架構師之路,從「儲存選型」起步
經常有人問,架構師的學習路線是什麼?
我一般推薦架構師的基本功,是從「儲存選型」開始的。

本文整理了儲存選型的思路和整體框架,主要包括幾個部分內容:
- 瞭解目前的儲存技術趨勢,以及對開發人員新的要求
- 儲存選型的原則,避免日常的經典誤區
- 結合典型資料庫特點,說明如何進行儲存選型,提高業務開發效率
- 常見的場景和解決方案
1、儲存技術發展看儲存選型
1.1 儲存型別多樣化
DB-Engines資料庫排名並不代表資料庫的安裝數量,或者使用量。但某資料庫越來越受歡迎則代表在一定時間範圍內更加廣泛的使用。
https://db-engines.com/en/ranking
這裡貼了一張2022年5月份的排行榜。
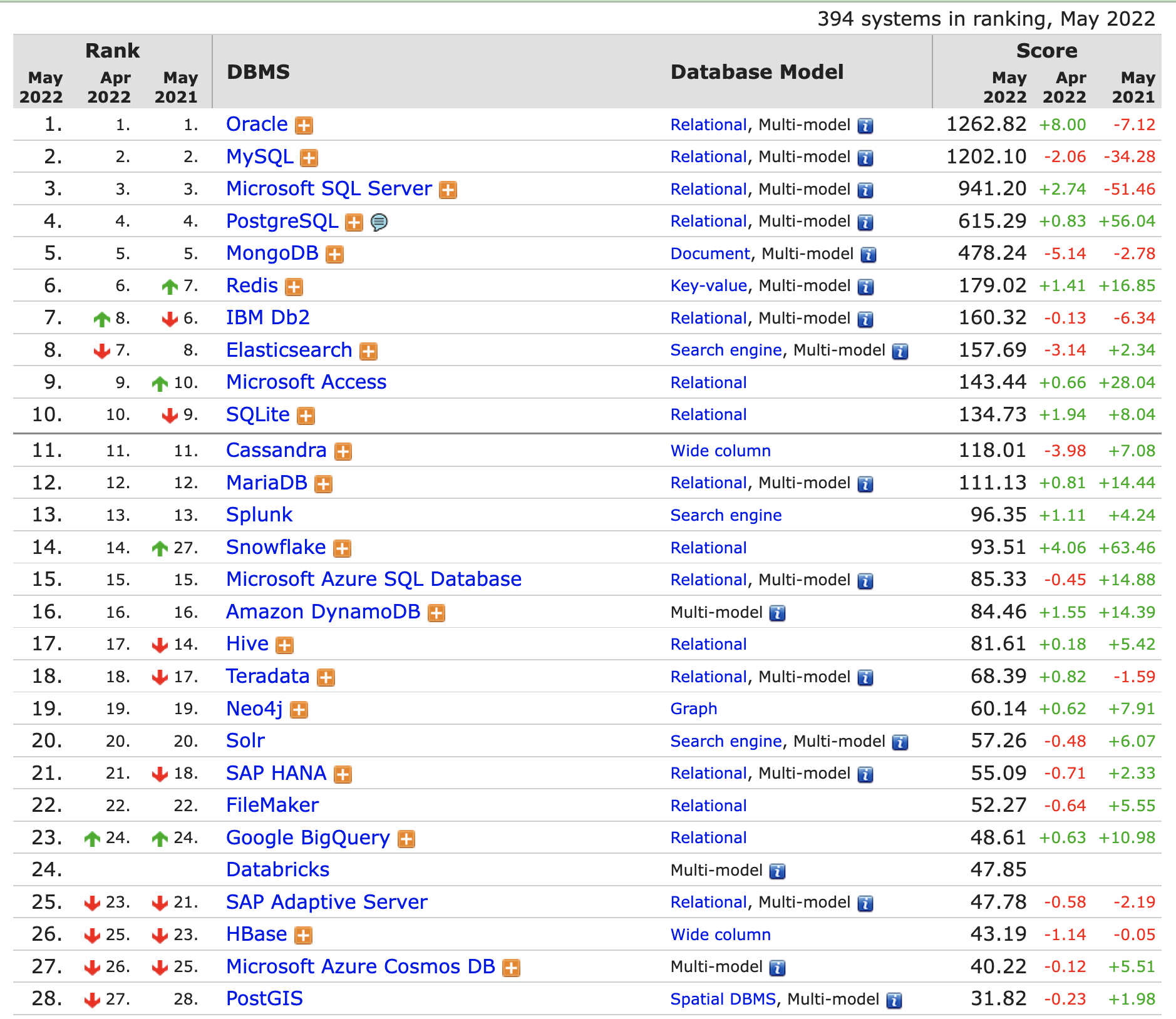
我們對於排名前10的資料庫中,比較熟悉的應該是MySQL、Redis和ES,這三個資料庫在我們日常開發中佔據絕大多數的比例。
但是,這三個資料庫只代表了一小部分的資料庫型別,我們是不是可以把視野開啟更多一些,看看沒有更多的資料庫型別,可以適合我們不同的業務,包括
Relational、Document、Key-value、Search engine、Wide column、Time Series、Graph等等不同資料庫型別。
1.2 雲原生儲存
除去上面的傳統資料庫之外,雲時代儲存技術又有了更多的變化。
除了簡單的把上面的資料庫託管到雲上之外,還多了許多充分利用雲的基礎設施產生的雲原生資料庫,比如aws的Amazon Aurora、阿里雲的PolarDB、騰訊雲的TDSQL等。
另外,雲時代還產生了更多型別的資料庫,比如阿里雲的多模資料庫Lindorm、Pingcap的HTAP資料庫TiDb等。
多型別資料庫是各個雲廠商發展的趨勢,他們為什麼會支援越來越多用途的資料庫呢?
