剖析 SPI 在 Spring 中的應用
vivo 網際網路伺服器團隊 - Ma Jian
一、概述
SPI(Service Provider Interface),是Java內建的一種服務提供發現機制,可以用來提高框架的擴充套件性,主要用於框架的開發中,比如Dubbo,不同框架中實現略有差異,但核心機制相同,而Java的SPI機制可以為介面尋找服務實現。SPI機制將服務的具體實現轉移到了程式外,為框架的擴充套件和解耦提供了極大的便利。
得益於SPI優秀的能力,為模組功能的動態擴充套件提供了很好的支撐。
本文會先簡單介紹Java內建的SPI和Dubbo中的SPI應用,重點介紹分析Spring中的SPI機制,對比Spring SPI和Java內建的SPI以及與 Dubbo SPI的異同。
二、Java SPI
Java內建的SPI通過java.util.ServiceLoader類解析classPath和jar包的META-INF/services/目錄 下的以介面全限定名命名的檔案,並載入該檔案中指定的介面實現類,以此完成呼叫。
2.1 Java SPI
先通過程式碼來了解下Java SPI的實現
① 建立服務提供介面
package jdk.spi;
// 介面
public interface DataBaseSPI {
public void dataBaseOperation();
}
② 建立服務提供介面的實現類
- MysqlDataBaseSPIImpl
實現類1
package jdk.spi.impl;
import jdk.spi.DataBaseSPI;
public class MysqlDataBaseSPIImpl implements DataBaseSPI {
@Override
public void dataBaseOperation() {
System.out.println("Operate Mysql database!!!");
}
}
- OracleDataBaseSPIImpl
實現類2
package jdk.spi.impl;
import jdk.spi.DataBaseSPI;
public class OracleDataBaseSPIImpl implements DataBaseSPI {
@Override
public void dataBaseOperation() {
System.out.println("Operate Oracle database!!!");
}
}
③ 在專案META-INF/services/目錄下建立jdk.spi.DataBaseSPI檔案

jdk.spi.DataBaseSPI
jdk.spi.impl.MysqlDataBaseSPIImpl
jdk.spi.impl.OracleDataBaseSPIImpl
④ 執行程式碼:
JdkSpiTest#main()
package jdk.spi;
import java.util.ServiceLoader;
public class JdkSpiTest {
public static void main(String args[]){
// 載入jdk.spi.DataBaseSPI檔案中DataBaseSPI的實現類(懶載入)
ServiceLoader<DataBaseSPI> dataBaseSpis = ServiceLoader.load(DataBaseSPI.class);
// ServiceLoader實現了Iterable,故此處可以使用for迴圈遍歷載入到的實現類
for(DataBaseSPI spi : dataBaseSpis){
spi.dataBaseOperation();
}
}
}
⑤ 執行結果:
Operate Mysql database!!!
Operate Oracle database!!!
2.2 原始碼分析
上述實現即為使用Java內建SPI實現的簡單範例,ServiceLoader是Java內建的用於查詢服務提供介面的工具類,通過呼叫load()方法實現對服務提供介面的查詢(嚴格意義上此步並未真正的開始查詢,只做初始化),最後遍歷來逐個存取服務提供介面的實現類。
上述存取服務實現類的方式很不方便,如:無法直接使用某個服務,需要通過遍歷來存取服務提供介面的各個實現,到此很多同學會有疑問:
- Java內建的存取方式只能通過遍歷實現嗎?
- 服務提供介面必須放到META-INF/services/目錄下?是否可以放到其他目錄下?
在分析原始碼之前先給出答案:兩個都是的;Java內建的SPI機制只能通過遍歷的方式存取服務提供介面的實現類,而且服務提供介面的組態檔也只能放在META-INF/services/目錄下。
ServiceLoader部分原始碼
public final class ServiceLoader<S> implements Iterable<S>{
// 服務提供介面對應檔案放置目錄
private static final String PREFIX = "META-INF/services/";
// The class or interface representing the service being loaded
private final Class<S> service;
// 類載入器
private final ClassLoader loader;
// The access control context taken when the ServiceLoader is created
private final AccessControlContext acc;
// 按照初始化順序快取服務提供介面範例
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// 內部類,實現了Iterator介面
private LazyIterator lookupIterator;
}
從原始碼中可以發現:
- ServiceLoader類本身實現了Iterable介面並實現了其中的iterator方法,iterator方法的實現中呼叫了LazyIterator這個內部類中的方法,解析完服務提供介面檔案後最終結果放在了Iterator中返回,並不支援服務提供介面實現類的直接存取。
- 所有服務提供介面的對應檔案都是放置在META-INF/services/目錄下,final型別決定了PREFIX目錄不可變更。
所以Java內建的SPI機制思想是非常好的,但其內建實現上的不足也很明顯。
三、Dubbo SPI
Dubbo SPI沿用了Java SPI的設計思想,但在實現上有了很大的改進,不僅可以直接存取擴充套件類,而且在存取的靈活性和擴充套件的便捷性都做了很大的提升。
3.1 基本概念
① 擴充套件點
一個Java介面,等同於服務提供介面,需用@SPI註解修飾。
② 擴充套件
擴充套件點的實現類。
③ 擴充套件類載入器:ExtensionLoader
類似於Java SPI的ServiceLoader,主要用來載入並範例化擴充套件類。一個擴充套件點對應一個擴充套件載入器。
④ Dubbo擴充套件檔案載入路徑
Dubbo框架支援從以下三個路徑來載入擴充套件類:
- META-INF/dubbo/internal
- META-INF/dubbo
- META-INF/services
Dubbo框架針對三個不同路徑下的擴充套件組態檔對應三個策略類:
- DubboInternalLoadingStrategy
- DubboLoadingStrategy
- ServicesLoadingStrategy
三個路徑下的擴充套件組態檔並沒有特殊之處,一般情況下:
- META-INF/dubbo對開發者開放
- META-INF/dubbo/internal 用來載入Dubbo內部的擴充套件點
- META-INF/services 相容Java SPI
⑤ 擴充套件組態檔
和Java SPI不同,Dubbo的擴充套件組態檔中擴充套件類都有一個名稱,便於在應用中參照它們。
如:Dubbo SPI擴充套件組態檔
#擴充套件範例名稱=擴充套件點實現類
adaptive=org.apache.dubbo.common.compiler.support.AdaptiveCompiler
