什麼是運算元?
摘要:本文介紹什麼是運算元,運算元有哪些基本特徵。
本文分享自華為雲社群《【CANN檔案速遞05期】一文讓您瞭解什麼是運算元》,作者: 昇騰CANN 。
什麼是運算元
深度學習演演算法由一個個計算單元組成,我們稱這些計算單元為運算元(Operator,簡稱OP)。在網路模型中,運算元對應層中的計算邏輯,例如:折積層(Convolution Layer)是一個運算元;全連線層(Fully-connected Layer, FC layer)中的權值求和過程,是一個運算元。
再例如:tanh、ReLU等,為在網路模型中被用做啟用函數的運算元。
運算元的名稱(Name)與型別(Type)
- 運算元的名稱:標識網路中的某個運算元,同一網路中運算元的名稱需要保持唯一。
- 運算元的型別:網路中每個運算元根據運算元型別進行實現邏輯的匹配,在一個網路中同一型別的運算元可能存在多個。
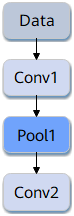
如下圖所示,Conv1、Pool1、Conv2都是此網路中的運算元名稱,其中Conv1與Conv2運算元的型別都為Convolution,表示分別做一次折積計算。
張量(Tensor)
- 張量是運算元計算資料的容器,包括輸入資料與輸出資料。
- 張量描述符(TensorDesc)是對輸入資料與輸出資料的描述,主要包含如下屬性:
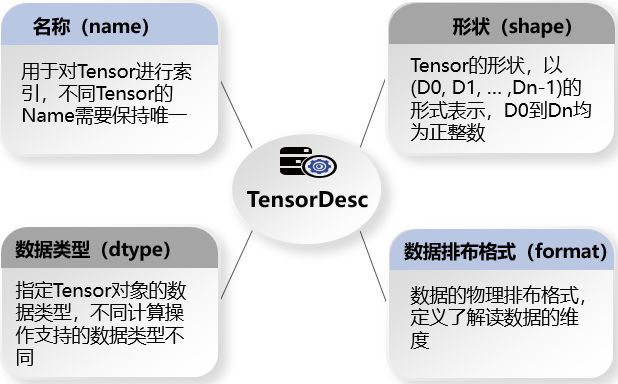
下面我們詳細介紹下張量描述符中的形狀和資料排布格式。
形狀(Shape)
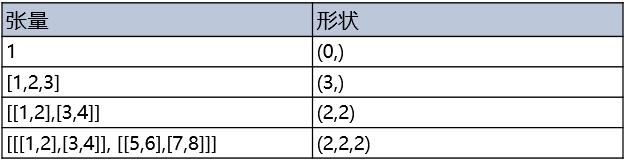
張量的形狀,比如形狀(3,4)表示第一維有3個元素,第二維有4個元素,是一個3行4列的矩陣陣列。在形狀中有多少個數位,就代表這個張量有多少維。形狀的第一個元素要看張量最外層的中括號中有幾個元素,形狀的第二個元素要看張量中從左邊開始數第二個中括號中有幾個元素,依此類推。例如:
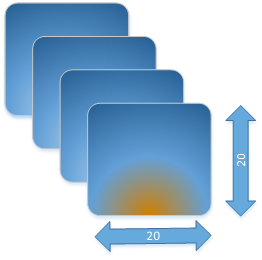
下面我們看一下形狀的物理含義,假設shape=(4, 20, 20, 3)。
假設有4張照片,即shape裡4的含義,每張照片的寬和高都是20,也就是20*20=400個畫素,每個畫素點都由紅/綠/藍3色組成,即shape裡面3的含義,這就是shape=(4, 20, 20, 3)的物理含義。
資料排布格式
在深度學習領域,多維資料通過多維陣列儲存,比如折積神經網路的特徵圖(Feature Map)通常用四維陣列儲存,即4D格式:
- N:Batch數量,例如影象的數目。
- H:Height,特徵圖高度,即垂直高度方向的畫素個數。
- W:Width,特徵圖寬度,即水平寬度方向的畫素個數。
- C:Channels,特徵圖通道,例如彩色RGB影象的Channels為3。
由於資料只能線性儲存,因此這四個維度有對應的順序。不同深度學習框架會按照不同的順序儲存特徵圖資料,比如Caffe,排列順序為[Batch, Channels, Height, Width],即NCHW。TensorFlow中,排列順序為[Batch, Height, Width, Channels],即NHWC。
以一張格式為RGB的圖片為例,NCHW中,C排列在外層,實際儲存的是「RRRRRRGGGGGGBBBBBB」,即同一通道的所有畫素值順序儲存在一起;而NHWC中C排列在最內層,實際儲存的則是「RGBRGBRGBRGBRGBRGB」,即不同通道的同一位置的畫素值順序儲存在一起。

儘管儲存的資料相同,但不同的儲存順序會導致資料的存取特性不一致,因此即便進行同樣的運算,相應的計算效能也會不同。
在昇騰AI處理器中,為了提高資料的存取效率,張量資料採用NC1HWC0的五維格式。其中C0與微架構強相關,等於AI Core中矩陣計算單元的大小,這部分資料需要連續儲存;C1是將C維度按照C0進行拆分後的數目,即C1=C/C0。如果不整除,最後一份資料需要補齊以對齊C0。
更多介紹
瞭解更詳細的內容,可以登入昇騰社群https://www.hiascend.com/,閱讀相關檔案。