C++ 煉氣期之算術運運算元
1. 前言
編寫程式時,資料確定後,就需要為資料提供相應的處理邏輯(方案或演演算法)。所謂邏輯有 2 種存在形態:
抽象形態:存在於意識形態,強調思考過程,與具體的程式語言無關。具體形態:通過程式碼來實現。需要使用表示式描述完整的計算過程。
表示式由 2 個部分組成:
-
資料。也可稱為運算元。 -
運運算元。運運算元是計算機語言提供的能對資料進行基本運算操作的功能體。開發者在實現自己的邏輯運算時,需要組合這些運運算元來描述自己的邏輯運算過程。
Tip: 可以把
C++的運運算元看成一種特殊語法格式的函數,或把C++中的函數當成一種特殊的運運算元。
在使用運運算元時,需要遵守下面的 2個基本原則:
運運算元對操作的資料有內建的型別要求。如數學運運算元要求運算元是數位型別。- 如果
運運算元需要多個運算元時,則要求資料型別必須相同。如果出現型別不一致時,編譯器會試著把不同型別的資料轉換成同型別的資料後再進行運算。開發者也可以顯示進行強制型別轉換。
2. 運運算元種類
C++中的運運算元非常多,如下是幾類常用的運運算元:
- 算術運運算元。
- 邏輯、關係運算子。
- 賦值運運算元。
- 遞增、遞減運運算元。
- 成員存取運運算元。
- 條件運運算元。
- 位運運算元。
sizeof運運算元。- 逗號運運算元。
使用運運算元前,需要理解如下幾個概念:
-
運運算元的優先順序: 不同類別中的
運運算元的優先順序是不相同的。當在一個表示式中出現多個運運算元時,則需要根據運運算元的優先順序進行先後運算。 -
運運算元的運算元: 作用於一個運算元的運運算元為
一元運運算元,作用於兩個運算元的運運算元為二元運運算元。C++中還有一個可作用於三個運算元的條件運運算元。 -
結合性: 當複雜表示式中的多個
運運算元的優先順序相同時,則要根據運運算元的結合性進行運算。如100/4*8這個表示式,/和*的優先順序是相同,因乘、除都是具有從左到右的結合性。所以先計算100/4=25再計算25*8。Tip: 只有當兩個運運算元作用於同一個運算元時,優先順序和結合性才有意義。
C++中的基礎運運算元較多,且因C++是弱型別語言,每一種運運算元在使用過程中都存在很多細節問題。算術運運算元又是運運算元中的基礎運運算元。
本文試圖通過講解清楚算術運運算元,讓閱讀者瞭解使用C++運運算元時應該注意的事項。
3. 算術運運算元
3.1 功能描述
算術運運算元用來對數位型資料進行數學語意上的加、減、乘、除。此類中有 5個運運算元:
+:對2個數位型別的資料進行數學語意上的加法運算。-:對2個數位型別的資料進行數學語意上的減法運算。*:對2個數位型別的資料進行數學語意上的乘法運算。/:對2個數位型別的資料進行數學語意上的除法運算。%:取餘或取模操作運運算元。運算結果是兩個運算元相除後的餘數部分,不能用於浮點資料型別。
算術運運算元是二元運運算元。使用時,需要提供 2 個運算元。
3.2 運運算元過載問題
C++可以過載運運算元,所謂過載運運算元,指同一個運運算元可以根據使用時的上下文資訊,表現出不同的運算能力。如-運運算元, 當作為二元運運算元時,用來對運算元進行相減操作。
int num1=30;
int num2=20;
//此處的 - 運運算元表現出減法運算能力
int res=num1-num2;
