迴圈碼、折積碼及其python實現
摘要:本文介紹了迴圈碼和折積碼兩種編碼方式,並且,作者給出了兩種編碼方式的編碼譯碼的python實現
關鍵字:迴圈碼,系統編碼,折積碼,python,Viterbi演演算法
迴圈碼的編碼譯碼
設 \(C\) 是一個 \(q\) 元 \([n,n-r]\) 迴圈碼,其生成多項式為\(g(x), \text{deg}(g(x))=r\)。顯然,\(C\) 有 \(n-r\) 個資訊位,\(r\) 個校驗位。我們用 \(C\) 對資訊源 \(V(n-r,q)\) 中的向量進行表示。
對任意資訊源向量 \(a_0a_1\cdots a_{n-r-1}\in V(n-r,q)\),迴圈碼有兩種編碼思路:
非系統的編碼方法
構造資訊多項式
該資訊源的多項式對應於迴圈碼 \(C\) 的一個碼字
系統編碼
構造資訊多項式
顯然當 \(a_0,a_1,\cdots,a_{n-r-1}\) 不全為零時。\(r\lt\text{deg}(\bar{a}(x))=n-1\)。用 \(g(x)\) 去除 \(\bar{a}(x)\),得到
其中 \(\text{deg}(r(x))\lt\text{deg}(g(x))=r\),資訊源多項式被編碼為C中的碼字
可以看到,\(\bar{a}(x)\) 和 \(r(x)\) ,沒有相同的項,所以這種編碼方式為系統編碼。也即,如果將 \(c(x)\) 中的 \(x\) 的項按生降次排序,則碼字前 \(n-r\) 位就是資訊位,後 \(r\) 位是校驗位。
例子:二元(7,4)迴圈碼
已知 \(C\) 是一個二元 \((7,4)\) 迴圈碼,生成多項式為 \(g(x)=x^3+x+1\)。
\(0101\in V(4,2)\) 是代編碼的資訊向量
非系統編碼(升冪排序,資訊向量為 \(x+x^3\))
也即,\(0101\in V(4,2)\) 被編碼為\(0111001\in V(7,2)\)
系統編碼(降冪排序,資訊向量為 \(x^5+x^3\))
也就是,\(0101\in V(4,2)\) 被編碼為\(0101100\in V(7,2)\)
一般而言,系統碼解碼速度相比非系統編碼更快。接下來我們對上述例子進一步探索。
系統碼的生成矩陣
考慮 \(F_2[x]/\langle x^7-1\rangle\) 中階數大於3的基。
也即,\(1000\in V(4,2)\) 被編碼為\(1000101\in V(7,2)\)。
也即,\(0100\in V(4,2)\) 被編碼為\(0100111\in V(7,2)\)。
也即,\(0010\in V(4,2)\) 被編碼為\(0010110\in V(7,2)\)。
也即,\(0001\in V(4,2)\) 被編碼為\(0001011\in V(7,2)\)。
所以生成多項式為 \(g(x)=x^3+x+1\) 的 \((7,4)\) 迴圈碼C的生成矩陣為
迴圈碼的譯碼
首先我們不加證明的引入迴圈矩陣的校驗多項式核校驗矩陣的知識。
定義 設 \(C\subset R_n\) 是一個 \(q\) 元 \([n,n-r]\) 迴圈碼,其生成多項式為 \(g(x)\),校驗多項式定義為
定理 設 \(C\subset R_n\) 是一個 \(q\) 元 \([n,n-r]\) 迴圈碼,其生成多項式為 \(g(x)\),校驗多項式為 \(h(x)\),則對任意 \(c(x)\in R_n(x)\),\(c(x)\) 是 \(C\) 的一個碼字當且僅當 \(c(x)h(x)=0\)。
定理 設\(C\subset R_n\) 是一個 \(q\) 元 \([n,n-r]\) 迴圈碼,其生成多項式為 \(g(x)\),校驗多項式記為
且其校驗矩陣為
所以可得,對於已知 \(C\) 是一個二元 \((7,4)\) 迴圈碼,生成多項式為 \(g(x)=x^3+x+1\),校驗多項式為 \(h(x)=x^4+x^3+x^2+1\),校驗矩陣為
因為是系統編碼,所以,如果將 \(c(x)\) 中的 \(x\) 的項按降冪次排序,則碼字前 \(n-r\) 位就是資訊位,後 \(r\) 位是校驗位。也就是,如果不出錯,則接受的的碼字的前 4 個''字母''(資訊位元)就是對方傳輸的資訊。
