Redis的記憶體淘汰策略(八)
一:Redis的AOF是什麼?
以紀錄檔的形式來記錄每個寫操作(讀操作不記錄),將Redis執行過的所有寫指令記錄下來(讀操作不記錄),只許追加檔案但不可以改寫檔案,redis啟動之初會讀取該檔案重新構建資料,換言之,redis重啟的話就根據紀錄檔檔案的內容將寫指令從前到後執行一次以完成資料的恢復工作。RDB可以搞定備份恢復的事情,為什麼還會出現AOF?
使用RDB進行儲存時候,如果Redis伺服器傳送故障,那麼會丟失最後一次備份的資料!AOF出現是來解決這個問題!同時出現RDB和AOF是衝突呢?還是共同作業?是共同作業,但是首先啟動找的是aof。當redis伺服器掛掉時,重啟時將按照以下優先順序恢復資料到記憶體:
- 如果只設定AOF,重啟時載入AOF檔案恢復資料;
- 如果同時 設定了RBD和AOF,啟動是隻載入AOF檔案恢復資料;
- 如果只設定RBD,啟動是載入RDB檔案恢復資料。
恢復時需要注意,要是主庫掛了不能直接重啟主庫,否則會直接覆蓋掉從庫的AOF檔案,一定要確保要恢復的檔案都正確才能啟動,否則會沖掉原來的檔案。
二:Redis組態檔redis.conf中關於AOF的相關設定
############################## APPEND ONLY MODE ############################### # By default Redis asynchronously dumps the dataset on disk. This mode is # good enough in many applications, but an issue with the Redis process or # a power outage may result into a few minutes of writes lost (depending on # the configured save points). # # The Append Only File is an alternative persistence mode that provides # much better durability. For instance using the default data fsync policy # (see later in the config file) Redis can lose just one second of writes in a # dramatic event like a server power outage, or a single write if something # wrong with the Redis process itself happens, but the operating system is # still running correctly. # # AOF and RDB persistence can be enabled at the same time without problems. # If the AOF is enabled on startup Redis will load the AOF, that is the file # with the better durability guarantees. # # Please check http://redis.io/topics/persistence for more information. #預設redis使用的是rdb方式持久化,這種方式在許多應用中已經足夠用了。 但是redis如果中途宕機,會導致可能有幾分鐘的資料丟失,根據save來策略進行持久化, Append Only File是另一種持久化方式,可以提供更好的持久化特性。 Redis會把每次寫入的資料在接收後都寫入 appendonly.aof 檔案, 每次啟動時Redis都會先把這個檔案的資料讀入記憶體裡,先忽略RDB檔案 appendonly no #如果要開啟,改為yes # The name of the append only file (default: "appendonly.aof") # aof檔名 appendfilename "appendonly.aof" # The fsync() call tells the Operating System to actually write data on disk # instead of waiting for more data in the output buffer. Some OS will really flush # data on disk, some other OS will just try to do it ASAP. # # Redis supports three different modes: # # no: don't fsync, just let the OS flush the data when it wants. Faster. # always: fsync after every write to the append only log. Slow, Safest. # everysec: fsync only one time every second. Compromise. # # The default is "everysec", as that's usually the right compromise between # speed and data safety. It's up to you to understand if you can relax this to # "no" that will let the operating system flush the output buffer when # it wants, for better performances (but if you can live with the idea of # some data loss consider the default persistence mode that's snapshotting), # or on the contrary, use "always" that's very slow but a bit safer than # everysec. # # More details please check the following article: # http://antirez.com/post/redis-persistence-demystified.html # # If unsure, use "everysec". # appendfsync always #aof持久化策略的設定 #no表示不執行fsync,由作業系統保證資料同步到磁碟,速度最快。 #always表示每次寫入都執行fsync,以保證資料同步到磁碟。 #everysec表示每秒執行一次fsync,可能會導致丟失這1s資料。 appendfsync everysec # appendfsync no # When the AOF fsync policy is set to always or everysec, and a background # saving process (a background save or AOF log background rewriting) is # performing a lot of I/O against the disk, in some Linux configurations # Redis may block too long on the fsync() call. Note that there is no fix for # this currently, as even performing fsync in a different thread will block # our synchronous write(2) call. # # In order to mitigate this problem it's possible to use the following option # that will prevent fsync() from being called in the main process while a # BGSAVE or BGREWRITEAOF is in progress. # # This means that while another child is saving, the durability of Redis is # the same as "appendfsync none". In practical terms, this means that it is # possible to lose up to 30 seconds of log in the worst scenario (with the # default Linux settings). # # If you have latency problems turn this to "yes". Otherwise leave it as # "no" that is the safest pick from the point of view of durability. # 在aof重寫或者寫入rdb檔案的時候,會執行大量IO,此時對於everysec和always的aof模式來說, 執行fsync會造成阻塞過長時間,no-appendfsync-on-rewrite欄位設定為預設設定為no。 如果對延遲要求很高的應用,這個欄位可以設定為yes,否則還是設定為no, 這樣對持久化特性來說這是更安全的選擇。設定為yes表示rewrite期間對新寫操作不fsync, 暫時存在記憶體中,等rewrite完成後再寫入,預設為no,建議yes。Linux的預設fsync策略是30秒。 可能丟失30秒資料。隨著aof檔案持續增大,會fork出一條程序去對aof檔案重寫 no-appendfsync-on-rewrite no # Automatic rewrite of the append only file. # Redis is able to automatically rewrite the log file implicitly calling # BGREWRITEAOF when the AOF log size grows by the specified percentage. # # This is how it works: Redis remembers the size of the AOF file after the # latest rewrite (if no rewrite has happened since the restart, the size of # the AOF at startup is used). # # This base size is compared to the current size. If the current size is # bigger than the specified percentage, the rewrite is triggered. Also # you need to specify a minimal size for the AOF file to be rewritten, this # is useful to avoid rewriting the AOF file even if the percentage increase # is reached but it is still pretty small. # # Specify a percentage of zero in order to disable the automatic AOF # rewrite feature. #aof自動重寫設定。當目前aof檔案大小超過上一次重寫的aof檔案大小的百分之多少進行重寫, 即當aof檔案增長到一定大小的時候Redis能夠呼叫bgrewriteaof對紀錄檔檔案進行重寫。 當前AOF檔案大小是上次紀錄檔重寫得到AOF檔案大小的一倍(設定為100)時, 自動啟動新的紀錄檔重寫過程。 auto-aof-rewrite-percentage 100 #設定允許重寫的最小aof檔案大小,避免了達到約定百分比但尺寸仍然很小的情況還要重寫 auto-aof-rewrite-min-size 64mb # An AOF file may be found to be truncated at the end during the Redis # startup process, when the AOF data gets loaded back into memory. # This may happen when the system where Redis is running # crashes, especially when an ext4 filesystem is mounted without the # data=ordered option (however this can't happen when Redis itself # crashes or aborts but the operating system still works correctly). # # Redis can either exit with an error when this happens, or load as much # data as possible (the default