循序漸進 Redis 分散式鎖(以及何時不用它)
場景
假設我們有個批次處理服務,實現邏輯大致是這樣的:
- 使用者在管理後臺向批次處理服務投遞任務;
- 批次處理服務將該任務寫入資料庫,立即返回;
- 批次處理服務有啟動單獨執行緒定時從資料庫獲取一批未處理(或處理失敗)的任務,投遞到訊息佇列中;
- 批次處理服務啟動多個消費執行緒監聽佇列,從佇列中拿到任務並處理;
- 消費執行緒處理完成(成功或者失敗)後修改資料庫中相應任務的狀態;
流程如圖:

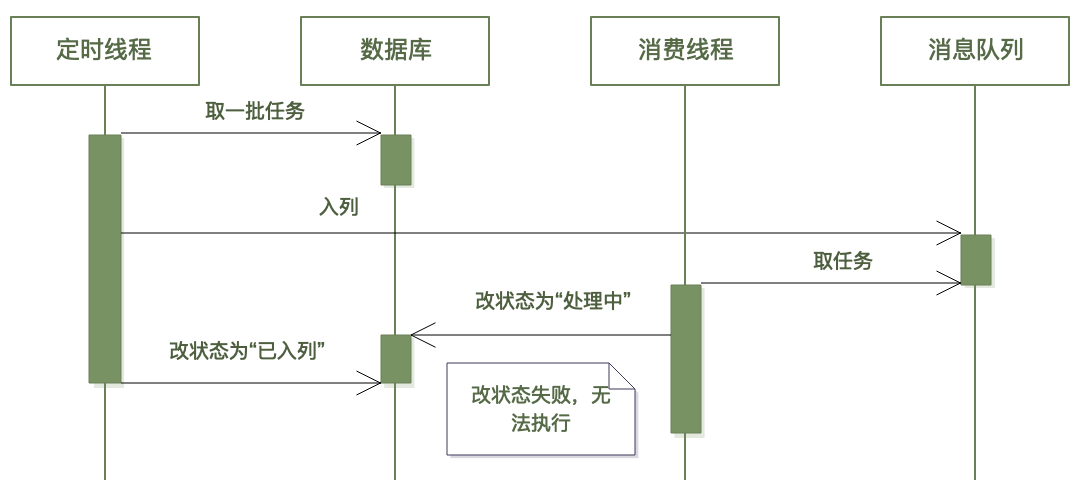
現在我們單獨看看上圖中虛線框中的內容(3~6):批次處理服務從資料庫拉取任務列表投遞到訊息佇列。
生產環境中,為了高可用,都會部署至少兩臺批次處理伺服器,也就是說至少有兩個程序在執行虛線框中的流程。
有什麼問題呢?
假設這兩個程序同時去查任務表(這是很有可能的),它倆很可能會得到同一批任務列表,於是這批任務都會入列兩次。
當然,這不是說一個任務入列兩次就一定會導致任務被重複執行——我們可以通過多引入一個狀態值來解決此問題。
消費者執行緒從佇列中獲取到任務後,再次用如下 SQL 更新任務狀態:
-- status:1-待處理;2-已入列;3-處理中;4-失敗待重試;5-徹底失敗(不可重試);
update tasks set status=3 where status=2 and id=$id;
由於 where 條件有 status=2,即只有原先狀態是「已入列」的才能變成「處理中」,如果多個執行緒同時拿到同一個任務,一定只有一個執行緒能執行成功上面的語句,進而繼續後續流程(其實這就是通過資料庫實現的簡單的分散式鎖——樂觀鎖)。
不過,當定時程序多了後,大量的重複資料仍然會帶來效能等其他問題,所以有必要解決重複入列的問題。
有個細節:請注意上圖中步驟 5、6,是先改資料庫狀態為「已入列」,再將訊息投遞到訊息佇列中——這和常規邏輯是反過來的。
能否顛倒 5 和 6 的順序,先入列,再改資料庫狀態呢?
