ElasticSearch7.3學習(三十二)----logstash三大外掛(input、filter、output)及其綜合範例
圖片上面只是一少部分。詳情見網址:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
1.2 標準輸入(Stdin)
這種控制檯輸入前面已經介紹過了,這裡就不解析了。
連結:ElasticSearch7.3學習(三十一)----Logstash基礎學習
input{
stdin{
}
}
output {
stdout{
codec=>rubydebug
}
}1.3 讀取檔案(File)
比如說我存在一個nginx1.log檔案,檔案內容如下:
注意:檔案遊標要指向下一行,不然最後一行可能讀取不到
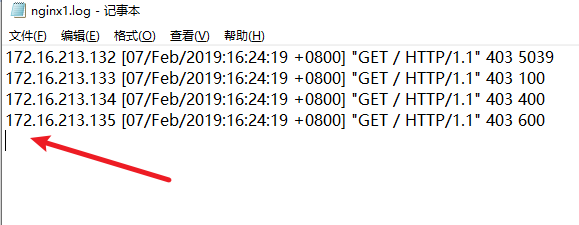
我想把檔案內容列印至控制檯顯示。可在config/test1.conf裡面新增如下內容,可採用萬用字元讀取多個檔案
input {
file {
path => ["E:/ElasticSearch/logstash-7.3.0/nginx*.log"]
start_position => "beginning"
}
}
output {
stdout {
codec=>rubydebug
}
}具體的執行方式參照:ElasticSearch7.3學習(三十一)----Logstash基礎學習
結果如下:
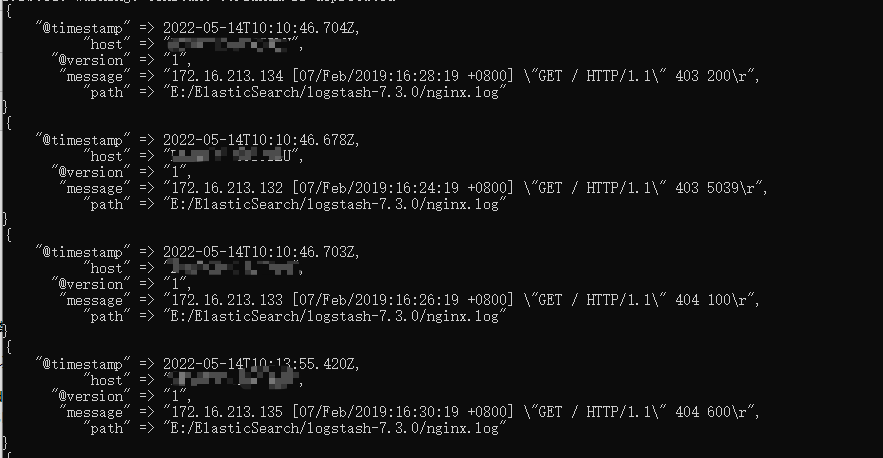
1.4 實時更新檔案
假如說我們往nginx1.log下新增加一條資料,看下效果
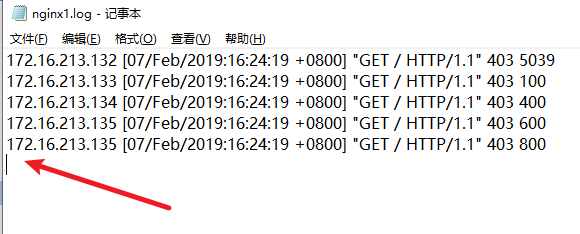
在生產環境下,服務一直在執行,紀錄檔檔案一直在增加,logstash會自動讀取新增的資料
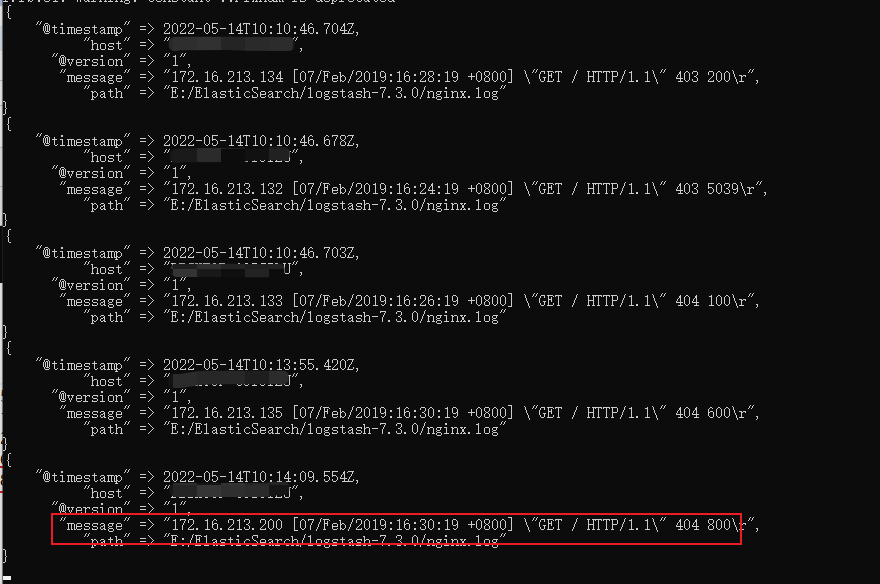
預設情況下,logstash會從檔案的結束位置開始讀取資料,也就是說logstash程序會以類似tail -f命令的形式逐行獲取資料。
logstash使用一個名為filewatch的ruby gem庫來監聽檔案變化,並通過一個叫.sincedb的資料庫檔案來記錄被監聽的紀錄檔檔案的讀取進度(時間戳),這個sincedb資料檔案的預設路徑在 <path.data>/plugins/inputs/file下面,檔名類似於.sincedb_123456,而<path.data>表示logstash外掛儲存目錄,預設是LOGSTASH_HOME/data。
1.5 讀取TCP網路資料
下面的內部表示監聽埠的資料列印在控制檯,用的比較少,這裡就不演示了。
input {
tcp {
port => "1234"
}
}
filter {
grok {
match => { "message" => "%{SYSLOGLINE}" }
}
}
output {
stdout{
codec=>rubydebug
}
}2、Logstash過濾器外掛(Filter)
2.1 Filter介紹
Logstash 可以幫利用它自己的Filter幫我們對資料進行解析,豐富,轉換等
詳情請見網址:https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
下面簡單的介紹幾個常用的。
2.2 Grok 正則捕獲
grok是一個十分強大的logstash filter外掛,他可以通過正則解析任意文字,將非結構化紀錄檔資料弄成結構化和方便查詢的結構。他是目前logstash 中解析非結構化紀錄檔資料最好的方式。
Grok 的語法規則是:
%{語法: 語意}例如輸入的內容為:
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039下面是一個組合匹配模式,它可以獲取上面輸入的所有內容:
%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}- %{IP:clientip}匹配模式將獲得的結果為:clientip: 172.16.213.132
- %{HTTPDATE:timestamp}匹配模式將獲得的結果為:timestamp: 07/Feb/2018:16:24:19 +0800
- %{QS:referrer}匹配模式將獲得的結果為:referrer: "GET / HTTP/1.1"