供給側的改變一定是來源於需求側,因為隨著網際網路、物聯網等場景發展,有很多業務需求不是任何單一的資料庫能解決的了。
1.3 告訴我們什麼?
「資料庫型別多元化」 & 「雲原生資料庫型別多元化」 是一個必然的發展趨勢。
我們要解決的場景會越來越多,我們需要掌握的資料庫領域也越來越廣,只有這樣,我們才能面對線上事務、離線分析、海量儲存、成本與效率等因素,真正做好儲存選型。
2、儲存選型原則:不要耍流氓
2.1 不講場景的選型都是耍流氓
大家可能都知道,資料庫的選型一定是基於實際的業務場景的。但是,可能也遇到過類似的對話:
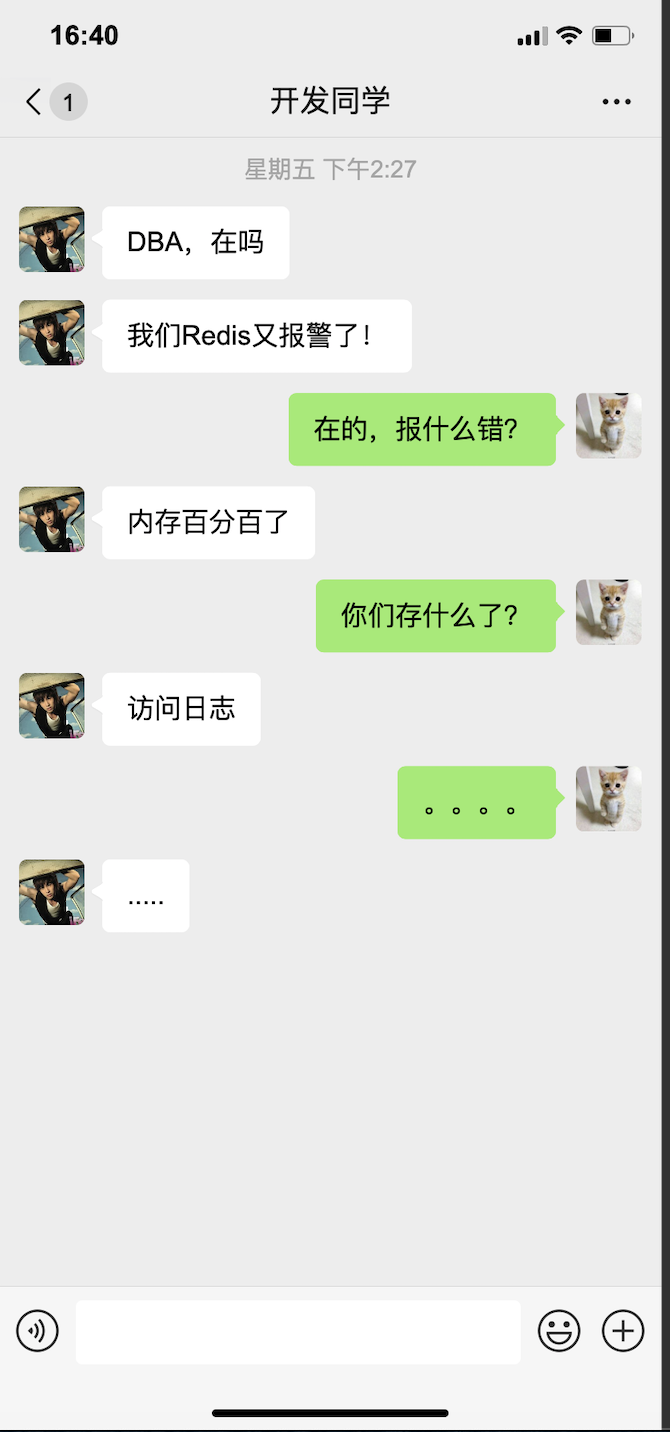
上面的對話可能有些誇張,但是實際生產中,可能是對場景的理解有誤,也可能是為了快速完成任務開發,結果是在「特定場景」選擇了錯誤的資料庫的情況時有發生。
常見的特定場景包括:
- 離線業務:紀錄檔、搜尋、統計等。
- 事務需求:強事務型、分析型。
- 資料熱度:全熱資料、冷熱明顯等。
- 資料讀寫偏好:多讀、多寫。
- 資料增長方式:按日期、按使用者、按位元置型別等。
對於儲存選型來說,一定需要識別特定場景的特點,是線上業務還是離線業務?資料冷熱是否明顯?資料存取方式特點?資料增長方式等等。
如果沒有根據場景特點來做儲存選型,可能會帶來不良後果,包括無法滿足業務需求、儲存成本暴漲等,然後就需要花大代價做不停機資料遷移和程式碼重構。
因此,針對特定業務場景的儲存選型一定要仔細、慎重,並在一開始就設計好。
2.2 不講資料規模的選型都是耍流氓
除了特定場景外,「資料規模」是儲存選型的另一個核心要素。