不能。從邏輯上來說確實應該如此,但它會帶來問題。消費執行緒從佇列中拿到任務後,會執行如下 SQL 語句:
update tasks set status=3 where status=2 and id=$id;
這條 SQL 依賴於前面(第 5 步)產生的狀態值,所以它要求在執行該語句的時候,第 5 步的 SQL 語句(將狀態改為「已入列」)一定已經執行完了。如果將 5 和 6 顛倒(先入列,再改狀態值),就有可能出現下圖的執行順序,導致消費者執行緒修改狀態失敗,進而執行不下去:
上圖中,任務入列後立即被消費執行緒獲取到並去修改資料庫,而此時定時執行緒的 SQL 可能還沒執行(可能網路延遲),這就出問題了。
定時執行緒先將狀態改為「已入列」帶來的問題是,如果改狀態後(入列前)程序掛了,會導致任務一直處於已入列狀態(但實際上未入列),所以還需要搭配其它的超時重試機制。
上圖虛線框中那段邏輯在並行原語中有個專門名稱叫「臨界區」——我們要做的就是讓多個操作者(程序、執行緒、協程)必須一個一個地(而不能一窩蜂地)去執行臨界區內部的邏輯,手段就是加鎖:
var lock = newLock()
// 加鎖
lock.lock()
// 執行臨界區的邏輯
// 釋放鎖
lock.unlock()
所謂鎖,就是多個參與者(程序、執行緒)爭搶同一個共用資源(術語叫「號誌」),誰搶到了就有資格往下走,沒搶到的只能乖乖地等(或者放棄)。鎖的本質是兩點:
- 它是一種共用資源,對於多方參與者來說,只有一個,就好比籃球場上只有一個籃球,所有人都搶這一個球;
- 對該資源的操作(加鎖、解鎖)是原子性的。雖然大家一窩蜂都去搶一個球,但最終這個球只會屬於某一個人,不可能一半在張三手上,另一半在李四手上。只有搶到球的一方才可以執行後續流程(投籃),另一方只能繼續搶;
在單個程序中,以上兩點很容易實現:同一個程序中的執行緒之間天然是共用程序記憶體空間的;原子性也直接由 CPU 指令保證。所以單個程序中,我們直接用程式語言提供的鎖即可。
程序之間呢?
程序之間的記憶體空間是獨立的。兩個程序(可能在兩臺不同的物理機上)建立的鎖資源自然也是獨立的——這就好比兩個籃球場上的兩個籃球之間毫不相干。
那怎樣讓兩個籃球場上的兩隊人比賽呢?只能讓他們去同一個地方搶同一個球——這在程式設計中叫「分散式鎖」。
有很多實現分散式鎖的方案(關聯式資料庫、zookeeper、etcd、Redis 等),本篇單講用 Redis 來實現分散式鎖。
小試牛刀
之所以能用 Redis 實現分散式鎖,依賴於其三個特性:
- Redis 作為獨立的儲存,其資料天然可以被多程序共用;
- Redis 的指令是單執行緒執行的,所以不會出現多個指令並行地讀寫同一塊資料;
- Redis 指令是純記憶體操作,速度是微妙級的(不考慮網路時延),效能足夠高;
有些人一想到「單執行緒-高效能」就條件反射地回答 IO 多路複用,其實 Redis 高效能最主要就是純記憶體操作。
Redis 分散式鎖的大體呼叫框架是這樣的:
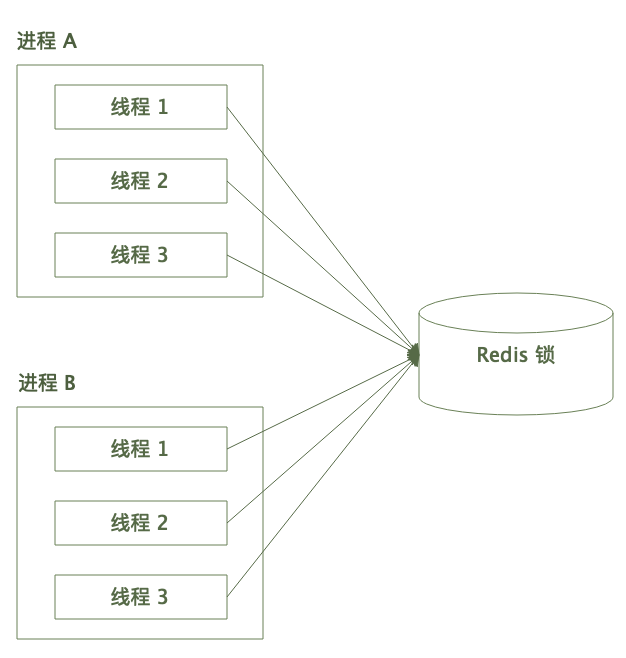
多個程序的多個執行緒爭搶同一把 Redis 鎖。
說到 Redis 分散式鎖,大部分人都會想到 setnx 指令:
// setnx 使用方式
SETNX key value
意思是:如果 key 不存在(Not eXists),則將 key 設定為 value 並返回 1,否則啥也不做並返回 0——也就是說, key 只會被設定一次,利用這個特性就可以實現鎖(如果返回 1 表示加鎖成功,0 則說明別人已經加鎖了,本次加鎖失敗)。
我們寫下虛擬碼:
// 獲取 redis client 單例
var redis = NewRedisClient(redisConf);
// 通過 SETNX 指令加鎖
func lock(string lockKey) bool {
result = redis.setnx(lockKey, 1);
return bool(result);
}
// 通過 DEL 指令解鎖
func unlock(string lockKey) {
redis.del(lockKey);
}
上面的定時任務程序中這樣使用:
var lockKey = "batch:task:list"
// 上鎖
if (!lock(lockKey)) {
// 獲取鎖失敗,直接返回
return false;
}
try {
// 查詢資料庫獲取待處理任務列表
// 更新任務狀態
// 入列
} finally {
// 解鎖
unlock(lockKey);
}
很簡單!半小時搞定,上線!
第一次懵逼
上線沒跑幾天就出問題了:任務無緣無故地不執行了,訊息佇列中很長時間沒接收到訊息了。
分析了半天,我們發現 Redis 中一直存在 batch:task:list 這條記錄,沒人去刪除它!