now) and start if the AOF file is found # to be truncated at the end. The following option controls this behavior. # # If aof-load-truncated is set to yes, a truncated AOF file is loaded and # the Redis server starts emitting a log to inform the user of the event. # Otherwise if the option is set to no, the server aborts with an error # and refuses to start. When the option is set to no, the user requires # to fix the AOF file using the "redis-check-aof" utility before to restart # the server. # # Note that if the AOF file will be found to be corrupted in the middle # the server will still exit with an error. This option only applies when # Redis will try to read more data from the AOF file but not enough bytes # will be found. #aof檔案可能在尾部是不完整的,當redis啟動的時候,aof檔案的資料被載入記憶體。 重啟可能發生在redis所在的主機作業系統宕機後, 尤其在ext4檔案系統沒有加上data=ordered選項(redis宕機或者異常終止不會造成尾部不完整現象。) 出現這種現象,可以選擇讓redis退出,或者匯入儘可能多的資料。如果選擇的是yes, 當截斷的aof檔案被匯入的時候,會自動釋出一個log給使用者端然後load。如果是no, 使用者必須手動redis-check-aof修復AOF檔案才可以。 aof-load-truncated yes # When rewriting the AOF file, Redis is able to use an RDB preamble in the # AOF file for faster rewrites and recoveries. When this option is turned # on the rewritten AOF file is composed of two different stanzas: # # [RDB file][AOF tail] # # When loading Redis recognizes that the AOF file starts with the "REDIS" # string and loads the prefixed RDB file, and continues loading the AOF # tail. # # This is currently turned off by default in order to avoid the surprise # of a format change, but will at some point be used as the default. #Redis4.0新增RDB-AOF混合持久化格式,在開啟了這個功能之後, AOF重寫產生的檔案將同時包含RDB格式的內容和AOF格式的內容, 其中RDB格式的內容用於記錄已有的資料,而AOF格式的記憶體則用於記錄最近發生了變化的資料, 這樣Redis就可以同時兼有RDB持久化和AOF持久化的優點(既能夠快速地生成重寫檔案, 也能夠在出現問題時,快速地載入資料)。 aof-use-rdb-preamble no
注:當 aof 檔案損壞的時候 可以使用修復:使用redis-check-aof –fix xxx.aof 進行修復 同理 rdb檔案也有專門的修復redis-check-dump
aof 檔案重寫: AOF檔案持續增長而過大時,會fork出一條新程序來將檔案重寫(也是先寫臨時檔案最後再rename),遍歷新程序的記憶體中資料,每條記錄有一條的Set語句。重寫aof檔案的操作,並沒有讀取舊的aof檔案,而是將整個記憶體中的資料庫內容用命令的方式重寫了一個新的aof檔案,這點和快照有點類似。
重寫過程中,AOF檔案被更改了怎麼辦?
Redis 可以在 AOF 檔案體積變得過大時,自動地在後臺對 AOF 進行重寫: 重寫後的新 AOF 檔案包含 了恢復當前資料集所需的最小命令集合。 重寫的流程是這樣,
- 主程序會fork一個子程序出來進行AOF重寫,這個重寫過程並不是基於原有的aof檔案來做的,而 是有點類似於快照的方式,全量遍歷記憶體中的資料,然後逐個序列到aof檔案中。
- 在fork子程序這個過程中,伺服器端仍然可以對外提供服務,那這個時候重寫的aof檔案的資料和 redis記憶體資料不一致了怎麼辦?不用擔心,這個過程中,主程序的資料更新操作,會快取到 aof_rewrite_buf中,也就是單獨開闢一塊快取來儲存重寫期間收到的命令,當子程序重寫完以後 再把快取中的資料追加到新的aof檔案。
- 當所有的資料全部追加到新的aof檔案中後,把新的aof檔案重新命名正式的檔案名字,此後所有的操 作都會被寫入新的aof檔案。
- 如果在rewrite過程中出現故障,不會影響原來aof檔案的正常工作,只有當rewrite完成後才會切 換檔案。因此這個rewrite過程是比較可靠的。
Redis允許同時開啟AOF和RDB,既保證了資料安全又使得進行備份等操作十分容易。如果同時開啟 後,Redis重啟會使用AOF檔案來恢復資料,因為AOF方式的持久化可能丟失的資料更少。
三:小結
AOF 檔案是一個只進行追加的紀錄檔檔案
Redis可以在AOF檔案體積變得過大時,自動地在後臺對AOF進行重寫,AOF檔案有序地儲存了對資料庫執行所有寫入操作,這些寫入操作作為redis協定的格式儲存,因此AOF檔案的內容非常容易被人讀懂,對檔案進行分析也很輕鬆對於相同的資料集來說,AOF檔案的體積通常大於RDB檔案的體積,根據所使用的fsync策略,AOF的速度可能會慢於RDB
1:到底啟用哪種持久化策略? :
RDB持久化方式能夠在指定的時間間隔能對你的資料進行快照儲存。AOF持久化方式記錄每次對伺服器寫的操作,當伺服器重啟的時候會重新執行這些命令來恢復原始的資料,AOF命令以redis協定追加儲存每次寫的操作到檔案末尾.Redis還能對AOF檔案進行後臺重寫,使得AOF檔案的體積不至於過大。
只做快取:如果你只希望你的資料在伺服器執行的時候存在,你也可以不使用任何持久化方式.