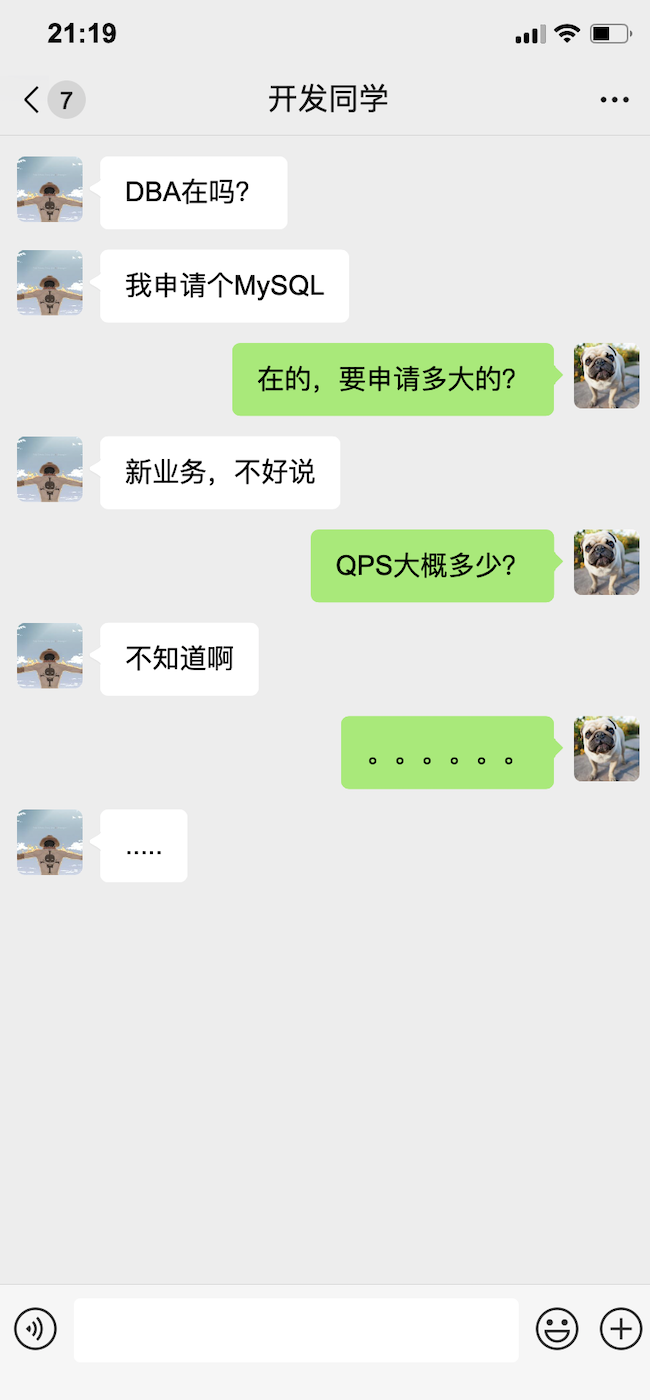
這樣的對話非常常見。
雖然在一些新業務場景下,確實很難準確評估業務的資料規模,但是無法評估的資料規模,往往意味著無法做好正確的儲存選型。
因此,如果有一定的先驗知識,我們需要儘量做好資料規模的評估。比如,之前有沒有類似的業務、其他組有沒有類似的需求或功能,它們目前的資料規模大致如何,然後進行評估。
常見的資料規模指標有三個:
- 資料總量
- QPS
- rt
不同的資料規模指標,往往意味著不同的儲存選型。
2.3 不講掌控度的選型都是耍流氓
對於儲存選型,「掌控度」是非常重要的選型原則。
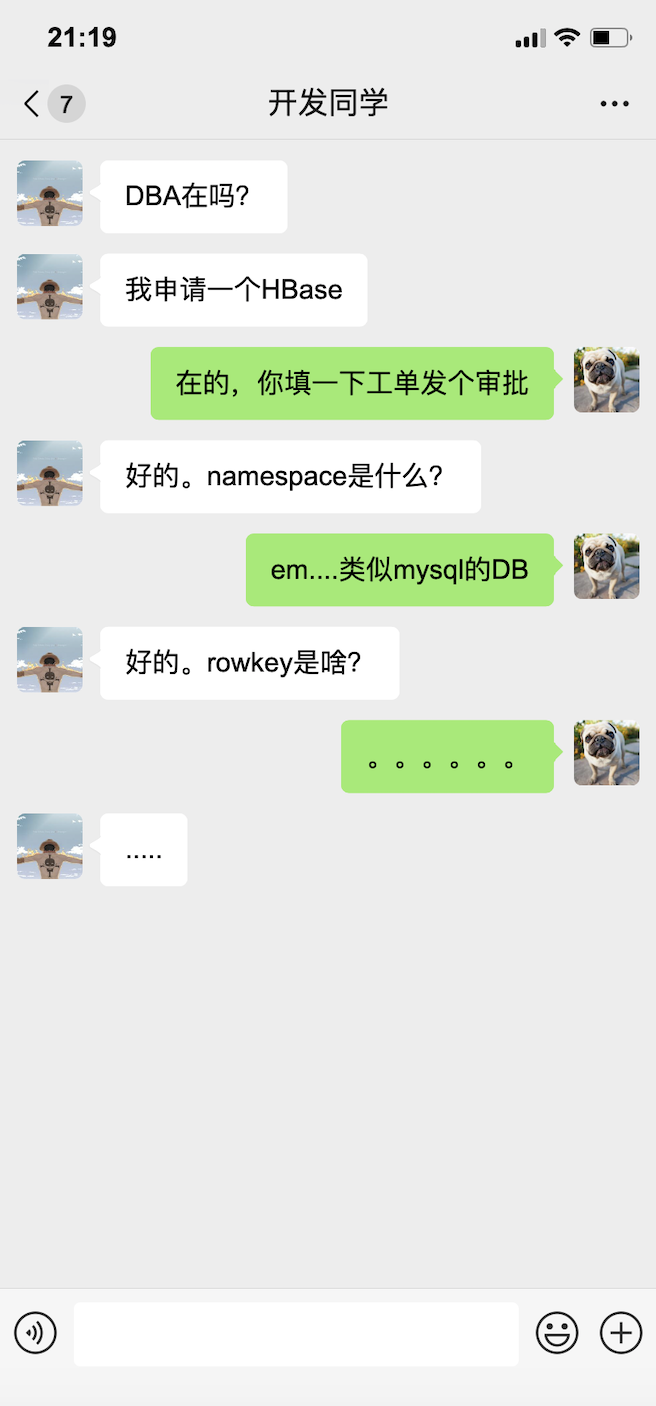
這裡其實包括了兩個維度,開發同學對儲存的掌控度 & DBA對儲存的掌控度。
1)開發同學的掌控度
對開發同學來說,選擇一個儲存,一定是基於對該儲存的基本認知&最佳實踐的瞭解。
一定不是其他人也這麼用所以我這麼用。
如果盲目使用一個自己不瞭解的儲存,很容易帶來不良後果,輕則造成資源浪費,重則引起線上故障(比如Mysql的慢sql、HBase的熱點存取等)。
2)DBA對儲存的掌控度
對DBA來說,對一個儲存的基本認知&最佳實踐是基礎要求了。在此之上,還有其他更多的要求。
一個是社群活躍度。社群活躍度決定著你獲取資訊的難易程度,也決定到出現了故障後的定位速度甚至是能不能定位出來,如果社群很活躍,自然就能得到更多的幫助。
