Stream常用操作以及原理探索
Stream常用操作以及原理
Stream是什麼?
Stream是一個高階迭代器,它不是資料結構,不能儲存資料。它可以用來實現內部迭代,內部迭代相比平常的外部迭代,它可以實現並行求值(高效,外部迭代要自己定義執行緒池實現多執行緒來實現高效處理)、惰性求值(中沒有終止操作,中間操作是不會執行的)、短路操作(拿到正確的結果就返回,不需要等到整個過程完成之後)等
-
Stream翻譯過來的意思就是「溪流,流」的意思,而我們剛開始學習java的時候接觸最多的就是IO流,它更像「農夫山泉」,「我們只做大自然的搬運工」,只是將一個檔案從這個地方傳到另一個地方,對於檔案當中內容不做任何增刪改操作,而Stream就會,也就是將要處理的資料當作流,在管道中進行傳輸,並在管道中的每個節點對資料進行處理,如過濾、排序、轉換等;
-
通常我們需要處理的資料是以Collection、Array等資料來源;
-
Stream它是Java8中的一個新特性,那關於Java8中的其他新特性內容可以參考這篇文章《Java8新特性實戰》;
-
那既然是Java8的新特性,而且我們也知道Java8大改動之一的就是增加了函數語言程式設計,而Stream就主角,那有關函數語言程式設計是什麼,可以參考知乎上的一篇文章《什麼是函數語言程式設計?》;
-
既然是函數語言程式設計,所以通常是配合Lambda表示式使用;
Stream怎麼用?
所有操作分類
首先Stream的所有操作可分為兩類,一是中間操作,二是終止操作
中間操作:中間操作只是一種標記,只有結束操作才會觸發實際計算
- 無狀態:指元素的處理不受前面元素的影響;
- 有狀態:有狀態的中間操作必須等到所有元素處理之後才知道最終結果,比如排序是有狀態操作,在讀取所有元素之前並不能確定排序結果。
終止操作:顧名思義,就是得出最後計算結果的操作
- 短路操作:指不用處理全部元素就可以返回結果;
- 非短路操作:指必須處理所有元素才能得到最終結果。
此外這裡我看到有的地方將collect定義為了中間操作,但通過我看了大部分對Stream的介紹,發現Collect這個收集操作是最終止操作,畢竟這也符合我們平時所用到它的場景,所以還請加以辨別有的文章中提到的collect是中間操作的錯誤解釋。

常用操作
以下兩張圖是對stream的常用操作做了一個簡單使用案例,原本流程圖在這Java8新特性


那至於常用操作這塊,本次部落格也不在進行過多的細說,因為網上有很多這種使用型別的文章,我常看的有這三篇文章:
-
- 作者是不高興就喝水,雖然這個題目名字有點不符文章內容,但內容還是很肝的,主要是一些應用例子。
-
- 作者是JavaGuide,裡面簡單的提了一些操作
-
- 作者是芋道原始碼,主要是對我們平時會用List、Set、Map這些集合型別做排序的例子
-
- 這個是自己當時在使用集合的時候看到的一篇文章,可以作為補充看看
為什麼使用Stream?