盯著程式碼我們突然發現問題所在:這個 key 壓根沒有過期時間!也就是說,如果程式不 DEL 它就永遠存在。
估計某程序在執行 unlock 之前崩潰了(或者哪個愣頭青執行了 kill -9 ?),或者 unlock 時發生了網路問題,或者 Redis 宕機了?總之 DEL 沒執行,於是這個鎖永遠得不到釋放!
好辦,加上過期時間唄:
...
// 通過 SETNX 指令加鎖
// 加上過期時間,單位毫秒
func lock(string lockKey, int ttl = 3000) bool {
// 加鎖
result = redis.setnx(lockKey, 1);
// 設定過期時間(毫秒)
redis.pexpire(lockKey, ttl);
return bool(result);
}
...
這段程式碼有什麼問題呢?
這裡通過兩次網路請求執行了兩條 Redis 指令:setnx 設定 KV,expire 設定超時時間——我們前面說鎖操作必須具備原子性,但這兩條操作誰也不能保證要麼都成功要麼都失敗啊。假如第一條指令(setnx)執行成功了,但 expire 由於網路原因或者程序崩潰導致執行失敗了呢?此時同樣會出現上面那個懵逼的問題啊。
我們可以用 Lua 指令碼實現 setnx 和 expire 操作的原子性,不過 Redis 2.6.12 版本後可以用 SET 指令搞定:
// 2.6.12 後的 SET 指令格式
// 現在的 SET 指令相當強大也相當複雜,可以替代 SETNX, SETEX, PSETEX, GETSET, 此處只寫出跟分散式鎖有關的
// 其中兩個可選引數:
// -- NX 表示 Not eXists,就是 SETNX 的意思;
// -- PX 是 PEXPIRE 的意思,表示設定 key 的過期時間(毫秒);
SET key value [NX] [PX milliseconds]
改下 Lock 程式碼:
// 加鎖
func lock(string lockKey, int ttl = 3000) bool {
// Set 函數引數對應上面的命令格式
result = redis.set(lockKey, 1, "NX", "PX", ttl);
return bool(result);
}
如此,加了過期時間防止鎖無法釋放,還保證了加鎖操作的原子性,妥了,上線!
第二次懵逼
第二次上線沒多久又出現了靈異事件:偶爾會出現一批任務重複入列——敢情這鎖加了個寂寞?
各種打紀錄檔,終於發現了端倪:有個程序加鎖 3.5 秒後才解鎖,而且解鎖成功了——但我們設定的鎖超時時間是 3 秒啊!
也就是說,這個執行緒解的是別的執行緒的鎖!
// 通過 DEL 指令解鎖
// 這裡直接調 Redis 的 DEL 指令刪除 lockKey,並沒有判斷該 lockKey 的值是不是本程序設定的
// 所以在有 TTL 的情況下,刪的可能是別的執行緒加的鎖
func unlock(string lockKey) {
redis.del(lockKey);
}
和程序內的本地鎖不同的是,Redis 分散式鎖加入超時機制後,鎖的釋放就存在兩種情況:
- 加鎖者主動釋放;
- 超時被動釋放;
所以解鎖(DEL)之前需要判斷鎖是不是自己加的,方法是在加鎖的時候生成一個唯一標識。之前我們 SET key value 時 value 給的是固定值 1,現在我們換成一個隨機值:
// Redis 分散式鎖
// 封裝成類
// 該類範例不具備執行緒安全性,不應跨執行緒使用
class Lock {
private redis;
private name;
private token;
private ttl;
private status;
const ST_UNLOCK = 1;
const ST_LOCKED = 2;
const ST_RELEASED = 3;
public function Lock(Redis redis, string name, int ttl = 3000) {
this.redis = redis;
this.name = name;
this.token = randStr(16);// 生成 16 位元組隨機字串
this.ttl = ttl;
this.status = self::ST_UNLOCK;
}
// 加鎖
public function lock() bool {
if (this.status != self::ST_UNLOCK) {
return false;
}
// 使用 SET 命令加鎖
// value 不再傳 1,而是設定成建構函式中生成的隨機串
try {
result = redis.set(this.name, this.token, "NX", "PX", this.ttl);
if (bool(result)) {
this.status = self::ST_LOCKED;
return true;
}
} catch (Exception e) {
return false;
}
return false;
}
// 解鎖
public function unlock() {
if (this.status != self::ST_LOCKED) {
return;
}
// 執行 DEL 之前需要用 GET 命令判斷 KEY 的值是不是當前的 token
// 由於需要執行 GET 和 DEL 兩條指令,而鎖操作必須保證原子性,需要用 Lua 指令碼
// 指令碼中通過 redis.call() 執行 Redis 命令
// 注意 Lua 指令碼陣列下標從 1 開始
// 這段指令碼的意思是:
// 如果 key 的值是 token,則 DEL key,否則啥也不做
var lua = "
if (redis.call('get', KEYS[1]) == ARGV[1]) then
redis.call('del', KEYS[1]);
end
return 1;
";
// 調 Redis 的 EVEL 指令執行 Lua 指令碼
// EVAL 指令格式:
// EVEL script numkeys key1,key2,arg1,arg2...