第二個是有沒有案例背書。最好是一些中廠、大廠最新的案例實踐(千萬不要被大廠多年前的案例迷惑,技術發展往往意味著更新更合適的解決方案)。如果案例與儲存不匹配,或者沒有什麼案例來支援你的儲存選型,那麼這個選型可能就是不合適的。
第三個是儲存元件的上手成本。團隊具備了什麼樣的技術儲備?選擇的是自研還是雲產品?雲產品是全託管的還是半托管的?畢竟每一種資料庫都不是這麼簡單,如果人力有限而上手難度又很大,那麼這個儲存元件目前可能不是一個好的選擇。
3、選型路線圖
結合上面的原則,我們來做一個儲存選型路線圖供大家參考。
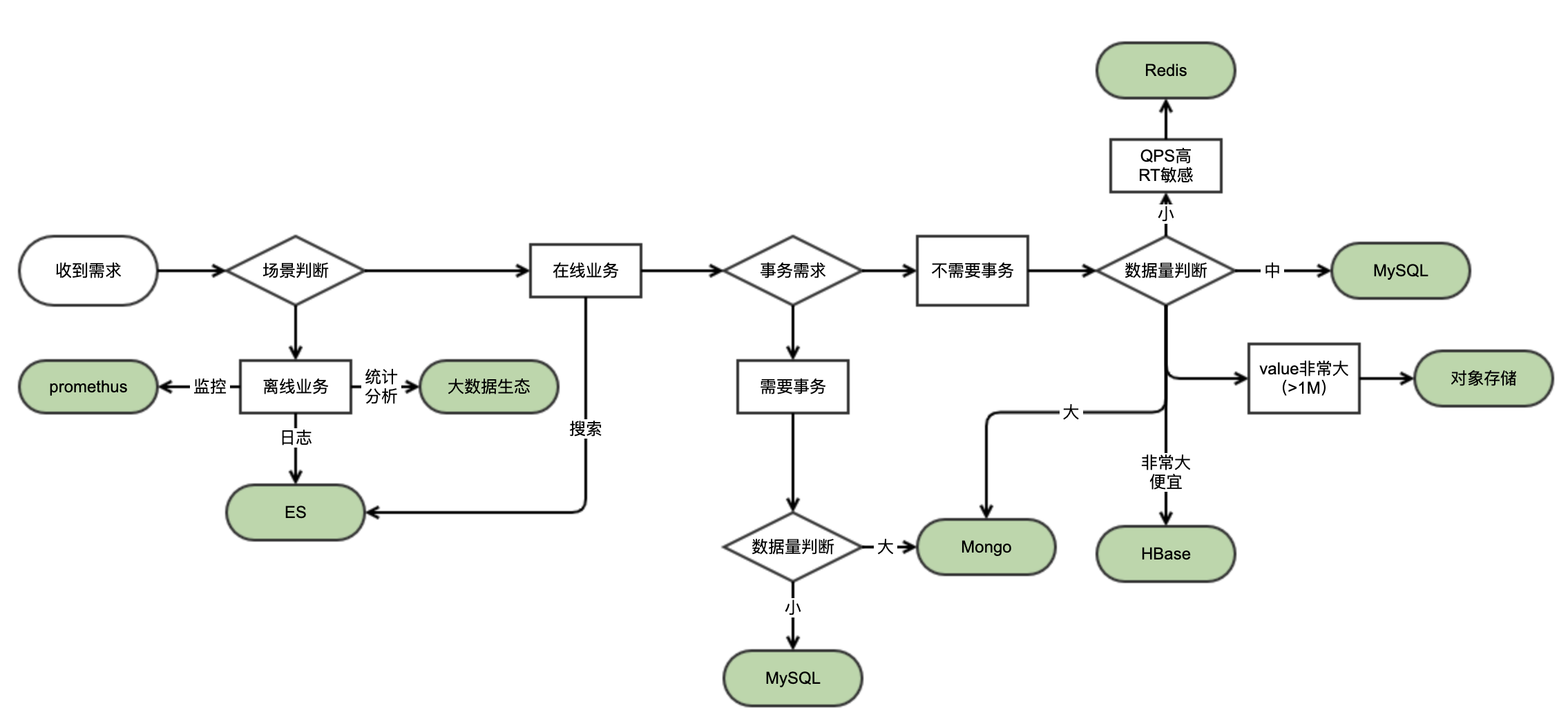
進一步,針對各個型別資料庫,我們都需要了解它們的優點、缺點、最佳實踐等,來結合業務場景因地制宜。
3.1 Relational
以MySQL為代表的關係型資料庫。
常用於線上業務(OLTP)場景,對於強事務有較好支援。
優點:
- 容易理解,大家基本上都用得比較熟
- 事務特性
- 配套成熟(備份恢復、資料訂閱、資料同步等)
- 服務極度穩定
缺點:
- 不易水平擴充套件
- 大表表結構變更復雜
- 全文檢索能力弱
- 複雜分析、統計能力弱
最佳實踐:
- 索引設計
- 避免n+1輪訓
- 避免深分頁
- 單表千萬考慮分庫分表,或者使用雲資料庫(polarDB或者TDSQL)
- 冷熱資料注意歸檔
- 不直接處理統計、分析型操作
3.2 Key-value
KV型NoSql顧名思義就是以鍵值對形式儲存的非關係型資料庫,是最簡單、最容易理解也是大家最熟悉的一種 NoSql。
Redis是其中的代表,典型用於快取場景。
優點:
- 資料基於記憶體,讀寫效率高
