一次 MySQL 誤操作導致的事故,「高可用」都頂不住了!
這是悟空的第 152 篇原創文章
官網:https://www.cnblogs.com/jackson0714/p/www.passjava.cn
你好,我是悟空。
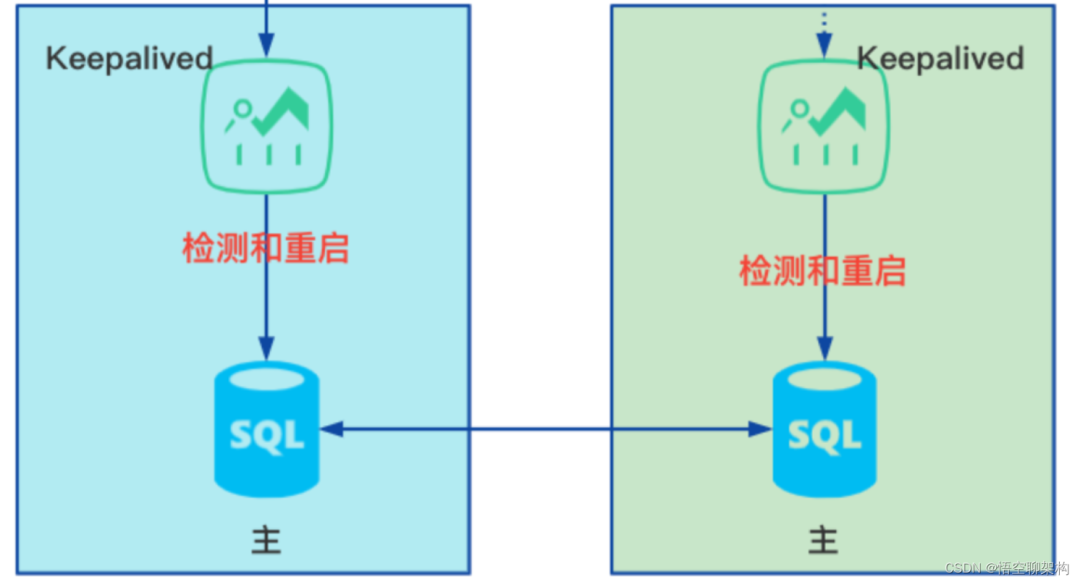
上次我們專案不是把 MySQL 高可用部署好了麼,MySQL 雙主模式 + Keepalived,來保證高可用。簡單來說就是有兩個 MySQL 主節點,分別有兩個 Keepalived 安裝在宿主機上監控 MySQL 的狀態,一旦發現有問題,就重啟 MySQL,而使用者端也會自動連線到另外一臺 MySQL。
詳情可以看悟空寫的這篇:實戰 MySQL 高可用架構
這次是我們在專案中遇到的一次事故,來一起復盤下吧。
本文目錄如下:
事故現場
- 環境:測試環境
- 時間:上午 10:30
- 反饋人員:測試群,炸鍋了,研發同事初步排查後,發現可能是資料庫問題。
然後就開始找原因吧。因為這套叢集環境是我部署的,所以我來排查的話輕車熟路。
系統部署圖
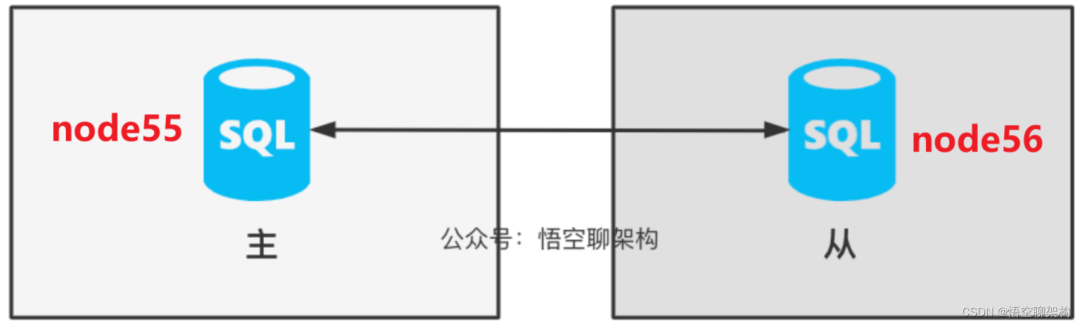
先說下系統的部署圖,方便大家理解。
兩個資料庫部署在 node55 和 node56 節點上,他們互為主從關係,所以叫做雙主。
還有兩個 Keepalived 部署在 node55 和 node56 上面,分別監控 MySQL 容器的狀態。
報錯原因和解決方案
- ① 我第一個想法就是,不是有 Keepalived 來保證高可用麼,即使 MySQL 掛了,也可以通過 Keepalived 來自動重啟才對。即使一臺重啟不起來,還有另外一臺可以用的吧?
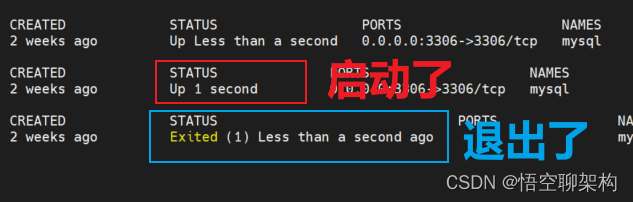
- ② 那就到伺服器上看下 MySQL 容器的狀態吧。到 MySQL 的兩臺伺服器上,先看下 MySQL 容器的狀態,docker ps 命令,發現兩臺 MySQL 容器都不在列表中,這代表容器沒正常執行。