// -- script: Lua 指令碼
// -- numkeys: 說明後面的引數中,有幾個是 key,這些 key 後面的都是引數
// 比如:EVAL "redis.call('set', KEYS[1], ARGV[1])" 1 mykey hello
// 等價於命令 SET mykey hello
// 參見:https://redis.io/commands/eval/
redis.eval(lua, 1, this.name, this.token);
this.status = self::ST_RELEASED;
}
}
業務呼叫:
lock = new Lock(redis, "batch:task:list");
try {
if (!lock.lock()) {
return false;
}
// 加鎖成功,執行業務
} finally {
lock.unlock();
}
上面這段程式碼實現了:
- 加鎖的時候設定了過期時間,防止程序崩潰而導致鎖無法釋放;
- 解鎖的時候判斷了當前的鎖是不是自己加的,防止釋放別人的鎖;
- 加鎖和解鎖操作都具備原子性;
這段程式碼已經是生產可用了,第三次上線。
不過,還是有些優化需要做的。
優化一:鎖等待
上面的 lock() 方法中,如果獲取鎖失敗則直接返回 false,結束執行流,這可能不能滿足某些業務場景。
在本地鎖場景中,如果獲取鎖失敗,執行緒會進入阻塞等待狀態——我們希望分散式鎖也能提供該功能。
我們在加鎖失敗時增加重試功能:
class Lock {
// 重試間隔:1 秒
const RETRY_INTERVAL = 1000;
// ...
// 重試次數(包括首次)
private retryNum;
// retryNum: 預設只執行一次(不重試)
public function Lock(Redis redis, string name, int ttl = 3000, int retryNum = 1) {
...
// 做下防禦
if (retryNum < 0 || retryNum > 20) {
retryNum = 1;
}
this.retryNum = retryNum;
}
// 加鎖
public function lock() bool {
if (this.status != self::ST_UNLOCK) {
return false;
}
// 使用 SET 命令加鎖
// 加入重試機制
for (i = 0; i < this.retryNum; i++) {
try {
result = redis.set(this.name, this.token, "NX", "PX", this.ttl);
if (bool(result)) {
// 加鎖成功,返回
this.status = self::ST_LOCKED;
return true;
}
} catch (Exception e) {
}
// 加鎖失敗了,等待一定的時間後重試
// 當前執行緒/協程進入休眠
sleep(self::RETRY_INTERVAL);
}
return false;
}
}
優化二:鎖超時
我們再回頭看看上面的加鎖邏輯,其核心程式碼如下:
public function lock() bool {
// ...
result = redis.set(this.name, this.token, "NX", "PX", this.ttl);
if (bool(result)) {
// 加鎖成功,返回
this.status = self::ST_LOCKED;
return true;
}
//...
}
這段程式碼有沒有什麼問題呢?
想象如下的加鎖場景:
// 鎖超時時間是 2 秒
var lock = new Lock(redis, name, 2000);
if (lock.lock()) {
// 加鎖成功,加鎖用時 2.5 秒
try {
// 執行業務邏輯
} finally {
// 解鎖
lock.unlock();
}
}
如上,我們建立一個有效期 2 秒的鎖,然後調 Redis 命令加鎖,該過程花了 2.5 秒(可能網路抖動)。
對於本執行緒來說,得到加鎖成功的返回值,繼續往下執行。
但此時該 lockKey 在 Redis 那邊可能已經過期了,如果此時另一個執行緒去拿鎖,也會成功拿到鎖——如此鎖的作用便失效了。
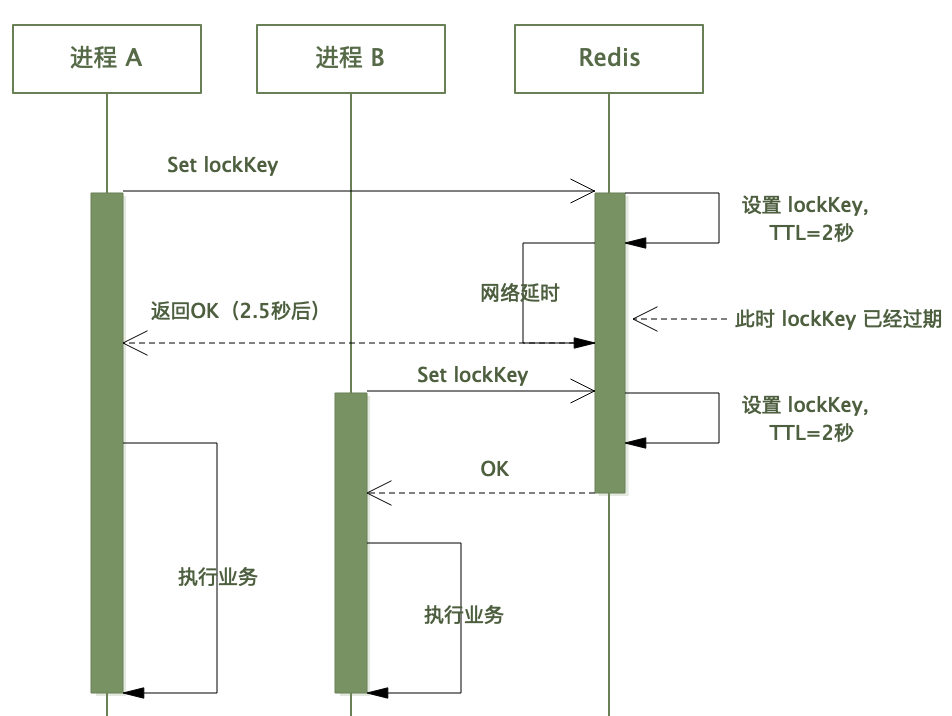
所以,在 lock() 方法中,調 Redis 上鎖成功後,需要判斷上鎖用時,如果時間超過了鎖的有效期,則應視為上鎖無效,如果有重試機制,則重試:
class Lock {
// 加鎖
public function lock() bool {
if (this.status != self::ST_UNLOCK) {
return false;
}
