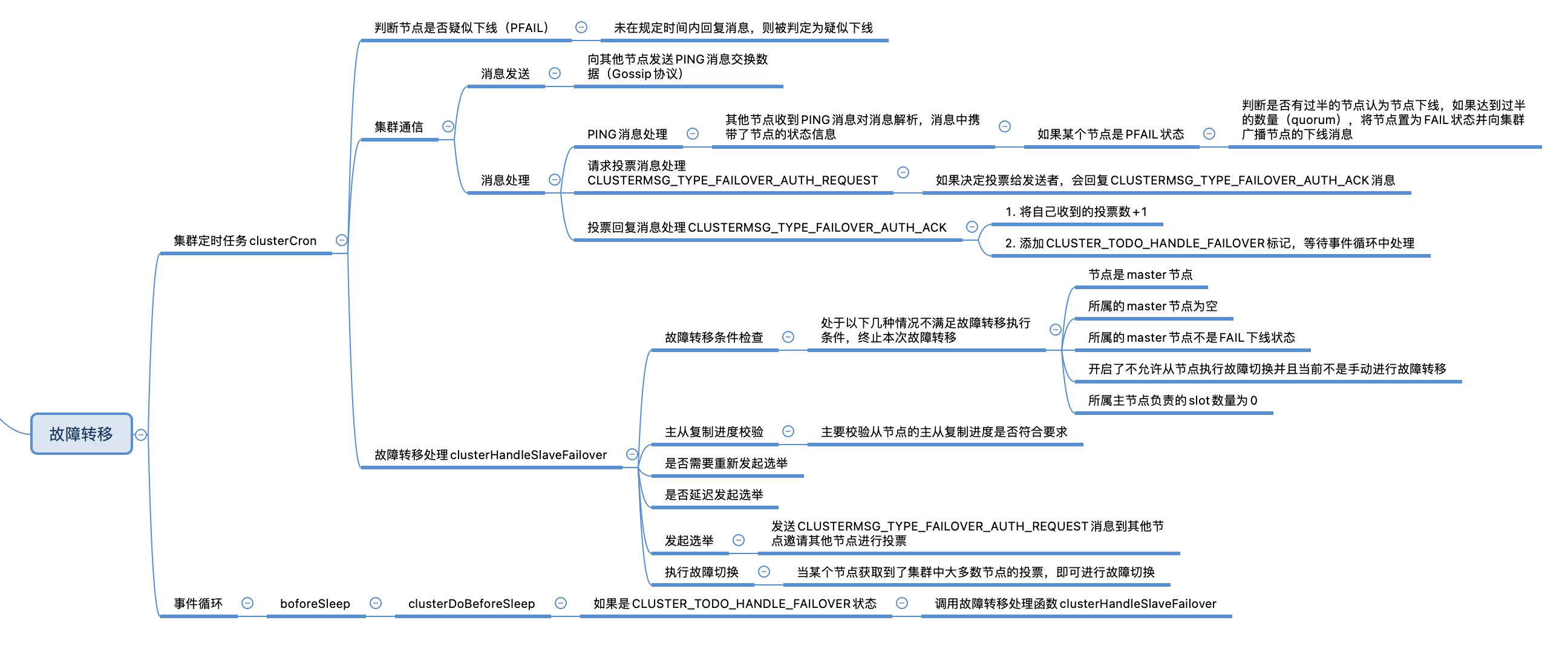
【Redis】Redis Cluster-叢集故障轉移
叢集故障轉移
節點下線
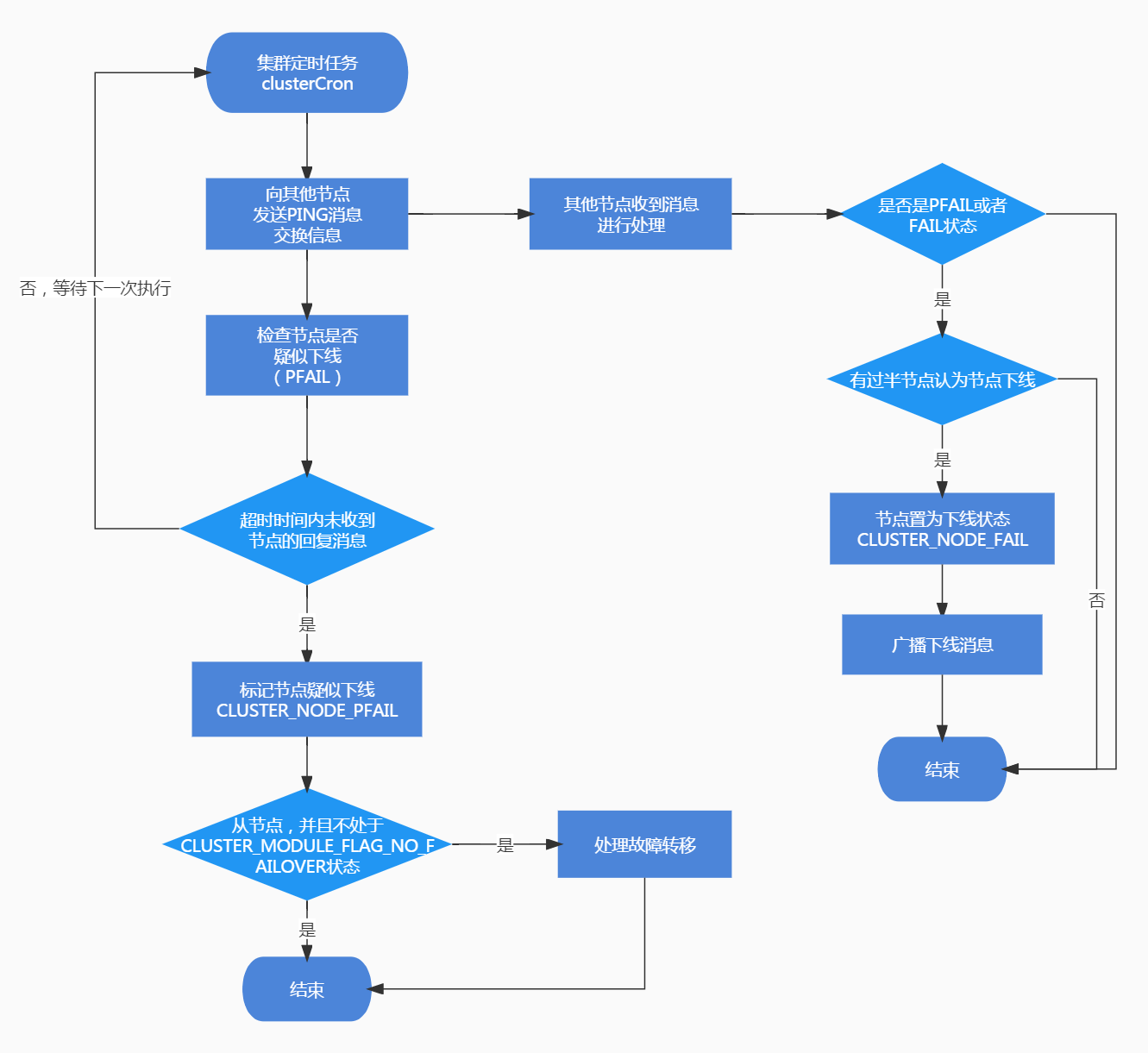
在叢集定時任務clusterCron中,會遍歷叢集中的節點,對每個節點進行檢查,判斷節點是否下線。與節點下線相關的狀態有兩個,分別為CLUSTER_NODE_PFAIL和CLUSTER_NODE_FAIL。
CLUSTER_NODE_PFAIL:當前節點認為某個節點下線時,會將節點狀態改為CLUSTER_NODE_PFAIL,由於可能存在誤判,所以需要根據叢集中的其他節點共同決定是否真的將節點標記為下線狀態,CLUSTER_NODE_PFAIL可以理解為疑似下線,類似哨兵叢集中的主觀下線。
CLUSTER_NODE_FAIL:叢集中有過半的節點標認為節點已下線,此時將節點置為CLUSTER_NODE_FAIL標記節點下線,CLUSTER_NODE_FAIL表示節點真正處於下線狀態,類似哨兵叢集的客觀下線。
#define CLUSTER_NODE_PFAIL 4 /* 疑似下線,需要根據其他節點的判斷決定是否下線,類似主觀下線 */
#define CLUSTER_NODE_FAIL 8 /* 節點處於下線狀態,類似客觀下線 */
疑似下線(PFAIL)
在叢集定時任務遍歷叢集中的節點進行檢查時,遍歷到的每個節點記為node,當前節點記為myself,檢查的內容主要有以下幾個方面:
一、判斷孤立主節點的個數
如果當前節點myself是從節點,正在遍歷的節點node是主節點,並且node節點不處於下線狀態,會判斷孤立節點的個數,滿足以下三個條件時,認定node是孤立節點,孤立節點個數增1:
node的從節點中處於非下線狀態的節點個數為0node負責的slot數量大於0,node節點處於CLUSTER_NODE_MIGRATE_TO狀態
二、檢查連線
這一步主要檢查和節點間的連線是否正常,有可能節點處於正常狀態,但是連線有問題,此時需要釋放連線,在下次執行定時任務時會進行重連,釋放連線需要同時滿足以下幾個條件:
- 與節點
node之間的連線不為空,說明之前進行過連線 - 當前時間距離連線建立的時間超過了超時時間
- 距離向
node傳送PING訊息的時間已經超過了超時時間的一半 - 距離收到
node節點傳送訊息的時間超過了超時時間的一半
三、疑似下線判斷
ping_delay記錄了當前時間距離向node節點傳送PING訊息的時間,data_delayd記錄了node節點向當前節點最近一次傳送訊息的時間,從ping_delay和data_delay中取較大的那個作為延遲時間。
