剖析虛幻渲染體系(16)- 圖形驅動的祕密
16.1 本篇概述
16.1.1 本篇內容
迄今為止,博主在部落格中闡述的內容包含圖形API、GPU、遊戲引擎、Shader、渲染技術、效能優化等等技術範疇內容,但似乎還未涉及圖形驅動的內幕。本篇將站在應用層開發者的視角,去闡述圖形驅動的相關技術內幕(如果是驅動開發者,則博主不認為是目標讀者),主要包含但不限於以下內容:
- 圖形驅動的架構。
- 圖形驅動的技術內幕。
- 圖形驅動的常見實現。
- 相關的硬體基礎。
16.1.2 裝置驅動概述
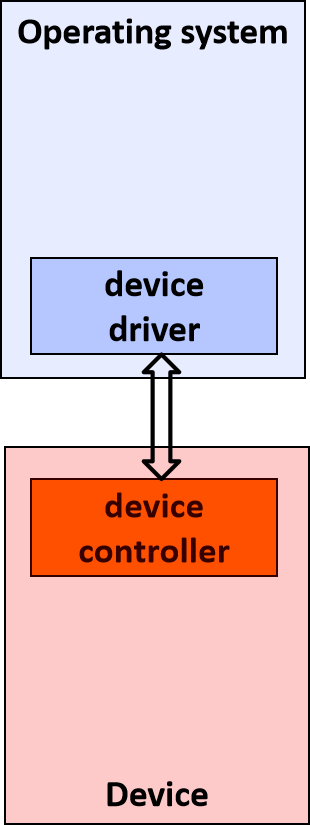
要給「驅動」一詞下一個準確的定義是一個挑戰。從最基本的意義上講,驅動程式是一個軟體元件,它允許作業系統和裝置相互通訊。例如,假設應用程式需要從裝置讀取一些資料,應用程式呼叫作業系統實現的函數,作業系統呼叫驅動程式實現的函數。該驅動程式由設計和製造該裝置的同一家公司編寫,他們知道如何與裝置硬體通訊以獲取資料。驅動程式從裝置獲取資料後,將資料返回給作業系統,作業系統將資料返回給應用程式。
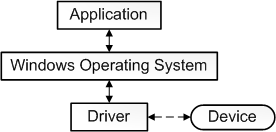
在計算機中,裝置驅動程式是一種計算機程式,用於操作或控制連線到計算機或自動機的特定型別的裝置。驅動程式為硬體裝置提供軟體介面,使作業系統和其他計算機程式能夠存取硬體功能,而無需知道所使用硬體的確切細節。
驅動程式通過硬體連線的計算機匯流排或通訊子系統與裝置通訊。當呼叫程式呼叫驅動程式中的例程時,驅動程式向裝置發出命令(驅動裝置)。一旦裝置將資料傳送回驅動程式,驅動程式就可以呼叫原始呼叫程式中的例程。驅動程式依賴於硬體且特定於作業系統,通常提供任何必要的非同步時間相關硬體介面所需的中斷處理。
裝置驅動程式,特別是在現代Microsoft Windows平臺上,可以在核心模式(x86 CPU上的ring 0)或使用者模式(x86 CPU上的ring 3)下執行。在使用者模式下執行驅動程式的主要好處是提高了穩定性,因為寫得不好的使用者模式裝置驅動程式不會通過覆蓋核心記憶體而導致系統崩潰。另一方面,使用者/核心模式轉換通常會帶來相當大的效能開銷,從而使核心模式驅動程式成為低延遲網路的首選。
使用者模組只能通過使用系統呼叫來存取核心空間,終端使用者程式(如UNIX shell或其他基於GUI的應用程式)是使用者空間的一部分,這些應用程式通過核心支援的函數與硬體互動。
常見的裝置驅動包含但不限於:
- 印表機。
- 視訊介面卡。
- 網路卡。
- 音效卡。
- 各種型別的本地匯流排,特別是用於在現代系統上控制匯流排。
- 各種低頻寬輸入/輸出匯流排(用於滑鼠、鍵盤等定點裝置)。
- 計算機儲存裝置,如硬碟、CD-ROM和軟碟匯流排(ATA、SATA、SCSI、SAS)。
- 實現對不同檔案系統的支援。
- 影象掃描器。
- 數碼相機。
- 數位無線電視調諧器。
- 用於無線個人區域網的射頻通訊收發器介面卡,用於家庭自動化中的短距離低速無線通訊(例如藍芽低能量(BLE)、執行緒、ZigBee和Z-Wave)。
- IrDA介面卡。
以上的解釋在以下幾個方面過於簡單:
-
並非所有驅動程式都必須由設計該裝置的公司編寫。在許多情況下,裝置是根據已釋出的硬體標準設計的,意味著驅動程式可以由Microsoft編寫,並且裝置設計器不必提供驅動程式。
-
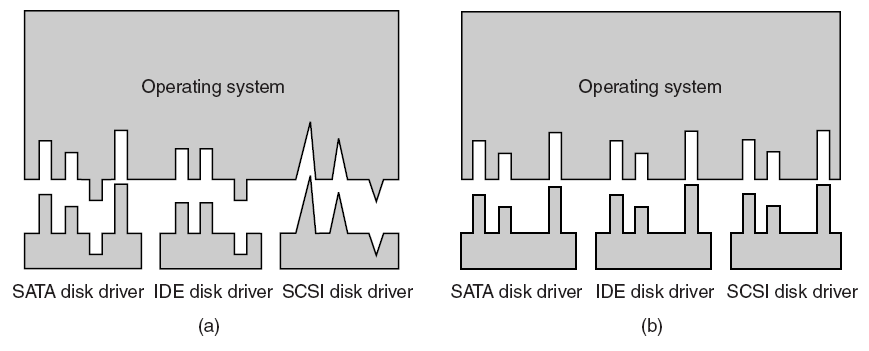
並非所有驅動程式都與裝置直接通訊。對於給定的I/O請求(如從裝置讀取資料),通常有多個驅動程式參與請求,這些驅動程式分層在驅動程式堆疊中。視覺化堆疊的傳統方法是,第一個參與者在頂部,最後一個參與者在底部,如下圖所示。堆疊中的一些驅動程式可能通過將請求從一種格式轉換為另一種格式來參與。這些驅動程式不直接與裝置通訊,他們只是操縱請求並將請求傳遞給堆疊中較低的驅動程式。
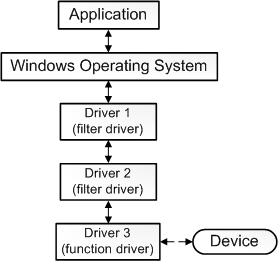
其中功能驅動程式是堆疊中直接與裝置通訊的一個驅動程式,過濾驅動程式是執行輔助處理的驅動程式。
-
一些過濾驅動程式觀察並記錄有關輸入/輸出請求的資訊,但不主動參與這些請求。例如,某些過濾驅動程式充當驗證器,以確保堆疊中的其他驅動程式正確處理I/O請求。
可以通過說驅動程式是觀察或參與作業系統和裝置之間通訊的任何軟體元件來擴充套件驅動程式的定義。
至此,擴充套件定義相當準確,但仍然不完整,因為一些驅動程式根本與任何硬體裝置都沒有關聯。例如,假設需要編寫一個能夠存取核心作業系統資料結構的工具,而只有在核心模式下執行的程式碼才能存取核心作業系統資料結構。可以通過將該工具拆分為兩個元件來實現這一點,第一個元件以使用者模式執行並顯示使用者介面,第二個元件以核心模式執行,可以存取核心作業系統資料。在使用者模式下執行的元件稱為應用程式,在核心模式下執行的元件稱為軟體驅動程式,軟體驅動程式與硬體裝置不關聯。下圖說明了與核心模式軟體驅動程式通訊的使用者模式應用程式。
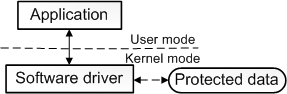
軟體驅動程式總是在核心模式下執行,編寫軟體驅動程式的主要原因是為了存取僅在核心模式下可用的受保護資料。然而,裝置驅動程式並不總是需要存取核心模式的資料和資源。因此,一些裝置驅動程式以使用者模式執行。
此外,還有匯流排驅動等更多功能性驅動(下圖)。
16.1.3 圖形驅動概述
顯示驅動程式是允許作業系統與圖形硬體一起工作的軟體。圖形硬體控制顯示器,可以是計算機中的擴充卡,也可以內建在計算機的主電路板中(如筆記型電腦),也可以駐留在計算機外部(如Matrox remote graphics units)。每種型號的圖形硬體都是不同的,需要一個顯示驅動程式來與系統的其餘部分連線。具有不同特性的較新圖形硬體型號不斷髮布,每種新型號的控制方式往往不同。
驅動程式將作業系統函數呼叫(命令)轉換為特定於該裝置的呼叫。對於同一型號的圖形硬體,使用不同函數呼叫的每個作業系統也需要不同的顯示驅動程式。例如,Windows XP和Linux需要非常不同的顯示驅動程式。但是,同一作業系統的不同版本有時可以使用相同的顯示驅動程式。例如,Windows 2000和Windows XP的顯示驅動程式通常是相同的。
如果未安裝特定於計算機圖形硬體的顯示驅動程式,圖形硬體將無法使用或功能有限。如果特定於型號的顯示驅動程式不可用,作業系統通常可以使用具有基本功能的通用顯示驅動程式。例如,Windows在「安全模式」下使用通用VGA或SVGA顯示驅動程式。在這種情況下,大多數特定於模型的功能都不可用。
由於圖形硬體非常複雜,並且顯示驅動程式非常特定於該硬體,因此顯示驅動程式通常由硬體制造商建立和維護,甚至作業系統中包含的顯示驅動程式也通常最初由製造商提供。製造商可以完全存取有關硬體的資訊,並在確保以最佳方式使用其硬體方面擁有既得利益。
顯示驅動程式對系統資源具有低階(核心級)存取許可權,因為顯示驅動程式需要直接與圖形硬體通訊,這種低階別存取使得顯示驅動程式的編碼更加仔細和可靠。顯示驅動程式中的錯誤比應用程式軟體中的錯誤更有可能使整個作業系統暫時無法使用。
幸運的是,某些公司或組織(如Matrox)憑藉其對專業使用者的傳統承諾以及其產品的長期產品生命週期,在製造可靠的顯示器驅動程式方面享有盛譽。長生命週期意味著其顯示器驅動程式的開發將持續更長的時間,使得懸而未決的問題更有可能得到解決,並且顯示驅動程式能夠適應不斷變化的軟體環境。新的作業系統和新的應用軟體正在不斷髮布,每一種都可能需要新的驅動程式版本來保持相容性或提供新的功能,可用的最新顯示驅動程式經常解決此類問題。長的產品生命週期也使得顯示驅動程式更有可能新增新的特性和功能,而不考慮作業系統和應用程式軟體。
對於Linux等開源作業系統,非製造商有時會維護顯示驅動程式,作業系統的開源特性使得為此類作業系統編寫程式碼變得更容易(但並不容易)。雖然Matrox為特殊目的維護自己的Linux顯示驅動程式,但Matrox Millennium G系列產品提供了基本的開源Linux顯示驅動程式,Matrox合作伙伴Xi Graphics(一家在Linux/Unix開發方面有10多年經驗的公司)為Matrox產品提供了全功能的Linux顯示驅動程式。
即使對於相同的作業系統和圖形硬體型號,有時也會同時提供不同的顯示驅動程式,以滿足不同的需求。以下是Matrox圖形硬體某些型號可用的不同顯示驅動程式的摘要:
- 「HF」驅動程式:此類驅動程式具有豐富的介面,需要Microsoft .NET Framework軟體,適用於喜歡此介面或者已有此介面的使用者,微軟NET軟體包含在許多最近安裝的Windows和許多其他需要它的應用程式中。「HF」軟體僅適用於某些型號的Parhelia系列產品和Millennium P系列產品。
- Microsoft .NET Framework:是由Microsoft建立的一種程式設計基礎架構,用於構建、部署和執行使用者使用的應用程式和服務.NET技術,如我們的HF驅動程式。
- 統一驅動程式:此類驅動程式一次支援多個不同型號的Matrox產品。對於需要一次為許多不同的Matrox產品安裝顯示驅動程式並希望從一個軟體包進行安裝的系統管理員非常有用,對於不確定自己的圖形硬體型號的使用者也很有用。由於統一驅動程式的介面必須支援不同的硬體,Matrox統一驅動程式使用支援更廣泛的「SE」介面。
- XDDM:Windows XP顯示驅動程式模型,有時被稱為XPDM或XPDDM。
- WDDM:Windows顯示驅動程式模型(WDDM)是Windows Vista、Server 2008和Windows 7支援的顯示驅動程式體系結構。
- 「WDM」(Windows驅動程式型號)驅動程式包:此類驅動程式適用於需要視訊捕獲和實時播放功能的使用者,有一個需要Microsoft的豐富介面.NET Framework軟體和支援視訊的額外功能,微軟NET軟體包含在許多最近安裝的Windows和許多其他需要它的應用程式中。僅適用於某些型號的Parhelia系列產品。
- WHQL驅動程式:「Windows硬體質量實驗室」驅動程式接受Microsoft開發的一系列標準測試,以提高驅動程式的可靠性。Matrox等硬體供應商執行這些測試,並將結果提交給Microsoft進行認證。如果使用者安裝的驅動程式未通過WHQL認證(即使驅動程式通過其他方式認證),則Windows作業系統的最新版本會向用戶發出警告。為了避免此類警告和WHQL流程提供的額外測試,系統管理員通常更喜歡使用WHQL驅動程式。
- 認證驅動程式:Matrox通過領先的專業2D/3D軟體認證顯示驅動程式,包括用於AEC、MCAD、GIS和P&P(工廠和工藝設計)的軟體,這種軟體通常要求很高,並廣泛使用圖形硬體加速。Matrox單獨認證此類應用程式,以確保額外的可靠性。該測試是對所有Matrox顯示器驅動程式進行的常規測試的補充。
- ISV認證驅動程式:某些「獨立軟體供應商」對其應用軟體有自己的認證流程,與Matrox認證的驅動程式相似,因為特定圖形硬體的顯示驅動程式會在特定應用程式中進行額外測試。但是,在這種情況下,Matrox將硬體和顯示驅動程式提交給ISV,ISV執行測試。與Matrox認證相比,ISV認證的頻率較低,涵蓋的應用較少。
- 測試版驅動程式:有時,特殊支援或修復程式首先作為「測試版」驅動程式釋出。這類驅動已經接受了一些測試,但不一定完成了整個測試周期,測試版驅動程式可供想要測試或預覽重要新功能的使用者使用。
- ......
裝置驅動程式是作業系統核心程式碼的最大貢獻者,Linux核心中有超過500萬行程式碼,並且會導致嚴重的複雜性、bug和開發成本。近年來,出現了一系列旨在提高可靠性和簡化驅動開發的研究。然而,除了用於研究的一小部分驅動程式之外,人們對這一龐大的程式碼體的構成知之甚少。
有學者研究Linux驅動程式的原始碼,以瞭解驅動程式的實際用途、當前的研究如何應用於這些驅動程式以及未來的研究機會,大體上,研究著眼於驅動程式程式碼的三個方面:
- 驅動程式程式碼功能的特徵是什麼,驅動程式研究如何適用於所有驅動程式。
- 驅動程式如何與核心、裝置和匯流排互動。
- 是否存在可抽象為庫以減少驅動程式大小和複雜性的相似性?
從驅動程式互動研究中,發現USB匯流排提供了一個高效的匯流排介面,具有重要的標準化程式碼和粗粒度存取,非常適合隔離執行驅動程式。此外,不同匯流排和級別的驅動程式的裝置互動水平差異很大,這表明隔離成本將因級別而異。
裝置驅動程式是在作業系統和硬體裝置之間提供介面的軟體元件,驅動程式設定和管理裝置,並將來自核心的請求轉換為對硬體的請求。驅動程式依賴於三個介面:
- 驅動程式和核心之間的介面,用於通訊請求和存取作業系統服務。
- 驅動器和裝置之間的介面,用於執行操作。
- 驅動器和匯流排之間的介面,用於管理與裝置的通訊。
下圖顯示了Linux中驅動程式根據其介面的層次結構,從基本驅動程式型別開始,即char、block和net,可確定72個獨特的驅動程式類別。大多數(52%)驅動程式程式碼是字元驅動程式,分佈在41個類中。網路驅動程式佔驅動程式程式碼的25%,但只有6個類。例如,視訊和GPU驅動程式對驅動程式程式碼的貢獻很大(近9%),這是因為複雜的裝置具有每代都會改變的指令集,但這些裝置由於其複雜性,在很大程度上被驅動程式研究所忽視。
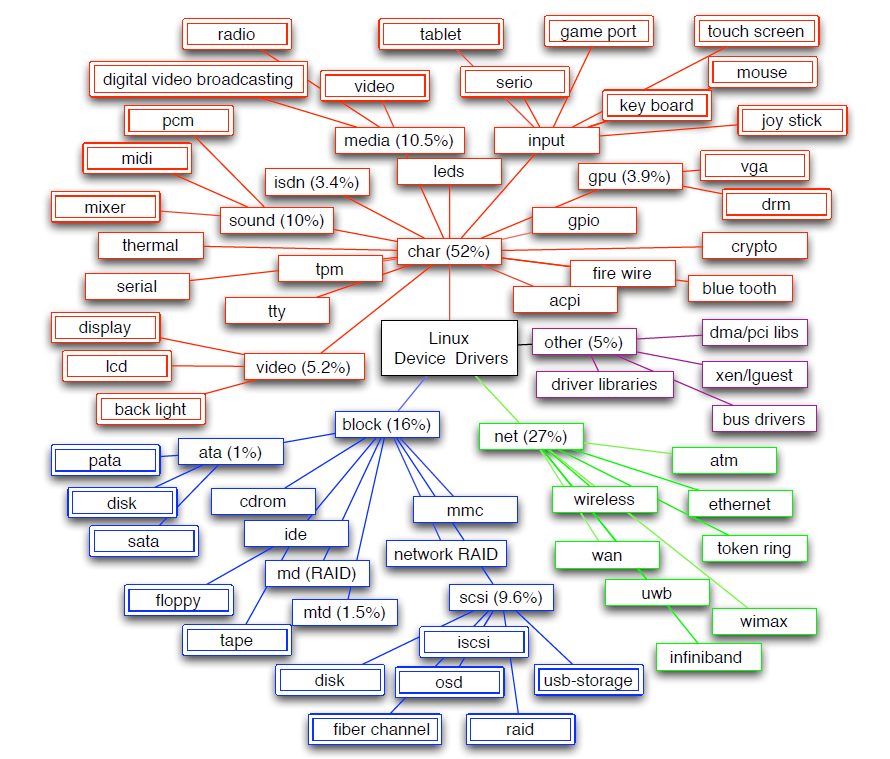
Linux驅動程式在基本驅動程式類方面的分類。其中提到了5個最大類的大小(以程式碼行的百分比表示)。
通常認為裝置驅動程式主要執行輸入/輸出。標準本科作業系統教科書規定:裝置驅動程式可以看作是轉換器,其輸入由高階命令組成,如「檢索塊123」其輸出由硬體控制器使用的低階別、特定於硬體的指令組成,硬體控制器將輸入/輸出裝置連線到系統的其餘部分。
隨著裝置功能越來越強大,並擁有自己的處理器,人們通常認為驅動程式執行的處理很少,只是在作業系統和裝置之間傳輸資料。然而,如果驅動程式需要大量的CPU處理,例如計算RAID奇偶校驗、網路校驗和或視訊驅動程式顯示資料,則必須保留處理能力。15%的驅動程式至少有一個執行處理的函數,而處理髮生在所有驅動程式函數中的1%。
下表比較了PCI、USB和XenBus所有裝置類別的複雜性指標。通過比較一個驅動程式支援的晶片組數量來考察支援多個裝置的效率,表明了支援新裝置的複雜性,以及驅動程式的抽象級別。支援來自不同供應商的許多晶片組的驅動程式表示具有高水平通用功能的標準化介面。相比之下,支援單個晶片組的驅動程式效率較低,因為每個裝置都需要一個單獨的驅動程式。

三種匯流排(bus)的驅動效率差別很大。PCI驅動程式支援每個驅動程式7.5個晶片組,幾乎總是來自同一供應商。相比之下,USB驅動程式的平均值為13.2,通常來自許多供應商。其中很大一部分差異在於USB協定的標準化,而許多PCI裝置都不存在這種標準化。例如,USB儲存裝置實現標準介面。因此,主USB儲存驅動程式程式碼在很大程度上很常見,但包括對裝置特定程式碼的呼叫。此程式碼包括特定於裝置的初始化、掛起/恢復(未提供通過USB儲存並作為附加功能要求保留)和其他需要裝置特定程式碼的例程。雖然USB驅動程式有了更大的標準化工作,但仍不完整。
所有現代作業系統中驅動程式的另一個關鍵要求是需要多路存取裝置。例如,一個磁碟控制器驅動程式必須允許多個應用程式同時讀寫資料,即使這些應用程式沒有其他關聯。這一要求會使驅動程式設計複雜化,因為它增加了對多個獨立執行緒之間同步的需要。研究驅動程式如何跨長延遲操作多路存取:它們傾向於執行緒化程式碼、在堆疊上儲存狀態並阻止事件,還是傾向於事件驅動程式碼、將回撥註冊為USB驅動程式的完成例程或PCI裝置的中斷處理程式和計時器。如果驅動程式被移動到核心之外,驅動程式和核心將使用通訊通道相互通訊,支援事件驅動並行可能更自然。
下圖中標記為事件友好型和執行緒化的條形圖中顯示的結果表明,執行緒化和事件友好型程式碼的劃分在驅動程式類中差異很大。總的來說,驅動程式出於不同的目的廣泛使用這兩種同步方法。驅動程式使用執行緒原語來同步驅動程式和裝置操作,同時初始化驅動程式並更新驅動程式全域性資料結構,而事件友好型程式碼用於核心I/O請求。
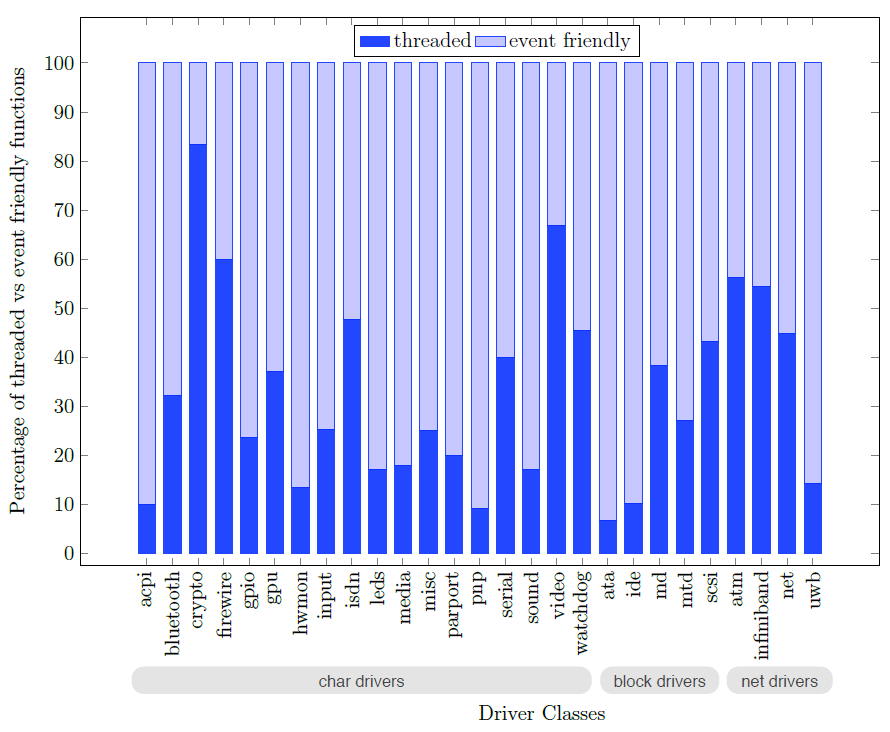
執行緒化和事件友好型同步原語覆蓋範圍內的驅動程式入口點的百分比。
隨著GPU效能的提高,對圖形驅動程式的要求也越來越高。良好的使用者體驗取決於穩定、可靠的軟體棧。
16.2 圖形驅動基礎
16.2.1 硬體概覽
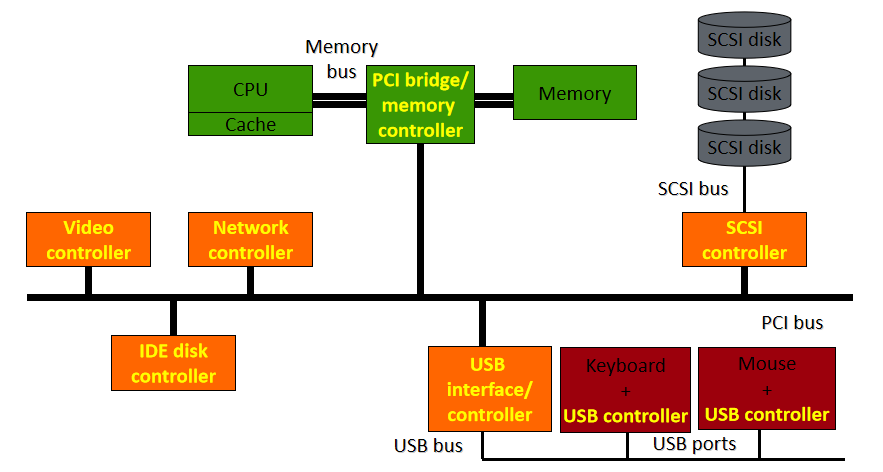
稍早期(如2012年)的計算機硬體架構大多可抽象成如下摸樣:
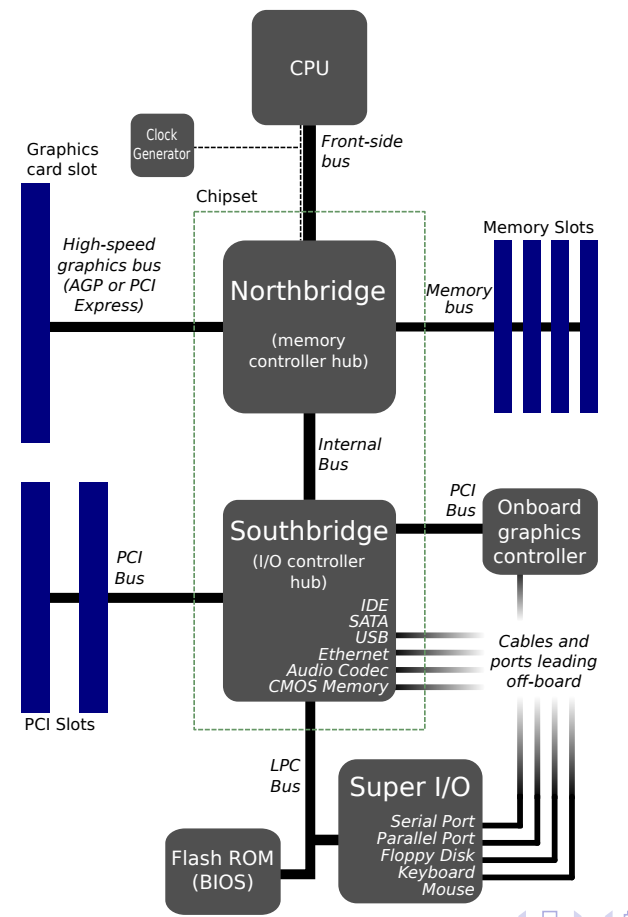
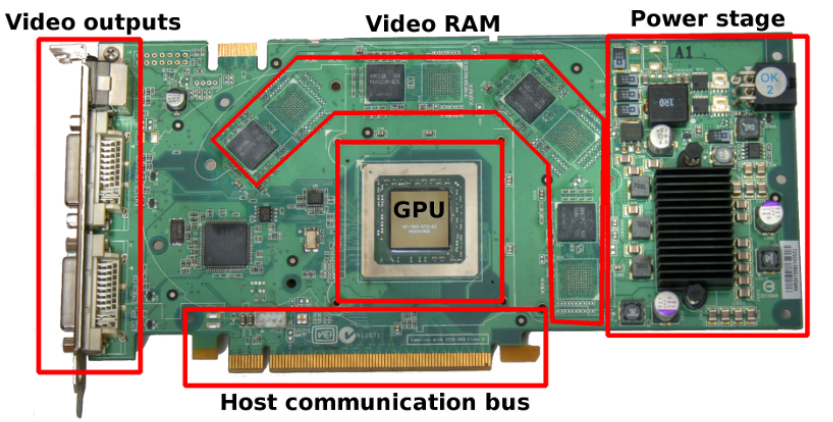
其中一款顯示卡的結構見下圖,包含了GPU(執行所有計算)、視訊輸出(連線到螢幕)、視訊記憶體(儲存紋理或通用資料)、電源管理(降低電壓,調節電流)、主機互動匯流排(與CPU的通訊)等部件:
如今,所有計算機的結構都是類似的:一箇中央處理器和許多外圍裝置。為了交換資料,這些外圍裝置通過匯流排互連,所有通訊都通過匯流排進行。下圖概述了標準計算機中外圍裝置的佈局。
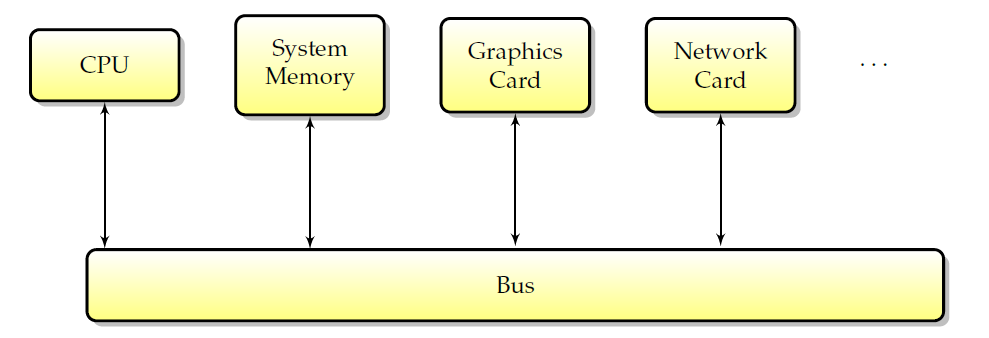
典型計算機中的外圍互連。
匯流排的第一個使用者是CPU。CPU使用匯流排存取系統記憶體和其他外圍裝置。然而,CPU並不是唯一能夠向外圍裝置寫入和讀取資料的裝置,外圍裝置本身也具有直接交換資訊的能力。具體地說,能夠在沒有CPU干預的情況下讀取和寫入記憶體的外圍裝置被稱為具有DMA(直接記憶體存取)能力,並且記憶體事務通常被稱為DMA。這種型別的事務很有趣,因為它允許驅動程式使用GPU而不是CPU來進行記憶體傳輸。由於CPU不再需要主動工作來實現這些傳輸,並且由於它允許CPU和GPU之間更好的非同步性,因此可以獲得更好的效能。DMA的常見用途包括提高紋理上傳或流視訊的效能。如今,所有圖形處理器都具有這種能力(稱為DMA匯流排主控),這種能力包括視訊卡請求並隨後控制匯流排幾微秒。
如果外設能夠在不連續的記憶體頁列表中實現DMA(當資料在記憶體中不連續時非常方便),則稱其具有DMA分散-收集(scatter-gather)功能(因為它可以將資料分散到不同的記憶體頁,或從不同的記憶體頁收集資料)。
請注意,DMA功能在某些情況下可能是一個缺點。例如,在實時系統上,意味著當DMA事務正在進行時,CPU無法存取匯流排,並且由於DMA事務是非同步發生的,可能導致錯過實時排程截止時間。另一個例子是小型DMA記憶體傳輸,其中設定DMA的CPU開銷大於非同步增益,導致傳輸速度變慢。因此,雖然DMA從效能角度來看有很多優勢,但在某些情況下應該避免。
另外,GPU需要主機:
- 設定螢幕模式/解析度(模式設定)。
- 設定引擎和通訊匯流排。
- 處理電源管理。熱量管理(風扇,對過熱/功率作出反應),更改GPU的頻率/電壓以節省電源。
- 處理資料。分配處理上下文(GPU VM+上下文ID),上傳紋理或場景資料,傳送要在上下文中執行的命令。
16.2.2 匯流排型別
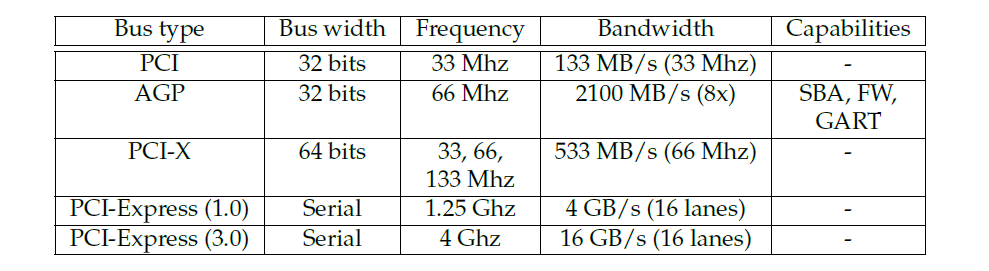
匯流排將機器外圍裝置連線在一起,不同外設之間的每一次通訊都通過(至少)一條匯流排進行。特別是,匯流排是大多數圖形卡連線到計算機其餘部分的方式(一個顯著的例外是某些嵌入式系統,其中GPU直接連線到CPU)。如下表所示,有許多適用於圖形的匯流排型別:PCI、AGP、PCI-X、PCI express等等。本小節將詳細介紹的所有匯流排型別都是PCI匯流排型別的變體,但其中一些匯流排在原始PCI設計上有獨特的改進。
-
PCI (Peripheral Component Interconnect,外設部件互連標準):PCI是目前允許連線圖形外圍裝置的最基本的匯流排。它的一個關鍵特性叫做匯流排控制,此功能允許給定的外圍裝置在給定的週期數內佔用匯流排並執行完整的事務(稱為DMA,直接記憶體存取)。PCI匯流排是一致的,意味著無需顯式重新整理即可使記憶體在裝置間保持一致。
-
AGP (Accelerated Graphics Port,圖形加速埠):AGP本質上是一種經過改進的PCI匯流排,與它的祖先相比,具有許多額外的功能。最重要的是,它的速度更快,主要得益於更高的時鐘速度以及在每個時鐘tick中每個通道傳送2、4或8位元的能力(分別適用於AGP 2x、4x和8x)。AGP還有三個顯著特點:
- 第1個特性是AGP GART(圖形光圈重對映表),是IOMMU的一種簡單形式。它允許從系統記憶體中取出一組(非連續的)實體記憶體頁,並將其暴露給GPU作為連續區域使用,以很低的成本增加了GPU可用的記憶體量,併為CPU和GPU之間共用資料建立了一個方便的區域(AGP圖形卡可以在該區域進行快速DMA,並且由於GART區域是一塊系統RAM,因此CPU存取比VRAM快得多)。一個顯著的缺點是,GART區域不一致,因此在另一方開始傳輸之前,需要重新整理對GART的寫入(無論是從GPU還是CPU)。另一個缺點是,硬體只處理一個GART區域,它必須由驅動程式分配。
- 第2個特性是AGP邊帶定址(SBA)。邊帶定址由用作地址匯流排的8個額外匯流排位組成,與多路複用地址和資料之間的匯流排頻寬不同,標準AGP頻寬只能用於資料。此功能對驅動程式開發人員是透明的。
- 第3個特性是AGP快速寫入(FW)。快速寫入允許直接向圖形卡傳送資料,而無需圖形卡啟動DMA。此功能對驅動程式開發人員也是透明的。
注意,後兩個功能在各種硬體上都不穩定,通常需要特定於晶片組的hack才能正常工作,因此建議不啟用它們。事實上,它們是AGP卡上出現奇怪硬體錯誤的極為常見的原因。
-
PCI-X:PCI-X是為伺服器板開發的一種更快的PCI,這種格式的圖形外圍裝置很少(一些Matrox G550卡)。不要將其與PCI-Express混淆,後者的使用非常廣泛。
-
PCI-Express (PCI-E):PCI Express是新一代PCI裝置,比簡單的改進PCI有更多的優點。最後,需要注意的是,根據體系結構,CPU-GPU通訊並不總是依賴於匯流排,在GPU和CPU位於單個晶片上的嵌入式系統上尤其常見。在這種情況下,CPU可以直接存取GPU暫存器。
16.2.3 視訊記憶體架構
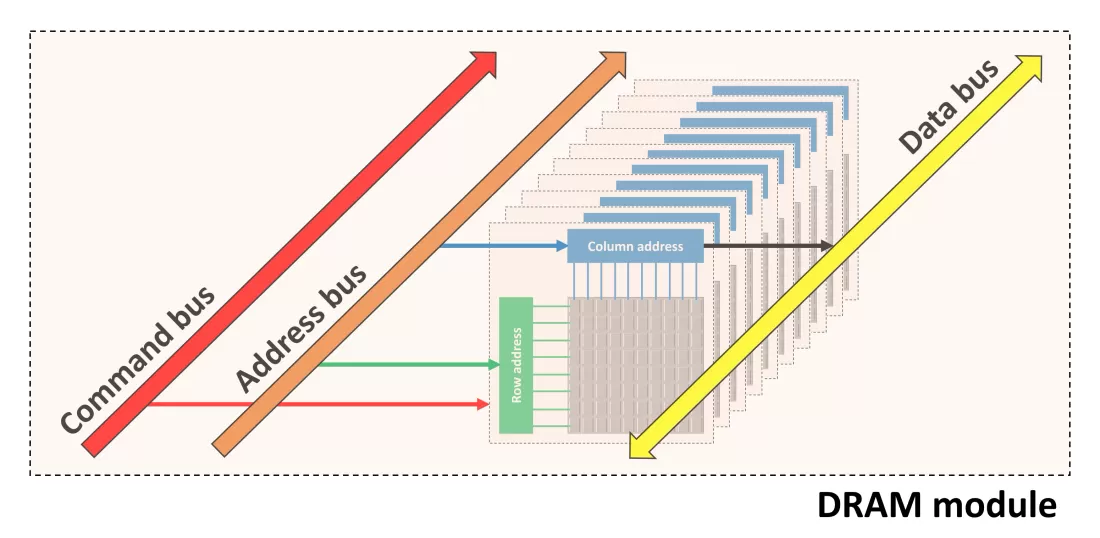
雖然DRAM通常被視為一個扁平的位元組陣列,但其內部結構要複雜得多。對於像GPU這樣的高效能應用程式,非常有必要深入地理解它。從下往上大致看,VRAM由以下部分組成:
-
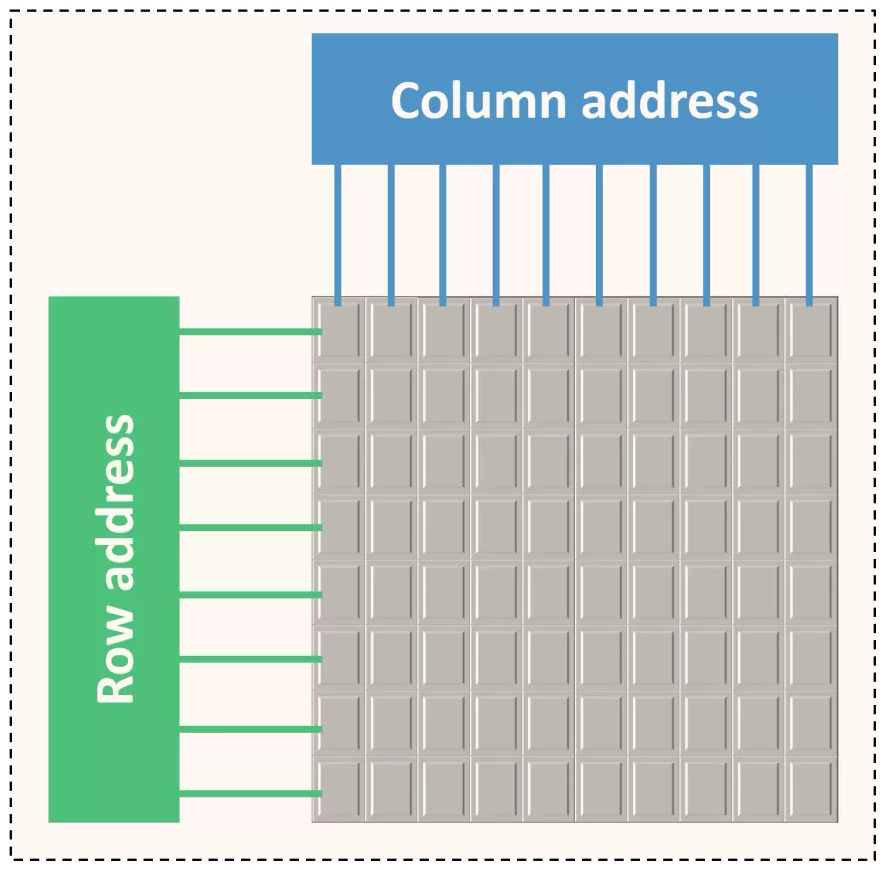
R行乘以C列的記憶體平面(memory plane),每個單元為一位。
-
由32、64或128個並行使用的記憶體平面組成的記憶體組(memory bank)——這些平面通常分佈在多個晶片上,其中一個晶片包含16或32個記憶體平面。bank中的所有頁面都連線到行定址系統(列也是如此),並且這些頁面由命令訊號和每行/列的地址控制。bank中的行和列越多,地址中需要使用的位就越多。
-
由若干個[2、4或8]個memory bank連線在一起並由地址位選擇的記憶體排(memory rank)——給定記憶體平面的所有memory bank位於同一晶片中。
-
由一個或兩個連線在一起並由晶片選擇線選擇的memory rank組成的記憶體子分割區(memory subpartition)——rank的行為類似於bank,但不必具有統一的幾何結構,而是在單獨的晶片中。
-
由一個或兩個稍微獨立的memory subpartition組成了記憶體分割區(memory partition)。
-
整個VRAM由幾個[1-8]個memory partition組成。
以上數量會因不同的GPU架構和家族而不同。
DRAM最基本的單元是記憶體平面,它是按所謂的列和行組織的二維位陣列:
column
row 0 1 2 3 4 5 6 7
0 X X X X X X X X
1 X X X X X X X X
2 X X X X X X X X
3 X X X X X X X X
4 X X X X X X X X
5 X X X X X X X X
6 X X X X X X X X
7 X X X X X X X X
buf X X X X X X X X
記憶體平面包含一個緩衝區,該緩衝區可容納整個行。在內部,DRAM通過緩衝區以行為單位進行讀/寫。因此有幾個後果:
- 在對某個位進行操作之前,必須將其行載入到緩衝區中,會很慢。
- 處理完一行後,需要將其寫回記憶體陣列,也很慢。
- 因此,存取新行的速度很慢,如果已經有一個活動行,存取速度甚至更慢。
- 在一段不活動時間後,搶先關閉一行通常很有用——這種操作稱為precharging(預充電?)一個bank。
- 但是,可以快速存取同一行中的不同列。
由於載入列地址本身比實際存取活動緩衝區中的位花費更多的時間,所以DRAM是以突發方式存取的,即對活動行中1-8個相鄰位的一系列存取。通常,突發中的所有位都必須位於單個對齊的8位元組中。記憶體平面中的行和列的數量始終是2的冪,並通過行選擇和列選擇位的計數來衡量[即行/列計數的log2],通常有8-10列位和10-14行位。記憶體平面被組織在bank中,bank由兩個記憶體平面的冪組成。記憶體平面是並行連線的,共用地址和控制線,只有資料/資料啟用線是分開的。這有效地使記憶體bank類似於由32位元/64位元/128位元記憶體單元組成的記憶體平面,而不是單個位——適用於平面的所有規則仍然適用於bank,但操作的單元比位大。單個儲存晶片通常包含16或32個儲存平面,用於單個bank,因此多個晶片通常連線在一起以形成更寬的bank。
一個記憶體晶片包含多個[2、4或8]個bank,使用相同的傳輸線,並通過bank選擇線進行多路複用。雖然在bank之間切換比在一行中的列之間切換要慢一些,但要比在同一bank中的行之間切換快得多。因此,一個記憶體bank由(MEMORY_CELL_SIZE / MEMORY_CELL_SIZE_PER_CHIP)記憶體晶片組成。一個或兩個通過公共線(包括資料)連線的記憶體列,晶片選擇線除外,構成記憶體子分割區。在rank之間切換與在bank中的列組之間切換具有基本相同的效能後果,唯一的區別是物理實現和為每個rank使用不同數量行選擇位的可能性(儘管列計數和列計數必須匹配)。存在多個bank/rank的後果:
- 確保一起存取的資料要麼屬於同一行,要麼屬於不同的bank,這一點很重要(以避免行切換)。
- 分塊記憶體佈局的設計使分塊大致對應於一行,相鄰的分塊從不共用一個bank。
記憶體子分割區在GPU上有自己的DRAM控制器。1或2個子分割區構成一個記憶體分割區,它是一個相當獨立的實體,具有自己的記憶體存取佇列、自己的ZROP和CROP單元,以及更高版本卡上的二級快取。所有記憶體分割區與crossbar邏輯一起構成了GPU的整個VRAM邏輯,分割區中的所有子分割區必須進行相同的設定,GPU中的分割區通常設定相同,但在較新的卡上則不是必需的。子分割區/分割區存在的後果:
- 與bank一樣,可以使用不同的分割區來避免相關資料的行衝突。
- 與bank不同,如果(子)分割區沒有得到同等利用,頻寬就會受到影響。因此,負載平衡非常重要。
雖然記憶體定址高度依賴於GPU系列,但這裡概述了基本方法。記憶體地址的位按順序分配給:
- 識別記憶體單元中的位元組,因為無論如何都必須存取整個單元。
- 多個列選擇位,以允許突發(burst)。
- 分割區/子分割區選擇-以低位進行,以確保良好的負載平衡,但不能太低,以便在單個分割區中保留相對較大的tile,以利於ROP。
- 剩餘列選擇位。
- 所有/大部分bank選擇位,有時是排名選擇位,以便相鄰地址不會導致行衝突。
- 行位。
- 剩餘的bank位或rank位,有效地允許將VRAM拆分為兩個區域,在其中一個區域放置顏色緩衝區,在另一個區域放置zeta緩衝區,這樣它們之間就不會有行衝突。
此外,可以不同倍數的資料速率同步動態隨機存取記憶體,正是我們所熟知的DDR-SDRAM或DDR:
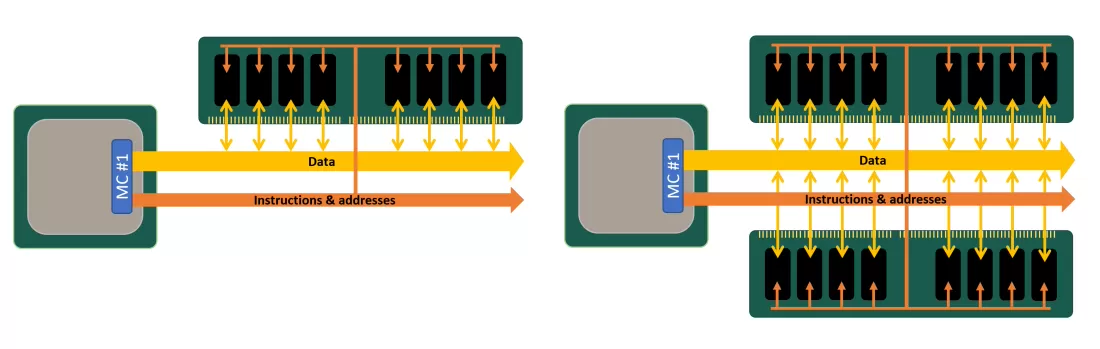
單ank和雙rank對比。
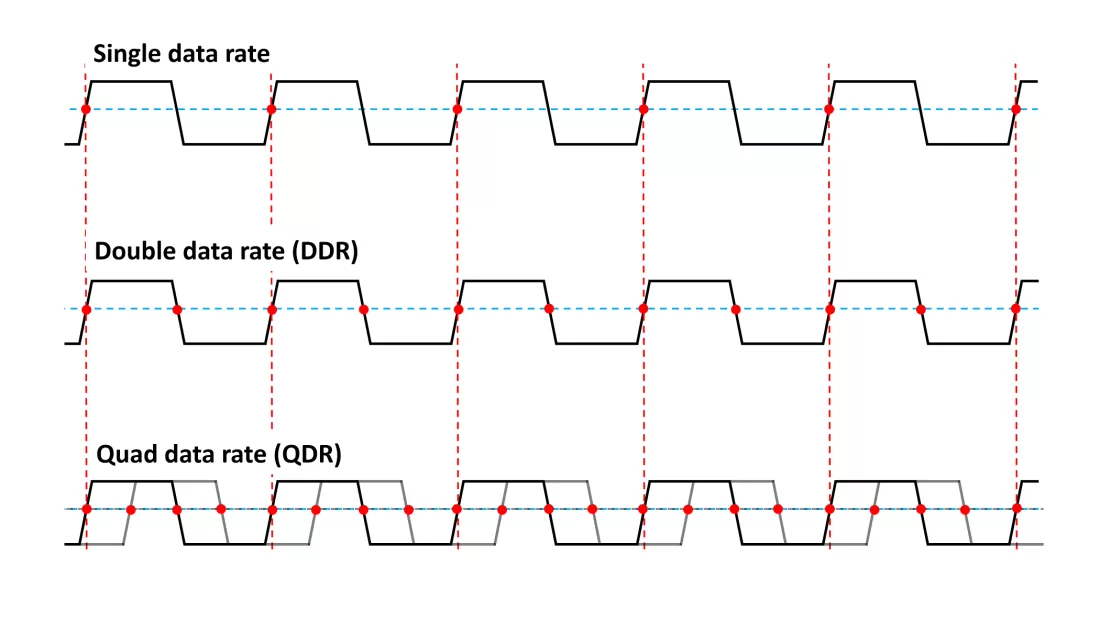
單速率、雙速率、四速率對比圖。
下圖是CPU和GPU記憶體請求路線:
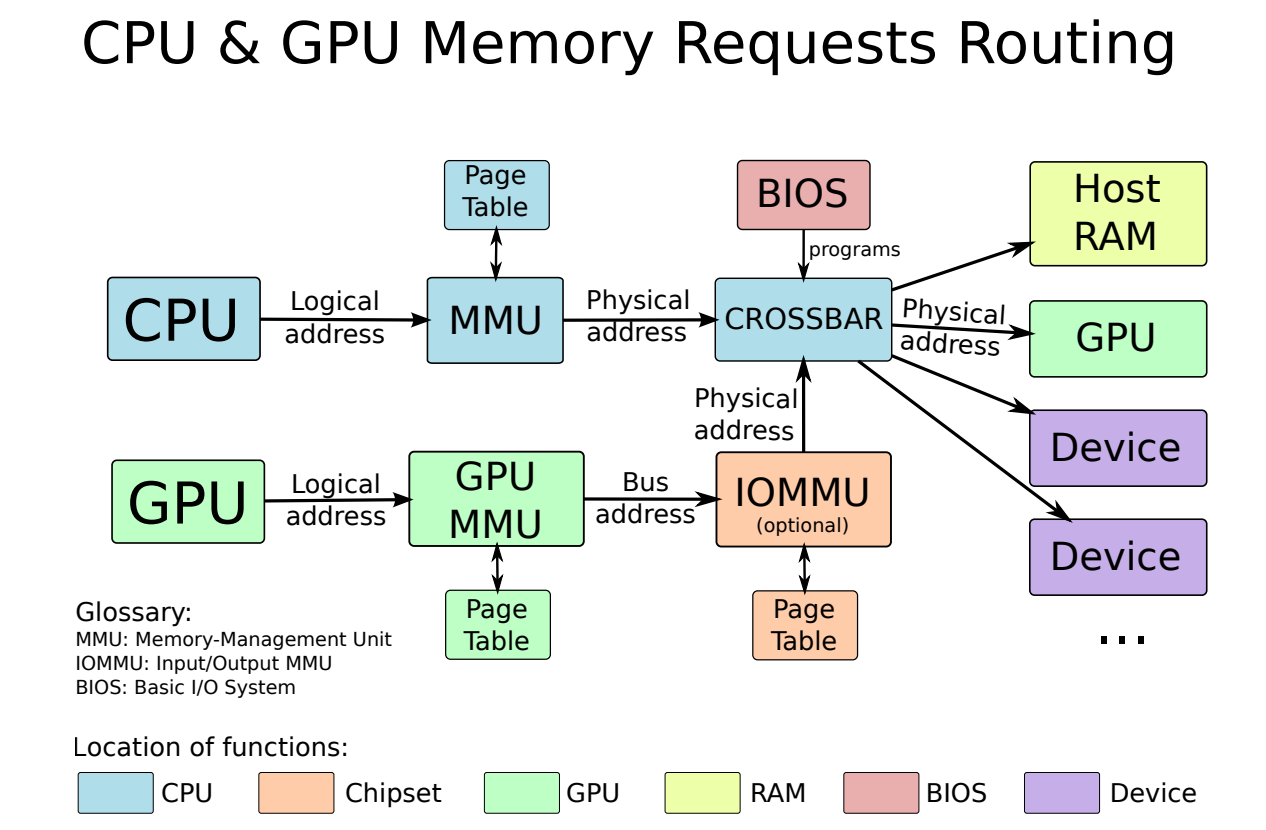
GTT/GART作為CPU-GPU共用緩衝區用於通訊:

