go-zero微服務實戰系列(五、快取程式碼怎麼寫)
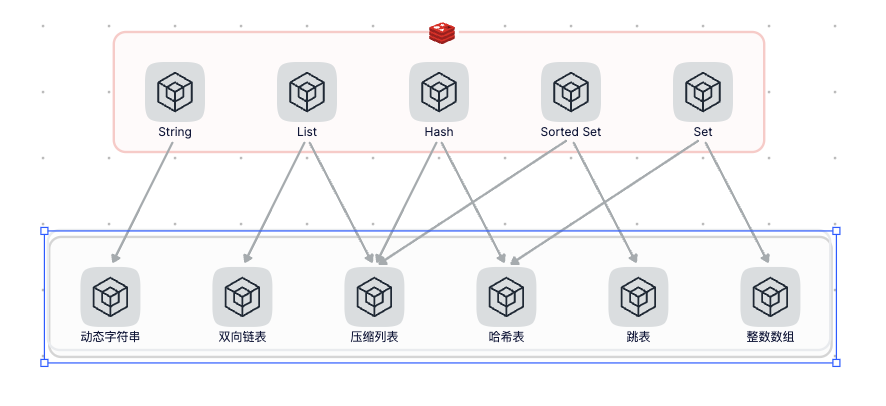
快取是高並行服務的基礎,毫不誇張的說沒有快取高並行服務就無從談起。本專案快取使用Redis,Redis是目前主流的快取資料庫,支援豐富的資料型別,其中集合型別的底層主要依賴:整數陣列、雙向連結串列、雜湊表、壓縮列表和跳錶五種資料結構。由於底層依賴的資料結構的高效性以及基於多路複用的高效能I/O模型,所以Redis也提供了非常強悍的效能。下圖展示了Redis資料型別對應的底層資料結構。
基本使用
在go-zero中預設整合了快取model資料的功能,我們在使用goctl自動生成model程式碼的時候加上 -c 引數即可生成整合快取的model程式碼
goctl model mysql datasource -url="root:123456@tcp(127.0.0.1:3306)/product" -table="*" -dir="./model" -c
通過簡單的設定我們就可以使用model層的快取啦,model層快取預設過期時間為7天,如果沒有查到資料會設定一個空快取,空快取的過期時間為1分鐘,model層cache設定和初始化如下:
CacheRedis:
- Host: 127.0.0.1:6379
Type: node
CategoryModel: model.NewCategoryModel(conn, c.CacheRedis)
這次演示的程式碼主要會基於product-rpc服務,為了簡單我們直接使用grpcurl來進行偵錯,注意啟動的時候主要註冊反射服務,通過goctl自動生成的rpc服務在dev或test環境下已經幫我們註冊好了,我們需要把我們的mode設定為dev,預設的mode為pro,如下程式碼所示:
s := zrpc.MustNewServer(c.RpcServerConf, func(grpcServer *grpc.Server) {
product.RegisterProductServer(grpcServer, svr)
if c.Mode == service.DevMode || c.Mode == service.TestMode {
reflection.Register(grpcServer)
}
})
直接使用go install安裝grpcurl工具,so easy !!!媽媽再也不用擔心我不會偵錯gRPC了
go install github.com/fullstorydev/grpcurl/cmd/grpcurl
啟動服務,通過如下命令查詢服務,服務提供的方法,可以看到當前提供了Product獲取商品詳情介面和Products批次獲取商品詳情介面
~ grpcurl -plaintext 127.0.0.1:8081 list
grpc.health.v1.Health
grpc.reflection.v1alpha.ServerReflection
product.Product
~ grpcurl -plaintext 127.0.0.1:8081 list product.Product
product.Product.Product
product.Product.Products
我們先往product表裡插入一些測試資料,測試資料放在lebron/sql/data.sql檔案中,此時我們檢視id為1的商品資料,這時候快取中是沒有id為1這條資料的
127.0.0.1:6379> EXISTS cache:product:product:id:1
(integer) 0
通過grpcurl工具來呼叫Product介面查詢id為1的商品資料,可以看到已經返回了資料
~ grpcurl -plaintext -d '{"product_id": 1}' 127.0.0.1:8081 product.Product.Product
{
"productId": "1",
"name": "夾克1"
}
再看redis中已經存在了id為1的這條資料的快取,這就是框架給我們自動生成的快取
127.0.0.1:6379> get cache:product:product:id:1
{\"Id\":1,\"Cateid\":2,\"Name\":\"\xe5\xa4\xb9\xe5\x85\x8b1\",\"Subtitle\":\"\xe5\xa4\xb9\xe5\x85\x8b1\",\"Images\":\"1.jpg,2.jpg,3.jpg\",\"Detail\":\"\xe8\xaf\xa6\xe6\x83\x85\",\"Price\":100,\"Stock\":10,\"Status\":1,\"CreateTime\":\"2022-06-17T17:51:23Z\",\"UpdateTime\":\"2022-06-17T17:51:23Z\"}
我們再請求id為666的商品,因為我們表裡沒有id為666的商品,框架會幫我們快取一個空值,這個空值的過期時間為1分鐘
127.0.0.1:6379> get cache:product:product:id:666
"*"
當我們刪除資料或者更新資料的時候,以id為key的行記錄快取會被刪除
快取索引
我們的分類商品列表是需要支援分頁的,通過往上滑動可以不斷地載入下一頁,商品按照建立時間倒序返回列表,使用遊標的方式進行分頁。
