DAST 黑盒漏洞掃描器 第五篇:漏洞掃描引擎與服務能力
0X01 前言
轉載請標明來源:https://www.cnblogs.com/huim/
本身需要對外有良好的服務能力,對內流程透明,有紀錄檔、問題排查簡便。
這裡的服務能力指的是系統層面的服務,將掃描器封裝成提供給業務的業務服務能力不在該篇講述範圍內
0X02 簡單的掃描
高階的漏洞往往用最樸實的掃描方法
最簡單的掃描需求,只需要從資料庫中讀取資料,定期跑一遍所有規則就好了。

一個指令碼更新資產,一個指令碼定時讀取資料、結合規則進行掃描、並把結果打到資料庫裡,一個指令碼定時讀取結果發郵件,這樣就已經滿足SRC自動化挖漏洞的需求了,而且效果還不錯。
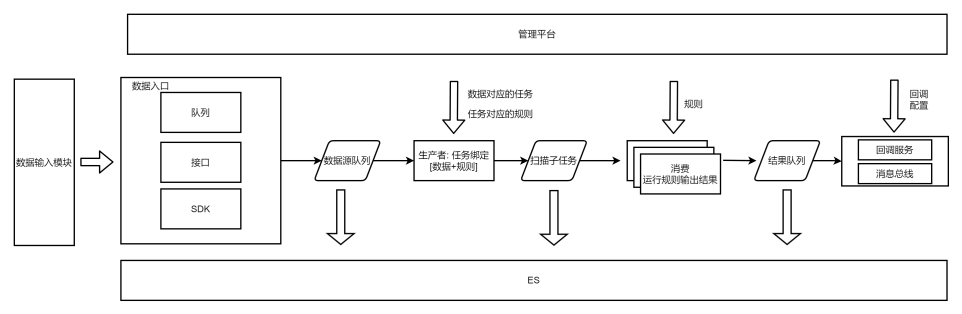
0X03 分散式掃描
隨著掃描的資產變多,單個機器的龜速掃描令人著急,所以執行規則這一步加上分散式,即任務打到佇列(redis/MQ/kafka等),再由多個節點執行掃描規則、輸出漏洞結果

0X04 幾個資料來源掃描
這樣很方便的可以掃描主機漏洞
再往後,不想只單單的掃描主機漏洞了,也想掃描注入/XSS/SSRF/XXE等基於url的漏洞,有了url型別資料。
甚至發現有的漏洞應該是針對域名的(單純的IP+埠請求到達不了負載均衡),又有了domain型別的資料。

0X05 多工掃描
這時候生產模組還能應付得過來,即讀取各型別資料、繫結各型別外掛。
但是有時候新增了規則,想單純的掃描對著所有資料掃描這條規則,需要另外起指令碼加一個臨時的生產者。
有時候新增了一批資產,想單獨對著這批資產掃描所有的規則,又需要臨時寫個生產者指令碼。
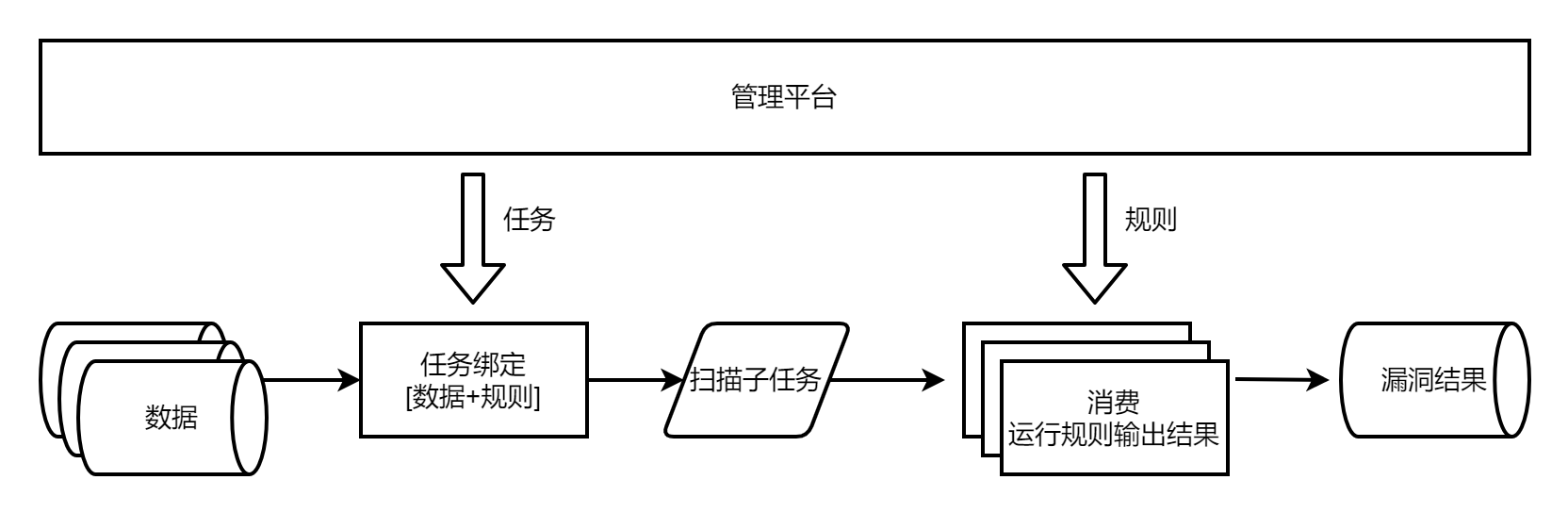
由此程式碼變得冗雜,操作變得繁瑣,於是有了任務的概念。
任務用於繫結資料與規則,一個任務就是一個生產掃描子任務的單位。
這樣增量規則掃描全量資料,新增一個任務繫結這個規則和對應的資料;增量資產掃描全量規則,新增一個任務繫結這批資產和對應的規則。
而從資料庫上操作任務與規則變得不太方便,於是加上了視覺化平臺,可在web端釋出掃描任務、新增修改規則。
0X06 多資料來源掃描