- ③ 這不可能,我可是安裝了 Keepalived 高可用元件的,難道 Keepalived 也掛了?
- ④ 趕緊檢查一波 Keepalived,發現兩臺 Keepalived 是正常執行的。通過執行命令檢視:systemctl status keepalived

- ⑤ 納尼,Keepalived 也是正常的, Keepalived 每隔幾秒會重啟 MySQL,可能我在那一小段空閒時間沒看到 MySQL 容器啟動?換個命令執行下,docker ps -a,列出所有容器的狀態。可以看到 MySQL 啟動後又退出了,說明 MySQL 確實是在重啟。
- ⑥ 那說明 Keepalived 雖然重啟了 MySQL 容器,但是 MySQL 自身有問題,那 Keepalived 的高可用也沒辦法了。
- ⑦ 那怎麼整?只能看下 MySQL 報什麼錯了。執行檢視容器紀錄檔的命令。docker logs <容器 id>。找到最近發生的紀錄檔:

- ⑧ 提示 mysql-bin.index 檔案不存在,這個檔案是設定在主從同步那裡的,在 my.cnf 設定裡面。

這個設定好後,然後執行主從同步的時候,就會在 var/lib/mysql/log 目錄下生成多個 mysql-bin.xxx 的檔案。還有一個 mysql-bin.index 索引檔案,它會標記現在 binlog 紀錄檔檔案記錄到哪裡了。

mysql-bin.index 檔案裡面的內容如下:
/var/lib/mysql/log/mysql-bin.000001
這個 mysql-bin.000001 檔案還是帶序號的,這裡還有坑,後面我再說。
⑨ 報錯資訊是提示缺少 mysql-bin.index,那我們就去檢查下唄,確實沒有啊!先不管這個檔案怎麼消失的吧,趕緊把這個 log 資料夾先建立出來,然後 mysql 會自動給我們生成這個檔案的。
解決方案:執行以下命令建立資料夾和新增許可權。
mkdir logchmod 777 log -R
⑩ 兩臺伺服器上都有這個 log 目錄後,Keepalived 也幫我們自動重啟好了 MySQL 容器,再來存取下其中一個節點 node56 的 MySQL 的狀態,咦,居然報錯了。

Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find first log file name in binary log index file'
可以看到幾個關鍵資訊:
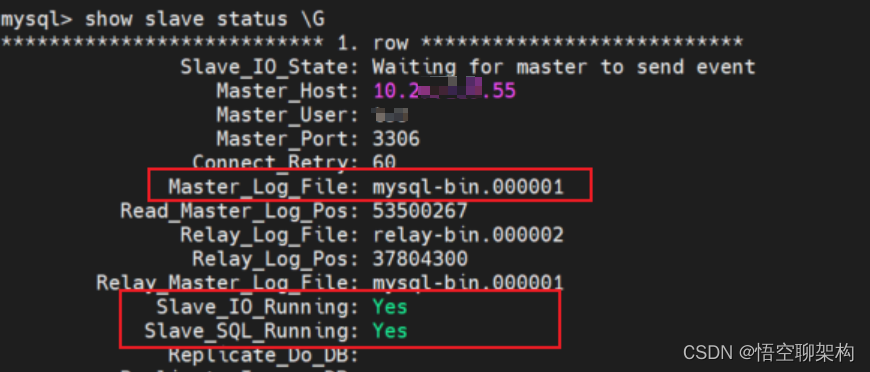
- Slave_IO_Running: NO,當前同步的 I/O 執行緒沒有執行,這個 I/O 執行緒是從庫的,它會去請求主庫的 binlog,並將得到的 binlog 寫到原生的 relay-log (中繼紀錄檔) 檔案中。沒有執行,則代表從庫同步是沒有正常執行。
- Master_Log_File: mysql-bin.000014,說明當前同步的紀錄檔檔案為
000014,之前我們看到節點 node56 上 mysql.index 裡面寫的是 000001,這個 000014 根本就不在 index 檔案裡面,所以就會報錯了。
這裡涉及到主從同步的原理,上一張圖:
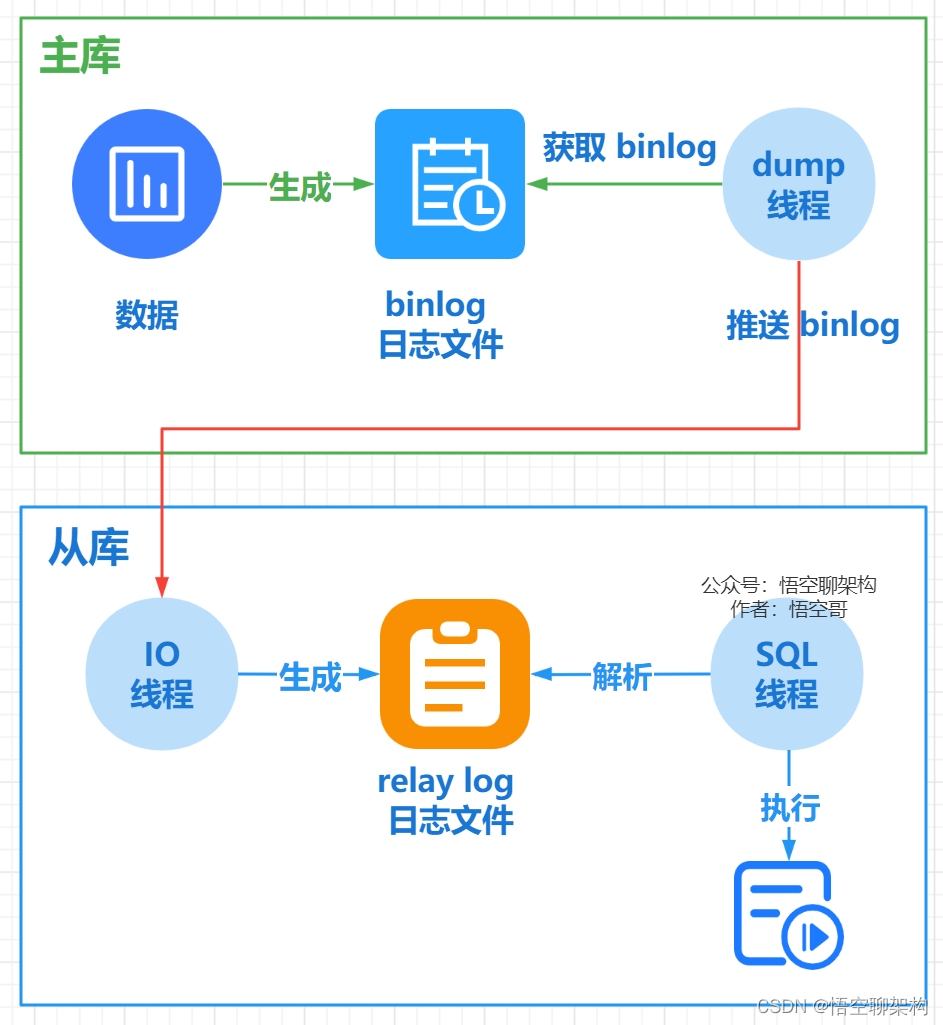
從庫會生成兩個執行緒, 一個 I/O 執行緒, 一個 SQL 執行緒;
I/O 執行緒會去請求主庫的 binlog 紀錄檔檔案, 並將得到的 binlog 紀錄檔檔案 寫到原生的 relay-log (中繼紀錄檔) 檔案中;
主庫會生成一個 dump 執行緒, 用來給從庫 I/O 執行緒傳 binlog;
SQL 執行緒,會讀取 relay log 檔案中的紀錄檔, 並解析成 SQL 語句逐一執行。
那好辦啊,我們重新指定下同步哪個紀錄檔檔案,以及同步的位置就好了。
解決方案:
看下主庫 node55 上紀錄檔檔案狀態。