16.2.4 虛擬和實體記憶體
記憶體有兩種主要的不同含義:
-
實體記憶體。實體記憶體是真實的硬體記憶體,儲存在記憶體晶片中。
-
虛擬記憶體。虛擬記憶體是實體記憶體地址的轉換,允許使用者空間應用程式檢視其分配的塊,就好像它們是連續的,而它們在晶片上是碎片化和分散的。
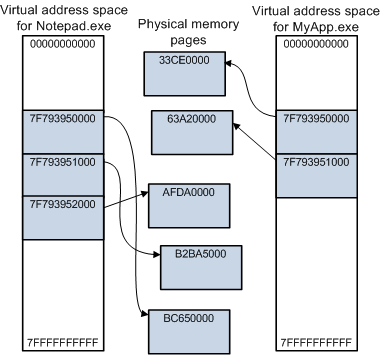
虛擬地址空間的一些關鍵功能,以及虛擬記憶體和實體記憶體的關係。
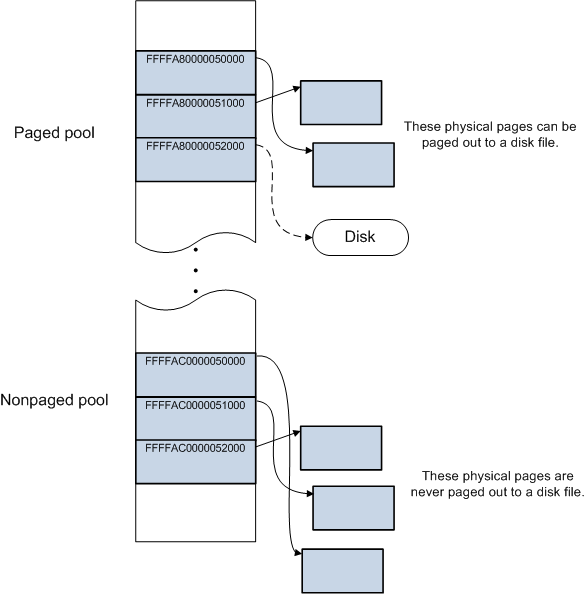
一些作業系統(如Windows)還存在分頁緩衝池(paged pool)和非分頁緩衝池(nonpaged pool)的機制。在使用者空間中,所有實體記憶體頁面都可以根據需要調出到磁碟檔案。 在系統空間中,某些物理頁面可以調出,而其他物理頁面則不能。 系統空間具有用於動態分配記憶體的兩個區域:分頁緩衝池和非分頁緩衝池。分頁緩衝池中分配的記憶體可以根據需要調出到磁碟檔案,非分頁緩衝池中分配的記憶體永遠無法調出到磁碟檔案。
為了簡化程式設計,更容易處理連續的記憶體區域。分配一個小的連續區域很容易,但分配一個更大的記憶體塊將需要同樣多的連續實體記憶體,在啟動後由於記憶體碎片化導致難以實現。因此,需要一種機制來保持應用程式的連續記憶體塊外觀,同時使用分散的記憶體塊。
為了實現這一點,記憶體被拆分為多個頁。就本文的範圍而言,可以說記憶體頁是實體記憶體中連續位元組的集合,以便使分散的物理頁列表在虛擬空間中看起來是連續的,一個稱為MMU(記憶體對映單元)的硬體使用頁表將虛擬地址(用於應用程式)轉換為實體地址(用於實際存取記憶體),如下圖所示。如果頁面不存在於虛擬空間中(因此不在MMU表中),MMU可以向其傳送訊號,為報告對不存在記憶體區域的存取提供了基本機制。反過來又被系統用來實現高階記憶體程式設計,如交換或動態頁面範例化。由於MMU僅對CPU存取記憶體有效,虛擬地址與硬體無關,因為無法將它們與實體地址匹配。
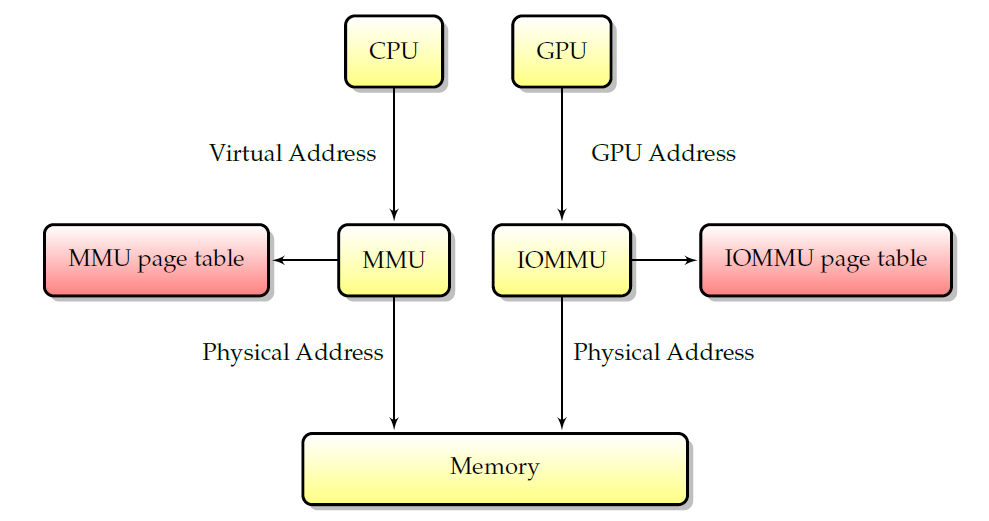
MMU和IOMMU。
雖然MMU只適用於CPU存取,但它對外圍裝置有一個等價物:IOMMU。如上圖所示,IOMMU與MMU相同,只是它虛擬化了外圍裝置的地址空間。IOMMU可以在主機板晶片組(在這種情況下,它在所有外圍裝置之間共用)或圖形卡本身(在圖形卡本身上,它將被稱為AGP GART、PCI GART)上看到各種化身。IOMMU的工作是將外圍裝置的記憶體地址轉換為實體地址。特別是,它允許「欺騙」裝置將其DMA限制在給定的記憶體範圍內,是更好的安全性和硬體虛擬化所必需的。
IOMMU的一個特例是Linux swiotlb,它在引導時分配一段連續的實體記憶體(使得有一個大的連續物理分配是可行的,因為還沒有碎片),並將其用於DMA。由於記憶體在物理上是連續的,不需要頁轉換,因此可以在該記憶體範圍內進行DMA。但是,意味著該記憶體(預設為64MB)是預先分配的,不會用於其他任何用途。
AGP GART是IOMMU的另一個特例,它與AGP圖形卡一起使用,向圖形卡顯示一個線性區域。在這種情況下,IOMMU被嵌入主機板上的AGP晶片組中。AGP GART區域作為虛擬記憶體的線性區域向系統公開。
IOMMU的另一個特例是某些GPU上的PCI GART,它允許向卡公開一塊系統記憶體。在這種情況下,IOMMU表嵌入到圖形卡中,通常使用的實體記憶體不需要是連續的。
顯然,有這麼多不同的記憶體型別,效能是不均勻的,並非所有的存取組合都是快速的,主要取決於它們是否涉及CPU、GPU或匯流排傳輸。另一個問題是記憶體一致性:如何確保跨裝置的記憶體一致,尤其是CPU寫入的資料可供GPU使用(或相反)。這兩個問題是相關的,因為較高的效能通常意味著較低水平的記憶體連貫性,反之亦然。
就設定記憶體快取引數而言,有兩種方法可以在記憶體範圍上設定快取屬性:
- MTRR。MTRR(記憶體型別範圍暫存器)是描述給定實體記憶體範圍屬性的暫存器。每個MTRR包含一個起始實體地址、一個大小和一個快取型別。MTRR的數量取決於系統,但非常有限。雖然適用於實體記憶體範圍,但效果會作用於相應的虛擬記憶體頁。例如,可以使用特定的快取型別對映頁面。
- PAT(頁面屬性表)允許設定每頁記憶體屬性。與MTRR一樣依賴有限數量的記憶體範圍不同,可以在每頁的基礎上指定快取屬性。但是,它是僅在最新x86處理器上可用的擴充套件。
除此之外,可以在某些體系結構上使用顯式快取指令,例如在x86上,movntq是一條未快取的mov指令,clflush可以選擇性地重新整理快取行。
有三種快取模式,可通過MTRR和PAT系統記憶體使用:
- UC(UnCached)記憶體未快取。CPU對此區域的讀/寫是未快取的,每個記憶體寫入指令都會觸發實際的即時記憶體寫入。有助於確保資訊已實際寫入,以避免CPU/GPU爭用的情況。
- WC(Write Combine)記憶體未快取,但CPU寫入被組合在一起以提高效能。在需要未快取記憶體但將寫操作組合在一起不會產生不利影響的情況下,非常有利於提高效能。
- WB(Write Back)記憶體已被快取。是預設模式,可以獲得CPU存取的最佳效能。然而,並不能確保記憶體寫入在有限時間後傳播到中央記憶體。
請注意,以上快取模式僅適用於CPU,GPU存取不受當前快取模式的直接影響。然而,當GPU必須存取之前由CPU填充的記憶體區域時,未快取模式可確保實際完成記憶體寫入,並且不會掛起在CPU快取中。實現相同效果的另一種方法是使用某些x86處理器(如cflush)上的快取重新整理指令,但比使用快取模式的可移植性差。另一種(可移植的)方法是使用記憶體屏障,它可以確保在繼續之前將掛起的記憶體寫入提交到主記憶體。
顯然,有這麼多不同的快取模式,並非所有存取都具有相同的效能:
- 在CPU存取系統記憶體時,未快取模式提供最差的效能,回寫提供最好的效能,寫入組合介於兩者之間。
- 當CPU從離散卡存取視訊記憶體時,所有存取都非常慢,無論是讀還是寫,因為每次存取都需要匯流排上的一個週期。因此,不建議使用CPU存取大面積的VRAM。此外,在某些GPU上需要同步,否則可能會導致GPU掛起。
- 顯然,GPU存取VRAM的速度非常快。
- GPU對系統RAM的存取不受快取模式的影響,但仍須通過匯流排,DMA事務就是這種情況。由於都是非同步發生的,從CPU的角度來看,它們可以被視為「免費」,但是每個DMA事務都涉及到不可忽略的設定成本。這就是為什麼在傳輸少量記憶體時,DMA事務並不總是優於直接CPU存取。
最後,關於記憶體的最後一個重要觀點是記憶體屏障和寫入賬本(write posting)的概念。對於快取(寫合併或寫回)記憶體區域,記憶體屏障可確保掛起的寫操作實際上已提交到記憶體。例如,在要求GPU讀取給定的記憶體區域之前,會使用此選項。對於I/O區域,存在一種類似的稱為寫入賬本的技術:包括在I/O區域內進行虛擬讀取,作為一種副作用,它會等到掛起的寫入生效後再完成。

經典的桌面電腦架構,在PCI Express上具有獨特的圖形卡。給定記憶體技術的典型頻寬缺少記憶體延遲,GPU和CPU之間不可能實現零拷貝,因為兩者都有各自不同的實體記憶體,資料必須從一個複製到另一個才能共用。
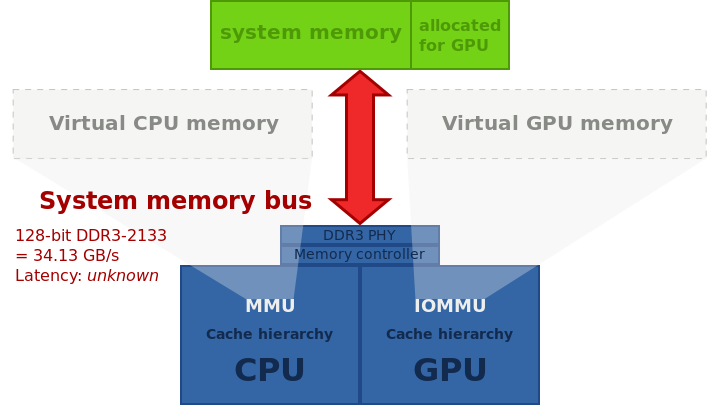
帶分割區主記憶體的整合圖形:系統記憶體的一部分專門分配給GPU,零拷貝不可能實現,資料必須通過系統記憶體匯流排從一個分割區複製到另一個分割區。
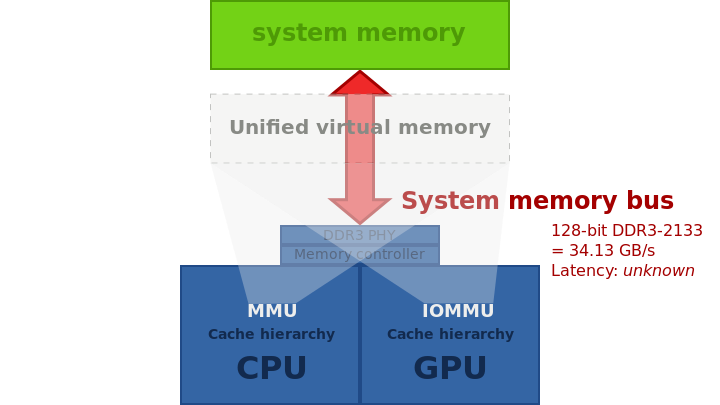
具有統一主記憶體儲器的整合圖形,可在AMD Kaveri或PlayStation 4(HSA)中找到。
16.2.5 PFIFO
大多數引擎的命令都是通過一個名為PFIFO的特殊引擎傳送的,PFIFO維護多個完全獨立的命令佇列,稱為通道(channel)或FIFO,每個通道通過「通道控制區」進行控制,該區域是MMIO[GF100之前]或VRAM[GF100+]的區域,PFIFO攔截所有進入該區域的通道並對其採取行動。
PFIFO內部在通道之間進行分時(time-sharing),但對應用程式是透明的,PFIFO控制的引擎也知道通道,併為每個通道維護單獨的上下文。
PFIFO的上下文切換能力取決於卡的次代。在NV40,PFIFO基本上可以隨時在通道之間切換。在舊卡上,由於缺少快取的後備儲存,只有在快取為空時才能切換。然而,PFIFO控制的引擎在切換方面要差得多:它們只能在命令之間切換。雖然這種方式在舊卡上不是一個大問題(因為命令保證在有限的時間內執行),但引入具有迴圈功能的可程式化著色器,可以通過啟動長時間執行的著色器來有效地掛起整個GPU。
PFIFO大致可分為4個部分:
- PFIFO pusher:收集使用者命令並將其注入。
- PFIFO cache:等待執行的大量命令。
- PFIFO puller:執行命令,將其傳遞給適當的引擎或驅動。
- PFIFO switcher:標出通道的時間片,並在PFIFO暫存器和RAMFC記憶體之間儲存/恢復通道的狀態。
通道由以下部分組成:
- 通道模式:PIO[NV1:GF100]、DMA[NV4:GF100]或IB[G80-]。
- PFIFO DMA pusher狀態[僅限DMA和IB通道]。
- PFIFO快取狀態:已接受但尚未執行的命令。
- PFIFO puller狀態。
- RAMFC:當PFIFO上的通道當前未啟用時,儲存上述資訊的VRAM區域[使用者不可見]。
- RAMHT[僅限GF100之前版本]:通道可以使用的「物件」表,物件由任意32位元控制程式碼標識,可以是DMA物件[參見NV3 DMA物件、NV4:G80 DMA物件、DMA物件]或引擎物件。在G80之前的卡上,可以在通道之間共用單個物件。
- vspace(僅G80+):頁表的層次結構,描述引擎在執行通道命令時可見的虛擬記憶體空間,多個通道可以共用一個vspace。
- 引擎特定狀態。
通道模式決定向通道提交命令的方式。在GF100之前的卡上可以使用PIO模式,並且需要將這些方法直接插入通道控制區域。它的速度慢且脆弱——當多個通道同時使用時,很容易發生故障,故而不推薦使用。在NV1:NV40上,所有通道都支援PIO模式。在NV40:G80上,只有前32個通道支援PIO模式。在G80上:GF100僅通道0支援PIO模式。
16.2.6 圖形卡剖析
如今,圖形卡基本上是計算機中的計算機。它是一個複雜的野獸,在一個單獨的卡上有一個專用處理器,具有自己的計算單元、匯流排和記憶體。本節概述圖形卡,包括以下元素。
- Graphics Memory(圖形記憶體)
GPU的記憶體(視訊記憶體),可以是真實的、專用的、卡上記憶體(對於離散卡),也可以是與CPU共用的記憶體(對於整合卡,也稱為「被盜記憶體」或「雕刻記憶體」)。請注意,共用記憶體的情況有著有趣的含義,因為如果實現得當,系統到視訊記憶體的拷貝實際上是免費的。在專用記憶體的情況下,意味著需要進行來回傳輸,並且它們將受到匯流排速度的限制。
現代GPU也有一種形式的虛擬記憶體,允許將不同的資源(系統記憶體的真實視訊記憶體)對映到GPU地址空間,與CPU的虛擬記憶體非常相似,但使用完全獨立的硬體實現。例如,較舊的Radeon卡(實際上是Rage 128)具有許多表面(Surface),我們可以將這些表面對映到GPU地址空間,每個表面都是連續的記憶體資源(視訊ram、AGP、PCI)。舊的Nvidia卡(NV40之前的所有卡)有一個類似的概念,它基於描述記憶體區域的物件,然後可以繫結到給定的用途。稍後的圖形卡(從NV50和R800開始)可以讓我們逐頁構建地址空間,還可以隨意選擇系統和專用視訊記憶體頁。這些與CPU虛擬地址空間的相似性非常驚人,事實上,未對映的頁面存取可以通過中斷向系統發出訊號,並在視訊記憶體頁面錯誤處理程式中執行。然而,小心處理這些問題,因為驅動程式開發人員必須處理來自CPU和GPU的多個地址空間,它們具有本質性的不同點。
- Surface(表面)
表面是所有渲染的基本源和目標。儘管它們的叫法有所差異(紋理、渲染目標、緩衝區…)基本思想總是一樣的。下圖描述了圖形表面的佈局。由於硬體限制(通常是某些2次方的下一個倍數),表面寬度被四捨五入到我們所稱的間距,因此存在一個未使用的畫素死區。
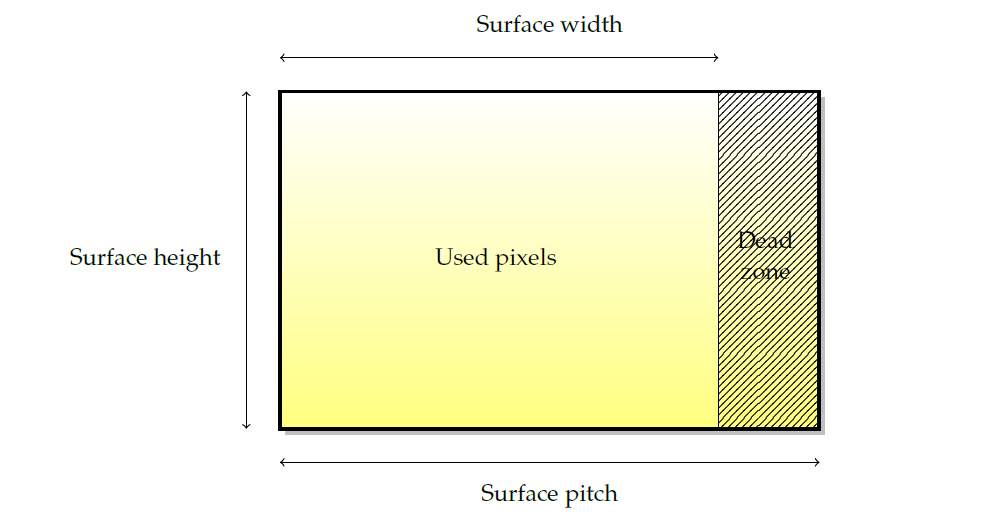
圖形表面具有許多特徵:
- 表面的畫素格式。畫素顏色由其紅色、綠色和藍色分量以及用作混合不透明度的alpha分量表示。整個畫素的位數通常與硬體大小相匹配(8、16或32位元),但四個元件之間的位數重新分配不必與硬體大小相匹配。用於每個畫素的位數被稱為每畫素位數或bpp。常見的畫素格式包括888 RGBX、8888 RGBA、565 RGB、5551 RGBA、4444 RGBA。請注意,現在大多數圖形卡都是在8888中原生工作的。
- 寬度和高度是最明顯的特徵,以畫素為單位。
- 間距是以位元組為單位的寬度(不是以畫素為單位!)表面的,包括空白區域(dead zone)畫素。pitch便於計算記憶體使用量,例如,表面的大小應通過
高度 x pitch而不是高度 x 寬度 x bpp來計算,以便包括dead zone。
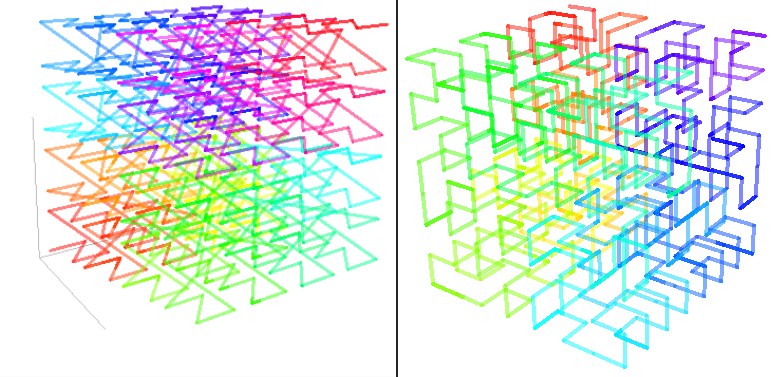
請注意,表面並非總是線性儲存在視訊記憶體中,事實上,出於效能原因,表面通常不是以線性儲存,因為這樣可以改善渲染時記憶體存取的位置。此類表面稱為分塊表面(tiled surface),分塊表面的精確佈局高度依賴於硬體,但通常是一種空間填充曲線,如Z曲線(又叫Z-order曲線、Morton曲線,下圖)或Hilbert曲線(下下圖)。

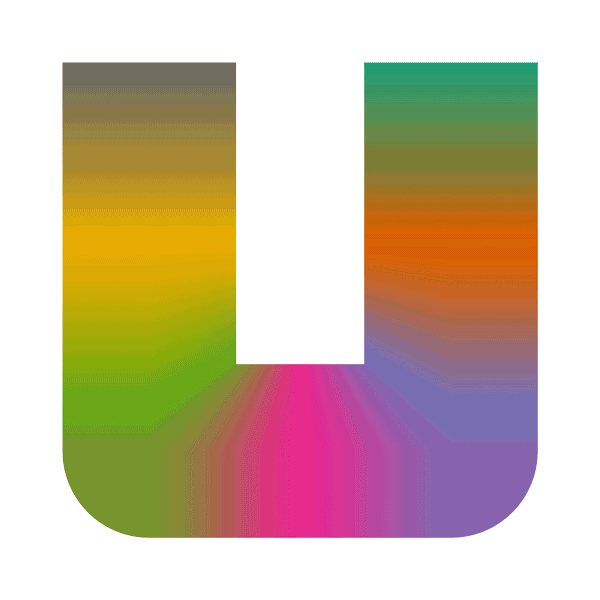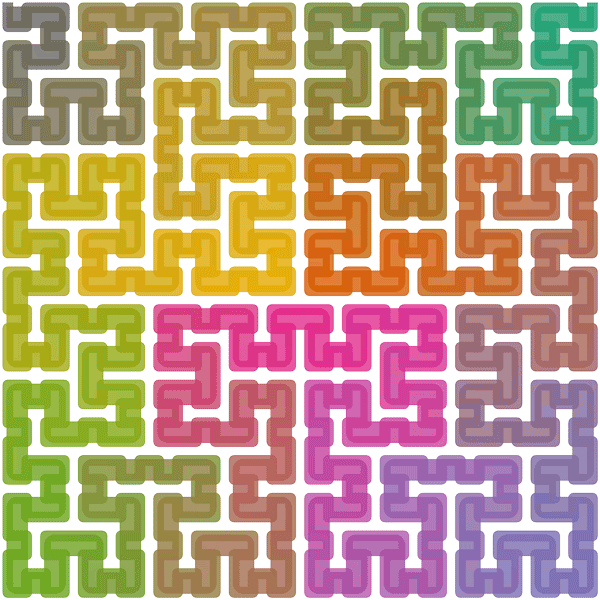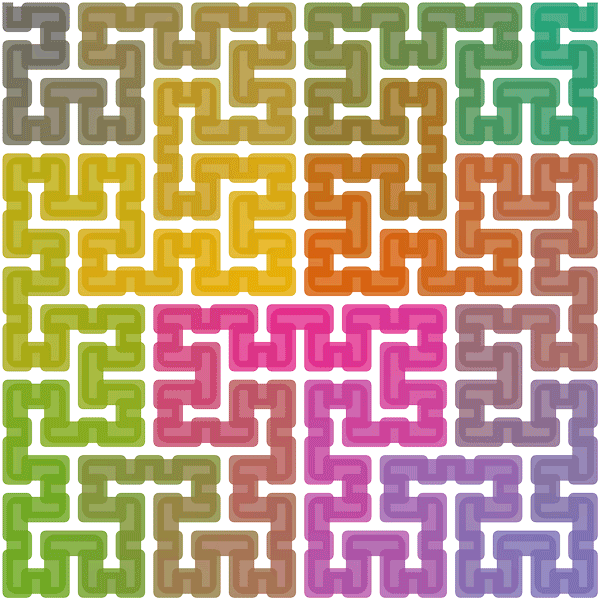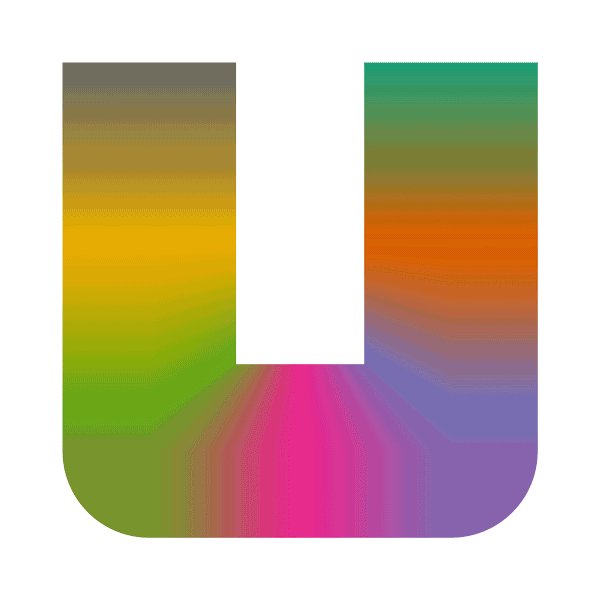
另外,Morton和Hilbert曲線還支援3D空間的遍歷:
- 2D Engine(2D引擎)
2D引擎或blitter是用於2D加速的硬體,Blitter是最早的圖形加速形式之一,今天仍然非常普遍。通常,2D引擎能夠執行以下操作:
- Blits。BLIT是GPU將記憶體矩形從一個位置複製到另一個位置的副本,源和目標可以是視訊或系統記憶體。
- 實心填充。實心填充包括用顏色填充矩形記憶體區域,也可以包括alpha通道。
- Alpha blits。Alpha Blit使用來自表面的畫素的Alpha分量來實現透明度。
- 拉伸拷貝。
下圖顯示了在兩個不同表面之間拼接矩形的範例。此操作由以下引數定義:源和目標座標、源和目標節距以及blit寬度和高度。然而,僅限於2D座標,通常不能使用blitting引擎進行透視或變換。
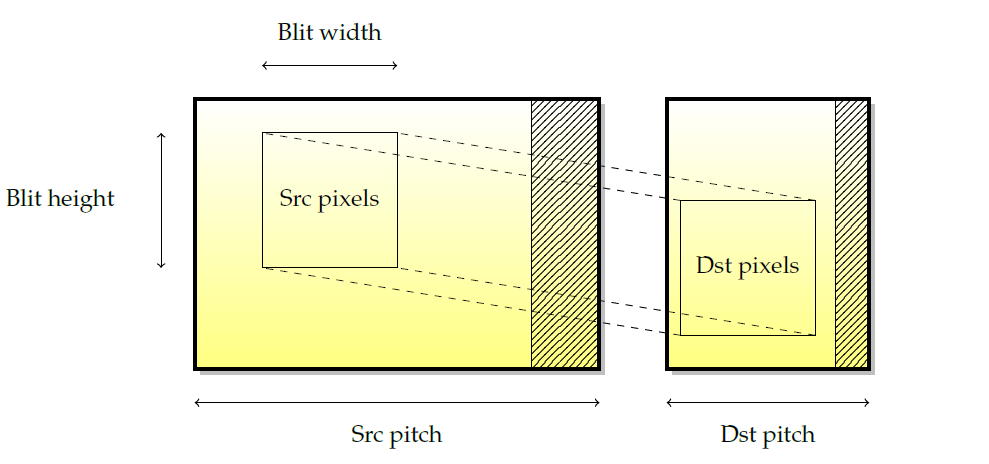
當blit發生在兩個重疊的源表面和目標表面之間時,副本的語意並不是簡單定義的,尤其是當人們認為blit發生的不是簡單的矩形移動,而是在核心逐畫素移動時。如下圖所示,如果一行一行地從上到下複製,一些源畫素將被修改為副作用。因此,拷貝方向的概念被引入到blitter中。在這種情況下,要獲得正確的副本,需要從下到上的副本。一些卡將根據表面重疊自動確定拷貝方向(例如nvidia GPU),而其他卡則不會,在這種情況下,必須由驅動處理。這就是為什麼有些GPU實際上支援負的pitch,以便告訴2D引擎後退。

最後,請記住,並非所有當前的圖形加速器都具有2D引擎。由於3D加速在技術上是2D加速的超集,因此可以使用3D引擎實現2D加速。事實上,一些驅動程式使用3D引擎來實現2D,使得GPU製造商可以完全放棄專用於2D的電晶體。然而,其他一些卡並不專用於電晶體,而是在GPU內部的3D操作之上對2D操作進行微程式化(nv10之後的nVidia卡和nv50之前的nVidia卡都是這種情況,對於Radeon R600系列,它們具有在3D之上實現2D的可選韌體)。有時會影響2D和3D操作的混合,因為它們現在共用硬體單元。
- 3D Engine(3D引擎)
3D引擎也稱為光柵化引擎。它包含一系列以管線(單向)方式交換資料的階段,如頂點->幾何->片元、圖形FIFO、DMA等。為了獲得更好的快取位置,紋理和表面通常會分塊。分塊意味著紋理不是線性儲存在GPU記憶體中,而是儲存在記憶體中,以便使紋理空間中接近的畫素也在記憶體空間中接近,例如Z階曲線和希爾伯特曲線。
- 覆蓋層和硬體精靈(Overlays and hardware sprites)。
掃描輸出:圖形顯示的最後一個階段是將資訊顯示在顯示裝置或螢幕上,顯示裝置是圖形鏈的最後一環,負責向用戶展示圖片。
此外,還有數位與模擬訊號、hsync、vsync、綠同步、聯結器和編碼器(CRTC、TMD、LVDS、DVI-I、DVI-A、DVI-D、VGA)等技術,此文忽略之。
16.2.7 圖形卡程式設計
每個PCI卡公開多個PCI資源,lspci-v列出了這些資源,包含但不限於BIOSS、MMIO範圍、視訊記憶體(或僅部分)。由於PCI總資源大小有限,通常一張卡只能將其部分視訊記憶體作為資源公開,存取剩餘記憶體的唯一方法是通過其他可存取區域的DMA(以類似於跳轉頁面的方式)。隨著視訊記憶體大小不斷增長,而PCI資源空間仍然有限,這種情況越來越普遍。
- MMIO
MMIO是卡的最直接存取方式。一系列地址暴露給CPU,每個寫操作都直接進入GPU,使得從CPU到GPU的命令通訊最簡單。這種程式設計是同步的;寫操作由CPU完成,並在GPU上以鎖步方式執行,會導致低於標準的效能,因為每次存取都會在匯流排上變成一個封包,而且CPU在提交後續命令之前必須等待以前的GPU命令完成。因此,MMIO僅用於當今驅動程式的非效能關鍵路徑。
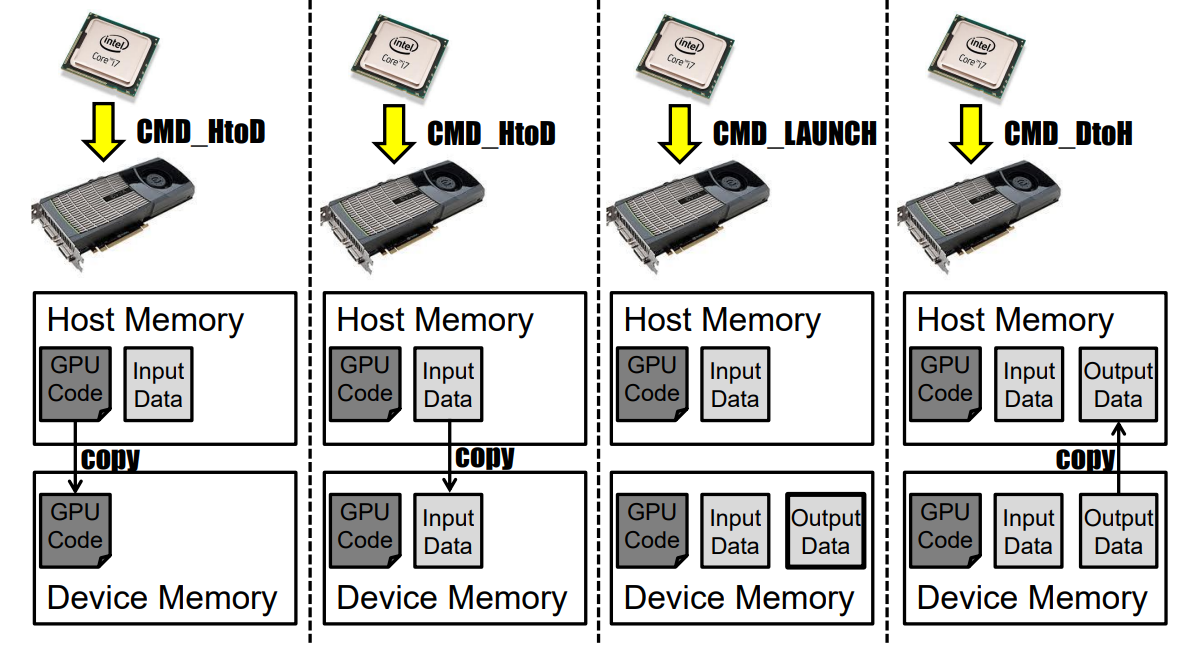
- DMA
直接記憶體存取(DMA)是指外圍裝置使用匯流排的匯流排主控功能,允許一個外設直接與另一個外設對話,而無需CPU的干預。在圖形卡的情況下,DMA最常見的兩種用途是:
1、GPU與系統記憶體之間的傳輸(用於讀取紋理和寫入緩衝區)。允許在AGP或PCI上實現紋理,以及硬體加速的紋理傳輸。
2、執行命令FIFO。由於CPU和GPU之間的MMIO是同步的,並且圖形驅動程式本身使用大量的I/O,因此需要更快的方式與卡通訊。命令FIFO是圖形卡和CPU之間共用的一塊記憶體(系統記憶體或更罕見的視訊記憶體),CPU在其中放置命令供GPU稍後執行,然後GPU使用DMA非同步讀取FIFO並執行命令。此模型允許非同步執行CPU和GPU命令流,從而提高效能。
- Interrupt(中斷)
中斷通常是硬體外圍裝置,尤其是GPU向CPU傳送事件訊號的一種方式。中斷的使用範例包括髮出圖形命令完成的訊號、發出垂直消隱事件的訊號、報告GPU錯誤等等。
當外圍裝置引發中斷時,CPU會執行一個稱為中斷處理程式的小例程(routine),該例程會搶佔其他當前執行。中斷處理程式有一個最長的執行時間,因此驅動程式必須保持較短的時間(不超過幾微秒)。為了執行更多的程式碼,常見的解決方案是從中斷處理程式排程一個小任務(tasklet)。
16.2.8 圖形硬體案例
- 前向渲染
前向渲染器(即經典渲染器)是渲染三維圖元最直接的方法,將向GPU逐個提交圖形API以繪製幾何體,並重復這個過程,是大多數移動GPU中使用的方法。
與其他體系結構相比,NVidia硬體具有多種特殊性。第一個是多個上下文的可用性,它使用多個命令FIFO(類似於某些高階infiniband網路卡的功能)和上下文切換機制來實現這些FIFO之間的轉換。一個小型韌體用於上下文之間的上下文切換,負責將圖形卡狀態儲存到記憶體的一部分並恢復另一個上下文。使用迴圈演演算法的排程系統處理上下文的選擇,並且時間片是可程式化的。
第二個特性是圖形物件的概念。Nvidia硬體具有兩個GPU存取級別:第一個是原始級別,用於上下文切換;第二個是圖形物件,對原始級別進行微程式設計以實現高階功能(例如2D或3D加速)。
- 延遲渲染
延遲渲染器是GPU的不同設計。驅動程式將其儲存在記憶體中,而不是在渲染API提交時渲染每個3D圖元,當它注意到幀結束時,它會發出單個硬體呼叫來渲染整個場景。與經典體系結構相比,延遲渲染有許多優點:
1、通過將螢幕拆分為分塊(通常在16 x 16到32 x 32畫素範圍內),可以實現更好的渲染位置。然後,GPU可以迭代這些分塊,對於其中的每個分塊,可以在內部(迷你)zbuffer中解析每畫素深度。渲染完整個分塊後,可以將其寫回視訊記憶體,從而節省寶貴的頻寬。類似地,由於可見性是在獲取紋理資料之前確定的,因此僅讀取有用的紋理資料(再次節省頻寬),並且僅對可見片元執行片元著色器(節省了計算能力)。
2、如果不需要深度緩衝區值,則無需將其寫入記憶體。深度緩衝區解析度可以在GPU內的每個分塊上實現,並且永遠不會寫回視訊記憶體,因此可以節省視訊記憶體頻寬和空間。
當然,分塊渲染需要在開始繪製之前將整個場景儲存在記憶體中,並且還將增加延遲,因為我們甚至需要在開始繪製之前等待幀結束。當驅動程式已經允許應用程式提交下一幀的資料時,通過在GPU上繪製給定幀可以部分隱藏延遲問題。然而,在某些情況下(回讀、跨程序同步),並不總是能夠避免它。
延遲渲染器對於頻寬通常非常稀缺的嵌入式平臺特別有用,並且應用程式非常簡單,因此額外的延遲和方法的限制無關緊要。SGX是延遲渲染GPU的一個範例。它使用分塊結構。SGX著色器結合了混合和深度測試。延遲渲染器的另一個範例是Mali系列GPU。
總之,計算機中有多個記憶體域,它們不一致。GPU是一臺完全獨立的計算機,有自己的匯流排、地址空間和計算單元。CPU和GPU之間的通訊是通過匯流排實現的,對效能有著非常重要的影響。GPU可以使用兩種模式進行程式設計:MMIO和命令FIFO。顯示裝置沒有標準的輸出方法。
16.3 作業系統圖形驅動
16.3.1 Windows圖形驅動
16.3.1.1 WDDM概述
Windows圖形驅動程式由IHV(英特爾、NVIDIA、AMD、高通、PowerVR、VIA、Matrox等)實現並維護,是非常豐富的驅動程式。支援基本回退(基本渲染、基本顯示),實現最低限度的驅動功能,還支援虛擬化(VMware、Virtual Box、Parallels驅動程式)、遠端桌面方案(XenDesktop、RDP等)、虛擬顯示(intelligraphics、extramon等)。
WDDM(Windows Display Driver Model)分為使用者模式和核心模式,移動到使用者模式是為了穩定性和可靠性。
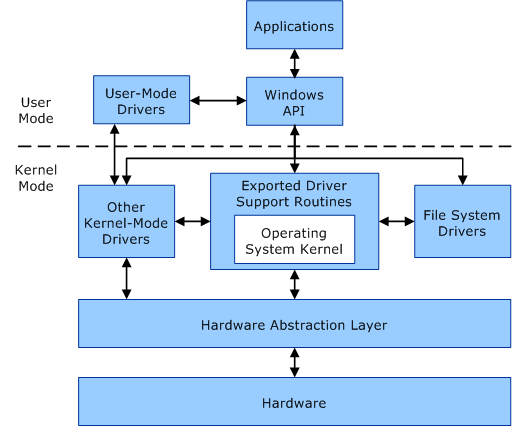
使用者模式和核心模式元件之間的通訊。
vista之前的大部分藍屏都是由圖形驅動程式(來自MSDN):「在Windows XP中,大型複雜的顯示驅動程式可能是系統不穩定的主要原因。這些驅動程式完全在核心模式下執行(即深入系統程式碼),因此,驅動程式中的一個問題通常會迫使整個系統重新啟動。根據在Windows XP時間段內收集的故障分析資料,顯示驅動程式佔所有藍屏的20%。」
在大多數程序中,使用者模式部分作為dll的一部分執行,仍然可以存取表面(編碼器/解碼器、二進位制植入、某些API可能部分(或間接)暴露於遠端存取表面(例如WebGL)。下圖顯示了支援WDDM所需的體系結構。
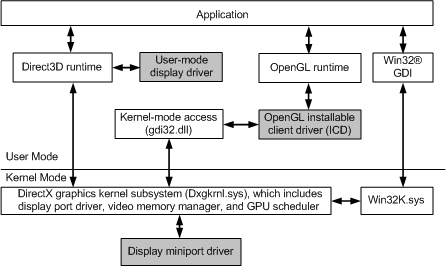
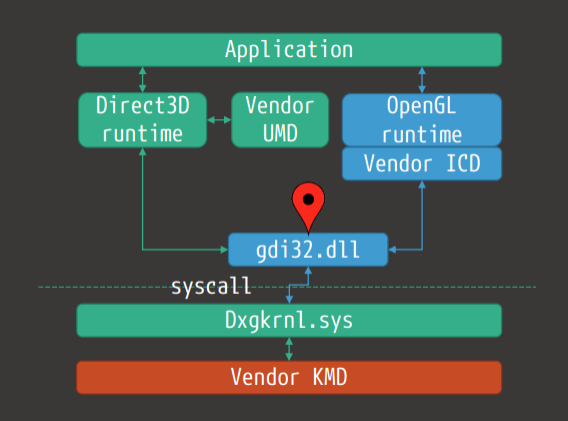
Windows的驅動模型演變歷史如下:
-
Windows XP:XPDM。
-
Windows Vista:WDDM 1.0、DWM和Aero。
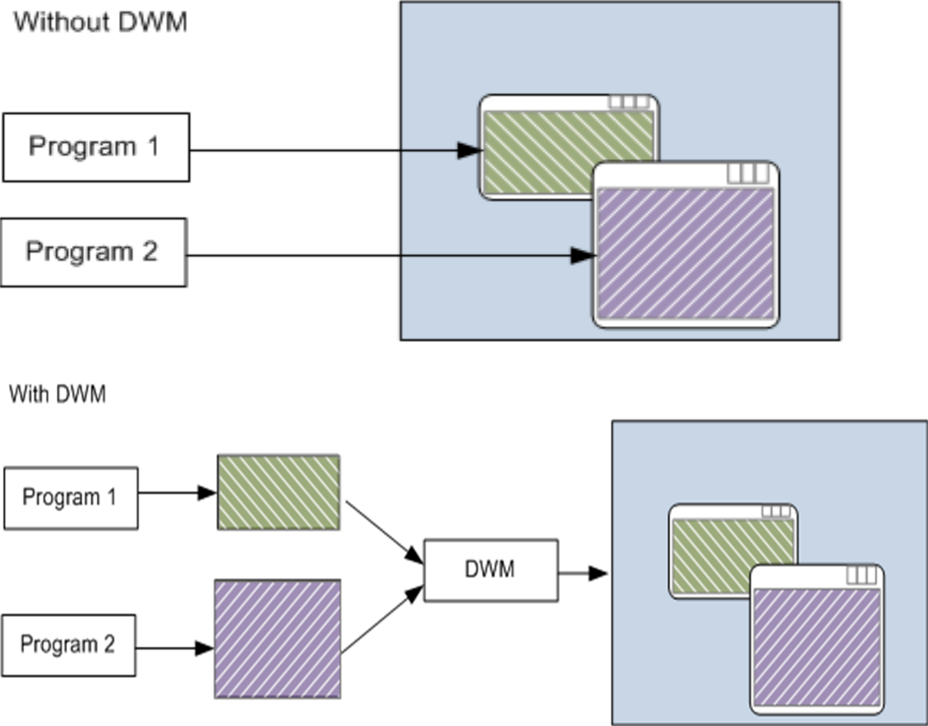
沒有DWM和有dWM的對比。因為DWM處理桌面的合成,所以當每個程式都必須跟蹤自己的顯示時,新功能就不可用了,工作列中的Aero Peek,Aero Glass可在最上面的視窗後檢視應用程式,能夠輕鬆改變方向,許多新的Windows動畫都依賴於DWM,包括「收縮到工作列」效果。
-
Windows 7:WDDM 1.1,擴充套件DWM。
-
Windows 8:WDDM 1.2,刪除XPDM支援。
-
Windows 8.1:WDDM 1.3。
-
Windows 10:WDDM 2.0。
16.3.1.2 WDDM架構
早期的Windows版本(如Vista),圖形/遊戲/多媒體/呈現堆疊架構如下:
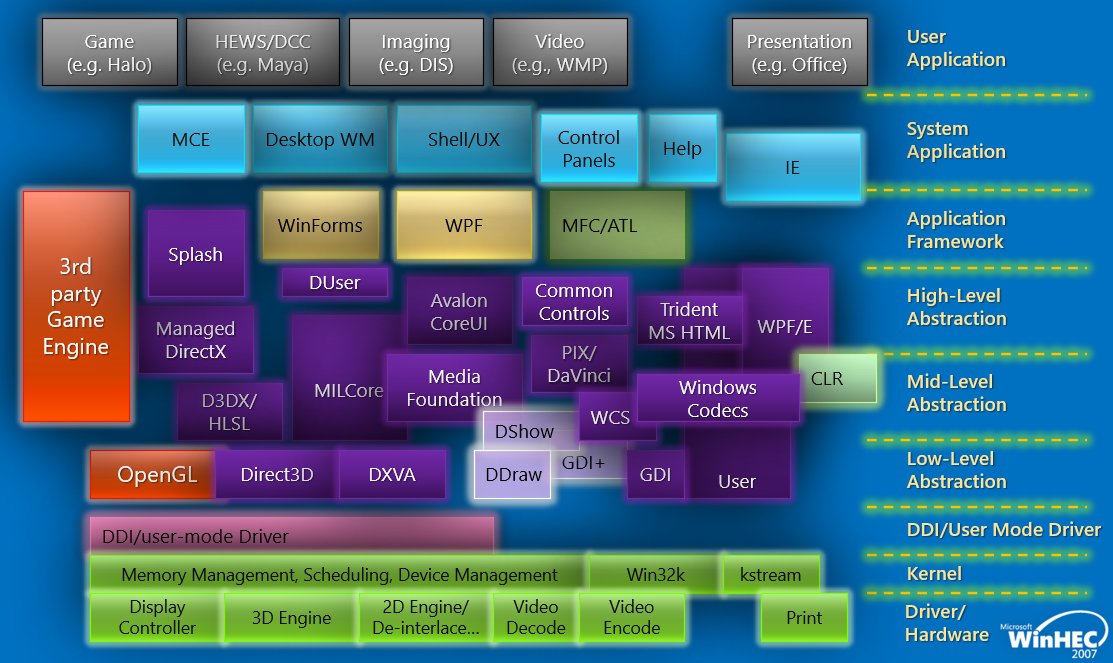
簡化後的架構圖如下:
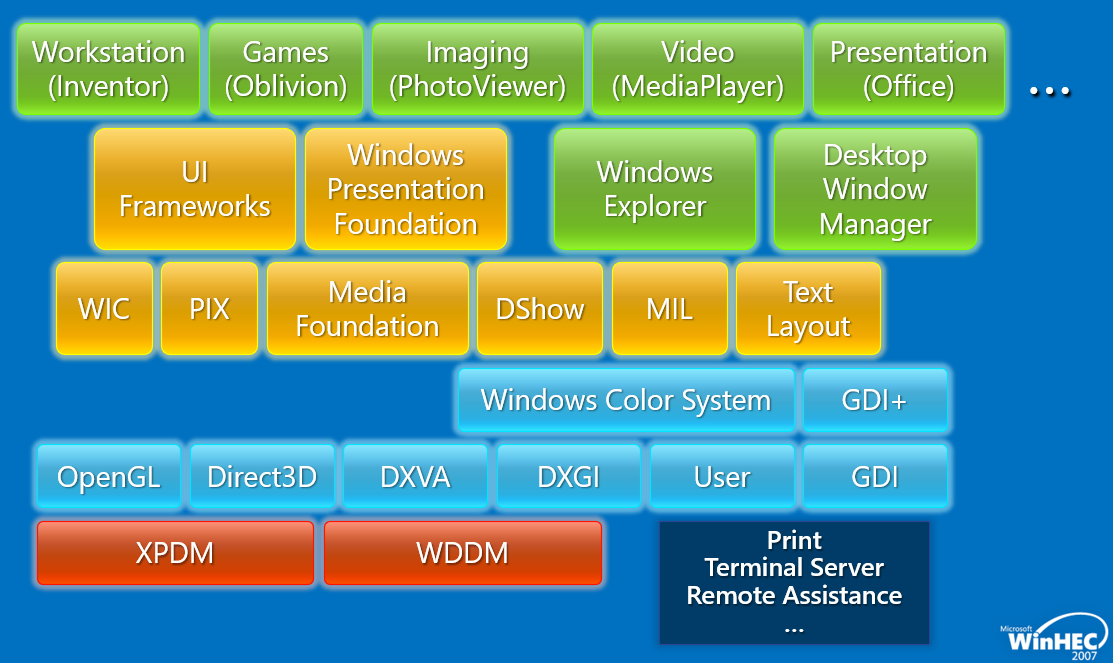
Windows Vista中的圖形核心如下:
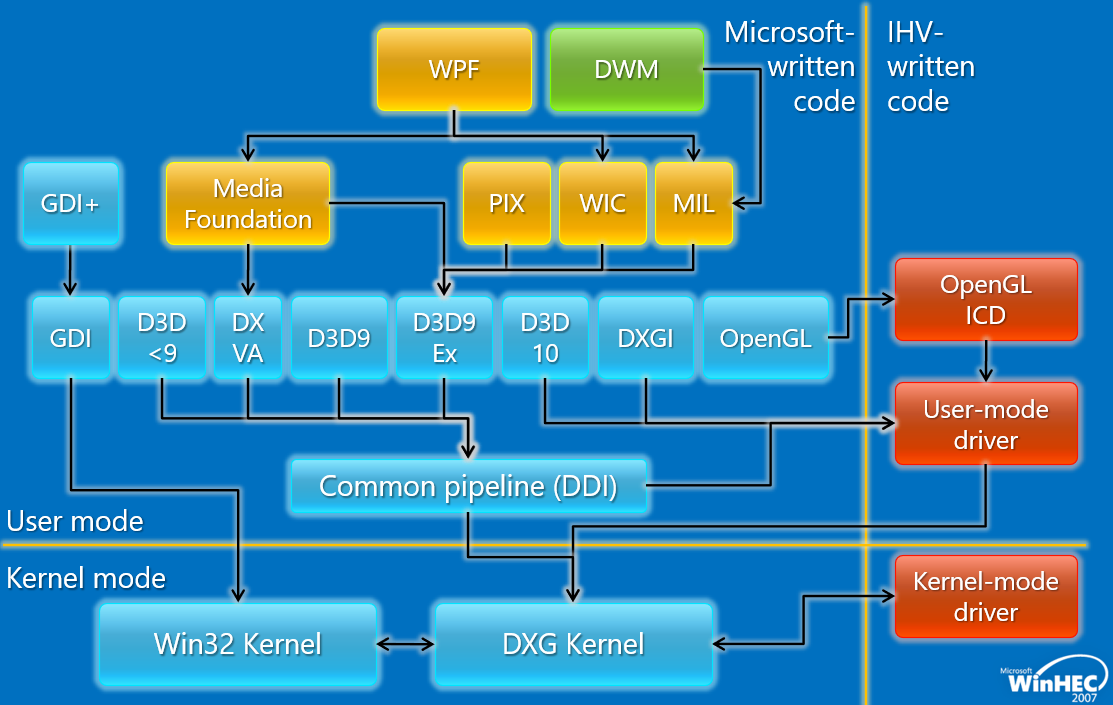
其中Windows Display Driver Model(WDDM,Windows顯示驅動模型)相關的模組如下:
WDDM是構建所有圖形的基石,基本原則是圖形功能正常,重新架構整個驅動程式堆疊,鞏固10年的發展,新的驅動程式模型,考量穩定性、安全、可用性(應用程式虛擬化)、效能。
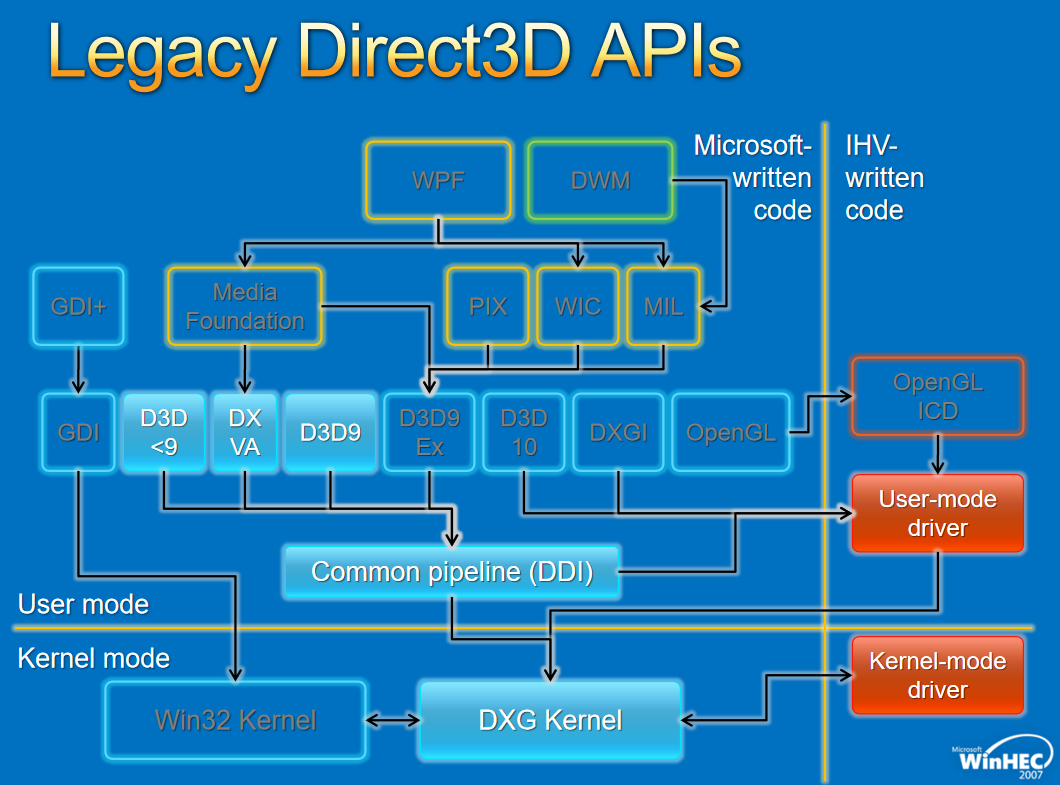
對於圖形API,早期的WDDM存在幾個版本,分別如下:
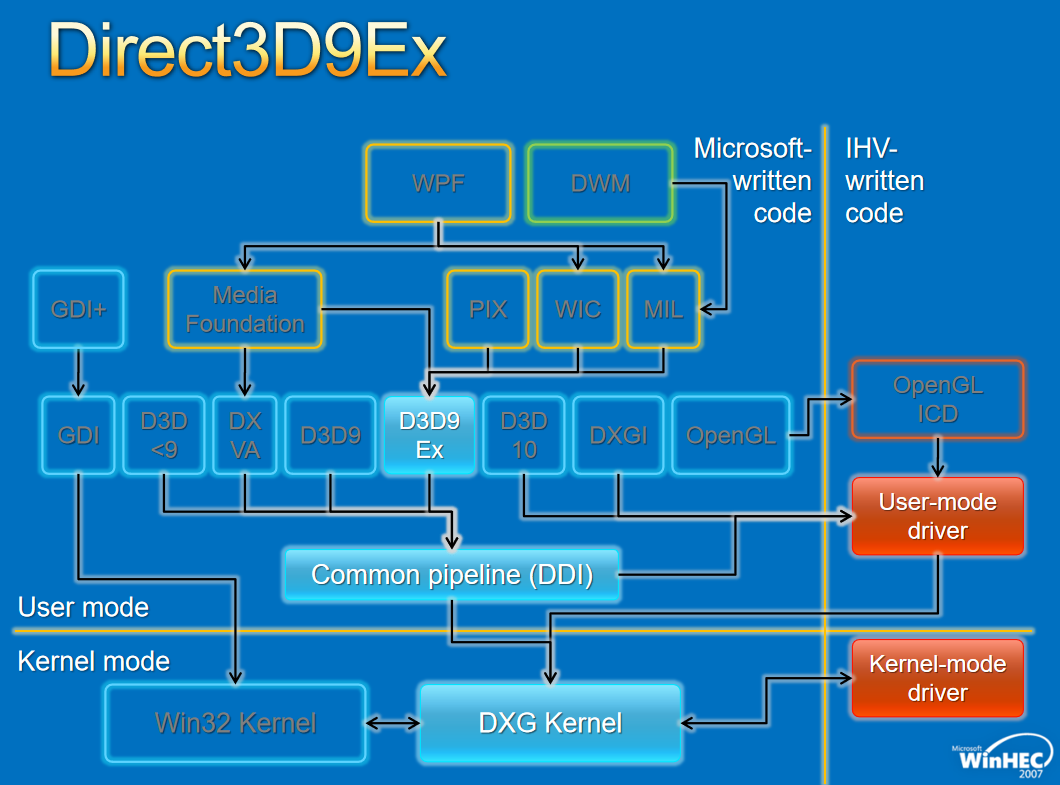
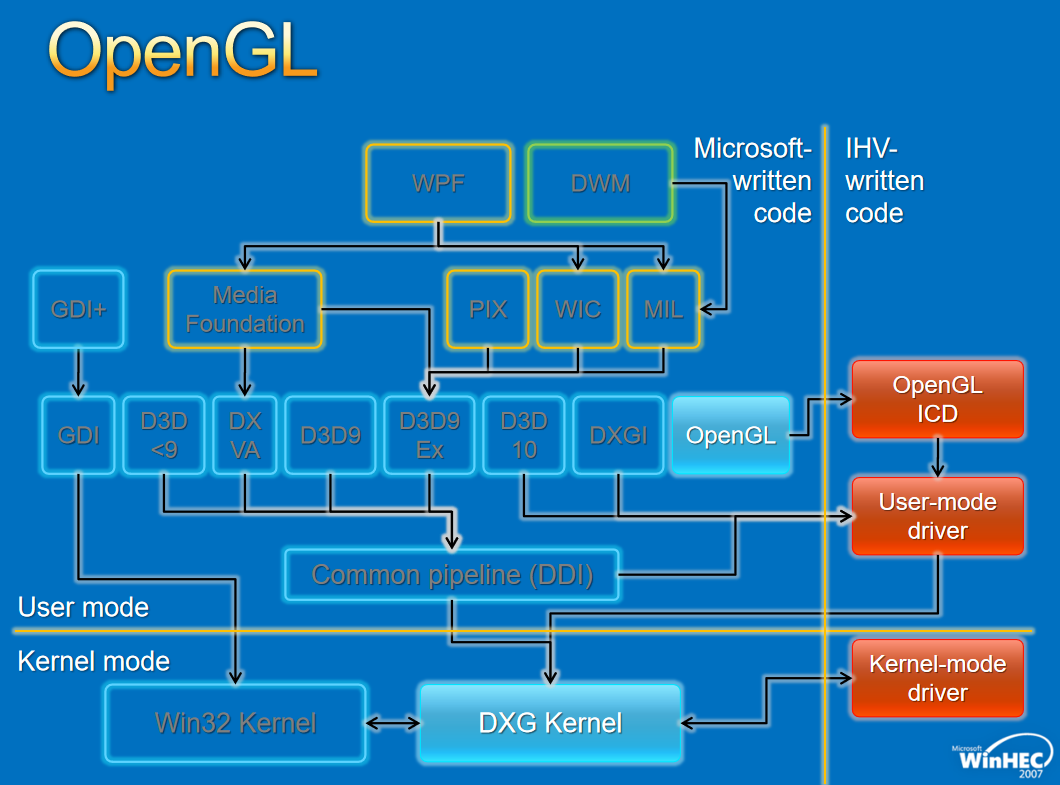
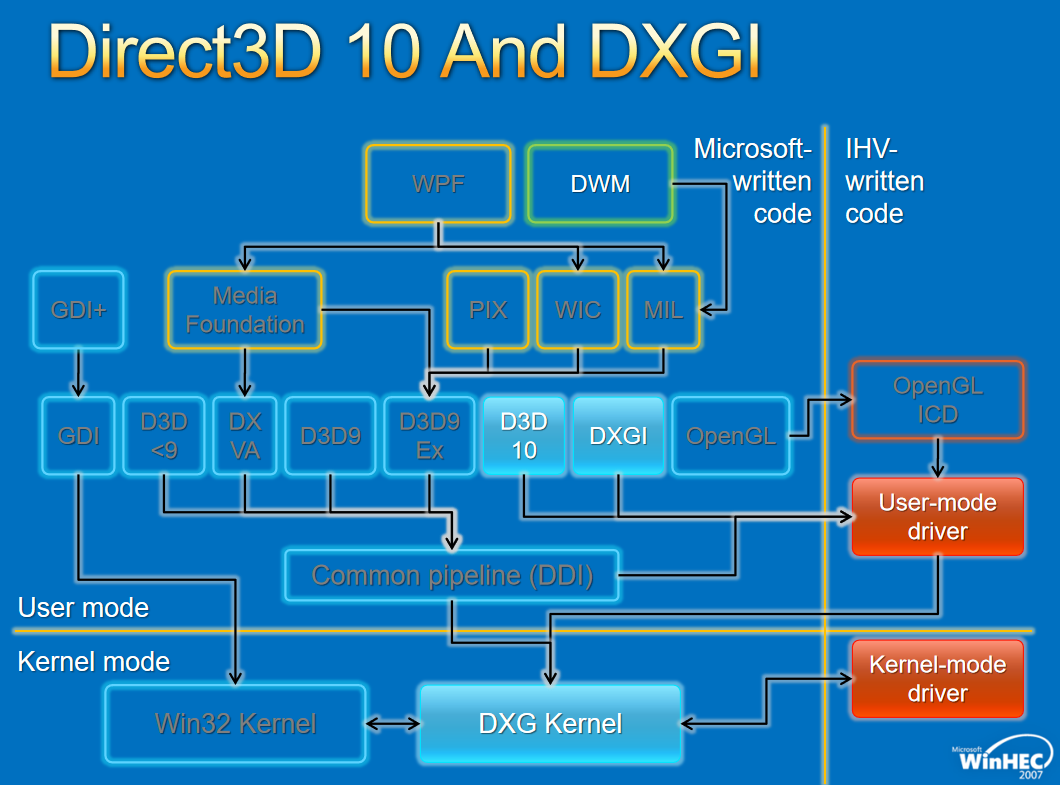
對於Window視窗管理,架構如下:
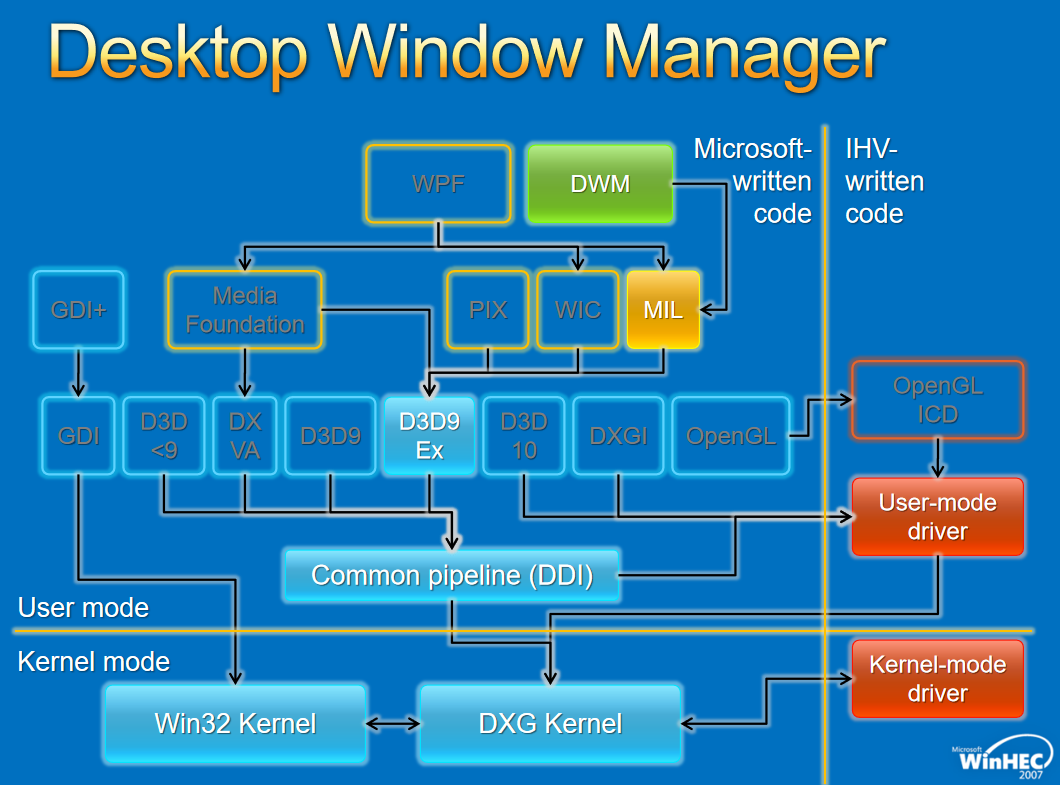
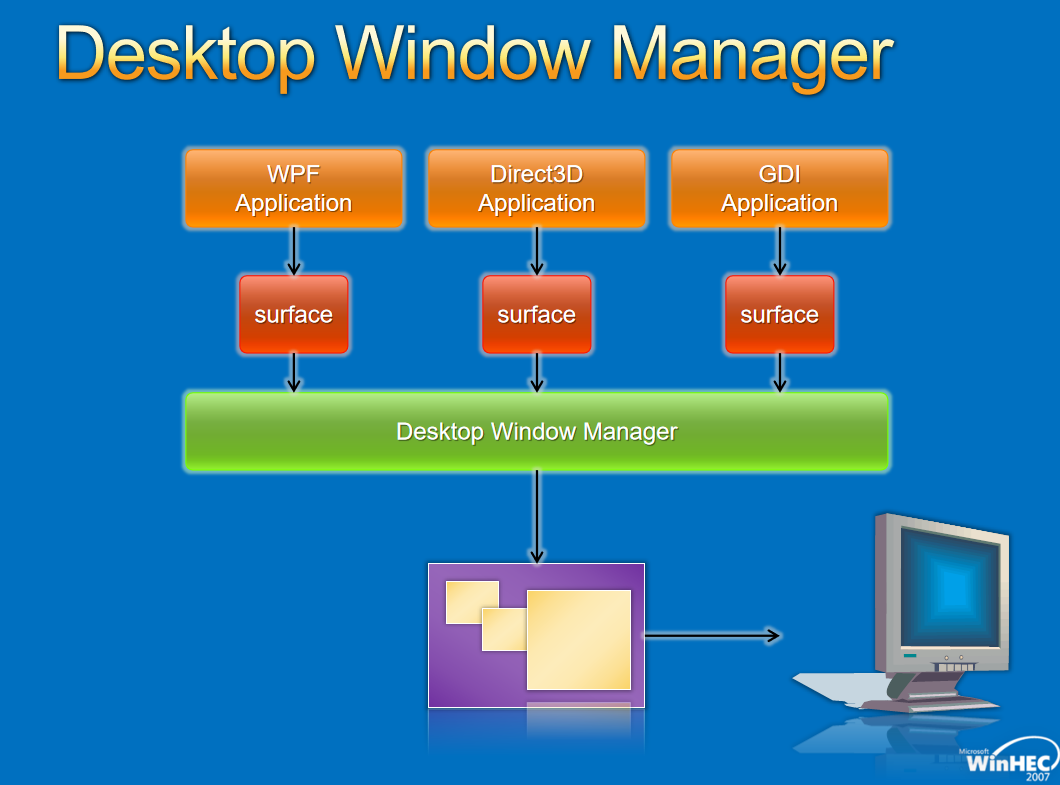
Windows圖形驅動程式模型適用於所有Windows使用者的單一圖形驅動程式模型,圖形驅動模型增強使用者體驗,創新實現了新的視覺和計算場景,效能和可靠性的改進使Windows能夠跨一系列形狀因素進行擴充套件。下面兩圖分佈展示了Windows 7和8的對比:

WDDM 1.2功能集:
-
增強使用者體驗:立體3D體驗,平滑螢幕旋轉,無縫啟動和恢復,顯示「容器ID」支援。
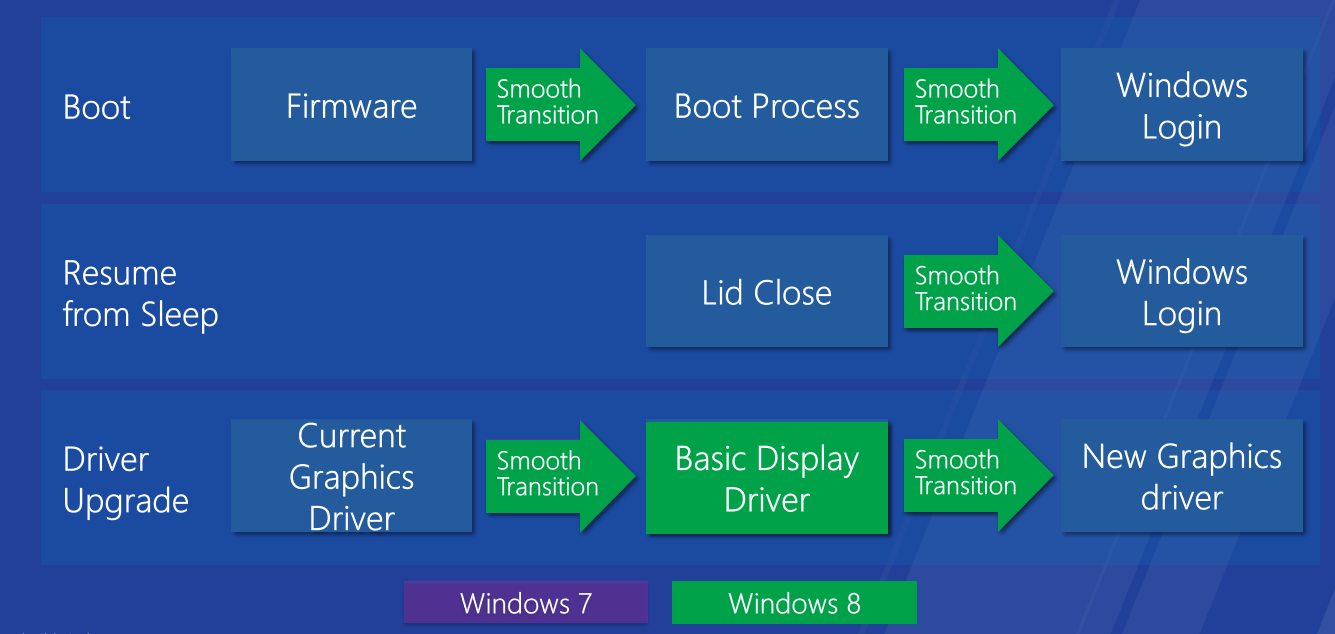
無縫引導、恢復和驅動程式升級。
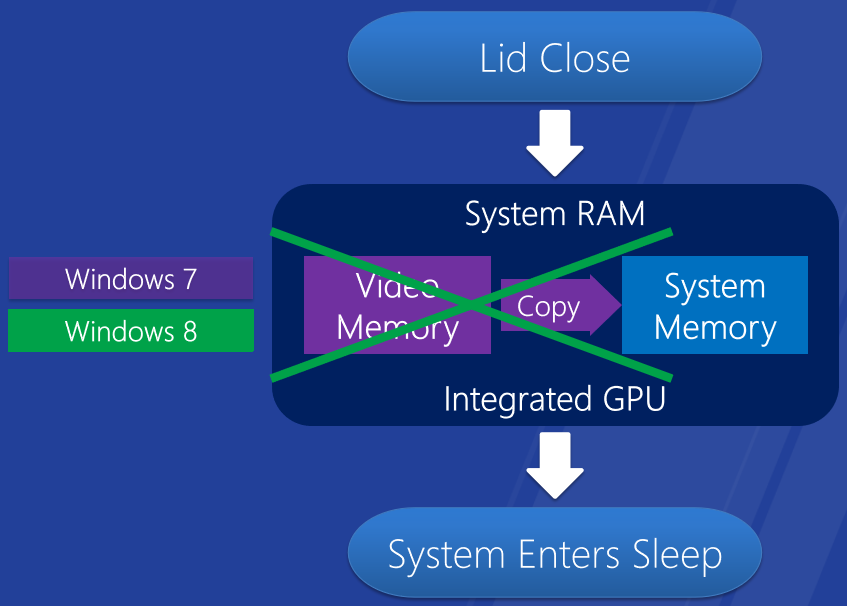
Windows 8上更快的睡眠和恢復-整合GPU。
-
更好的效能:GPU優先權,睡眠和恢復優化,視訊記憶體提供和回收API、DDI,細粒度裝置電源管理,SoC優化,基於分塊的渲染優化。
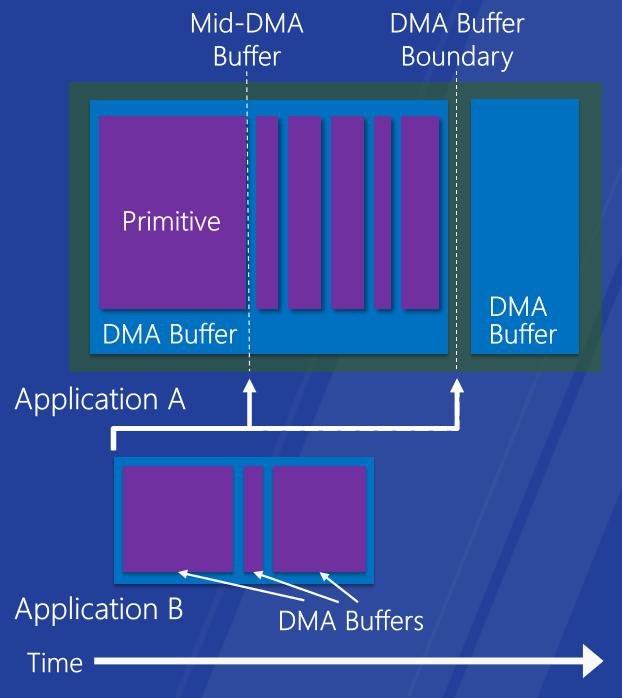
改進的桌面和觸控響應能力。快速流暢的地鐵風格和觸控體驗,支援細粒度GPU搶佔,搶佔越精細,響應速度越快。
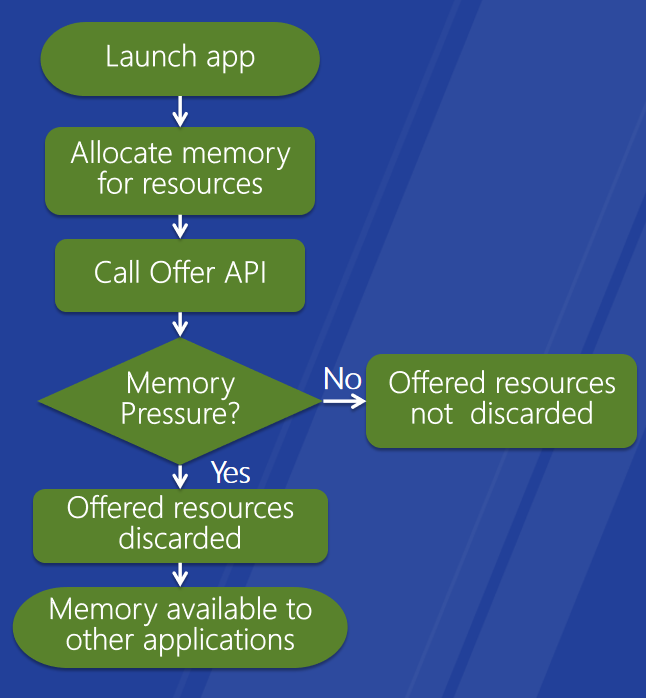
視訊記憶體提供和回收API。改進的視訊記憶體分配方案,優點:提高應用程式的視訊記憶體可用性,新D3D API和WDDM DDI
:D3D應用程式、WDDM 1.2驅動程式。
元件電源管理。
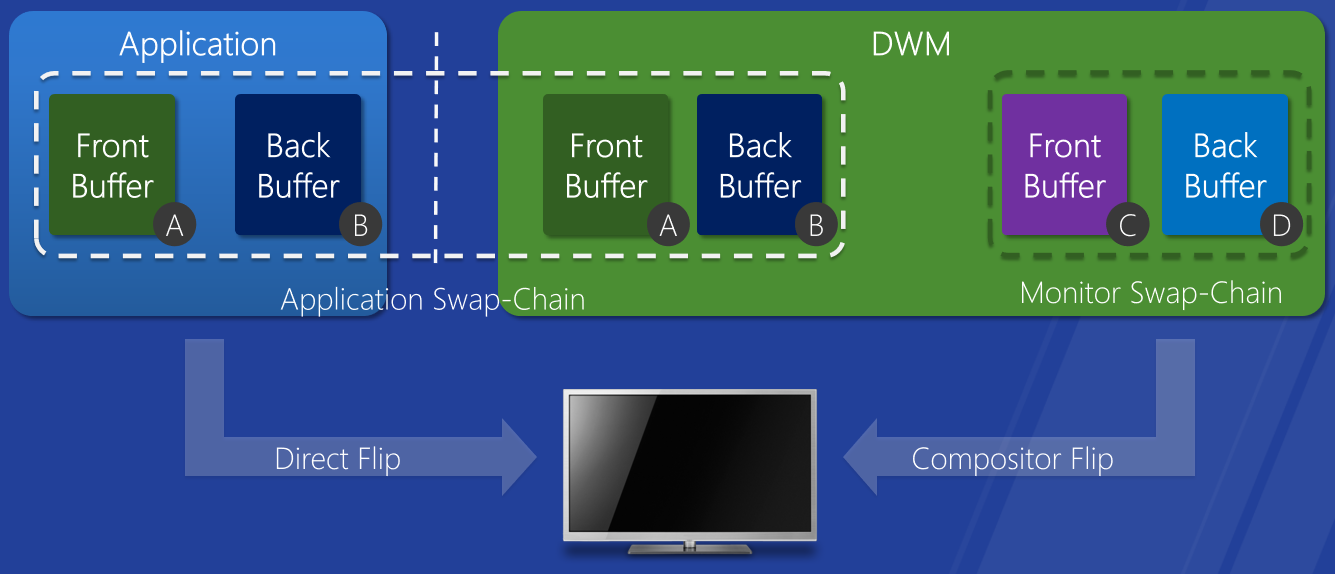
直接翻轉。優化桌面組合以提高能效,在視訊幀播放期間節省記憶體拷貝。
基於平鋪的渲染優化。TBR GPU的日益普及,針對TBR優化的圖形堆疊,節省電力,最小化記憶體頻寬使用率,分塊減少。
-
改善可靠性:改進的GPU容錯能力,為開發人員和系統製造商提供更好的診斷,無需重新啟動伺服器的驅動程式升級。
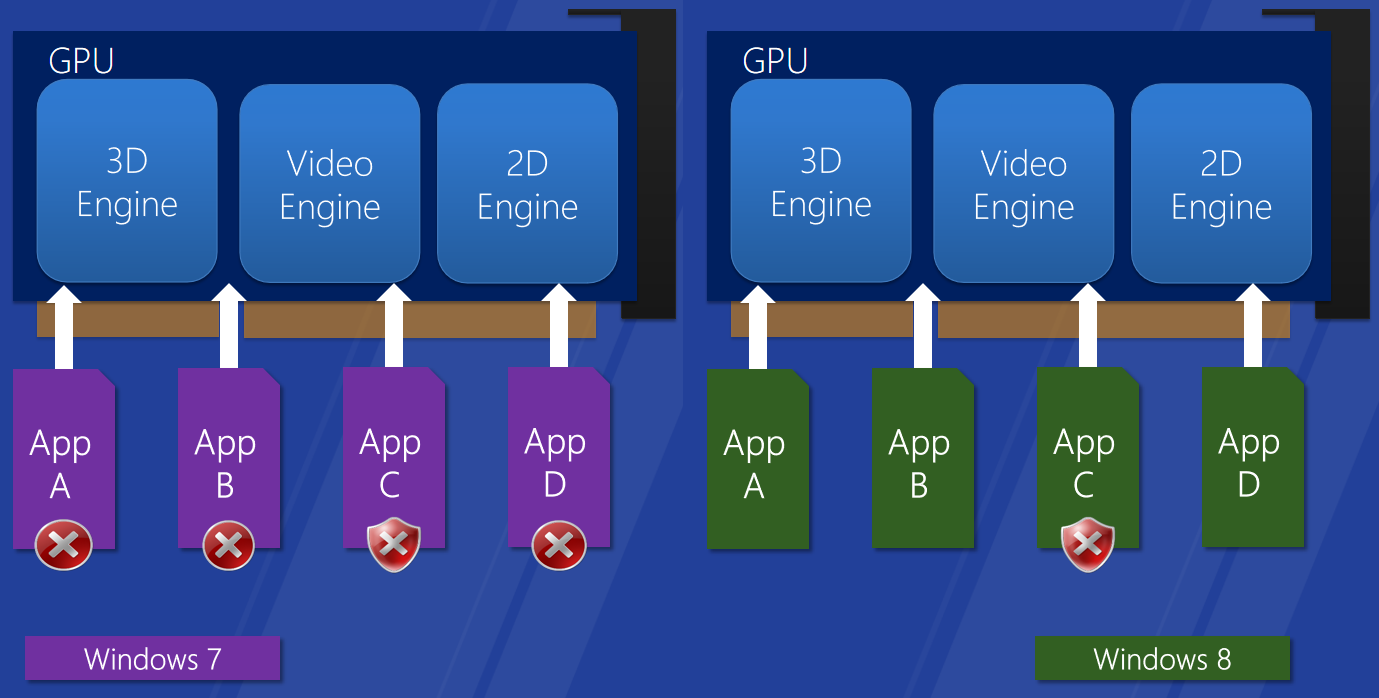
改進的GPU容錯能力。左:windows 7的超時檢測和恢復改進,以前的作業系統,全域性TDR,所有圖形應用程式重置並重新啟動。右:Windows 8的GPU掛起檢測,搶佔超時,能夠執行長時間執行的任務,逐引擎的TDR。
總之,Windows 8的WDDM實現視覺上豐富、快速和流暢的終端使用者體驗,通過各種形式因素帶來全新體驗,優化效能,同時節省電源,利用效能工具調整圖形驅動程式。
如今,WDDM的驅動架構如下:

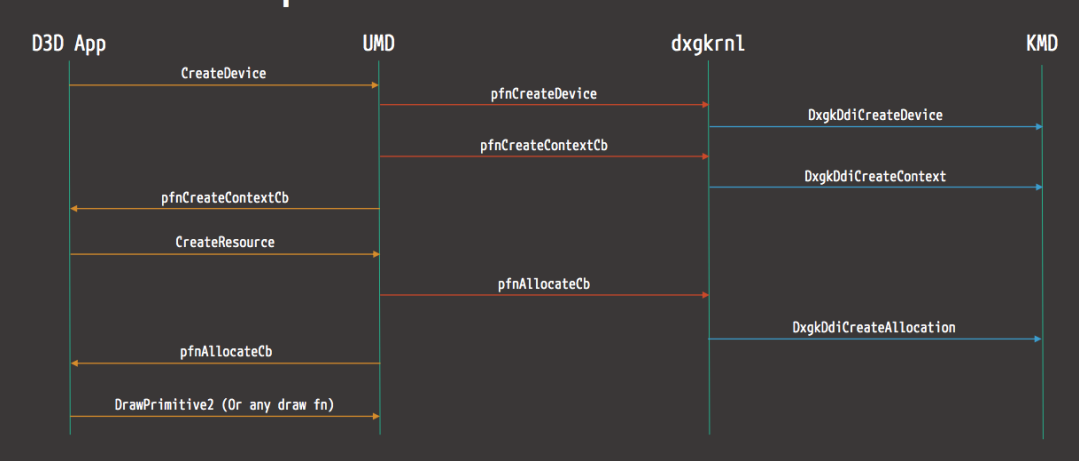
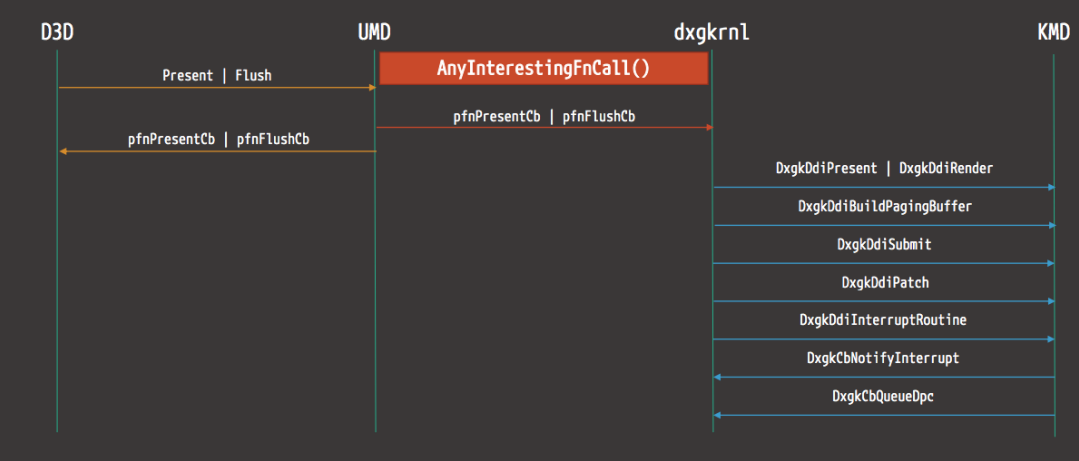
以下是來自D3D的渲染操作流範例圖:
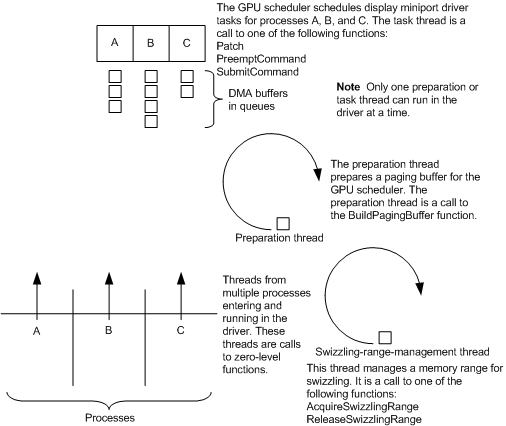
下圖顯示了WDDM中顯示微型埠驅動程式的執行緒同步工作方式:
16.3.1.3 WDDM介面
kmd驅動是WDDM的核心模式的其中一個模組,它看起來如下所示:
NTSTATUS DriverEntry(IN PDRIVER_OBJECT DriverObject, IN PUNICODE_STRING RegistryPath)
{
(...)
DRIVER_INITIALIZATION_DATA DriverInitializationData;
(...)
DriverInitializationData.DxgkDdiEscape = DDIEscape;
(...)
Status = DxgkInitialize(DriverObject, RegistryPath, &DriverInitializationData);
(...)
}
WDDM kmd驅動程式在同步時,為這些回撥提供了一個執行緒模型,該模型基本上由四個級別組成(其中每個回撥屬於其中一個級別):
3:只有一個執行緒可以進入,GPU必須處於空閒狀態,沒有正在處理的DMA緩衝區,視訊記憶體被逐出到主機CPU記憶體。
2:與3相同,但視訊記憶體移出除外。
1:呼叫被分類為類,每個類只允許一個執行緒同時呼叫回撥。
0:完全可重入。
如果允許並行,則兩個並行執行緒不能屬於同一程序,在尋找潛在的競爭條件場景時,需要謹記這一點。
對於WDDM kmd驅動程式入口點,相當少的回撥從userland獲得了重要的輸入:退出、渲染、分配、QueryAdapter,在找到它們之前,我們需要執行正確的驅動程式初始化,然後檢視回撥。涉及的結構體或介面:
// Escape
NTSTATUS D3DKMTEscape(_In_ const D3DKMT_ESCAPE *pData );
typedef struct _D3DKMT_ESCAPE
{
D3DKMT_HANDLE hAdapter;
D3DKMT_HANDLE hDevice;
D3DKMT_ESCAPETYPE Type;
D3DDDI_ESCAPEFLAGS Flags;
VOID *pPrivateDriverData;
UINT PrivateDriverDataSize;
D3DKMT_HANDLE hContext;
} D3DKMT_ESCAPE;
// Render
NTSTATUS APIENTRY DxgkDdiRender(_In_ const HANDLE hContext, _Inout_ DXGKARG_RENDER *pRender){ ... }
typedef struct _DXGKARG_RENDER
{
const VOID CONST *pCommand;
const UINT CommandLength;
VOID *pDmaBuffer;
UINT DmaSize;
VOID *pDmaBufferPrivateData;
UINT DmaBufferPrivateDataSize;
DXGK_ALLOCATIONLIST *pAllocationList;
UINT AllocationListSize;
D3DDDI_PATCHLOCATIONLIST *pPatchLocationListIn;
UINT PatchLocationListInSize;
D3DDDI_PATCHLOCATIONLIST *pPatchLocationListOut;
UINT PatchLocationListOutSize;
UINT MultipassOffset;
UINT DmaBufferSegmentId;
PHYSICAL_ADDRESS DmaBufferPhysicalAddress;
} DXGKARG_RENDER;
// Allocation
NTSTATUS APIENTRY DxgkDdiCreateAllocation(const HANDLE hAdapter, DXGKARG_CREATEALLOCATION *pCreateAllocation){ ... }
typedef struct
_DXGKARG_CREATEALLOCATION
{
const VOID *pPrivateDriverData;
UINT PrivateDriverDataSize;
UINT NumAllocations;
DXGK_ALLOCATIONINFO *pAllocationInfo;
HANDLE hResource;
DXGK_CREATEALLOCATIONFLAGS Flags;
} DXGKARG_CREATEALLOCATION;
// queryadapter
NTSTATUS APIENTRY DxgkDdiQueryAdapterInfo(HANDLE hAdapter, DXGKARG_QUERYADAPTERINFO *pQueryAdapterInfo ){ ... }
typedef struct _DXGKARG_QUERYADAPTERINFO
{
DXGK_QUERYADAPTERINFOTYPE Type;
VOID *pInputData;
UINT InputDataSize;
VOID *pOutputData;
UINT OutputDataSize;
} DXGKARG_QUERYADAPTERINFO;
16.3.2 Linux圖形驅動
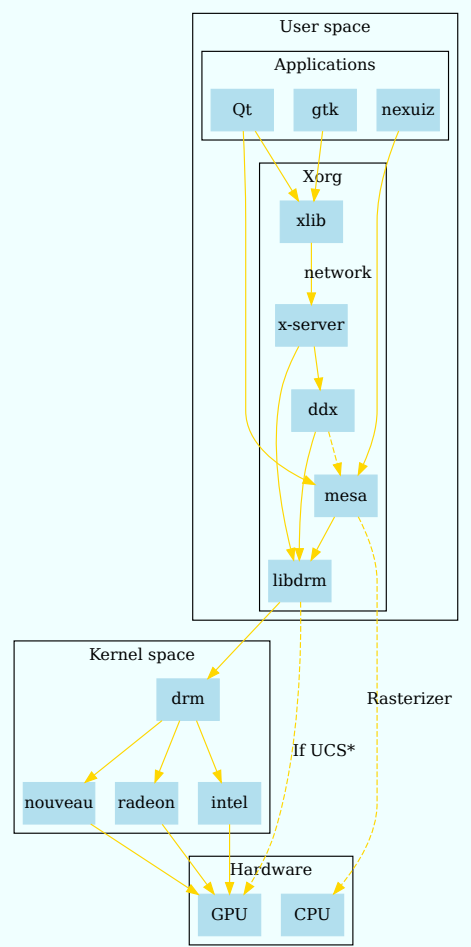
Linux圖形堆疊在過去幾年中經歷了許多演變。本節的目的是詳細說明這段歷史,並給出多年來所做更改背後的理由。今天,設計仍然深深植根於這段歷史,本節將解釋這段歷史,以更好地推動Linux圖形堆疊的當前設計。下面簡述Linux圖形驅動架構涉及的各個模組或概念:
-
PCI (Peripheral Component Interconnect):使用者需要將圖形卡插入主機板上的PCI插槽。PCI規範不能免費向公眾提供,此計算機匯流排的程式設計入口點是PCI設定空間,是通過x86體系結構I/O埠地址空間中的0xCF8和0xCFC I/O埠存取的。更具體地說,0xCF8是地址埠,0xCFC是資料埠。每個PCI實體(匯流排上的最小可定址單元,如記憶體中的位元組)有自己的設定空間。實體的設定空間中將有3種型別的資源:
- 輸入/輸出記憶體。這是實體解碼的實體記憶體塊。簽出/proc/iomem的內容。
- 輸入/輸出埠。將由實體解碼的I/O埠空間中的資料。簽出/proc/ioports檔案的內容。
- IRQ(中斷請求)。簽出/proc/irq目錄的內容。
此類資源的設定使用2個系統完成:
- PCI PNP(隨插即用)已過時。
- ACPI(高階設定和電源介面),目前實現的方法,是一項由OS(作業系統)核心完成的任務。
-
AGP (Accelerated Graphic Port)、PCI Express card:系統將看到插入AGP插槽或PCI Express插槽的圖形卡,就像PCI裝置一樣。
-
ACPI (Advanced Configuration and Power Interface):如今的計算機通常具有ACPI功能,ACPI取代PCI PNP用於實體設定,併為該批次新增電源管理、多處理器sweet和其他內容。與PCI不同,ACPI規範是免費提供的。ACPI基於記憶體表:在計算機啟動時,作業系統必須在實體記憶體中找到RSDP(根系統描述指標)。在x86體系結構上,需要在特定的實體記憶體區域中查詢「RSD PTR」字串。
-
XORG、DDX (Device Dependent X)和DIX (Device Independent X):XORG是X Window系統使用者端libs和伺服器的一部分、整個專案的參考實現,需要了解X Window核心協定。請記住,XORG有多個伺服器,如DMX(分散式多頭X)伺服器、kdrive伺服器或著名的XGL伺服器。DIX是XORG的一部分,負責處理使用者端、網路透明度和軟體渲染。DDX是XORG處理硬體(以及在一定程度上處理作業系統)的一部分。
-
EXA:EXA是XORG加速的API,xfree86 DDX是唯一實現它的DDX。每次初始化螢幕時(例如,在新伺服器生成開始時),都會初始化EXA加速(如果啟用)。
-
DRI (Direct Rendering Infrastructure) 和DRM (Direct Rendering Manager):DRI和DRM是圖形卡硬體程式設計的管道,主要由mesa(即「libre」opengl實現)使用,但由於對硬體的存取必須在所有圖形卡硬體使用者端之間同步,xfree86 DDX視訊驅動模組必須處理它,因為它本身就是這樣的使用者端。然後,EXA當想要執行加速操作時,必須與硬體進行DRI對話。有一個用於xfree86 DDX程式碼的DRI xfree86 DDX模組,希望通過DRI方式進行硬體存取。此模組和相關的xfree86 DDX程式碼將使用DRM使用者級介面庫libdrm。理論上,未來的DRM演進將允許我們擺脫XORG伺服器的PCI程式設計程式碼。
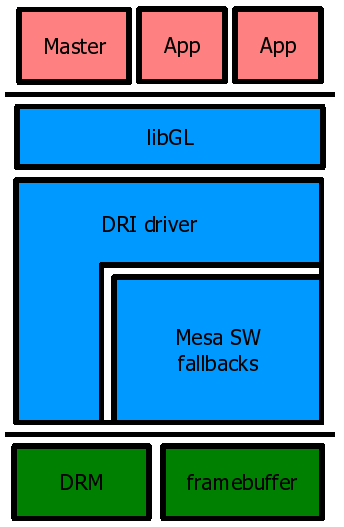
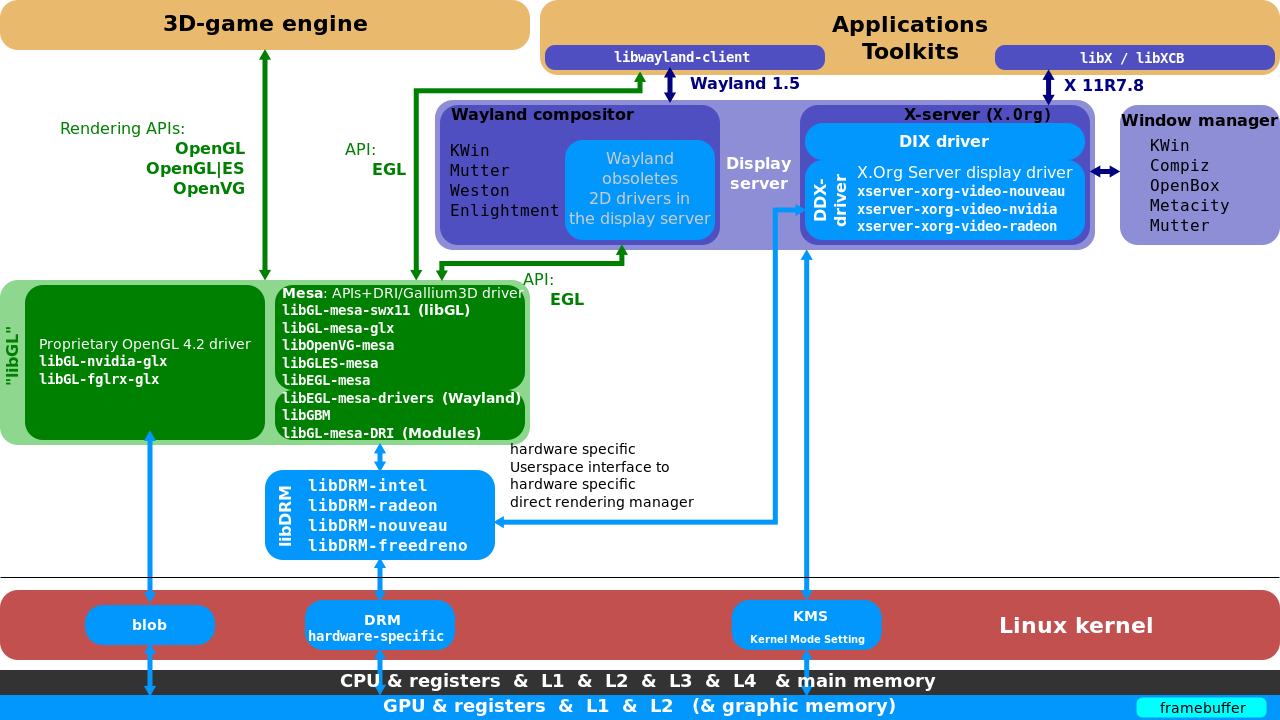
16.3.2.1 X11基礎架構
X11架構圖如下,包含DIX(裝置無關X)、DDX(裝置相關X)、Xlib、通訊端、X協定、X擴充套件,shm->用於傳輸的共用記憶體,XCB->非同步等。
X服務的內部互動圖如下:
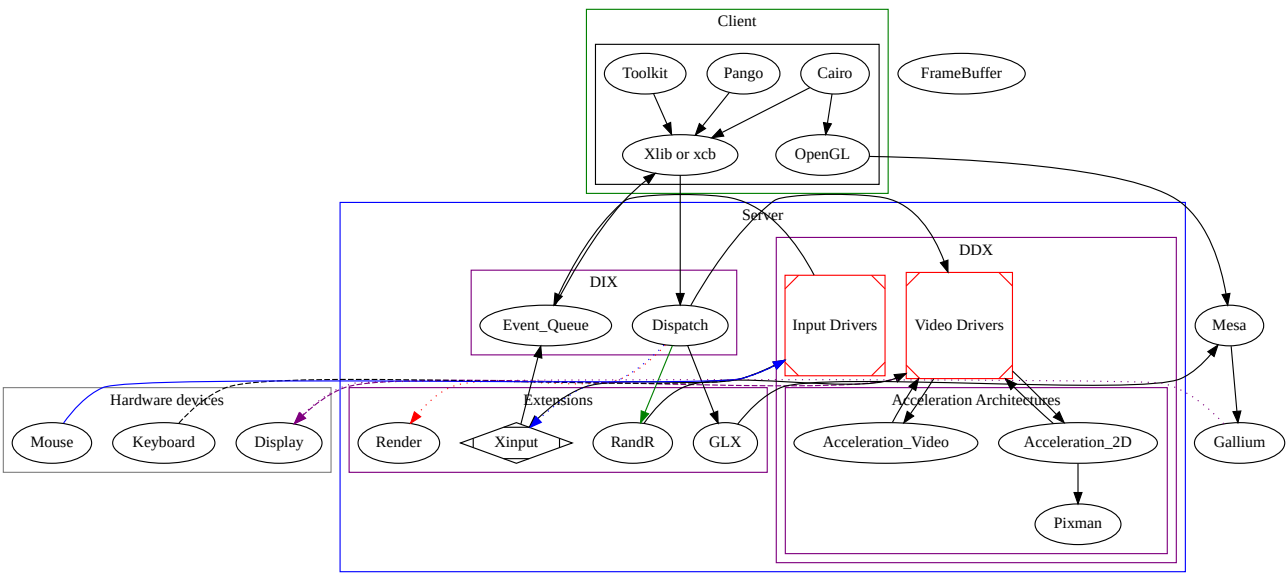
16.3.2.2 DRI/DRM基礎架構
直接渲染管理器(DRM)是Linux核心的一個子系統,負責與現代視訊卡的GPU介面。DRM公開了一個API,使用者空間程式可以使用該API向GPU傳送命令和資料,並執行諸如設定顯示器的模式設定等操作。DRM最初是作為X Server直接渲染基礎設施的核心空間元件開發的,但從那時起,它已被其他圖形堆疊替代品(如Wayland)使用。
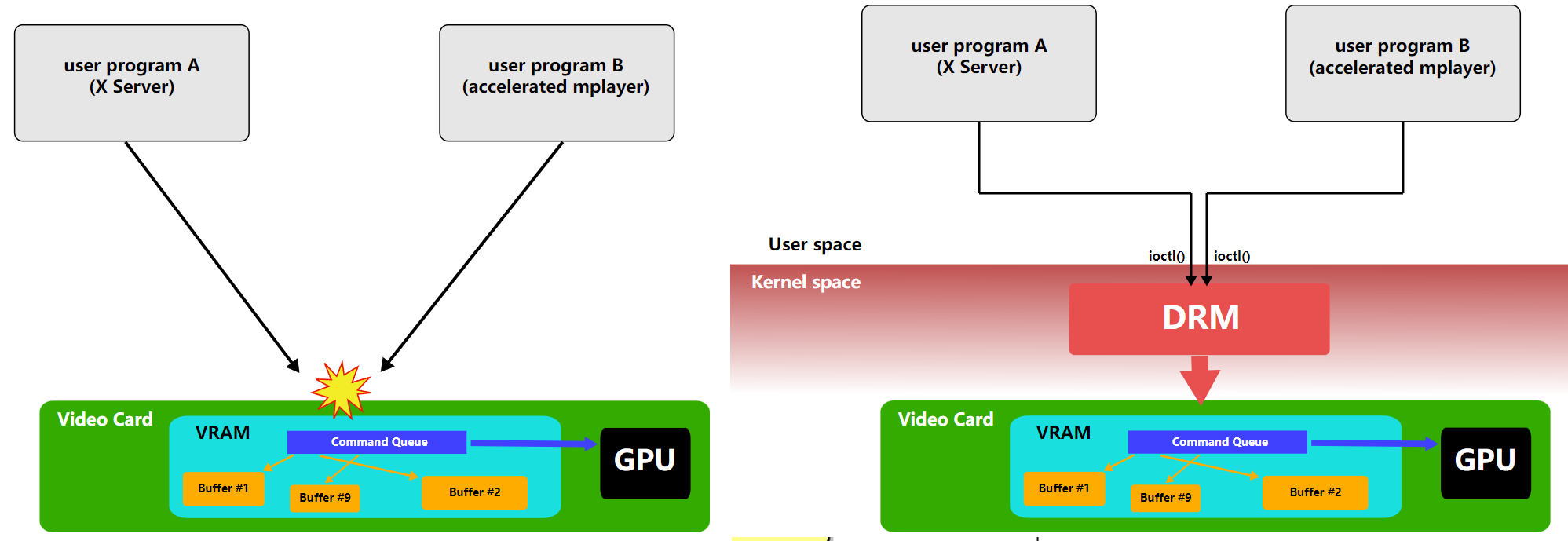
DRM允許多個程式同時存取3D視訊卡,避免衝突。
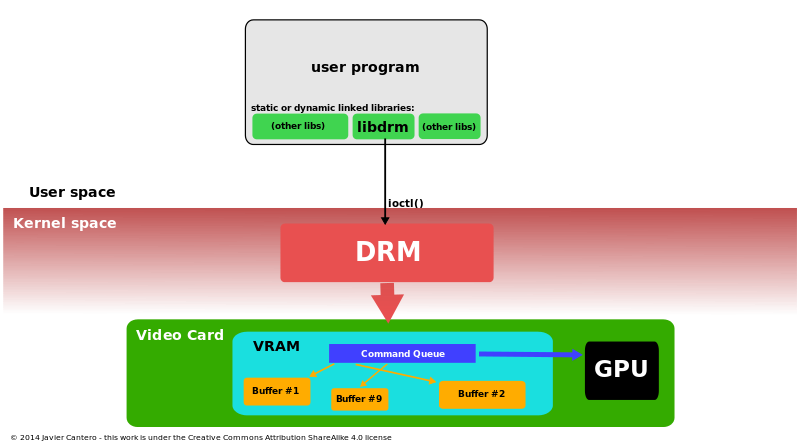
使用Linux核心的直接渲染管理器存取3D加速圖形卡的過程。
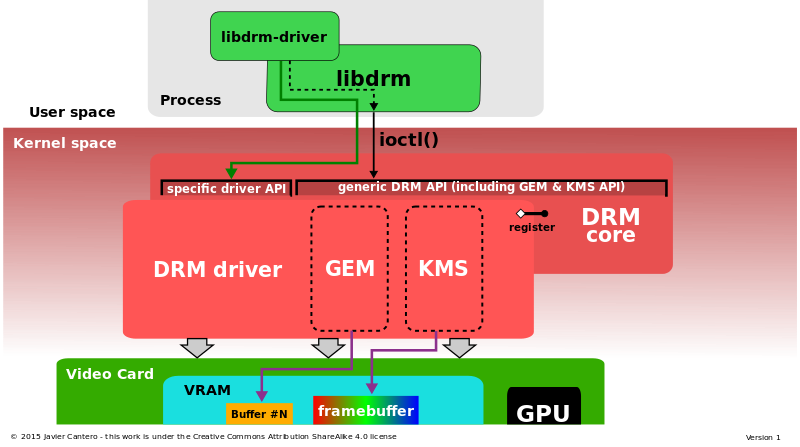
直接渲染管理器體系結構詳細資訊:DRM核心和DRM驅動程式(包括GEM和KMS),由libdrm介面。
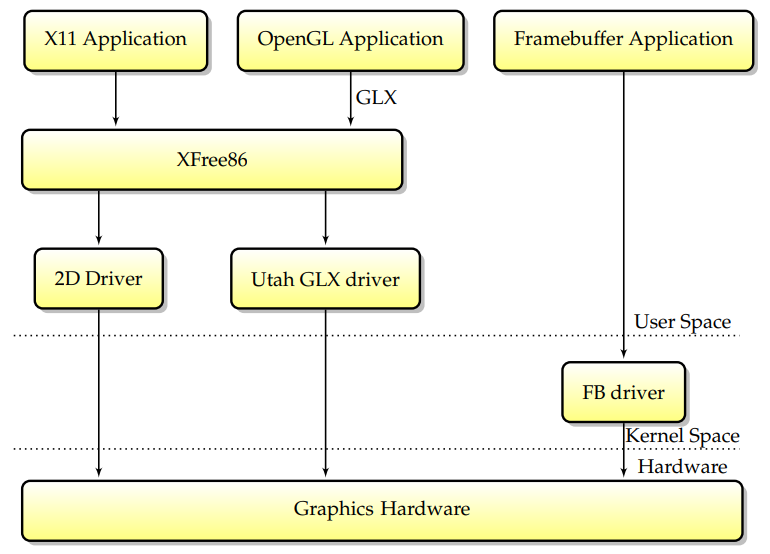
最初(當Linux首次支援圖形硬體加速時),只有一段程式碼可以直接存取圖形卡:XFree86伺服器。設計如下:通過以超級使用者許可權執行,XFree86伺服器可以從使用者空間存取卡,並且不需要核心支援來實現2D加速。這種設計的優點是簡單,而且XFree86伺服器可以很容易地從一個作業系統移植到另一個作業系統,因為它不需要核心元件。多年來,這是最廣泛的X伺服器設計(儘管也有明顯的例外,比如XSun,它在核心中為一些驅動程式實現了modesetting)。
後來,第一個獨立於硬體的3D加速設計Utah-GLX出現在Linux上,Utah-GLX基本上包含一個實現GLX的附加使用者空間3D驅動程式,並以類似於2D驅動程式的方式從使用者空間直接存取圖形硬體。在3D硬體與2D明顯分離的時代(因為2D和3D使用的功能完全不同,或者因為3D卡是一個完全獨立的卡,即3Dfx),擁有一個完全獨立的驅動程式是有意義的。此外,從使用者空間直接存取硬體是在Linux下實現3D加速的最簡單方法和最短途徑。
與此同時,幀緩衝區驅動程式越來越廣泛,它代表了可以同時直接存取圖形硬體的另一個元件。為了避免幀緩衝區和XFree86驅動程式之間的潛在衝突,決定在VT交換機上,核心將向X伺服器發出訊號,告訴其儲存圖形硬體狀態。要求每個驅動程式在VT交換機上儲存其完整的GPU狀態使驅動程式更加脆弱,對於突然面臨不同驅動程式之間容易出現錯誤的互動的開發人員來說,生活變得更加困難。請記住,XFree86驅動程式至少有兩種可能(xf86視訊vesa和本機XFree86驅動程式)和兩種核心幀緩衝區驅動程式(vesafb和本機幀緩衝區驅動程式),因此每個GPU至少有四種共存驅動程式的組合。
顯然,這種模式有缺點。首先,它要求允許未經授權的使用者空間應用程式存取3D圖形硬體。其次,如上圖所示,所有GL加速都必須通過X協定間接進行,將顯著降低其速度,尤其是對於紋理上傳等資料密集型功能。由於人們越來越擔心Linux的安全性和效能缺陷,需要另一種模型。
為了解決Utah-GLX模型的可靠性和安全性問題,將DRI模型放在一起;XFree86及其後續版本X.Org都使用了它。該模型依賴於一個額外的核心元件,其職責是從安全形度檢查3D命令流的正確性。現在的主要變化是,沒有許可權的OpenGL應用程式將向核心提交命令緩衝區,核心將檢查它們的安全性,然後將它們傳遞給硬體執行,而不是直接存取卡。這種模型的優點是不再需要信任使用者空間,但XFree86的2D命令流仍然沒有通過DRM,因此X伺服器仍然需要超級使用者許可權才能直接對映GPU暫存器。
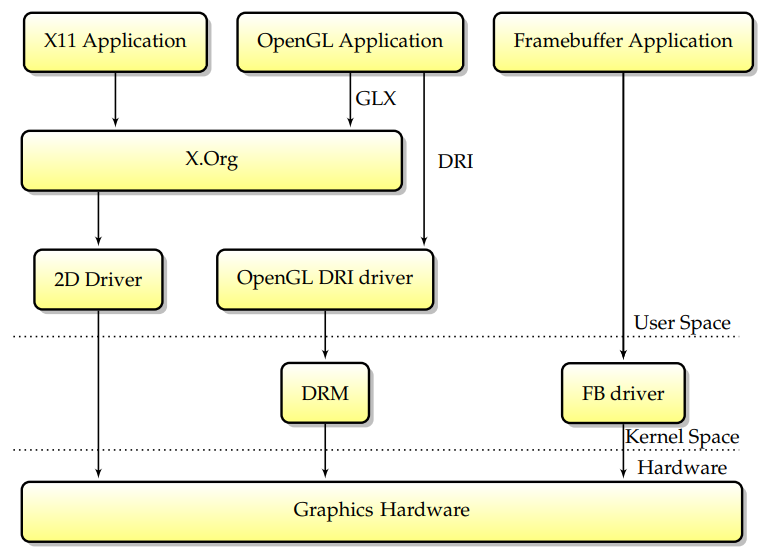
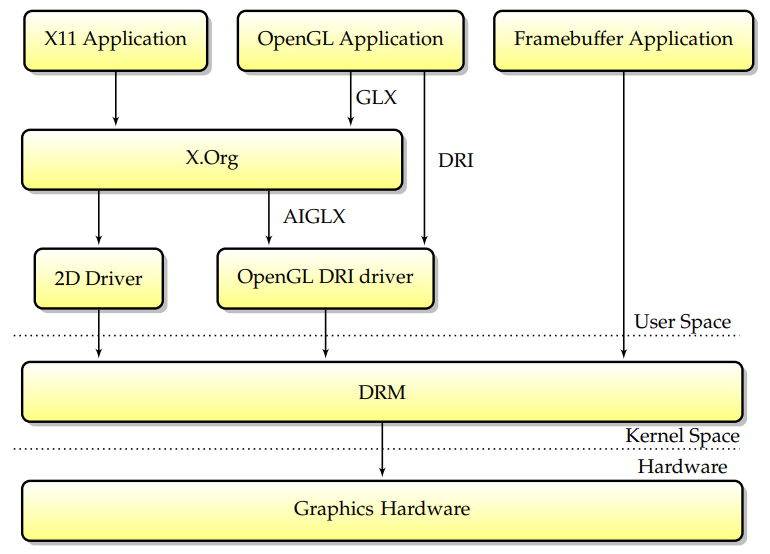
當前堆疊是從一組新的需求演變而來的。首先,要求X伺服器具有超級使用者許可權總是會帶來嚴重的安全隱患。其次,在以前的設計中,不同的驅動程式接觸單個硬體,通常會導致問題。為了解決這個問題,關鍵有兩個方面:第一,將核心幀緩衝區功能合併到DRM模組中,第二,讓X.Org通過DRM模組存取圖形卡並無許可權執行。這種模型被稱為核心模式設定(KMS),在這個模型中,DRM模組現在負責作為幀緩衝區驅動程式和X.Org提供模式設定服務。
總之,應用程式通過封裝繪圖呼叫的特定庫與X.Org通訊,當前的DRI設計隨著時間的推移在許多重要步驟中不斷髮展,在現代堆疊中,所有圖形硬體活動都由核心模組DRM控制。Linux總的模組互動圖如下:
更詳細的互動和分層架構如下:
16.3.2.3 Framebuffer驅動
在核心,幀緩衝區驅動程式實現以下功能:
- 模式設定。模式設定包括設定視訊模式以在螢幕上獲取圖片,包括選擇視訊解析度和重新整理率。
- 可選2d加速。幀緩衝區驅動程式可以提供用於加速linux控制檯的基本2D加速,包括視訊記憶體中的拷貝和實體填充。加速有時通過掛鉤提供給使用者空間(然後使用者空間必須對特定於卡的MMIO暫存器進行程式設計,需要root許可權)。
通過只實現這兩部分,幀緩衝區驅動程式仍然是最簡單、最合適的linux圖形驅動程式形式。幀緩衝區驅動程式並不總是依賴於特定的卡型號(如nvidia或ATI)。存在vesa、EFI或Openfirmware之上的驅動程式,這些驅動程式不是直接存取圖形硬體,而是呼叫韌體功能來實現模式設定和2D加速。
幀緩衝區驅動程式是linux圖形驅動程式的最簡單形式。只需很少的實現工作,幀緩衝區驅動程式提供了較低的記憶體佔用,因此對嵌入式裝置很有用。實現加速是可選的,因為存在軟體回退功能。
16.3.2.4 直接渲染管理器
在複雜的世界中,使用核心模組是一項要求。此核心模組稱為直接渲染管理器(DRM),可用於多種用途:
- 將圖形卡的關鍵初始化放在核心中,例如上載韌體或設定DMA區域。
- 在多個使用者空間元件之間共用渲染硬體,並處理存取。
- 通過防止應用程式對任意記憶體區域執行DMA,以及更一般地防止以任何可能導致安全漏洞的方式對卡進行程式設計來加強安全性。
- 通過向用戶空間提供視訊記憶體分配功能來管理卡的記憶體。
- DRM得到了改進,以實現模式設定,簡化了以前DRM和幀緩衝區驅動程式爭用同一GPU的情況。相反,將刪除幀緩衝區驅動程式,並在DRM中實現幀緩衝區支援。
核心模組(DRM)是全域性DRI/DRM使用者空間/核心方案(下圖包含libdrm-DRM-入口點-多個使用者空間應用程式):
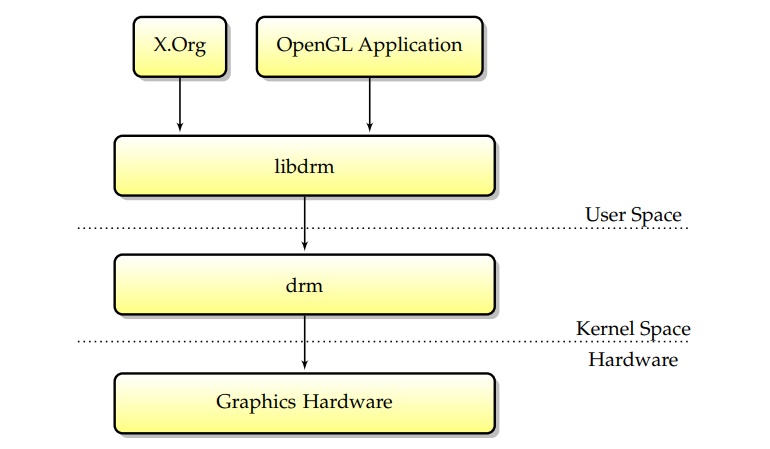
當設計一個Linux圖形驅動程式以實現不僅僅是簡單的幀緩衝區支援時,首先要做的是一個DRM元件,應該派生出一種既高效又能加強安全性的設計。DRI/DRM方案可以以不同的方式實現,並且介面確實完全是特定於卡的。
DRM批次緩衝區提交模型:DRM設計的核心是DRM_GEM_EXECBUFFER ioctl,允許使用者空間應用程式向核心提交一個批次處理緩衝區,然後核心將其放在GPU上。此ioctl允許許多事情,如共用硬體、管理記憶體和強制執行記憶體保護。
DRM的職責之一是在多個使用者空間程序之間複用GPU本身。如果GPU保持圖形狀態,那麼當多個應用程式使用同一GPU時,就會出現一個問題:如果什麼都不做,應用程式就會破壞彼此的狀態。根據當前的硬體,主要有兩種情況:
1、當GPU具有硬體狀態跟蹤功能時,硬體共用會更簡單,因為每個應用程式都可以傳送到單獨的上下文,GPU會跟蹤每個應用程式本身的狀態。此種方法就是新驅動的工作方式。
2、當GPU沒有多個硬體上下文時,複用硬體的常見方法是在每個批次處理緩衝區的請求時重新提交狀態,是intel和radeon驅動程式多路複用GPU的方式。請注意,重新提交狀態的職責完全依賴於使用者空間。如果使用者空間沒有在每個批次處理緩衝區開始時重新提交狀態,那麼來自其他DRM程序的狀態將洩漏到它身上。DRM還防止同時存取同一硬體。
核心能夠移動記憶體區域來處理記憶體壓力大的情況。根據硬體的不同,有兩種實現方法:
1、如果硬體具有完整的記憶體保護和虛擬化,則可以在分配記憶體資源時將其分頁到GPU中,並隔離每個程序。因此,支援GPU記憶體的記憶體保護不需要太多。
2、當硬體沒有記憶體保護時,仍然可以完全在核心中實現,使用者空間完全不受其影響。為了允許重新定位對使用者空間程序起作用,而使用者空間程序在其他方面並不知道它們,命令提交ioctl將通過將所有硬體偏移量替換到當前位置來重寫核心中的命令緩衝區。由於核心知道所有記憶體緩衝區的當前位置,使得前述方法成為可能。為了防止存取任意GPU記憶體,命令提交ioctl還可以檢查這些偏移量中的每一個是否為呼叫程序所有,如果不是,則拒絕批次處理緩衝區。這樣,當硬體不提供該功能時,就可以實現記憶體保護。
DRM管理現代linux圖形堆疊中的所有圖形活動,是堆疊中唯一受信任的部分,負責安全,因此,不應信任其他元件。它提供基本的圖形功能:模式設定、幀緩衝區驅動程式、記憶體管理。
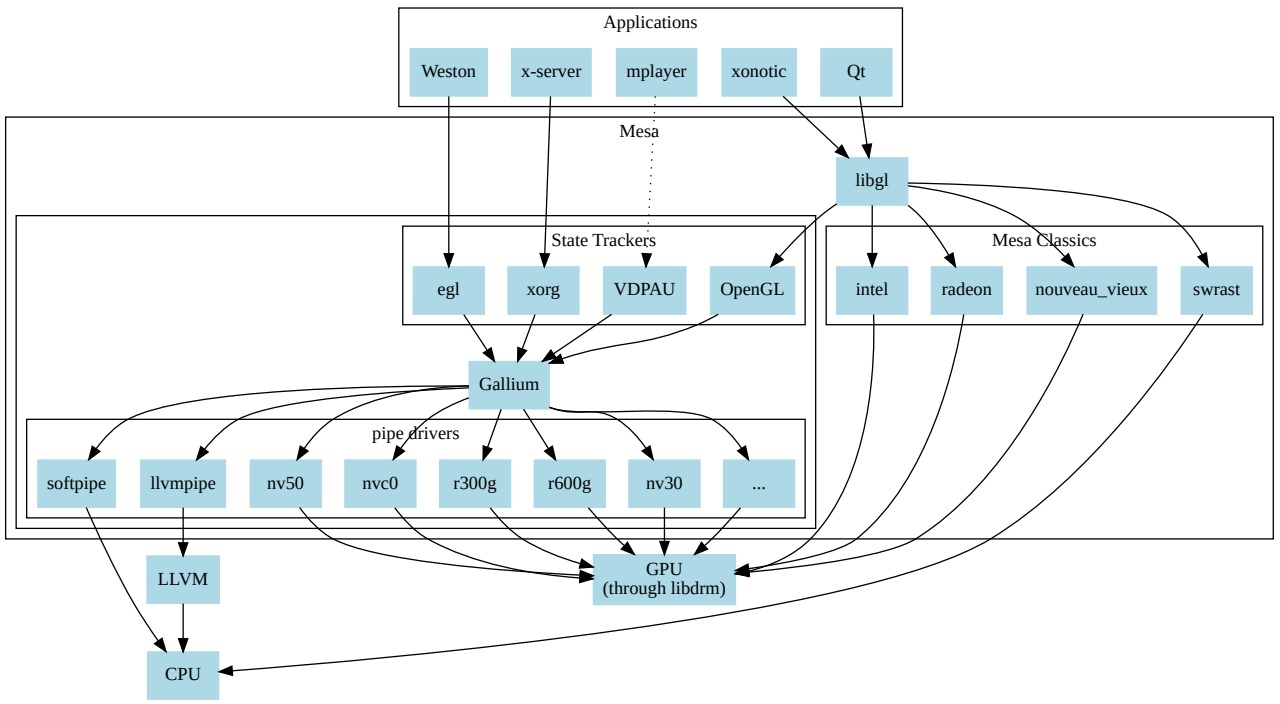
16.3.2.5 Mesa
Mesa也稱為Mesa3D和Mesa3D圖形庫,是OpenGL、Vulkan和其他圖形API規範的開源軟體實現。Mesa將這些規範轉換為特定於供應商的圖形硬體驅動程式。其最重要的使用者是兩個圖形驅動程式,它們主要由Intel和AMD為各自的硬體開發和資助(AMD在不推薦的AMD Catalyst上推廣其Mesa驅動程式Radeon和RadeonSI,Intel只支援Mesa驅動程式)。專有圖形驅動程式(如Nvidia GeForce驅動程式和Catalyst)取代了所有Mesa,提供了自己的圖形API實現,開發名為Nouveau的Mesa Nvidia驅動程式的開源工作主要由社群開發。
除了遊戲等3D應用程式外,現代顯示服務(X.org的Glamer或Wayland的Weston)也使用OpenGL/EGL;因此,所有圖形通常都要使用Mesa。Mesa由freedesktop託管,該專案於1993年8月由布萊恩·保羅發起。Mesa隨後被廣泛採用,現在包含了世界各地各種個人和公司的眾多貢獻,包括管理OpenGL規範的Khronos集團圖形硬體制造商的貢獻。
Mesa有兩個主要用途:
1、Mesa是OpenGL的軟體實現,被認為是參考實現,在檢查一致性時很有用,因為官方的OpenGL一致性測試並不公開。
2、Mesa為linux下的開源圖形驅動程式提供了OpenGL入口點。
Mesa是Linux下的參考OpenGL實現,所有開源圖形驅動程式都使用Mesa for 3D。

電動遊戲通過OpenGL將渲染計算實時外包給GPU,著色器使用OpenGL著色語言或SPIR-V編寫,並在CPU上編譯,編譯後的程式在GPU上執行。(下圖)
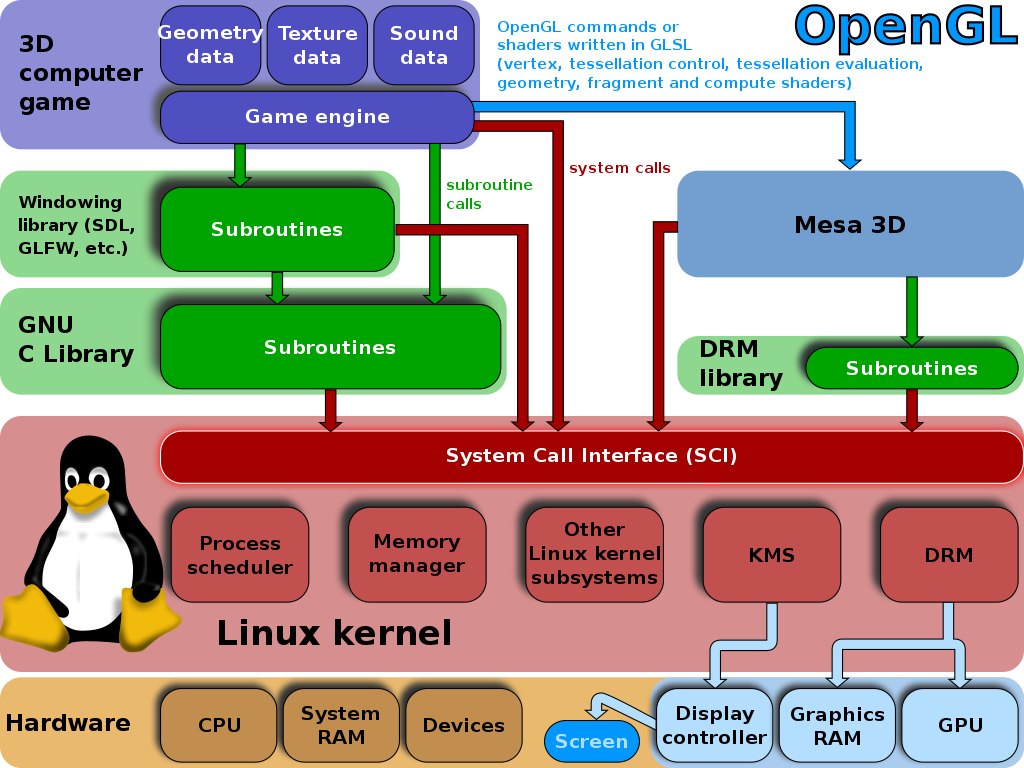
Linux圖形堆疊見下圖:DRM&libDRM,Mesa 3D,其中顯示服務屬於視窗系統,只用於遊戲等上層應用。
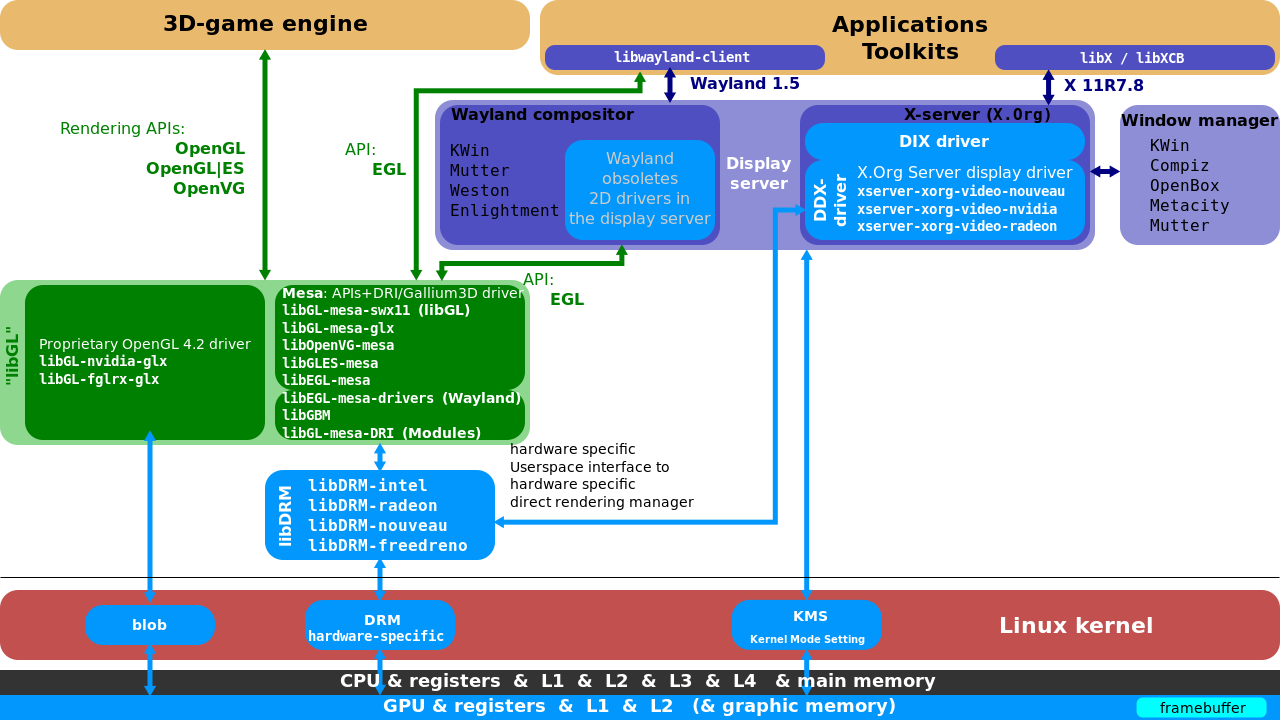
Wayland的免費實現依賴於EGL的Mesa實現,名為libwayland EGL的特殊庫是為支援對幀緩衝區的存取而編寫的,EGL 1.5版本已過時。在GDC 2014上,AMD正在探索使用DRM而不是其核心內blob的戰略變化。
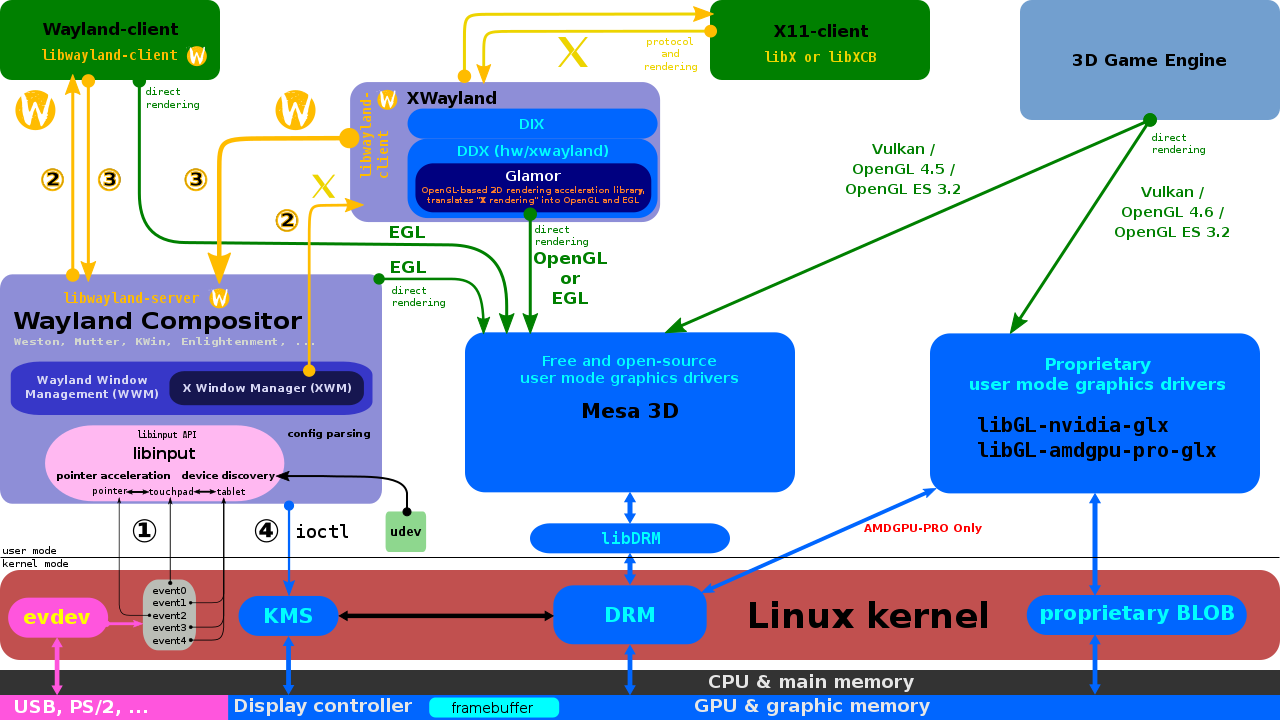
16.3.2.6 Wayland
Wayland旨在更簡單地替代X,更易於開發和維護。Wayland是一種用於合成器與其客戶機對話的協定,也是該協定的C庫實現。合成器可以是在Linux核心模式設定和evdev輸入裝置上執行的獨立顯示伺服器、X應用程式或wayland使用者端本身。使用者端可以是傳統應用程式、X伺服器(無根或全螢幕)或其他顯示伺服器。Wayland專案的一部分也是Wayland合成器的Weston參考實現,Weston可以作為X使用者端或Linux KMS執行,Weston合成器是一種最小且快速的合成器,適用於許多嵌入式和移動用例。
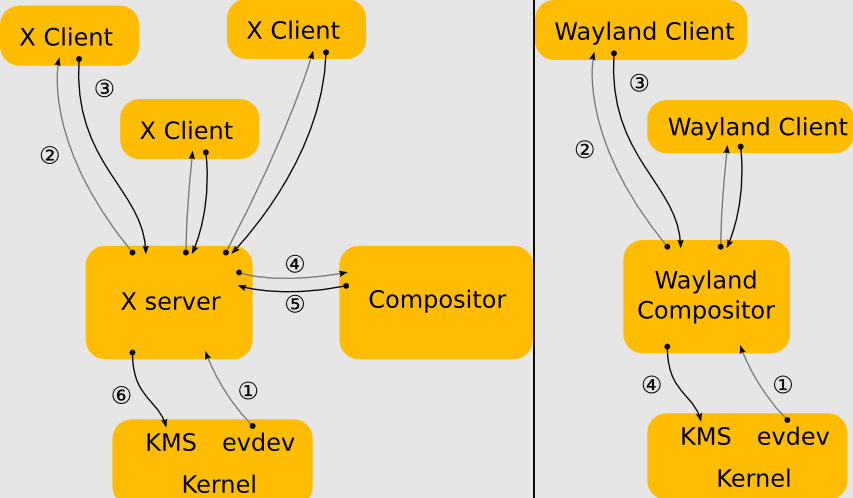
使用X(左)和Wayland(右)的驅動架構對比。
16.3.3 排程機制
16.3.3.1 OS And GPU abstraction
早在10年前,微軟聯合大學的科研人員在Operating Systems must support GPU abstractions中指出,缺乏對GPU抽象的作業系統支援從根本上限制了GPU在許多應用領域的可用性。作業系統為最常見的資源(如CPU、輸入裝置和檔案系統)提供抽象。相比之下,作業系統目前將GPU隱藏在笨拙的ioctl 介面後面,將抽象的負擔轉移到使用者庫和執行時上。因此,作業系統無法為GPU提供系統範圍的保證,例如公平性和隔離性,開發人員在構建整合GPU和其他作業系統管理資源的系統時,必須犧牲模組化和效能。他們提出了新的核心抽象,以支援GPU和其他加速器裝置作為一流的計算資源。
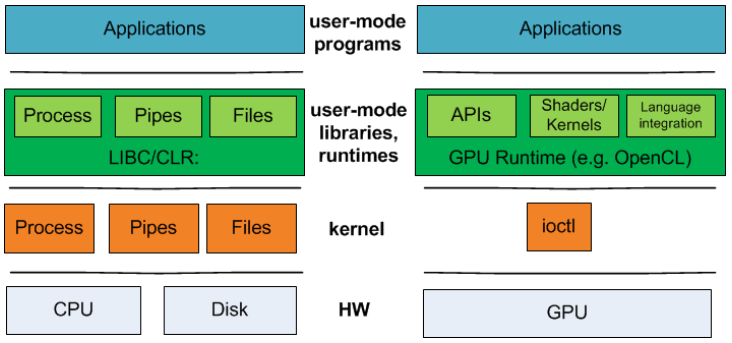
CPU與GPU程式的技術堆疊。對於GPU程式,CPU程式的作業系統級別和使用者模式執行時抽象之間沒有1對1的對應關係。
不存在對GPU抽象的直接作業系統支援,因此利用GPU完成此工作負載必然需要一個使用者級GPU程式設計框架和執行時,如CUDA或OpenCL。在這些框架中實現xform和detect會大大提高隔離執行的元件的速度,但組合系統(catusb | xform | detect | hidinput)會因跨使用者核心邊界和跨PCI-e匯流排的硬體的過度資料移動而受損。
現代作業系統目前無法保證GPU的公平性和效能隔離,主要是因為GPU不是作為共用計算資源(如CPU)管理的,而是作為I/O裝置管理的,其介面僅限於一小部分已知操作(如init_module、read、write、ioctl)。當作業系統需要使用GPU來實現其功能時,這種設計就成為了一個嚴重的限制。實際上,NVIDIA GPU Direct[1]實現了這樣一個功能,但需要在所涉及的任何I/O裝置的驅動程式中提供專門的支援。自己計算(例如,Windows 7與Aero使用者介面一樣)。在當前的制度下,時間分割和超時可以確保螢幕重新整理率保持不變,但在執行公平性和系統負載平衡時,作業系統在很大程度上取決於GPU驅動程式。
新的體系結構可能會改變跨GPU和CPU記憶體域管理資料的相對難度,但軟體將繼續發揮重要作用,在可預見的未來,優化資料移動仍然很重要。AMD的Fusion將CPU和GPU整合到一個晶片上,然而,它將CPU和GPU記憶體分割區。Intel的Sandy Bridge(另一種CPU/GPU組合)表明,未來幾年將出現各種形式的整合CPU/GPU硬體上市。新的混合系統,例如NVIDIA Optimus,在晶片和高效能離散圖形卡上都具有能效,即使使用組合的CPU/GPU晶片,資料管理也更加明確。但即使是一個完全整合的虛擬記憶體系統,也需要系統支援來最小化資料拷貝。

原型系統中基於CUDA的xform程式實現的相對GPU執行時間和開銷(越低越好)。sync使用CPU和GPU之間的緩衝區同步通訊,async使用非同步通訊,async pp同時使用非同步和乒乓緩衝區來進一步隱藏延遲。條形圖分為在GPU上執行的時間和系統開銷。DtoH表示裝置和主機之間在每個幀上進行通訊的實現,反之亦然,並且兩者都表示每個幀的雙向通訊。報告的執行時間與同步、雙向情況(同步兩者)相關。
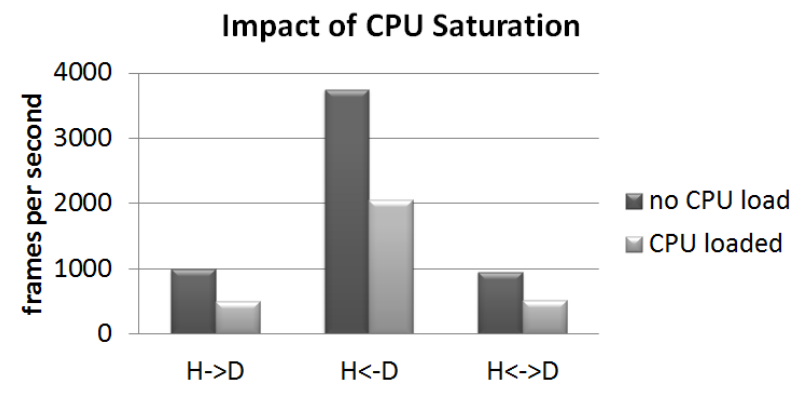
CPU密集工作對GPU密集任務的影響。當系統中存在並行GPU和CPU工作時,當前的作業系統抽象限制了作業系統提供效能隔離的能力。H→D是一個CUDA工作負載,它具有從主機到GPU裝置的通訊,而H←D具有從GPU到主機的通訊,H↔D具有雙向通訊。
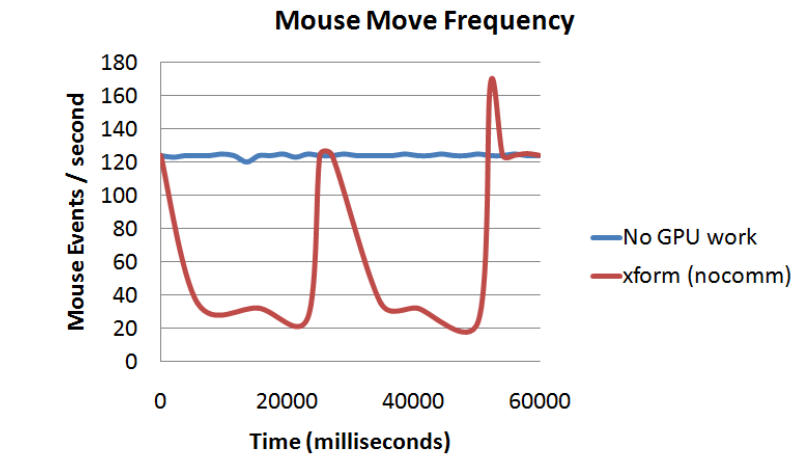 g)
g)
GPU密集工作對CPU密集任務的影響。這些圖顯示了作業系統能夠在程式大量使用GPU的60秒內傳遞滑鼠移動事件的頻率(以Hz為單位)。在此期間的平均CPU利用率低於25%。
他們提出了以下新的作業系統抽象,可以使GPU適用於更廣泛的應用程式域。這些抽象允許將計算表示為有向圖,從而實現高效的資料移動和高效、公平的排程。
-
PTask。PTask類似於傳統的OS程序抽象,但PTask基本上在GPU上執行。PTask需要來自OS的一些編排來協調其執行,但不需要使用者模式主機程序。PTask有一個可以繫結到埠的輸入和輸出資源列表(類似於POSIX stdin、stdout、stderr檔案描述符)。
-
Port。Port是核心名稱空間中的一個物件,可以繫結到PTask輸入和輸出資源。一個Port是一個資料來源或接收器,提供了一種方法來公開GPU程式碼中的資料和引數,這些資料和引數必須動態繫結,並且可以由GPU或CPU記憶體中的緩衝區填充。
-
Channel。Channel類似於POSIX管道:它將埠連線到其他埠,或連線到系統中的其他資料來源和接收器,如I/O匯流排、檔案等。Channel具有子型別GraphInputChannel、GraphOutChannel和GraphInternalChannel。
-
Graph。Graph是PTask節點的集合,其輸入和輸出埠通過通道連線。可以獨立建立和執行多個圖,PTask執行時負責公平地排程它們。
在作業系統介面上支援這些新的抽象需要新的系統呼叫來建立和管理ptask、埠和通道,額外的系統呼叫類似於POSIX中的程序API、程序間通訊API和排程器提示API。
與GPU協調作業系統排程的兩個主要好處是:
- 效率性。是指ptask準備就緒和在GPU上排程之間的低延遲,以及在GPU上排程足夠的ptask工作以充分利用其計算頻寬。
- 公平性。是指作業系統排程器在GPU利用率和使用者介面響應性之間取得平衡。此外,與GPU競爭的PTAK都能獲得其計算頻寬的合理份額。並非所有PTASK都有所有這些排程要求,如典型的CUDA程式不關心低延遲排程。
總之,他們主張對核心抽象進行根本性的重組,以管理互動式、大規模並行裝置。核心必須根據需要只公開足夠的硬體細節,以使程式設計師能夠實現良好的效能和低延遲,同時提供根據機器拓撲進行封裝和專門化的通訊抽象。GPU是一種通用的共用計算資源,必須由作業系統進行管理,以提供公平性和隔離性。
16.3.3.2 Halide Pipeline
Schedule Synthesis for Halide Pipelines on GPUs揭示了Halide DSL和編譯器通過分離演演算法描述和優化排程,實現了針對異構體系結構的影象處理管道的高效能程式碼生成。然而,自動排程生成目前僅適用於多核CPU體系結構。因此,在為具有GPU功能的平臺進行優化時,仍然需要專家級知識。他們使用新的優化過程擴充套件了當前的Halide自動排程程式,以高效地生成基於CUDA的GPU體系結構的排程。實驗結果表明,該排程平均比手動排程快10%,比以前的自動排程快2倍以上。
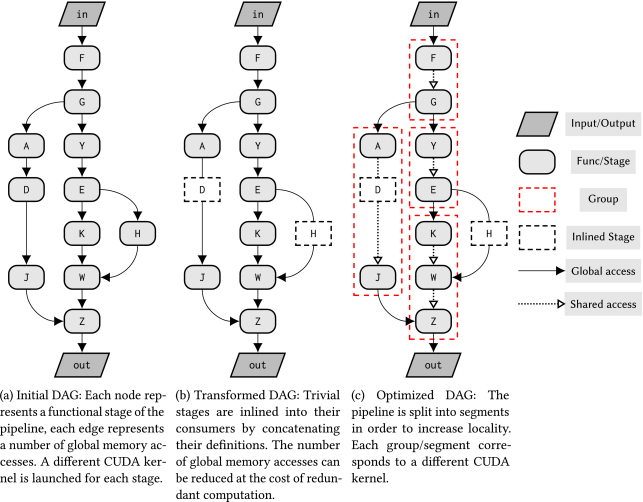
通用管道範例:在將管道拆分為分配了優化計劃的較小階段組之前,將普通階段內聯到其使用者中。

簡單的實現會在不同的CUDA核心中完全計算每個階段,並將所有資料儲存到全域性記憶體中。

重疊分塊時間表計算一次分塊內迭代(或執行緒塊)所需的所有畫素,並將其儲存在共用記憶體中。
本節介紹在Halide master自動排程程式中實現的新優化過程,以生成針對基於CUDA的GPU架構的優化排程。其遵循一個類似於當前優化流程的過程,其中瑣碎(逐點消耗)階段首先被內聯到其消費者中,然後使用Halide master中實現的貪婪演演算法進行分組。下圖顯示了autoscheduler使用的優化流的概述。
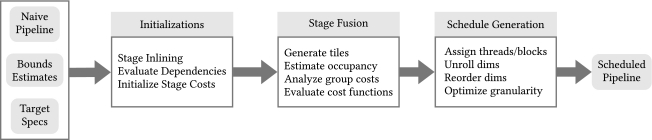
基本排程流程:排程器需要回圈邊界估計以及使用者給定的目標規範描述,以生成給定管道的優化排程。編譯流中的大多數步驟都已擴充套件,以支援自動GPU排程。
16.3.3.3 Hardware Accelerated GPU Scheduling
Hardware Accelerated GPU Scheduling闡述了WDDM在2020年5月引入的一種基於硬體加速的GPU排程機制。
自從Windows顯示驅動程式Model 1.0(WDDM)的推出以及GPU排程在Windows中的引入,已經過去了將近14年。很少有人會記得WDDM之前的日子,在那裡,應用程式只需向GPU提交他們想要的工作即可。他們提交到一個全域性佇列,在那裡它以嚴格的「先提交,先執行」方式執行。在大多數GPU應用程式都是全螢幕遊戲的時候,這些最基本的排程方案是可行的,一次執行一個。
隨著向使用GPU實現更豐富圖形和動畫的廣泛應用程式的過渡,該平臺需要更好地確定GPU工作的優先順序,以確保響應的使用者體驗。因此,WDDM GPU排程程式誕生了。
隨著時間的推移,Windows顯著增強了WDDM核心的GPU排程程式,支援每個新WDDM版本的其他功能和場景。然而,在整個發展過程中,排程器的一個方面沒有改變。他們一直在CPU上執行一個高優先順序執行緒,該執行緒負責協調、優先排序和安排各種應用程式提交的工作。
這種排程GPU的方法在提交開銷以及工作到達GPU的延遲方面有一些基本的限制,這些開銷大部分被傳統的應用程式編寫方式所掩蓋。例如,應用程式通常會在第N幀上執行GPU工作,並讓CPU提前執行,為第N+1幀準備GPU命令。這種GPU命令的批次緩衝允許應用程式每幀只提交幾次,從而最大限度地降低排程成本,並確保良好的CPU-GPU執行並行性。
CPU和GPU之間緩衝的一個固有副作用是,使用者體驗到的延遲會增加。CPU在「第N+1幀」期間拾取使用者輸入,但GPU直到下一幀才渲染使用者輸入,延遲減少和提交/排程開銷之間存在根本的緊張關係。應用程式可以更頻繁地提交,以小批次方式提交以減少延遲,或者可以提交更大批次的工作以減少提交和排程開銷。
隨著Windows 2020年5月10日的更新,其引入一個新的GPU排程程式作為使用者選擇加入,但預設關閉選項。有了正確的硬體和驅動程式,Windows現在可以將大部分GPU排程解除安裝到基於GPU的專用排程處理器上。Windows系統可以通過Windows設定 -> 系統 -> 顯示 -> 圖形設定存取設定頁面,以便開啟或關閉硬體加速的GPU排程。