- KV型資料,時間複雜度為O(1),查詢速度快
缺點:
- 查詢方式單一
- 記憶體有限,且非常昂貴
- 由於儲存是基於記憶體的,會有丟失資料的風險(有持久化儲存方案)
最佳實踐:
- 合理控制kv大小,避免大key
- 避免熱點key
- 設定合理的TTL
- 注意快取雪崩、穿透、擊穿、相容問題
- 不要用於訊息佇列,異常情況無法堆積訊息
- 不要將redis作為資料庫使用,可能會丟資料
3.3 Search engine
搜尋型NoSql顧名思義主要是用在搜尋場景下的。
儘管MySQL可以通過索引來加速查詢,但是對於全文搜尋、模糊搜尋等場景就比較無力,搜尋型NoSql正是為了補足這個場景誕生的。
ElasticSearch是其中的代表產品。
優點:
- 支援分詞場景、全文搜尋,這是區別於關係型資料庫最大特點
- 支援條件查詢,支援聚合操作,適合資料分析
- 在叢集環境下可以方便橫向擴充套件,可承載PB級別的資料
缺點:
- 讀寫之間有延遲,寫入的資料不一定能馬上讀到
- 硬體效能要求高
最佳實踐:
- 核心線上應用強依賴ES需要考慮可行的降級方案
- 禁止使用單索引多type
- ES成本較高,因此建議僅資料庫加速、全文檢索情況下使用es
- ES中僅儲存索引欄位,通過id回查資料庫,不要全量資料儲存ES
- 根據節點數量設定合理的分片數量、分片大小
3.4 Document
檔案型 NoSql 指的是將半結構化資料儲存為檔案的一種 NoSql,通常以 JSON 或者 XML 格式儲存資料。
Mongo是其中的代表產品。
優點:
- 沒有預定義的欄位,擴充套件欄位容易
