增強,以跨越梯度回到原始圖。
演演算法過程:

以節點表示為條件,以決定要遮蔽的節點特徵的哪些維度。頭部接收節點表示 $h_v$,並在原始節點特徵的每個特徵維數上學習伯努利分佈。然後對該分佈進行取樣,在初始特徵空間上構造一個二值掩模 $m$。因為初始節點特徵可以由類別屬性組成,所以我們使用一個線性層將它們投射到一個連續的空間中,從而得到 $x_{v}^{\prime}$。增廣圖具有與原始圖相同的結構,具有初始節點特徵 $x_{v}^{\prime} \odot m$($\odot$ 為哈達瑪乘積)。
演演算法過程:

2.4 Base Encoder
基本編碼器 $g_{\theta}(.): \mathbb{R}^{\left|\mathcal{V}^{\prime}\right| \times d_{x}^{\prime}} \times \mathbb{R}^{\left|\mathcal{V}^{\prime}\right| \times\left|\mathcal{V}^{\prime}\right|} \longmapsto \mathbb{R}^{\left|\mathcal{V}^{\prime}\right| \times d_{h}} \times \mathbb{R}^{d_{h}}$ 是一個共用的圖編碼器,的增強接收增強圖 $G^{\prime}=\left(\mathcal{V}^{\prime}, \mathcal{E}^{\prime}\right)$ 從相應的增強頭接收一個增強圖 $G^{\prime}=\left(\mathcal{V}^{\prime}, \mathcal{E}^{\prime}\right)$,並學習一組節點表示 $\mathbf{H}_{v}^{\prime} \in \mathbb{R}^{\left|\mathcal{V}^{\prime}\right| \times d_{h}} $ 和增強圖 $G^{\prime}$ 上的圖表示 $h_{G}^{\prime} \in \mathbb{R}^{d_{h}}$。學習增強的目標是幫助基編碼器學習這些增強的不變性,從而產生魯棒的表示。基礎編碼器用策略和增強頭進行訓練。在推理時,輸入圖被直接輸入給基編碼器,以計算下游任務的編碼。
2.5 Training
本文采用 InfooMax 目標函數:
$\underset{\omega, \mu \phi_{i}, \phi_{j}, \theta}{\text{max}} \frac{1}{|\mathcal{G}|} \sum\limits _{G \in \mathcal{G}}\left[\frac{1}{|\mathcal{V}|} \sum_{v \in \mathcal{V}}\left[\mathrm{I}\left(h_{v}^{i}, h_{G}^{j}\right)+\mathrm{I}\left(h_{v}^{j}, h_{G}^{i}\right)\right]\right]$
其中,$\omega$, $\mu$, $\phi_{i}$, $\phi_{j}$, $\theta$ 是待學習模組的引數,$h_{v}^{i}$、$h_{G}^{j}$ 是由增強 $i$ 和 $j$ 編碼的節點 $v$ 和圖 $G$ 的表示,$I$ 是互資訊估計量。我們使用 Jensen-Shannon MI estimator:
$\mathcal{D}(., .): \mathbb{R}^{d_{h}} \times \mathbb{R}^{d_{h}} \longmapsto \mathbb{R}$ 是一個鑑別器,它接受一個節點和一個圖表示,並對它們之間的一致性進行評分,並實現為 $\mathcal{D}\left(h_{v}, h_{g}\right)=h_{n} \cdot h_{g}^{T}$。我們提供了來自聯合分佈 $p$ 的正樣本和來自邊緣 $p \times \tilde{p}$ 乘積的負樣本,並使用小批次隨機梯度下降對模型引數進行了優化。我們發現,通過訓練基編碼器和增強編碼器之間的隨機交替來正則化編碼器有助於基編碼器更好地泛化。為此,我們在每一步都訓練策略和增強頭,但我們從伯努利中取樣,以決定是更新基編碼器還是增強編碼器的權值。演演算法1總結了訓練過程。

3 Experiments
資料集
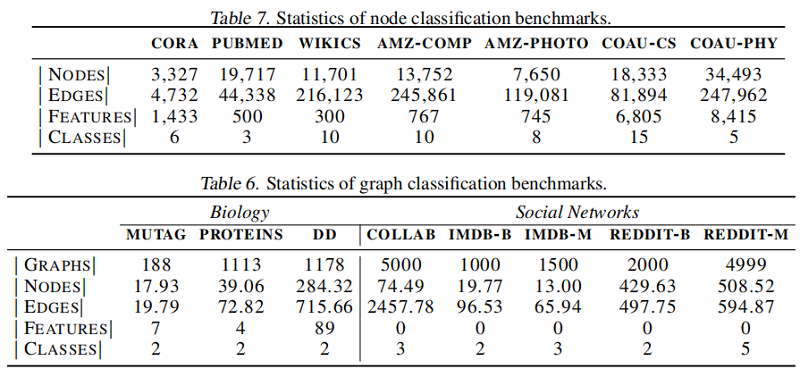
節點分類
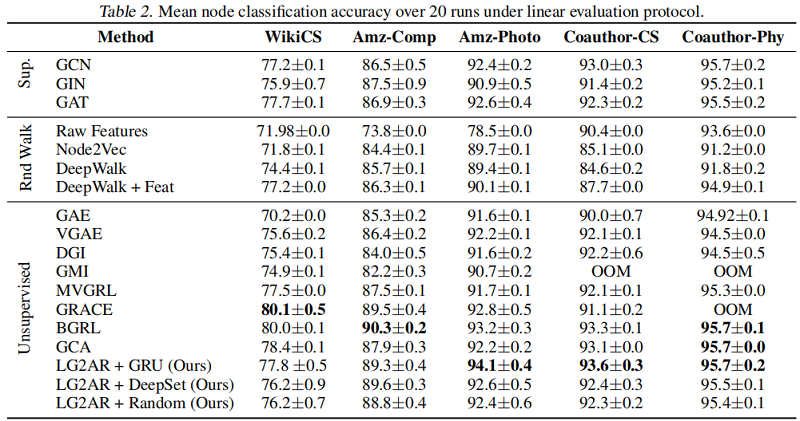
圖分類
4 Conclusion
我們引入了LG2AR和端到端框架來自動化圖對比學習。所提出的框架可以端到端學習增強、檢視選擇策略和編碼器,而不需要為每個資料集設計增強的特別試錯過程。實驗結果表明,LG2AR在8個圖分類中的8個上取得了最先進的結果基準測試,與以前的無監督方法相比,7個節點分類基準測試中的6個。結果還表明,LG2AR縮小了與監督同行的差距。此外,研究結果表明,學習策略和學習增強功能都有助於提高效能。在未來的工作中,我們計劃研究所提出的方法的大型預訓練和遷移學習能力。
修改歷史
2022-06-26 建立文章
因上求緣,果上努力~~~~ 作者:Learner-,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/16409040.html