怎麼在快取中儲存分類的商品呢?我們使用Sorted Set來儲存,member為商品的id,即我們只在Sorted Set中儲存快取索引,查出快取索引後,因為我們自動生成了以主鍵id索引為key的快取,所以查出索引列表後我們再查詢行記錄快取即可獲取商品的詳情,Sorted Set的score為商品的建立時間。
下面我們一起來分析分類商品列表的邏輯該怎麼寫,首先先從快取中讀取當前頁的商品id索引,呼叫cacheProductList方法,注意,這裡呼叫查詢快取方法忽略了error,為什麼要忽略這個error呢,因為我們期望的是盡最大可能的給使用者返回資料,也就是redis掛掉了的話那我們就會從資料庫查詢資料返回給使用者,而不會因為redis掛掉而返回錯誤。
pids, _ := l.cacheProductList(l.ctx, in.CategoryId, in.Cursor, int64(in.Ps))
cacheProductList方法實現如下,通過ZrevrangebyscoreWithScoresAndLimitCtx倒序從快取中讀資料,並限制讀條數為分頁大小
func (l *ProductListLogic) cacheProductList(ctx context.Context, cid int32, cursor, ps int64) ([]int64, error) {
pairs, err := l.svcCtx.BizRedis.ZrevrangebyscoreWithScoresAndLimitCtx(ctx, categoryKey(cid), cursor, 0, 0, int(ps))
if err != nil {
return nil, err
}
var ids []int64
for _, pair := range pairs {
id, _ := strconv.ParseInt(pair.Key, 10, 64)
ids = append(ids, id)
}
return ids, nil
}
為了表示列表的結束,我們會在Sorted Set中設定一個結束標誌符,該標誌符的member為-1,score為0,所以我們在從快取中查出資料後,需要判斷資料的最後一條是否為-1,如果為-1的話說明列表已經載入到最後一頁了,使用者再滑動螢幕的話前端就不會再繼續請求後端的介面了,邏輯如下,從快取中查出資料後再根據主鍵id查詢商品的詳情即可
pids, _ := l.cacheProductList(l.ctx, in.CategoryId, in.Cursor, int64(in.Ps))
if len(pids) == int(in.Ps) {
isCache = true
if pids[len(pids)-1] == -1 {
isEnd = true
}
}
如果從快取中查出的資料為0條,那麼我們就從資料庫中查詢該分類下的資料,這裡要注意從資料庫查詢資料的時候我們要限制查詢的條數,我們預設一次查詢300條,因為我們每頁大小為10,300條可以讓使用者下翻30頁,大多數情況下使用者根本不會翻那麼多頁,所以我們不會全部載入以降低我們的快取資源,當用戶真的翻頁超過30頁後,我們再按需載入到快取中
func (m *defaultProductModel) CategoryProducts(ctx context.Context, cateid, ctime, limit int64) ([]*Product, error) {
var products []*Product
err := m.QueryRowsNoCacheCtx(ctx, &products, fmt.Sprintf("select %s from %s where cateid=? and status=1 and create_time<? order by create_time desc limit ?", productRows, m.table), cateid, ctime, limit)
if err != nil {
return nil, err
}
return products, nil
}
獲取到當前頁的資料後,我們還需要做去重,因為如果我們只以createTime作為遊標的話,很可能資料會重複,所以我們還需要加上id作為去重條件,去重邏輯如下
for k, p := range firstPage {
if p.CreateTime == in.Cursor && p.ProductId == in.ProductId {
firstPage = firstPage[k:]
break
}
}
最後,如果沒有命中快取的話,我們需要把從資料庫查出的資料寫入快取,這裡需要注意的是如果資料已經到了末尾需要加上資料結束的識別符號,即val為-1,score為0,這裡我們非同步的寫會快取,因為寫快取並不是主邏輯,不需要等待完成,寫失敗也沒有影響呢,通過非同步方式降低介面耗時,處處都有小優化呢
if !isCache {
threading.GoSafe(func() {
if len(products) < defaultLimit && len(products) > 0 {
endTime, _ := time.Parse("2006-01-02 15:04:05", "0000-00-00 00:00:00")
products = append(products, &model.Product{Id: -1, CreateTime: endTime})
}
_ = l.addCacheProductList(context.Background(), products)
})
}