- 相較於關係型資料庫,讀寫效能優越
- 分片叢集易水平擴充套件
缺點:
- 檔案結構過於靈活,可能導致不易維護
- 使用者端控制力強,對開發、優化上有一定要求
最佳實踐:
- 選擇合理的片鍵
- 建立合適的索引
- 正確使用寫關注設定(Write Concern)
- 正確使用讀選項設定(Read Preference)
- 正確使用更新語句(區域性更新、防止大量更新集中在一條資料內)
3.5 Wide column
一般用於可靠性要求不高的海量儲存場景。
HBase是代表產品(國外cassandra用得多,國內HBase用得多)。
優點:
- 動態列調整,不受表結構困擾
- 海量資料儲存,PB 級別資料
- 橫向擴充套件方便,且支援廉價儲存擴充套件,成本低,適用於無法預估儲存量的海量資料
缺點
- Hadoop生態產品,元件依賴多,沒有云託管產品,運維能力要求比較高
- Rowkey設計需要一定經驗,避免熱點
- 單叢集SLA一般3個9,如果用於線上核心業務,一定需要考慮降級和容災
- 只支援行級事務
最佳實踐
- 適用於行數多,但單個kv資料量小(1M以下)
- 特別注意Rowkey設計,避免熱點
- 大value(10M以上)禁止存入HBase,考慮物件儲存
- 表建立時必須預分割區
- 表的列族數量不得超過 2 個
- HBase是CP型系統,SLA一般是3個9,一般建議離線業務使用。如果核心線上業務使用,必須做好降級、容災
4、一些場景和方案參考
上文提出了 三條選型原則 和 常見資料庫的選型一句,下面結合不同場景做一下常規選型方案參考。
