《阿里雲天池大賽賽題解析》——O2O優惠卷預測
程式碼下載:https://github.com/luxuantao/alibaba_tianchi_book
請自己閱讀賽題描述和下載程式碼
1.資料探索
1.1資料說明
本賽題提供使用者在2016年1月1日至2016年6月30日之間真實線上線下消費行為,預測使用者在2016年7月領取優惠券後15天以內的使用情況。
- Table 1: 使用者線下消費和優惠券領取行為
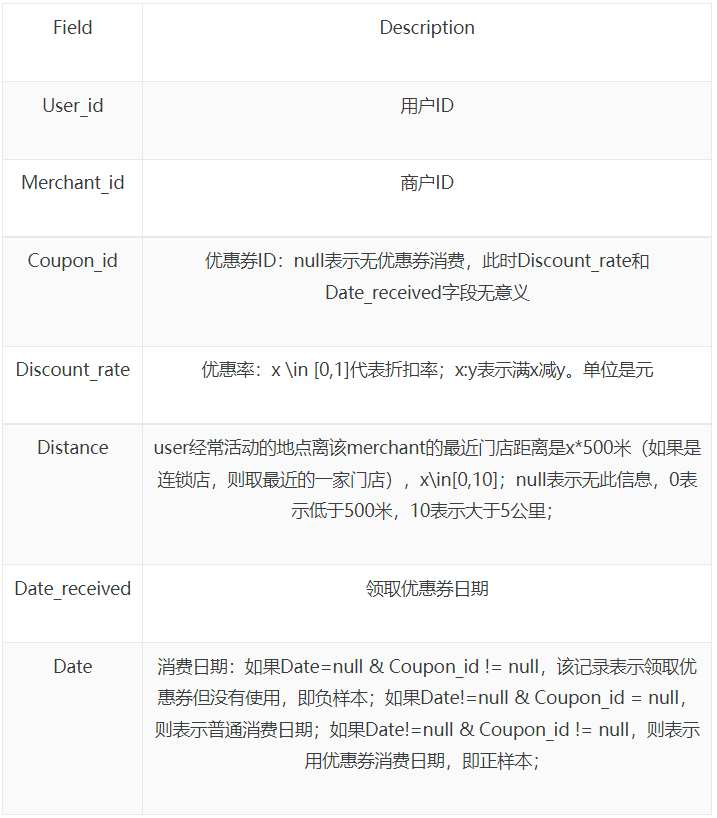
- Table 2: 使用者線上點選/消費和優惠券領取行為
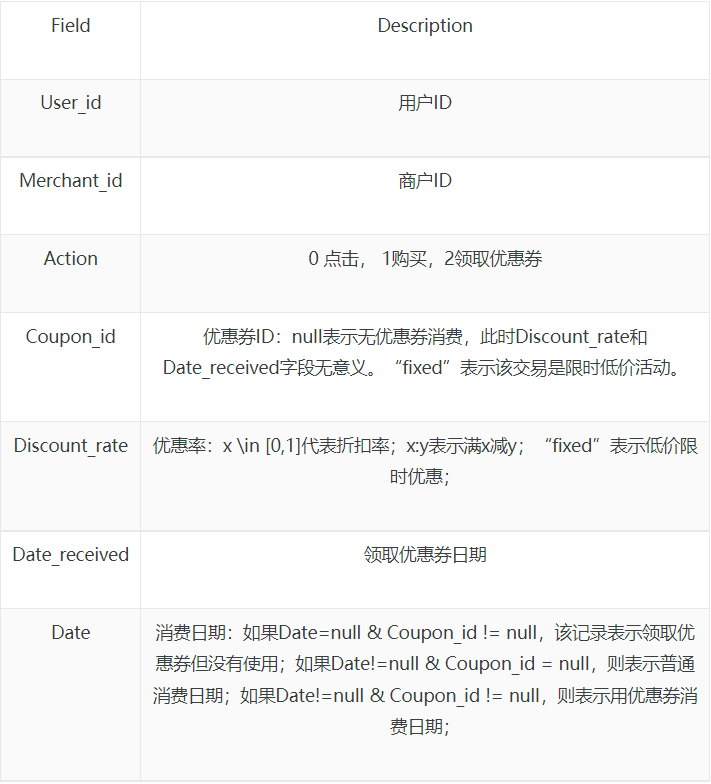
- Table 3:使用者O2O線下優惠券使用預測樣本
- Table 4:選手提交檔案欄位,其中user_id,coupon_id和date_received均來自Table 3,而Probability為預測值

