論文解讀(SR-GNN)《Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data》
論文資訊
論文標題:Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data
論文作者:Qi Zhu, Natalia Ponomareva, Jiawei Han, Bryan Perozzi
論文來源:2021, NeurIPS
論文地址:download
論文程式碼:download
1 Introduction
半監督學習通過使用資料之間的關係(即邊連線關係,會產生歸納偏差),以及一組帶標籤的樣本,來預測其餘部分的標籤。
半監督學習存在的問題:訓練資料集和測試資料集的資料分佈不一致,容易產生 過擬合、泛化性差的問題。當資料集太小或太大,選擇一部分帶標記的子集進行訓練,這類問題就顯得比較明顯。
具體來說,我們的貢獻如下:
1. We provide the first focused discussion on the distributional shift problem in GNNs.
2. We propose generalized framework, Shift-Robust GNN (SR-GNN), which can address shift in both shallow and deep GNNs.
3. We create an experimental framework which allows for creating biased train/test sets for graph learning datasets.
4. We run extensive experiments and analyze the results, proving that our methods can mitigate distributional shift.
2 Related Work
標準學習理論假設訓練和推理資料來自相同的分佈,但在許多實際情況下,這不成立。在遷移學習中,領域自適應(Domain adaptation)問題涉及將知識從源域(用於學習)轉移到目標域(最終的推理分佈)。
[3] 作為該領域的開創性工作定義了一個基於模型在 源域 和 目標域 表現的距離度量函數來量化兩域的相似性。為獲得最終的模型,一個直觀的想法是基於源資料和目標資料的加權組合來訓練模型,其中權重是域距離的量化函數。
3 Distributional shift in GNNs
SSL 分類器,通常使用交叉熵損失函數 $l$:
$\mathcal{L}=\frac{1}{M} \sum\limits_{i=1}^{M} l\left(y_{i}, z_{i}\right)$
當訓練資料和測試資料來自同一域 $\operatorname{Pr}_{\text {train }}(X, Y)=\operatorname{Pr}_{\text {test }}(X, Y)$ 時,訓練得到的分類器表現良好。
3.1 Data shift as representation shift
基於標準學習理論的基礎假設 $\operatorname{Pr}_{\text {train }}(Y \mid Z)=\operatorname{Pr}_{\text {test }}(Y \mid Z)$,分佈位移的主要原因是表示位移,即
$\operatorname{Pr}_{\text {train }}(Z, Y) \neq \operatorname{Pr}_{\text {test }}(Z, Y) \rightarrow \operatorname{Pr}_{\text {train }}(Z) \neq \operatorname{Pr}_{\text {test }}(Z)$
本文關注的是訓練資料集和測試資料集表示 $Z$ 之間的分佈轉移。
為衡量這種變化,可使用 MMD[8] 或 CMD[37] 等差異指標。CMD 測量分佈 $\mathrm{p}$ 和 $\mathrm{q}$ 之間的直接距離,如下:
$\mathrm{CMD}=\frac{1}{|b-a|}\|\mathrm{E}(p)-\mathrm{E}(q)\|_{2}+\sum\limits _{k=2}^{\infty} \frac{1}{|b-a|^{k}}\left\|c_{k}(p)-c_{k}(q)\right\|_{2}$