如果延遲時間大於超時時間,判斷node是否已經處於CLUSTER_NODE_PFAIL或者CLUSTER_NODE_FAIL狀態,如果都不處於,將節點狀態置為CLUSTER_NODE_PFAIL,認為節點疑似下線。
從程式碼中可以看出,走到這個判斷的時候說明
node->ping_sent不為0,表示當前節點向node傳送了PING訊息但是還未收到回覆(收到回覆時會將置為0),ping_delay大於超時時間說明在規定的時間內未收到node傳送的PONG訊息,data_delayd大於超時時間說明在規定的時間內未收到node傳送的任何訊息(當前節點只要收到其他節點傳送的訊息就會在處理訊息的函數中記錄收到訊息的時間),所以不論哪個值大,只要超過超時時間,都說明在一定的時間內,當前節點未收到node節點傳送的訊息,所以認為node疑似下線。
上述檢查完成之後,會判斷當前節點是否是從節點,如果不處於CLUSTER_MODULE_FLAG_NO_FAILOVER狀態,呼叫clusterHandleSlaveFailover處理故障轉移,不過需要注意此時只是將節點置為疑似下線,並不滿足故障轉移條件,需要等待節點被置為FAIL下線狀態之後,再次執行叢集定時任務進入到clusterHandleSlaveFailover函數中才可以開始處理故障轉移。
void clusterCron(void) {
// ...