而在甲方內部,隨著接入的資料來源越來越多,url資料有映象流量、爬蟲流量、代理流量、nginx流量等等,host資料有hids agent流量、黑盒資產探測流量、cmdb/IT等流量,domain有域名爆破流量、內部運維繫統獲取的流量等。
每多一個資料來源,都得加一段程式碼邏輯 : "當資料來源是a的時候,從哪哪哪獲取流量資料"。
當資料來源數量超過十種,任務模組的資料來源獲取程式碼變得很冗雜,且並寫死橫行(從哪哪哪獲取資料)、邏輯寫死不通用(a的資料要從介面分頁遍歷、b的資料需要從redis讀、c的資料是kafka、d的資料從資料庫獲取)。
某些資料不走中間的某段過濾匹配邏輯,於是又要加一個欄位 is_xxx 標識 ,再在引擎裡 if is_xxx=True,程式碼通用性低、高度耦合,遇到bug時排查成本極高,比如遇到這個流量怎麼會有這樣的輸出結果、怎麼會報錯這類問題時,往往花半天一天追蹤流量。
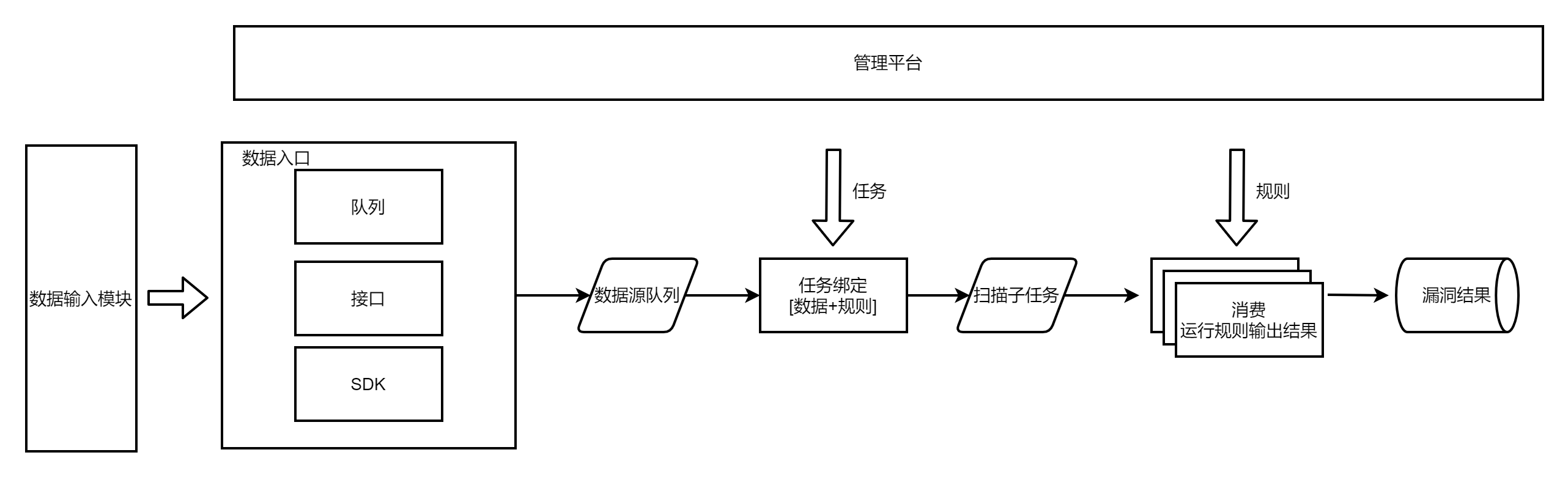
故而需要對資料來源進行改造,統一資料來源輸入格式,資料來源分幾種型別,url/host/domain,每種型別都有固定的格式,由外部按照這種格式進行輸入。
在資料來源過多時,外部的輸入程式碼太多了,可額外抽象出來形成資料輸入模組。
比如定義redis型別資料從哪裡獲取、介面怎麼分頁獲取資料、資料庫怎麼迭代讀取等,再一一設定資料格式轉換方式。這樣再遇到需要新增的流量型別,需要新增的程式碼就是可複用的某類資料獲取方式。
0X07 系統間服務能力
但是又遇到一個問題,遇到跨部門或者跨專案需要呼叫掃描能力時,很不方便,輸入上需要自己設定資料來源,還需要掃描開發人員新增這類資料,掃描結果還需要去資料庫獲取,有的沒結果不知道到底是沒掃描還是沒漏洞。
對於業務方,需求增改、服務呼叫不方便。
所以需要提高服務提供的能力,對於呼叫方來說,掃描是一個黑箱子,只管傳入資料、啟動任務、獲取結果,提供給呼叫方的是掃描服務能力。
對於掃描引擎開發方,對外進行引擎能力封裝,服務與上下游拆分開,也實現低耦合、高可維護、可延伸易擴充套件,不會因需求增改而頻繁改動引擎程式碼、從而導致程式碼冗餘、開發維護成本上升。