4.1 主要場景和方案
毋庸置疑,網際網路業務的主要場景,是採用mysql進行資料儲存。正如MySQL的自己所說 —— most popular open source database。

當然,為了扛住高並行場景,快取也不可缺失。因此,最主要的方案就是 MySQL + Redis。
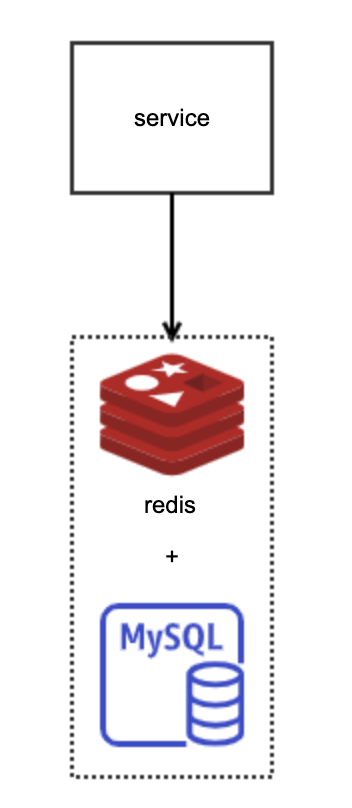
適用於日常主要場景:
- MySQL滿足事務性要求
- Redis抗熱點
4.2 模糊搜尋 or 全文檢索
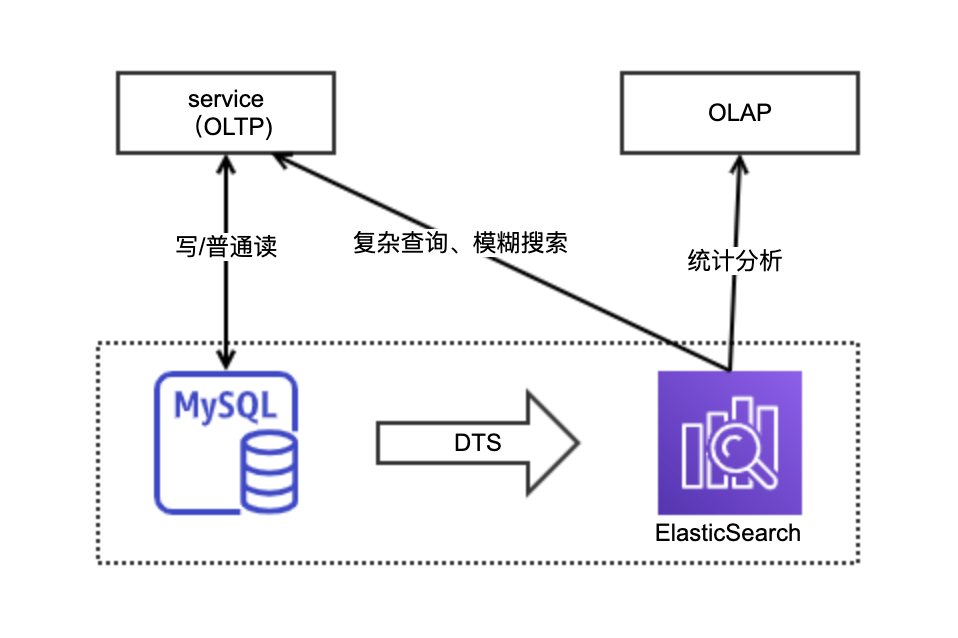
適用於搜尋場景:
- 複雜查詢
- 模糊搜尋
- 全文搜尋
- 統計分析
4.3 大量資料方案
資料規模:100TB以內的資料量。
1)MySQL分庫分表 + es
傳統MySQL橫向擴充套件方案,利用分庫分表中介軟體進行儲存擴充套件,利用ES進行非分表鍵查詢和複雜查詢。
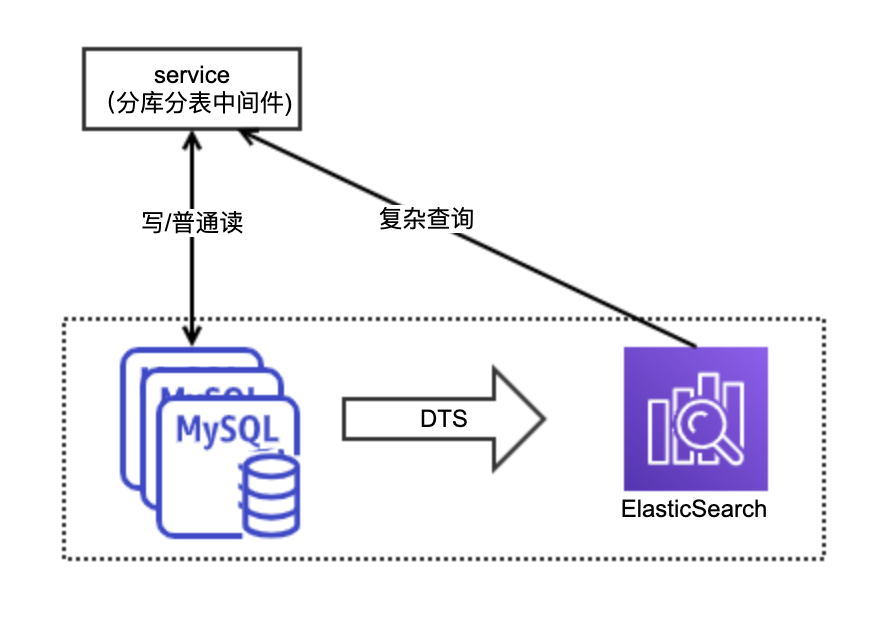
適用場景:
- 資料量較大
- 有中介軟體使用能力
- 已有MySQL橫向擴充套件
2)雲原生資料庫(以polarDB為例)
雲時代的新方案。
PolarDB是阿里巴巴自研的新一代雲原生關係型資料庫,在儲存計算分離架構下,利用了軟硬體結合的優勢,為使用者提供具備極致彈性、高效能、海量儲存、安全可靠的資料庫服務,100%相容MySQL 5.6/5.7/8.0。
最高100 TB,不再需要因為單機容量的天花板而去購買多個範例做分片,由此簡化應用開發,降低運維負擔。