可以看出想要寫一個完整的基於遊標分頁的邏輯還是比較複雜的,有很多細節需要考慮,大家平時在寫類似程式碼時一定要細心,該方法的整體程式碼如下:
func (l *ProductListLogic) ProductList(in *product.ProductListRequest) (*product.ProductListResponse, error) {
_, err := l.svcCtx.CategoryModel.FindOne(l.ctx, int64(in.CategoryId))
if err == model.ErrNotFound {
return nil, status.Error(codes.NotFound, "category not found")
}
if in.Cursor == 0 {
in.Cursor = time.Now().Unix()
}
if in.Ps == 0 {
in.Ps = defaultPageSize
}
var (
isCache, isEnd bool
lastID, lastTime int64
firstPage []*product.ProductItem
products []*model.Product
)
pids, _ := l.cacheProductList(l.ctx, in.CategoryId, in.Cursor, int64(in.Ps))
if len(pids) == int(in.Ps) {
isCache = true
if pids[len(pids)-1] == -1 {
isEnd = true
}
products, err := l.productsByIds(l.ctx, pids)
if err != nil {
return nil, err
}
for _, p := range products {
firstPage = append(firstPage, &product.ProductItem{
ProductId: p.Id,
Name: p.Name,
CreateTime: p.CreateTime.Unix(),
})
}
} else {
var (
err error
ctime = time.Unix(in.Cursor, 0).Format("2006-01-02 15:04:05")
)
products, err = l.svcCtx.ProductModel.CategoryProducts(l.ctx, ctime, int64(in.CategoryId), defaultLimit)
if err != nil {
return nil, err
}
var firstPageProducts []*model.Product
if len(products) > int(in.Ps) {
firstPageProducts = products[:int(in.Ps)]
} else {
firstPageProducts = products
isEnd = true
}
for _, p := range firstPageProducts {
firstPage = append(firstPage, &product.ProductItem{
ProductId: p.Id,
Name: p.Name,
CreateTime: p.CreateTime.Unix(),
})
}
}
if len(firstPage) > 0 {
pageLast := firstPage[len(firstPage)-1]
lastID = pageLast.ProductId
lastTime = pageLast.CreateTime
if lastTime < 0 {
lastTime = 0
}
for k, p := range firstPage {
if p.CreateTime == in.Cursor && p.ProductId == in.ProductId {
firstPage = firstPage[k:]
break
}
}
}
ret := &product.ProductListResponse{
IsEnd: isEnd,
Timestamp: lastTime,
ProductId: lastID,
Products: firstPage,
}
if !isCache {
threading.GoSafe(func() {
if len(products) < defaultLimit && len(products) > 0 {
endTime, _ := time.Parse("2006-01-02 15:04:05", "0000-00-00 00:00:00")
products = append(products, &model.Product{Id: -1, CreateTime: endTime})
}
_ = l.addCacheProductList(context.Background(), products)
})
}
return ret, nil
}
我們通過grpcurl工具請求ProductList介面後返回資料的同時也寫進了快取索引中,當下次再請求的時候就直接從快取中讀取
grpcurl -plaintext -d '{"category_id": 8}' 127.0.0.1:8081 product.Product.ProductList
快取擊穿