宣告式處理資料
第一個原因我覺得是Stream流可以以宣告式的方式去處理資料,也就是像它其中就有filter、sort這種以及寫好的操作,只需要拿來使用即可,如果我們平時使用for迴圈,還要在for迴圈中自己去寫怎麼過濾的這些操作,最後才得出自己想要的結果,對比這種命令式的操作
可以說讓我們程式碼更加乾淨、簡潔。
對比for迴圈
對於與for迴圈效率的對比,我覺得和以下內容差不多,但搜尋網上資料來證明某一觀點正確的我目前沒有找到,很多人持有觀點就是「犧牲程式碼效率來換取程式碼簡潔度」,「Stream的優勢在於有並行處理」,「Stream的效率與for差不多,為了程式碼簡潔更偏向Stream」等。
但是犧牲程式碼效率換程式碼簡潔度我覺得還是有問題的,不能一概而論。但是函數語言程式設計的優點就是程式碼簡潔,多核友好並行處理這是不可否認的。
- 針對不同的資料結構,Stream流的執行效率是不一樣的
- 針對不同的資料來源,Stream流的執行效率也是不一樣的
- 對於簡單的數位(list-Int)遍歷,普通for迴圈效率的確比Stream序列流執行效率高(1.5-2.5倍)。但是Stream流可以利用並行執行的方式發揮CPU的多核優勢,因此並行流計算執行效率高於for迴圈。
- 對於list-Object型別的資料遍歷,普通for迴圈和Stream序列流比也沒有任何優勢可言,更不用提Stream並行流計算。
雖然在不同的場景、不同的資料結構、不同的硬體環境下。Stream流與for迴圈效能測試結果差異較大,甚至發生逆轉。但是總體上而言:
- Stream並行流計算 >> 普通for迴圈 ~= Stream序列流計算 (之所以用兩個大於號,你細品)
- 資料容量越大,Stream流的執行效率越高。
- Stream並行流計算通常能夠比較好的利用CPU的多核優勢。CPU核心越多,Stream並行流計算效率越高。
- 如果資料在1萬以內的話,for迴圈效率高於foreach和stream;如果資料量在10萬的時候,stream效率最高,其次是foreach,最後是for。另外需要注意的是如果資料達到100萬的話,parallelStream非同步並行處理效率最高,高於foreach和for
處理集合資料
Stream可以說是Java8中對於處理集合的抽象概念,所以我們經常對集合中的資料採用像SQL這種類似方式去處理;所以經常會用Stream進行遍歷操作,那相較於我們以前寫的巢狀for迴圈可以說是程式碼更加的簡潔,更直觀易讀。當然迴圈只是迴圈,而Stream是個流的形式去做處理。那如何去做迭代,那就得看看stream的原理了。
惰性計算
惰性計算我們也可以稱作惰性求值或者延遲求值,這種方式在函數語言程式設計中極為常見,也就是當計算出結果後不立馬去返回值,而是在它要被用到的時候來計算;
在Stream中,我們就可以看作中間操作,比如當要對一個List集合做出Stream操作,比如filter,但是沒有最終操作,它返回的還是一個Stream流。也就是我們可以看作下圖這種方式。

與Collection的不同點
從實現角度比較, Stream和Collection也有眾多不同:
- 不儲存資料。 流不是一個儲存元素的資料結構。 它只是傳遞源(source)的資料。
- 功能性的(Functional in nature)。 在流上操作只是產生一個結果,不會修改源。 例如filter只是生成一個篩選後的stream,不會刪除源裡的元素。
- 延遲搜尋。 許多流操作, 如filter, map等,都是延遲執行。 中間操作總是lazy的。
- Stream可能是無界的。 而集合總是有界的(元素數量是有限大小)。 短路操作如limit(n) , findFirst()可以在有限的時間內完成在無界的stream
- 可消費的(Consumable)。 不是太好翻譯, 意思流的元素在流的宣告週期內只能存取一次。 再次存取只能再重新從源中生成一個Stream
Stream原理
也許我們會覺得,Stream的實現是每一次去呼叫函數,它就會進行一次迭代,這肯定是不對的,這樣Stream的效率是很低的。
其實事實是我們可以通過看原始碼來發現它是怎樣迭代的,其實Stream內部是通過流水線(Pipeline)的方式來實現的,基本思想是在迭代的時候順著流水線(Pipeline)儘可能的執行更多的操作,從而避免多次迭代。
也就是說Stream在執行中間操作時僅僅是記錄,當用戶呼叫終止操作時,會在一個迭代裡將已經記錄的操作順著流水線全部執行掉。沿著這個思路,有幾個問題需要解決:
- 使用者的操作如何記錄?
- 操作如何疊加?
- 疊加之後的操作如何執行?