for (i = 0; i < this.retryNum; i++) {
try {
// 上鎖之前,儲存當前毫秒數
var startTime = getMillisecond();
// 上鎖
result = redis.set(this.name, this.token, "NX", "PX", this.ttl);
// 上鎖後,計算使用的時間
var useTime = getMillisecond() - startTime;
// 加鎖成功條件:Redis 上鎖成功,且所用的時間小於鎖有效期
if (bool(result) && useTime < this.ttl) {
// 加鎖成功,返回
this.status = self::ST_LOCKED;
return true;
}
} catch (Exception e) {}
// 加鎖失敗了,等待一定的時間後重試
// 當前執行緒/協程進入休眠
sleep(self::RETRY_INTERVAL);
}
return false;
}
}
如上,在判斷條件中增加了加鎖用時的判斷。
這段程式碼還有問題嗎?
有的。
我們用 Redis 的 SET NX 命令加鎖,該命令如果發現 key 已經存在,則直接返回 0,加鎖失敗。
在上面的失敗重試邏輯中,如果是因為加鎖用時超限導致的失敗(鎖有效期是 2 秒,結果加鎖操作用了 2.5 秒),此時我們並不能切確知道在 Redis 那邊該 key 是否真的已經失效了,如果沒有失效(比如來去網路用時各 1.24 秒,此時該 key 並沒有失效),那麼下一次的重試會因 SET NX 的機制而失敗。
所以我們不能用 SET NX 加鎖,只能用普通的 SET + Lua 指令碼來實現:
class Lock {
// 加鎖
public function lock() bool {
if (this.status != self::ST_UNLOCK) {
return false;
}
// 加鎖的 Lua 指令碼
// 注意 Lua 中的註釋不是用 // 或者 /**/,而是用 --
// 引數說明:
// KEYS[1]: lockKey
// ARGV[1]: token
// ARGV[2]: ttl 毫秒
var lua = "
local val = redis.call('get', KEYS[1]);
if (not val) then
-- 沒有設定,則直接設定
return redis.call('set', KEYS[1], ARGV[1], 'PX', ARGV[2]);
else
-- 存在,則比較 val 是否等於 token
if (val == ARGV[1] ) then
-- 該 key 就是當前執行緒設定的
-- 延長其 TTL
return redis.call('pexpire', KEYS[1], ARGV[2]);
else
-- 其他執行緒上的鎖
return 0;
end
end
";
for (i = 0; i < this.retryNum; i++) {
// 加鎖邏輯同上
}
return false;
}
}
如此,便解決了加鎖超時導致的競態問題——但只解決了一半。
設想這樣的場景:
程序 A 加了一個有效期 5 秒的鎖,加鎖成功後執行業務邏輯,業務邏輯執行耗時 10 秒——就是說,在業務邏輯執行到差不多一半的時候鎖就失效了,此時別的程序就可以搶到鎖了,這就會導致競態問題。
有兩種解決方案:
- 設定個較長的過期時間。這是最簡單的(而且也很有效)。比如我們預估 99% 的處理時間不超過 2 秒,則將鎖有效期設定為 10 秒。該方案最大的缺點是一旦程序崩潰導致無法主動釋放鎖,就會導致其他程序在很長一段時間內(如 10 秒)無法獲得鎖,這在某些場景下可能是非常嚴重的。
- 搞個定時任務執行緒,定時延長鎖的有效期。
方案二虛擬碼如下:
// 帶 Refresh 版本的分散式鎖
class Lock {
private redis;
private name;
private ttl;
private token;
private retryNum;
private status;
// 定時器
private timer;
// 鎖狀態:1 未加鎖;2 已加鎖;3 已釋放
const ST_UNLOCK = 1;
const ST_LOCKED = 2;
const ST_RELEASED = 3;
// 重新整理狀態:
// 4 重新整理成功;
// 5 非法(key 不存在或者不是本執行緒加的鎖)
// 6 重新整理失敗(Redis 不可用)
const RF_SUC = 4;
const RF_INVALID = 5;
const RF_FAIL = 6;
// 建構函式
public function Lock(Redis redis, string name, int ttl = 2000, int retryNum = 1) {
...