同時開啟兩種持久化方式 – 在這種情況下,當redis重啟的時候會優先載入AOF檔案來恢復原始的資料, 因為在通常情況下AOF檔案儲存的資料集要比RDB檔案儲存的資料集要完整. RDB的資料不實時,同時使用兩者時伺服器重啟也只會找AOF檔案。那要不要只使用AOF呢? 建議不要,因為RDB更適合用於備份資料庫(AOF在不斷變化不好備份), 快速重啟,而且不會有AOF可能潛在的bug,留著作為一個萬一的手段。
2.效能建議:
因為RDB檔案只用作後備用途,建議只在Slave上持久化RDB檔案,而且只要15分鐘備份一次就夠了,只保留save 900 1這條規則。如果Enalbe AOF,好處是在最惡劣情況下也只會丟失不超過兩秒資料,啟動指令碼較簡單隻load自己的AOF檔案就可以了。代價一是帶來了持續的IO,二是AOF rewrite的最後將rewrite過程中產生的新資料寫到新檔案造成的阻塞幾乎是不可避免的。只要硬碟許可,應該儘量減少AOF rewrite的頻率,AOF重寫的基礎大小預設值64M太小了,可以設到5G以上。預設超過原大小100%大小時重寫可以改到適當的數值。如果不Enable AOF ,僅靠Master-Slave Replication 實現高可用性也可以。能省掉一大筆IO也減少了rewrite時帶來的系統波動。代價是如果Master/Slave同時掛掉,會丟失十幾分鐘的資料,啟動指令碼也要比較兩個Master/Slave中的RDB檔案,載入較新的那個。新浪微博就選用了這種架構。
記憶體回收:
Reids 所有的資料都是儲存在記憶體中的,在某些情況下需要對佔用的記憶體空間進行回收。記憶體回收主要分為兩類,一類是 key 過期,一類是記憶體使用達到上限(max_memory)觸發記憶體淘汰。
過期策略:
定時過期(主動 淘汰 ):每個設定過期時間的 key 都需要建立一個定時器,到過期時間就會立即清除。該策略可以立即清除過期的資料,對記憶體很友好;但是會佔用大量的 CPU 資源去處理過期的資料,從而影響快取的響應時間和吞吐量。
惰性過期(被動 淘汰 ):只有當存取一個 key 時,才會判斷該 key 是否已過期,過期則清除。該策略可以最大化地節省 CPU 資源,卻對記憶體非常不友好。極端情況可能出現大量的過期 key 沒有再次被存取,從而不會被清除,佔用大量記憶體。例如 String,在 getCommand 裡面會呼叫 expireIfNeeded
第二種情況,每次寫入 key 時,發現記憶體不夠,呼叫 activeExpireCycle 釋放一部分記憶體。
每隔一定的時間,會掃描一定數量的資料庫的 expires 字典中一定數量的 key,並清除其中已過期的 key。該策略是前兩者的一個折中方案。通過調整定時掃描的時間間隔和每次掃描的限定耗時,可以在不同情況下使得 CPU 和記憶體資源達到最優的平衡效果。
Redis 中同時使用了惰性過期和定期過期兩種過期策略j結合
Redis 的記憶體淘汰策略,是指當記憶體使用達到最大記憶體極限時,需要使用淘汰演演算法來決定清理掉哪些資料,以保證新資料的存入。redis.conf 引數設定:
# maxmemory <bytes>
如果不設定 maxmemory 或者設定為 0,64 位系統不限制記憶體,32 位系統最多使用 3GB 記憶體。
Redis記憶體回收策略:
很多人瞭解了Redis的好處之後,於是把任何資料都往Redis中放,如果使用不合理很容易導致資料超 過Redis的記憶體,這種情況會出現什麼問題呢?