關鍵問題解決
以上我們可以知道Stream的完整操作,是一個由<資料來源、操作、回撥函數>組成的三元組;
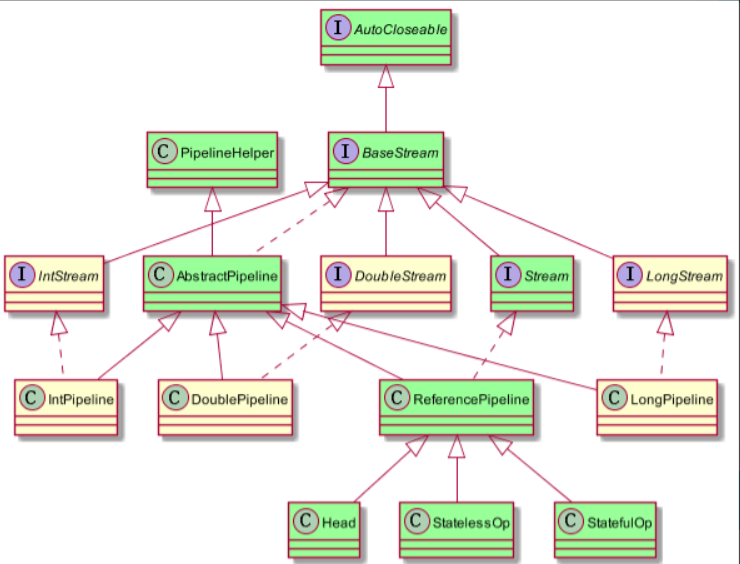
此外我們還需要知道Stream的相關類與介面的繼承關係。如下圖:
- 從圖中可以看出我們除了基本型別以外,參照型別是通過範例化的ReferencePipeline來表示
- 而與ReferencePipeline並行三個類是為其基本型別客製化的。
1.操作如何記錄?
- 首先JDK原始碼中經常會用stage(階段)來標識一次操作。
- 其次,Stream操作通常需要一個回撥函數(Lambda表示式)

從以上我們可以看出,當我們呼叫stream方法時,最終會去建立一個Head範例來表示操作頭,也就是第一個stage,當呼叫filter()方法時則會建立中間操作範例StatelessOp(無狀態),接著呼叫map()方法時則會建立中間操作範例StatelessOp(無狀態),最後呼叫sort()方法時會建立最終操作範例StatefulOp(有狀態),