}
// 加鎖
// 加鎖成功後啟動定時器
public function lock() bool {
if (this.status != self::ST_UNLOCK) {
return false;
}
// 加鎖的 Lua 指令碼,同前面的
lua = "...";
for (i = 0; i < this.retryNum; i++) {
var startTime = getMillisecond();
try {
// 執行 Lua 指令碼上鎖
result = this.redis.eval(lua, 1, this.name, this.token, this.ttl);
var useTime = getMillisecond() - startTime;
if (bool(result) && useTime < this.ttl) {
// 加鎖成功
this.status = self::ST_LOCKED;
// 啟動定時器
this.tick();
return true;
}
} catch (Exception e) {
// Redis 不可用
}
// 失敗重試
sleep(RETRY_INTERVAL);
}
return false;
}
// 啟動定時器,定時重新整理過期時間
private function tick() {
this.timer = startTimerInterval(
this.ttl / 3,
function () {
result = this.refresh();
if (result == self::RF_INVALID) {
// key 不存在,或者該鎖被其他執行緒佔用
// 停掉定時器
this.timer.stop();
}
}
);
}
// 釋放鎖
// 需要停掉定時器
public function unlock() {
if (this.status != self::ST_LOCKED) {
return;
}
// 釋放鎖的 Lua 指令碼,同前
var lua = "...";
try {
this.redis.eval(lua, 1, this.name, this.token);
} catch (Exception e) {} finally {
this.status = self::ST_RELEASED;
// 停掉定時器
this.timer.stop();
}
}
// 重新整理鎖過期時間
private function refresh() int {
if (this.status != self::ST_LOCKED) {
return self::RF_INVALID;
}
var lua = "
-- key 存在而且其值等於 token 才重新整理過期時間
if (redis.call("get", KEYS[1]) == ARGV[1]) then
return redis.call("pexpire", KEYS[1], ARGV[2])
else
return 0
end
";
try {
result = this.redis.eval(lua, 1, this.name, this.token, this.ttl);
if (result == 0) {
// key 不存在或者是別人加的鎖
return self::RF_INVALID;
} else {
// 重新整理成功
return self::RF_SUC;
}
} catch (Exception e) {
// Redis 不可用
return self::RF_FAIL;
}
}
}
如上,加鎖成功後建立一個單獨的定時器(獨立的執行緒/協程)重新整理鎖的 TTL,只要鎖沒被主動釋放(而且程序沒有崩潰),就會不停地續命,保證不會過期。此時,我們就能在加鎖時選擇一個比較小的過期時間(比如 2 秒),一旦程序崩潰,其他程序也能較快獲得鎖。
上面定時器時間為何選擇 ttl/3 呢?
假設鎖過期時間(ttl)為 6 秒,由上面 lock() 函數邏輯可知,加鎖耗時不可能超過 6 秒(超過就會判定為加鎖失敗)。我們假設某次加鎖耗時比 6 秒小那麼一丟丟(也就是近似 6 秒),接下來什麼時候發起第一次重新整理才能保證 Redis 那邊的 key 不過期呢?極端情況下必須立即重新整理(如果考慮重新整理時的網路時延,就算立即重新整理也不一定能保證)。
不過我們考慮的是一般情況。我們可以認為 6 秒耗時都花在網路上(Redis 本身執行時間可以忽略不計),然後再近似認為這 6 秒被來去均攤,各花 3 秒,因而當我們接收到 Redis 的響應時,該 key 在 Redis 那邊的 TTL 已經用掉了一半,所以定時間隔必須小於 ttl/2,再將重新整理時的網路時延考慮進去,取 ttl/3 或者 ttl/4 比較合適。
就算有了 refresh 機制,也不能說是萬無一失了。
考慮 Redis 宕機或者網路不通的情況。
假設執行緒 A 加鎖(ttl=2s)後不久 Redis 就宕機了(或者該業務服所在網路發生分割區導致網路不通),宕機期間 refresh 會失敗。2s 後 Redis 重啟恢復正常,此時執行緒 A 設定的那個 key 已經過期了,其他執行緒就能夠獲取鎖,如果執行緒 A 的執行時間超過 2s,就和其他執行緒產生競態。
refresh 機制解決不了該問題,要用其他手段來保證 Redis 和鎖的高可用性,如 Redis 叢集、官方提供的 Redlock 方案等。
可重入性
一些語言(如 java)內建可重入鎖,一些語言(如 go)則不支援。
我們通過程式碼說下可重入鎖是什麼:
var lock = newLock();
// 在同一個執行緒中, foo() 調 bar()
// 函數 foo() 和 bar() 都在競爭同一把鎖
function foo() {
lock.lock();
...
bar();
...
