CVPR2022 | 弱監督多標籤分類中的損失問題
前言 本文提出了一種新的弱監督多標籤分類(WSML)方法,該方法拒絕或糾正大損失樣本,以防止模型記憶有噪聲的標籤。由於沒有繁重和複雜的元件,提出的方法在幾個部分標籤設定(包括Pascal VOC 2012、MS COCO、NUSWIDE、CUB和OpenImages V3資料集)上優於以前最先進的WSML方法。各種分析還表明,方法的實際效果很好,驗證了在弱監督的多標籤分類中正確處理損失很重要。
歡迎關注公眾號CV技術指南,專注於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀、CV招聘資訊。

論文:Large Loss Matters in Weakly Supervised Multi-Label Classification
論文:http://arxiv.org/pdf/2206.03740
程式碼:https://github.com/snucml/LargeLossMatters
背景
弱監督多標籤分類(WSML)任務是利用每幅影象的部分觀察標籤來學習多標籤分類,由於其巨大的標註成本,變得越來越重要。
目前,有兩種簡單的方法可以使用部分標籤來訓練模型。一種是隻使用觀察到的標籤來訓練模型,而忽略未觀察到的標籤。另一種是假設所有未觀察到的標籤都是負面的,並將其納入訓練,因為在多標籤設定中,大多數標籤都是負面的。
但第二種方法有一個侷限性,即這種假設會在標籤中產生一些噪聲,從而妨礙模型學習,因此之前的工作大多遵循第一種方法,並嘗試使用各種技術(如引導或正則化)探索未觀察標籤的線索。然而,這些方法包括大量計算或複雜的優化管道。
基於以上思路,作者假設,如果標籤噪聲能夠得到妥善處理,第二種方法可能是一個很好的起點,因為它具有將許多真正的負面標籤納入模型訓練的優勢。因此,作者就從噪聲標籤學習的角度來看待WSML問題。
眾所周知,當訓練帶有噪聲標籤的模型時,該模型首先適應乾淨的標籤,然後開始記憶噪聲標籤。雖然之前的研究表明記憶效應僅在有噪聲的多類別分類場景中存在,但作者發現,在有噪聲的多標籤分類場景中也存在同樣的效應。如圖1所示,在訓練期間,來自乾淨標籤(真負樣本)的損失值從一開始就減小,而來自噪聲標籤(假負樣本)的損失從中間減小。
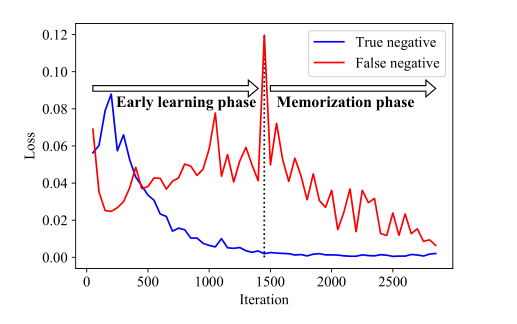
圖1 WSML中的記憶效應
基於這一發現,作者開發了三種不同的方案,通過在訓練過程中拒絕或糾正大損失樣本,防止誤報標籤被記憶到多標籤分類模型中。
貢獻
1) 首次通過實驗證明,記憶效應發生在有噪聲的多標籤分類過程中。
2) 提出了一種新的弱監督多標籤分類方案,該方案明確利用了帶噪聲標籤的學習技術。
3)提出的方法輕巧且簡單,在各種部分標籤資料集上實現了最先進的分類效能。
方法