同樣呼叫其他操作對應的方法也會生成一個ReferencePipeline範例,通過呼叫這一系列操作最終形成一個雙向連結串列,即每個Stage都記錄了前一個Stage和本次的操作以及回撥函數。
原始碼:
1.呼叫stream,建立Head範例
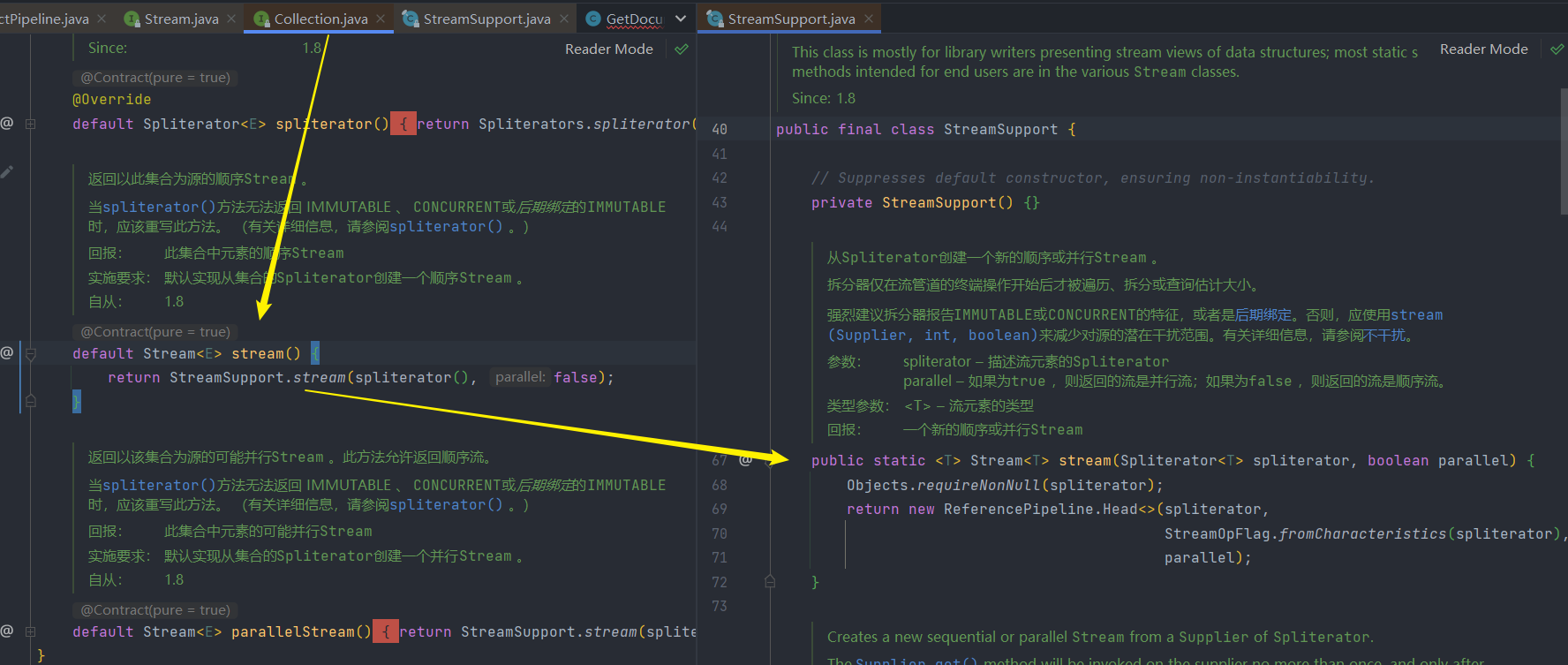
2.呼叫filter或map中間操作
- 這些中間操作以及最終操作都在ReferencePipeline這個類中,它實現其元素型別的中間管道階段或管道源階段的抽象基礎類別。
下面程式碼邏輯就是將回撥函數mapper包裝到一個Sink當中。由於Stream.map()是一個無狀態的中間操作,所以map()方法返回了一個StatelessOp內部類物件(一個新的Stream),呼叫這個新Stream的opWripSink()方法將得到一個包裝了當前回撥函數的Sink。
這個Sink就是下面提到的操作如何疊加方式。
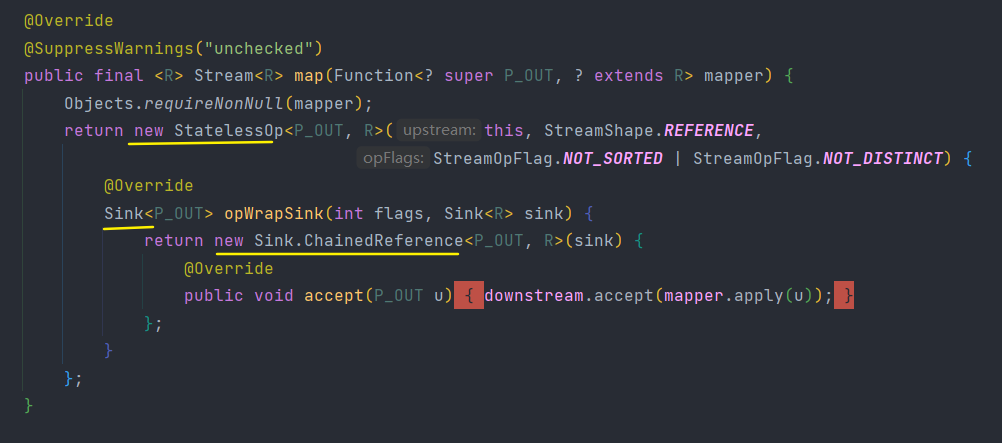
2.操作如何疊加?