Windows繼續控制優先順序,並決定哪些應用程式在上下文中具有優先順序。他們將高頻任務解除安裝到GPU排程處理器,處理各種GPU引擎的量子管理和上下文切換。
新的GPU排程程式是對驅動程式模型的重大和根本性更改,更改排程程式類似於在仍居住在房屋中的情況下重建房屋的基礎。
雖然新的排程器減少了GPU排程的開銷,但大多數應用程式都被設計為通過緩衝來隱藏排程成本。硬體加速GPU排程第一階段的目標是使圖形子系統的一個基本支柱現代化,併為將來的事情做好準備。
就目前而言,有評測文章發現,開啟此項功能對部分3A遊戲並無實際的影格率提升。
16.3.3.4 TimeGraph
GPU現在常用於圖形和資料平行計算。隨著越來越多的應用程式趨向於在多工環境中的GPU上加速,其中多個任務同時存取GPU,作業系統必須在GPU資源管理中提供優先順序和隔離功能,特別是在實時設定中。當前主流的GPU是命令驅動的:
多工的常見問題是CPU常常會導致GPU阻塞:
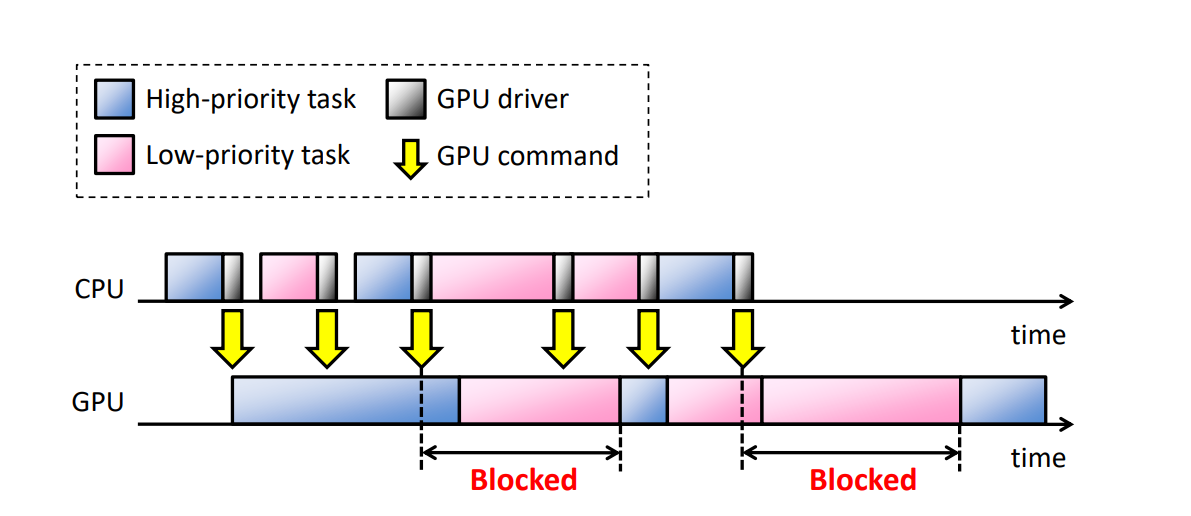
TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments介紹了TimeGraph——一種裝置驅動程式級別的實時GPU排程器,用於保護重要的GPU工作負載免受效能干擾。
TimeGraph採用了一種新的事件驅動模型,該模型將GPU與CPU同步,以監控從使用者空間發出的GPU命令,並以響應方式控制GPU資源的使用。TimeGraph支援兩種基於優先順序的排程策略,以解決GPU處理的非同步性和非搶佔性帶來的響應時間和吞吐量之間的權衡問題。資源保留機制還用於說明和強制執行GPU資源使用,從而防止行為不端的任務耗盡GPU資源。進一步提供GPU命令執行成本的預測,以增強隔離。
他們使用OpenGL圖形基準進行的實驗表明,即使面對極端的GPU工作負載,TimeGraph也能將主要GPU任務的幀速率保持在所需的水平,而如果沒有TimeGraph支援,這些任務幾乎沒有響應。此外還發現,施加在時間圖上的效能開銷可以限制在4-10%,其事件驅動排程器的吞吐量比現有的tick驅動排程器提高了約30倍。
該文假設系統由通用多核CPU和板載GPU組成,不操縱任何GPU內部單元,因此GPU命令在提交到GPU後不會被搶佔。TimeGraph獨立於庫、編譯器和執行時引擎,因此,時間圖的原理適用於不同的GPU架構(如NVIDIA Fermi/Tesla和ATI Stream)和程式設計框架(如OpenGL、OpenCL、CUDA和HMPP)。目前,TimeGraph是為Gallium3D OpenGL軟體棧中的Nouveau設計和實現的,該軟體棧也計劃支援OpenCL。此外,TimeGraph已移植到打包在PathScale ENZO套件中的PSCNV開源驅動程式,該套件支援CUDA和HMPP。然而,鑑於目前可用的一組開源解決方案:Nouveau和Gallium3D,該文主要關注OpenGL工作負載。
TimeGraph是裝置驅動程式的一部分,它是使用者空間程式向GPU提交GPU命令的介面。假設裝置驅動程式是基於大多數UNIXlike作業系統中採用的直接渲染基礎設施(DRI)模型設計的,作為X Window系統的一部分。在DRI模式下,使用者空間程式可以直接存取GPU來渲染幀,而無需使用視窗協定,同時仍可以使用視窗伺服器將渲染幀blit到螢幕上。GPGPU框架不需要這樣的視窗過程,因此它們的模型更加簡化。
為了向GPU提交GPU命令,必須為使用者空間程式分配GPU通道,這些通道在概念上表示GPU上的單獨地址空間。例如,NVIDIA Fermi和Tesla架構支援128個通道,每個通道的GPU命令提交模型如下圖所示。
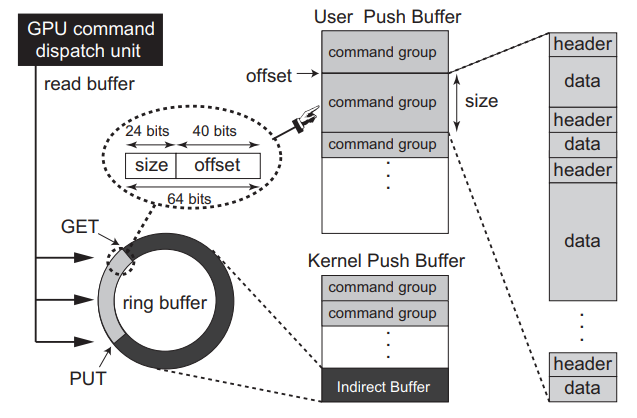
GPU命令提交模型。
每個通道使用兩種型別的核心空間緩衝區:使用者推播緩衝區和核心推播緩衝區。使用者推播緩衝區對映到相應任務的地址空間,其中GPU命令從使用者空間推播。GPU命令通常分組為非搶佔區域,以匹配使用者空間原子性假設。同時,核心推播緩衝區用於核心原語,如主機裝置同步、GPU初始化和GPU模式設定。
當用戶空間程式將GPU命令推播到使用者推播緩衝區時,它們還將封包寫入核心推播緩衝區的特定環形緩衝區部分,稱為間接緩衝區,每個封包都是一個(大小和地址)元組,用於定位某個GPU命令組。驅動程式將GPU上的命令排程單元設定為讀取用於命令提交的緩衝區,這個環形緩衝區由GET和PUT指標控制,指標從同一個地方開始。每次封包寫入緩衝區時,驅動程式都會將PUT指標移動到封包的尾部,並向GPU命令排程單元傳送訊號,以下載位於GET和PUT指標之間的封包所在的GPU命令組。然後,GET指標會自動更新到與PUT指標相同的位置。一旦這些GPU命令組提交到GPU,驅動程式將不再管理它們,並繼續提交下一組GPU命令組(如果有)。因此,這個間接緩衝區扮演著命令佇列的角色。
每個GPU命令組可以包括多個GPU命令,每個GPU命令都由檔頭(header)和資料組成,檔頭包含方法和資料大小,而資料包含傳遞給方法的值。方法表示GPU指令,其中一些指令在計算和圖形之間共用,另一些則針對每種指令。我們假設,一旦GPU命令組解除安裝到GPU上,裝置驅動程式不會搶佔它們。在同一GPU通道中,GPU命令執行順序錯誤。GPU通道由GPU引擎自動切換。
上述驅動程式模型基於直接渲染管理器(DRM),尤其針對NVIDIA Fermi和Tesla架構,但也可以用於其他架構,只需稍加修改。
TimeGraph的體系結構及其與軟體堆疊其餘部分的互動如下圖所示。使用者空間程式無需修改,GPU命令組可以通過現有軟體框架生成。然而,TimeGraph需要與裝置驅動程式空間中名為PushBuf的特定介面進行通訊,PushBuf介面允許使用者空間提交儲存在使用者推播緩衝區中的GPU命令組。TimeGraph使用此PushBuf介面將GPU命令組排隊,它還使用為GPU到CPU中斷準備的IRQ處理程式來排程下一個可用的GPU命令組。
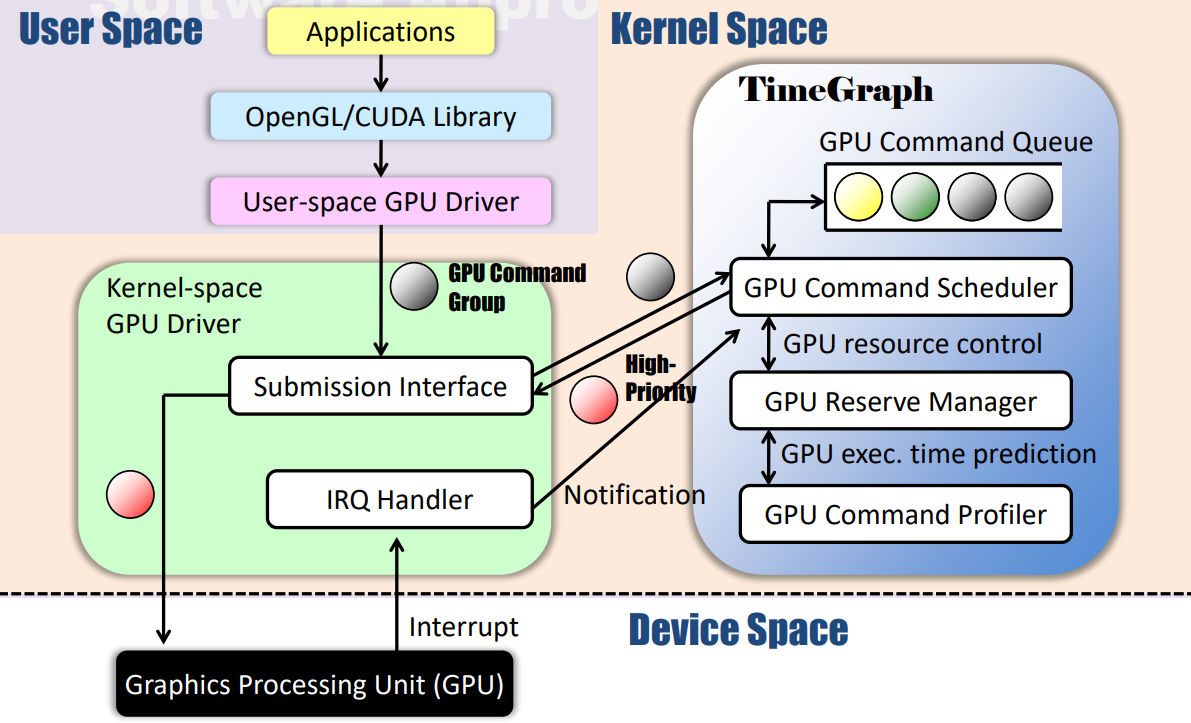
時間圖由GPU命令排程器、GPU保留管理器和GPU命令探查器組成。GPU命令排程器根據任務優先順序對GPU命令組進行排隊和排程,它還與GPU保留管理器協調,以計算和強制執行任務的GPU執行時間。GPU命令探查器支援預測GPU命令執行成本,以避免超出保留範圍。支援兩種排程策略來解決響應時間和吞吐量之間的權衡問題:
-
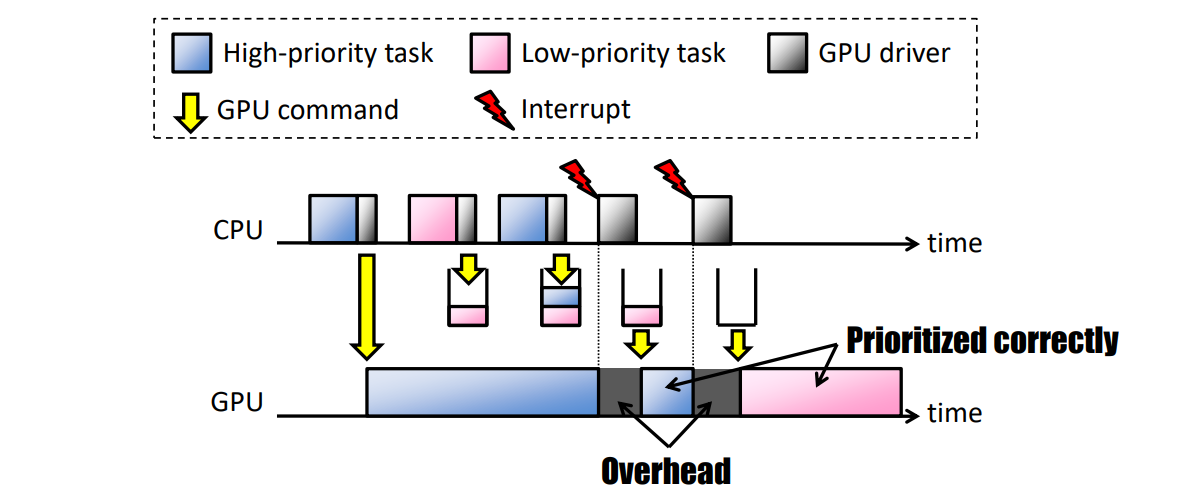
可預測響應時間(PRT):此策略最大限度地減少GPU上的優先順序反轉,以根據優先順序提供可預測的響應時間。當GPU不空閒時,GPU命令排隊;當GPU空閒時,GPU命令被排程:
-
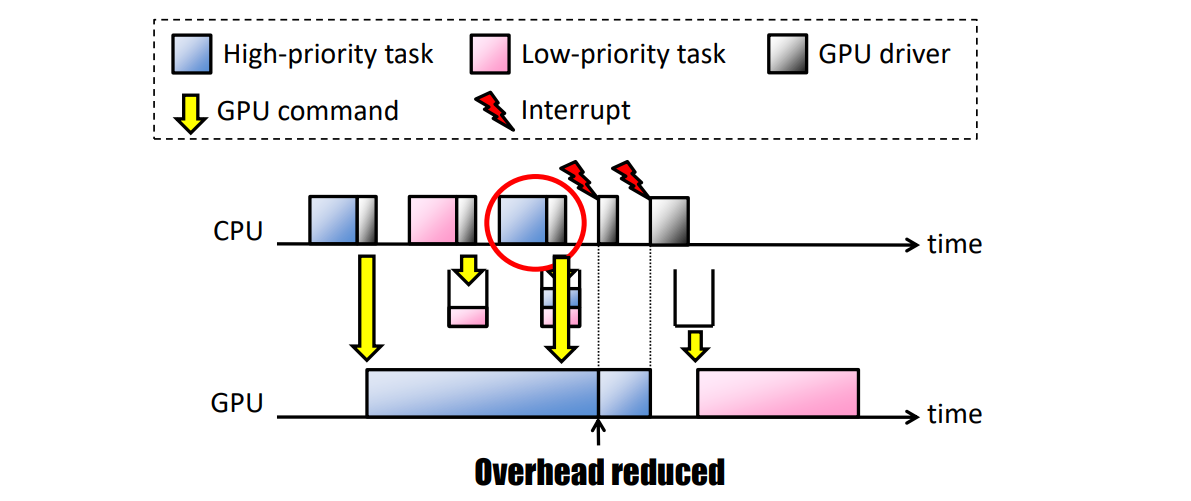
高吞吐量(HT):此策略增加總吞吐量,允許額外的優先順序反轉。當GPU不空閒時,只有當優先順序低於當前GPU上下文時,GPU命令才會排隊;當GPU空閒時,會排程GPU命令:
 ng)
ng)
它還支援兩種GPU保留策略,以解決隔離和吞吐量之間的權衡問題:
-
後驗強制(PE):此策略在GPU命令組完成後強制GPU資源使用,而不犧牲吞吐量。優化GPU資源使用,指定每個任務的容量(C)和週期(P)(/proc/GPU/$任務):
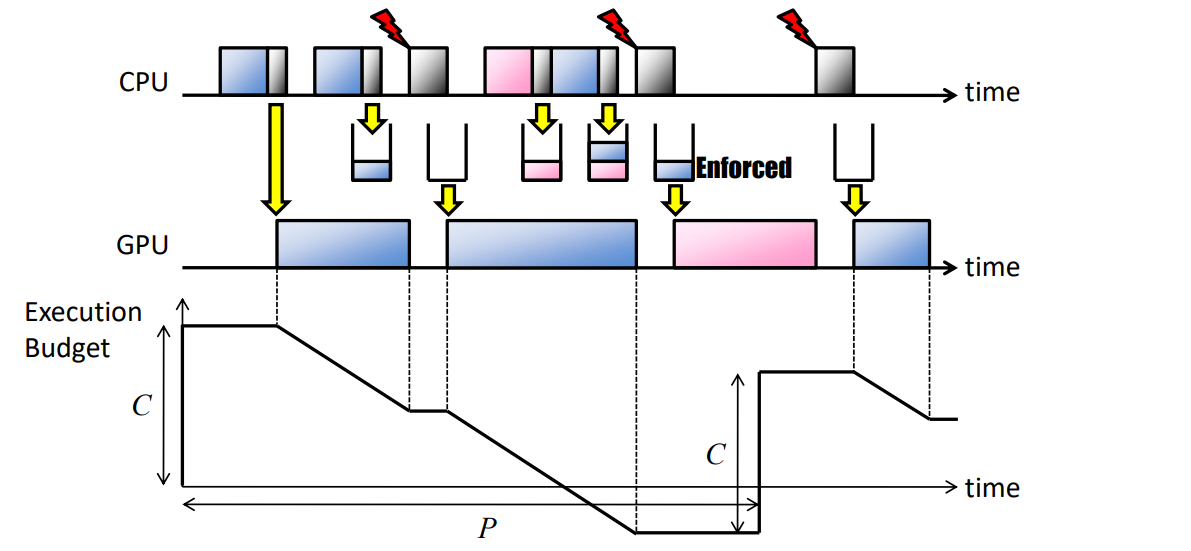
-
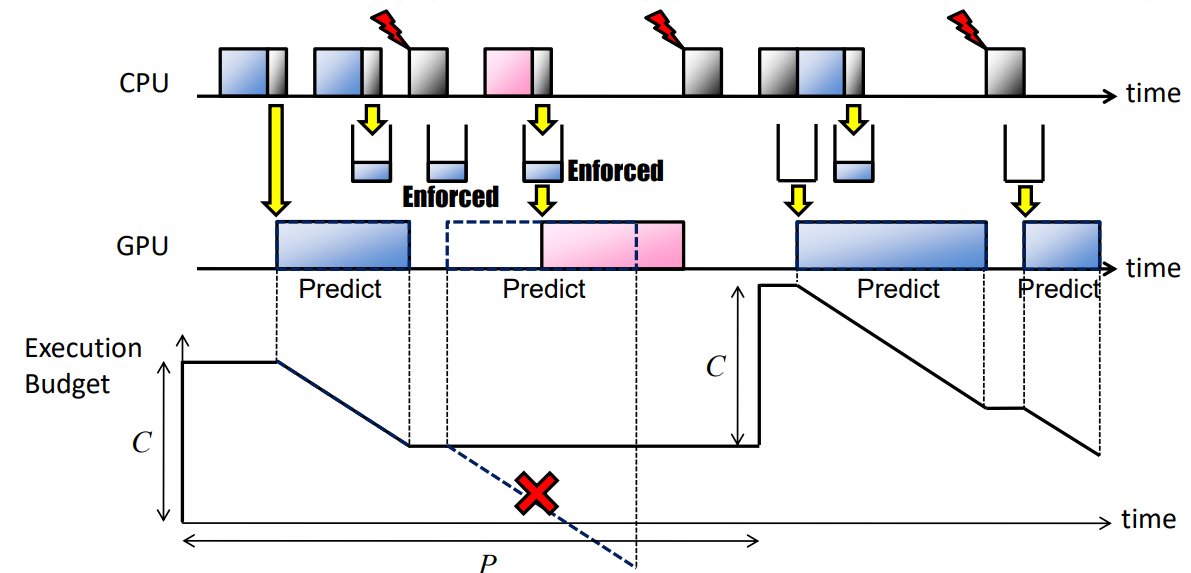
先驗強制(AE):此策略在提交GPU命令組之前,使用GPU執行成本預測強制GPU資源使用,但會增加額外的開銷。指定每個任務的容量(C)和週期(P)(/proc/GPU/$任務):
為了將多個任務統一到一個保留中,TimeGraph保留機制提供了共用保留模式。特別是,TimeGraph在載入時使用PE策略建立一個特殊的共用保留範例,稱為Background,它為不屬於任何特定保留的所有GPUAccessed任務提供服務。下圖顯示了PushBuf介面和IRQ處理程式的高階圖,其中TimeGraph引入的修改以粗體框架突出顯示。此圖基於Nouveau實現,但大多數GPU驅動程式應該具有類似的控制流。
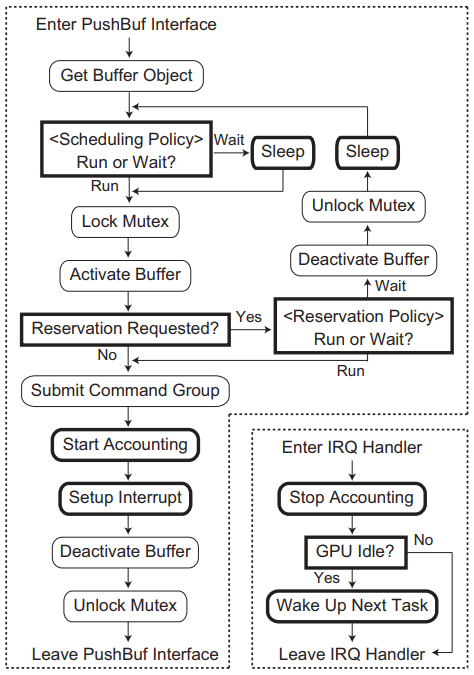
PushBuf介面和IRQ處理程式與時間圖方案的關係圖。
GPU命令排程器的目標是根據任務優先順序對非搶佔式GPU命令組進行排隊和排程。為此,TimeGraph包含一個暫停任務的等待佇列,它還管理GPU聯機列表,即指向當前在GPU上執行的GPU命令組的指標列表。
當GPU命令組進入PushBuf介面時,GPU聯機列表用於檢查當前是否有正在執行的GPU命令組。如果列表為空,則將相應的任務插入其中,並將GPU命令組提交給GPU。否則,任務將插入到要排程的等待佇列中。
GPU聯機列表的管理需要有關GPU命令組何時完成的資訊。TimeGraph採用事件驅動模型,該模型使用GPU到CPU中斷來通知每個GPU命令組的完成,而不是以前工作中採用的tick驅動模型。每次中斷時,相應的GPU命令組將從GPU聯機列表中刪除。
TimeGraph支援兩種GPU排程策略。可預測響應時間(PRT)策略鼓勵此類任務在不影響重要任務的情況下及時執行。此策略在某種意義上是可預測的,GPU命令組是基於任務優先順序進行排程的,以使高優先順序任務在GPU上響應。另一方面,高吞吐量(HT)策略適用於應該儘可能快地執行的任務。有一個權衡,即PRT策略以犧牲吞吐量為代價防止任務受到干擾,而HT策略實現了一個任務的高吞吐量,但可能會阻止其他任務。例如,桌面小部件、瀏覽器外掛和視訊播放器任務需要使用PRT策略,而三維遊戲和互動式三維介面任務可以使用HT策略。
PRT策略強制任何GPU命令組等待前面的GPU命令組(如果有)完成。具體而言,如果GPU聯機列表為空,則到達裝置驅動程式的新GPU命令組可以立即提交給GPU。否則,相應的任務必須在等待佇列中休眠。等待佇列中的最高優先順序任務(如果有)在GPU的每次中斷時被喚醒。
下圖(a)顯示了在PRT策略下如何在GPU上排程具有不同優先順序的三個任務,即高優先順序、中優先順序(MP)和低優先順序(LP)。當MP任務到達時,其GPU命令組可以在GPU上執行,因為沒有GPU命令組正在執行。如果GPU和CPU非同步執行,則MP任務可以在其上一個GPU命令組執行時再次到達。但是,根據PRT策略,由於GPU沒有空閒,MP任務這次將排隊。由於同樣的原因,甚至下一個HP任務也會排隊,因為更高優先順序的任務可能很快就會到達。TimeGraph附加在每個GPU命令組末尾的特定GPU命令集會向CPU生成一箇中斷,並相應地呼叫TimeGraph排程程式以喚醒等待佇列中的最高優先順序任務。因此,接下來選擇在GPU上執行HP任務,而不是MP任務。這樣,LP任務的下一個範例和HP任務的第二個範例將根據其優先順序進行排程。
鑑於GPU命令組的到達時間未知,且每個GPU命令組都是非搶佔的,我們認為PRT策略是提供可預測響應時間的最佳方法。然而,在每個GPU命令組邊界進行排程決策不可避免地會帶來開銷,如下圖(a)所示。
HT策略減少了這種排程開銷,稍微減少了可預測的響應時間。如果(i)當前正在執行的GPU命令組是由同一任務提交的,並且(ii)等待佇列中沒有更高優先順序的任務,則允許立即將GPU命令組提交給GPU。否則,它們必須以與PRT策略相同的方式暫停。在中斷時,只有當GPU聯機列表為空(GPU空閒)時,等待佇列中優先順序最高的任務才會被喚醒。
下圖(b)描述了在HT策略下如何排程下圖(a)中使用的同一組GPU命令組。與PRT策略不同,MP任務的第二個範例可以立即提交其GPU命令組,因為當前正在執行的GPU命令組是由其自身發出的。MP任務的這兩個GPU命令組可以連續執行,而不會產生空閒時間,HP任務的兩個GPU命令組也是如此。因此,HT策略更適用於面向吞吐量的任務,但HP任務被MP任務阻塞更長的時間。這是一種權衡,如果優先順序反轉至關重要,則PRT策略更合適。
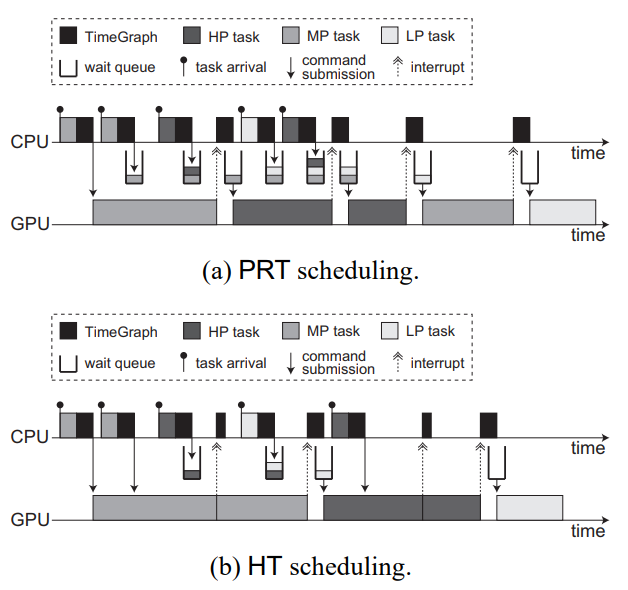
TimeGraph中GPU排程的範例。
TimeGraph支援GPU執行時間預測,使用基於歷史的方法——搜尋與傳入GPU命令序列匹配的以前GPU命令序列的記錄,適用於二維,但需要調查三維和計算。
TimeGraph開啟後,在各方面的效能影響如下:
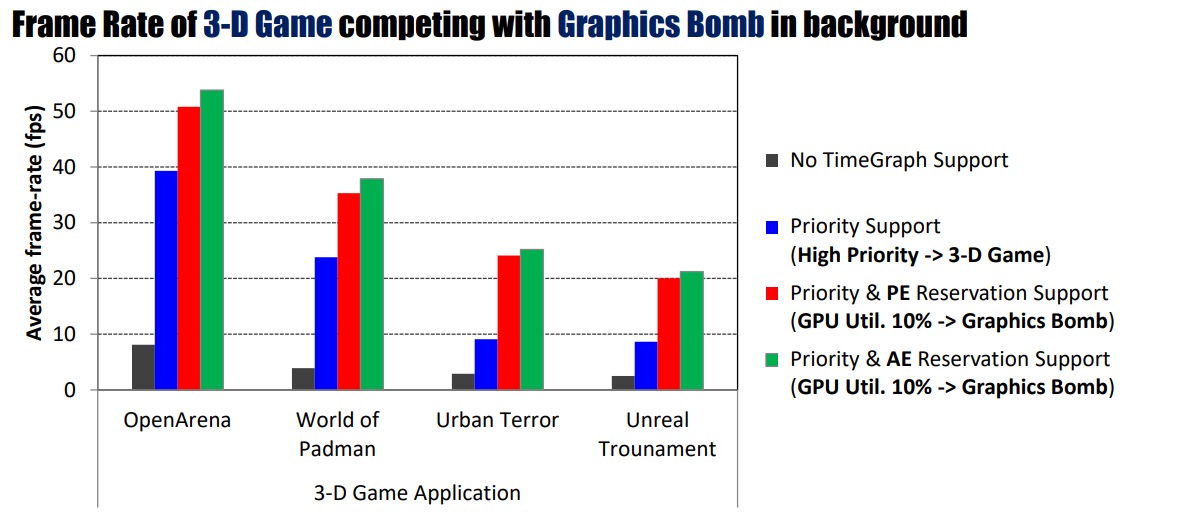
在後臺中與圖形Bomb競爭的三維遊戲幀速率。
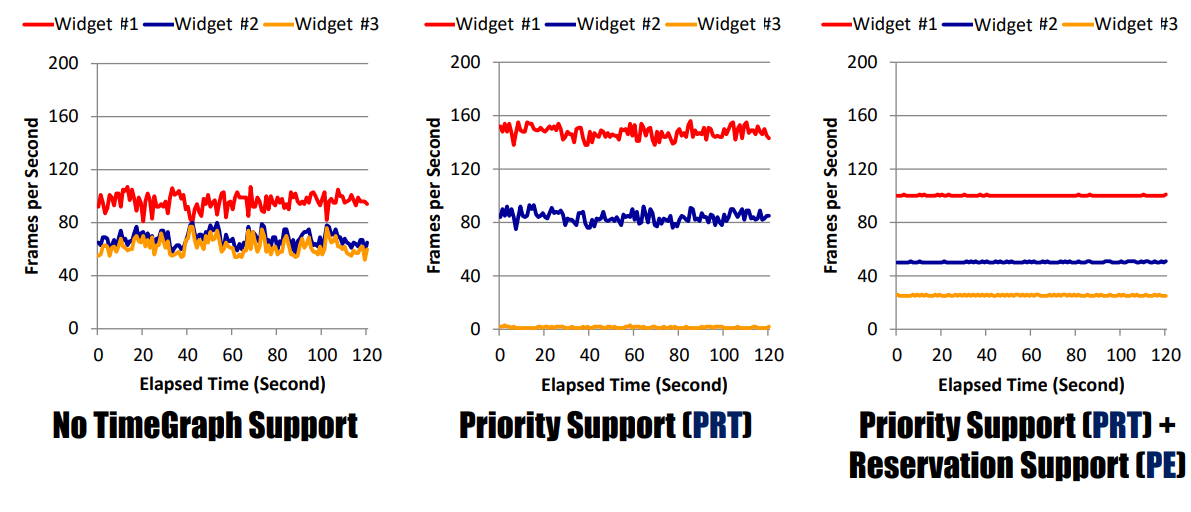
干擾時間。
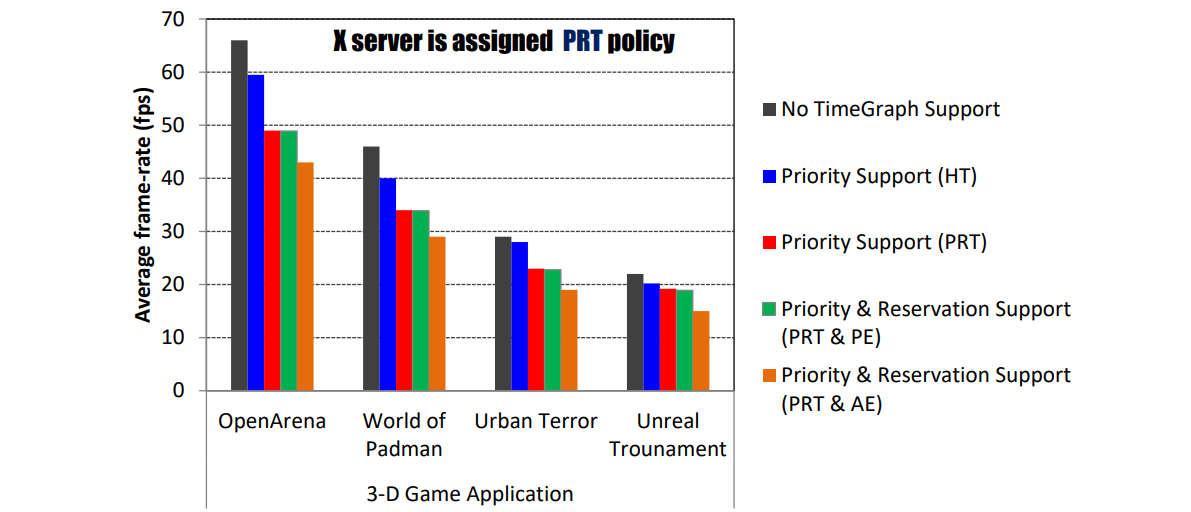
獨立裝置的效能。
總之,TimeGraph支援在多工環境中對GPU應用程式進行優先順序排序和隔離:
- 裝置驅動程式解決方案:不修改使用者空間。
- GPU命令的排程。
- 保留GPU資源使用。
16.3.3.5 GPU Scheduling
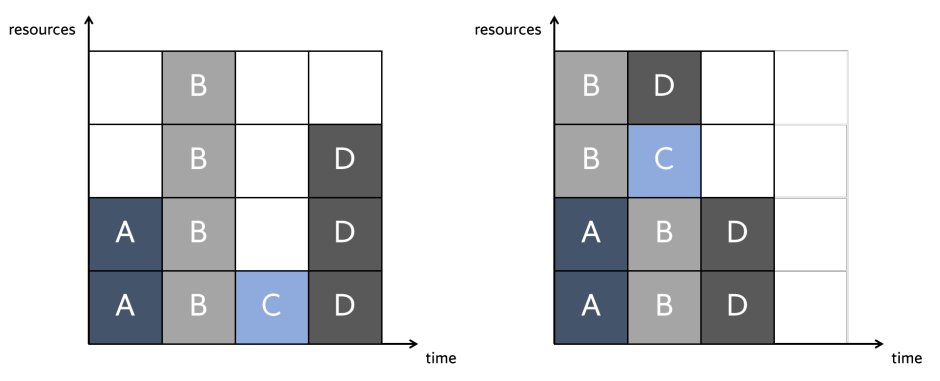
要開始理解在多個獨立應用程式之間共用單個GPU的含義和困難,我們首先必須瞭解GPU通常如何處理單個應用程式的任務排程。排程是跨時間和空間維度考慮的,即決定任務應該在何時何地執行。時間排程由上述FCFS演演算法確定;當任務到達佇列的頭部時,它將得到服務(如果有足夠的資源可用)。這種排程也是非搶佔性的——一旦將一個塊排程到裝置,就不能為另一個塊搶佔執行。此外,這種非搶佔也適用於任務級別。空間排程根據任務資源需求和SMX上的資源可用性的雙重考慮,確定任務可以執行的SMX單元。
在硬體排程級別,最小的可排程單元是執行緒塊,意味著裝置上的某些SMX必須能夠滿足整個塊的資源需求,以便將其分派執行。此外,一個核心的所有執行緒塊都不必一次處理。這引入了執行波的概念。如果我們將塊排程視為一個瞬時過程,那麼每個wave都會根據塊需求和裝置資源可用性來排程最大允許的塊數。一旦安排了wave,所有剩餘的塊都將保留在執行佇列中,直到裝置上的其他執行完成,從而釋放資源。
有許多因素決定了有多少塊可以組成一個完整的執行wave。核心執行緒塊的設定是一個重要因素,因為這決定了所需的每個資源的數量。另一個關鍵限制因素是對每個SMX允許的駐留執行緒塊數量的內建約束。必須注意這種約束,因為在達到最大駐留塊數之前,其他資源通常可能不會完全耗盡。這在由具有不同設定和資源需求的核心組成的並行執行場景中尤其可能。下表列出了多代NVIDIA GPU上每個SMX的資源限制。
| Compute Capability | 3.5 | 5.2 | 6.0 | 7.0 |
|---|---|---|---|---|
| Maximum Threads / SMX | 2048 | 2048 | 2048 | 2048 |
| Maximum Thread Blocks / SMX | 16 | 32 | 32 | 32 |
| Maximum Threads per Block | 1024 | 1024 | 1024 | 1024 |
| Maximum Registers / SMX | 65536 | 65536 | 65536 | 65536 |
| Shared Memory per SMX | 48 KB | 96 KB | 64 KB | 96 KB |
首先,執行緒塊在所有SMX單元中的分佈確保了某些技術(例如功率選通)無法可靠地應用於提高功率效率。其次,空間排程方法會導致不確定性模式,從而消除了通過將某些塊對映到特定SMX來提高利用率和/或效率的可能方法。最後,在並行場景下,獨立核心的不同資源需求導致SMX單元集的利用率不對稱。
將上述排程策略應用於多個獨立應用程式共用GPU裝置的場景,需要消除資源衝突並確保某些屬性,例如公平性。在GPU計算中實現這一點的一種方法是通過構造流。
GPU流表示CPU和GPU之間的獨立執行流,類似於CPU執行緒。在流中,操作按呼叫順序(即FCF)順序執行。在不同的流之間,根據資源的可用性,可以並行或交錯執行操作。下圖顯示了多流場景的抽象表示,流中的操作被排程到單個工作佇列中,只有當操作到達流佇列的前端時,才會將其排程到下一級裝置排程器。
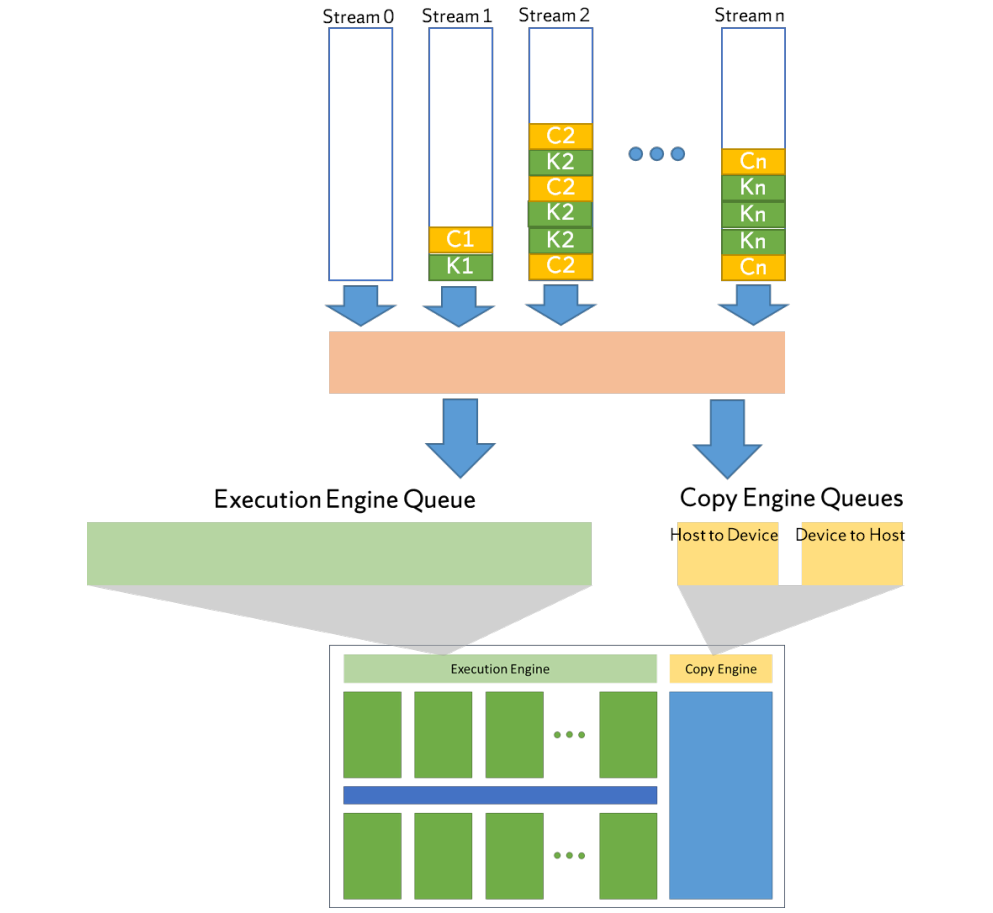
多核心排程層次結構。
下一級排程器表示執行佇列(對於核心)或複製佇列(對於記憶體傳輸)。同樣,這些佇列中的操作是以FCFS方式排程的,但由於某些裝置狀況,會出現一些警告。下表是一些GPU排程規則(是針對NVIDIA Jetson TX2體系結構根據經驗得出的一組排程規則,並針對其他幾種NVIDIA體系結構進行了驗證)。
| 識別符號 | 規則 |
|---|---|
| G1 | 當呼叫關聯的CUDA API函數(記憶體傳輸或核心啟動)時,複製操作或核心在其流的流佇列中排隊。 |
| G2 | 當核心到達其流佇列的頭部時,它將被排入EE佇列。 |
| G3 | EE佇列頭部的核心一旦完全排程,就會從該佇列中退出佇列。 |
| G4 | 一旦核心的所有塊完成執行,核心就會從其流佇列中退出佇列。 |
| X1 | 只有位於EE佇列頭部的核心塊才有資格分配。 |
| R1 | 只有在滿足資源約束的情況下,位於EE佇列頭部的核心塊才有資格被分配。 |
| R2 | 只有在某些SM上有足夠的可用執行緒資源時,位於EE佇列頭部的核心塊才有資格被分配。 |
| R3 | 只有在某些SM上有足夠的共用記憶體資源可用時,位於EE佇列頭部的核心塊才有資格被分配。 |
| C1 | 複製操作到達其流佇列的頭部時,將在CE佇列上排隊。 |
| C2 | CE佇列頭部的複製操作有資格分配給CE。 |
| C3 | 一旦將拷貝分配給GPU上的CE,CE佇列頭部的拷貝操作將從CE佇列中退出。 |
| C4 | CE完成複製後,複製操作將從其流佇列中退出佇列。 |
| N1 | 當對於每個其他流佇列,要麼佇列為空,要麼其頭部的核心在Kk之後啟動時,位於空流佇列頭部的核心Kk被排隊到EE佇列上。 |
| N2 | 非空流佇列頭部的核心Kk不能在EE佇列上排隊,除非空流佇列為空或其頭部的核心是在Kk之後啟動的。 |
| A1 | 核心只能在與其流優先順序匹配的EE佇列上排隊。 |
| A2 | 只有當所有高優先順序EE佇列(優先順序高過優先順序低)為空時,任何EE佇列頭部的核心塊才有資格分配。 |
理解這些排程規則對於實現最大資源利用率和高系統吞吐量至關重要。這些規則共同說明,一旦核心的塊開始排程到GPU(通過X1),在排程完第一個核心的所有塊之前,無法排程其他核心(G3)。當第一個核心由於不滿足其中一個資源規則(R1-R3)而在執行佇列中暫停時,最有可能出現這種情況。然而,執行佇列中後續核心的設定完全可能滿足這些資源規則。因此,將錯失提高裝置利用率的機會,從而需要更精細的執行佇列排程方法。在不進行類似解釋的情況下,我們聲稱複製佇列也存在這些考慮因素,因此需要對替代排程策略進行類似的檢查。
先前的研究為進一步分析GPU資源的利用情況提供了動力,以實現高效能和能效。Hong和Kim在論文沿著兩個主軸對應用程式進行了分類,即計算約束的應用程式和記憶體約束的應用程式,並表明效能、利用率和能效之間的關係與此特徵相關。受計算限制的應用程式具有強伸縮性。對於固定的問題大小,如果給應用程式更多的處理核心,它將顯示與核心數量成比例的加速(即,在更短的時間內完成相同數量的工作)。另一方面,記憶體受限的應用程式具有弱伸縮性。在這種情況下,效能受到固定問題大小的限制,如果問題大小按比例增加(即在相同時間內完成更多工作),則新增更多處理器只能提高效能。
Hong和Kim展示了這些縮放特性與各種GPU核心的效能和功耗之間的關係,以得出在應用程式中使用的最佳核心數。這種方法聲稱的好處是,根據應用型別,在不同的利用率下可以實現最佳的能效。對於受計算限制的應用程式,最佳點是充分利用率,而對於受記憶體限制的應用程式,最佳點是低於此值。顯而易見的結論是,許多應用程式不需要完全補充GPU資源來實現最佳效能。此外,該論文中方法的目標是開發一個模型,以確定單個核心的最佳核心數量,併成功證明了能量效率的提高。然而,該方法沒有解決並行執行場景,也沒有提出一種利用未充分利用的GPU資源潛力的方法。
下圖所示的簡單場景,在左邊,展示了單個核心執行的概念場景(即,獨立核心之間沒有裝置共用)以及由此產生的效能和利用率。特別是,該裝置的利用率僅為62.5%,計劃核心的最大生成時間為4個時間單位。然而,當考慮並行執行時,如下圖右所示,利用率增加到83.3%,最大完工時間減少到3個時間單位。雖然所示場景是對複雜排程問題的過度簡化,特別是考慮到上面討論的排程規則和約束,但它提供了分析和開發新技術以最大限度地利用GPU計算架構能力的最初動機。
序列(左)和並行(右)執行的效能和利用率比較。
在考慮典型GPU裝置的功耗特性時,進一步驗證了利用並行性和最大化裝置利用率的好處。如上所述,工作以迴圈或半迴圈的方式分配給裝置上的SMX單元。因此,整個裝置在執行期間通電,功率選通等策略通常不適用。當然,有多種因素決定核心應用程式的峰值功耗,包括執行緒操作、記憶體存取等,但我們觀察到,峰值通常與所利用的主裝置資源的總體百分比無關。下圖說明了這樣一個範例。
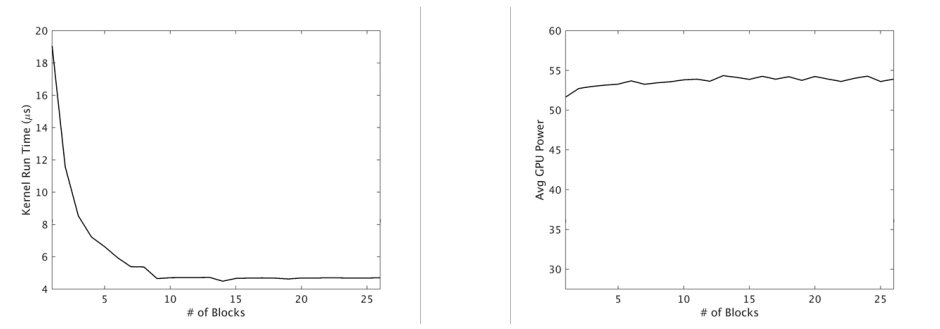
核心執行時間(左)和GPU功耗(右),用於增加塊數和裝置利用率。
在本例中,核心的最高效能是在GPU利用率不足的情況下實現的。類似地,峰值功耗從最低利用率水平到可能的最大利用率增長約5%,增幅可以忽略不計。這有助於從經驗上驗證中的觀察結果,並允許我們提出這樣的主張:提高系統吞吐量的方法,即在較短時間內完成更多工,將對系統能效產生積極影響,而無需引入任何明確管理功耗的技術。鑑於這些機會,研究的主要重點是獨立GPU任務的優化排程,以提高系統吞吐量和資源利用率。除了上述能效外,這種方法的好處還包括通過平均標準化週轉時間來衡量改善各自的任務績效。
OS的GPU排程可從使用者空間和核心空間考量,它們各有4種排程方式。
首先考慮使用者空間的GPU排程器的軟體體系結構,下圖描述了幾種體系結構。
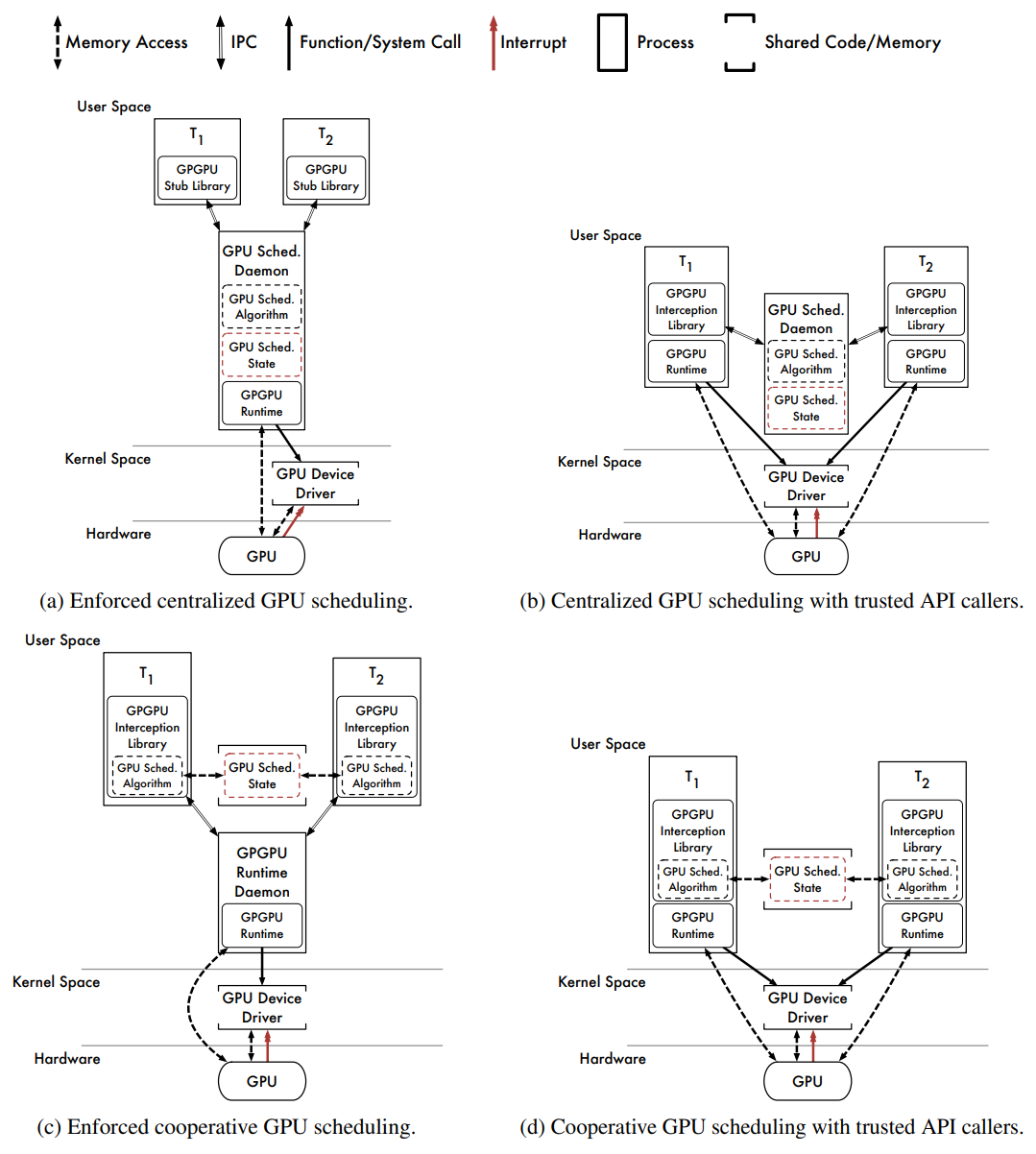
在使用者空間中實現的API驅動的GPU排程程式的幾種軟體體系結構。
- Centralized Scheduling With Enforcement(集中排程與實施)
上圖(a)描述了使用者空間中GPU排程的通用軟體體系結構。GPGPU API呼叫被髮出到每個任務中的GPGPU存根庫,存根庫通過IPC通道(例如UNIX域通訊端、TCP/IP通訊端等)將API請求重定向到GPGPU排程守護程式,該守護程式根據集中式排程策略為請求提供服務。守護行程自行執行所有API呼叫,強制執行所有排程決策。
好處:
1、由於決策集中,排程策略易於實施。
2、由於計劃的API呼叫由GPGPU排程守護程式本身執行,因此執行排程決策。
缺點:
1、守護行程必須包含或能夠載入組成任務的GPU核心程式碼。這可以在編譯守護程式時完成。GPU核心程式碼的動態載入也是可能的,但實現起來並不簡單。
2、由於任務和守護行程之間的訊息傳遞,IPC引入了開銷。
3、除非使用任何記憶體重對映技術,GPU核心資料必須通過IPC通道傳輸。資料密集型GPGPU應用程式(例如,由攝像機提供資料的行人檢測應用程式)的效能較差。
4、必須對守護行程本身進行排程。這會帶來額外的排程程式開銷。此外,除非RTOS提供一種機制,使守護行程可以從其組成部分繼承優先順序任務,可排程性分析不是直截了當的。可以通過提高守護程式的優先順序(會影響可排程性分析)來繞過此限制,或者可以為守護程式專門保留一個CPU(會導致其他工作丟失一個CPU)。這兩種方法都不可取。
GViM、gVirtuS、vCUDA、rCUDA和MPS採用這種流行的體系結構。然而,這些都沒有實現實時GPU排程策略。通過IPC通道傳輸GPU核心資料的開銷可能會導致資料量大的應用程式無法接受的效能。
- Centralized Scheduling Without Enforcement(集中排程,無需強制執行)
上圖(b)描述了另一個基於守護行程的排程器。GPGPU API呼叫被插入的庫截獲,對於每個呼叫,庫都會通過IPC通道向GPU排程守護程式發出相應GPU引擎的請求。庫等待每個請求被授予,守護程式根據集中式排程策略授予請求,一旦授予了必要的資源,插入的庫就會將截獲的API呼叫傳遞給原始GPGPU執行時。
好處:
1、易於實現,因為排程決策是集中的,GPU核心程式碼對於每個組成任務都是原生的。
2、GPU核心資料不會通過IPC通道複製。資料密集型GPGPU應用程式效能良好。
缺點:
1、無法執行GPU排程決策。行為不當或惡意的任務可能會繞過插入庫並直接存取GPGPU執行時。
2、IPC引入了訊息傳遞開銷。
3、必須安排守護程式本身。
由於GPU核心輸入和輸出資料不穿過IPC通道,這種體系結構犧牲了排程決策的執行,以實現資料密集型應用程式的效能優勢。此外,這是8種GPU排程體系結構中最容易實現的,是基於Windows 7的PTask原型所採用的體系結構,PTask是一種非實時GPU排程程式。RGEM也是一種實時GPU排程器,它也採用了這種體系結構。
- Cooperative Scheduling With Enforcement(帶執行的共同作業排程)
上圖(c)描述了共同作業GPU排程器和GPGPU執行時守護程式的軟體體系結構。插入的庫攔截API呼叫,每個任務中庫的每個範例呼叫相同的GPU排程演演算法,該演演算法嵌入在插入的庫中。GPU排程程式狀態的單個範例儲存在共用記憶體中,插入的庫將API呼叫傳遞給守護程式以實際執行。
好處:
1、GPU排程是高效的,因為每個任務都可以直接存取GPU排程程式狀態。
2、排程決策執行力弱。儘管GPGPU執行時守護程式集中了對GPU的所有存取,但行為不當或惡意的任務可能會繞過共同作業GPU排程程式直接向守護程式發出工作。
缺點:
1、對共用GPU排程程式狀態的存取必須在任務之間進行協調(或同步)。根據使用的同步機制,任務可能需要在執行排程演演算法時非搶佔地執行(以避免死鎖)。這需要RTO的支援或存取臨時禁用搶佔的特權CPU指令。
2、行為不當或惡意的任務可能會損壞GPU排程程式狀態,因為它可能會覆蓋共用記憶體中的任何資料。從此類故障中恢復可能很困難。
3、行為不當或惡意的任務可能繞過GPU排程程式,直接向GPGPU執行時守護程式發出工作,除非守護程式具有驗證請求的機制。
4、IPC引入了訊息傳遞開銷。
5、GPU核心資料必須通過IPC通道傳輸。
6、必須安排守護程式本身。
該體系結構中與IPC相關的開銷消除了共同作業排程的任何潛在好處。此外,由於可以繞過GPU排程器,執行排程決策的能力被削弱。這種體系結構與集中式排程(上圖a)相比沒有明顯的優勢。
- Cooperative Scheduling Without Enforcement(無強制的協同排程)
上圖(d)描述了共同作業GPU排程程式的軟體體系結構,無需使用守護程式。插入的庫攔截API呼叫,與之前一樣,任務協同執行相同的GPU排程演演算法,並在相同的共用排程程式狀態下執行。截獲的API呼叫在計劃時傳遞給原始GPGPU執行時。
好處:
1、沒有IPC管理費用。資料密集型GPGPU應用程式效能良好。
2、沒有要排程的守護程式。這簡化了實時分析,並減少了對RTO的支援。
3、高效的GPU排程。
壞處:
1、必須協調對GPU排程程式狀態的存取。
2、GPU排程程式狀態容易損壞。
3、無法執行GPU排程決策。
這是研究的最有效的使用者空間體系結構。它避免了所有IPC開銷,避免了守護行程帶來的所有開銷和分析難題。然而,它也是所有8種體系結構中最脆弱的,必須信任任務:不要繞過GPU排程程式和不損壞GPU排程程式狀態。
接下來探索核心空間的GPU排程。
使用者空間中的GPU排程有幾個弱點。一個缺點是,我們可能無法充分保護GPU排程程式資料結構。共同作業排程方法就是這種情況,其中GPU排程程式狀態可能會被行為錯誤或惡意任務破壞。然而,使用者空間排程的最大弱點是我們無法與底層RTO緊密整合,可能會妨礙我們以任何程度的信心實現正確的實時系統。RTOS可以提供一些機制,允許實時任務通過使用者空間操作影響其他任務的排程優先順序(例如,具有優先順序修改進度機制的實時鎖定協定,以及直接操縱優先順序的系統呼叫)。可以利用這些為使用者空間GPU排程器新增一些實時確定性。然而,這些機制可能不足以最小化,更重要的是,限制GPU相關的優先順序反轉。
我們解決很多問題的能力受到使用者空間的嚴重限制。通過將GPU排程器與CPU排程器和RTOS核心中的其他作業系統元件(如中斷處理服務)緊密整合,可以最好地解決這些問題。這些問題促使我們考慮核心空間GPU排程器。下圖描述了核心空間GPU排程器的幾種高階軟體體系結構。假設所有方法都受益於與RTO緊密整合的能力。
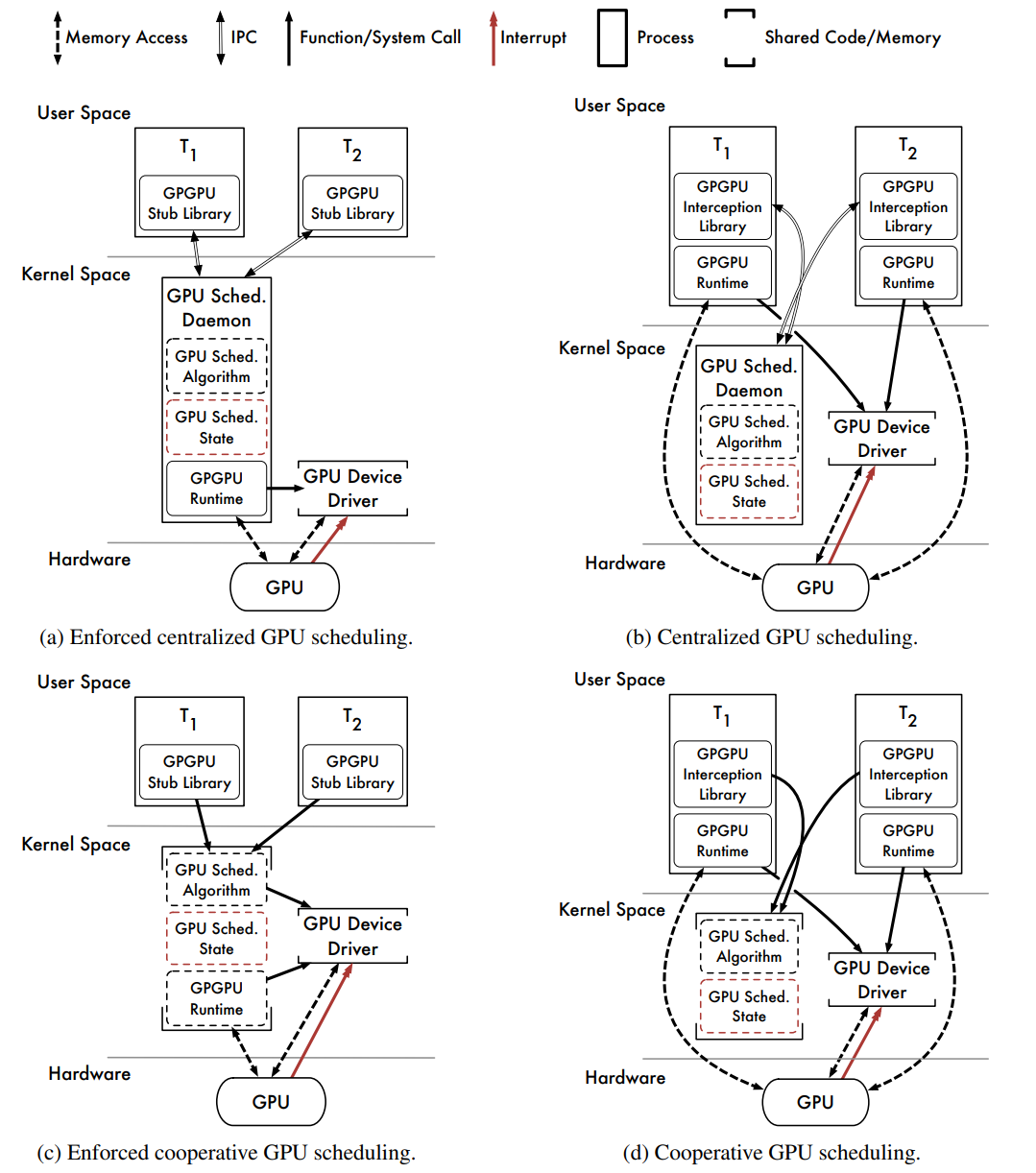
- Centralized Scheduling With Enforcement(集中排程與實施)
上圖(a)描述了具有集中式排程程式守護程式的軟體體系結構。該體系結構與圖3.1(a)中所示的體系結構非常相似,其功能大致相同。然而,GPU排程守護程式現在從核心空間執行。
好處:
1、GPU核心資料不會通過IPC通道複製。這是可能的,因為GPU排程守護程式可以直接存取其組成任務的使用者空間記憶體。資料密集型GPGPU應用程式效能良好。
2、排程策略是集中的。
3、執行計劃決策。
缺點:
1、核心空間GPGPU執行時可能不可用。所有制造商提供的GPGPU執行時僅在使用者空間中執行。
2、必須對守護行程本身進行排程。會帶來額外的系統開銷,然而,從核心空間來看,可以更靈活地對守護行程進行適當的優先順序排序,以確保實時確定性。
3、守護行程必須包括或能夠載入組成任務的GPU核心程式碼。
4、IPC引入了訊息傳遞開銷。
這種體系結構得益於強制的集中式排程,無需在IPC通道上穿梭GPU核心輸入和輸出資料。由於訊息傳遞,這種方法仍然會遇到一些IPC通道開銷。然而,這種方法最大的缺點是實用性:核心空間GPGPU執行時通常不可用。正如Gdev(採用上圖a和d的混合架構)所示,雖不是一個無法克服的挑戰,但很困難。
- Centralized Scheduling Without Enforcement(集中排程,無需強制執行)
上圖(b)描述了另一個帶有GPU排程守護程式的軟體體系結構,其架構與使用者空間的(b)中的架構相匹配,只是守護行程現在在核心空間中執行。
好處:
1、使用通用使用者空間GPGPU執行時。
2、排程策略是集中的。
3、GPU核心資料未通過IPC通道複製。
好處:
1、無法執行GPU排程決策。
2、IPC引入了訊息傳遞開銷。
3、必須排程守護程式本身。
該體系結構在核心空間集中式排程和實際約束之間達成了妥協。排程決策是在核心空間內做出的,但由具有使用者空間GPGPU執行時的單個任務執行。因此,體系結構無法強制執行其排程決策,是基於Linux的PTask原型所採用的體系結構,PTask是一個非實時GPU排程器。
- Cooperative Scheduling With Enforcement(帶執行的共同作業排程)
上圖(c)描述了共同作業GPU排程器的軟體體系結構。GPGPU API呼叫被路由到存根庫,存根庫通過OS系統呼叫呼叫核心空間GPU排程程式。GPU排程程式狀態由所有任務共用,但儲存在核心空間資料結構中。計劃的API呼叫由核心空間GPGPU執行時使用呼叫任務的程式執行緒執行。
好處:
1、GPU排程程式狀態受保護。與共同作業使用者空間排程器不同,GPU排程器狀態在核心空間內受到保護,不會因行為不當或惡意的使用者空間任務而損壞。
2、在核心空間中,對GPU排程程式狀態的同步存取是微不足道的。在更新GPU排程程式資料結構時,無需升級許可權以非搶佔方式執行。
3、GPU排程是有效的。
4、執行計劃決策。
好處:
1、需要核心空間GPGPU執行時。
這是從效能角度研究的8種體系結構中最強的一種,共同作業排程決策是高效的,由RTO執行。GPGPU執行時是使用呼叫任務的程式堆疊在核心空間中執行的,而不是單獨排程的守護行程,沒有IPC開銷,唯一限制是對核心空間GPGPU執行時的依賴。
- Cooperative Scheduling Without Enforcement(無強制的協同排程)
上圖(d)描述了共同作業GPU排程器的另一種軟體體系結構。插入的庫攔截API呼叫,並通過系統呼叫呼叫核心空間GPU排程器。與之前一樣,GPU排程程式狀態由所有任務共用,並保護其不受行為不當和惡意任務的影響。要計劃API呼叫,GPU排程程式將控制權返回到插入的庫。插入的庫使用使用者空間GPGPU執行時執行計劃的API呼叫。
好處:
1、使用通用使用者空間GPGPU執行時。
2、GPU排程程式狀態受保護。
3、存取GPU排程程式狀態很容易同步。
4、GPU排程是有效的。
壞處:
1、無法執行GPU排程決策。
為了支援使用者空間GPGPU執行時,此體系結構犧牲了強制功能,通過直接存取GPGPU執行時,信任任務不會繞過插入的庫。儘管有此限制,但從效能角度來看,它仍然是一個強大的體系結構。與前面的方法一樣,排程決策是有效的。此外,沒有與IPC或守護行程相關的開銷。對於願意實現作業系統級程式碼的研究人員或開發人員來說,這種體系結構是最實用的高效能選項。
再聊聊其它GPU排程相關的雜項技術。
下圖是名為vHybrid的CPU-GPU排程架構:
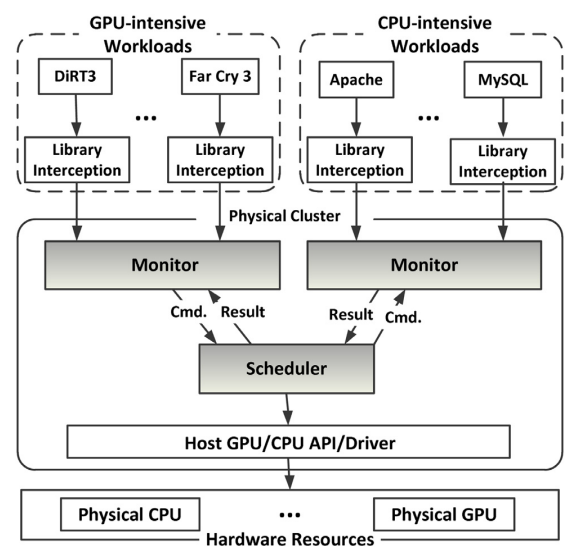
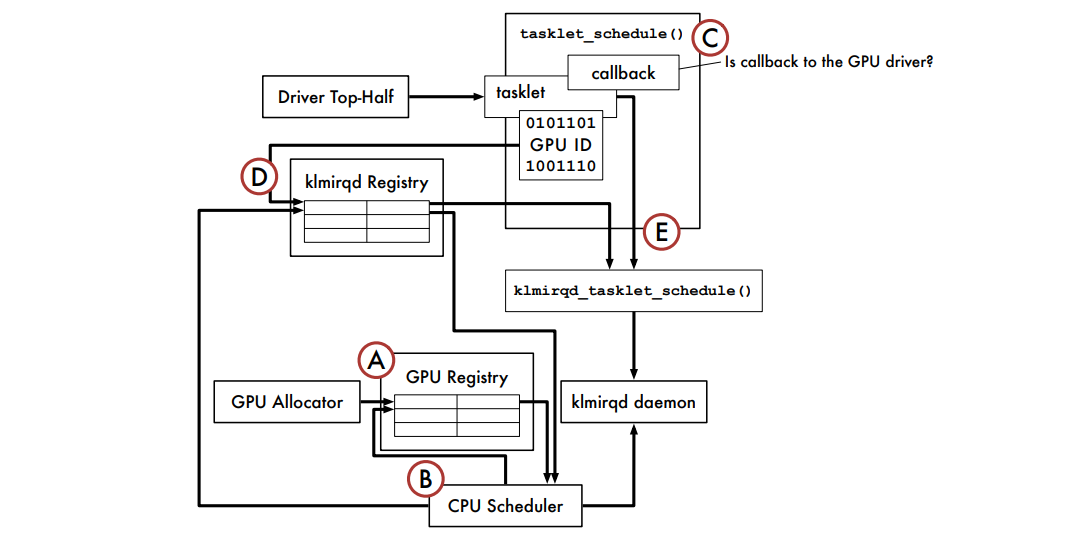
下圖是使用klmirqd的GPU微執行緒排程基礎架構:
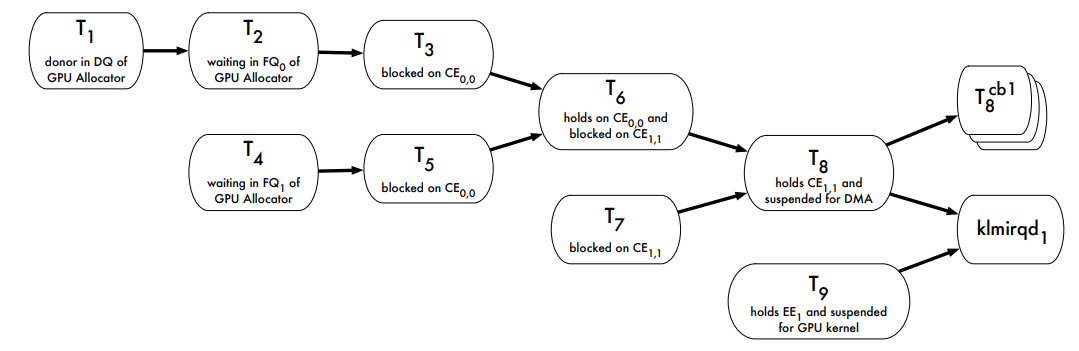
使用GPUSync的任務的複雜執行依賴鏈範例:
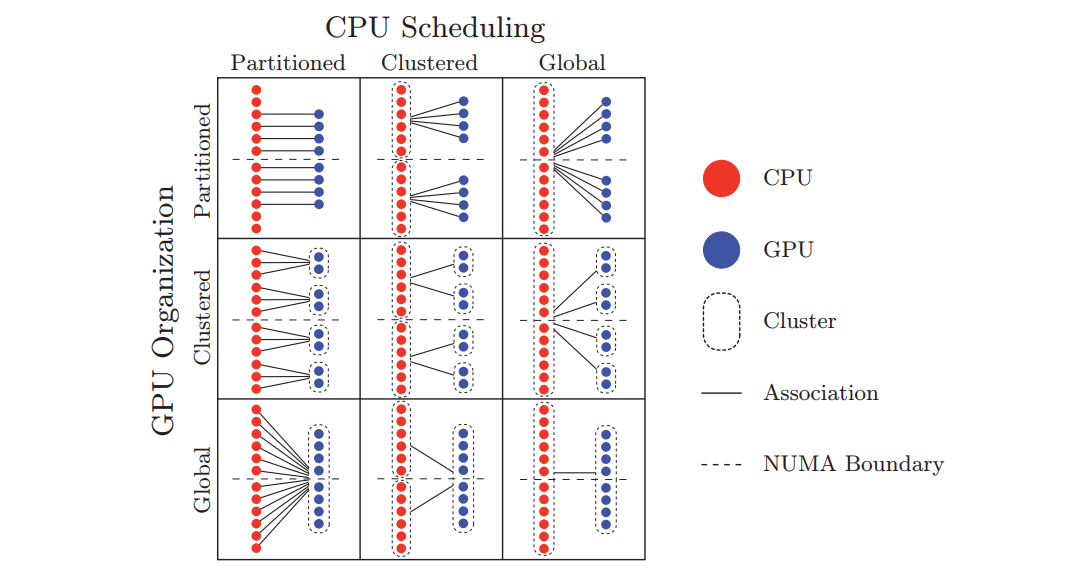
混合平臺設定:
下半部分開銷處理的高階檢視:
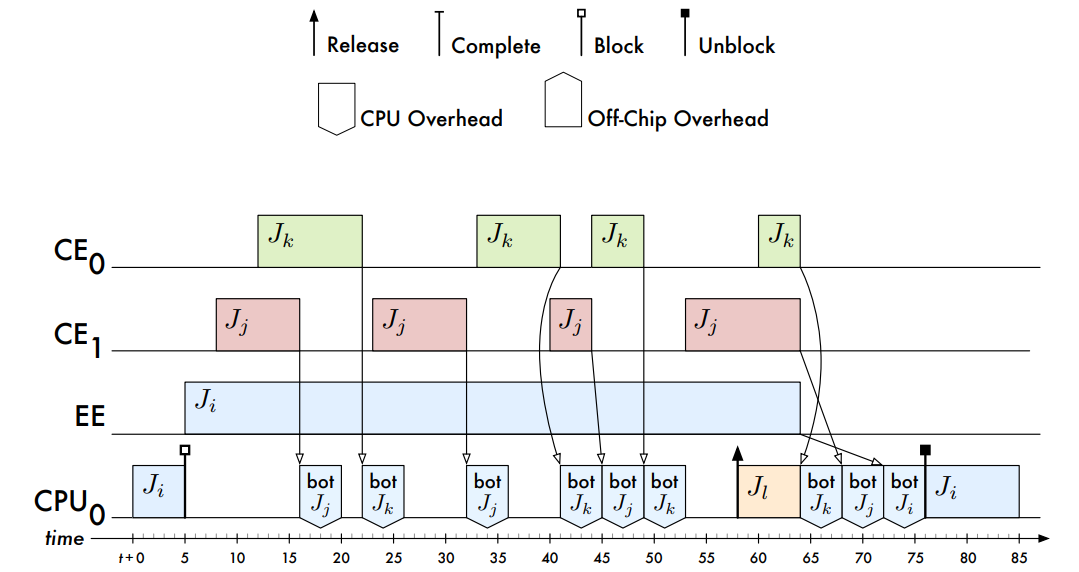
間接開銷增加引擎臨界區長度的情況:
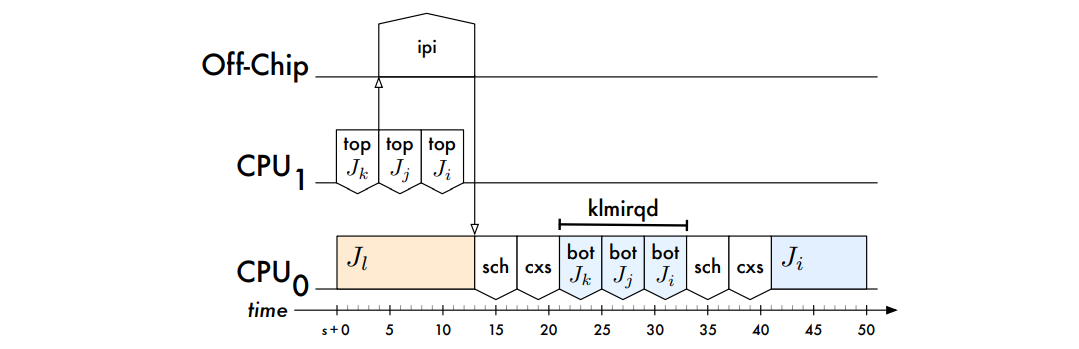
描述回撥開銷的排程:

更多詳情看參閱:
- REAL-TIME SCHEDULING FOR GPUS WITH APPLICATIONS IN ADVANCED AUTOMOTIVE SYSTEMS
- GPU Resource Optimization and Scheduling for Shared Execution Environments
16.4 GPU驅動
16.4.1 NVIDIA
16.4.1.1 Turing架構
Turing代表了十多年來最大的架構飛躍,它提供了一種新的核心GPU架構,使PC遊戲、專業圖形應用程式和深度學習推斷在效率和效能方面取得了重大進步。
使用新的基於硬體的加速器和混合渲染方法,Turing融合了光柵化、實時光線跟蹤、AI和模擬,以實現PC遊戲中難以置信的真實感、神經網路支援的驚人新效果、電影質量的互動體驗,以及建立或導航複雜3D模型時的流體互動。
在核心體系結構中,Turing顯著提升圖形效能的關鍵促成因素是具有改進著色器執行效率的新GPU處理器(流式多處理器SM)體系結構,以及包括支援最新GDDR6記憶體技術的新記憶體系統體系結構。
影象處理應用程式(如ImageNet Challenge)是深度學習的首批成功案例之一,因此AI有潛力解決許多重要的圖形問題也就不足為奇了。Turing的Tensor Cores為一套新的基於深度學習的神經服務提供動力,除了為基於雲的系統提供快速AI推斷外,還為遊戲和專業圖形提供驚人的圖形效果。

Turing的革命性新特性。
NVIDIA Turing是世界上最先進的GPU體系結構,高階TU102 GPU包括在臺積電12納米FFN(FinFET NVIDIA)高效能製造工藝上製造的186億個電晶體。GeForce RTX 2080 Ti Founders Edition GPU具有以下優異的計算效能:
- 14.2峰值單精度(FP32)效能的TFLOPS。
- 28.5峰值半精度(FP16)效能的TFLOPS。
- 14.2 TIPS1通過獨立的整數執行單元與FP並行。
- 113.8 Tensor TFLOPS。
- 10 Giga射線/秒。
- 78 Tera RTX-OPS。
Quadro RTX 6000提供了專為專業工作流設計的卓越計算效能:
- 16.3峰值單精度(FP32)效能的TFLOPS。
- 32.6峰值半精度(FP16)效能的TFLOPS。
- 16.3 TIPS通過獨立的整數執行單元與FP並行。
- 130.5張量TFLOPS。
- 10 Giga射線/秒。
- 84 Tera RTX-OPS。
此外,新的特性還有新的Streaming Multiprocessor (SM)、Turing Tensor Core、實時光追加速、新的著色改進(Mesh Shading、Variable Rate Shading、Texture-Space Shading 、Multi-View Rendering)、Deep Learning、GDDR6等等。

Turing架構的TU102 GPU。
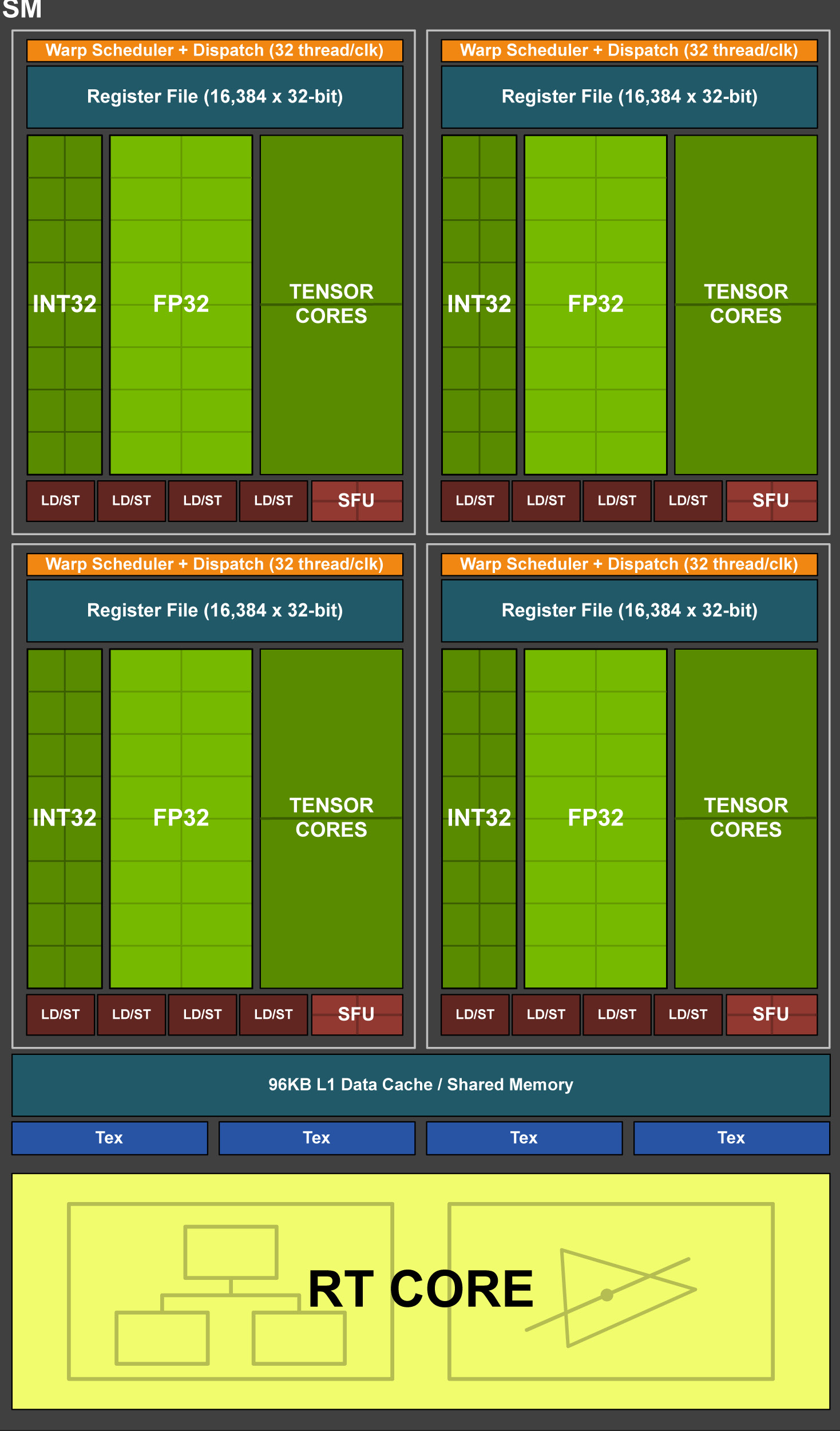
Turing TU102/TU104/TU106 Streaming Multiprocessor (SM)。
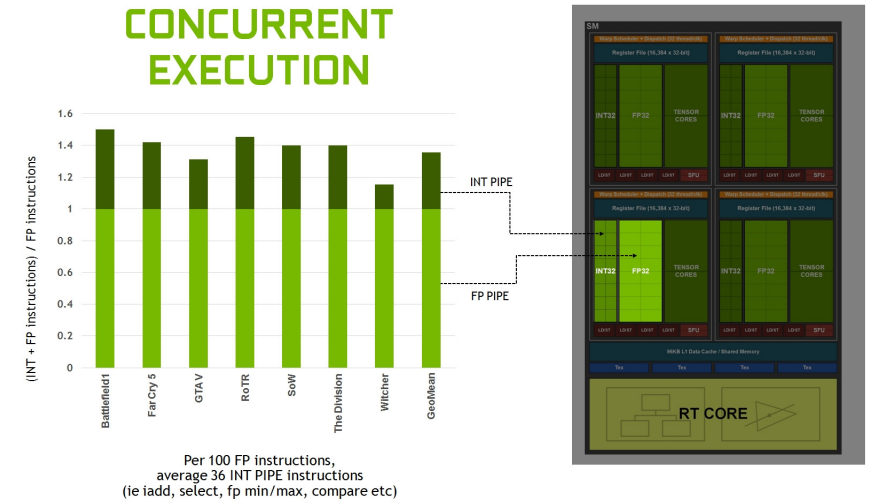
分析許多工作負載顯示,平均每100個浮點操作有36個整數操作。
新的共用記憶體體系結構。

與Pascal相比,Turing Shading在許多不同工作負載下的效能加速比。
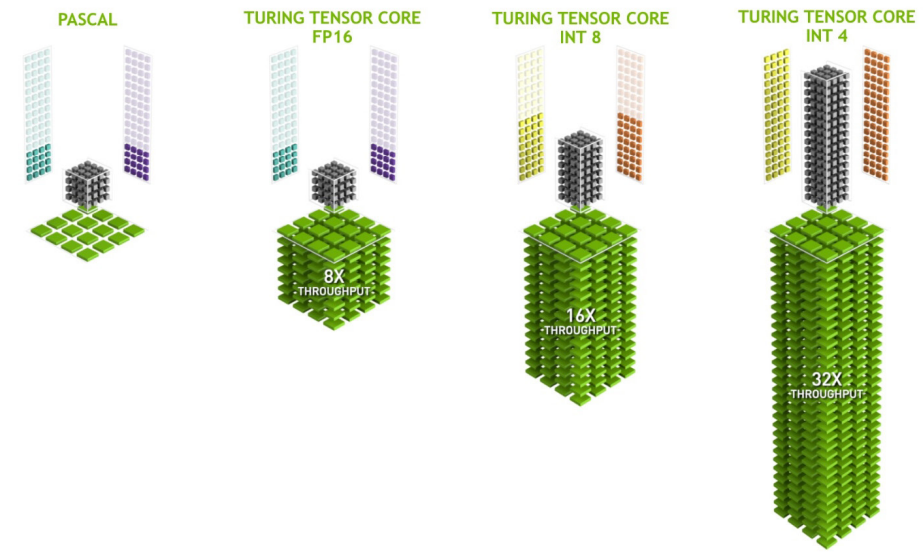
新的Turing Tensor Core為人工智慧推理提供了多精度。
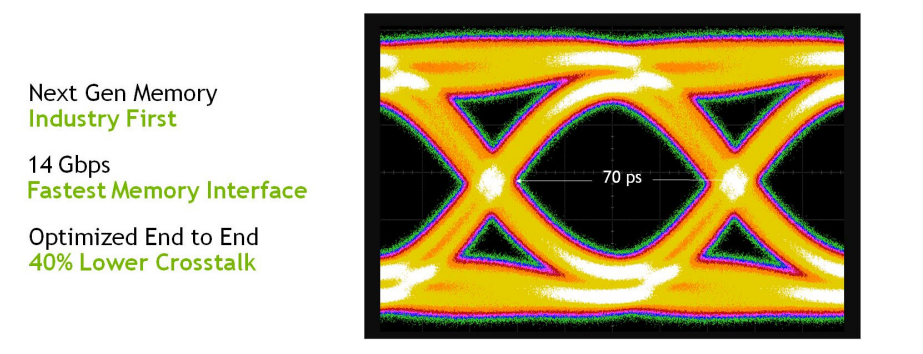
Turing GDDR6。
圖靈GPU除了新的GDDR6記憶體子系統之外,還新增了更大、更快的二級快取。TU102 GPU附帶6 MB二級快取,是TITAN Xp中使用的上一代GP102 GPU提供的3 MB二級快取的兩倍。TU102還提供了比GP102高得多的二級快取頻寬。與上一代NVIDIA GPU一樣,圖靈中的每個ROP分割區包含八個ROP單元,每個單元可以處理一個顏色樣本。完整的TU102晶片包含12個ROP分割區,總共96個ROP。
NVIDIA GPU利用幾種無失真記憶體壓縮技術來減少資料寫入幀緩衝記憶體時的記憶體頻寬需求。GPU的壓縮引擎有各種不同的演演算法,這些演演算法根據資料的特性確定壓縮資料的最有效方式,減少了寫入記憶體和從記憶體傳輸到二級快取的資料量,並減少了使用者端(如紋理單元)和幀緩衝區之間傳輸的資料量。圖靈進一步改進了Pascal最先進的記憶體壓縮演演算法,在GDDR6原始資料傳輸速率增加的基礎上,進一步提升了有效頻寬。如下圖所示,原始頻寬的增加和通訊量的減少意味著與Pascal相比,Turing上的有效頻寬增加了50%,對於保持體系結構平衡和支援新Turing SM體系結構提供的效能至關重要。
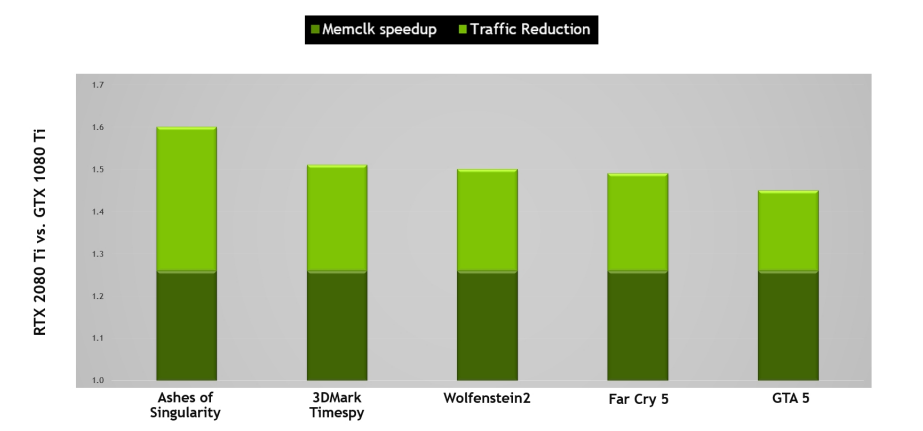
與基於Pascal GP102的1080 Ti相比,基於Turing TU102的RTX 2080 Ti的記憶體子系統和壓縮(流量減少)改進提供了大約50%的有效頻寬改進。
此外,Turing還開創性地增加了實時光線追蹤的支援,引入了混合管線:

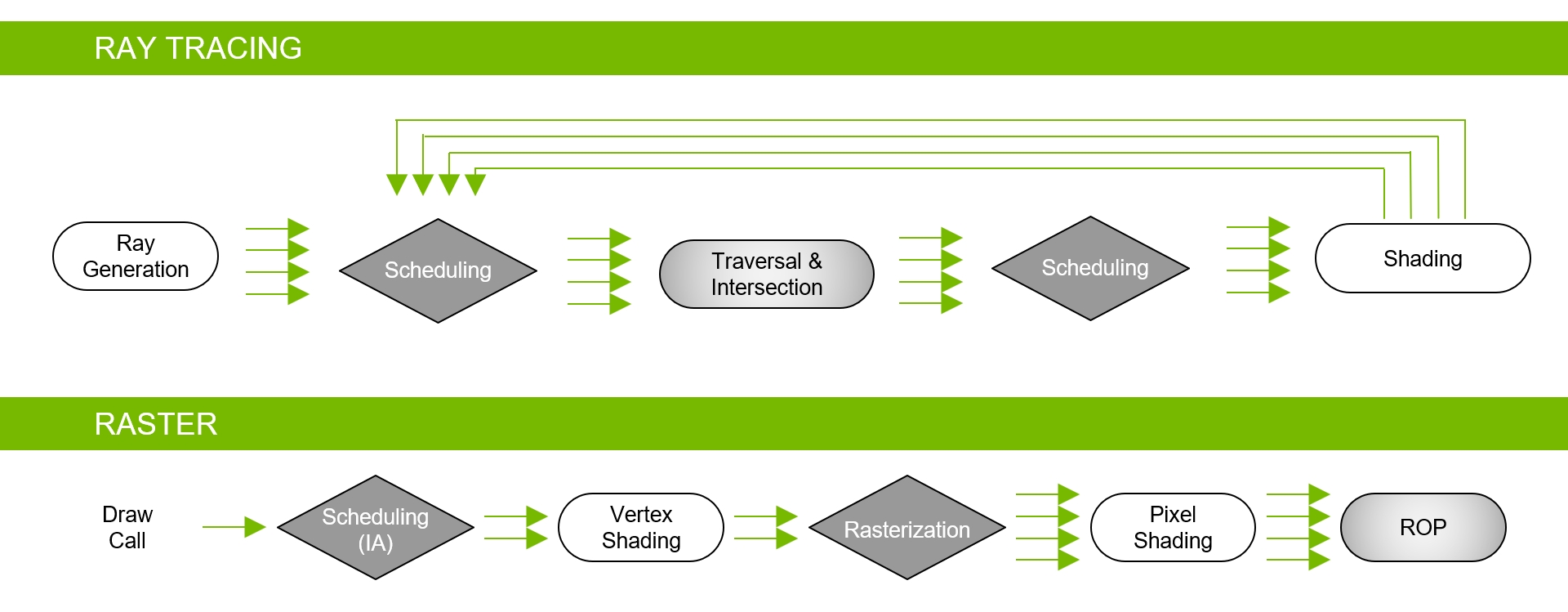
Turing GPU可以加速以下許多渲染和非渲染操作中使用的光線跟蹤技術:
- 反射和折射。
- 陰影和環境光遮擋。
- 全域性照明。
- 即時離線光照貼圖烘焙。
- 美麗的照片和高質量的預覽。
- 用於注視點VR渲染的主光線。
- 遮擋剔除。
- 物理、碰撞檢測、粒子模擬。
- 音訊模擬(例如,NVIDIA VRWorks音訊構建在OptiX API之上)。
- AI可見性查詢。
- 引擎內路徑跟蹤(非實時)生成參考螢幕截圖,用於調整實時渲染技術和去噪器、材質合成和場景照明。
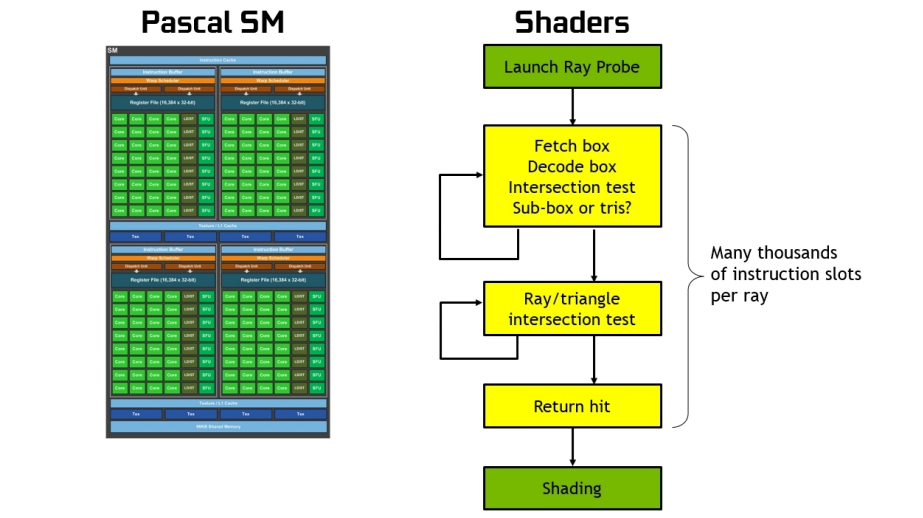
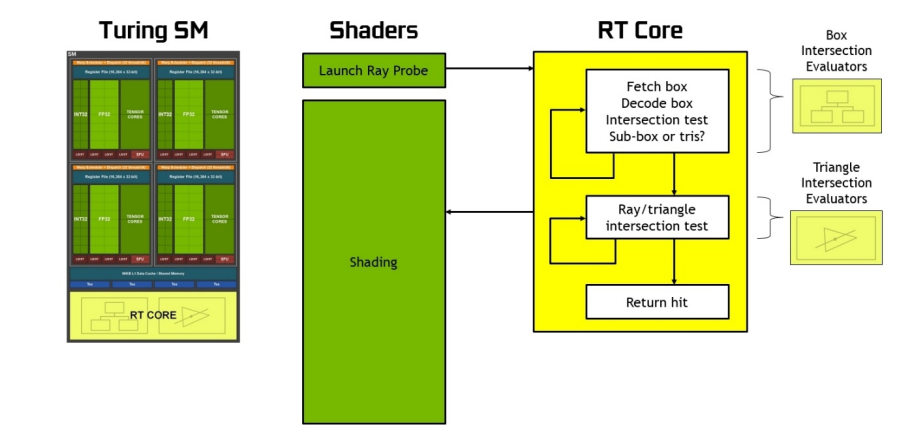
在沒有硬體加速的情況下,光線跟蹤需要每條光線上千個軟體指令槽,以便在BVH結構中連續測試較小的包圍盒,直到可能碰到三角形為止。這是一個計算密集型的過程,如果沒有基於硬體的光線跟蹤加速,就不可能在GPU上實時完成(見下圖)。
下圖說明了傳統的光柵化和著色過程,3D場景被光柵化並轉換為螢幕空間中的畫素,對畫素進行可見性測試、外觀著色測試和深度測試。所有操作都發生在相同的螢幕空間畫素網格上,在相同的畫素上。
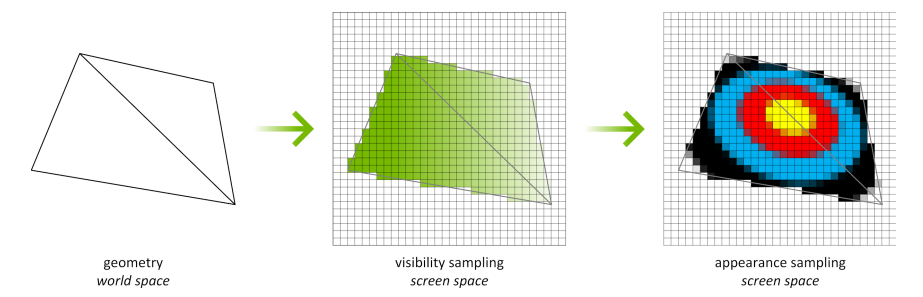
使用紋理空間著色(Texture Space Shading,TSS),可見性取樣(光柵化和z測試)和外觀取樣(著色)這兩個主要操作可以解耦,並以不同的速率、在不同的取樣網格上、甚至在不同的時間軸上執行。著色過程不再直接繫結到螢幕空間畫素,而是發生在紋理空間中。在下圖中,幾何體仍被光柵化以生成螢幕空間畫素,可見性測試仍在螢幕空間中進行。然而,不是在螢幕空間中著色,而是發現需要覆蓋輸出畫素的紋理。換句話說,螢幕空間畫素的足跡對映到單獨的紋理空間中,並在紋理空間中對關聯的texel進行著色。對映到紋理空間是一種標準的紋理對映操作,對LOD和各向異性過濾等具有相同的控制。為了生成最終的螢幕空間畫素,我們從著色紋理中取樣。紋理是根據範例請求按需建立的,僅為參照的紋理生成值。

TSS的一個範例用例是提高VR渲染的效率,下圖顯示了VR渲染中TSS的一個範例用例。在VR中,渲染一對立體影象,左眼可見的幾乎所有元素也顯示在右眼檢視中。使用TSS,我們可以對整個左眼檢視進行著色,然後通過從完成的左眼檢視取樣來渲染右眼檢視。右眼檢視只需在未找到有效樣本的情況下對新紋理進行著色(例如,從左眼角度看,背景物件在檢視中被遮擋,但右眼可見)。

多檢視渲染(MVR)允許開發人員從多個視點高效地繪製場景,甚至以不同姿勢繪製角色的多個範例,所有這些都在一個通道中完成。Turing硬體每個過程最多支援四個檢視,在API級別最多支援32個檢視。通過只提取一次幾何體並對其著色,Turing可以在渲染多個版本時以最佳方式處理三角形及其關聯的頂點屬性。當通過D3D12檢視範例化API存取時,開發人員只需使用變數SV_ViewID來索引不同的變換矩陣、參照不同的混合權重或控制他們喜歡的任何著色器行為,這些行為取決於他們正在處理的檢視。
下圖顯示了200° FOV HMD的設定,其中使用了兩個傾斜面板,需要MVR更大的表現力。MVR的靈活性也有利於支援標準立體VR顯示器的更精確校準,以與單個使用者的面部對齊。在立體渲染中,眼睛只是在X方向上相互偏移的簡單假設並不完全正確,實際上還有一些額外的不對稱,需要獨立投影才能獲得最高的保真度對齊。

200°FOV HMD,其中使用兩個傾斜面板,並受益於MVR。

MVR單通道級聯陰影貼圖渲染。
16.4.1.2 Ampere架構
NVIDIA Ampere體系架構GPU系列的最新成員GA102和GA104,GA102和GA104是新英偉達「GA10x」級Ampere架構GPU的一部分,GA10x GPU基於革命性的NVIDIA Turing GPU架構。
GeForce RTX 3090是GeForce RTX系列中效能最高的GPU,專為8K HDR遊戲設計。憑藉10496個CUDA核心、24GB GDDR6X記憶體和新的DLSS 8K模式,它可以在8K@60fps。GeForce RTX 3080的效能是GeForce RTX 2080的兩倍,實現了GPU有史以來最大的一代飛躍,GeForce RTX 3070的效能可與NVIDIA上一代旗艦GPU GeForce RTX 2080 Ti相媲美,GA10x GPU中新增的HDMI 2.1和AV1解碼功能允許使用者使用HDR以8K的速度傳輸內容。
NVIDIA A40 GPU是資料中心在效能和多工作負載能力方面的一次革命性飛躍,它將一流的專業圖形與強大的計算和AI加速相結合,以應對當今的設計、創意和科學挑戰。A40具有與RTX A6000相同的核心數量和記憶體大小,將為下一代虛擬工作站和基於伺服器的工作負載提供動力。NVIDIA A40的能效比上一代高出2倍,它為專業人士帶來了光線跟蹤渲染、模擬、虛擬製作等最先進的功能。

Ampere GA10x體系結構具有巨大的飛躍。
GA102的關鍵特性有2倍FP32處理、第二代RT Core、第三代Tensor Core、GDDR6X和GDDR6記憶體、PCIe Gen 4等。
與之前的NVIDIA GPU一樣,GA102由圖形處理叢集(Graphics Processing Cluster,GPC)、紋理處理叢集(Texture Processing Cluster,TPC)、流式多處理器(Streaming Multiprocessor,SM)、光柵操作器(Raster Operator,ROP)和記憶體控制器組成。完整的GA102 GPU包含7個GPC、42個TPC和84個SM。
GPC是主要的高階硬體塊,所有關鍵圖形處理單元都位於GPC內部。每個GPC都包括一個專用的光柵引擎,現在還包括兩個ROP分割區(每個分割區包含八個ROP單元),是NVIDIA Ampere Architecture GA10x GPU的一個新功能。GPC包括六個TPC,每個TPC包括兩個SM和一個PolyMorph引擎。
GA102 GPU還具有168個FP64單元(每個SM兩個),FP64 TFLOP速率是FP32操作TFLOP速率的1/64。包括少量的FP64硬體單元,以確保任何帶有FP64程式碼的程式都能正確執行,包括FP64 Tensor Core程式碼。
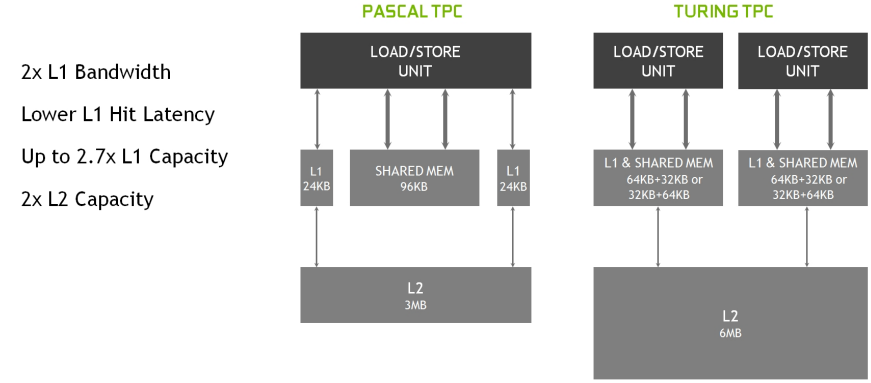
GA10x GPU中的每個SM包含128個CUDA核、四個第三代Tensor核、一個256 KB的暫存器檔案、四個紋理單元、一個第二代光線跟蹤核和128 KB的L1/共用記憶體,這些記憶體可以根據計算或圖形工作負載的需要設定為不同的容量。GA102的記憶體子系統由12個32位元記憶體控制器組成(共384位元),512 KB的二級快取與每個32位元記憶體控制器配對,在完整的GA102 GPU上總容量為6144 KB。
Ampere架構還對ROP執行了優化。在以前的NVIDIA GPU中,ROP繫結到記憶體控制器和二級快取。從GA10x GPU開始,ROP是GPC的一部分,通過增加ROP的總數和消除掃描轉換前端和光柵操作後端之間的吞吐量不匹配來提高光柵操作的效能。每個GPC有7個GPC和16個ROP單元,完整的GA102 GPU由112個ROP組成,而不是先前在384位元記憶體介面GPU(如前一代TU102)中可用的96個ROP。此方法可改進多取樣抗鋸齒、畫素填充率和混合效能。
在SM架構方面,圖靈SM是NVIDIA的第一個SM體系結構,包括用於光線跟蹤操作的專用核心。Volta GPU引入了張量核,Turing包括增強的第二代張量核。Turing和Volta SMs支援的另一項創新是並行執行FP32和INT32操作。GA10x SM改進了上述所有功能,同時還新增了許多強大的新功能。與以前的GPU一樣,GA10x SM被劃分為四個處理塊(或分割區),每個處理塊都有一個64 KB的暫存器檔案、一個L0指令快取、一個warp排程程式、一個排程單元以及一組數學和其他單元。這四個分割區共用一個128 KB的一級資料快取/共用記憶體子系統。與每個分割區包含兩個第二代張量核、總共八個張量核的TU102 SM不同,新的GA10x SM每個分割區包含一個第三代張量核,總共四個張量核,每個GA10x張量核的功能是圖靈張量核的兩倍。與Turing相比,GA10x SM的一級資料快取和共用記憶體的組合容量要大33%。對於圖形工作負載,快取分割區容量是圖靈的兩倍,從32KB增加到64KB。

