Java中的set集合如何理解

推薦學習:《》
Set系類集合特點:
- 無序:存取順序不一致
- 不重複:可以去除重複
- 無索引:沒有帶索引的方法,所以不能使用普通for迴圈遍歷,也不能通過索引來獲取元素
Set集合實現類特點:
HashSet:無序、不重複、無索引
LinkedHashSet:有序、不重複、無索引
TreeSet:排序、不重複、無索引
Set集合的功能上基本上與Collection的API一致。
HashSet集合
HashSet集合:
Set<String> set = new HashSet<>();
set.add("石原里美");
set.add("石原里美");
set.add("工藤靜香");
set.add("朱茵");
System.out.println(set);
set.remove("朱茵");
System.out.println(set);輸出結果:
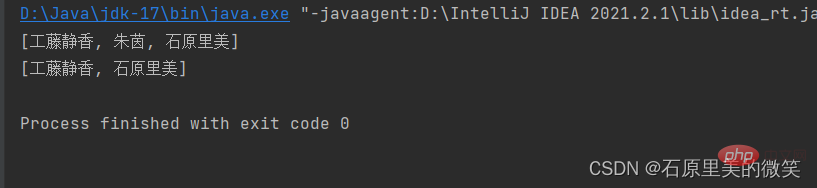
通過上述程式碼與執行結果,我們可以清晰地看出,HashSet集合無序、不重複的特性;
結合上述圖片所示,可以看出HashSet集合是無法通過get()方法的索引獲取資料的,並且在刪除集合中的資料的時候,也只能通過定向的對資料進行刪除。
LinkedHashSet集合:
LinkedHashSet集合:
Set<String> set = new LinkedHashSet<>();
set.add("石原里美");
set.add("石原里美");
set.add("工藤靜香");
set.add("朱茵");
System.out.println(set);
set.remove("朱茵");
System.out.println(set);輸出結果:
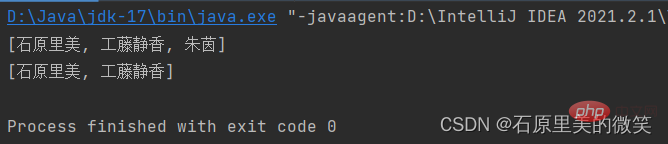
通過上述程式碼與輸出結果做對比,即可看出無序與有序之間的區別,前者是會將傳入的資料順序打亂,而後者則是仍然按照輸入資料的順序儲存資料,因此輸出的時候是有序狀態。
TreeSet集合:
TreeSet集合:
Set<Integer> set = new TreeSet<>();
set.add(13);
set.add(23);
set.add(23);
set.add(11);
System.out.println(set);
set.remove(23);
System.out.println(set);輸出結果:

通過上述程式碼和輸出結果我們便可以通過字面意思去理解為什麼TreeSet的特點是排序了,即將儲存的資料按照Java預設的排序方式進行排序。
然而此時若儲存自定義如People物件,TreeSet無法直接排序,會出現報錯的情況!
//People類:
public class People{
private String name;
private int age;
private String classroom;
public People(){
}
public People(String name, int age, String classroom) {
this.name = name;
this.age = age;
this.classroom = classroom;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getClassroom() {
return classroom;
}
public void setClassroom(String classroom) {
this.classroom = classroom;
}
@Override
public String toString() {
return "People{" +
"name='" + name + '\'' +
", age=" + age +
", classroom='" + classroom + '\'' +
'}';
}
}
//main方法:
public static void main(String[] args) {
Set<People> p = new TreeSet<>();
p.add(new People("張三",19,"智慧"));
p.add(new People("李四",18,"資料庫"));
p.add(new People("王五",20,"滲透"));
System.out.println(p);
}若想解決該問題,我們就需要為TreeSet集合自定義儲存型別,現有兩種方式可以解決該問題:一種是自定義類實現Comparable介面並重寫裡面的compareTo方法指定規則;另一種則是集合自帶比較器物件進行規則定義。
方式一:自定義類實現Comparable介面重寫裡面的compareTo方法指定比較規則(多餘無關緊要的程式碼在此不再贅述了,只展示重要的那部分程式碼)
//改變的第一個地方:實現Comparable類
public class People implements Comparable<People> {
//改變的第二個地方:重寫Comparable類中的compareTo方法
@Override
public int compareTo(People o) {
return this.age-o.age;
}
}輸出結果(根據年齡進行比較):

在重寫的方法中,return後面的程式碼決定了該物件將要根據什麼準則進行比較,比較規則如下:
- 如果認為第一個元素大於第二個元素返回正整數即可
- 如果認為第一個元素小於第二個元素返回負整數即可
- 如果認為第一個元素等於第二個元素返回0即可,此時Treeset集合只會保留一個元素,認為兩者重複
方式二:集合自帶比較器物件進行規則定義
Set<People> p = new TreeSet<>(new Comparator<People>() {
@Override
public int compare(People o1, People o2) {
return o1.getAge()-o2.getAge();
}
});在原來的基礎之上對集合的建立作出改變,並且其比較準則與前面的定義方法類似,相對前面的方式,這種方式會更加方便快捷一些。在此,我們也可以回顧一些前面所學到的知識「Lambda表示式」,對給程式碼塊進行化簡。
Set<People> p = new TreeSet<>((o1, o2) -> o1.getAge()-o2.getAge());
如果沒有學習過Lambda表示式,或者說是對Lambda表示式的知識不清晰,那麼可以可以看Java中的lambda表示式如何理解——精簡這篇文章的講解,或許會對你有所幫助的。
推薦學習:《》
以上就是Java中的set集合如何理解的詳細內容,更多請關注TW511.COM其它相關文章!