ClickHouse(02)ClickHouse架構設計介紹概述與ClickHouse資料分片設計
ClickHouse核心架構設計是怎麼樣的?ClickHouse核心架構模組分為兩個部分:ClickHouse執行過程架構和ClickHouse資料儲存架構,下面分別詳細介紹。
ClickHouse執行過程架構
總的來說,結合目前蒐集到的一些資料,可以看到目前ClickHouse核心架構由下圖構成,主要的抽象模組是Column、DataType、Block、Functions、Storage、Parser與Interpreter。
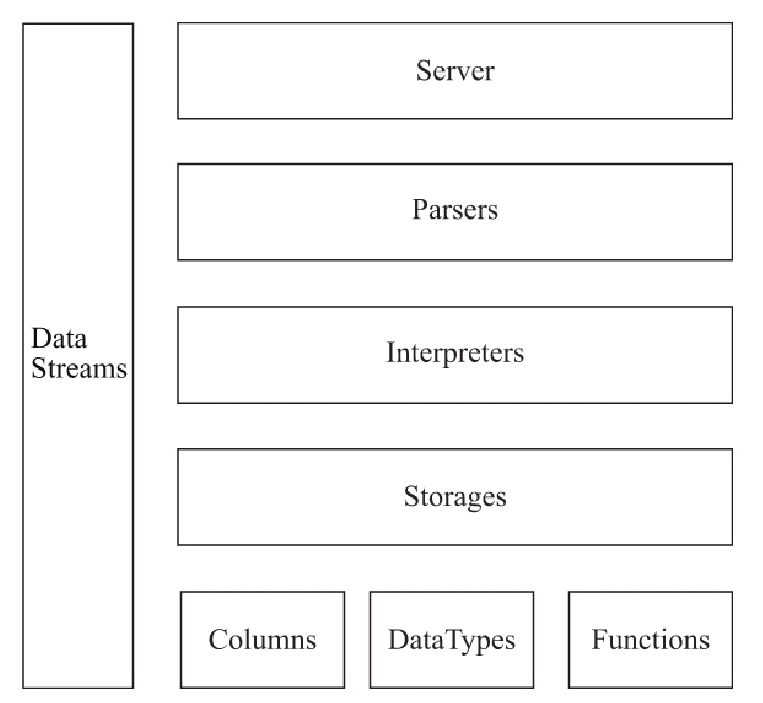
簡單來說,就是一條sql,會經由Parser與Interpreter,解析和執行,通過呼叫Column、DataType、Block、Functions、Storage等模組,最終返回資料,下面是各個模組具體的介紹。
Columns
表示記憶體中的列(實際上是列塊),需使用 IColumn 介面。該介面提供了用於實現各種關係操作符的輔助方法。幾乎所有的操作都是不可變的:這些操作不會更改原始列,但是會建立一個新的修改後的列。
Column物件分為介面和實現兩個部分,在IColumn介面物件中,定義了對資料進行各種關係運算的方法,例如插入資料的insertRangeFrom和insertFrom方法、用於分頁的cut,以及用於過濾的filter方法等。而這些方法的具體實現物件則根據資料型別的不同,由相應的物件實現,例如ColumnString、ColumnArray和ColumnTuple等。
Field
表示單個值,有時候也可能需要處理單個值,可以使用Field。Field 是 UInt64、Int64、Float64、String 和 Array 組成的聯合。與Column物件的泛化設計思路不同,Field物件使用了聚合的設計模式。在Field物件內部聚合了Null、UInt64、String和Array等13種資料型別及相應的處理邏輯。
DataType
IDataType 負責序列化和反序列化:讀寫二進位制或文字形式的列或單個值構成的塊。IDataType直接與表的資料型別相對應。比如,有 DataTypeUInt32、DataTypeDateTime、DataTypeString等資料型別。
IDataType與IColumn之間的關聯並不大。不同的資料型別在記憶體中能夠用相同的IColumn實現來表示。比如,DataTypeUInt32和DataTypeDateTime都是用ColumnUInt32或ColumnConstUInt32來表示的。另外,相同的資料型別也可以用不同的IColumn實現來表示。比如,DataTypeUInt8既可以使用ColumnUInt8 來表示,也可以使用過ColumnConstUInt8 來表示。
IDataType僅儲存後設資料。比如,DataTypeUInt8不儲存任何東西(除了vptr);DataTypeFixedString僅儲存N(固定長度字串的串長度)。
IDataType具有針對各種資料格式的輔助函數。比如如下一些輔助函數:序列化一個值並加上可能的引號;序列化一個值用於 JSON 格式;序列化一個值作為 XML 格式的一部分。輔助函數與資料格式並沒有直接的對應。比如,兩種不同的資料格式 Pretty 和 TabSeparated 均可以使用 IDataType 介面提供的 serializeTextEscaped 這一輔助函數。
Block