GA10x Streaming Multiprocessor (SM) 。
GA10x SM繼續支援圖靈支援的雙速FP16(HFMA)操作。與TU102、TU104和TU106圖靈GPU類似,標準FP16操作由GA10x GPU中的張量核處理。FP32吞吐量的比較X因子如下表:
| Turing | GA10x | |
|---|---|---|
| FP32 | 1X | 2X |
| FP16 | 2X | 2X |
如前所述,與前一代圖靈體系結構一樣,GA10x具有用於共用記憶體、一級資料快取和紋理快取的統一體系結構。這種統一設計可以根據工作負載進行重新設定,以便根據需要為L1或共用記憶體分配更多記憶體。一級資料快取容量已增加到每個SM 128 KB。在計算模式下,GA10x SM將支援以下設定:
- 128 KB L1 + 0 KB Shared Memory
- 120 KB L1 + 8 KB Shared Memory
- 112 KB L1 + 16 KB Shared Memory
- 96 KB L1 + 32 KB Shared Memory
- 64 KB L1 + 64 KB Shared Memory
- 28 KB L1 + 100 KB Shared Memory
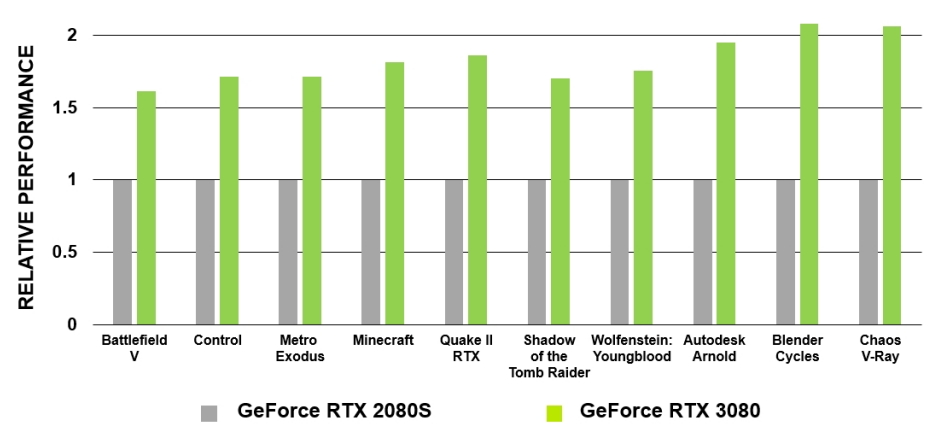
Ampere架構的RT Core比Turing的RT Core的射線/三角形相交測試速度提高了一倍:
GA10x GPU通過一種新功能增強了先前NVIDIA GPU的非同步計算功能,該功能允許在每個GA10x GPU SM中同時處理RT Core和圖形或RT Core和計算工作負載。GA10x SM可以同時處理兩個計算工作負載,並且不像以前的GPU代那樣僅限於同時計算和圖形,允許基於計算的降噪演演算法等場景與基於RT Core的光線跟蹤工作同時執行。

相比Turing架構,NVIDIA Ampere體系結構在渲染同一遊戲中的同一幀時,可大大提高效能:
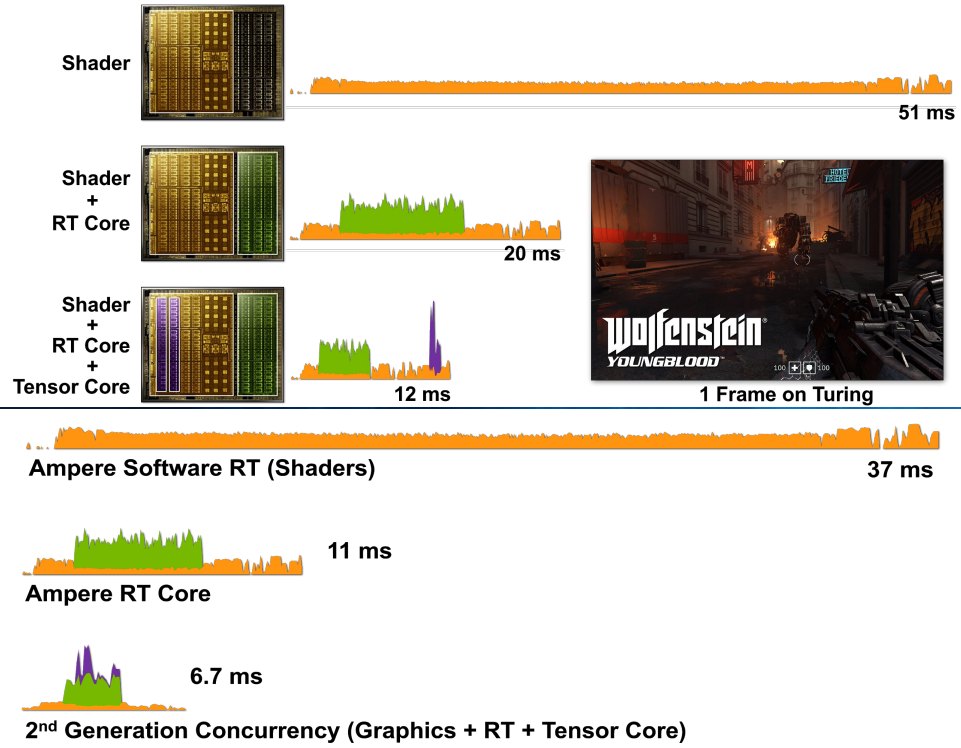
上:基於圖靈的RTX 2080超級GPU渲染Wolfenstein的一幀:僅使用著色器核心(CUDA核心)、著色器核心+RT核心和著色器核心+RT核心+張量核心的Youngblood。請注意,在新增不同的RTX處理核心時,幀時間逐漸減少。
下:基於安培體系結構的RTX 3080 GPU渲染一幀Wolfenstein:Youngblood僅使用著色器核心(CUDA核心)、著色器核心+RT核心和著色器核心+RT核心+張量核心。
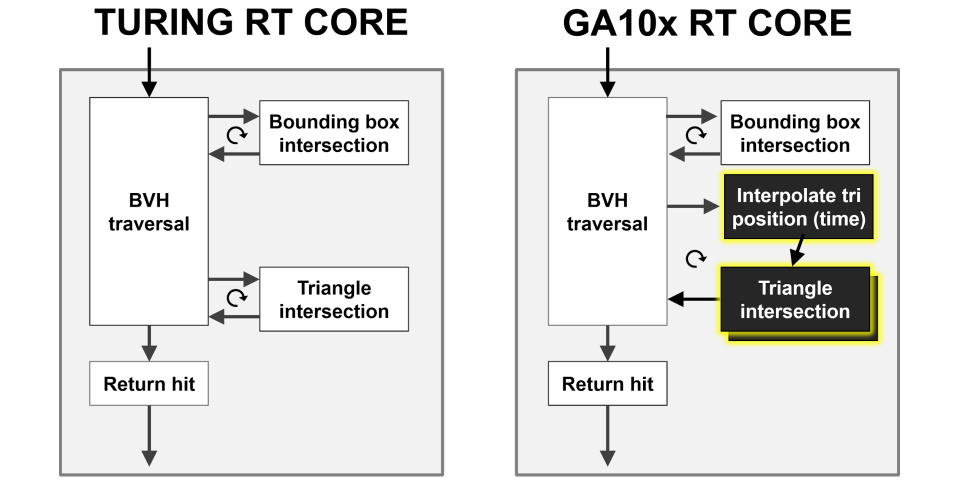
GA10x RT Core使光線/三角形相交測試速率比Turing RT Core提高了一倍,還新增了一個新的插值三角形位置加速單元,以協助光線跟蹤運動模糊操作。
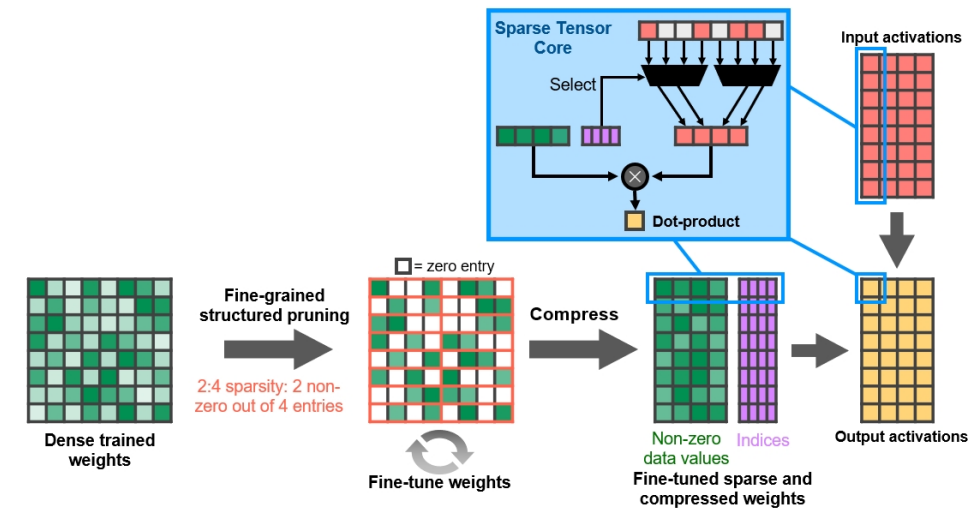
在啟用稀疏性的情況下,GeForce RTX 3080提供的FP16 Tensor堆芯操作峰值吞吐量是GeForce RTX 2080 Super的2.7倍,後者具有密集的Tensor堆芯操作:

細粒度結構化稀疏性使用四取二非零模式修剪訓練權重,然後是微調非零權重的簡單通用方法。對權重進行壓縮,使資料佔用和頻寬減少2倍,稀疏張量核心操作通過跳過零使數學吞吐量加倍。(下圖)
下圖顯示了GDDR6(左)和GDDR6X(右)之間的資料眼(data eye)比較,通過GDDR6X介面可以以GDDR6的一半頻率傳輸相同數量的資料,或者,在給定的工作頻率下,GDDR6X可以使有效頻寬比GDDR6增加一倍。
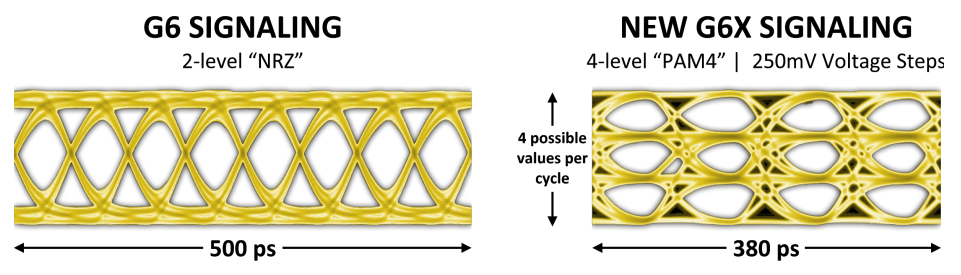
GDDR6X使用PAM4信令提高了效能和效率。
為了解決PAM4信令帶來的訊雜比挑戰,開發了一種名為MTA(最大傳輸消除,見下圖)的新編碼方案,以限制高速訊號的轉移。MTA可防止訊號從最高電平轉換到最低電平,反之亦然,從而提高介面訊雜比。它是通過在編碼管腳上傳輸的位元組中為每個管腳分配一部分資料突發(時間交錯),然後使用明智選擇的碼字將資料突發的剩餘部分對映到沒有最大轉換的序列來實現的。此外,還引入了新的介面培訓、自適應和均衡方案。最後,封裝和PCB設計需要仔細規劃和全面的訊號和電源完整性分析,以實現更高的資料速率。

在傳統的儲存模型中,遊戲資料從硬碟讀取,然後從系統記憶體和CPU傳輸,然後再傳輸到GPU,使得IO常常成為遊戲的效能瓶頸:
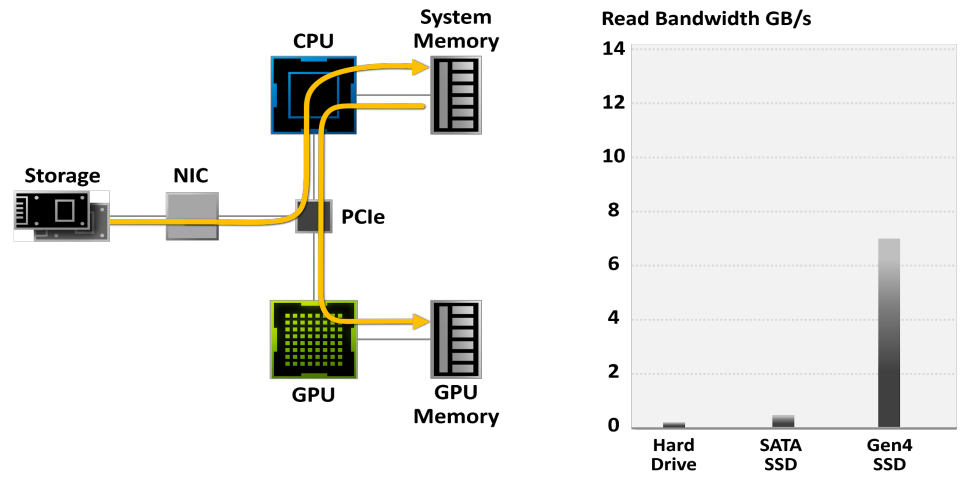
使用傳統的儲存模型,遊戲解壓縮可以消耗Threadripper CPU上的所有24個核心。現代遊戲引擎已經超過了傳統儲存API的能力。需要新一代的輸入/輸出體系結構。資料傳輸速率為灰色條,所需CPU核心為黑色/藍色塊。需要壓縮資料,但CPU無法跟上:
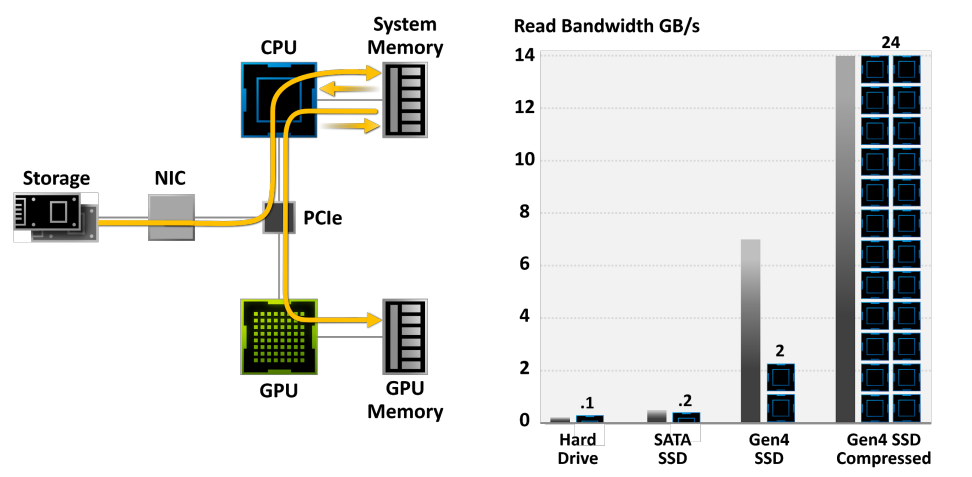
NVIDIA RTX IO插入Microsoft即將推出的DirectStorage API,這是一種新一代儲存體系結構,專為配備最先進NVMe SSD的遊戲PC和現代遊戲所需的複雜工作負載而設計。總之,專門為遊戲客製化的流線型和並行化API可以顯著減少IO開銷,並最大限度地提高從NVMe SSD到支援RTX IO的GPU的效能/頻寬。具體而言,NVIDIA RTX IO帶來了基於GPU的無失真解壓縮,允許通過DirectStorage進行的讀取保持壓縮,並傳送到GPU進行解壓縮。此技術可消除CPU的負載,以更高效、更壓縮的形式將資料從記憶體移動到GPU,並將I/O效能提高了兩倍。
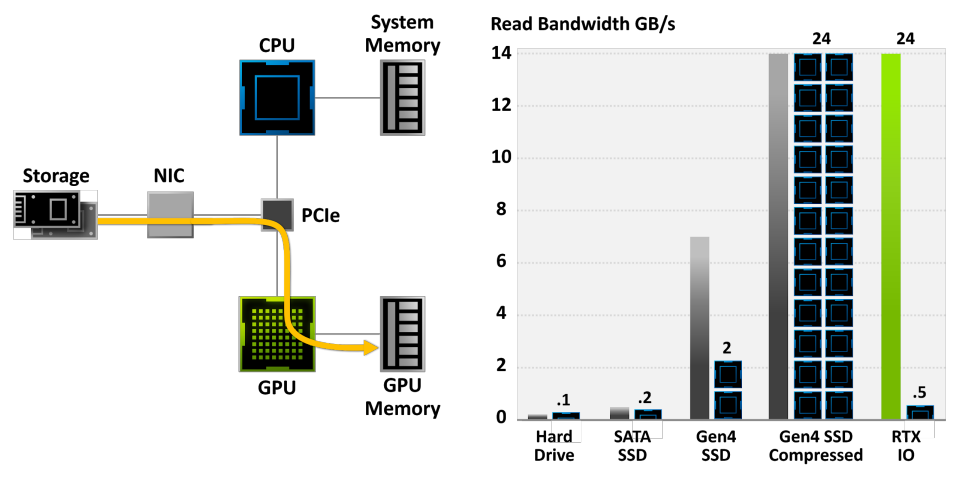
RTX IO提供100倍的吞吐量,20倍的CPU利用率。資料傳輸速率為灰色和綠色條,所需CPU核心為黑色/藍色塊。
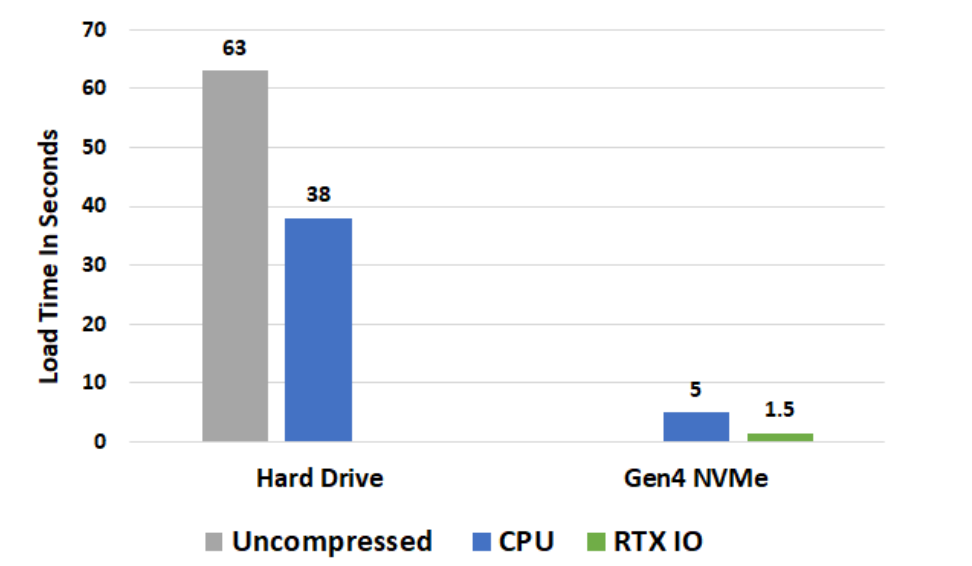
關卡載入時間比較。負載測試在24核Threadripper 3960x平臺上執行,原型Gen4 NVMe m.2 SSD,alpha軟體。
16.4.1.3 Nouveau
「Nouveau」是法語中「new」的意思。nouveau專案旨在為nVidia卡構建高質量、免費/自由的軟體驅動程式,Nouveau由Linux核心KMS驅動程式(Nouveau)、Mesa中的Gallium3D驅動程式和Xorg DDX(xf86 video Nouveau)組成,核心元件也已移植到NetBSD。官網是https://nouveau.freedesktop.org/index.html。
所有GPU均支援2D/3D加速(GA10x除外),大多數pre-Maxwell卡支援視訊解碼加速,在GM10x Maxwell、Kepler和Tesla G94-GT218 GPU上支援手動效能級別選擇。GM20x和更新的GPU重新鎖定的希望渺茫,因為如今韌體需要NVIDIA簽署才能獲得必要的存取許可權。最近的更新是2021年1月:Linux 5.11中合併了GA10x核心模式設定支援。
nouveau最初使用Mesa 3D的直接渲染基礎設施(DRI)渲染3D計算機圖形,允許直接從3D應用程式使用圖形處理單元(GPU)加速3D繪製;但在2008年2月,DRI支援方面的工作停止了,並轉移到了新的Gallium3D。2013年9月23日Nvidia公開宣佈,他們將釋出一些關於其GPU的檔案,旨在解決影響Nvidia GPU與nouveau的現成可用性的領域。2016年7月9日,Red Hat員工Ben Skeggs提交了一個修補程式,該修補程式將對GeForce GTX 1070和GeForce GTX 1080品牌圖形卡上基於Pascal的GP104晶片的支援新增到Linux核心中。XDC2016介紹了2016年的現狀和未來的工作,FOSDEM上顯示了OpenCL的新工作狀態。2019年,NVidia提供了一些有關開普勒、麥克斯韋、帕斯卡和沃爾塔晶片組的檔案。
除了nouveau,支援NVIDIA顯示卡的驅動還有pscnv、DirectFB nVidia driver、BeOS/Haiku nVidia driver、Utah-GLX、xfree 3.3.3 nvidia driver等。
2022年5月,NVIDIA釋放了支援最新NV GPU的Linux核心驅動模組,原始碼在:NVIDIA Linux Open GPU Kernel Module Source。
16.4.2 AMD
AMD Radeon軟體是一種用於高階Micro Devices圖形卡和APU的裝置驅動程式和實用軟體包。其圖形化使用者介面由Electron構建,並與64位元Windows和Linux發行版相容。
該軟體以前稱為AMD Radeon Settings、AMD Catalyst和ATI Catalyst。AMD Radeon軟體旨在支援GPU或APU晶片上的所有功能塊,除了用於渲染的指令程式碼外,還包括顯示控制器及其用於視訊解碼(統一視訊解碼器(UVD))和視訊編碼(視訊編碼引擎(VCE))的SIP塊。裝置驅動程式還支援AMD TrueAudio,是一個用於執行聲音相關計算的SIP塊。
Radeon軟體包括的功能:遊戲組態檔管理、超頻和降頻、效能監控、錄製和串流媒體、捕獲的視訊和螢幕截圖管理、軟體更新通知、升級advisor等。另外還支援多顯示器、視訊加速、音訊加速、電量節省、GPGPU、等功能,還支援D3D、Mantle、OpenGL、Vulkan、OpenCL等圖形API。
GCN通過結合硬體和驅動程式支援,與快取一致性一起引入了虛擬記憶體。虛擬記憶體消除了記憶體管理中最具挑戰性的方面,並提供了新的功能。AMD在高效能圖形和微處理器方面的獨特專長尤其有益,因為GCN的虛擬記憶體模型已被仔細定義為與x86相容。此舉簡化了初始產品中CPU和離散GPU之間的資料移動,更重要的是,它為CPU和GPU無縫共用的單個地址空間鋪平了道路。共用而非複製資料對於效能和能效至關重要,也是AMD加速處理單元(APU)等異構系統中的關鍵元素。
GCN命令處理器負責從驅動程式接收高階API命令,並將其對映到不同的處理管道。GCN有兩條主要管道。非同步計算引擎(ACE)負責管理計算著色器,而圖形命令處理器處理圖形著色器和固定功能硬體。每個ACE都可以處理並行的命令流和圖形命令處理器可以為每種著色器型別提供單獨的命令流,從而建立大量的工作來利用GCN的多工。
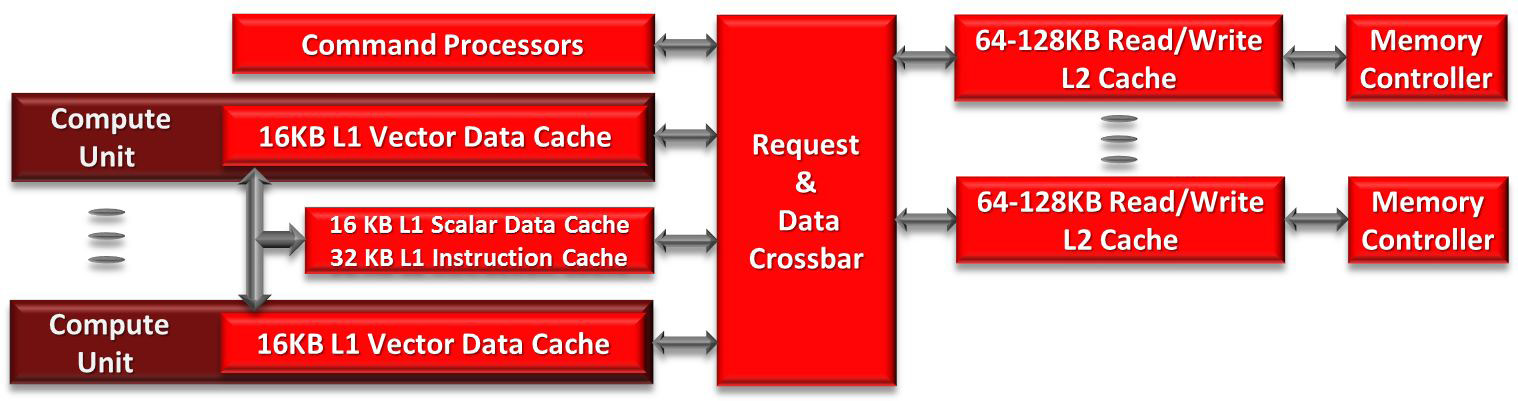
AMD GCN架構的快取層次結構。
16.4.3 Intel
下圖顯示了Intel圖形平臺上完整的功能棧所需的成分,以及每個元件的簡要說明。
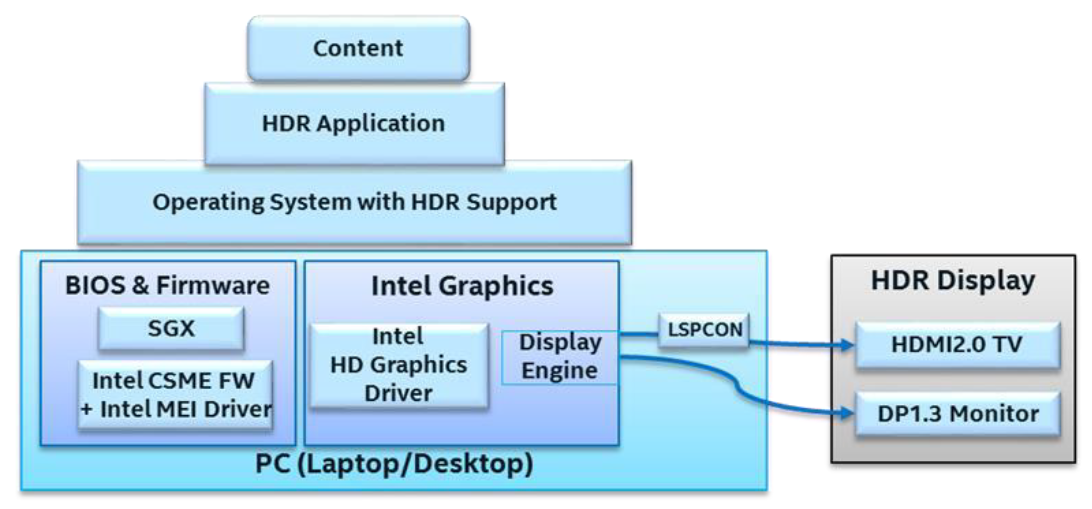
- Intel Graphics Controller:整合在第7代Intel Core處理器及更新版本中的圖形引擎硬體,用於解碼和呈現HDR內容。其顯示引擎通過HDMI和DisplayPort電纜將HDR訊號傳輸到HDR顯示器。
- Intel Graphics Driver:除上述相應的硬體外,還需要特定的驅動程式版本,始終建議獲取intel.com、PC OEM網站或通過Windows Update上釋出的最新圖形驅動程式。
- Operating System:Windows 10作業系統的適當版本,Windows 10 Fall Creators Update(RS3)是任何較新版本都適用的最低作業系統版本。
- LSPCON:要在第7代Intel Core處理器上通過HDMI實現HDR信令,主機板上必須有一個稱為LSPCON(電平移位器和協定轉換器)的額外硬體元件,是一種必須由PC製造商安裝的元件,終端使用者無法新增。注意,LSPCON僅適用於HDMI,而不適用於DisplayPort。在使用第9代Intel Core處理器或更高版本HDMI2的較新平臺中,原生支援2.0,因此不需要LSPCON支援。
- LSPCON FW:LSPCON上需要正確版本的FW。
- System BIOS:特別是對於超高清藍光播放,系統BIOS必須正確設定以支援Intel Software Guard Extensions(SGX)。
- Intel CSME FW:需要Intel Management Engine(ME)韌體版本才能實現必要的HW-DRM支援和HDCP2.2高階HDR視訊內容需要鏈路保護,通常包含在系統製造商擁有的系統BIOS中。
- Intel MEI Driver:必須安裝此驅動程式,以便軟體可以與ME FW通訊。
- Application:播放HDR內容需要特定的應用程式和internet瀏覽器(如Microsoft Edge)。
- Content:HDR視訊檔來自不同的來源,要從某些串流媒體提供商(如Netflix)接收HDR內容,必須具有適當的計劃/帳戶型別。
- HDR display:少數裝置的內建顯示器上提供了稱為擴充套件動態範圍(EDR)的部分HDR體驗,但筆記型電腦和平板電腦的內建顯示器尚無法實現真正的HDR播放。
- Display connector:電腦上連線到HDR顯示器的物理顯示介面(介面)可以是HDMI、DisplayPort、mini DisplayPort或USB Type-C。尋找HDCP2.2支援很重要,可將高階內容傳輸到顯示器所需的。
- Cable/ dongle:對於支援本機HDMI或DP聯結器的PC,可以直接使用適當的電纜連線到顯示器。如果PC帶有USB Type-C埠(支援Thunderbolt 3或DP Alt模式),則需要介面卡或加密狗將USB Type-C轉換為HDMI2.0或DisplayPort,以及支援HDCP2,miniDP聯結器也需要類似的介面卡,此類介面卡可從第三方供應商處獲得,如Club3D、BelkinUptab等。
另外,Intel Graphics Media Accelerator(GMA)是Intel於2004年推出的一系列整合圖形處理器,取代了早期的Intel Extreme Graphics系列,並由Intel HD和Iris Graphics系列取代,本系列面向低成本圖形解決方案市場。該系列產品整合在主機板上,圖形處理能力有限,並使用計算機的主記憶體而不是專用視訊記憶體進行儲存。它們通常出現在小筆電、低價筆記型電腦和臺式電腦上,以及不需要高水平圖形功能的商務電腦上。在2007年初,大約90%的PC主機板都有一個整合GPU。
16.4.4 Qualcomm
Freedreno是一個開源的逆向工程專案,為高通公司的Adreno圖形硬體實現了一個完全開源的驅動程式。Freedreno由MSM DRM驅動程式、xf86視訊Freedreno DDX和Mesa內部的Freedreno Gallium3D驅動程式組成。原始碼地址是https://github.com/freedreno/freedreno。
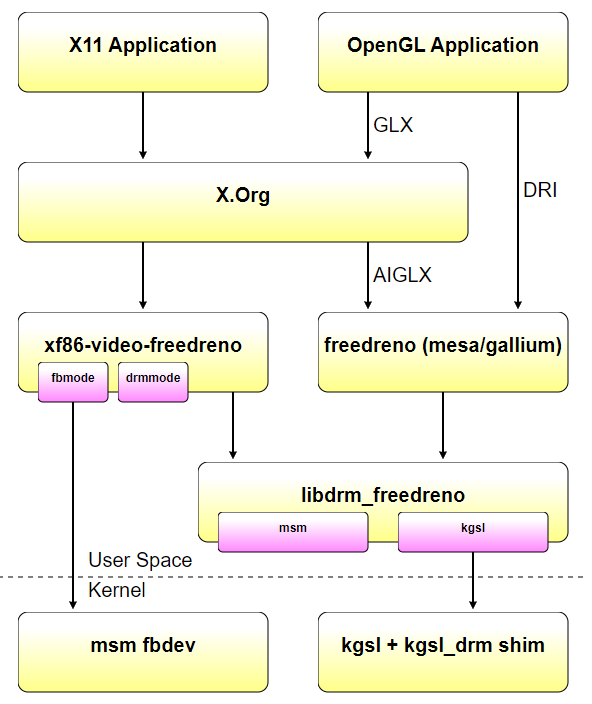
使用者空間元件可以在兩種模式下執行,要麼使用msm drm/kms核心驅動程式,要麼使用下游msm android樹中的msm fbdev+kgsl驅動程式。這樣做的主要目的是使在android裝置上使用freedreno更加容易,特別是因為msm drm/kms驅動程式尚未對手機/平板電腦上的LCD顯示器提供完整的DSI面板支援。(即使DSI支援在msm drm/kms中就位,仍然需要為每個不同型號的LCD面板編寫面板驅動程式。)
使用drm/kms驅動程式時,圖形堆疊看起來與任何其他開源桌面驅動程式(nouveau、radeon等)的圖形堆疊一樣:
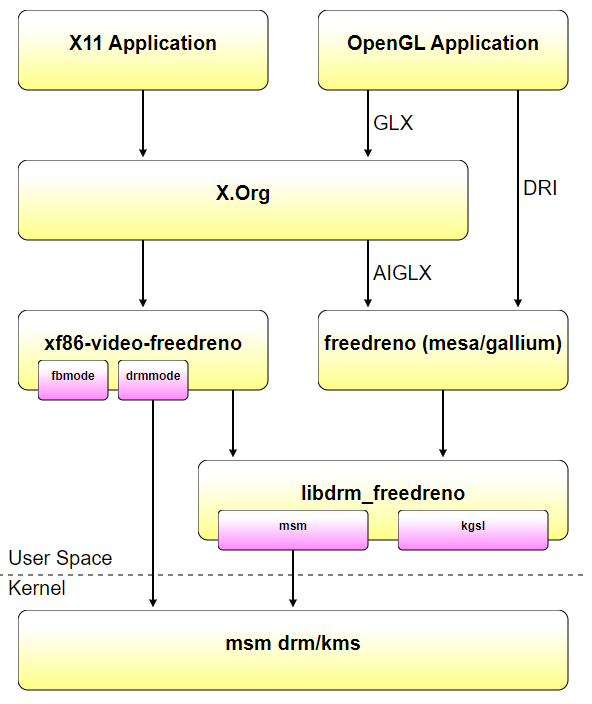
使用android fbdev/kgsl驅動程式時,堆疊幾乎相同,只是xf86 video freedreno中的fbmode_display模式設定程式碼和libdrm_freedreno中的kgsl後端被用來代替drmmode_display和msm後端。無需重新編譯任何使用者空間元件,xf86 video freedreno和libdrm_freedreno可以確定在執行時使用什麼。
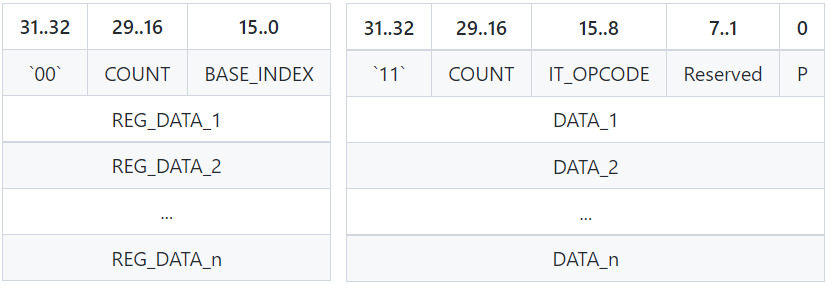
Command Processor (CP)是從ringbuffer(PM4命令流)讀取一系列渲染命令的塊,它可以設定一些暫存器值或觸發一些渲染操作,主要由Type-0(PKT0)和Type-3(PKT3)命令組成。Type-0 (PKT0)從BASE_INDEX指定的暫存器開始,將N個連續(32位元)DWORD寫入N個暫存器(下圖左),Type-3(PKT3)執行IT_OPCODE操作碼指定的操作(下圖右)。
與許多嵌入式/SoC GPU一樣,Adreno是一種基於Tile的體系架構,然而,其實現方式要簡單一些。大多數分塊器渲染小(32x32和/或64x64)分塊,硬體以某種方式對每個分塊的幾何體進行排序,通常忽略給定分塊的不可見表面。另一方面,Adreno有一個(相對)大的核心(GMEM)或片上(OCMEM)分塊緩衝區,大小從256KB到1MB不等。正在渲染的緩衝區分為「tile」或「bin」,顏色緩衝區和(如果啟用)深度/模板緩衝區可以在分塊緩衝區中容納。驅動程式完全負責每個tile/bin的繪製,以及恢復(將資料從系統記憶體移動到GMEM)和解析(將資料從GMEM移動到系統記憶體)。請注意,解析步驟可以通過多個通道用於多樣本解析。
最簡單的方法是建立CMD以設定狀態並執行清除/繪製,忽略tile,然後在頂級命令流緩衝區(提交給核心的內容)中,執行(可選)將每個tile設定、IB(分支)解析為清除/繪製命令,然後解析:
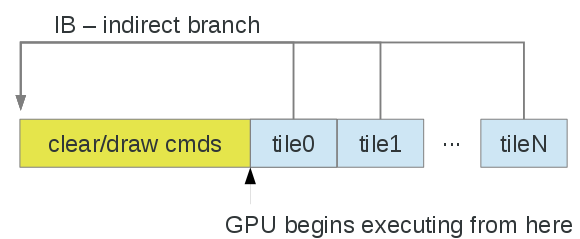
- 每個tile內的渲染效果與傳統IMR類似。
- 逐tile命令:
- 恢復——可選將內容從系統記憶體傳輸到tile緩衝區。
- 設定視窗偏移和螢幕剪下。
- IB清除/繪製渲染命令。
- 解析——將tile緩衝區傳輸到系統記憶體。
- 注意:命令流構建的順序與GPU執行的順序不同,並且恢復/解析也在清除/繪製中使用的一些GPU狀態暫存器,因此在驅動程式中需要注意在第一次清除/繪製之前將某些狀態物件標記為髒。
以上是gallium3D驅動程式中實現的內容,當存在少量幾何體和/或廉價的頂點著色器時,不一定是一個巨大的缺點。
上述的粗略的方法有一個缺點,即頂點著色器針對每個bin的每個頂點執行,但其實可以分為兩個過程以減少開銷。在第一個pass(「裝箱」過程)中,頂點被拆分為每個分塊箱,此資訊在第二個pass中用於限制為每個箱子處理的頂點。不需要在兩個過程上使用相同的頂點著色器,裝箱過程可以使用簡化的著色器,該著色器僅計算gl_Position / gl_PointSize。
注:以下注釋適用於a3xx,但a2xx應大致相似。
blob驅動程式為每個tile分配一個VSC_PIPE,共有八個管線,可以為一個管線分配多個tile,即可以使用四個管線來排列4x4個tile,如下所示:
# X, Y = upper-left tile coord of group of tiles mapped to pipe
# W, H = size of group in tiles, so below each pipe is mapped to
# a 2x2 group of tiles
VSC_PIPE[0].CONFIG: { X = 0 | Y = 0 | W = 2 | H = 2 }
VSC_PIPE[0x1].CONFIG: { X = 0 | Y = 2 | W = 2 | H = 2 }
VSC_PIPE[0x2].CONFIG: { X = 2 | Y = 0 | W = 2 | H = 2 }
VSC_PIPE[0x3].CONFIG: { X = 2 | Y = 2 | W = 2 | H = 2 }
對於每個管線,驅動程式設定管線緩衝區地址/大小( VSC_PIPE[p].DATA_ADDRESS和VSC_PIPE[p].DATA_LENGTH),為gpu提供了儲存可見性流資料的位置。大小緩衝區(VSC_SIZE_ADDRESS),一個4位元組 x 8個管線的緩衝區,GPU在其中儲存寫入每個管線緩衝區的資料量,在裝箱過程中用於控制將哪些頂點儲存到哪個管線。在渲染過程中,在每個tile的開始處,驅動程式將GPU設定為通過CP_SET_BIN_DATA封包使用來自管線p的資料(即適當的緩衝區大小/地址):
OUT_PKT3(ring, CP_SET_BIN_DATA, 2);
OUT_RELOC(ring, pipe[p].bo, 0); /* same value as VSC_PIPE[p].DATA_ADDRESS */
OUT_RELOC(ring, size_addr_bo, (p * 4)); /* same value as VSC_SIZE_ADDRESS + (p * 4) */
OUT_PKT0(ring, REG_A3XX_PC_VSTREAM_CONTROL, 1);
OUT_RING(ring, A3XX_PC_VSTREAM_CONTROL_SIZE(pipe[p].config.w * pipe[p].config.h) |
A3XX_PC_VSTREAM_CONTROL_N(n)); /* N is 0..(SIZE-1) */
OUT_PKT3(ring, CP_SET_BIN, 3);
OUT_RING(ring, 0x00000000);
OUT_RING(ring, CP_SET_BIN_1_X1(x1) | CP_SET_BIN_1_Y1(y1));
OUT_RING(ring, CP_SET_BIN_2_X2(x2) | CP_SET_BIN_2_Y2(y2));
與大多數/所有分塊器一樣,切換渲染目標代價高昂,會觸發重新整理。此外,至少對於freedreno gallium3D驅動程式,如果只渲染緩衝區的一部分,建議剪去緩衝區中不會被touch(讀或寫)的部分。gallium驅動程式可以使用此資訊調整tile邊界/大小,避免不必要的恢復(將資料從系統記憶體拉入GMEM)或解析(從GMEM寫回系統記憶體)。
對於指令集體系結構(Instruction Set Architecture,ISA),與a2xx著色器ISA不同,a3xx使用「簡單」標量指令集,但有一些技巧。編譯器需要更加了解排程和其他一些約束。每條指令為64位元(qword),有7種基本指令編碼或「類別」(在某些情況下有多個子編碼)。與a2xx一樣,沒有單獨的CF vs FETCH/ALU程式。但某些類別的指令是非同步執行的,需要特殊的同步來處理先讀後寫(或先讀後寫)。與a2xx不同的是,現在有完整和半(16位元)暫存器,它們都沒有重疊。指令不僅針對浮點,還針對整數。7種指令編碼描述如下:
-
類別0(cat0):通常採用零引數的流控制指令(有時帶有嵌入常數),例如:
nop、jump、branch。 -
類別1(cat1):移動/轉換的變體(單個源暫存器),此類指令沒有操作碼,儘管著色器助記符因src和目標型別而異。如果src和目標型別相同,則稱為移動:
mov.f16f16 Rdst, Rsrc- 從同一型別src和dst移動。cov.f32u16 Rdst, Rsrc- 從f32 src移動/轉換到u16 dst。mova- 是mov.f16f16定址到暫存器(a0)。(在所有情況下,src暫存器都可以是const)
-
類別2(cat2):普通ALU指令,通常帶有2個src暫存器,但在少數情況下,第2個src編碼會被忽略:
add.f Rdst, Rsrc0, Rsrc1and.b Rdst, Rsrc0, Rsrc1floor.f Rdst, Rsrc0- an example of cat2 which ignores the 2nd src.
-
類別3(cat3):三個src暫存器操作,例如:
mad.f16- src0 * src1 + src2sel.f32- src1 ? src0 : src2
-
類別4(cat4):與cat1-cat3相比,複雜的單src操作需要更多的週期(可能無法預測的數量)和/或更非同步:
rcp Rdst, Rsrclog2 Rdst, Rsrc
從cat4指令寫入的暫存器讀取的其他非cat4指令必須將(ss)位設定為與複雜alu管線同步。
-
類別5(cat5):一般紋理樣本相關說明:
sam (f32)(xyzw)Rdst, Rsrc0, Rsrc1, s#0, t#0isam (f32)(xyzw)Rdst, Rsrc0, Rsrc1, s#0, t#0samgq (f32)(xyzw)Rdst, Rsrc0, Rsrc1, s#0, t#0isam (f32)(xyzw)Rdst, Rsrc0, Rsrc1, Rsrc2
-
類別6(cat6):將指令載入/儲存到專用/本地/全域性記憶體、原子新增/訂閱/交換等,以及其他雜項指令。對opencl最有用。
在排程(Scheduling)上,編譯器負責在前一條指令的目標暫存器準備就緒之前考慮(指令排程)週期數。對於cat1-cat3指令,目標暫存器在三條指令之後可用,如果需要,編譯器負責插入nop指令。對於由cat4或cat5指令寫入的目標暫存器,(ss)或(sy)位可以設定為同步,因為與cat1-cat3不同,完成所需的週期數是不可預測的。特別是對於cat3指令,直到第二個週期才需要第三個src暫存器,因此,諸如DP4(點積)指令可以實現為:
; DP4 r0.x, r2.xyzw, r3.xyzw:
mul.f r0.x, r2.x, r3.x
nop
mad.f32 r0.x, r2.y, r3.y, r0.x
nop
mad.f32 r0.x, r2.z, r3.z, r0.x
nop
mad.f32 r0.x, r2.w, r3.w, r0.x
而不是需要兩個nop才能獲得前一條指令的結果,如果可能,編譯器當然可以在這些nop插槽中排程不相關的指令。寫入暫存器的指令以前是紋理樣本指令的src(WAR hazard),需要(ss)位集。
通常,簡單的if/else構造將被展開,執行分支的所有分支,然後使用sel指令有條件地寫回從流控制角度「獲取」的分支的結果。amonst執行緒的發散流控制通常很昂貴(即,硬體最終必須線上程組中一次執行一個執行緒),因此編譯器通常會盡量避免這種情況。(目前,if/else是用gallium驅動程式中的分支實現的,僅僅是因為編譯器不夠聰明,不知道如何將其展開。)當需要分支時,可以使用cat0指令來實現它們,例如,可以通過以下方式實現if/else:
cmps.f.eq p0.x, hr1.x, hc2.x
br p0.x, #6
mov.f16f16 hr1.x, hc2.x
mov.f16f16 hr1.y, hc2.y
mov.f16f16 hr1.z, hc2.x
mov.f16f16 hr1.w, hc2.y
jump #6
(jp)nop
mov.f16f16 hr1.x, hc2.y
mov.f16f16 hr1.y, hc2.x
mov.f16f16 hr1.z, hc2.x
mov.f16f16 hr1.w, hc2.y
(jp)nop
請注意,分支目標指令上設定了(jp)(跳轉目標)標誌,可能有助於執行緒排程器找出潛在的聚合點,跳轉目標不必是nop。分支可以是向前(正)或向後(負)立即偏移。
分組通道結束後,沒有更多要插入或刪除的指令。從深度通道建立的深度排序列表中最深的節點開始排程每個基本塊,遞迴地嘗試在每個指令的源指令加上延遲槽之後排程每個指令,根據需要插入NOP。
在指令中使用const src引數有一些限制,在某些情況下,編譯器需要將const移動到GPR中。已知的限制包括:
- cat2最多可以使用一個常數src(但可以在任意位置)。
- cat3不能將常數src作為第二個引數(src1)。
- cat4不能接受常數src。
16.4.5 其它
此外,還有其它平臺的驅動:
-
Vidix:是一種適用於類Unix作業系統的行動式程式設計介面,它允許在使用者空間中執行的視訊卡驅動程式通過X Window系統的直接圖形存取擴充套件直接存取幀緩衝區。
-
MPLAB:MPLAB Harmony Graphics Suite是MPLAB生態系統的擴充套件,用於為32位元微晶片裝置建立嵌入式圖形韌體解決方案。
-
MiniGLX:是一種應用程式程式設計介面規範,有助於在沒有視窗系統的系統上進行OpenGL渲染,例如,沒有X視窗系統的Linux或沒有視窗系統的嵌入式系統。該介面是GLX介面的子集,加上一組最小的Xlib類函數。
16.5 圖形驅動應用
16.5.1 視訊與合成
在執行GFX/視訊播放用例(應用程式的視訊流型別)時,檢視影響英特爾體系結構下UI體驗的特定穩定性問題,行為是凍結一個UI,然後是一個黑畫面,然後是系統重新啟動(當然是在一段隨機的時間間隔之後)。
如果3D使用者端應用程式「掛起」GPU,則GPU程序可能會被終止,然後GPU會完全重置。對於複雜的用例,如視訊解碼,許多幀/物件當前處於執行狀態,因此終止GPU程序並重置GPU會導致不受歡迎的效果。
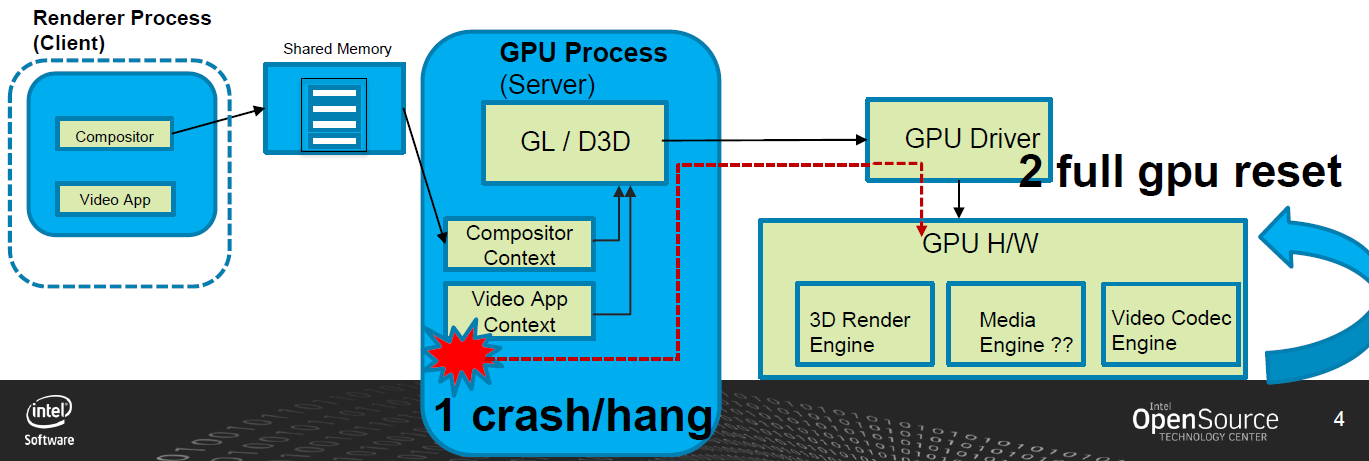
建議的解決方案:超時檢測和恢復(Timeout Detection & Recovery,TDR)。Intel GPU的新功能(上游為wip),允許應用程式在單個批次處理緩衝區上啟用掛起檢測,從而提高穩定性和魯棒性。超時檢測和恢復(TDR)允許獨立重置GPU中的不同引擎(而不是完全重置GPU)。一般來說,這些實現在i915驅動程式中引入了一個新的IRQ處理程式,以及在gpu的環形緩衝區中發出的批次處理緩衝區的啟動指令之前和之後引入了兩個新的gpu命令指令。TDR的步驟如下:
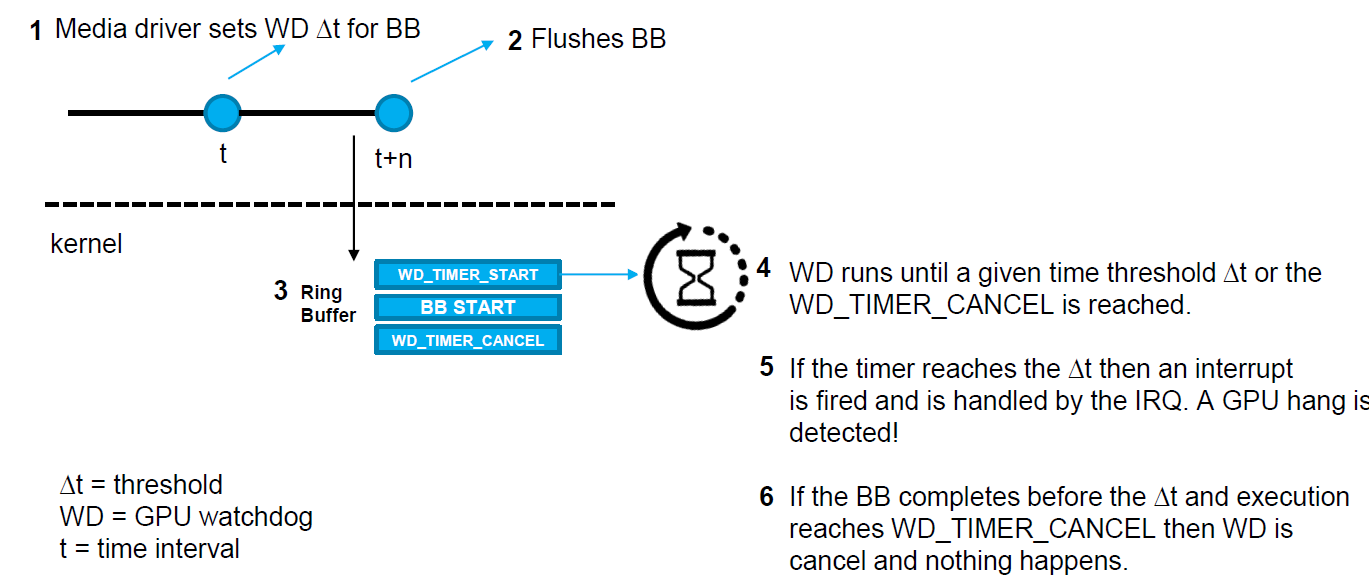
建議的解決方案:
1、UMD媒體驅動程式在傳送批緩衝區後啟動定時器。
2、計時器過期後,檢測到媒體引擎處於掛起狀態。
3、GPU驅動程式僅重置受影響的媒體引擎。
4、由於UMD媒體驅動程式知道提交錯誤批次的時間,因此可以在媒體驅動程式從重置中恢復的時間內採取措施。
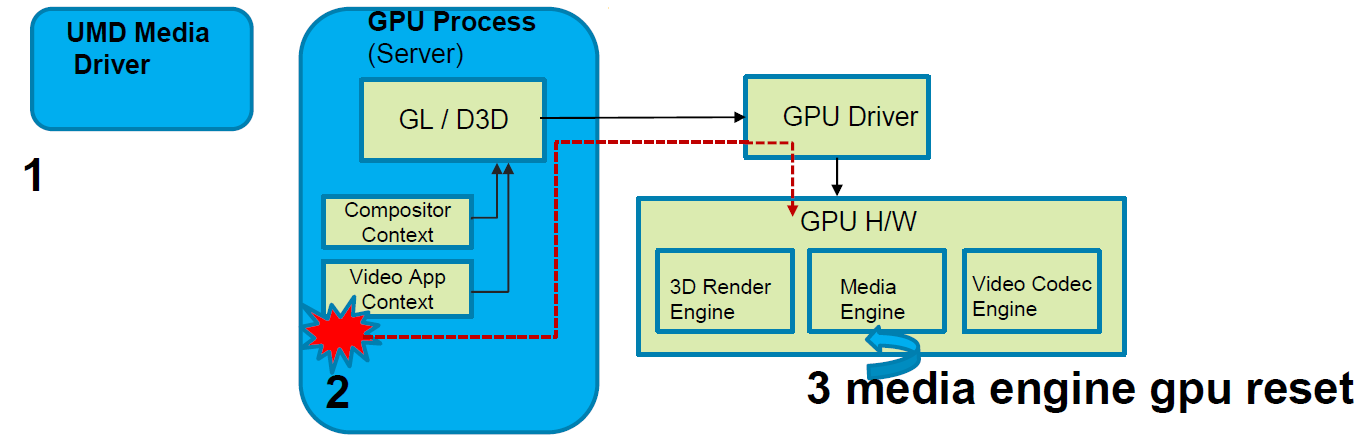
整個機制通過任意閾值工作,該閾值可以通過ioctl從應用程式設定。但閾值不能太低,否則會產生太多誤報。
合成器(compositor)如何受益?結合下圖加以回答:
1、合成器的基本任務是生成幀。
2、過去,當我們檢測到GPU掛起時,合成器恢復(螢幕凍結、綠色或黑色螢幕或系統重新啟動)為時已晚。
3、視訊使用者端應用程式現在可以早期確定「任務」是否導致媒體引擎崩潰,如果是,則向合成器標記以顯示當前幀,同時媒體引擎從重置中返回。