其中
-
- $c_{k}$ 代表第 $k$ 階中心矩,通常 $k=5$ ;
- $a$、$b$ 表示這些分佈的聯合分佈支援度;
上式值越大則兩域距離越大。
本文定義的 GNNs 為 $H^{k}=\sigma\left(H^{k-1} \theta^{k}\right)$,傳統的 GNNs 為 $H^{k}=\sigma\left(\tilde{A} H^{k-1} \theta^{k}\right)$。
傳統的 GNNs 由於使用了歸一化鄰接矩陣,導致產生歸納偏差,從而改變了 表示的分佈。所以在半監督學習中 ,由於 圖歸納以及取樣特徵向量的偏移,有便宜的訓練樣本困難產生較大的效能干擾。
在形式上,對分佈位移的分析如下:
Definition 3.1 (Distribution shift in GNNs). Assume node representations $Z=\left\{z_{1}, z_{2}, \ldots, z_{n}\right\}$ are given as an output of the last hidden layer of a graph neural network on graph $G$ with n nodes. Given labeled data $\left\{\left(x_{i}, y_{i}\right)\right\}$ of size $M$ , the labeled node representation $Z_{l}=\left(z_{1}, \ldots, z_{m}\right)$ is a subset of the nodes that are labeled, $Z_{l} \subset Z$ . Assume $Z$ and $Z_{l}$ are drawn from two probability distributions $p$ and $q$. The distribution shift in GNNs is then measured via a distance metric $d\left(Z, Z_{l}\right)$
Figure 1 表明樣本偏差導致的分佈偏移的影響直接降低了模型的效能。通過使用節點 GCN 模型繪製了三個資料集分佈位移距離值( $x$ 軸)和相應的模型精度( $y$ 軸)的關係。
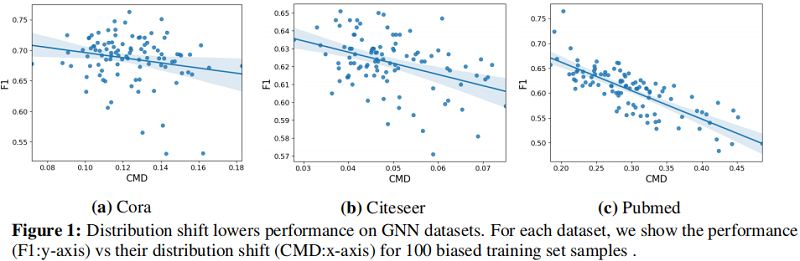
結果表明,GNN 在這些資料集上的節點分類效能與分佈位移的大小成反比,並激發了我們對分佈位移的研究。
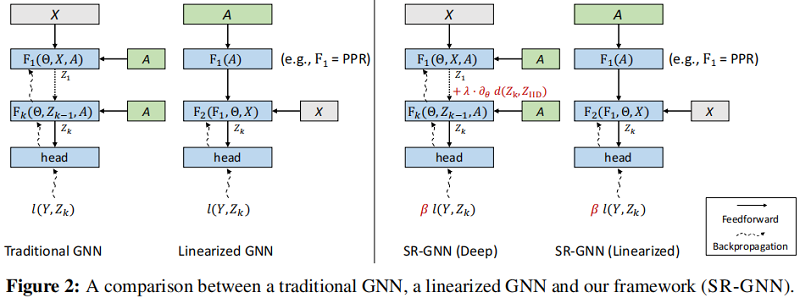
4 Shift-Robust Graph Neural Networks
本節首先提出兩種 GNN 模型解決分佈位移問題($\operatorname{Pr}_{\text {train }}(Z) \neq \operatorname{Pr}_{\text {test }}(Z)$,然後提出一種通用框架來減少分佈位移2問題。
ben
 ji
ji
4.1 Scenario 1: Traditional GNN models
傳統 GNN 模型 (GCN) $\Phi$ 包含 可學習函數 $\mathbf{F}$ ,引數 $\Theta$ ,鄰接矩陣 $A$ :
$\Phi=\mathbf{F}(\Theta, A)$
在 GCN 中,圖的歸納偏差在每一層上都是乘法的,並且梯度在所有層中反向傳播。最後一層生成的節點表示為:
$Z \equiv Z_{k}=\Phi\left(\Theta, Z_{k-1}, A\right)$, $Z_{k} \in[a, b]^{n}$, $Z_{0}=X$
訓練樣本 $\left\{x_{i}\right\}_{i=1}^{M}$ 的節點表示為 $Z_{\text {train }}=\left\{z_{i}\right\}_{i=1}^{M}$。對於測試樣本,從未標記的資料中抽取一個無偏的 IID 樣本集 $X_{\text {IID }}=\left\{x_{i}^{\prime}\right\}_{i=1}^{M}$,並將輸出表示為 $Z_{\text {IID }}=\left\{z_{i}^{\prime}\right\}_{i=1}^{M}$。