- %{NUMBER:response}匹配模式將獲得的結果為:NUMBER: "403"
- %{NUMBER:bytes}匹配模式將獲得的結果為:NUMBER: "5039"
通過上面這個組合匹配模式,我們將輸入的內容分成了五個部分,即五個欄位,將輸入內容分割為不同的資料欄位,這對於日後解析和查詢紀錄檔資料非常有用,這正是使用grok的目的。
舉個例子:可在config/test1.conf裡面新增如下內容,用法同上
input{
stdin{}
}
filter{
grok{
match => ["message","%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}"]
}
}
output{
stdout{
codec => "rubydebug"
}
}輸入內容:
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039結果如下:
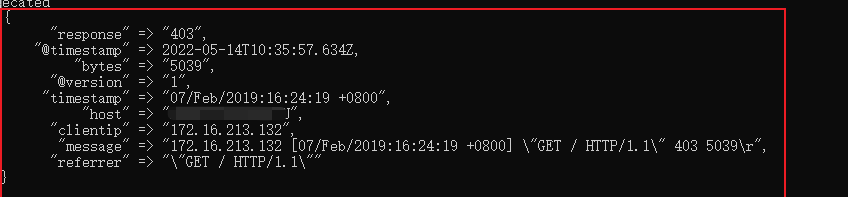
可以看到將一個長的字串拆分為好幾個欄位,這樣做的一個好處在於可以分割字串,這樣的話可直接輸出至ElasticSearch。
2.3 時間處理(Date)
date外掛是對於排序事件和回填舊資料尤其重要,它可以用來轉換紀錄檔記錄中的時間欄位,變成LogStash::Timestamp物件,然後轉存到@timestamp欄位裡,這在之前已經做過簡單的介紹。 下面是date外掛的一個設定範例:
可在config/test1.conf裡面新增如下內容,用法同上
input{
stdin{}
}
filter {
grok {
match => ["message", "%{HTTPDATE:timestamp}"]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
}
output{
stdout{
codec => "rubydebug"
}
}輸入內容:
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039結果如下:

可以看到將時間戳格式轉換為比較容易理解的格式。
2.4 資料修改(Mutate)
下面幾個用法就不單獨演示了,後面會有一個綜合範例演示所有的用法。
(1)正規表示式替換匹配欄位
gsub可以通過正規表示式替換欄位中匹配到的值,只對字串欄位有效,下面是一個關於mutate外掛中gsub的範例(僅列出filter部分):
filter {
mutate {
gsub => ["filed_name_1", "/" , "_"]
}
}這個範例表示將filed_name_1欄位中所有"/"字元替換為"_"。
(2)分隔符分割字串為陣列
split可以通過指定的分隔符分割欄位中的字串為陣列,下面是一個關於mutate外掛中split的範例(僅列出filter部分):
filter {
mutate {
split => ["filed_name_2", "|"]
}
}這個範例表示將filed_name_2欄位以"|"為區間分隔為陣列。
(3)重新命名欄位
rename可以實現重新命名某個欄位的功能,下面是一個關於mutate外掛中rename的範例(僅列出filter部分):
filter {
mutate {
rename => { "old_field" => "new_field" }
}
}這個範例表示將欄位old_field重新命名為new_field。
(4)刪除欄位
remove_field可以實現刪除某個欄位的功能,下面是一個關於mutate外掛中remove_field的範例(僅列出filter部分):
filter {
mutate {
remove_field => ["timestamp"]
}
}這個範例表示將欄位timestamp刪除。
(5)GeoIP 地址查詢歸類
將ip轉為地理資訊
filter {
geoip {
source => "ip_field"
}
}2.5 綜合範例
下面給出一個綜合範例,將上面介紹到的用法整合到一個filter中使用。
首先轉換成多個欄位 --> 去除message欄位 --> 日期格式轉換 --> 欄位轉換型別 --> 欄位重新命名 --> replace替換欄位 --> split按分割符拆分資料成為陣列
可在config/test1.conf裡面新增如下內容,用法同上
input {
stdin {}