jdk=org.apache.dubbo.common.compiler.support.JdkCompiler
javassist=org.apache.dubbo.common.compiler.support.JavassistCompiler
3.2 Dubbo SPI
先通過程式碼來演示下 Dubbo SPI 的實現。
① 建立擴充套件點(即服務提供介面)
擴充套件點
package dubbo.spi;
import org.apache.dubbo.common.extension.SPI;
@SPI // 註解標記當前介面為擴充套件點
public interface DataBaseSPI {
public void dataBaseOperation();
}
② 建立擴充套件點實現類
- MysqlDataBaseSPIImpl
擴充套件類1
package dubbo.spi.impl;
import dubbo.spi.DataBaseSPI;
public class MysqlDataBaseSPIImpl implements DataBaseSPI {
@Override
public void dataBaseOperation() {
System.out.println("Dubbo SPI Operate Mysql database!!!");
}
}
- OracleDataBaseSPIImpl
擴充套件類2
package dubbo.spi.impl;
import dubbo.spi.DataBaseSPI;
public class OracleDataBaseSPIImpl implements DataBaseSPI {
@Override
public void dataBaseOperation() {
System.out.println("Dubbo SPI Operate Oracle database!!!");
}
}
③在專案META-INF/dubbo/目錄下建立dubbo.spi.DataBaseSPI檔案:

dubbo.spi.DataBaseSPI
#擴充套件範例名稱=擴充套件點實現類
mysql = dubbo.spi.impl.MysqlDataBaseSPIImpl
oracle = dubbo.spi.impl.OracleDataBaseSPIImpl
PS:檔案內容中,等號左邊為該擴充套件類對應的擴充套件範例名稱,右邊為擴充套件類(內容格式為一行一個擴充套件類,多個擴充套件類分為多行)
④ 執行程式碼:
DubboSpiTest#main()
package dubbo.spi;
import org.apache.dubbo.common.extension.ExtensionLoader;
public class DubboSpiTest {
public static void main(String args[]){
// 使用擴充套件類載入器載入指定擴充套件的實現
ExtensionLoader<DataBaseSPI> dataBaseSpis = ExtensionLoader.getExtensionLoader(DataBaseSPI.class);
// 根據指定的名稱載入擴充套件範例(與dubbo.spi.DataBaseSPI中一致)
DataBaseSPI spi = dataBaseSpis.getExtension("mysql");
spi.dataBaseOperation();
DataBaseSPI spi2 = dataBaseSpis.getExtension("oracle");
spi2.dataBaseOperation();
}
}
⑤ 執行結果:
Dubbo SPI Operate Mysql database!!!
Dubbo SPI Operate Oracle database!!!
從上面的程式碼實現直觀來看,Dubbo SPI在使用上和Java SPI比較類似,但也有差異。
相同:
- 擴充套件點即服務提供介面、擴充套件即服務提供介面實現類、擴充套件組態檔即services目錄下的組態檔 三者相同。
- 都是先建立載入器然後存取具體的服務實現類,包括深層次的在初始化載入器時都未實時解析擴充套件組態檔來獲取擴充套件點實現,而是在使用時才正式解析並獲取擴充套件點實現(即懶載入)。
不同:
- 擴充套件點必須使用@SPI註解修飾(原始碼中解析會對此做校驗)。
- Dubbo中擴充套件組態檔每個擴充套件(服務提供介面實現類)都指定了一個名稱。
- Dubbo SPI在獲取擴充套件類範例時直接通過擴充套件組態檔中指定的名稱獲取,而非Java SPI的迴圈遍歷,在使用上更靈活。
3.3 原始碼分析
以上述的程式碼實現作為原始碼分析入口,瞭解下Dubbo SPI是如何實現的。
ExtensionLoader
① 通過ExtensionLoader.getExtensionLoader(Classtype)建立對應擴充套件型別的擴充套件載入器。
ExtensionLoader#getExtensionLoader()
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
if (type == null) {
throw new IllegalArgumentException("Extension type == null");
}
// 校驗當前型別是否為介面
if (!type.isInterface()) {
throw new IllegalArgumentException("Extension type (" + type + ") is not an interface!");
}
// 介面上是否使用了@SPI註解
if (!withExtensionAnnotation(type)) {
throw new IllegalArgumentException("Extension type (" + type +
") is not an extension, because it is NOT annotated with @" + SPI.class.getSimpleName() + "!");
}
// 從記憶體中讀取該擴充套件點的擴充套件類載入器
ExtensionLoader<T> loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
// 記憶體中不存在則直接new一個擴充套件
if (loader == null) {
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<T>(type));
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;
}
getExtensionLoader()方法中有三點比較重要的邏輯:
- 判斷當前type型別是否為介面型別。
- 當前擴充套件點是否使用了@SPI註解修飾。
- EXTENSION_LOADERS為ConcurrentMap型別的記憶體快取,記憶體中存在該型別的擴充套件載入器則直接使用,不存在就new一個並放入記憶體快取中。
再看下new ExtensionLoader(type)原始碼
ExtensionLoader#ExtensionLoader()
// 私有構造器
private ExtensionLoader(Class<?> type) {
this.type = type;
// 建立ExtensionFactory自適應擴充套件
objectFactory = (type == ExtensionFactory.class ? null : ExtensionLoader.getExtensionLoader(ExtensionFactory.class).getAdaptiveExtension());
}
重點:構造方法為私有型別,即外部無法直接使用構造方法建立ExtensionLoader範例。
每次初始化ExtensionLoader範例都會初始化type和objectFactory ,type為擴充套件點型別;objectFactory 為ExtensionFactory型別。