適用場景:
- 資料量較大
- 有公有云使用基礎設施
3)mongo分片叢集
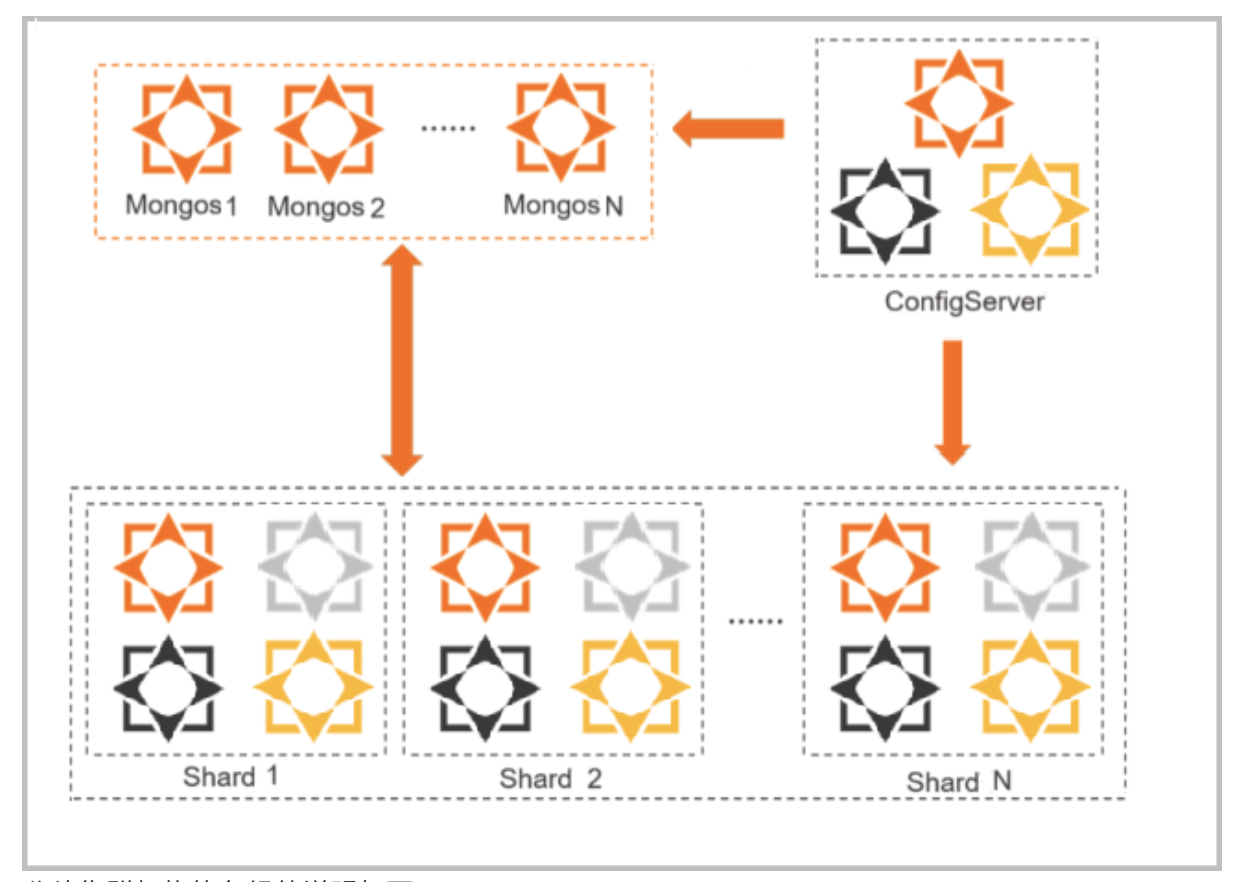
適用場景:
- 資料量較大的NoSQL場景
- 表結構變更頻繁場景,free-schema
- 對mongo使用有一定理解
4.4 海量資料方案
資料規模:100TB以上的資料量。
1)高可用資料庫 + HBase
由於資料量非常大,需要考慮儲存成本。因此一般會考慮冷熱資料分離。
熱資料在高可用資料庫進行讀寫,可以選擇MySQL、Mongo等。冷資料存入成本較低的HBase等元件。
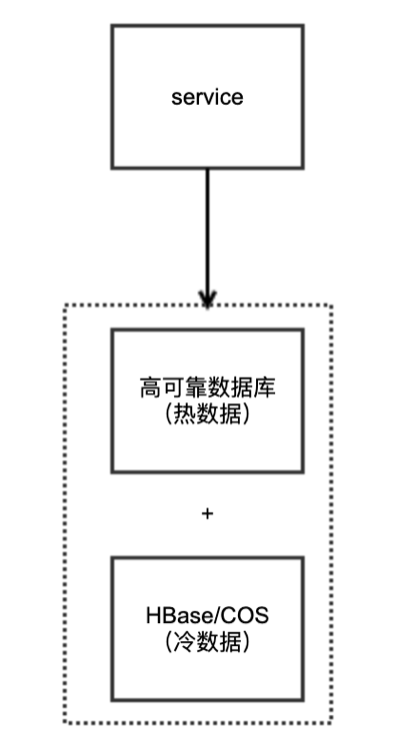
適用場景:
- 海量資料
- 可靠性要求高
2)直接使用HBase
如果是非核心線上業務,或者離線業務,可以考慮直接使用HBase。
適用場景:
- 海量資料
- 低成本
- 可靠性要求不高
5、總結
在業務開發過程中,除了常用的MySQL,一定要多關注市面上更合適的儲存方案,這是架構師的基本功。
通過了解更多儲存元件的基本特性和使用場景,因地制宜選擇合適儲存,提高業務開發效率,降低使用成本。
希望本文能夠拋磚引玉,提供一些啟發和思考。
都看到最後了,原創不易,點個關注,點個贊吧~
文章持續更新,可以微信搜尋「阿丸筆記 」第一時間閱讀,回覆【筆記】獲取Canal、MySQL、HBase、JAVA實戰筆記,回覆【資料】獲取一線大廠面試資料。
知識碎片重新梳理,構建Java知識圖譜:github.com/saigu/JavaK…(歷史文章查閱非常方便)