為減輕訓練 和 測試樣本之間的分佈位移問題,本文提出一個正則化器 $d:[a, b]^{n} \times[a, b]^{n} \rightarrow \mathbb{R}^{+}$ 用於新增到交叉熵損失上。由於 $\Phi$ 是完全可微的,可以使用分佈位移度量作為正則化,以直接最小化有偏和無偏的 IID 樣本之間的差異:
$\mathcal{L}=\frac{1}{M} \sum_{i} l\left(y_{i}, z_{i}\right)+\lambda \cdot d\left(Z_{\text {train }}, Z_{\text {IID }}\right)$
這裡度量分佈位移採用 中心力矩差異正則化器(central moment discrepancy regularizer)$d_{\mathrm{CMD}}$:
$d_{\mathrm{CMD}}\left(Z_{\text {train }}, Z_{\mathrm{IID}}\right)=\frac{1}{b-a}\left\|\mathbf{E}\left(Z_{\text {train }}\right)-\mathbf{E}\left(Z_{\mathrm{IID}}\right)\right\|+\sum\limits_{k=2}^{\infty} \frac{1}{|b-a|^{k}}\left\|c_{k}\left(Z_{\text {train }}\right)-c_{k}\left(Z_{\mathrm{IID}}\right)\right\|$
其中,
-
- $\mathbf{E}(Z)=\frac{1}{M} \sum_{i} z_{i}$;
- $c_{k}(Z)=\mathbf{E}(Z-\mathbf{E}(Z))^{k}$ 是 $k$ 階中心矩;
4.2 Scenario 2: Linearized GNN Models
線性化GNN模型使用兩個不同的函數:一個用於非線性特徵變換,另一個用於線性圖擴充套件階段:
$\Phi=\mathbf{F}_{\mathbf{2}}(\underbrace{\mathbf{F}_{\mathbf{1}}(\mathbf{A})}_{\text {linear function }}, \Theta, X)$
其中,線性函數 $\mathbf{F}_{\mathbf{1}}$ 將圖歸納偏差與節點特徵相結合,然後交予多層神經網路特徵編碼器 $\mathbf{F}_{\mathbf{2}}$ 解耦。SimpleGCN[34] 中 $\mathbf{F}_{\mathbf{1}}(A)=A^{k} X$ 。線性化模型的另一個分支 [16,4,36] 採用 personalized pagerank 來預先計算圖中的資訊擴散 ( $\mathbf{F}_{\mathbf{1}}(A)=\alpha(I-(1-\alpha) \tilde{A})^{-1}$ ),並將其應用於已編碼的節點特性 $F(\Theta, X)$。
上述兩種模型,圖歸納偏差作為線性函數 $\mathbf{F}_{\mathbf{1}}$ 的特徵輸入。但足夠階段並沒有可學習層,所以不能簡單使用上述提出的分佈正則化器。
在這兩種模型中,圖歸納偏差作為線性 $\mathbf{F}_{\mathbf{1}}$ 的輸入特徵提供。不幸的是,由於在這些模型的這個階段沒有可學習的層,所以我們不能簡單地應用前一節中提出的分佈正則化器。
在這種情況下,可以將訓練和測試樣本視為來自 $\mathbf{F}_{\mathbf{1}}$ 的行級樣本,然後將分佈位移 $\operatorname{Pr}_{\text {train }}(Z) \neq \operatorname{Pr}_{\text {test }}(Z)$ 問題轉化為匹配訓練和測試圖的歸納偏差特徵空間 $h_{i} \in \mathbb{R}^{n}$。為從訓練資料推廣到測試資料,可以採用樣本加權方案來糾正偏差,這樣有偏差的訓練樣本 $\left\{h_{i}\right\}_{i=1}^{M}$ 將類似於IID樣本 $ \left\{h_{i}^{\prime}\right\}_{i=1}^{M}$。由此得到的交叉熵損失為
$\mathcal{L}=\frac{1}{M} \beta_{i} l\left(y_{i}, \Phi\left(h_{i}\right)\right)$
其中,
-
- $\beta_{i}$ 是每個訓練範例的權值;
- $l$ 是交叉熵損失;