}
filter {
grok {
match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" }
remove_field => [ "message" ]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate {
convert => [ "response","float" ]
rename => { "response" => "response_new" }
gsub => ["referrer","\"",""]
split => ["clientip", "."]
}
}
output {
stdout {
codec => "rubydebug"
}輸入內容:
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039結果如下:
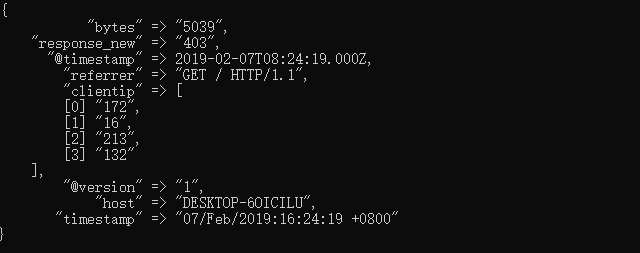
可以看到上述規則已成功輸出。
3、Logstash輸出外掛(output)
output是Logstash的最後階段,一個事件可以經過多個輸出,而一旦所有輸出處理完成,整個事件就執行完成。也就是說可以輸出到多個資料終點。
一些常用的輸出包括:
-
file: 表示將紀錄檔資料寫入磁碟上的檔案。
-
elasticsearch:表示將紀錄檔資料傳送給Elasticsearch。Elasticsearch可以高效方便和易於查詢的儲存資料。
詳細請見網址:https://www.elastic.co/guide/en/logstash/current/output-plugins.html
下面用法就不演示了,和上面大同小異。
3.1 輸出到標準輸出(stdout)
output {
stdout {
codec => rubydebug
}
}3.2 儲存為檔案(file)
output {
file {
path => "/data/log/%{+yyyy-MM-dd}/%{host}_%{+HH}.log"
}
}3、輸出到elasticsearch
output {
elasticsearch {
host => ["192.168.1.1:9200","172.16.213.77:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}-
host:是一個陣列型別的值,後面跟的值是elasticsearch節點的地址與埠,預設埠是9200。可新增多個地址。
-
index:寫入elasticsearch的索引的名稱,這裡可以使用變數。Logstash提供了%{+YYYY.MM.dd}這種寫法。在語法解析的時候,看到以+ 號開頭的,就會自動認為後面是時間格式,嘗試用時間格式來解析後續字串。這種以天為單位分割的寫法,可以很容易的刪除老的資料或者搜尋指定時間範圍內的資料。此外,注意索引名中不能有大寫字母。
-
manage_template:用來設定是否開啟logstash自動管理模板功能,如果設定為false將關閉自動管理模板功能。如果我們自定義了模板,那麼應該設定為false。
-
template_name:這個設定項用來設定在Elasticsearch中模板的名稱。
4、綜合案例
4.1 資料準備
下面這個案例將綜合上面所有的內容
實現實時讀取檔案內容到原生的ElasticSearch
首先初始檔案nginx1.log空檔案內容如下:

將遊標指向下一行。在config/test1.conf裡面新增如下內容,用法同上
input {
file {
path => ["E:/ElasticSearch/logstash-7.3.0/nginx*.log"]
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" }
remove_field => [ "message" ]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate {
rename => { "response" => "response_new" }
convert => [ "response","float" ]
gsub => ["referrer","\"",""]
remove_field => ["timestamp"]
split => ["clientip", "."]
