一文精通HashMap靈魂七問,你學還是不學
如果讓你看一篇文章,就可以精通HashMap,成為硬剛才面試官的高手,你學還是不學?
彆著急,開始之前不如先嚐試回來下面幾個問題吧:
HashMap的底層結構是什麼?
什麼時候HashMap中的連結串列會轉化為紅黑樹?
為什麼當連結串列長度超過8個時候會轉化成紅黑樹?這為什麼是8個而不是3個呢?
HashMap是執行緒安全的嘛?
HashMap為什麼是執行緒不安全的?有哪些具體體現?
ConcurrentHashMap和HashTable是如何實現執行緒安全的呢?有何不同呢?
一、HashMap底層結構是什麼樣的?
HashMap底層是陣列+連結串列+紅黑樹組成的複合結構。
陣列被分為一個個的桶(bucket),通過雜湊值決定鍵值對在陣列中儲存的位置;
當鍵值對的雜湊值相同,則以連結串列形式儲存;
當連結串列長度大於或等於閾值(預設為 8)的時候,如果同時還滿足容量大於或等於 MIN_TREEIFY_CAPACITY(預設為 64)的要求,就會把連結串列轉換為紅黑樹。同樣,後續如果刪除了元素,當紅黑樹的節點小於或等於 6 個以後,又會恢復為連結串列。
HashMap 的結構示意圖:
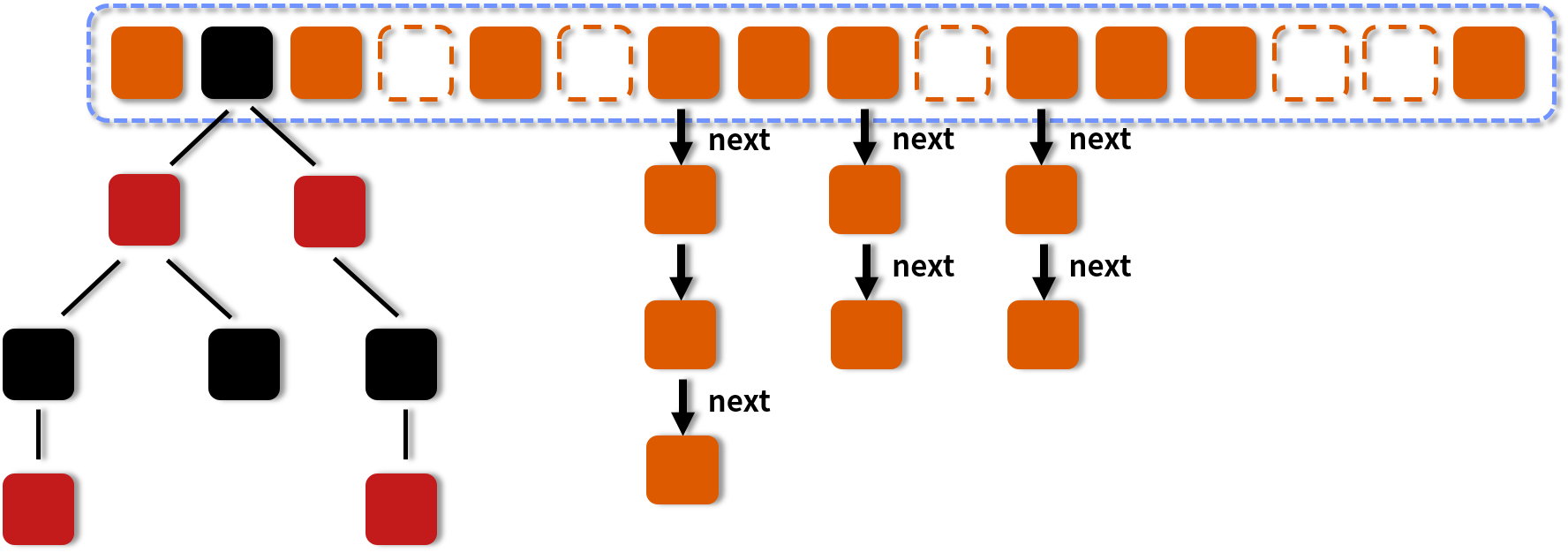
二、為什麼需要將連結串列轉化為紅黑樹呢?