Block是表示記憶體中表的子集(chunk)的容器,是由三元組:(IColumn,IDataType,列名)構成的集合。在查詢執行期間,資料是按 Block進行處理的。如果我們有一個Block,那麼就有了資料(在IColumn物件中),有了資料的型別資訊告訴我們如何處理該列,同時也有了列名(來自表的原始列名,或人為指定的用於臨時計算結果的名字)。
當我們遍歷一個塊中的列進行某些函數計算時,會把結果列加入到塊中,但不會更改函數引數中的列,因為操作是不可變的。之後,不需要的列可以從塊中刪除,但不是修改。這對於消除公共子表示式非常方便。
Block用於處理資料塊。注意,對於相同型別的計算,列名和型別對不同的塊保持相同,僅列資料不同。最好把塊資料(block data)和塊頭(block header)分離開來,因為小塊大小會因複製共用指標和列名而帶來很高的臨時字串開銷。
Block Streams
塊流用於處理資料。我們可以使用塊流從某個地方讀取資料,執行資料轉換,或將資料寫到某個地方。IBlockInputStream 具有 read 方法,其能夠在資料可用時獲取下一個塊。IBlockOutputStream 具有 write 方法,其能夠將塊寫到某處。
塊流負責:
- 讀或寫一個表。表僅返回一個流用於讀寫塊。
- 完成資料格式化。比如,如果你打算將資料以Pretty格式輸出到終端,你可以建立一個塊輸出流,將塊寫入該流中,然後進行格式化。
- 執行資料轉換。假設你現在有IBlockInputStream並且打算建立一個過濾流,那麼你可以建立一個FilterBlockInputStream並用IBlockInputStream 進行初始化。之後,當你從FilterBlockInputStream中拉取塊時,會從你的流中提取一個塊,對其進行過濾,然後將過濾後的塊返回給你。查詢執行流水線就是以這種方式表示的。
Storage
IStorage介面表示一張表。該介面的不同實現對應不同的表引擎。比如 StorageMergeTree、StorageMemory等。這些類的範例就是表。
IStorage 中最重要的方法是read和write,除此之外還有alter、rename和drop等方法。read方法接受如下引數:需要從表中讀取的列集,需要執行的AST查詢,以及所需返回的流的數量。read方法的返回值是一個或多個IBlockInputStream物件,以及在查詢執行期間在一個表引擎內完成的關於資料處理階段的資訊。
在大多數情況下,read方法僅負責從表中讀取指定的列,而不會進行進一步的資料處理。進一步的資料處理均由查詢直譯器完成,不由 IStorage 負責。
但是也有值得注意的例外:AST查詢被傳遞給read方法,表引擎可以使用它來判斷是否能夠使用索引,從而從表中讀取更少的資料。有時候,表引擎能夠將資料處理到一個特定階段。比如,StorageDistributed 可以向遠端伺服器傳送查詢,要求它們將來自不同的遠端伺服器能夠合併的資料處理到某個階段,並返回預處理後的資料,然後查詢直譯器完成後續的資料處理。
Parser與Interpreter
Parser和Interpreter是非常重要的兩組介面:Parser分析器負責建立AST物件;而Interpreter直譯器則負責解釋AST,並進一步建立查詢的執行管道。它們與IStorage一起,串聯起了整個資料查詢的過程。Parser分析器可以將一條SQL語句以遞迴下降的方法解析成AST語法樹的形式。不同的SQL語句,會經由不同的Parser實現類解析。例如,有負責解析DDL查詢語句的ParserRenameQuery、ParserDropQuery和ParserAlterQuery解析器,也有負責解析INSERT語句的ParserInsertQuery解析器,還有負責SELECT語句的ParserSelectQuery等。