在本文中,作者提出了新的WSML方法,其動機是基於噪聲多類學習的思想,它忽略了模型訓練過程中的巨大損失。通過在損失函數中進一步引入了權重項λi:
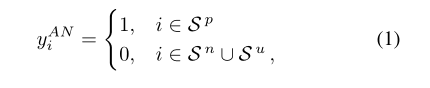
作者提出了三種提供權重λi的不同方案,示意圖描述如圖2所示。
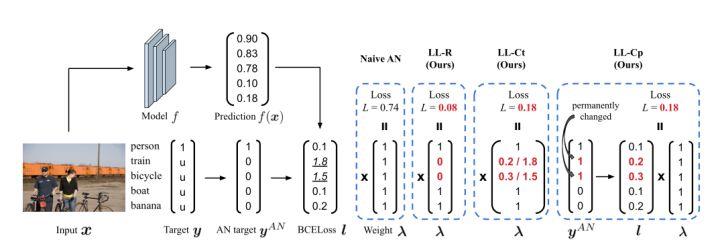
圖2 提出的方法的總體管道
1.損失拒絕
處理大損耗樣本的一種方法是通過設定λi=0來拒絕它。在有噪聲的多類任務中,B.Han等人提出了一種在訓練過程中逐漸增加拒絕率的方法。作者同樣設定函數λi,
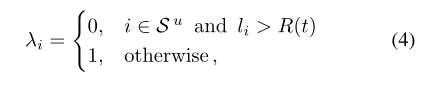
由於模型在初始階段學習乾淨的模式,因此在t=1時不拒絕任何損失值。在每次迭代中使用小批次而不是完整批次D′來組成損失集。作者將此方法稱為LL-R。
2. 損失糾正(臨時)
處理大損失樣本的另一種方法是糾正而不是拒絕它。在多標籤設定中,可以通過將相應的註釋從負值切換到正值來輕鬆實現這一點。「臨時」一詞的意思是,它不改變實際標籤,而只使用根據修改後的標籤計算的損失,將函數λi定義為
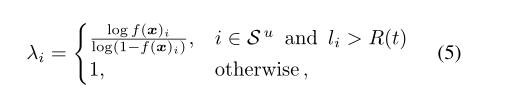
作者將此方法命名為LL-Ct。這種方法的優點是,它從未觀察到的標籤中增加了真實陽性標籤的數量。
3. 損失糾正(永久)
通過永久更正標籤來更積極地處理較大的損失值。直接將標籤從陰性改為陽性,並在下一個訓練過程中使用修改後的標籤。為此,為每種情況定義λi=1,並修改標籤如下:
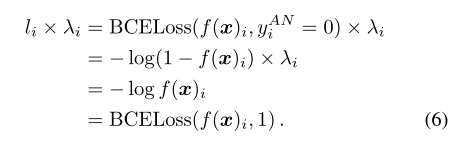
作者將此方法命名為LL-Cp。
實驗
表2 人為建立的部分標籤資料集的定量結果
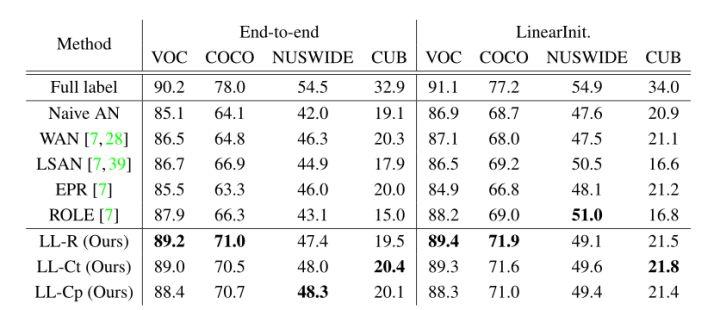
表3 OpenImages V3資料集中的定量結果
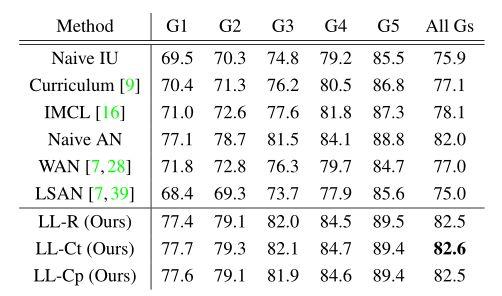
圖3 人為生成COCO部分標籤資料集的定性結果
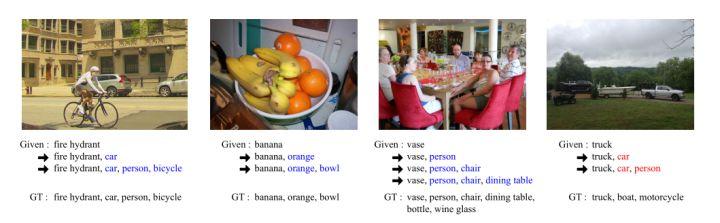
圖4 COCO資料集上建議的方法的精度分析
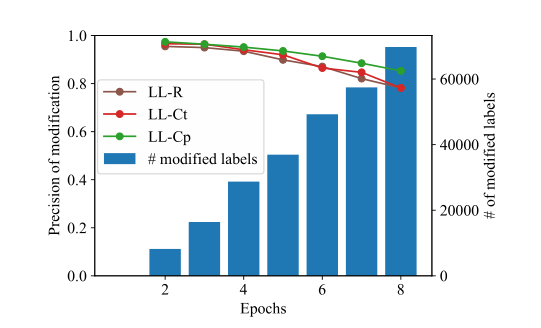
圖5 LL-Ct對COCO資料集的超引數效應
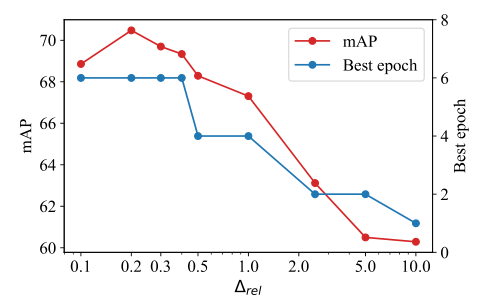
圖6 使用較少數量的影象進行訓練
表4 Pointing Game
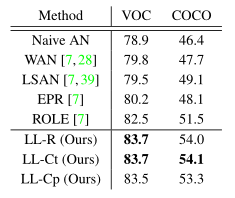
結論
在本文中,作者提出了損失修改方案,該方案拒絕或糾正了在訓練帶有部分標記註釋的多標籤分類模型時出現的大損失樣本。這源於經驗觀察,即記憶效應也發生在嘈雜的多標籤分類場景中。