從上面我們可以知道Stream通過stage來記錄操作,但stage只儲存當前操作,它是不知道怎麼操作下一個stage,它又需要什麼操作。
所以要執行的話還需要某種協定將各個stage關聯起來。
JDK中就是使用Sink(我們可以稱為「匯聚結點」)介面來實現的,Sink介面定義begin()、end()、cancellationRequested()、accept()四個方法,如下表所示。
| 方法名 | 作用 |
|---|---|
| void begin(long size) | 開始遍歷元素之前呼叫該方法,通知Sink做好準備。 |
| void end() | 所有元素遍歷完成之後呼叫,通知Sink沒有更多的元素了。 |
| boolean cancellationRequested() | 是否可以結束操作,可以讓短路操作儘早結束。 |
| void accept(T t) | 遍歷元素時呼叫,接受一個待處理元素,並對元素進行處理。Stage把自己包含的操作和回撥方法封裝到該方法裡,前一個Stage只需要呼叫當前Stage.accept(T t)方法就行了。 |
Sink介面註釋檔案:
Consumer的擴充套件,用於通過流管道的各個階段傳遞值,具有管理大小資訊、控制流等的附加方法。在第一次呼叫Sink上的accept()方法之前,您必須首先呼叫begin()方法來通知它有資料來了(可選地通知接收器有多少資料來了),並且在所有資料都傳送之後,你必須呼叫end()方法。在呼叫end()之後,您不應該在沒有再次呼叫begin() ) 的情況下呼叫accept() )。 Sink還提供了一種機制,通過該機制,sink 可以合作發出它不希望接收更多資料的訊號( cancellationRequested()方法),源可以在向Sink傳送更多資料之前輪詢該機制。
接收器可能處於以下兩種狀態之一:初始狀態和活動狀態。它從初始狀態開始; begin()方法將其轉換為活動狀態, end()方法將其轉換回初始狀態,在該狀態下可以重複使用。資料接受方法(如accept()僅在活動狀態下有效。
API 註釋:
流管道由一個源、零個或多箇中間階段(例如過濾或對映)和一個終端階段(例如歸約或 for-each)組成。具體來說,考慮管道:
int longestStringLengthStartingWithA
= strings.stream()
.filter(s -> s.startsWith("A"))
.mapToInt(String::length)
.max();
在這裡,我們分為三個階段,過濾、對映和歸約。過濾階段使用字串並行出這些字串的子集;對映階段使用字串並行出整數;歸約階段消耗這些整數並計算最大值。
Sink範例用於表示此管道的每個階段,無論該階段接受物件、整數、長整數還是雙精度數。 Sink 具有accept(Object) 、 accept(int)等的入口點,因此我們不需要每個原始特化的專用介面。 (對於這種雜食性趨勢,它可能被稱為「廚房水槽」。)管道的入口點是過濾階段的Sink ,它將一些元素「下游」傳送到對映階段的Sink ,然後將整數值向下遊傳送到Sink以進行縮減階段。與給定階段關聯的Sink實現應該知道下一階段的資料型別,並在其下游Sink上呼叫正確的accept方法。同樣,每個階段都必須實現與其接受的資料型別相對應的正確accept方法。
Sink.OfInt等特化子型別覆蓋accept(Object)以呼叫accept的適當原語特化,實現Consumer的適當原語特化,並重新抽象accept的適當原語特化。
Sink.ChainedInt等鏈子型別不僅實現Sink.OfInt ,還維護了一個表示下游Sink的downstream欄位,並實現了begin() 、 end()和cancellationRequested()方法來委託給下游Sink 。大多數中間操作的實現將使用這些連結包裝器。例如,上面範例中的對映階段如下所示:
IntSink is = new Sink.ChainedReference<U>(sink) {
public void accept(U u) {
downstream.accept(mapper.applyAsInt(u));
}
};
在這裡,我們實現Sink.ChainedReference<U> ,這意味著我們期望接收U型別的元素作為輸入,並將下游接收器傳遞給建構函式。因為下一階段需要接收整數,所以我們必須在向下遊傳送值時呼叫accept(int)方法。 accept()方法將對映函數從U應用到int並將結果值傳遞給下游Sink 。
interface Sink<T> extends Consumer<T> {}
從上面那張圖中呼叫ReferencePipeline.map()的方法,我們會發現我們在建立一個ReferencePipeline範例的時候,需要重寫opWrapSink方法來生成對應Sink範例。而且通過閱讀原始碼會發現常用的操作都會建立一個ChainedReference範例;
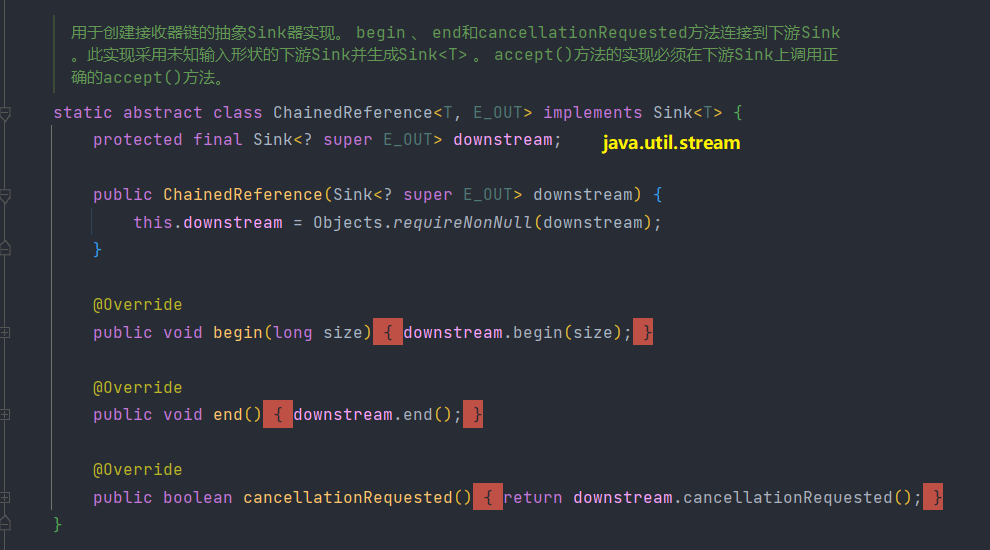
有了上面的協定,相鄰Stage之間呼叫就很方便了,每個Stage都會將自己的操作封裝到一個Sink裡,前一個Stage只需呼叫後一個Stage的
accept()方法即可,並不需要知道其內部是如何處理的。當然對於有狀態的操作,Sink的
begin()和end()方法也是必須實現的。比如Stream.sorted()是一個有狀態的中間操作,其對應的Sink.begin()方法可能建立一個乘放結果的容器,而accept()方法負責將元素新增到該容器,最後end()負責對容器進行排序。對於短路操作,
Sink.cancellationRequested()也是必須實現的,比如Stream.findFirst()是短路操作,只要找到一個元素,cancellationRequested()就應該返回true,以便呼叫者儘快結束查詢。Sink的四個介面方法常常相互共同作業,共同完成計算任務。
實際上Stream API內部實現的的本質,就是如何過載Sink的這四個介面方法
3.操作疊加後如何進行執行?
Sink完美封裝了Stream每一步操作,並給出了[處理->轉發]的模式來疊加操作。這一連串的齒輪已經咬合,就差最後一步撥動齒輪啟動執行。是什麼啟動這一連串的操作呢?也許你已經想到了啟動的原始動力就是結束操作(Terminal Operation),一旦呼叫某個結束操作,就會觸發整個流水線的執行。
結束操作之後不能再有別的操作,所以結束操作不會建立新的流水線階段(Stage),直觀的說就是流水線的連結串列不會在往後延伸了。結束操作會建立一個包裝了自己操作的Sink,這也是流水線中最後一個Sink,這個Sink只需要處理資料而不需要將結果傳遞給下游的Sink(因為沒有下游)。對於Sink的[處理->轉發]模型,結束操作的Sink就是呼叫鏈的出口。
我們再來考察一下上游的Sink是如何找到下游Sink的。
一種可選的方案是在PipelineHelper中設定一個Sink欄位,在流水線中找到下游Stage並存取Sink欄位即可。
但Stream類庫的設計者沒有這麼做,而是設定了一個
Sink AbstractPipeline.opWrapSink(int flags, Sink downstream)方法來得到Sink,該方法的作用是返回一個新的包含了當前Stage代表的操作以及能夠將結果傳遞給downstream的Sink物件。為什麼要產生一個新物件而不是返回一個Sink欄位?