快取擊穿是指存取某個非常熱的資料,快取不存在,導致大量的請求傳送到了資料庫,這會導致資料庫壓力陡增,快取擊穿經常發生在熱點資料過期失效時,如下圖所示:
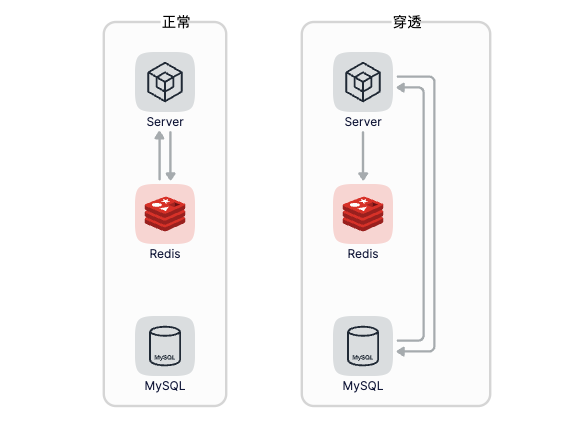
既然快取擊穿經常發生在熱點資料過期失效的時候,那麼我們不讓快取失效不就好了,每次查詢快取的時候不要使用Exists來判斷key是否存在,而是使用Expire給快取續期,通過Expire返回結果判斷key是否存在,既然是熱點資料通過不斷地續期也就不會過期了
還有一種簡單有效的方法就是通過singleflight來控制,singleflight的原理是當同時有很多請求同時到來時,最終只有一個請求會最終存取到資源,其他請求都會等待結果然後返回。獲取商品詳情使用singleflight進行保護範例如下:
func (l *ProductLogic) Product(in *product.ProductItemRequest) (*product.ProductItem, error) {
v, err, _ := l.svcCtx.SingleGroup.Do(fmt.Sprintf("product:%d", in.ProductId), func() (interface{}, error) {
return l.svcCtx.ProductModel.FindOne(l.ctx, in.ProductId)
})
if err != nil {
return nil, err
}
p := v.(*model.Product)
return &product.ProductItem{
ProductId: p.Id,
Name: p.Name,
}, nil
}
快取穿透
快取穿透是指要存取的資料既不在快取中,也不在資料庫中,導致請求在存取快取時,發生快取缺失,再去存取資料庫時,發現資料庫中也沒有要存取的資料。此時也就沒辦法從資料庫中讀出資料再寫入快取來服務後續的請求,類似的請求如果多的話就會給快取和資料庫帶來巨大的壓力。
針對快取穿透問題,解決辦法其實很簡單,就是快取一個空值,避免每次都透傳到資料庫,快取的時間可以設定短一點,比如1分鐘,其實上文已經有提到了,當我們存取不存在的資料的時候,go-zero框架會幫我們自動加上空快取,比如我們存取id為999的商品,該商品在資料庫中是不存在的。
grpcurl -plaintext -d '{"product_id": 999}' 127.0.0.1:8081 product.Product.Product
此時檢視快取,已經幫我新增好了空快取
127.0.0.1:6379> get cache:product:product:id:999
"*"
快取雪崩
快取雪崩時指大量的的應用請求無法在Redis快取中進行處理,緊接著應用將大量的請求傳送到資料庫,導致資料庫被打掛,好慘吶!!快取雪崩一般是由兩個原因導致的,應對方案也不太一樣。
第一個原因是:快取中有大量的資料同時過期,導致大量的請求無法得到正常處理。
針對大量資料同時失效帶來的快取雪崩問題,一般的解決方案是要避免大量的資料設定相同的過期時間,如果業務上的確有要求資料要同時失效,那麼可以在過期時間上加一個較小的亂數,這樣不同的資料過期時間不同,但差別也不大,避免大量資料同時過期,也基本能滿足業務的需求。
第二個原因是:Redis出現了宕機,沒辦法正常響應請求了,這就會導致大量請求直接打到資料庫,從而發生雪崩
針對這類原因一般我們需要讓我們的資料庫支援熔斷,讓資料庫壓力比較大的時候就觸發熔斷,丟棄掉部分請求,當然熔斷是對業務有損的。
在go-zero的資料庫使用者端是支援熔斷的,如下在ExecCtx方法中使用熔斷進行保護
func (db *commonSqlConn) ExecCtx(ctx context.Context, q string, args ...interface{}) (
result sql.Result, err error) {
ctx, span := startSpan(ctx, "Exec")
defer func() {
endSpan(span, err)
}()
err = db.brk.DoWithAcceptable(func() error {
var conn *sql.DB
conn, err = db.connProv()
if err != nil {
db.onError(err)
return err
}
result, err = exec(ctx, conn, q, args...)
return err
}, db.acceptable)
return
}
結束語
本篇文章先介紹了go-zero中快取使用的基本姿勢,接著詳細介紹了使遊標通過快取索引來實現分頁功能,緊接著介紹了快取擊穿、快取穿透、快取雪崩的概念和應對方案。快取對於高並行系統來說是重中之重,但是快取的使用坑還是挺多的,大家在平時專案開發中一定要非常仔細,如果使用不當的話不但不能帶來效能的提升,反而會讓業務程式碼變得複雜。
在這裡要非常感謝go-zero社群中的@group和@尋找,最美的心靈兩位同學,他們積極地參與到該專案的開發中,並提了許多改進意見。
希望本篇文章對你有所幫助,謝謝。
每週一、週四更新
程式碼倉庫: https://github.com/zhoushuguang/lebron
專案地址
https://github.com/zeromicro/go-zero
歡迎使用 go-zero 並 star 支援我們!
微信交流群
關注『微服務實踐』公眾號並點選 交流群 獲取社群群二維條碼。