因為紅黑樹有和連結串列不一樣的查詢效能。從連結串列中查詢一個元素,時間複雜度是 O(n)。而從紅黑樹查詢,由於紅黑樹有自平衡的特點,可以防止不平衡情況的發生,所以時間複雜是 O(log(n))。如果連結串列長度較短,O(n) 和 O(log(n)) 的區別不大,但是如果連結串列較長,那麼這種差異就會很明顯了。所以為了提升HashMap查詢效能,在連結串列長度超過閾值的時候將連結串列轉化為紅黑樹進行儲存。
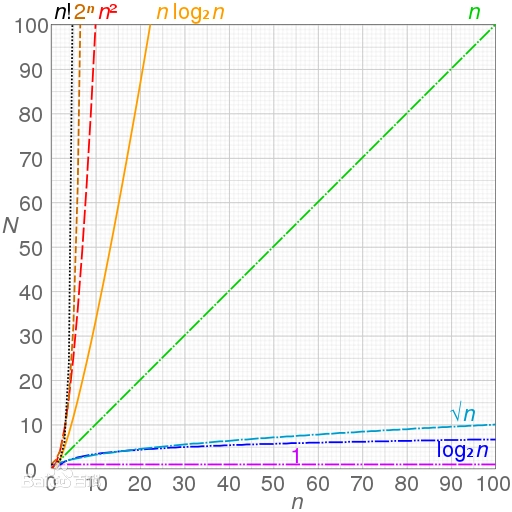
三、既然紅黑樹查詢效能優於連結串列,那為什麼不在一開始就使用紅黑樹呢?而是要經歷一個轉換的過程呢?
世上本沒有「銀彈」,紅黑樹也不是「銀彈」。單個 TreeNode 需要佔用的空間大約是普通連結串列Node 的兩倍,所以只有當包含足夠多的 Nodes 時才會轉成 TreeNodes,而是否足夠多就是由 TREEIFY_THRESHOLD 的值決定的。而當桶中節點數由於移除或者 resize 變少後,又會變回普通的連結串列的形式,以便節省空間。
這其實是一種tradeoff,指的是一種取捨、一種權衡,最後達成折中平衡。在HashMap裡面,如果要效能就需要犧牲空間,要空間就要犧牲效能,魚與熊掌不可兼得,最後達成折中方案:連結串列加紅黑樹,在適當情況下進行轉化。
四、為什麼連結串列轉化為紅黑樹的這個閾值要預設設定為 8 呢?
如果 hashCode 分佈良好,也就是雜湊演演算法足夠好,計算出來的雜湊值散離散程度高,那麼很少出現雜湊衝突和連結串列很長的情況,紅黑樹這種形式也就很少會被用到。在理想情況下,連結串列長度符合泊松分佈,各個長度的命中概率依次遞減,當長度為 8 的時候,概率僅為 0.00000006。這是一個小於千萬分之一的概率,通常我們的 Map 裡面是不會儲存這麼多的資料的,所以通常情況下,並不會發生從連結串列向紅黑樹的轉換。請看原始碼(本文原始碼均為Java8版本)註釋:
* Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
如果在偵錯過程中發現HashMap中的連結串列結構經常轉換為紅黑樹進行儲存,那麼這時候應該注意下雜湊函數是不是出現問題了。
五、對比一下Hashtable、HashMap、TreeMap 有什麼不同?
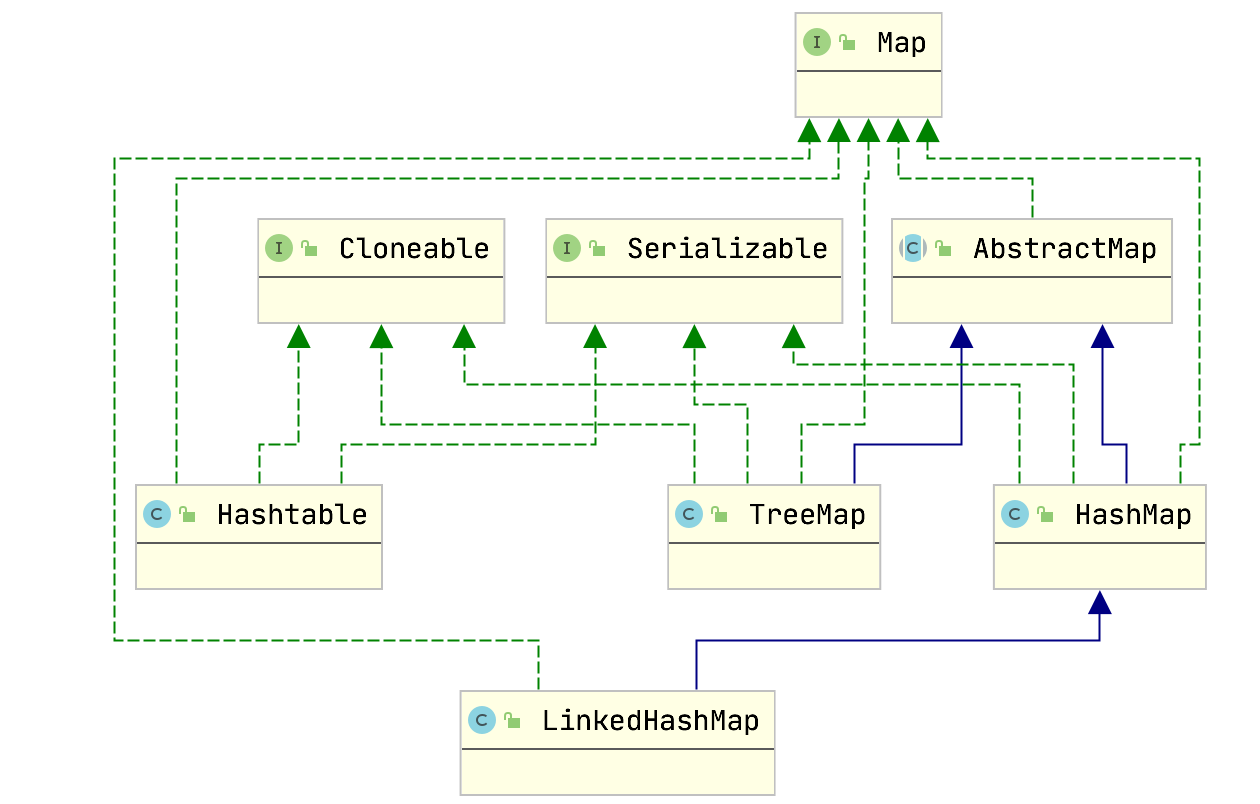
Hashtable、HashMap、TreeMap 都是最常見的Map實現,是以鍵值對的形式儲存和運算元據的容器型別。
Hashtable 是早期 Java 類庫提供的一個雜湊表實現,本身是同步的,不支援 null 鍵和值,由於同步導致的效能開銷,所以已經不建議使用。
HashMap 是目前最常用的雜湊表實現,與 HashTable 的主要區別在於: HashMap 不是同步的,支援 null 鍵和值等。通常情況下,HashMap 進行 put 或者 get 操作,可以達到常數時間的效能,所以它是絕大部分利用鍵值對存取場景的首選。
TreeMap 則是基於紅黑樹的一種提供順序存取的 Map,和 HashMap 不同,它的 get、put、remove 之類操作都是 O(log(n))的時間複雜度,如果有排序的訴求可以選擇使用。
六、HashMap為什麼是執行緒不安全的?具體有哪些體現?
put方法中的++modCount