我們的目標是要預測使用者優惠券的線下使用情況,線上資料我們重點關注與使用者相關的特徵(是作為線下資料的一個輔助),線下我們關注的特徵資料就比較多了。
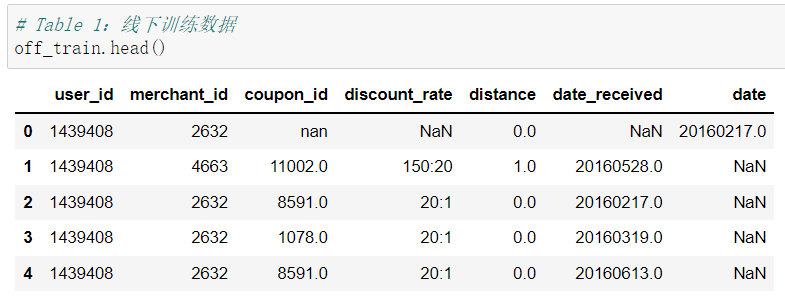
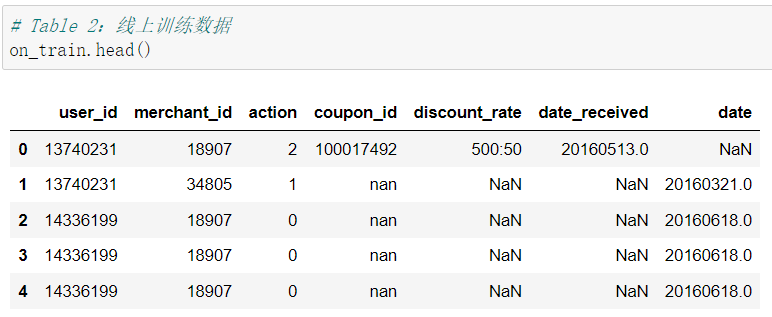
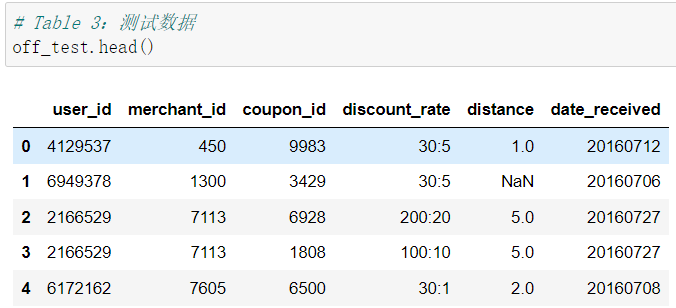
首先我們先看看整理好的Table 1.2.3 的資料大概都長什麼樣兒。
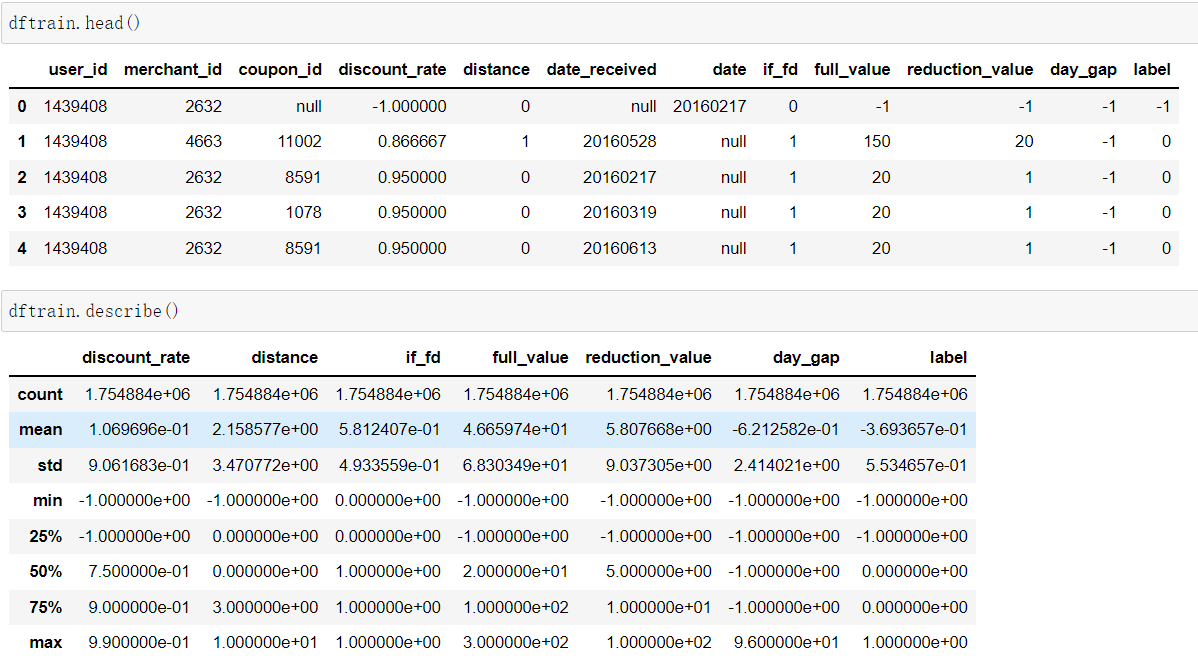
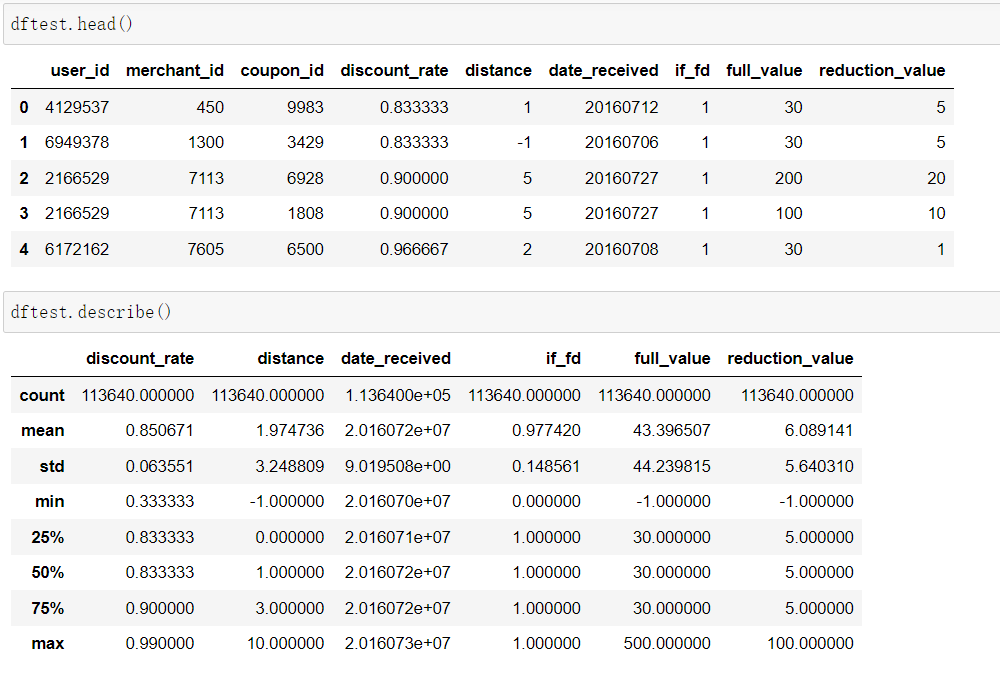
- Table 1:線下訓練資料
- Table 2:線上訓練資料
- Table 3:測試資料
1.2資料邊界
這裡我們需要確定每個資料的資料邊界,也就是從幾年幾月幾號到幾年幾月幾號,這樣方便後續的資料整理對應,於是需要對資料日期範圍情況進行初步探索。
- 資料集領券日期範圍
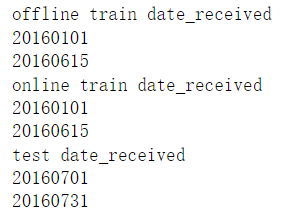
- 檢視訓練集的用卷日期範圍