這是因為使用opWrapSink()可以將當前操作與下游Sink(上文中的downstream引數)結合成新Sink。試想只要從流水線的最後一個Stage開始,不斷呼叫上一個Stage的opWrapSink()方法直到最開始(不包括stage0,因為stage0代表資料來源,不包含操作),就可以得到一個代表了流水線上所有操作的Sink,用程式碼錶示就是這樣:
類PipelineHelper
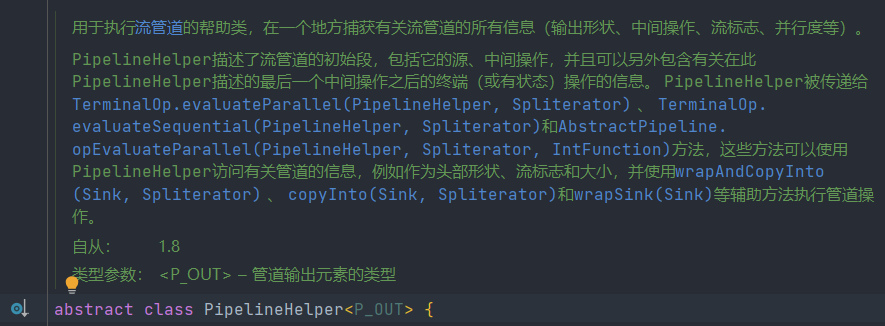

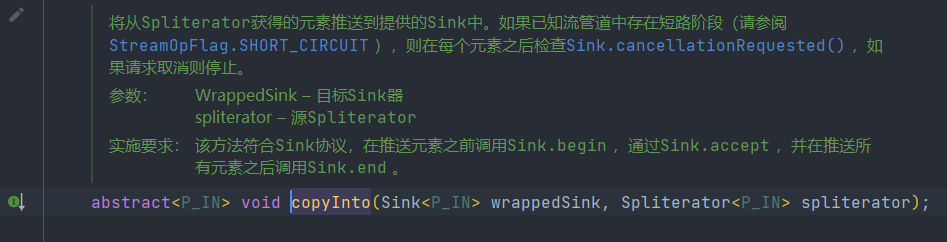
類 AbstractPipeline extends PipelineHelper
-
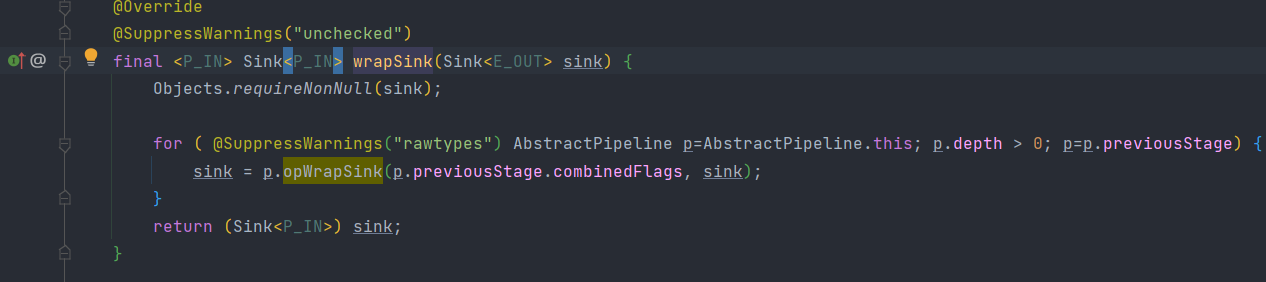
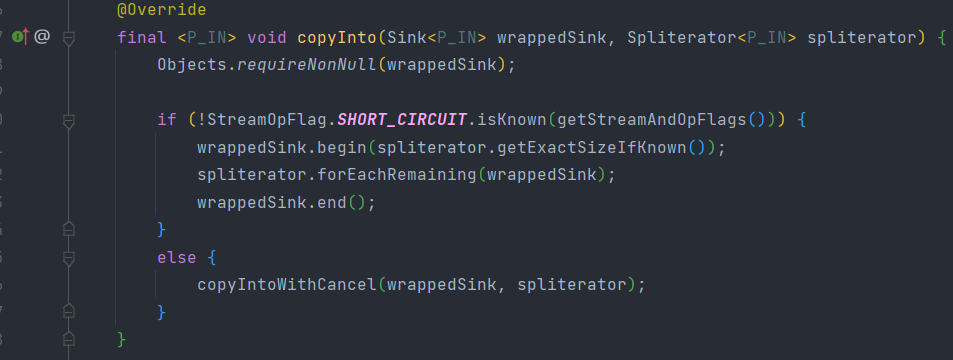
通過wrapSink方法得到從開始到結束的所有操作幷包裝在一個sink裡面,然後通過copyInto執行,就相當於整個流水線進行了執行
-
程式碼執行邏輯:首先呼叫wrappedSink.begin()方法告訴Sink資料即將到來,然後呼叫spliterator.forEachRemaining()方法對資料進行迭代,最後呼叫wrappedSink.end()方法通知Sink資料處理結束。

4.操作結果在哪?