Interpreter直譯器的作用就像Service服務層一樣,起到串聯整個查詢過程的作用,它會根據直譯器的型別,聚合它所需要的資源。首先它會解析AST物件;然後執行「業務邏輯」(例如分支判斷、設定引數、呼叫介面等);最終返回IBlock物件,以執行緒的形式建立起一個查詢執行管道。
Functions
函數既有普通函數,也有聚合函數。
普通函數不會改變行數-它們的執行看起來就像是獨立地處理每一行資料。實際上,函數不會作用於一個單獨的行上,而是作用在以Block 為單位的資料上,以實現向量查詢執行。
還有一些雜項函數,比如塊大小、rowNumberInBlock,以及跑累積,它們對塊進行處理,並且不遵從行的獨立性。
ClickHouse 具有強型別,因此隱式型別轉換不會發生。如果函數不支援某個特定的型別組合,則會丟擲異常。但函數可以通過過載以支援許多不同的型別組合。比如,plus 函數(用於實現+運運算元)支援任意數位型別的組合:UInt8+Float32,UInt16+Int8等。同時,一些可變引數的函數能夠級接收任意數目的引數,比如concat函數。
實現函數可能有些不方便,因為函數的實現需要包含所有支援該操作的資料型別和IColumn型別。比如,plus函數能夠利用C++模板針對不同的數位型別組合、常數以及非常數的左值和右值進行程式碼生成。
這是一個實現動態程式碼生成的好地方,從而能夠避免模板程式碼膨脹。同樣,執行時程式碼生成也使得實現融合函數成為可能,比如融合«乘-加»,或者在單層迴圈迭代中進行多重比較。
由於向量查詢執行,函數不會«短路»。比如,如果你寫 WHERE f(x) AND g(y),兩邊都會進行計算,即使是對於 f(x) 為 0 的行(除非f(x)是零常數表示式)。但是如果 f(x) 的選擇條件很高,並且計算 f(x) 比計算 g(y) 要划算得多,那麼最好進行多遍計算:首先計算 f(x),根據計算結果對列資料進行過濾,然後計算 g(y),之後只需對較小數量的資料進行過濾。
ClickHouse資料儲存架構
ClickHouse資料儲存架構由分片(Shard)組成,而每個分片又通過副本(Replica)組成。ClickHouse分片有限免兩個特點。
- ClickHouse的1個節點只能擁有1個分片,也就是說如果要實現1分片、1副本,則至少需要部署2個服務節點。
- 分片只是一個邏輯概念,其物理承載還是由副本承擔的。
下面是cluster擁有1個shard(分片)和2個replica(副本),且副本由192.37.129.6服務節點和192.37.129.7服務節承載。從本質上看,這個設定是是一個分片一個副本,因為分片最終還是由副本來實現,所以這個其中一個副本是屬於分片,分片是一個邏輯概念,它指的是其中的一個副本,這個和Elasticsearch中的分片和副本的概念有所不同。
<ch_cluster>
<shard>
<replica>
<host>192.37.129.6</host>
<port>9000</port>
</replica>
<replica>
<host>192.37.129.7</host>
<port>9000</port>
</replica>
</shard>
</ch_cluster>
ClickHouse相關資料分享
本文來自部落格園,作者:張飛的豬,轉載請註明原文連結:https://www.cnblogs.com/the-pig-of-zf/p/16394605.html
作者公眾號:張飛的豬巨量資料分享,不定期分享巨量資料學習的總結和相關資料,歡迎關注。