但是考慮到一般情形,二元迴圈碼解碼流程如下
- 根據碼字 \(C\) 及其生成多項式,構造校驗多項式,進一步得到校驗矩陣 \(H\)
- 接收到向量 \(y\),計算其伴隨 \(S(y)=yH^{T}\)
- 若 \(S(y)\) 等於零,我們則認為傳輸過程沒有發生錯誤,\(y\) 就是傳送碼字
- 若 \(S(y)\) 不等於零,則 \(S(y)\) 可表示為 \(b(H_i)^T\),其中 \(0\ne b\in GF(q),1\le i\le n\)。這時我們認為 \(y\) 中的第 \(i\) 個分量發生錯誤,\(y\) 被譯為碼字 \(y-\alpha_i\),其中 \(\alpha_i\) 中的第 \(i\) 個分量為 \(b\),其餘分量為零。
對於上述碼字,若接收到 \(y=0110010\),\(S(y)=yH^T=011=1*H_4\),所以傳送碼字為 \(0111010\),也即代表資訊源 \(0111\)。
對於上述迴圈碼,python程式實現如下
# (7,4)二元迴圈碼
# 生成多項式 g(x)= x^3+x+1
import numpy as np
# 生成矩陣
G = np.array([
[1,0,0,0,1,0,1],
[0,1,0,0,1,1,1],
[0,0,1,0,1,1,0],
[0,0,0,1,0,1,1]
])
# 校驗矩陣
H = np.array([
[1,1,1,0,1,0,0],
[0,1,1,1,0,1,0],
[0,0,1,1,1,0,1]
])
# 編碼
def encode_cyclic(x):
if not len(x) == 4:
print("請輸入4位元資訊位元")
return
y = np.dot(x,G)
print(x,"編碼為:",y)
return y
# 譯碼,過程與漢明碼一致
def decode_cyclic(y):
if not len(y) == 7:
print("請輸入7位資訊位元")
return
x_tmp = np.dot(y,H.T)%2
if (x_tmp!=0).any():
for i in range(H.shape[1]):
if (x_tmp==H[:,i]).all():
y[i] = (y[i]-1)%2
break
x = y[0:4]
print(y,"解碼為:",x)
return x
# 測試
if __name__ == '__main__':
y = [1,0,0,0,1,0,1]
decode_cyclic(y)
x=[1,0,0,0]
encode_cyclic(x)
折積碼
折積碼是通道編碼技術的一種,屬於一種糾錯碼。最早由1955年Elias最早提出,目的是為了減少在信源訊息在通道傳輸過程中產生的差錯,增加接收端譯碼的準確性。
折積碼的生成方式是將待傳輸的資訊序列通過線性有限狀態移位暫存器,也就是在折積碼的編碼過程中,需要輸入訊息源與編碼器中的衝激響應做折積。具體說來,在任意時段,編碼器的 \(n\) 個輸出不僅與此時段的 \(k\) 個輸入有關,還與暫存器中前 \(m\) 個輸入有關。折積碼的糾錯能力隨著 \(m\) 的增加而增大,同時差錯率隨著 \(m\) 的增加而成指數下降。
引數 \((n,k,m)\) 解釋如下:
- \(m\) :約束長度,即位移暫存器的級數(個數),每級(每個)包含 \(k\) 個引數(\(k\) 個輸入)。
- \(k\) :資訊碼位的數目,是折積編碼器的每級輸入的位元數目
- \(n\) :k位資訊碼對應編碼後的輸出位元數,它與 \(mk\) 個輸入位元相關
- 編碼速率: \(R_c=k/n\)
由此看來,折積碼編碼的結果與之前的輸入有關,編碼具有記憶性,是非分組碼。而分組碼的編碼只於當前輸入有關,編碼不具有記憶性。
1967年Viterbi提出基於動態規劃的最大似然Viterbi譯碼法。
折積碼編碼
如下圖為:(2,1,2)折積碼的編碼示意圖
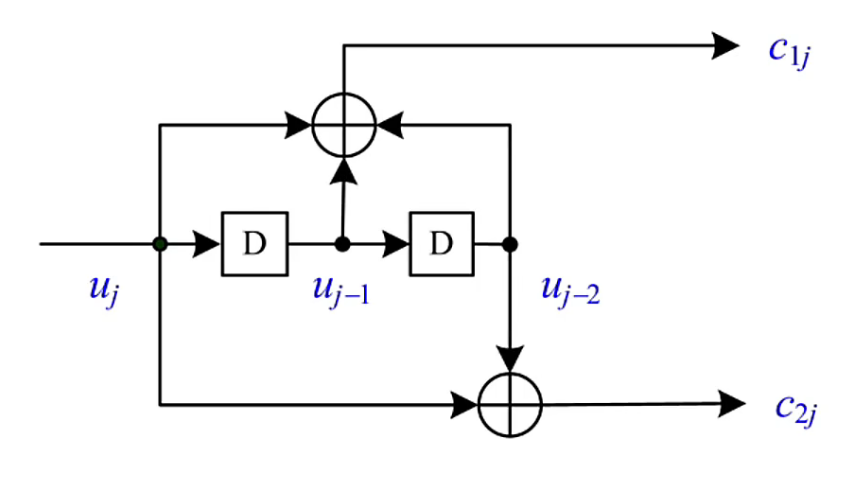
格圖結構更加緊湊,代表著時間的移動,也即,資訊位元在不斷輸入。