記下這兩個資訊:File=mysql-bin.00001,Position=117748。(這裡也有個坑:先要鎖表,再看這兩個值,從庫開始同步後,再解鎖表)。
具體執行的命令如下:
FLUSH TABLES WITH READ LOCK;
SHOW MASTER STATUS
UNLOCK TABLES
然後在從庫 node56 上重新指定同步的紀錄檔檔案和位置:
# 停止從庫同步STOP SLAVE;# 設定同步檔案和位置CHANGE MASTER TO MASTER_HOST='10.2.1.55',MASTER_PORT=3306,MASTER_USER='vagrant',MASTER_PASSWORD='vagrant',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=117748;# 開啟同步START SLAVE;
再次檢視就不報錯了,I/O 執行緒也跑起來了,
在這裡插入圖片描述
然後將 node55 當做從庫,node56 當做主庫,同樣執行上面的幾步,狀態顯示正常了,然後用 navicat 工具連下資料庫,都是正常的,在測試群反饋下結果,搞定收工。
好像忘了一個問題,為啥 log 資料夾被幹掉了??
為什麼會出現問題?
然後問了一波當時有沒有人刪除這個 /var/lib/mysql/log 目錄,也沒有人會隨便刪除這個目錄的吧。
但是發現 log 的上級目錄 /var/lib/mysql 有很多其他資料夾,比如 xxcloud, xxcenter 等。這不就是我們專案中幾個資料庫的名字麼,只要在這個目錄的資料夾,都會顯示在 navicat 上,是一一對應的,如下圖所示。其中也顯示了 log 資料庫。
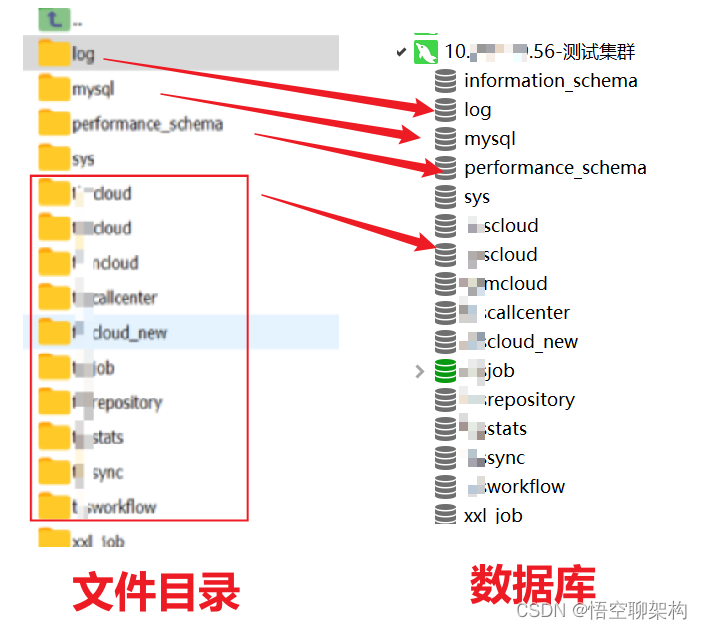
那會不會有人從 navicat 上幹掉了 log 資料庫?極有可能啊!
果然,有位同事之前在遷移升級的過程中,發現這個 log 資料庫在老的系統是沒有的,所以就清理了,這就相當於把 log 資料庫幹掉了,同時也會把 log 資料夾幹掉了。好了,終於水落石出了! 這個其實也是我前期沒有考慮到 log 目錄的一個問題。沒錯,這是我的鍋~
改進
其實操作同步資料庫的時候,不應該用這種覆蓋同步的方式,可以採取單庫同步的方式,也就不會幹掉 log 資料庫了。但是,這個 log 資料庫放在這裡有點奇怪啊,能不能不要出現在這裡呢?
我們只要指定這個 log 目錄不在 /var/lib/mysql 目錄下就好了。
東哥建議:log 檔案和資料庫 data 檔案進行隔離:
datadir = /var/lib/mysql/data
log_bin = /var/lib/mysql/log
另外一個問題,我們的高可用真的高可用了嗎?
至少沒有做到及時報警,MySQL 資料庫掛了,我是不知道的,都是通過測試同學反饋的。
能不能及時感知到 MySQL 異常呢?
這裡可以利用 Keepalived 傳送郵件的功能,或者通過紀錄檔報警系統。這個是後面需要改進的地方。
- END -