② 使用getExtension()獲取指定名稱的擴充套件類範例getExtension為過載方法,分別為getExtension(String name)和getExtension(String name, boolean wrap),getExtension(String name)方法最終呼叫的還是getExtension(String name, boolean wrap)方法。
ExtensionLoader#getExtension()
public T getExtension(String name) {
// 呼叫兩個引數的getExtension方法,預設true表示需要對擴充套件範例做包裝
return getExtension(name, true);
}
public T getExtension(String name, boolean wrap) {
if (StringUtils.isEmpty(name)) {
throw new IllegalArgumentException("Extension name == null");
}
if ("true".equals(name)) {
return getDefaultExtension();
}
// 獲取Holder範例,先從ConcurrentMap型別的記憶體快取中取,沒值會new一個並存放到記憶體快取中
// Holder用來存放一個型別的值,這裡用於存放擴充套件範例
final Holder<Object> holder = getOrCreateHolder(name);
// 從Holder讀取該name對應的範例
Object instance = holder.get();
if (instance == null) {
// 同步控制
synchronized (holder) {
instance = holder.get();
// double check
if (instance == null) {
// 不存在擴充套件範例則解析擴充套件組態檔,實時建立
instance = createExtension(name, wrap);
holder.set(instance);
}
}
}
return (T) instance;
}
Holder類:這裡用來存放指定擴充套件範例
③ 使用createExtension()建立擴充套件範例
ExtensionLoader#createExtension()
// 部分createExtension程式碼
private T createExtension(String name, boolean wrap) {
// 先呼叫getExtensionClasses()解析擴充套件組態檔,並生成記憶體快取,
// 然後根據擴充套件範例名稱獲取對應的擴充套件類
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
// 根據擴充套件類生成範例並對範例做包裝(主要是進行依賴注入和初始化)
// 優先從記憶體中獲取該class型別的範例
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
// 記憶體中不存在則直接初始化然後放到記憶體中
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
// 主要是注入instance中的依賴
injectExtension(instance);
......
}
createExtension()方法:建立擴充套件範例,方法中EXTENSION_INSTANCES為ConcurrentMap型別的記憶體快取,先從記憶體中取,記憶體中不存在重新建立;其中一個核心方法是getExtensionClasses():
ExtensionLoader#getExtensionClasses()
private Map<String, Class<?>> getExtensionClasses() {
// 優先從記憶體快取中讀
Map<String, Class<?>> classes = cachedClasses.get();
if (classes == null) {
// 採用同步手段解析組態檔
synchronized (cachedClasses) {
// double check
classes = cachedClasses.get();
if (classes == null) {
// 正式開始解析組態檔
classes = loadExtensionClasses();
cachedClasses.set(classes);
}
}
}
return classes;
}
cachedClasses為Holder<map<string, class>>型別的記憶體快取,getExtensionClasses中會優先讀記憶體快取,記憶體中不存在則採用同步的方式解析組態檔,最終在loadExtensionClasses方法中解析組態檔,完成從擴充套件組態檔中讀出擴充套件類:
ExtensionLoader#loadExtensionClasses()
// 在getExtensionClasses方法中是以同步的方式呼叫,是執行緒安全
private Map<String, Class<?>> loadExtensionClasses() {
// 快取預設擴充套件名稱
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
// strategies策略類集合,分別對應dubbo的三個組態檔目錄
for (LoadingStrategy strategy : strategies) {
loadDirectory(extensionClasses, strategy.directory(), type.getName(), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
loadDirectory(extensionClasses, strategy.directory(), type.getName().replace("org.apache", "com.alibaba"), strategy.preferExtensionClassLoader(), strategy.overridden(),
strategy.excludedPackages());
}
return extensionClasses;
}
原始碼中的strategies即static volatile LoadingStrategy[] strategies陣列,通過Java SPI從META-INF/services/目錄下載入組態檔完成初始化,預設包含三個類:
- DubboInternalLoadingStrategy
- DubboLoadingStrategy
- ServicesLoadingStrategy
分別對應dubbo的三個目錄:
- META-INF/dubbo/internal
- META-INF/dubbo
- META-INF/services
上述的原始碼分析只是對Dubbo SPI做了簡要的介紹,Dubbo中對SPI的應用很廣泛,如:序列化元件、負載均衡等都應用了SPI技術,還有很多SPI功能未做分析,比如:自適應擴充套件、Activate活性擴充套件等 等,感興趣的同學可以更深入的研究。
四、Spring SPI
Spring SPI沿用了Java SPI的設計思想,但在實現上和Java SPI及Dubbo SPI也存在差異,Spring通過spring.handlers和spring.factories兩種方式實現SPI機制,可以在不修改Spring原始碼的前提下,做到對Spring框架的擴充套件開發。
4.1 基本概念
- DefaultNamespaceHandlerResolver
類似於Java SPI的ServiceLoader,負責解析spring.handlers組態檔,生成namespaceUri和NamespaceHandler名稱的對映,並範例化NamespaceHandler。
- spring.handlers
自定義標籤組態檔;Spring在2.0時便引入了spring.handlers,通過設定spring.handlers檔案實現自定義標籤並使用自定義標籤解析類進行解析實現動態擴,內容設定如:
http\://www.springframework.org/schema/c=org.springframework.beans.factory.xml.SimpleConstructorNamespaceHandler
http\://www.springframework.org/schema/p=org.springframework.beans.factory.xml.SimplePropertyNamespaceHandler
http\://www.springframework.org/schema/util=org.springframework.beans.factory.xml.UtilNamespaceHandler
spring.handlers實現的SPI是以namespaceUri作為key,NamespaceHandler作為value,建立對映關係,在解析標籤時通過namespaceUri獲取相應的NamespaceHandler來解析
- SpringFactoriesLoader
類似於Java SPI的ServiceLoader,負責解析spring.factories,並將指定介面的所有實現類範例化後返回。
- spring.factories
Spring在3.2時引入spring.factories,加強版的SPI組態檔,為Spring的SPI機制的實現提供支撐,內容設定如:
# PropertySource Loaders
org.springframework.boot.env.PropertySourceLoader=\
org.springframework.boot.env.PropertiesPropertySourceLoader,\
org.springframework.boot.env.YamlPropertySourceLoader
# Run Listeners
org.springframework.boot.SpringApplicationRunListener=\org.springframework.boot.context.event.EventPublishingRunListener
spring.factories實現的SPI是以介面的全限定名作為key,介面實現類作為value,多個實現類用逗號隔開,最終返回的結果是該介面所有實現類的範例集合
- 載入路徑
Java SPI從/META-INF/services目錄載入服務提供介面設定,而Spring預設從META-INF/spring.handlers和META-INF/spring.factories目錄載入設定,其中META-INF/spring.handlers的路徑可以通過建立範例時重新指定,而META-INF/spring.factories固定不可變。
4.2 spring.handlers
首先通過程式碼初步介紹下spring.handlers實現。
4.2.1 spring.handlers SPI
① 建立NameSpaceHandler
MysqlDataBaseHandler
package spring.spi.handlers;
import org.springframework.beans.factory.config.BeanDefinition;
import org.springframework.beans.factory.xml.NamespaceHandlerSupport;
import org.springframework.beans.factory.xml.ParserContext;
import org.w3c.dom.Element;
// 繼承抽象類
public class MysqlDataBaseHandler extends NamespaceHandlerSupport {
@Override
public void init() {
}
@Override
public BeanDefinition parse(Element element, ParserContext parserContext) {
System.out.println("MysqlDataBaseHandler!!!");
return null;
}
}
OracleDataBaseHandler
package spring.spi.handlers;
import org.springframework.beans.factory.config.BeanDefinition;
import org.springframework.beans.factory.xml.NamespaceHandlerSupport;
import org.springframework.beans.factory.xml.ParserContext;
import org.w3c.dom.Element;
public class OracleDataBaseHandler extends NamespaceHandlerSupport {
@Override
public void init() {
}
@Override
public BeanDefinition parse(Element element, ParserContext parserContext) {
System.out.println("OracleDataBaseHandler!!!");
return null;
}
}
② 在專案META-INF/目錄下建立spring.handlers檔案:
檔案內容:
spring.handlers
#一個namespaceUri對應一個handler
http\://www.mysql.org/schema/mysql=spring.spi.handlers.MysqlDataBaseHandler
http\://www.oracle.org/schema/oracle=spring.spi.handlers.OracleDataBaseHandler
③ 執行程式碼:
SpringSpiTest#main()
package spring.spi;
import org.springframework.beans.factory.xml.DefaultNamespaceHandlerResolver;
import org.springframework.beans.factory.xml.NamespaceHandler;
public class SpringSpiTest {
public static void main(String args[]){
// spring中提供的預設namespace URI解析器
DefaultNamespaceHandlerResolver resolver = new DefaultNamespaceHandlerResolver();
// 此處假設nameSpaceUri已從xml檔案中解析出來,正常流程是在專案啟動的時候會解析xml檔案,獲取到對應的自定義標籤
// 然後根據自定義標籤取得對應的nameSpaceUri
String mysqlNameSpaceUri = "http://www.mysql.org/schema/mysql";
NamespaceHandler handler = resolver.resolve(mysqlNameSpaceUri);
// 驗證自定義NamespaceHandler,這裡引數傳null,實際使用中傳具體的Element
handler.parse(null, null);
String oracleNameSpaceUri = "http://www.oracle.org/schema/oracle";
handler = resolver.resolve(oracleNameSpaceUri);
handler.parse(null, null);
}
}
④ 執行結果:
MysqlDataBaseHandler!!!
OracleDataBaseHandler!!!
上述程式碼通過解析spring.handlers實現對自定義標籤的動態解析,以NameSpaceURI作為key獲取具體的NameSpaceHandler實現類,這裡有別於Java SPI,其中:
DefaultNamespaceHandlerResolver是NamespaceHandlerResolver介面的預設實現類,用於解析自定義標籤。
- DefaultNamespaceHandlerResolver.resolve(String namespaceUri)方法以namespaceUri作為引數,預設載入各jar包中的META-INF/spring.handlers組態檔,通過解析spring.handlers檔案建立NameSpaceURI和NameSpaceHandler的對映。
- 載入組態檔的預設路徑是META-INF/spring.handlers,但可以使用DefaultNamespaceHandlerResolver(ClassLoader, String)構造方法修改,DefaultNamespaceHandlerResolver有多個過載方法。
- DefaultNamespaceHandlerResolver.resolve(String namespaceUri)方法主要被BeanDefinitionParserDelegate的parseCustomElement()和decorateIfRequired()方法中呼叫,所以spring.handlers SPI機制主要用在bean的掃描和解析過程中。
4.2.2 原始碼分析
下面從上述程式碼開始深入原始碼瞭解spring handlers方式實現的SPI是如何工作的。
- DefaultNamespaceHandlerResolver
① DefaultNamespaceHandlerResolver.resolve()方法本身是根據namespaceUri獲取對應的namespaceHandler對標籤進行解析,核心原始碼:
DefaultNamespaceHandlerResolver#resolve()
public NamespaceHandler resolve(String namespaceUri) {
// 1、核心邏輯之一:獲取namespaceUri和namespaceHandler對映關係
Map<String, Object> handlerMappings = getHandlerMappings();
// 根據namespaceUri引數取對應的namespaceHandler全限定類名or NamespaceHandler範例
Object handlerOrClassName = handlerMappings.get(namespaceUri);
if (handlerOrClassName == null) {
return null;
}
// 2、handlerOrClassName是已初始化過的範例則直接返回
else if (handlerOrClassName instanceof NamespaceHandler) {
return (NamespaceHandler) handlerOrClassName;
}else {
String className = (String) handlerOrClassName;
try {
///3、使用反射根據namespaceHandler全限定類名載入實現類
Class<?> handlerClass = ClassUtils.forName(className, this.classLoader);
if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) {
throw new FatalBeanException("Class [" + className + "] for namespace [" + namespaceUri +
"] does not implement the [" + NamespaceHandler.class.getName() + "] interface");
}
// 3.1、初始化namespaceHandler範例
NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);
// 3.2、 初始化,不同的namespaceHandler實現類初始化方法邏輯有差異
namespaceHandler.init();
// 4、將初始化好的範例放入記憶體快取中,下次解析到相同namespaceUri標籤時直接返回,避免再次初始化
handlerMappings.put(namespaceUri, namespaceHandler);
return namespaceHandler;
}catch (ClassNotFoundException ex) {
throw new FatalBeanException("NamespaceHandler class [" + className + "] for namespace [" +
namespaceUri + "] not found", ex);
}catch (LinkageError err) {
throw new FatalBeanException("Invalid NamespaceHandler class [" + className + "] for namespace [" +
namespaceUri + "]: problem with handler class file or dependent class", err);
}
}
}
第1步:原始碼中getHandlerMappings()是比較核心的一個方法,通過懶載入的方式解析spring.handlers並返回namespaceUri和NamespaceHandler的對映關係。
第2步:根據namespaceUri返回對應的NamespaceHandler全限定名或者具體的範例(是名稱還是範例取決於是否被初始化過,若是初始化過的範例會直接返回)
第3步:是NamespaceHandler實現類的全限定名,通過上述原始碼中的第3步,使用反射進行初始化。
第4步:將初始化後的範例放到handlerMappings記憶體快取中,這也是第2步為什麼可能是NamespaceHandler型別的原因。
看完resolve方法的原始碼,再看下resolve方法在Spring中呼叫場景,大致可以瞭解spring.handlers的使用場景:
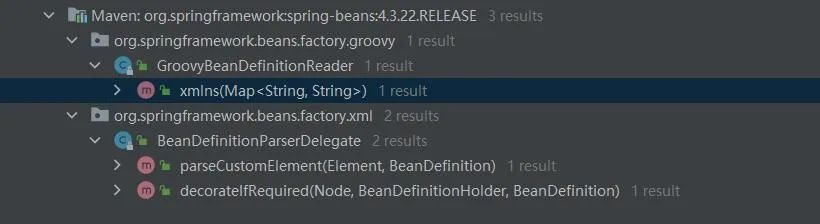
可以看到resolve()主要用在標籤解析過程中,主要被在BeanDefinitionParserDelegate的parseCustomElement和decorateIfRequired方法中呼叫。
② resolve()原始碼中核心邏輯之一便是呼叫的getHandlerMappings(),在getHandlerMappings()中實現對各個jar包中的META-INF/spring.handlers檔案的解析,如:
DefaultNamespaceHandlerResolver#getHandlerMappings()
private Map<String, Object> getHandlerMappings() {
Map<String, Object> handlerMappings = this.handlerMappings;
// 使用執行緒安全的解析邏輯,避免在並行場景下重複的解析,沒必要重複解析
// 這裡在同步程式碼塊的內外對handlerMappings == null作兩次判斷很有必要,採用懶漢式初始化
if (handlerMappings == null) {
synchronized (this) {
handlerMappings = this.handlerMappings;
// duble check
if (handlerMappings == null) {
if (logger.isDebugEnabled()) {
logger.debug("Loading NamespaceHandler mappings from [" + this.handlerMappingsLocation + "]");
}
try {
// 載入handlerMappingsLocation目錄檔案,handlerMappingsLocation路徑值可變,預設是META-INF/spring.handlers
Properties mappings =