從上圖中,我們可得出,若輸入序列是 \(10110\),則輸出序列為 \(11 10 00 01 01\)。
程式碼範例如下
# (2,1,2)折積碼
# 折積編碼
def encode_conv(x):
# 儲存編碼資訊
y = []
# 兩個暫存器u_1 u_2初始化為0
u_2 = 0
u_1 = 0
for j in x:
c_1 = (j + u_1 + u_2)%2
c_2 = (j+u_2)%2
y.append(c_1)
y.append(c_2)
# 更新暫存器
u_2 = u_1
u_1 = j
print(x,"編碼為:",y)
return y
# 測試程式碼
if __name__ == '__main__':
encode_conv([1,0,1,1,0])
折積碼的譯碼
我們注意到
- 任何一個編碼器輸出序列,都對應著樹圖(格圖)上唯一的一條路徑
- 譯碼器要根據接收序列,找出這條路徑
- 按照最大似然(Maximum Likelihood )譯碼原則,譯碼器應該在圖的所有路徑中找出這樣一條,其編碼輸出序列與譯碼器接收的序列之間碼距最小。
分支度量(以(2,1,2)折積碼為例)
設 \(j\) 時刻接受的位元是 \(y_{1j}y_{2j}\)
- 網格圖在 \(j\ge2\) 時刻有8種不同的分支(相同分支:出發狀態和到達狀態相同),每個分支對應兩個位元編碼輸出 \(c_{1j}c_{2j}\)
- 這兩個位元編碼輸出與接收位元之間的漢明距離稱為該分支的分支度量
例如從第 \(i\) 步到第 \((i+1)\) 步接收的位元位 \(01\)
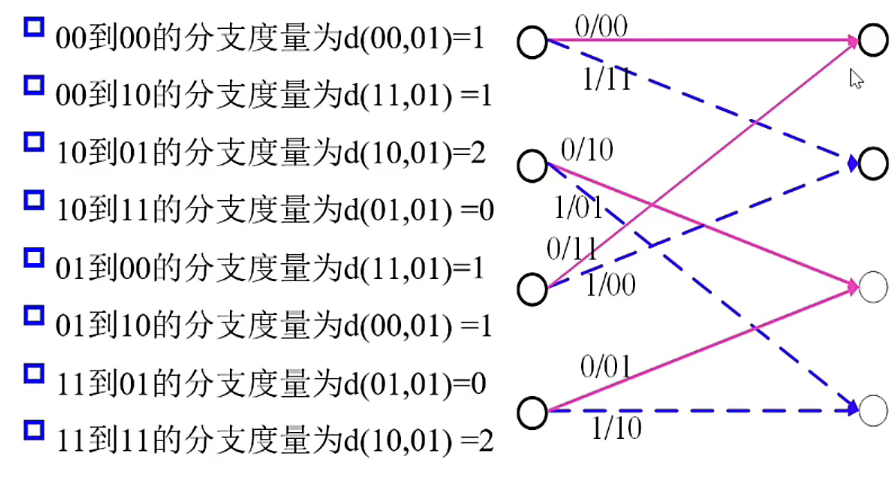
其中 \(A(i)\) 表示從開始時刻到當前時刻的累積度量為 \(i\)
Viterbi譯碼
- 最大似然序列譯碼要求序列有限,因此對於折積碼來說,要求能截尾。基於最大似然譯碼(ML譯碼)準則,尋找從起點到終點的極大似然路徑,即從起點到終點累計度量最小的路徑。
- 截尾:在資訊序列輸入完成以後,利用輸入一些特定的位元,使 \(M\) 個狀態的各殘留路徑可以到達某一已知狀態(一般是全零狀態)。這樣就變成只有一條殘留路徑,這就是最大似然序列。
- Viterrbi譯碼核心思想:進行累加-比較-選擇,基於計算,併產生新的倖存路徑。
對於接收序列為:01 11 01 11 00

通過上述路徑分析圖可得,經過最大似然譯碼分析後,譯碼序列為:11000
Viterbi譯碼python實現如下:
def decode_conv(y):
# shape = (4,len(y)/2)
# 初始化
score_list = np.array([[ float('inf') for i in range(int(len(y)/2)+1)] for i in range(4)])
for i in range(4):
score_list[i][0]=0
# 記錄回溯路徑
trace_back_list = []
# 每個階段的回溯塊
trace_block = []
# 4種狀態 0-3分別對應['00','01','10','11']
states = ['00','01','10','11']
# 根據不同 狀態 和 輸入 編碼資訊
def encode_with_state(x,state):
# 編碼後的輸出
y = []
u_1 = 0 if state<=1 else 1
u_2 = state%2
c_1 = (x + u_1 + u_2)%2
c_2 = (x + u_2)%2
y.append(c_1)
y.append(c_2)
return y
# 計算漢明距離
def hamming_dist(y1,y2):
dist = (y1[0]-y2[0])%2 + (y1[1]-y2[1])%2
return dist
# 根據當前狀態now_state和輸入資訊位元input,算出下一個狀態
def state_transfer(input,now_state):
u_1 = int(states[now_state][0])
next_state = f'{input}{u_1}'
return states.index(next_state)