- Redis中有很多無效的快取,這些快取資料會降低資料IO的效能,因為不同的資料型別時間複雜度 演演算法不同,資料越多可能會造成效能下降
- 隨著系統的執行,redis的資料越來越多,會導致實體記憶體不足。通過使用虛擬記憶體(VM),將很 少存取的資料交換到磁碟上,騰出記憶體空間的方法來解決實體記憶體不足的情況。雖然能夠解決物理 記憶體不足導致的問題,但是由於這部分資料是儲存在磁碟上,如果在高並行場景中,頻繁存取虛擬 記憶體空間會嚴重降低系統效能。
所以遇到這類問題的時候,我們一般有幾種方法。
- 對每個儲存到redis中的key設定過期時間,這個根據實際業務場景來決定。否則,再大的記憶體都會 雖則系統執行被消耗完。 增
- 加記憶體
- 使用記憶體淘汰策略。
設定了maxmemory的選項,redis記憶體使用達到上限。可以通過設定LRU演演算法來刪除部分key,釋放空間。預設是按照過期時間的,如果set時候沒有加上過期時間就會導致資料寫滿maxmemory。
Redis中提供了一種記憶體淘汰策略,當記憶體不足時,Redis會根據相應的淘汰規則對key資料進行淘汰。 Redis一共提供了8種淘汰策略,預設的策略為noeviction,當記憶體使用達到閾值的時候, 所有引起申請記憶體的命令會報錯。
- volatile-lru,針對設定了過期時間的key,使用lru演演算法進行淘汰。
- allkeys-lru,針對所有key使用lru演演算法進行淘汰。
- volatile-lfu,針對設定了過期時間的key,使用lfu演演算法進行淘汰。
- allkeys-lfu,針對所有key使用lfu演演算法進行淘汰。
- volatile-random,從所有設定了過期時間的key中使用隨機淘汰的方式進行淘汰。
- allkeys-random,針對所有的key使用隨機淘汰機制進行淘汰。
- volatile-ttl,刪除生存時間最近的一個鍵。
- noeviction,不刪除鍵,值返回錯誤。
字首為volatile-和allkeys-的區別在於二者選擇要清除的鍵時的字典不同,volatile-字首的策略代表從 redisDb中的expire字典中選擇鍵進行清除;allkeys-開頭的策略代表從dict字典中選擇鍵進行清除。
記憶體淘汰演演算法的具體工作原理是:
- 使用者端執行一條新命令,導致資料庫需要增加資料(比如set key value)
- Redis會檢查記憶體使用,如果記憶體使用超過 maxmemory,就會按照置換策略刪除一些 key
- 新的命令執行成功
瞭解LRU演演算法:
LRU是Least Recently Used的縮寫,也就是表示最近很少使用,也可以理解成最久沒有使用。也就是說 當記憶體不夠的時候,每次新增一條資料,都需要拋棄一條最久時間沒有使用的舊資料。
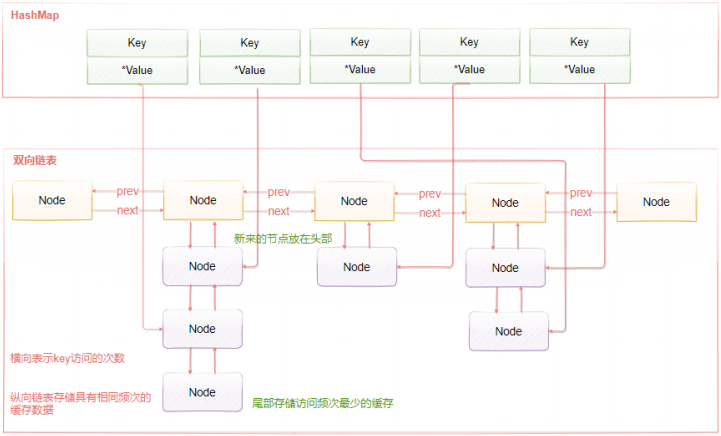
標準的LRU演演算法為了降低查詢和刪除元素的時間複雜度,一般採用Hash表和雙向連結串列結合的資料結構, hash表可以賦予連結串列快速查詢到某個key是否存在連結串列中,同時可以快速刪除、新增節點,
如下圖所 示。 雙向連結串列的查詢時間複雜度是O(n),刪除和插入是O(1),藉助HashMap結構,可以使得查詢的時 間複雜度變成O(1) Hash表用來查詢在連結串列中的資料位置,連結串列負責資料的插入,當新資料插入到連結串列頭部時有兩種情況。
- 連結串列滿了,把連結串列尾部的資料丟棄掉,新加入的快取直接加入到連結串列頭中。
- 當連結串列中的某個快取被命中時,直接把資料移到連結串列頭部,原本在頭節點的快取就向連結串列尾部移動
這樣,經過多次Cache操作之後,最近被命中的快取,都會存在連結串列頭部的方向,沒有命中的,都會在 連結串列尾部方向,當需要替換內容時,由於連結串列尾部是最少被命中的,我們只需要淘汰連結串列尾部的資料即可。

Redis中的LRU演演算法:
實際上,Redis使用的LRU演演算法其實是一種不可靠的LRU演演算法,它實際淘汰的鍵並不一定是真正最少使用 的資料,它的工作機制是:
- 隨機採集淘汰的key,每次隨機選出5個key
- 然後淘汰這5個key中最少使用的key
這5個key是預設的個數,具體的數值可以在redis.conf中設定
maxmemory-samples 5
當近似LRU演演算法取值越大的時候就會越接近真實的LRU演演算法,因為取值越大獲取的資料越完整,淘汰中 的資料就更加接近最少使用的資料。這裡其實涉及一個權衡問題,
如果需要在所有的資料中搜尋最符合條件的資料,那麼一定會增加系統的開銷,Redis是單執行緒的,所以耗時的操作會謹慎一些。
為了在一定成本內實現相對的LRU,早期的Redis版本是基於取樣的LRU,也就是放棄了從所有資料中搜 索解改為取樣空間搜尋最優解。Redis3.0版本之後,Redis作者對於基於取樣的LRU進行了一些優化:
- Redis中維護一個大小為16的候選池,當第一次隨機選取採用資料時,會把資料放入到候選池中, 並且候選池中的資料會根據時間進行排序。
- 當第二次以後選取資料時,只有小於候選池內最小時間的才會被放進候選池。 當候選池的資料滿了之後,那麼時間最大的key就會被擠出候選池。
- 當執行淘汰時,直接從候選池 中選取最近存取時間小的key進行淘汰。