PropertiesLoaderUtils.loadAllProperties(this.handlerMappingsLocation, this.classLoader);
if (logger.isDebugEnabled()) {
logger.debug("Loaded NamespaceHandler mappings: " + mappings);
}
// 初始化記憶體快取
handlerMappings = new ConcurrentHashMap<String, Object>(mappings.size());
// 將載入到的屬性合併到handlerMappings中
CollectionUtils.mergePropertiesIntoMap(mappings, handlerMappings);
// 賦值記憶體快取
this.handlerMappings = handlerMappings;
}catch (IOException ex) {
throw new IllegalStateException(
"Unable to load NamespaceHandler mappings from location [" + this.handlerMappingsLocation + "]", ex);
}
}
}
}
return handlerMappings;
}
原始碼中this.handlerMappings是一個Map型別的記憶體快取,存放解析到的namespaceUri以及NameSpaceHandler範例。
getHandlerMappings()方法體中的實現使用了執行緒安全方式,增加了同步邏輯。
通過閱讀原始碼可以瞭解到Spring基於spring.handlers實現SPI邏輯相對比較簡單,但應用卻比較靈活,對自定義標籤的支援很方便,在不修改Spring原始碼的前提下輕鬆實現接入,如Dubbo中定義的各種Dubbo標籤便是很好的利用了spring.handlers。
Spring提供如此靈活的功能,那是如何應用的呢?下面簡單瞭解下parseCustomElement()。
- BeanDefinitionParserDelegate.parseCustomElement()
resolve作為工具型別的方法,被使用的地方比較多,這裡僅簡單介紹在BeanDefinitionParserDelegate.parseCustomElement()中的應用。
BeanDefinitionParserDelegate#parseCustomElement()
public BeanDefinition parseCustomElement(Element ele, BeanDefinition containingBd) {
// 獲取標籤的namespaceUri
String namespaceUri = getNamespaceURI(ele);
// 首先獲得DefaultNamespaceHandlerResolver範例在再以namespaceUri作為引數呼叫resolve方法解析取得NamespaceHandler
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
// 呼叫NamespaceHandler中的parse方法開始解析標籤
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
parseCustomElement作為解析標籤的中間方法,再看下parseCustomElement的呼叫情況:

在parseBeanDefinitions()中被呼叫,再看下parseBeanDefinitions的原始碼
DefaultBeanDefinitionDocumentReader#parseBeanDefinitions()
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
// spring內部定義的標籤為預設標籤,即非spring內部定義的標籤都不是預設的namespace
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
// root子標籤也做此判斷
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}else{
// 子標籤非spring預設標籤(即自定義標籤)也走parseCustomElement來解析
delegate.parseCustomElement(ele);
}
}
}
}else {
// 非spring的預設標籤(即自定義的標籤)走parseCustomElement來解析
delegate.parseCustomElement(root);
}
}
到此就很清晰了,呼叫前判斷是否為Spring預設標籤,不是預設標籤呼叫parseCustomElement來解析,最後呼叫resolve方法。
4.2.3 小節
Spring自2.0引入spring.handlers以後,為Spring的動態擴充套件提供更多的入口和手段,為自定義標籤的實現提供了強力支撐。
很多文章在介紹Spring SPI時都重點介紹spring.factories實現,很少提及很早就引入的spring.handlers,但通過個人的分析及與Java SPI的對比,spring.handlers也是一種SPI的實現,只是基於xml實現。
相比於Java SPI,基於spring.handlers實現的SPI更加的靈活,無需遍歷,直接對映,更類似於Dubbo SPI的實現思想,每個類指定一個名稱(只是spring.handlers中是以namespaceUri作為key,Dubbo設定中是指定的名稱作為key)。
4.3 spring.factories
同樣先以測試程式碼來介紹spring.factories實現SPI的邏輯。
4.3.1 spring.factories SPI
① 建立DataBaseSPI介面
介面
package spring.spi.factories;
public interface DataBaseSPI {
public void dataBaseOperation();
}
② 建立DataBaseSPI介面的實現類
MysqlDataBaseImpl
#實現類1
package spring.spi.factories.impl;
import spring.spi.factories.DataBaseSPI;
public class MysqlDataBaseImpl implements DataBaseSPI {
@Override
public void dataBaseOperation() {
System.out.println("Mysql database test!!!!");
}
}
MysqlDataBaseImpl
#實現類2
package spring.spi.factories.impl;
import spring.spi.factories.DataBaseSPI;
public class OracleDataBaseImpl implements DataBaseSPI {
@Override
public void dataBaseOperation() {
System.out.println("Oracle database test!!!!");
}
}
③ 在專案META-INF/目錄下建立spring.factories檔案:
檔案內容
spring.factories
#key是介面的全限定名,value是介面的實現類
spring.spi.factories.DataBaseSPI = spring.spi.factories.impl.MysqlDataBaseImpl,spring.spi.factories.impl.OracleDataBaseImpl
④ 執行程式碼
SpringSpiTest#main()
package spring.spi.factories;
import java.util.List;
import org.springframework.core.io.support.SpringFactoriesLoader;