cout<<res<<endl;
//輸出結果: 10
當作為一元運運算元時,則是取負的意思。如下程式碼:
int num=-10;
int num01=-num;
cout<<num01<<endl;
//輸出結果為 10,負負為正
同理,
+運運算元也存在過載。運運算元過載是
C++中的一個特色。對於有符號資料型別而言,如果在字面常數前面沒有顯示提供
正、負符號,則預設為+(正)符號。
3.3 兩數相除的問題
當/運運算元作用於 2 個整型數位時,會得到捨棄小數點後的整數部分數值,或稱為兩數相除的商,意味著會丟失精度。
如下程式碼:
int num1=7;
int num2=3;
int res=num1/num2;
cout<<res<<endl;
//輸出結果:2,丟失精度
如果要保留兩個數位相除的精度,則應該以浮點資料型別的身份進行相除。
double num1=7;
double num2=3;
double res=num1/num2;
cout<<res<<endl;
//輸出結果:2.33333
%運運算元作用於 2 個整型型別的資料時,運算結果是 2 個數位相除之後的餘數部分。如下程式碼:
int num1=5;
int num2=3;
int res=num1 % num2;
cout<<res<<endl;
//輸出結果:2 。
%用於浮點資料型別相除時,會出現編譯錯誤。也就是 %只能用於整型資料的運算,不能用於浮點資料型別。
3.4 關 於/和%運運算元的正、負問題
- 當
2個運算元據都是正數時。
int num1=21;
int num2=8;
int res=num1 / num2;
cout<<" / 運算:"<<res<<endl;
res=num1 % num2;
cout<<" % 運算:"<<res<<endl;
/和%動算符的輸出結果都是正數。
/ 運算:2
% 運算:5
- 當
2個運算元都為負數時。
int num1=-21;
int num2=-8;
int res=num1 / num2;
cout<<" / 運算:"<<res<<endl;
res=num1 % num2;
cout<<" % 運算:"<<res<<endl;
輸出結果,一個是正數,一個是負數。
/ 運算:2
% 運算:-5
- 當
2個運算元中被除數為負,除數為正時。
int num1=-21;
int num2=8;
int res=num1 / num2;
cout<<" / 運算:"<<res<<endl;
res=num1 % num2;
cout<<" % 運算:"<<res<<endl;
輸出結果都是負數。
/ 運算:-2
% 運算:-5
- 當
2個運算元中被除數為正,除數為負時。
int num1=21;
int num2=-8;
int res=num1 / num2;
cout<<" / 運算:"<<res<<endl;
res=num1 % num2;
cout<<" % 運算:"<<res<<endl;
輸出結果為一負一正。
/ 運算:-2
% 運算:5
結論:
- 當
2個數位使用%運運算元進行相除操作時,運算結果的正負號與num1運算元(被除數)的正負號保持一致。 /運運算元運算結果的正負號和數學上的語意一致。兩個運算元都為正或為負時則正正得正,負負得正。兩個運算元為一正一負時:則正負得負。