lock.unlock();
}
function bar() {
lock.lock();
// do something
lock.unlock();
}
如上,同一個執行緒中 foo() 調 bar(),由於 foo() 調 bar() 之前加了鎖,因而 bar() 中再競爭該鎖時就會一直等待,導致 bar() 函數執行不下去,進而導致 foo() 函數無法解鎖,於是造成死鎖。
如果上面的 lock 是一把可重入鎖,bar() 就會加鎖成功。
實現原理是:加鎖的 lock() 方法中會判斷當前這把鎖被哪個執行緒持有,如果持有鎖的執行緒和現在搶鎖的執行緒是同一個執行緒,則視為搶鎖成功(這鎖本來就是被它持有的嘛,搶啥呢)。
由於 foo() 和 bar() 是在同一個執行緒中呼叫的,所以他倆都會加鎖成功。
鎖是加成功了,解鎖呢?bar() 中的 unlock() 要怎麼處理呢?直接把鎖釋放掉?不行啊,foo() 中的 unlock() 還沒執行呢,bar() 雖然用完鎖了,但 foo() 還沒用完啊,你 bar() 三下五除二把鎖給釋放了,其他執行緒拿到鎖,不就和 foo() 中程式碼構成競態了嗎?
所以可重入鎖採用號誌的思想,在內部維持了兩個屬性:threadid 表示哪個執行緒持有鎖;lockNum 表示持有執行緒加了幾次鎖。同一個執行緒,每 lock() 一次 lockNum 加 1,每 unlock() 一次 lockNum 減 1,只有 lockNum 變成 0 了才表示這把鎖真正釋放了,其他執行緒才能用。
原理講完了,但你不覺得上面的程式碼很怪嗎?
既然 foo() 已經加鎖了,bar() 為何還要加同一把鎖呢?
在某些情況下這樣做可能是有原因的,但大多數情況下,這個問題可以從設計上解決,而不是非要引入可重入鎖。
比如我們可以將 bar() 宣告為非執行緒安全的,將加鎖工作交給呼叫者,同時限制 bar() 的可見域,防止其被濫用。
go 語言不支援可重入鎖的理由就是:當你的程式碼需要用可重入鎖了,你首先要做的是審視你的設計是否有問題。
可重入鎖的便捷性可能會帶來程式碼設計上的問題。
所以本篇並不打算去實現可重入能力——雖然實現起來並不難,無非是將上面講的原理在 Redis 上用 Lua 指令碼實現一遍而已。
不是銀彈
有了錘子,全世界都是釘子。
分散式鎖看似是顆銀彈,但有些問題用其他方案會比分散式鎖要好。
我們看看秒殺扣庫存的例子。
網上很多講分散式鎖的文章都拿秒殺扣庫存來舉例。
秒殺場景為了應對高並行,一般會將秒殺商品庫存提前寫入到 Redis 中,我們假設就用字串型別存商品庫存:
// Redis 命令,設定商品 id=1234 的庫存 100 件
set seckill.stock.1234 100
另外一個使用者只能參加一次秒殺,所以扣庫存前需要判斷該使用者是否已經參加了(防止羊毛黨薅羊毛)。
扣庫存邏輯是這樣的:
var stockKey = "seckill.stock.1234";
var userKey = "seckill.ordered.users";
var lock = new Lock(redis, "seckill");
// 此處省略活動時間的判斷
try {
// 加分散式鎖
lock.lock();
// 判斷庫存
var stockNum = redis.get(stockKey);
if (stockNum <= 0) {
// 庫存不足
return false;
}
// 判斷使用者是否已經參加過
if (redis.sismember(userKey, userId)) {
return false;
}
// 扣庫存
if (redis.decr(stockKey) >= 0) {
// 下單
...
} else {
return false;
}
// 將使用者加入到已參加集合中
redis.sadd(userKey, userId);
return true;
} catch (Exception e) {
// 異常
} finally {
// 解鎖
lock.unlock();
}
以上邏輯為何要用分散式鎖呢?
假設不用分散式鎖,羊毛黨同時發了十個請求(同一個使用者),由於 redis.sismember(userKey, userId) 判斷都會返回 0,於是都能扣庫存下單,羊毛薅了一地。
但該場景有沒有更優的解決方案呢?
我們使用分散式鎖是為了保證臨界區程式碼(lock 保護的區域)執行的原子性——不過 Redis 的原子性還可以通過 Lua 指令碼來實現吧。
上面程式碼一共進行了 6 次 Redis 互動,假設每次用時 50ms,光 Redis 互動這塊就用了 0.3s 的時間。
如果我們將這些邏輯封裝成 Lua 指令碼,只需要一次 Redis 互動就能保證原子性:
var lua = "
-- 引數說明:
-- KEYS[1]: actKey
-- KEYS[2]: userKey
-- KEYS[3]: stockKey
-- ARGV[1]: userId
-- 判斷活動時間
-- (事先將活動的關鍵資訊儲存到 Redis hash 中)
-- 取活動的開始和結束時間
local act = redis.call('hmget', KEYS[1], 'start', 'end');
local now = redis.call('time')[1];
if (not act[1] or now < act[1] or now >= act[2])
then
return 0;
end
-- 判斷庫存
local stock = redis.call('get', KEYS[3]);
if (not stock or tonumber(stock) <= 0)
then
return 0;
end
-- 判斷使用者是否已經參與過
if (redis.call('sismember', KEYS[2], ARGV[1]) == 1)
then
return 0;
end
-- 扣庫存
if (redis.call('decr', KEYS[3]) >= 0)
then
-- 加入使用者
return redis.call('sadd', KEYS[2], ARGV[1]);
else
return 0;
end
";
var actKey = "seckill.act."+actId;
var userKey = actKey + ".users";
var stockKey = actKey + ".stock." + goodsId;
if (redis.eval(lua, 3, actKey, userKey, stockKey, userId)) {
// 扣庫存成功,下單
...