public class SpringSpiTest {
public static void main(String args[]){
// 呼叫SpringFactoriesLoader.loadFactories方法載入DataBaseSPI介面所有實現類的範例
List<DataBaseSPI> spis= SpringFactoriesLoader.loadFactories(DataBaseSPI.class, Thread.currentThread().getContextClassLoader());
// 遍歷DataBaseSPI介面實現類範例
for(DataBaseSPI spi : spis){
spi.dataBaseOperation();
}
}
}
⑤ 執行結果
Mysql database test!!!!
Oracle database test!!!!
從上述的範例程式碼中可以看出spring.facotries方式實現的SPI和Java SPI很相似,都是先獲取指定介面型別的實現類,然後遍歷存取所有的實現。但也存在一定的差異:
(1)設定上:
Java SPI是一個服務提供介面對應一個組態檔,組態檔中存放當前介面的所有實現類,多個服務提供介面對應多個組態檔,所有設定都在services目錄下;
Spring factories SPI是一個spring.factories組態檔存放多個介面及對應的實現類,以介面全限定名作為key,實現類作為value來設定,多個實現類用逗號隔開,僅spring.factories一個組態檔。
(2)實現上
Java SPI使用了懶載入模式,即在呼叫ServiceLoader.load()時僅是返回了ServiceLoader範例,尚未解析介面對應的組態檔,在使用時即迴圈遍歷時才正式解析返回服務提供介面的實現類範例;
Spring factories SPI在呼叫SpringFactoriesLoader.loadFactories()時便已解析spring.facotries檔案返回介面實現類的範例(實現細節在原始碼分析中詳解)。
4.3.2 原始碼分析
我們還是從測試程式碼開始,瞭解下spring.factories的SPI實現原始碼,細品spring.factories的實現方式。
- SpringFactoriesLoader測試程式碼入口直接呼叫SpringFactoriesLoader.loadFactories()靜態方法開始解析spring.factories檔案,並返回方法引數中指定的介面型別,如測試程式碼裡的DataBaseSPI介面的實現類範例。
SpringFactoriesLoader#loadFactories()
public static <T> List<T> loadFactories(Class<T> factoryClass, ClassLoader classLoader) {
Assert.notNull(factoryClass, "'factoryClass' must not be null");
ClassLoader classLoaderToUse = classLoader;
// 1.確定類載入器
if (classLoaderToUse == null) {
classLoaderToUse = SpringFactoriesLoader.class.getClassLoader();
}
// 2.核心邏輯之一:解析各jar包中META-INF/spring.factories檔案中factoryClass的實現類全限定名
List<String> factoryNames = loadFactoryNames(factoryClass, classLoaderToUse);
if (logger.isTraceEnabled()) {
logger.trace("Loaded [" + factoryClass.getName() + "] names: " + factoryNames);
}
List<T> result = new ArrayList<T>(factoryNames.size());
// 3.遍歷實現類的全限定名並進行範例化
for (String factoryName : factoryNames) {
result.add(instantiateFactory(factoryName, factoryClass, classLoaderToUse));
}
// 排序
AnnotationAwareOrderComparator.sort(result);
// 4.返回範例化後的結果集
return result;
}
原始碼中loadFactoryNames() 是另外一個比較核心的方法,解析spring.factories檔案中指定介面的實現類的全限定名,實現邏輯見後續的原始碼。
經過原始碼中第2步解析得到實現類的全限定名後,在第3步通過instantiateFactory()方法逐個範例化實現類。
再看loadFactoryNames()原始碼是如何解析得到實現類全限定名的:
SpringFactoriesLoader#loadFactoryNames()
public static List<String> loadFactoryNames(Class<?> factoryClass, ClassLoader classLoader) {
// 1.介面全限定名
String factoryClassName = factoryClass.getName();
try {
// 2.載入META-INF/spring.factories檔案路徑(分佈在各個不同jar包裡,所以這裡會是多個檔案路徑,列舉返回)
Enumeration<URL> urls = (classLoader != null ? classLoader.getResources(FACTORIES_RESOURCE_LOCATION) :
ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION));
List<String> result = new ArrayList<String>();
// 3.遍歷列舉集合,逐個解析spring.factories檔案
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
Properties properties = PropertiesLoaderUtils.loadProperties(new UrlResource(url));
String propertyValue = properties.getProperty(factoryClassName);
// 4.spring.factories檔案中一個介面的實現類有多個時會用逗號隔開,這裡拆開獲取實現類全限定名
for (String factoryName : StringUtils.commaDelimitedListToStringArray(propertyValue)) {
result.add(factoryName.trim());
}
}
return result;
}catch (IOException ex) {
throw new IllegalArgumentException("Unable to load factories from location [" +
FACTORIES_RESOURCE_LOCATION + "]", ex);
}
}
原始碼中第2步獲取所有jar包中META-INF/spring.factories檔案路徑,以列舉值返回。
原始碼中第3步開始遍歷spring.factories檔案路徑,逐個載入解析,整合factoryClass型別的實現類名稱。
獲取到實現類的全限定名集合後,便根據實現類的名稱逐個範例化,繼續看下instantiateFactory()方法的原始碼:
SpringFactoriesLoader#instantiateFactory()
private static <T> T instantiateFactory(String instanceClassName, Class<T> factoryClass, ClassLoader classLoader) {
try {