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}4.2 執行結果
檢視es中索引結果
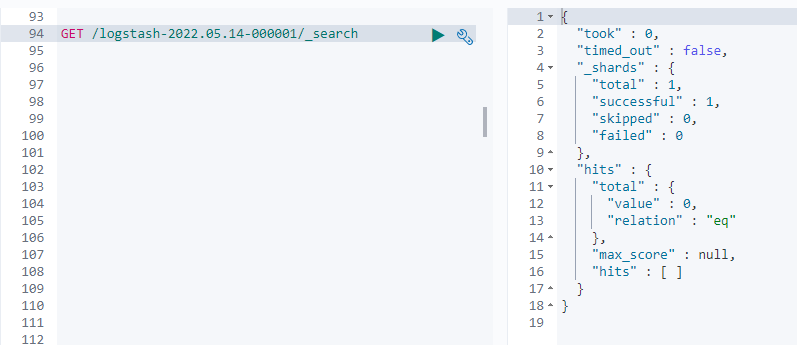
可以看到索引已成功建立
在往檔案裡新增內容
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
結果如下:
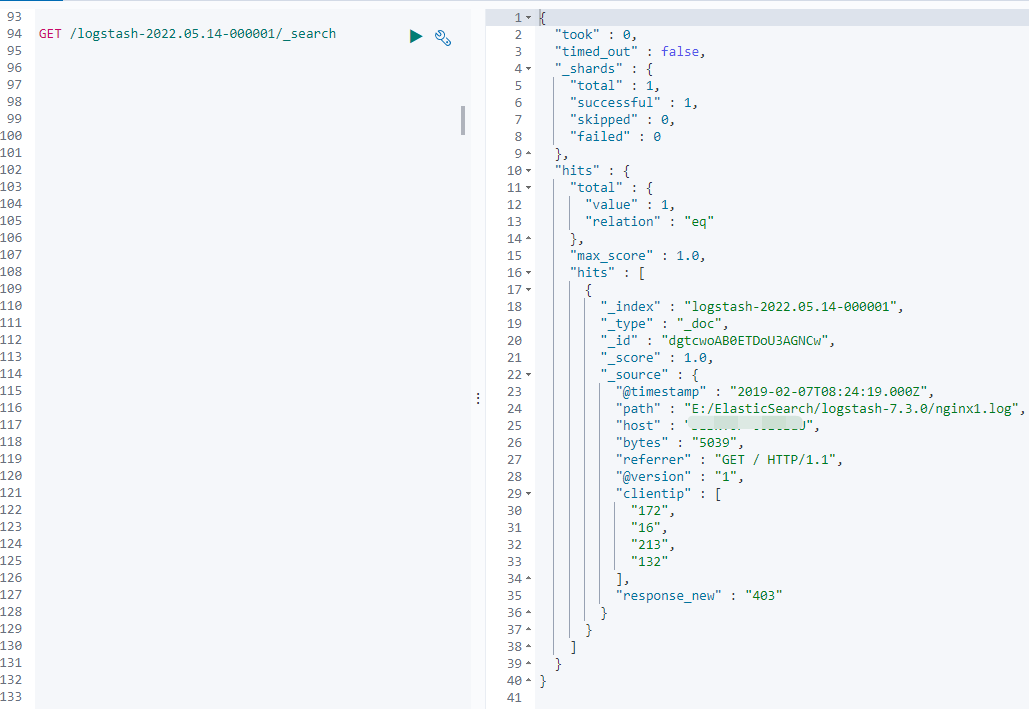
可以看到更新的資料已輸出至ES,並且規則已成功體現在資料上面。
本文來自部落格園,作者:|舊市拾荒|,轉載請註明原文連結:https://www.cnblogs.com/xiaoyh/p/16270516.html