雖然不包括繁重的和複雜的元件,但作者的方案成功地防止了多標籤分類模型記憶有噪聲的假陰性標籤,在各種部分標記的多標籤資料集上實現了最先進的效能。
---------------------------------------------------------------------------------
CV技術指南建立了一個計算機視覺技術交流群和免費版的知識星球,目前星球內人數已經700+,主題數量達到200+。
知識星球內將會每天釋出一些作業,用於引導大家去學一些東西,大家可根據作業來持續打卡學習。CV技術群內每天都會發最近幾天出來的頂會論文,大家可以選擇感興趣的論文去閱讀,持續follow最新技術,若是看完後寫個解讀給我們投稿,還可以收到稿費。 另外,技術群內和本人朋友圈內也將釋出各個期刊、會議的徵稿通知,若有需要的請掃描加好友,並及時關注。
加群加星球方式:關注公眾號CV技術指南,獲取編輯微信,邀請加入。
歡迎關注公眾號CV技術指南,專注於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀、CV招聘資訊。

歡迎可以寫以下內容的朋友聯絡我(關注公眾號後獲取聯絡方式)。
- 最新頂會的解讀。例如最近的CVPR2022論文。
- 各個方向的系統性綜述、主要模型發展演變、各個模型的創新思路和優缺點、程式碼解析等。如目標檢測大總結:對目標檢測從傳統方法到深度學習的所有大總結,主要包括傳統方法檢測、RCNN系列、YOLO系列、anchor-free系列、小目標檢測方法總結、小樣本目標檢測方法總結、視訊中的目標檢測方法總結、目標檢測使用的損失函數總結等內容。支援邊學邊寫。
- TVM入門到實踐的教學
- MNN入門到實踐的教學
- OpenVINO入門到實踐的教學
- libtorch入門到實踐的教學
- Oneflow入門到實踐的教學
- Detectron入門到實踐的教學
- caffe原始碼閱讀
- 深度學習從入門到精通(從折積神經網路開始講起)
- 若自己有想寫的且這上面沒提到的,可以跟我聯絡。宣告:有報酬,具體請聯絡詳談。
公眾號其它文章
CVPR2022 | iFS-RCNN:一種增量小樣本範例分割器
CVPR2022 | Time 3D:用於自動駕駛的端到端聯合單目三維物體檢測與跟蹤
CVPR2022 | A ConvNet for the 2020s & 如何設計神經網路總結
CVPR2022 | PanopticDepth:深度感知全景分割的統一框架
CVPR2022 | 未知目標檢測模組STUD:學習視訊中的未知目標
從零搭建Pytorch模型教學(五)編寫訓練過程--一些基本的設定
從零搭建Pytorch模型教學(四)編寫訓練過程--引數解析
從零搭建Pytorch模型教學(三)搭建Transformer網路