通過探索可以發現訓練資料的用券資料是到6月30日,而領券日期並不是到6月30日,而是到6月15日,這在設計滑窗結構的時候需要注意(滑窗結構後續會講解)。
1.3訓練集與測試集的相關性
在機器學習比賽及實際應用的時候,不同資料的價值是不一樣的,同時也並不是所有得到的資料都是有用的。對測試集和訓練集資料的重合情況進行探查對於後續的特徵構建的思路有很大的指導作用。
- 對使用者(user_id)在訓練集和測試集的重合情況進行探索發現:

- 對商家(merchant_id)在訓練集和測試集的重合情況進行探索發現:

- 對優惠券(coupon_id)在訓練集和測試集的重合情況進行探索發現:

最後我們總結如下:
- 測試集的使用者ID與Offline訓練集重複佔比0.999以上,與Online訓練集重複佔比0.565。
- 測試集的商家ID與Offline訓練集重複佔比0.999以上,與Online訓練集沒有重複。
- 測試集的優惠券ID與訓練集都沒有重複。
結論:Online資料價值比較低,後續特徵提取將以Offline訓練集為主。在提取優惠券統計特徵的時候不能通過ID進行合併。 在後續視覺化分析中將主要在Offline訓練集及測試集之間進行。
1.4將特徵數值化
給定的資料中,除了折扣和距離,其他的資料都為文字,需要先對其進行資料化才能進行探索,也就是對資料先進行清洗。
- 計算折扣率,將滿減和折扣統一
因為discount_rate為null的時候一般都是沒有使用優惠券,這個時候折扣應該是1。discount_rate的資料有2種模式,第一種就是x \in [0,1]代表折扣率;第二種x:y表示滿x減y。
- 整理日期,並獲取Label,輸入內容為Date:Date_received
整理好後,重新進行資料分析: