Snowflake(雪花演演算法),什麼情況下會衝突?
文章首發在公眾號(龍臺的技術筆記),之後同步到部落格園和個人網站:xiaomage.info

分散式系統中,有一些需要使用全域性唯一 ID 的場景,這種時候為了防止 ID 衝突可以使用 36 位的 UUID,但是 UUID 有一些缺點,首先他相對比較長,另外 UUID 一般是無序的
有些時候我們希望能使用一種簡單些的 ID,並且希望 ID 能夠按照時間有序生成
什麼是雪花演演算法
Snowflake 中文的意思是雪花,所以常被稱為雪花演演算法,是 Twitter 開源的分散式 ID 生成演演算法
Twitter 雪花演演算法生成後是一個 64bit 的 long 型的數值,組成部分引入了時間戳,基本保持了自增
SnowFlake 演演算法的優點:
- 高效能高可用:生成時不依賴於資料庫,完全在記憶體中生成
- 高吞吐:每秒鐘能生成數百萬的自增 ID
- ID 自增:存入資料庫中,索引效率高
SnowFlake 演演算法的缺點:
依賴與系統時間的一致性,如果系統時間被回撥,或者改變,可能會造成 ID 衝突或者重複
雪花演演算法組成
snowflake 結構如下圖所示:

包含四個組成部分
不使用:1bit,最高位是符號位,0 表示正,1 表示負,固定為 0
時間戳:41bit,毫秒級的時間戳(41 位的長度可以使用 69 年)
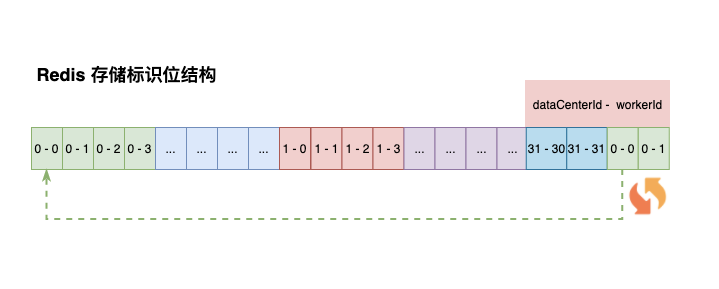
標識位:5bit 資料中心 ID,5bit 工作機器 ID,兩個標識位組合起來最多可以支援部署 1024 個節點

序列號:12bit 遞增序列號,表示節點毫秒內生成重複,通過序列號表示唯一,12bit 每毫秒可產生 4096 個 ID
通過序列號 1 毫秒可以產生 4096 個不重複 ID,則 1 秒可以生成 4096 * 1000 = 409w ID
預設的雪花演演算法是 64 bit,具體的長度可以自行設定。如果希望執行更久,增加時間戳的位數;如果需要支援更多節點部署,增加標識位長度;如果並行很高,增加序列號位數
總結:雪花演演算法並不是一成不變的,可以根據系統內具體場景進行客製化
雪花演演算法適用場景
因為雪花演演算法有序自增,保障了 MySQL 中 B+ Tree 索引結構插入高效能
所以,日常業務使用中,雪花演演算法更多是被應用在資料庫的主鍵 ID 和業務關聯主鍵
雪花演演算法生成 ID 重複問題
假設:一個訂單微服務,通過雪花演演算法生成 ID,共部署三個節點,標識位一致
此時有 200 並行,均勻散佈三個節點,三個節點同一毫秒同一序列號下生成 ID,那麼就會產生重複 ID
通過上述假設場景,可以知道雪花演演算法生成 ID 衝突存在一定的前提條件
- 服務通過叢集的方式部署,其中部分機器標識位一致
- 業務存在一定的並行量,沒有並行量無法觸發重複問題
- 生成 ID 的時機:同一毫秒下的序列號一致
標識位如何定義
如果能保證標識位不重複,那麼雪花 ID 也不會重複
通過上面的案例,知道了 ID 重複的必要條件。如果要避免服務內產生重複的 ID,那麼就需要從標識位上動文章
我們先看看開源框架中使用雪花演演算法,如何定義標識位
Mybatis-Plus v3.4.2 雪花演演算法實現類 Sequence,提供了兩種構造方法:無參構造,自動生成 dataCenterId 和 workerId;有參構造,建立 Sequence 時明確指定標識位
Hutool v5.7.9 參照了 Mybatis-Plus dataCenterId 和 workerId 生成方案,提供了預設實現
一起看下 Sequence 的建立預設無參構造,如何生成 dataCenterId 和 workerId
public static long getDataCenterId(long maxDatacenterId) {
long id = 1L;
final byte[] mac = NetUtil.getLocalHardwareAddress();
if (null != mac) {
id = ((0x000000FF & (long) mac[mac.length - 2])
| (0x0000FF00 & (((long) mac[mac.length - 1]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
return id;
}
入參 maxDatacenterId 是一個固定值,代表資料中心 ID 最大值,預設值 31
為什麼最大值要是 31?因為 5bit 的二進位制最大是 11111,對應十進位制數值 31
獲取 dataCenterId 時存在兩種情況,一種是網路介面為空,預設取 1L;另一種不為空,通過 Mac 地址獲取 dataCenterId
可以得知,dataCenterId 的取值與 Mac 地址有關
接下來再看看 workerId
public static long getWorkerId(long datacenterId, long maxWorkerId) {
final StringBuilder mpid = new StringBuilder();
mpid.append(datacenterId);
try {
mpid.append(RuntimeUtil.getPid());
} catch (UtilException igonre) {
//ignore
}
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
入參 maxWorkderId 也是一個固定值,代表工作機器 ID 最大值,預設值 31;datacenterId 取自上述的 getDatacenterId 方法
name 變數值為 PID@IP,所以 name 需要根據 @ 分割並獲取下標 0,得到 PID
通過 MAC + PID 的 hashcode 獲取16個低位,進行運算,最終得到 workerId
分配標識位
Mybatis-Plus 標識位的獲取依賴 Mac 地址和程序 PID,雖然能做到儘量不重複,但仍有小几率
標識位如何定義才能不重複?有兩種方案:預分配和動態分配
預分配
應用上線前,統計當前服務的節點數,人工去申請標識位
這種方案,沒有程式碼開發量,在服務節點固定或者專案少可以使用,但是解決不了服務節點動態擴容性問題
動態分配
通過將標識位存放在 Redis、Zookeeper、MySQL 等中介軟體,在服務啟動的時候去請求標識位,請求後標識位更新為下一個可用的
通過存放標識位,延伸出一個問題:雪花演演算法的 ID 是 服務內唯一還是全域性唯一