}
上面的指令碼還可以先快取到 Redis 伺服器中,然後用 evalsha 命令執行,這樣使用者端就不用每次都傳這麼一大坨程式碼,進一步提升傳輸效能。
總結
本篇我們從 setnx 命令開始實現了一個最簡單的分散式鎖,而後通過實際使用發現其存在各種缺陷並逐步增強其實現,主要涉及到以下幾個方面:
- 被動釋放。程序崩潰後,程序本地鎖自然會銷燬,但 Redis 鎖不會。所以要加 TTL 機制,防止因加鎖者崩潰而導致鎖無法釋放;
- 屬主。執行緒不能釋放別的執行緒的鎖;
- 鎖等待。加鎖失敗時可以等待一段時間並重試,而不是立即返回;
- 保活。通過定時重新整理鎖的 TTL 防止被動釋放;
不難發現,分散式鎖比程序內本地鎖要複雜得多,也重得多(本地鎖操作是納秒級別,分散式鎖操作是毫秒級別),現實中,在使用分散式鎖之前我們要思考下有沒有其它更優方案,比如樂觀鎖、Lua 指令碼等。
另外需要注意的是,分散式鎖只能解決多程序之間的並行問題,並不能實現資料操作的冪等性。一個例子是增減積分的操作。
增加積分的例子:
// 給使用者增加積分
// sourceType、sourceId:積分來源標識,如消費贈送積分場景的 orderCode
// 冪等性:同樣的 userId-sourceType-sourceId 不能重複加積分
function addBonus(userId, sourceType, sourceId, bonus) {
// 加分散式鎖
var lock = new Lock(...);
try {
if (!lock.lock()) {
return false;
}
// 檢查是否重複
if (isRepeat(userId, sourceType, sourceId)) {
return false;
}
// 加積分
add(userId, sourceType, sourceId, bonus);
} finally {
lock.unlock();
}
}
上面分散式鎖的作用是防止並行請求(呼叫端 bug?薅羊毛?),而該操作的冪等性是由 isRepeat() 保證的(查資料庫)。
保障冪等性一般有悲觀鎖和樂觀鎖兩種模式。
上面這種屬於悲觀鎖模式(把整個操作鎖起來),另一種樂觀鎖實現方式是給 userId-sourceType-sourceId 加上組合唯一鍵約束,此時就不需要加分散式鎖,也不需要 isRepeat() 檢測,直接 add(userId, sourceType, sourceId, bonus) 就能搞定。
最後說下文中為啥使用虛擬碼(而不是用具體某一門程式語言實現)。
用虛擬碼的最主要目的是省去語言特定的實現細節,將關注點放在邏輯本身。
比如 redis 使用者端,不同語言有不同的使用方式,就算同一門語言的不同類庫用法也不同,有些語言的類庫用起來又臭又長,影響心情。
虛擬碼不受特定語言約束,用起來自由自在,本文中 redis 使用者端的使用方式和 Redis 官方的原始命令格式完全一致,沒有額外的心智負擔。
再比如生成 token 的隨機字串函數 randStr(),go 語言要這樣寫:
func randStr(size int) (string, error) {
sl := make([]byte, size)
if _, err := io.ReadFull(rand.Reader, sl); err != nil {
return "", err
}
return base64.RawURLEncoding.EncodeToString(sl), nil
}
程式碼雖然不多,但沒玩過 go 的小夥伴看到這兒心裡是不是要起伏那麼兩三下?但這玩意怎麼實現跟本文的主題沒半毛錢關係。
相反,本文的 lua 指令碼都是貨真價實的,測試通過的——因為這是本文的核心啊。
虛擬碼的缺點是它不能「拎包入住」,但本文的重點並不是要寫個原始碼庫——我們沒必要真的自己寫一個,直接用 redission 或者其他什麼庫不香嗎?
本文的重點在於分析 Redis 分散式鎖的原理,分散式鎖面臨哪些問題?解決思路是什麼?使用時要注意什麼?知其然知其所以然。
當你不知其所以然時,很多東西顯得特高大上,什麼「看門狗」,搞得神乎其神,當搞明白其原理和目的時,也就那麼回事。

本文來自部落格園,作者:林子er,轉載請註明原文連結:https://www.cnblogs.com/linvanda/p/16393316.html