# 根據不同初始時刻更新引數
# 也即指定狀態為 state 時的引數更新
# y_block 為 y 的一部分, shape=(2,)
# pre_state 表示當前要處理的狀態
# index 指定需要處理的時刻
def update_with_state(y_block,pre_state,index):
# 輸入的是 0
encode_0 = encode_with_state(0,pre_state)
next_state_0 = state_transfer(0,pre_state)
score_0 = hamming_dist(y_block,encode_0)
# 輸入為0,且需要更新
if score_list[pre_state][index]+score_0<score_list[next_state_0][index+1]:
score_list[next_state_0][index+1] = score_list[pre_state][index]+score_0
trace_block[next_state_0][0] = pre_state
trace_block[next_state_0][1] = 0
# 輸入的是 1
encode_1 = encode_with_state(1,pre_state)
next_state_1 = state_transfer(1,pre_state)
score_1 = hamming_dist(y_block,encode_1)
# 輸入為1,且需要更新
if score_list[pre_state][index]+score_1<score_list[next_state_1][index+1]:
score_list[next_state_1][index+1] = score_list[pre_state][index]+score_1
trace_block[next_state_1][0] = pre_state
trace_block[next_state_1][1] = 1
if pre_state==3 or index ==0:
trace_back_list.append(trace_block)
# 預設暫存器初始為 00。也即,開始時刻,預設狀態為00
# 開始第一個 y_block 的更新
y_block = y[0:2]
trace_block = [[-1,-1] for i in range(4)]
update_with_state(y_block=y_block,pre_state=0,index=0)
# 開始之後的 y_block 更新
for index in range(2,int(len(y)),2):
y_block = y[index:index+2]
for state in range(len(states)):
if state == 0:
trace_block = [[-1,-1] for i in range(4)]
update_with_state(y_block=y_block,pre_state=state,index=int(index/2))
# 完成前向過程,開始回溯
# state_trace_index 表示 開始回溯的狀態是啥
state_trace_index = np.argmin(score_list[:,-1])
# 記錄原編碼資訊
x = []
for trace in range(len(trace_back_list)-1,-1,-1):
x.append(trace_back_list[trace][state_trace_index][1])
state_trace_index = trace_back_list[trace][state_trace_index][0]
x = list(reversed(x))
print(y,"解碼為:",x)
return x
# 測試程式碼
if __name__ == '__main__':
# 對應 1 1 0 0 0
decode_conv([0,1,1,1,0,1,1,1,0,0])
參考