實現方式:
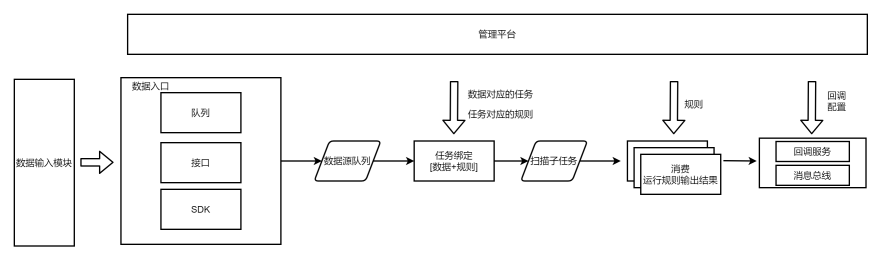
資料接入時,呼叫方在管理平臺註冊資料標籤,並在傳入資料時標明資料標籤(抽象資料設定步驟);
結果輸出時,呼叫方註冊回撥介面(資料打往回撥介面),掃描結果分有漏洞/無漏洞/沒掃描這一類,回撥介面選擇接收的結果型別;或註冊處置結果標籤,掃描結果打給訊息匯流排。
回撥方式不知道對方介面設定的狀態,可能介面報錯了訊息沒有正確打過去,可能介面返回200的 status: false但無法判斷是失敗了,簡單來講就是無法保證資料一致性,掃描結果裡有但介面因為報錯沒有這個結果。所以還是儘量使用訊息匯流排的方式,由消費方對消費失敗的資料進行記錄、排查並作再消費,保證接收結果的介面不會丟資料。
再由註冊方操作任務,繫結待掃描的流量的標籤,需要掃描的規則,處置的方式即結果是打給某個回撥或者是打上某個結果標籤。
實現效果:
這樣將引擎封裝起來,基本可以保證引擎中不會因為過多的資料來源,而東一塊西一塊,有很多的針對不同資料來源讀取的程式碼。
引擎本身只保證資料讀取、按照規定的任務選擇掃描規則、將掃描的結果打到結果佇列或者打回給呼叫方。
0X08 全流程紀錄檔
但還有另外一個問題,排查問題成本比較大。
掃描器引擎邏輯相比部分產品會比較複雜,主要涉及到其中的存活檢測、叢集判斷、白名單限制、QPS控制、任務排程等功能,有時候丟流量或者因為某個欄位不對導致漏報、在外掛執行前請求的內容有問題導致判斷為不存活的流量從而漏報。
這些情況在以redis為佇列的引擎中,排查起來比較麻煩。
所以需要全流程的紀錄檔:最好能知道幾個關鍵步驟的中間結果是什麼樣的,遇到問題時排查方便。掃描器在去重後掃描中間過程資料量不如IDS大 (日百億處理結果),大概也就上千萬,可以全部記錄下來,資源緊張可以只記錄一段時間。
關於紀錄檔種類:我們溯源排查時一般需要的中間結果有資料來源、掃描子任務、掃描結果。
關於紀錄檔實現:redis pop後資料就沒了,引擎讀後做雙寫比較麻煩。
所以選擇可訂閱的訊息佇列,比如kafka,引擎使用一個group進行訊息消費,再起一個服務用另外的group對這批topic的資料進行儲存,熟悉的ELK結構。