16.5.2 Rocksolid
Rocksolid最初是GPU基準產品的引擎,後來發展成為一個獨立的產品。除了客戶需求之外,該開發仍然與基準開發緊密相關。輕量級渲染/計算引擎主要針對非遊戲用途,從小型嵌入式系統擴充套件到現代桌面級硬體。它不是一個成熟的遊戲引擎,但它的開銷比大型現代遊戲引擎低得多,也更容易客製化,更穩定,並且可以通過獲得安全認證。下圖是Rocksolid引擎的架構圖,由此可知,它可以直接存取裝置驅動,從而提升效能。
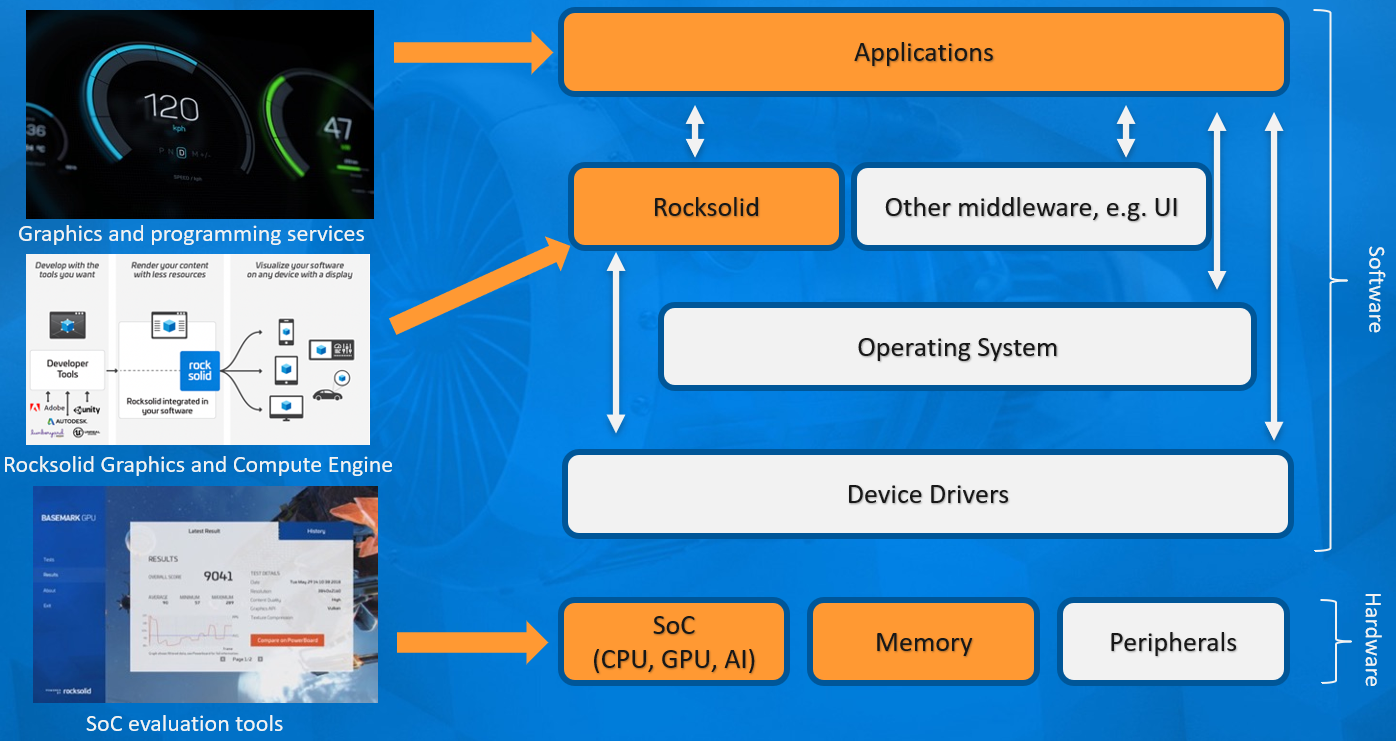
圖形管線是一種非常好的執行方式,例如影象處理任務。在許多硬體中,如果問題自然對映到全螢幕光柵化過程,則將其作為圖形管道而不是計算管道執行會更快。在一個工業客戶案例中,Rocksolid被用於提供GPU加速的影象處理管道。與原始OpenCL版本相比,目標硬體的速度快了好幾倍。
在OpenGL中,Rocksolid引擎只是在拓撲排序中執行記錄的節點命令列表。在Vulkan中,每個使用的命令佇列都有一個提交執行緒。目前,預設設定只是一個命令佇列,所以只有一個提交執行緒。提交執行緒連續執行。當提交執行緒仍在推播命令時,程式的其餘部分可以準備下一幀。Vulkan的CPU可見資源由簡單的迴圈圍欄系統保護。
16.5.3 I/O驅動
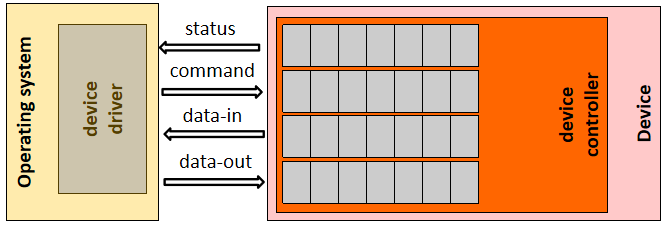
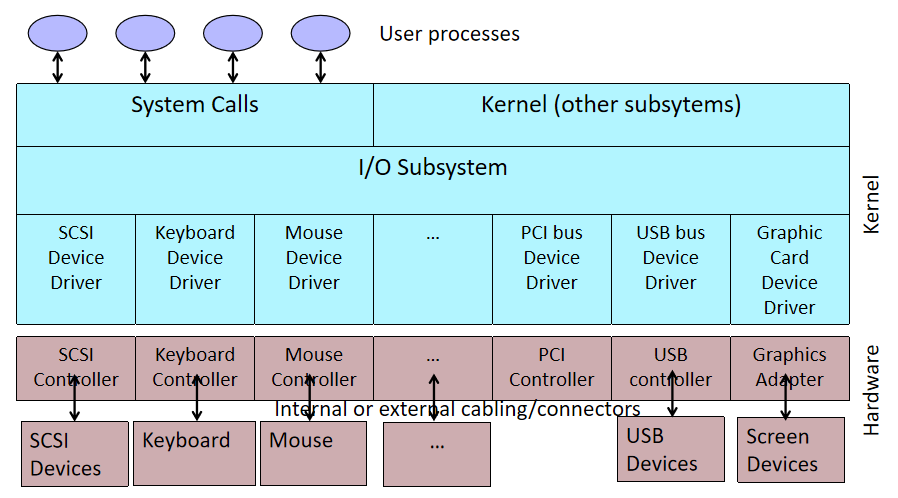
將應用程式的輸入/輸出請求轉換為裝置的低階命令,並將其傳送給裝置控制器,獲取輸入/輸出裝置的響應並將其傳送到應用程式。
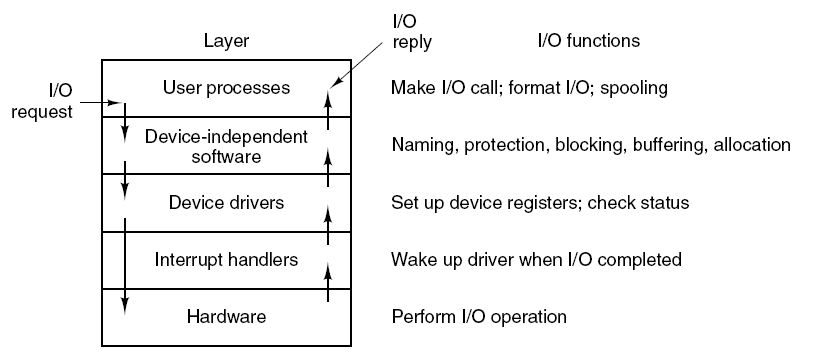
輸入/輸出系統的各層以及各層的主要功能。
如何在硬體中存取IO呢?步驟如下:
- 作業系統需要向裝置控制器傳送/接收命令和控制以完成輸入/輸出。
- 裝置控制器有一個或多個用於控制和資料的暫存器。
- 處理器通過讀/寫這些暫存器與控制器通訊。
- 如何定址這些暫存器?
- 基於記憶體的I/O。
- 基於埠的輸入/輸出。
- 混合輸入/輸出。
記憶體對映/基於埠/混合的IO的方式如下圖:
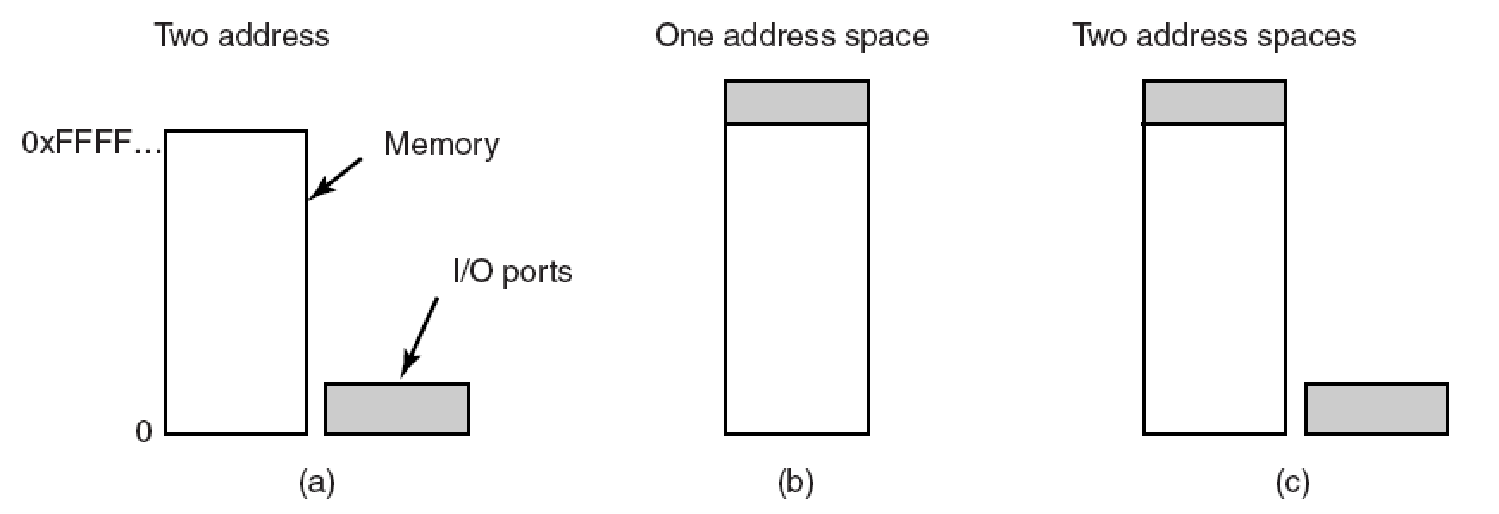
(a)特殊CPU指令(輸入/輸出)。(b)記憶體對映:為硬體輸入/輸出暫存器保留記憶體區域。標準記憶體指令會更新它們。(c)混合:一些控制器對映到記憶體,一些使用I/O指令。
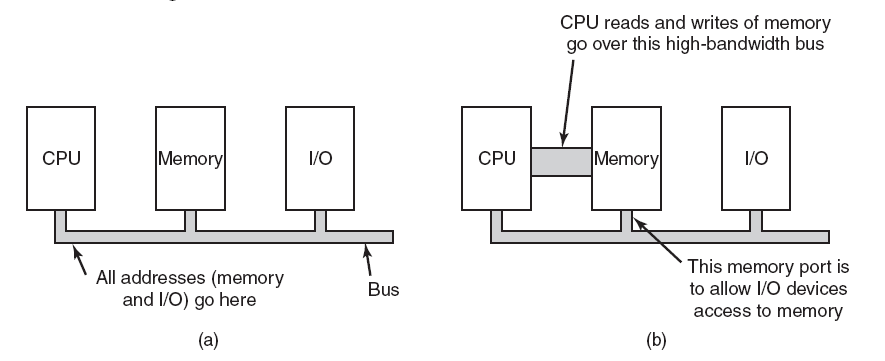
單匯流排和雙匯流排IO。(a)記憶體對映I/O只有一個地址空間,記憶體對映I/O更易於實現和使用。幀緩衝區或類似裝置更適合於記憶體對映的I/O。(b)基於埠的I/O有兩個地址空間:一個用於記憶體,一個用於埠。雙匯流排允許並行讀/寫資料和裝置。
單匯流排和雙匯流排更詳細的對比圖如下:
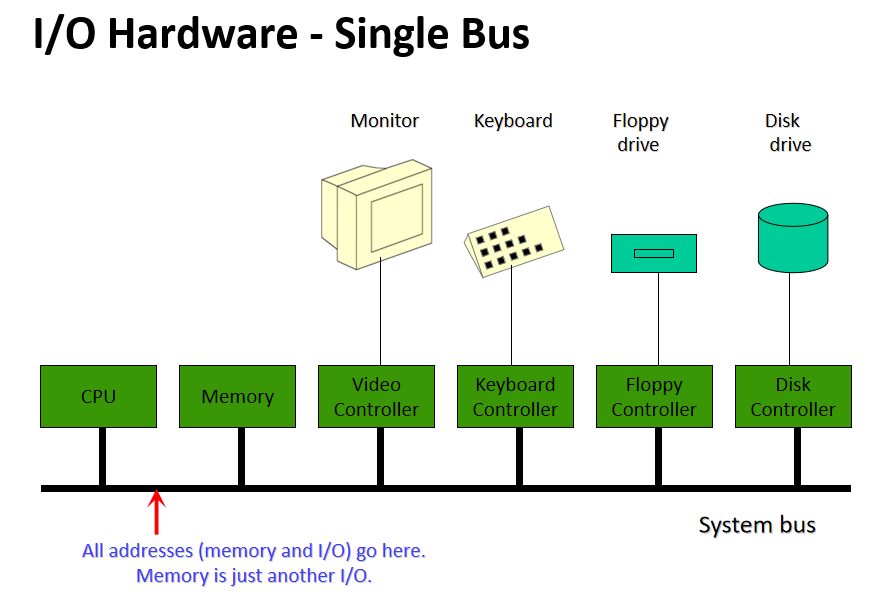
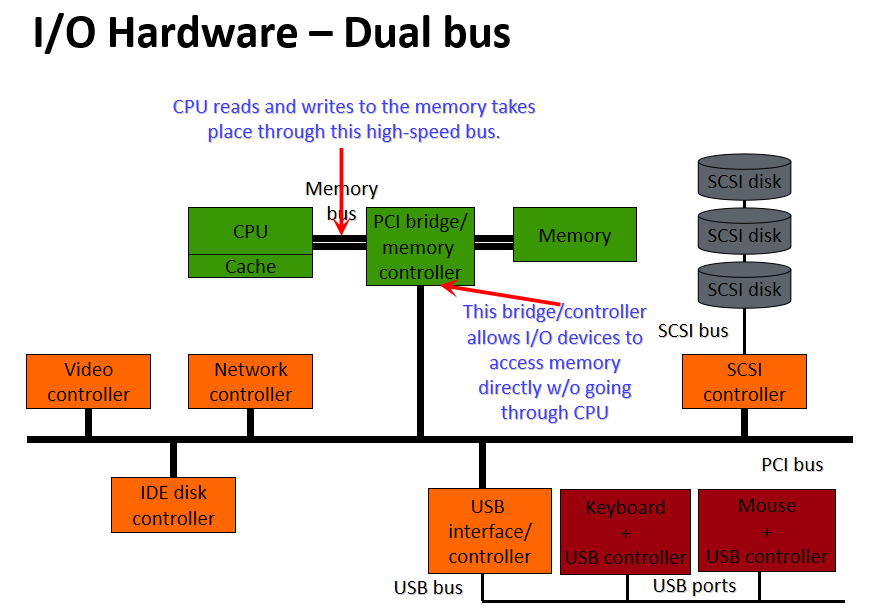
匯流排:元件(包括CPU)之間的互連,可以連線多個裝置:
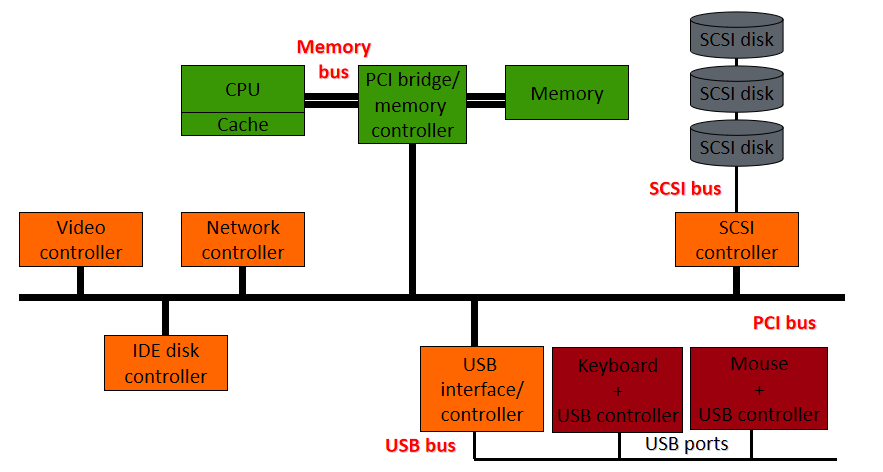
埠:僅插入一個輸入/輸出裝置的介面:
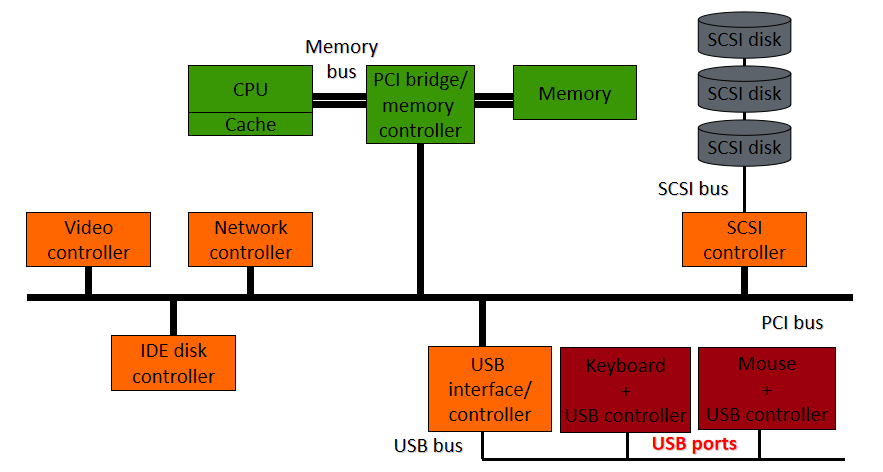
裝置控制器:將物理裝置連線到系統匯流排/埠:
每個裝置都有一個裝置控制器和一個裝置驅動程式來與作業系統通訊,裝置驅動程式是可以插入作業系統以處理特定裝置的軟體模組,裝置控制器用作裝置和裝置驅動程式之間的介面,裝置控制器可以處理多個裝置。作為一個介面,它的主要任務是將序列位流轉換為位元組塊,並根據需要執行糾錯。
IO埠暫存器有狀態暫存器(由host讀取)、命令暫存器(由host寫入)、暫存器中的資料(由host讀取以獲取輸入)、資料輸出暫存器(由host寫入以傳送輸出)。
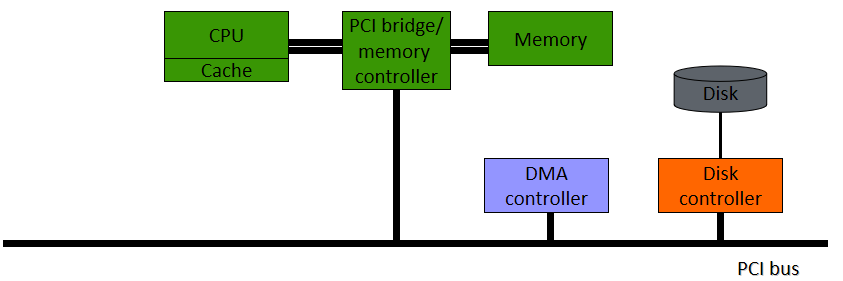
直接記憶體存取(Direct Memory Access,DMA):對於進行大型傳輸的裝置,如磁碟驅動器,使用昂貴的通用處理器來監視狀態位並將資料一次輸入1位元組的控制器暫存器,似乎是一種浪費——這一過程稱為程式設計輸入/輸出。基於中斷的I/O不是一種補救方法,因為每個位元組都會建立一個到中斷處理程式例程的上下文開關。在基於輪詢和基於中斷的I/O中,所有位元組都需要通過CPU,並且輸入/輸出裝置<->CPU<->記憶體有很多開銷。如果我們可以將這個平凡的任務解除安裝到一個特殊用途的處理器上,該處理器可以將資料從輸入/輸出裝置直接移動到記憶體中,那就太好了!這就是直接記憶體存取(DMA)控制器。
要啟動DMA傳輸,host將DMA命令塊寫入記憶體。指向傳輸源的指標,指向傳輸目標的指標,以及要傳輸的位元組數的計數。CPU將此命令塊的地址寫入DMA控制器,然後繼續其他工作。DMA控制器繼續直接操作記憶體匯流排,在匯流排上放置地址以執行傳輸,而無需主CPU的幫助。簡單的DMA控制器是PC中的標準元件,PC的匯流排主控輸入/輸出板通常包含自己的高速DMA硬體。使用DMA的IO範例:
/* Code executed when the print system call is made */
copyFromUser(buffer, p, count);
setupDMAController();
scheduler();
/* Interrupt Service Routine Procedure for the printer */
acknowledgeInterrupt();
unblockUser();
returnFromInterrupt();
請注意,中斷是每個I/O任務生成一次,而不是每個位元組生成一次(在基於中斷的I/O情況下)。
IO硬體介面:裝置驅動程式被告知將磁碟資料傳輸到地址X處的緩衝區,裝置驅動程式告訴磁碟控制器將C位元組從磁碟傳輸到地址X處的緩衝區,磁碟控制器啟動DMA傳輸,磁碟控制器將每個位元組傳送到DMA控制器,DMA控制器將位元組傳輸到緩衝區X,遞增記憶體地址,遞減C直到0,當C==0時,DMA中斷CPU以完成訊號傳輸。
應用程式IO介面如下圖所示:
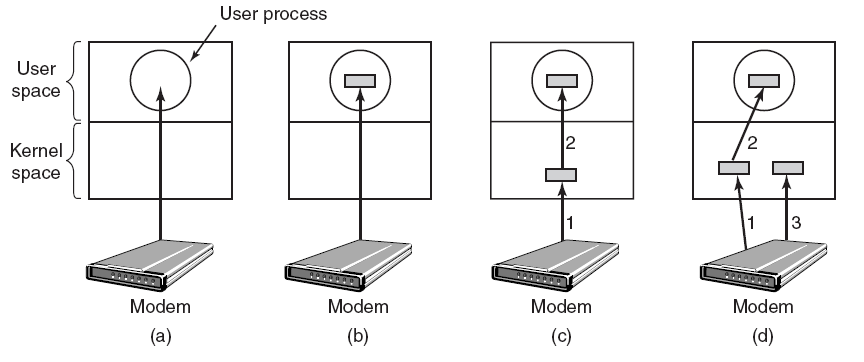
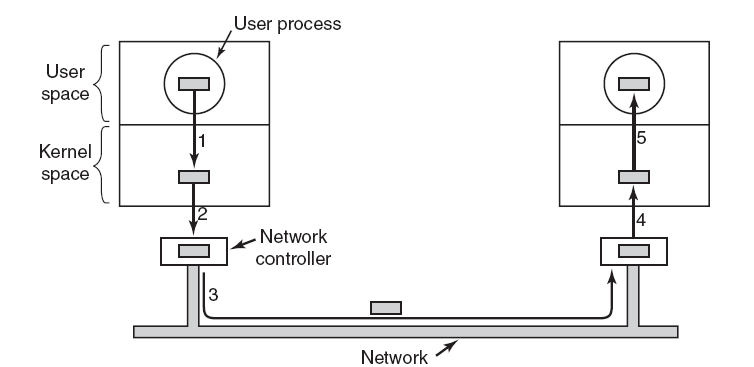
連線到計算機的每個輸入/輸出裝置都需要一些特定於裝置的程式碼來控制它。裝置製造商編寫,每個作業系統都需要自己的裝置驅動程式,每個裝置驅動程式都支援特定型別或類別的輸入/輸出裝置。滑鼠驅動程式可以支援不同型別的滑鼠,但不能用於網路攝像頭。作業系統定義了驅動程式的功能以及它如何與作業系統的其餘部分互動。裝置驅動程式具有多個功能,要接受來自其上方獨立於裝置的軟體的抽象讀寫請求,並確保執行這些請求,裝置初始化,管理is電源需求和紀錄檔事件。
Microsoft Windows使用檔案系統上的裝置快捷方式來定址裝置,裝置存取API為應用程式程式設計師提供了一個介面,以檢查裝置並與之互動,Windows裝置框架為裝置驅動程式開發提供了使用者和核心介面。輸入/輸出分類(作業系統視角)有:
- 字元流和塊。
- 順序存取與隨機存取。裝置驅動程式允許查詢裝置中的偏移量。
- 同步與非同步。裝置驅動程式上的I/O操作與裝置控制器上的I/O完成同步,非同步I/O更早返回,稍後報告成功/失敗。
- 緩衝和直接。報告的操作結果在緩衝區或裝置控制器上完成。
- 共用或專用。每個裝置範例上的I/O是互斥的。(即印表機)
- 唯讀、只寫、讀寫。
核心提供了許多與I/O相關的服務:排程、緩衝、快取、池化、裝置保留及錯誤處理,基於硬體和裝置驅動程式基礎架構構建。
IO排程用來排程一組I/O請求,意味著確定執行它們的良好順序。作業系統開發人員通過維護每個裝置的請求佇列來實現排程,當應用程式發出阻塞I/O系統呼叫時,該請求將被置於該裝置的佇列中。I/O排程器重新排列佇列的順序,以提高總體系統效率和應用程式的平均響應時間。輸入/輸出通常很慢,一些裝置的物理特性需要優化,例如硬碟——由磁頭移動和旋轉引起的機械裝置和延遲。如果在FIFO策略中執行輸入/輸出,機械之字形運動可能會否決輸入/輸出操作。I/O排程獲取裝置上的一組I/O請求,並確定在裝置上執行請求的最佳順序和時間。當多個任務競爭要處理的I/O請求時,排程變得複雜。
塊裝置操作與虛擬記憶體和分頁緊密耦合,一些幀用作頁面快取,並將塊裝置的資料儲存在系統中。塊裝置中的輸入/輸出:搜尋塊是否已在頁快取中(實體記憶體中):如果找到現有幀的讀/寫緩衝區,否則,分配一個幀,將裝置塊讀取到幀中,將幀標記為快取裝置塊對 從此幀讀取/寫入緩衝區。髒頁定期寫入塊裝置,顯著加快I/O操作,尤其是檔案系統後設資料操作。
頁面快取思想還與記憶體對映的I/O相結合,mmap()檔案採用類似的機制。程序的虛擬記憶體對映作為檔案(而不是塊裝置)備份的頁,更改會在記憶體上更新,快取的幀會定期在磁碟上強制執行。VM系統跟蹤頁面和檔案快取以及其他(常駐和免費)頁面的幀,VM系統根據系統的記憶體狀態調整檔案和裝置快取的大小。
緩衝區是在兩個裝置之間或裝置與應用程式之間傳輸資料時儲存資料的儲存區域。進行緩衝有三個原因:
-
處理資料流的生產者和消費者之間的速度不匹配。通過介面卡接收檔案以儲存在硬碟上。
(a) 無緩衝輸入。(b) 使用者空間中的緩衝。(c)在核心中進行緩衝,然後複製到使用者空間。(d) 核心中的雙緩衝。
-
在具有不同資料傳輸大小的裝置之間進行調整。網路:訊息通常在傳送和接收過程中被分割。
聯網可能涉及一個封包的多個副本。
-
支援應用程式I/O的複製語意。應用程式呼叫write()系統呼叫,提供指向緩衝區的指標和指定要寫入的位元組數的整數。系統呼叫返回後,如果應用程式更改緩衝區的內容,會發生什麼情況?在處理write()系統呼叫時,作業系統會將應用程式資料複製到核心緩衝區,然後再將控制權返回給應用程式。磁碟寫入是從核心緩衝區執行的,因此對應用程式緩衝區的後續更改不會產生任何影響。
快取在I/O級別完成,以提高I/O效率。緩衝區和快取之間的區別在於,緩衝區可能只儲存資料項的現有副本,而快取根據定義,只儲存位於其他位置的項的更快儲存上的副本。快取和緩衝是不同的功能,但有時一個記憶體區域可以用於這兩個目的。例如,為了保留拷貝語意並實現磁碟I/O的高效排程,作業系統使用主記憶體中的緩衝區來儲存磁碟資料。
輸入/輸出軟體通常分為四層,每個層都有一個定義良好的介面。
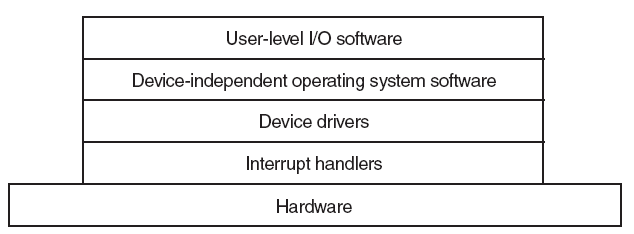
下面是有(右)無(左)標準驅動介面的對比圖:
16.5.4 UE圖形驅動
雖然原則上應用層不應該關心驅動層和GPU的細節,但往往事與願違,眾多的GPU、系統、圖形API、版本造就了眾多的驅動程式版本,它們之間可能存在一些奇奇怪怪的問題,而驅動程式有著很長的供應鏈路,修復問題的週期往往比較漫長。作為應用程式開發者,肯定不能坐以待斃,需主動解決或規避。UE提供了有限的介面和型別,為我們提供了一些資訊,從而可以讀取GPU或驅動的資訊。相關的主要介面:
// GenericPlatformDriver.h
// 視訊驅動細節
struct FGPUDriverInfo
{
uint32 VendorId; // DirectX供應商ID,0如果未設定,請使用以下函數設定/獲取
FString DeviceDescription; // e.g. "NVIDIA GeForce GTX 680" or "AMD Radeon R9 200 / HD 7900 Series"
FString ProviderName; // e.g. "NVIDIA" or "Advanced Micro Devices, Inc."
FString InternalDriverVersion; // e.g. "15.200.1062.1004"(AMD), "9.18.13.4788"(NVIDIA)
FString UserDriverVersion; // e.g. "Catalyst 15.7.1"(AMD) or "Crimson 15.7.1"(AMD) or "347.88"(NVIDIA)
FString DriverDate; // e.g. 3-13-2015
FString RHIName; // e.g. D3D11, D3D12
FGPUDriverInfo();
bool IsValid() const;
FString GetUnifiedDriverVersion() const;
bool IsAMD() const { return VendorId == 0x1002; }
bool IsIntel() const { return VendorId == 0x8086; }
bool IsNVIDIA() const { return VendorId == 0x10DE; }
(...)
};
// GPU硬體資訊
struct FGPUHardware
{
// 驅動資訊
const FGPUDriverInfo DriverInfo;
FGPUHardware(const FGPUDriverInfo InDriverInfo);
FString GetSuggestedDriverVersion(const FString& InRHIName) const;
FBlackListEntry FindDriverBlacklistEntry() const;
bool IsLatestBlacklisted() const;
const TCHAR* GetVendorSectionName() const;
(...)
};
// GenericPlatformMisc.h
struct CORE_API FGenericPlatformMisc
{
// 獲取GPU驅動資訊
static struct FGPUDriverInfo GetGPUDriverInfo(const FString& DeviceDescription);
(...)
};
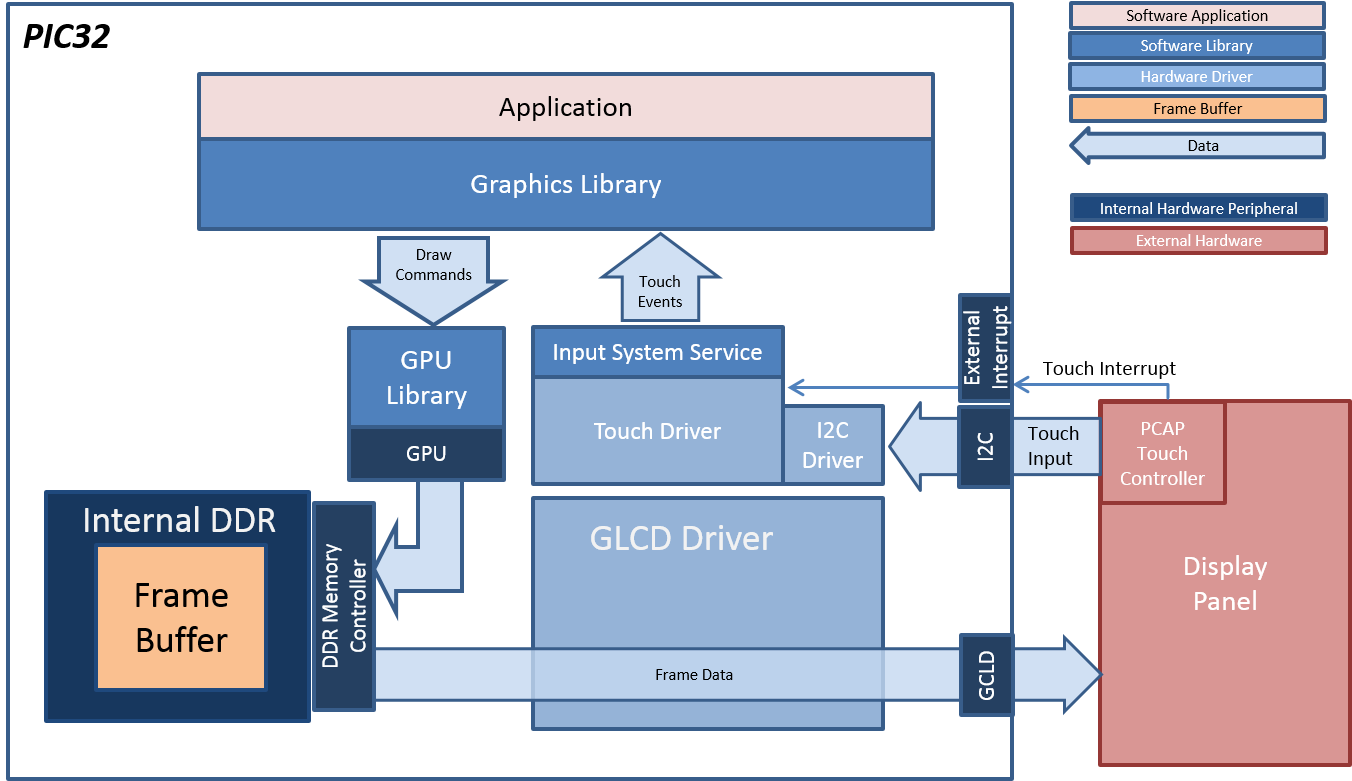
有了以上介面,就可以方便地在渲染層、遊戲邏輯層獲取驅動資訊以執行鍼對性的操作。
除了GPU驅動,還可以存取圖形API的驅動,常出現在各個圖形API的RHI實現中,例如Android Vulkan:
// AndroidPlatformMisc.cpp
bool FAndroidMisc::HasVulkanDriverSupport()
{
(...)
// this version does not check for VulkanRHI or disabled by cvars!
if (VulkanSupport == EDeviceVulkanSupportStatus::Uninitialized)
{
// assume no
VulkanSupport = EDeviceVulkanSupportStatus::NotSupported;
VulkanVersionString = TEXT("0.0.0");
// check for libvulkan.so
void* VulkanLib = dlopen("libvulkan.so", RTLD_NOW | RTLD_LOCAL);
if (VulkanLib != nullptr)
{
UE_LOG(LogAndroid, Log, TEXT("Vulkan library detected, checking for available driver"));
// if Nougat, we can check the Vulkan version
if (FAndroidMisc::GetAndroidBuildVersion() >= 24)
{
extern int32 AndroidThunkCpp_GetMetaDataInt(const FString& Key);
int32 VulkanVersion = AndroidThunkCpp_GetMetaDataInt(TEXT("android.hardware.vulkan.version"));
if (VulkanVersion >= UE_VK_API_VERSION)
{
// final check, try initializing the instance
VulkanSupport = AttemptVulkanInit(VulkanLib);
}
}
else
{
// otherwise, we need to try initializing the instance
VulkanSupport = AttemptVulkanInit(VulkanLib);
}
dlclose(VulkanLib);
if (VulkanSupport == EDeviceVulkanSupportStatus::Supported)
{
UE_LOG(LogAndroid, Log, TEXT("VulkanRHI is available, Vulkan capable device detected."));
return true;
}
else
{
UE_LOG(LogAndroid, Log, TEXT("Vulkan driver NOT available."));
}
}
else
{
UE_LOG(LogAndroid, Log, TEXT("Vulkan library NOT detected."));
}
}
return VulkanSupport == EDeviceVulkanSupportStatus::Supported;
}
16.6 本篇總結
本篇主要闡述了圖形渲染體系的驅動部分,包含它的概念、技術、架構、機制和相關的硬體部件。
在PC上,開發者可以要求使用者更新其驅動程式,這樣做相對容易。在移動裝置上,驅動需要在多個階段獲得認證,從硬體供應商到客戶的鏈條很長,這樣做既昂貴又緩慢,錯誤修復和新功能可能需要數月時間,意味著bug修復可能需要很長時間才能進入使用者的手中。在較舊/低端裝置上,它們可能永遠不會到來。目前正在努力改進這一點,但如果看到驅動程式錯誤,行業從業者準備解決它。這一情況正在好轉(但程序緩慢)。
說到驅動程式bug,在移動裝置上研究Vulkan驅動程式的團隊通常沒有在PC上那麼大,有很多GPU的嵌入式變體需要測試。意味著驅動的質量常常有點落後。再加上釋出修復程式的延遲,看看它是否有效或引入其他問題,驅動程式質量成為一個問題就不足為奇了。隨著一致性測試的改進,驅動程式的測試變得更好,Khronos的硬體供應商非常清楚這是一個高度優先事項。需要行業從業者齊心協力改善這一點(CTS)。
隨著現代圖形API的到來,驅動不再進行隱式的優化,可預測的效能是可預測的低!使用新API啟動新專案的開發人員具有優勢(下圖),新的圖形API給大型軟體安裝群帶來了更多的問題。構建渲染流,以便以正確的順序獲得所需的資訊,在開始時要比改裝容易得多。最重要的是,可以根據舊的API執行的驅動程式優化來編寫引擎,以獲得良好的效能。現在,軟體開發人員擁有了控制權,使得效能可以預測,並確保應用了正確的優化,但也確實意味著由開發人員來確保這些優化存在。
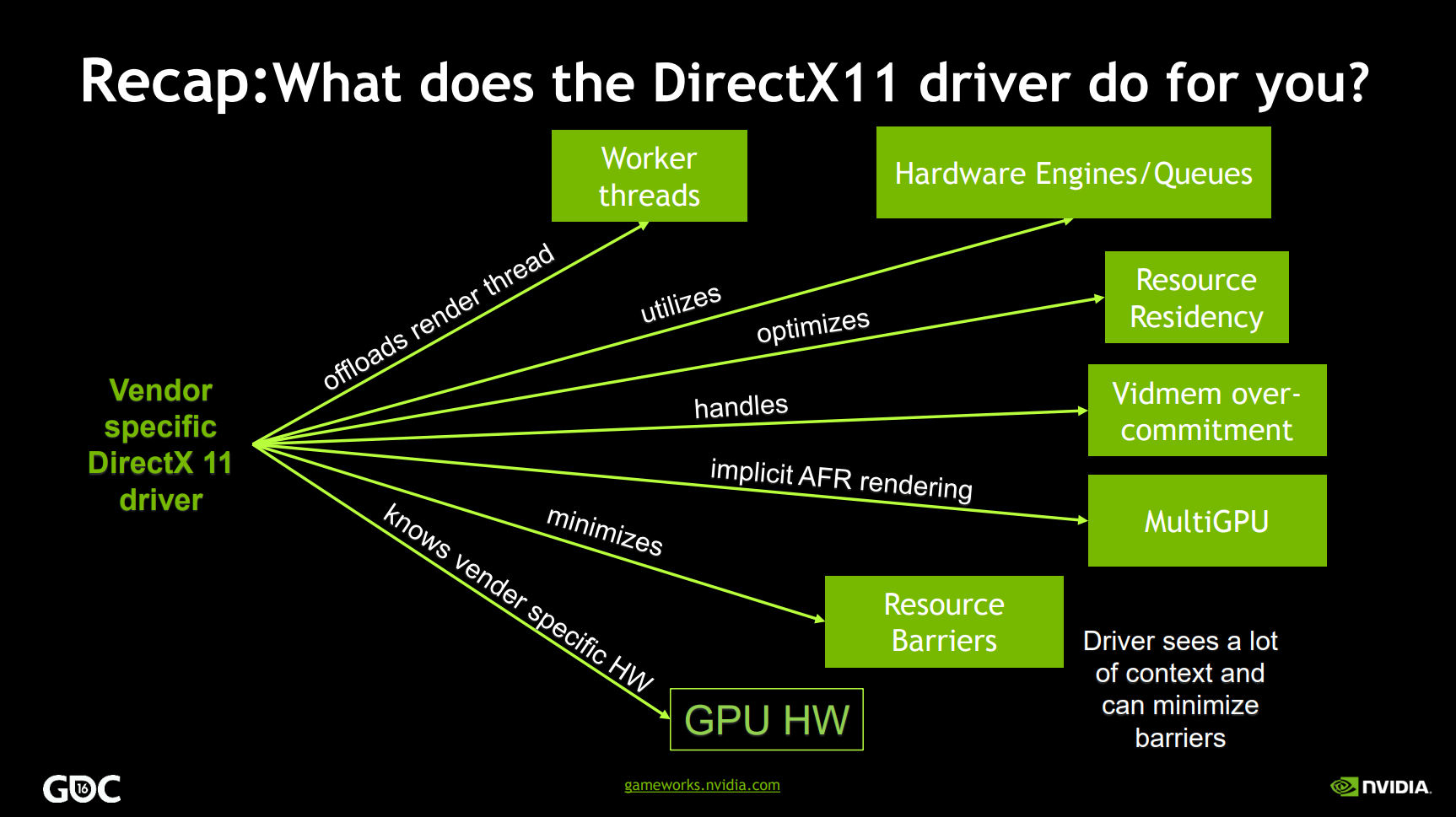
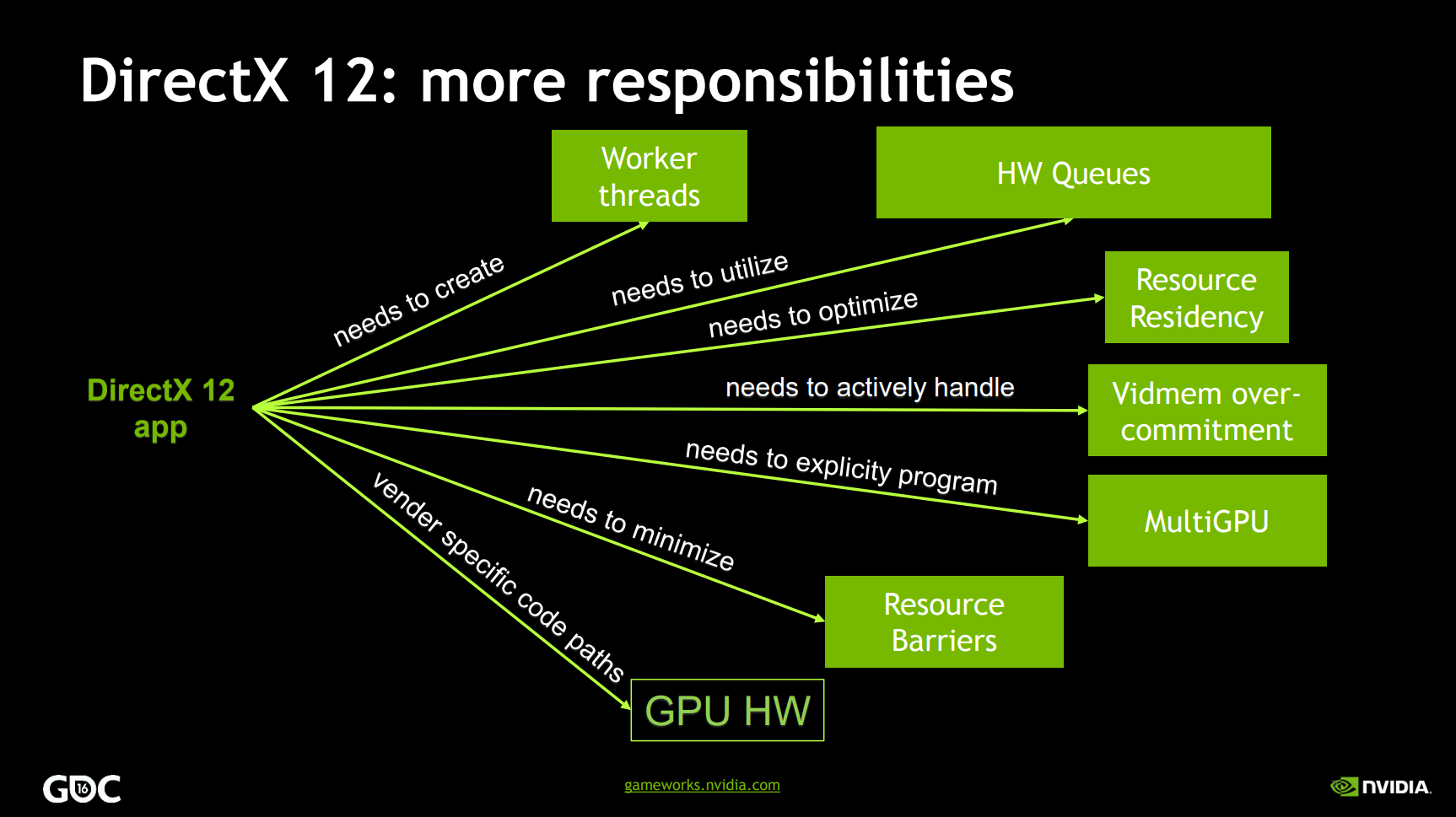
DirectX11驅動程式(上)和DirectX12應用程式(下)執行的工作對比圖。
特別說明
- 感謝所有參考文獻的作者,部分圖片來自參考文獻和網路,侵刪。
- 本系列文章為筆者原創,只發表在部落格園上,歡迎分享本文連結,但未經同意,不允許轉載!
- 系列文章,未完待續,完整目錄請戳內容綱目。
- 系列文章,未完待續,完整目錄請戳內容綱目。
- 系列文章,未完待續,完整目錄請戳內容綱目。
參考文獻
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- Understanding Modern Device Drivers
- AMD GRAPHICS CORES NEXT (GCN) ARCHITECTURE
- I/O systems
- A low latency GPU engine based reset mechanism for a more robust UI experience
- Graphics Driver Quality - AMD
- High Dynamic Range(HDR)on Intel Graphics
- Understanding the Windows 8 graphics driver model
- Linux Graphics Drivers: an Introduction
- Linux GPU Driver Developer’s Guide
- Matrox Display Driver Guide
- nouveau Development
- envytools
- Mobile Graphics 101 - Arm Community
- Understanding Citrix HDX Graphics
- Windows Kernel Graphics Driver Attack Surface
- Vulkan in Rocksolid
- Windows Graphics Architecture
- Anatomy of RAM
- Memory structure
- FIFO overview
- NVIDIA TURING GPU ARCHITECTURE
- NVIDIA AMPERE GA102 GPU ARCHITECTURE
- 深入GPU硬體架構及執行機制
- Graphic Stack Overview
- The State of Linux Graphics
- A deeper look into GPUs and the Linux Graphics Stack
- Device driver
- Free and open-source graphics device driver
- Mesa (computer graphics)
- nouveau (software)
- AMD Radeon Software
- Freedreno in freedesktop
- Freedreno Architecture Overview
- Freedreno in Mesa3d
- Freedreno in Phoronix
- Freedreno in GitHub
- Adreno tiling
- Vidix
- Graphics card
- NVIDIA Linux Open GPU Kernel Module Source
- MPLAB® Harmony Graphics Suite Applications
- What is a driver?
- WDDM Architecture
- Low-Level GPU Documentation
- MiniGLX
- Intel GMA
- Game Architecture and Game Engine
- Z-order curve
- Hilbert curve
- Direct Rendering Manager
- Direct X – Direct way to Microsoft Windows Kernel
- User mode and kernel mode
- Virtual address spaces
- Thread Synchronization and TDR
- Wayland
- Wayland Architecture
- Operating Systems must support GPU abstractions
- Schedule Synthesis for Halide Pipelines on GPUs
- Hardware Accelerated GPU Scheduling
- Windows 10 Hardware-Accelerated GPU Scheduling Benchmarks (Frametimes, FPS)
- TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
- TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
- REAL-TIME SCHEDULING FOR GPUS WITH APPLICATIONS IN ADVANCED AUTOMOTIVE SYSTEMS
- GPU Resource Optimization and Scheduling for Shared Execution Environments
- An Integrated GPU Power and Performance Model
- A user mode CPU–GPU scheduling framework for hybrid workloads
- Balancing Energy Efficiency and Real-Time Performance in GPU Scheduling