// 1.使用classLoader類載入器載入instanceClassName類
Class<?> instanceClass = ClassUtils.forName(instanceClassName, classLoader);
if (!factoryClass.isAssignableFrom(instanceClass)) {
throw new IllegalArgumentException(
"Class [" + instanceClassName + "] is not assignable to [" + factoryClass.getName() + "]");
}
// 2.instanceClassName類中的構造方法
Constructor<?> constructor = instanceClass.getDeclaredConstructor();
ReflectionUtils.makeAccessible(constructor);
// 3.範例化
return (T) constructor.newInstance();
}
catch (Throwable ex) {
throw new IllegalArgumentException("Unable to instantiate factory class: " + factoryClass.getName(), ex);
}
}
範例化方法是私有型(private)靜態方法,這個有別於loadFactories和loadFactoryNames。
範例化邏輯整體使用了反射實現,比較通用的實現方式。
通過對原始碼的分析,Spring factories方式實現的SPI邏輯不是很複雜,整體上的實現容易理解。
Spring在3.2便已引入spring.factories,那spring.factories在Spring框架中又是如何使用的呢?先看下loadFactories方法的呼叫情況:
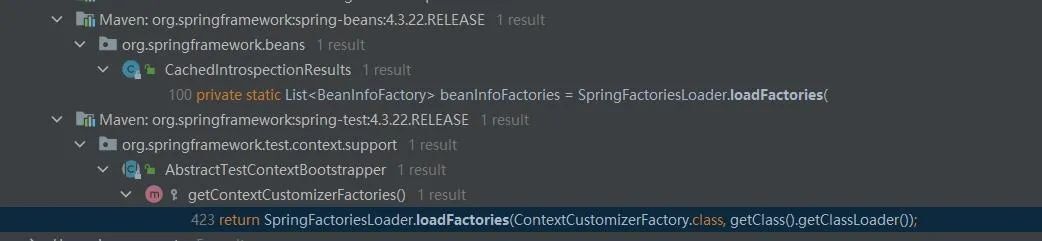
從呼叫情況看Spring自3.2引入spring.factories SPI後並沒有真正的利用起來,使用的地方比較少,然而真正把spring.factories發揚光大的,是在Spring Boot中, 簡單瞭解下SpringBoot中的呼叫。
- getSpringFactoriesInstances()getSpringFactoriesInstances()並不是Spring框架中的方法,而是SpringBoot中SpringApplication類裡定義的私有型(private)方法,很多地方都有呼叫,原始碼如下:
SpringApplication#getSpringFactoriesInstance()
// 單個引數getSpringFactoriesInstances方法
private <T> Collection<T> getSpringFactoriesInstances(Class<T> type) {
// 預設呼叫多參的過載方法
return getSpringFactoriesInstances(type, new Class<?>[] {});
}
// 多個引數的getSpringFactoriesInstances方法
private <T> Collection<T> getSpringFactoriesInstances(Class<T> type,
Class<?>[] parameterTypes, Object... args) {
ClassLoader classLoader = getClassLoader();
// 呼叫SpringFactoriesLoader中的loadFactoryNames方法載入介面實現類的全限定名
Set<String> names = new LinkedHashSet<>(
SpringFactoriesLoader.loadFactoryNames(type, classLoader));
// 範例化
List<T> instances = createSpringFactoriesInstances(type, parameterTypes,
classLoader, args, names);
AnnotationAwareOrderComparator.sort(instances);
return instances;
}
在getSpringFactoriesInstances()中呼叫了SpringFactoriesLoader.loadFactoryNames()來載入介面實現類的全限定名集合,然後進行初始化。
SpringBoot中除了getSpringFactoriesInstances()方法有呼叫,在其他邏輯中也廣泛運用著SpringFactoriesLoader中的方法來實現動態擴充套件,這裡就不在一一列舉了,有興趣的同學可以自己去發掘。
4.3.3 小節
Spring框架在3.2引入spring.factories後並沒有有效的利用起來,但給框架的使用者提供了又一個動態擴充套件的能力和入口,為開發人員提供了很大的自由發揮的空間,尤其是在SpringBoot中廣泛運用就足以證明spring.factories的地位。spring.factories引入在 提升Spring框架能力的同時也暴露出其中的不足:
首先,spring.factories的實現類似Java SPI,在載入到服務提供介面的實現類後需要回圈遍歷才能存取,不是很方便。
其次,Spring在5.0.x版本以前SpringFactoriesLoader類定義為抽象類,但在5.1.0版本之後Sping官方將SpringFactoriesLoader改為final類,型別變化對前後版本的相容不友好。
五、應用實踐
介紹完Spring中SPI機制相關的核心原始碼,再來看看專案中自己開發的輕量版的分庫分表SDK是如何利用Spring的SPI機制實現分庫分表策略動態擴充套件的。
基於專案的特殊性並沒有使用目前行業中成熟的分庫分表元件,而是基於Mybatis的外掛原理自己開發的一套輕量版分庫分表元件。為滿足不同場景分庫分表要求,將其中分庫分表的相關邏輯以策略模式進行抽取分離,每種分庫分表的實現對應一條策略,支援使用方對分庫分表策略的動態擴充套件,而這裡的動態擴充套件就利用了spring.factories。
首先給出輕量版分庫分表元件流程圖,然後我們針對流程圖中使用到Spring SPI的地方進行詳細分析。
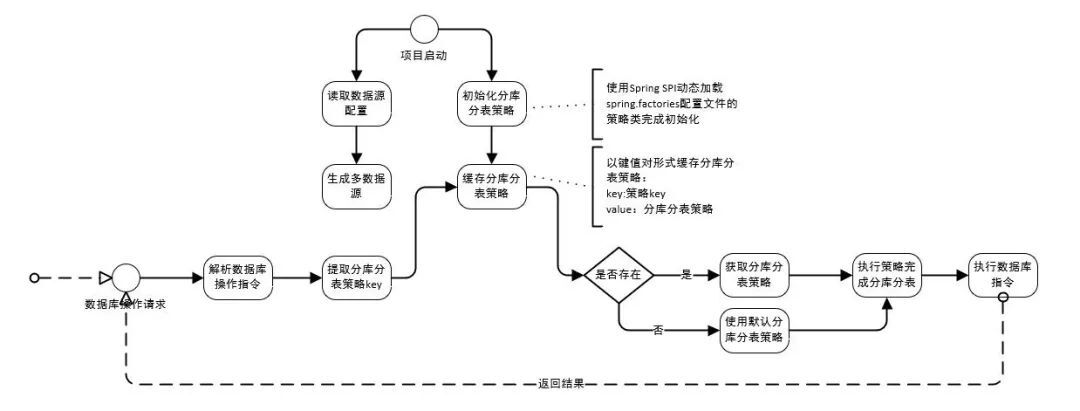
說明:
- 上述流程圖中專案啟動過程中生成資料來源和分庫分表策略的初始化,策略初始化完成後快取到記憶體中。
- 發起資料庫操作指令時,解析是否需要分庫分表(流程中只給出了需要分庫分表的流程),需要則通過提取到的策略key獲取對應的分庫分表策略並進行分庫分表,完成資料庫操作。
通過上述的流程圖可以看到,分庫分表SDK通過spring.factories支援動態載入分庫分表策略以相容不同專案的不同使用場景。
其中分庫分表部分的策略類圖:
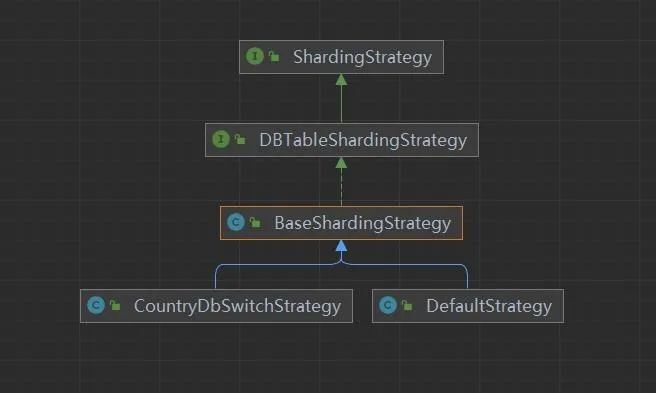
其中:ShardingStrategy和DBTableShardingStrategy為介面;BaseShardingStrategy為預設實現類;DefaultStrategy和CountryDbSwitchStrategy為SDK中基於不同場景預設實現的分庫分表策略。
在專案實際使用時,動態擴充套件的分庫分表策略只需要繼承BaseShardingStrategy即可,SDK中初始化分庫分表策略時通過SpringFactoriesLoader.loadFactories()實現動態載入。
六、總結
SPI技術將服務介面與服務實現分離以達到解耦,極大的提升程式的可延伸性。
本文重點介紹了Java內建SPI和Dubbo SPI以及Spring SPI三者的原理和相關原始碼;首先演示了三種SPI技術的實現,然後通過演示程式碼深入閱讀了三種SPI的實現原始碼;其中重點介紹了Spring SPI的兩種實現方式:spring.handlers和spring.factories,以及使用spring.factories實現的分庫分表策略載入。希望通過閱讀本文可以讓讀者對SPI有更深入的瞭解。