3.5 資料溢位問題
在使用算術運運算元時,有可能出現資料溢位現象。如下程式碼:
short num=32767;
short num01=num+1;
cout<<num01<<endl;
輸出結果:
數位:-32768
無符號short(16位元)的型別資料的最大值是 32767,在此數位上加一,num01的值理論是上 32768。但實際結果是 -32768。因為 32768已經超過short範圍,編譯器會重新計算出一個新的結果(並不是預期值)。這種現象叫資料溢位。
對於無符號 short,可以認為其有 2 部分,一部分為負數,一部分為正數。當正數溢位後,會進入負數部分。
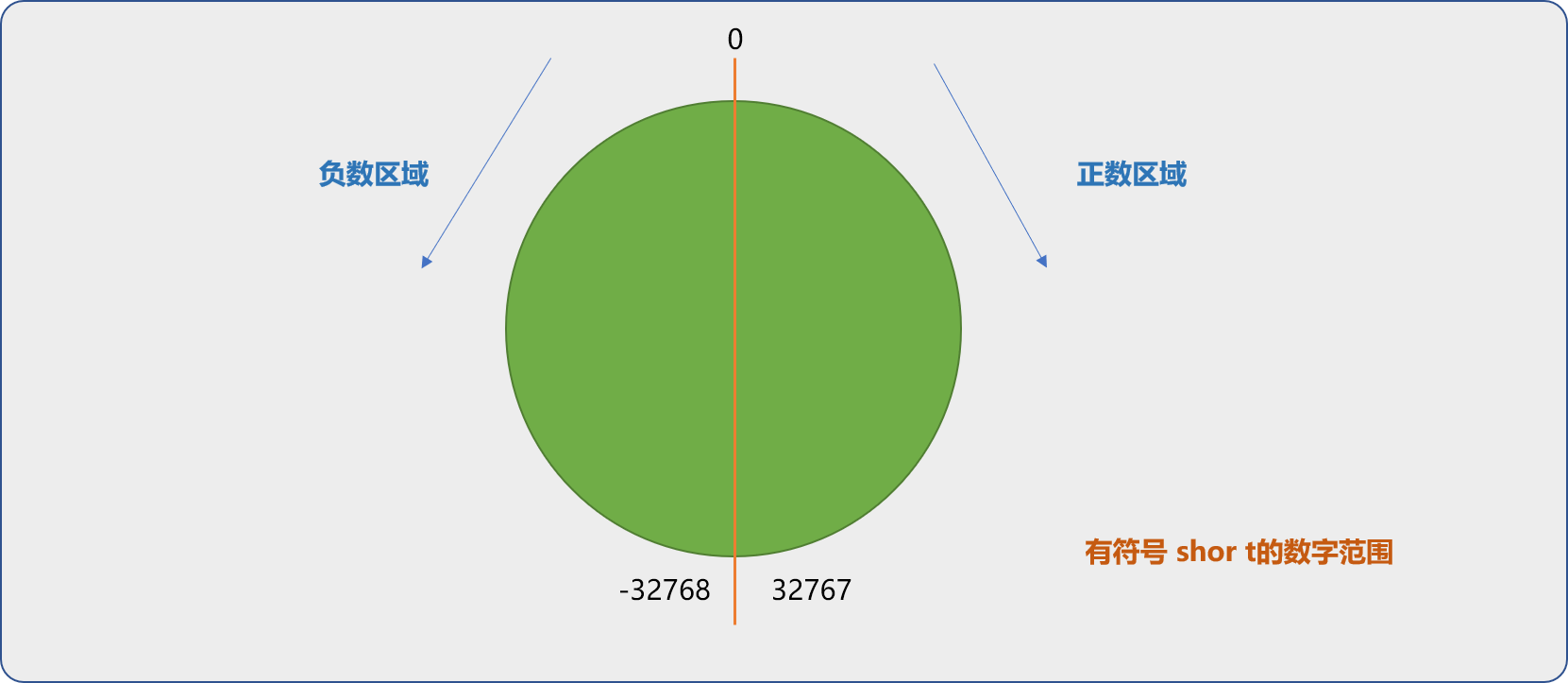
如下程式碼,因溢位,超過了負數區域最小值,會溢位到正數區域。
short num1=-32768;
short num2=num1-1;
cout<<num2;
//輸出結果:32767
資料溢位發生在當把資料型別範圍大的資料儲存到資料型別小的型別變數中時。
double資料儲存到int型別變數中。int型別的資料儲存到short型別變數中。long long int型別的資料儲存到int型別變數中時。- ……
數學運運算元也可以用於指標型別運算,因指標變數其資料本質就是數位資料。但指標變數不能用於乘法和除法,加、減的語意是指標的向前後後移動,乘法、除法沒有語意價值。
3.6 型別轉換
根據運運算元的基本使用原則,要求所有運算元的型別必須相同。
有時,在一個表示式中,即使存在多個運算元的型別不一致,也能正常工作。那是因為,編譯器會把不同的資料型別轉換成一致,然後再進行運算。
由編譯器完成的型別轉換,稱為自動(隱式)型別轉換:
- 整型提升:
C++將bool、char、unsigned char、signed char和short值轉換為int。這些轉換被稱為整型提升。 - 浮點提升:整型型別自動向浮點型別轉換,如
int向double轉換。這種轉換是不會存在資料丟失問題,但會產生空間浪費。 - 向下縮窄: 當目標型別小於原型別時,如
double向int轉換,int型別向short轉換時,這種轉換是可以的,但會發生資料丟失的情況。可能會得不到預期結果。
碗裡的水倒到缸裡,不會丟失水。
缸裡面的水倒到碗裡,如果缸裡面的水很少,不夠或者剛夠一碗水,不會發生水丟失。但是,這裡會有潛在丟失問題,因為生活常識告訴我們,缸裡面的水往往是要超過一個碗所能盛下的容量。
所以,向下縮窄存在潛在的資料丟失風險。
如下程式碼,其中發生了 2 次自動型別轉換,有資料丟失的潛在風險。
double num1=7;
int num2=3;
int res=num1/num2;
cout<<res<<endl;
//輸出結果: 2
- 浮點提升:
num2中的資料會被轉換成double資料型別,讓右邊的表示式符合同型別原則。此時,右邊表示式運算後的結果型別為double。這一步不會發生資料丟失問題。 - 向下縮窄: 左邊的
res變數型別為int,編譯器會把右邊的double型別結果轉換成int。如果數值大於int型別範圍時,則會出現丟失精度問題。
如下程式碼,則不會發生資料丟失問題:
double num1=7;
int num2=3;
double res=num1/num2;
cout<<res<<endl;
//輸出結果:2.33333
如下的程式碼,也會發生自動型別轉換。
int num1=20;
char num2='A';
int res=num1+num2;
cout<<res<<endl;
//輸出結果: 85
char型別會轉換成int型別。字元儲存在計算機上時,需要對其進行數位編碼,字元轉換成int的數位是底層的編碼數位。
如下程式碼,也會發生自動型別。
int num1=20;
bool num2=true;
int res=num1+num2;
cout<<res<<endl;
C++中,bool資料型別本質上就是int型別。true會轉換為1。false會轉換為0。
3.7 {}賦值語法
C++在進行自動型別轉換時,如果目標型別小於原型別時,也是能夠轉換的,這種現象叫縮窄。縮窄會存在潛存資料安全問題。C++11提供了{}賦值語法,會對超過範圍的縮窄進行編譯提示。如下程式碼。
- 因
44555數位已經超過char範圍,向下縮窄不被允許。
char c1= {44555};
- 因
X是一個變數,在執行時,x有可能被修改,並讓其值大於char數位範圍,向下縮窄不被允許。
int x=66;
char c4={x};
3.8 強制型別轉換
C++允許開發者顯式地進行型別轉換。語法格式有 2 種:
- (目標型別名)變數。
- 目標型別名(變數)。
強制型別轉換不會修改變數本身,而是建立一個新的值。用於表示式中進行計算。
double num1=23.6;
//C++強制型別轉換語法
int num2=double(num1);
cout<<num2<<endl;
//C 強制型別轉換語法
num2=(double)num1;
cout<<num2<<endl;
C++還提供了 4 個型別轉換運運算元,使得轉換過程更規範。這裡只做簡要介紹,有興趣者可以深入瞭解一下。
dynamic_cast。在類層次結構中進行向上轉換。const_cast。用於執行只有一種用途的型別轉換,即改變值為const或volatile。static_cast。只有當型別之間可以隱式轉換時才能轉換。reinterpret_cast。用於一些有很大潛在危險的型別轉換。
3.9 auto 語法
auto關鍵字在C++的作用是自動型別推導。在宣告變數時,可以使用 auto關鍵字,不指定變數的型別說明。編譯器會根據變數中所儲存的資料的型別自動推匯出資料型別。
// num 是浮點資料型別
auto num=5.3;
//num1 是整型資料型別
auto num1=4;
如 Python、JS就是一種動態語言,表現在資料型別可以底層編譯器自動識別。
雖然C++有 auto語法,但C++歸屬於弱型別語言,在資料型別識別上,一半依賴於開發者的語法約束,一半依賴編譯器的自動識別。
4. 總結
因C++語言的開放性,資料型別的自我適應性非常靈活。在一個表示式,當出現型別不同的情況時,編譯器會試圖進行各種型別上的轉換,讓表示式符合型別相同的運算原則。
寬鬆的好處是速度快,但也會帶來潛在的風險,開發者應該儘可能在語法上對資料型別進行約束,不要過於依賴編譯器。養成良好的編碼習慣。