orphaned_masters = 0;
max_slaves = 0;
this_slaves = 0;
di = dictGetSafeIterator(server.cluster->nodes);
// 遍歷叢集中的節點
while((de = dictNext(di)) != NULL) {
// 獲取節點
clusterNode *node = dictGetVal(de);
now = mstime(); /* 當前時間 */
if (node->flags &
(CLUSTER_NODE_MYSELF|CLUSTER_NODE_NOADDR|CLUSTER_NODE_HANDSHAKE))
continue;
/* 如果當前節點myself是從節點,正在遍歷的節點node是主節點,並且node節點不處於下線狀態 */
if (nodeIsSlave(myself) && nodeIsMaster(node) && !nodeFailed(node)) {
// 獲取不處於下線狀態的從節點數量
int okslaves = clusterCountNonFailingSlaves(node);
/* 如果處於正常狀態的從節點數量為0、node負責的slot數量大於0, 並且節點處於CLUSTER_NODE_MIGRATE_TO狀態 */
if (okslaves == 0 && node->numslots > 0 &&
node->flags & CLUSTER_NODE_MIGRATE_TO)
{
orphaned_masters++; // 孤立主節點數量加1
}
// 更新最大從節點數量
if (okslaves > max_slaves) max_slaves = okslaves;
// 如果myself是從節點 並且myself是node的從節點
if (nodeIsSlave(myself) && myself->slaveof == node)
this_slaves = okslaves; // 記錄處於正常狀態的從節點數量
}
/* 這一步主要檢查連線是否出現問題 */
mstime_t ping_delay = now - node->ping_sent; // 當前時間減去向node傳送PING訊息時間
mstime_t data_delay = now - node->data_received; // 當前時間減去收到node向當前節點傳送訊息的時間
if (node->link && /* 如果連線不為空 */
now - node->link->ctime >
server.cluster_node_timeout && /* 距離連線建立的時間超過了設定的超時時間 */
node->ping_sent && /* 已經傳送了PING訊息暫未收到回覆 */
/* 距離傳送PING訊息的時間已經超過了超時時間的一半 */
ping_delay > server.cluster_node_timeout/2 &&
/* 距離收到node節點傳送訊息的時間超過了超時時間的一半
*/
data_delay > server.cluster_node_timeout/2)
{
/* 斷開連線,在下次執行定時任務時會重新連線 */
freeClusterLink(node->link);
}
/* 如果連線不為空、ping_sent為0(收到PONG訊息後會將ping_sent置為0),並且當前時間減去收到node的PONG訊息的時間大於超時時間的一半 */
if (node->link &&
node->ping_sent == 0 &&
(now - node->pong_received) > server.cluster_node_timeout/2)
{
// 立即傳送PING訊息,保持連線
clusterSendPing(node->link, CLUSTERMSG_TYPE_PING);
continue;
}
if (server.cluster->mf_end && // 手動執行故障轉移時間限制不為0,表示正在執行手動故障轉移
nodeIsMaster(myself) && // 如果myself是主節點
server.cluster->mf_slave == node && // 如果node是myself從節點並且正在執行手動故障轉移
node->link)
{
// 傳送PING訊息,保持連線
clusterSendPing(node->link, CLUSTERMSG_TYPE_PING);
continue;
}
/* 如果沒有活躍的PING訊息,說明當前節點暫未向node發起新的PING訊息,跳過,處理下一個節點 */
if (node->ping_sent == 0) continue;
/* 校驗節點是否主觀下線 */
// ping_delay記錄了當前時間距離向node節點傳送PING訊息的時間,傳送PING訊息node->ping_sent會置為1,走到這裡說明向node節點傳送過PING訊息,但是暫未收到回覆
// data_delay記錄了node節點向當前節點最近一次傳送訊息的時間
// 從ping_delay和data_delay中取較大的那個作為延遲時間
mstime_t node_delay = (ping_delay < data_delay) ? ping_delay :
data_delay;
// 如果節點的延遲時間大於超時時間
if (node_delay > server.cluster_node_timeout) {
/* 如果不處於CLUSTER_NODE_PFAIL或者CLUSTER_NODE_FAIL狀態*/
if (!(node->flags & (CLUSTER_NODE_PFAIL|CLUSTER_NODE_FAIL))) {
serverLog(LL_DEBUG,"*** NODE %.40s possibly failing",
node->name);
// 將節點標記為故障狀態CLUSTER_NODE_PFAIL,標記疑似下線
node->flags |= CLUSTER_NODE_PFAIL;
update_state = 1;
}
}
}
// ...