以 Redis 舉例,如果要做服務內唯一,存放標識位的 Redis 節點使用自己專案內的就可以;如果是全域性唯一,所有使用雪花演演算法的應用,要用同一個 Redis 節點
兩者的區別僅是 不同的服務間是否公用 Redis。如果沒有全域性唯一的需求,最好使 ID 服務內唯一,因為這樣可以避免單點問題
服務的節點數超過 1024,則需要做額外的擴充套件;可以擴充套件 10 bit 標識位,或者選擇開源分散式 ID 框架
動態分配實現方案
Redis 儲存一個 Hash 結構 Key,包含兩個鍵值對:dataCenterId 和 workerId
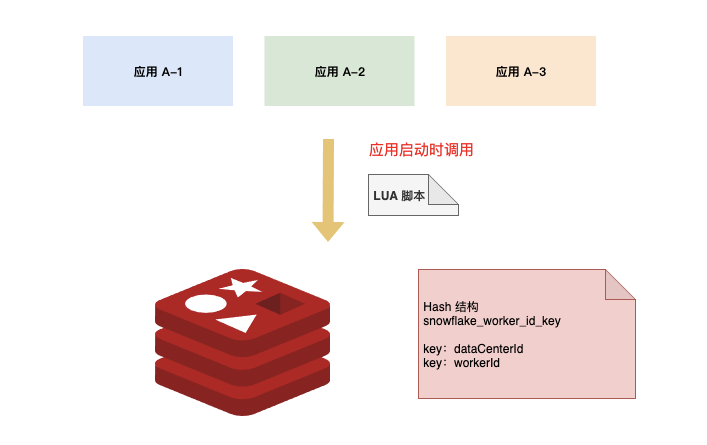
在應用啟動時,通過 Lua 指令碼去 Redis 獲取標識位。dataCenterId 和 workerId 的獲取與自增在 Lua 指令碼中完成,呼叫返回後就是可用的標示位
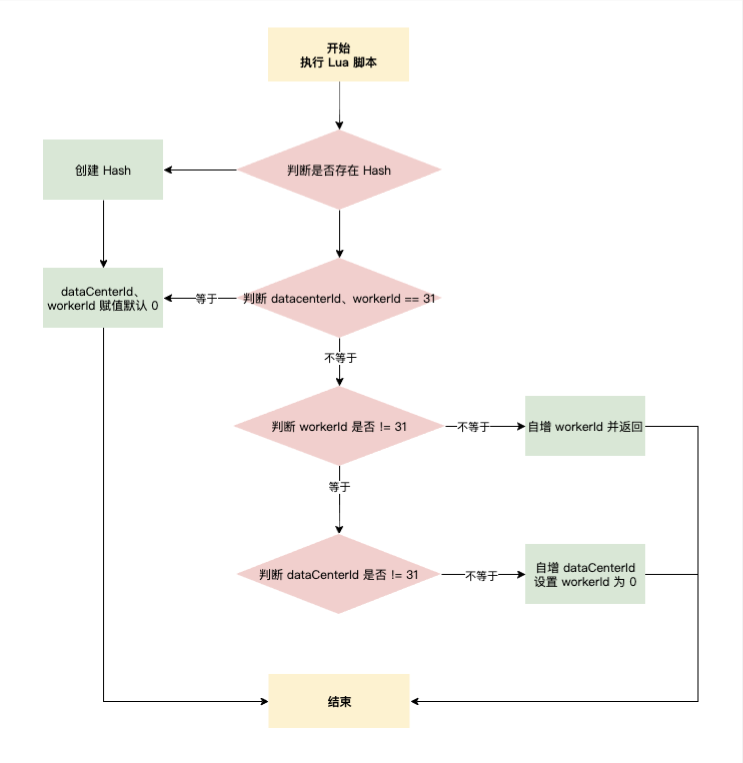
具體 Lua 指令碼邏輯如下:
- 第一個服務節點在獲取時,Redis 可能是沒有 snowflake_work_id_key 這個 Hash 的,應該先判斷 Hash 是否存在,不存在初始化 Hash,dataCenterId、workerId 初始化為 0
- 如果 Hash 已存在,判斷 dataCenterId、workerId 是否等於最大值 31,滿足條件初始化 dataCenterId、workerId 設定為 0 返回
- dataCenterId 和 workerId 的排列組合一共是 1024,在進行分配時,先分配 workerId
- 判斷 workerId 是否 != 31,條件成立對 workerId 自增,並返回;如果 workerId = 31,自增 dataCenterId 並將 workerId 設定為 0
dataCenterId、workerId 是一直向下推進的,總體形成一個環狀。通過 Lua 指令碼的原子性,保證 1024 節點下的雪花演演算法生成不重複。如果標識位等於 1024,則從頭開始繼續迴圈推進
開源分散式 ID 框架
Leaf 和 Uid 都有實現雪花演演算法,Leaf 額外提供了號段模式生成 ID
美團 Leaf:https://github.com/Meituan-Dianping/Leaf
百度 Uid:https://github.com/baidu/uid-generator
雪花演演算法可以滿足大部分場景,如無必要,不建議引入開源方案增加系統複雜度
回顧總結
文章通過圖文並茂的方式幫助讀者梳理了一遍什麼是雪花演演算法,以及如何解決雪花演演算法生成 ID 衝突的問題
關於雪環演演算法生成 ID 衝突問題,文中給了一種方案:分配標示位;通過分配雪花演演算法的組成標識位,來達到預設 1024 節點下 ID 生成唯一
可以去看 Hutool 或者 Mybatis-Plus 雪花演演算法的具體實現,幫助大家更好的理解
雪花演演算法不是萬能的,並不能適用於所有場景。如果 ID 要求全域性唯一併且服務節點超出 1024 節點,可以選擇修改演演算法本身的組成,即擴充套件標識位,或者選擇開源方案:LEAF、UID
創作不易,文章看完有幫助,點關注支援一下,祝好