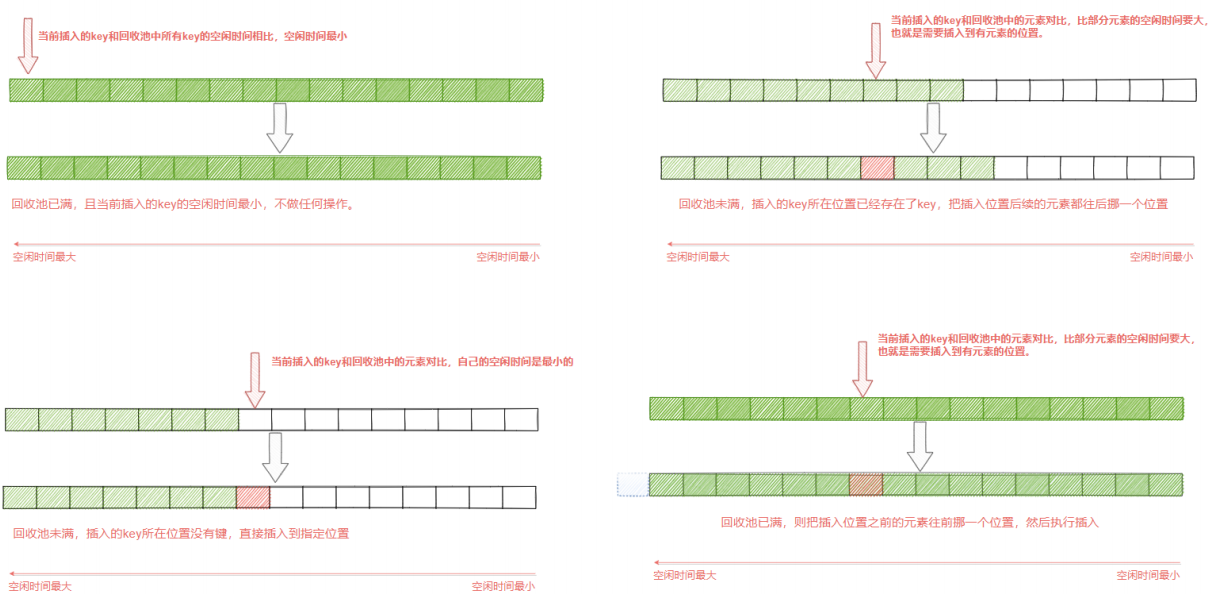
如下圖所示,首先從目標字典中採集出maxmemory-samples個鍵,快取在一個samples陣列中,然 後從samples陣列中一個個取出來,和回收池中以後的鍵進行鍵的空閒時間 (空閒時間越大,代表越久沒有被使用,準備淘汰),從而更新回收池。 在更新過程中,首先利用遍歷找到的每個鍵的實際插入位置x,然後根據不同情況進行處理。
- 回收池滿了,並且當前插入的key的空閒時間最小(也就是回收池中的所有key都比當前插入的key 的空閒時間都要大),則不作任何操作。
- 回收池未滿,並且插入的位置x沒有鍵,則直接插入即可
- 回收池未滿,且插入的位置x原本已經存在要淘汰的鍵,則把第x個以後的元素都往後挪一個位 置,然後再執行插入操作。
- 回收池滿了,將當前第x個以前的元素往前挪一個位置(實際就是淘汰了),然後執行插入操作。
這樣做的目的是能夠選出最真實的最少被存取的key,能夠正確不常使用的key。因為在Redis3.0之前是 隨機選取樣本,這樣的方式很有可能不是真正意義上的最少存取的key。
LRU演演算法有一個弊端,加入一個key值存取頻率很低,但是最近一次被存取到了,那LRU會認為它是熱點 資料,不會被淘汰。同樣, 經常被存取的資料,最近一段時間沒有被存取,這樣會導致這些資料被淘汰掉,導致誤判而淘汰掉熱點 資料,於是在Redis 4.0中,新加了一種LFU演演算法。
LFU演演算法:
LFU(Least Frequently Used),表示最近最少使用,它和key的使用次數有關,其思想是:根據key最 近被存取的頻率進行淘汰,比較少存取的key優先淘汰,反之則保留。
LRU的原理是使用計數器來對key進行排序,每次key被存取時,計數器會增大,當計數器越大,意味著 當前key的存取越頻繁,也就是意味著它是熱點資料。 它很好的解決了LRU演演算法的缺陷:一個很久沒有 被存取的key,偶爾被存取一次,導致被誤認為是熱點資料的問題。
LFU的實現原理如下圖所示,LFU維護了兩個連結串列,橫向組成的連結串列用來儲存存取頻率,每個存取頻 率的節點下儲存另外一個具有相同存取頻率的快取資料。具體的工作原理是:
- 當新增元素時,找到相同存取頻次的節點,然後新增到該節點的資料連結串列的頭部。如果該資料連結串列 滿了,則移除連結串列尾部的節點
- 當獲取元素或者修改元素時,都會增加對應key的存取頻次,並把當前節點移動到下一個頻次節 點。
- 新增元素時,存取頻率預設為1,隨著存取次數的增加,頻率不斷遞增。而當前被存取的元素也會 隨著頻率增加進行移動。