針對不同型別的返回結果,下表給出了各種有返回結果的Stream結束操作:
| 返回型別 | 對應的結束操作 |
|---|---|
| boolean | anyMatch() allMatch() noneMatch() |
| Optional | findFirst() findAny() |
| 歸約結果 | reduce() collect() |
| 陣列 | toArray() |
- 對於表中返回boolean或者Optional的操作(Optional是存放 一個 值的容器)的操作,由於值返回一個值,只需要在對應的Sink中記錄這個值,等到執行結束時返回就可以了。
- 對於歸約操作,最終結果放在使用者呼叫時指定的容器中(容器型別通過[收集器](https://www.cnblogs.com/CarpenterLee/p/5-Streams API(II).md#收集器)指定)。collect(), reduce(), max(), min()都是歸約操作,雖然max()和min()也是返回一個Optional,但事實上底層是通過呼叫[reduce()](https://www.cnblogs.com/CarpenterLee/p/5-Streams API(II).md#多面手reduce)方法實現的。
- 對於返回是陣列的情況,毫無疑問的結果會放在陣列當中。這麼說當然是對的,但在最終返回陣列之前,結果其實是儲存在一種叫做Node的資料結構中的。Node是一種多叉樹結構,元素儲存在樹的葉子當中,並且一個葉子節點可以存放多個元素。這樣做是為了並行執行方便。
參考文章:
梳理
//例子:List<T> a = b.stream().map(m::getId()).collect(Collectors.toList())
//1.首先呼叫stream方法,看原始碼:
public interface Collection<E> extends Iterable<E> {
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
}
//2.進入StreamSupport
//3.發現用的ReferencePipeline建立的Head頭,進行此次操作記錄
public final class StreamSupport {
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
}
//4.呼叫中間操作map方法,發現中間操作和最終操作的那些操作都在此
//5.發現map操作是個StatelessOp(無狀態操作),同時此類繼承於AbstractPipeline,並重寫了opWrapSink方法;
//6.並通過Sink介面實現相鄰stage直接的連線,來進行操作記錄的疊加
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
}
//7.通過PipelineHelper中的wrapSink介面進行開始到結束的操作記錄包裝到一個Sink中
abstract class PipelineHelper<P_OUT> {
abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
}
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
}
//8.通過PipelineHelper中的copyInto介面執行stage
abstract class PipelineHelper<P_OUT> {
abstract<P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
}
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
}
//9.最後通過不同型別的操作型別來得出Stream的返回結果
最後
這些個人想說的話還是留在結尾吧,畢竟放前言好像有點不符,畢竟文章重點也不是這。
有一段時間沒有寫部落格了,還是得自我反省。反省的結果就是人喜歡偷懶,變得不會去對一段時間的學習內容進行一個總結,加之在整個寫部落格過程中需要梳理自己的思路,並且還要對自己寫的內容要有一定的正確性判斷,如此寫部落格的時間也隨之變長。漸漸地,自己也放鬆了下來,而這樣導致的最大問題就是自己的知識體系越來越碎,導致自己好像一直在學東西,但同時忘記的速度也在隨之變快,導致自己無法去正確在實踐當中去運用這些所學的技術以及知識點。
上次也說了,會總結設計模式的相關內容,但畢竟這種思想級別的東西,如果不通過理論加實踐,是很難總結出來一些對自己有用的東西的,而且這些內容畢竟放到自己網上部落格當中,那就不僅僅是自己在看了,我也不希望有一些和我一樣的菜鳥看完之後被文章所誤導。
Stream這個東西也算自己平時用的較多的一個東西,所以來進行一個總結。
文中如有錯誤,請各位大佬及時指出,並請不吝賜教。
警言: 無論人生上到哪一層臺階,階下有人在仰望你,階上亦有人在俯視你。你擡頭自卑,低頭自得,唯有平視,才能看見真實的自己。
轉載請註明原文連結:https://www.cnblogs.com/yuyueq/p/16413348.html
如果覺得這篇文章對你有小小的幫助的話,記得在右下角點個「推薦」哦,博主在此感謝你的支援!