然後,通過求解一個 核均值匹配(KMM)[9] 來計算最優 $\beta$:
$\min _{\beta_{i}}\left\|\frac{1}{M} \sum\limits_{i=1}^{M} \beta_{i} \psi\left(h_{i}\right)-\frac{1}{M^{\prime}} \sum\limits_{i=1}^{M^{\prime}} \psi\left(h_{i}^{\prime}\right)\right\|^{2} \text {, s.t. } B_{l} \leq \beta<B_{u}$
$\psi: \mathbb{R}^{n} \rightarrow \mathcal{H}$ 表示由核 $k$ 引入的 reproducing kernel Hilbert space(RKHS) 的特徵對映。在實驗中,作者使用混合高斯核函數 $k(x, y)=\sum_{\alpha_{i}} \exp \left(\alpha_{i}\|x-y\|_{2}\right)$, $\alpha_{i}=1,0.1,0.01 $。下限 $B_{l}$ 和上限 $B_{u}$ 約束的存在是為了確保大多數樣本獲得合理的權重,而不是隻有少數樣本 獲得非零權重。
實際的標籤空間中有多個類。為了防止 $\beta$ 引起的標籤不平衡,進一步要求特定 $c$ 類的 $\beta$ 之和在 校正前後保持相同 $\sum_{i}^{M} \beta_{i} \cdot \mathbb{I}\left(l_{i}=c\right)=\sum_{i}^{M} \mathbb{I}\left(l_{i}=c\right), \forall c$ 。
4.3 Shift-Robust GNN Framework
現在我們提出了 Shift-Robust GNN(SR-GNN)-我們解決GNN中分佈轉移的一般訓練目標:
$\mathcal{L}_{\text {SR-GNN }}=\frac{1}{M} \beta_{i} l\left(y_{i}, \Phi\left(x_{i}, A\right)\right)+\lambda \cdot d\left(Z_{\text {train }}, Z_{\text {IID }}\right)$
該框架由一個用於處理可學習層中的分佈轉移的正則化元件(第4.1節)和一個範例重加權元件組成,該元件能夠處理在特徵編碼後新增了圖歸納偏差的情況(第4.2節)。
現在,我們將討論我們的框架的一個具體範例,並將該範例應用於APPNP[16]模型。APPNP模型的定義為:
$\Phi_{\text {APPNP }}=\underbrace{\left((1-\alpha)^{k} \tilde{A}^{k}+\alpha \sum\limits_{i=0}^{k-1}(1-\alpha)^{i} \tilde{A}^{i}\right)}_{\text {approximated personalized page rank }} \underbrace{\mathbf{F}(\Theta, X)}_{\text {feature encoder }}$
首先在節點特徵 $X$ 上應用特徵編碼器 $\mathbf{F}$,併線性逼近 personalized pagerank matrix。因此,我們有 $h_{i}=\pi_{i}^{\mathrm{ppr}}$,其中 $\pi_{i}^{\mathrm{ppr}}$ 是個性化的頁面向量。為此,我們通過範例加權來減輕由圖歸納偏差產生的分佈轉移。此外,讓 $Z=\mathbf{F}(\Theta, X)$ 和我們可以進一步減少非線性網路的分佈位移提出的差異正則化器 $d$。在我們的實驗中,我們展示了SR-GNN在另外兩個具有代表性的GNN模型上的應用:GCN[15]和DGI[32]。
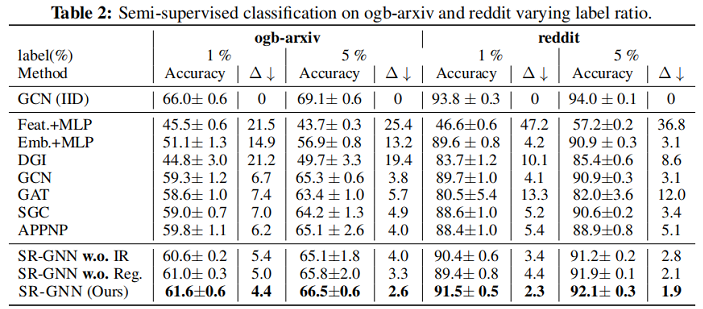
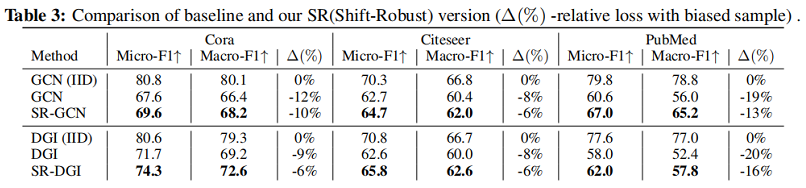
5 Experiments
實驗

5 Conclusion
對於半監督學習,考慮表示分佈一致性問題。
修改歷史
2022-06-24 建立文章
因上求緣,果上努力~~~~ 作者:Learner-,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/16406463.html