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
++modCount和 ++size看似一行程式碼,但是該操作並不能保證原子性,實際上是分三個步驟執行的,會存在並行問題。modCount這個引數在HashMap中表述HashMap內部結果改變的次數,例如rehash。如果++modCount發生並行問題,會丟擲ConcurrentModificationException。
在put方法中,通過比較++size和threshold的大小判斷是否進行擴容操作,如果++size發生並行問題,可能使得HashMap在應該擴容的時候未進行擴容,導致put操作的時候元素插入失敗或者丟失。
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;
擴容期間取出來值不準確
HashMap 預設初始容量為16,如果不停地往 map 中新增新的資料,當元素個數大於負載因子容量大小的時候,會進行擴容,擴至原來的2倍。
newThr = oldThr << 1
在擴容期間,它會新建一個新的空陣列,並且將老陣列中的元素重新放置到新陣列中。那麼,在這個填充的過程中,如果有執行緒獲取值,很可能會取到 null 值。
同時put導致資料丟失
比如,有多個執行緒同時使用 put 方法來新增元素,而且恰好兩個 put 的 key 的雜湊值是一樣的,計算出來的 bucket 位置一樣,並且兩個執行緒又同時判斷該位置是空的,可以寫入,所以這兩個執行緒的兩個不同的 value 便會新增到陣列的同一個位置,這樣最終就只會保留一個資料,丟失一個資料。
死迴圈造成CPU100%
該問題是多執行緒同時擴容的時候連結串列死迴圈而引起的CPU100%問題。可參考:https://coolshell.cn/articles/9606.html
七、同樣是執行緒安全的,ConcurrentHashMap和Hashtable有什麼區別?ConcurrentHashMap在Java7 和Java8又有何不同?
雖然 ConcurrentHashMap 和 Hashtable 它們兩個都是執行緒安全的,但是從原理上分析,Hashtable 實現並行安全的原理是通過 synchronized 關鍵字實現的。
ConcurrentHashMap在Java7中是通過Segment實現執行緒安全的,在Java8是通過Node + CAS + synchronized實現的。
Java7中的ConcurrentHashMap最外層是多個Segment,每個Segment的底層資料結構與HashMap類似,仍然是陣列加連結串列組成。
Java8中的ConcurrentHashMap依然是陣列+ 連結串列+ 紅黑樹的方式實現的,結構和HashMap一致。
ConcurrentHashMap在Java7 和Java8的對比如下:
| Java7 | Java8 | |
|---|---|---|
| 資料結構 | Segment + 陣列+連結串列 | 陣列+連結串列+紅黑樹 |
| 並行原理 | Segment | Node + CAS + synchronized |
| 並行度 | Segment個數,預設16 | 陣列長度 |
| Hash衝突 | 拉鍊法 | 拉鍊法+紅黑樹 |
如果看完有幫忙,能不能幫我點個贊呢?