// 如果是從節點
if (nodeIsSlave(myself)) {
clusterHandleManualFailover();
// 如果不處於CLUSTER_MODULE_FLAG_NO_FAILOVER狀態
if (!(server.cluster_module_flags & CLUSTER_MODULE_FLAG_NO_FAILOVER))
clusterHandleSlaveFailover(); // 處理故障轉移
if (orphaned_masters && max_slaves >= 2 && this_slaves == max_slaves &&
server.cluster_allow_replica_migration)
clusterHandleSlaveMigration(max_slaves);
}
// ...
}
下線(FAIL)
當前節點認為某個node下線時,會將node狀態置為CLUSTER_NODE_PFAIL疑似下線狀態,在定時向叢集中的節點交換資訊也就是傳送PING訊息時,訊息體中記錄了node的下線狀態,其他節點在處理收到的PING訊息時,會將認為node節點下線的那個節點加入到node的下線連結串列fail_reports中,並呼叫markNodeAsFailingIfNeeded函數判斷是否有必要將節點置為下線FAIL狀態:
void clusterProcessGossipSection(clusterMsg *hdr, clusterLink *link) {
uint16_t count = ntohs(hdr->count);
// 獲取clusterMsgDataGossip資料
clusterMsgDataGossip *g = (clusterMsgDataGossip*) hdr->data.ping.gossip;
// 傳送訊息的節點
clusterNode *sender = link->node ? link->node : clusterLookupNode(hdr->sender);
while(count--) {
/* 根據nodename查詢節點,node指向當前收到訊息節點中維護的節點*/
node = clusterLookupNode(g->nodename);
// 如果節點已知
if (node) {
/* 如果傳送者是主節點 */
if (sender && nodeIsMaster(sender) && node != myself) {
// 如果gossip節點是FAIL或者PFAIL狀態
if (flags & (CLUSTER_NODE_FAIL|CLUSTER_NODE_PFAIL)) {
// 將sender加入到node節點的下線連結串列fail_reports中
if (clusterNodeAddFailureReport(node,sender)) {
serverLog(LL_VERBOSE,
"Node %.40s reported node %.40s as not reachable.",
sender->name, node->name);
}
// 判斷是否需要將節點置為下線
markNodeAsFailingIfNeeded(node);
} else {
// 校驗sender是否在下線節點連結串列fail_reports中,如果在需要移除恢復線上狀態
if (clusterNodeDelFailureReport(node,sender)) {
serverLog(LL_VERBOSE,
"Node %.40s reported node %.40s is back online.",
sender->name, node->name);
}
}
}
// ...
} else { // 如果節點未知
// ...
}
/* 遍歷下一個節點 */
g++;
}
}
markNodeAsFailingIfNeeded
markNodeAsFailingIfNeeded用於判斷是否有必要將某個節點標記為FAIL狀態:
- 計算quorum,為叢集節點個數一半 + 1,記為
needed_quorum - 如果節點已經被置為FAIL狀態,直接返回即可
- 呼叫
clusterNodeFailureReportsCount函數,獲取節點下線連結串列node->fail_reports中元素的個數,node->fail_reports連結串列中記錄了認為node下線的節點個數,節點個數記為failures - 如果當前節點是主節點,
failures增1,表示當前節點也認為node需要置為下線狀態 - 判斷是否有過半的節點認同節點下線,也就是
failures大於等於needed_quorum,如果沒有過半的節點認同node需要下線,直接返回即可 - 如果有過半的節點認同
node需要下線,此時取消節點的疑似下線標記PFAIL狀態,將節點置為FAIL狀態 - 在叢集中廣播節點的下線訊息,以便讓其他節點知道該節點已經下線
void markNodeAsFailingIfNeeded(clusterNode *node) {
int failures;
// 計算quorum,為叢集節點個數一半 + 1
int needed_quorum = (server.cluster->size / 2) + 1;
if (!nodeTimedOut(node)) return; /* We can reach it. */
// 如果節點已經處於下線狀態
if (nodeFailed(node)) return; /* Already FAILing. */
// 從失敗報告中獲取認為節點已經下線的節點數量
failures = clusterNodeFailureReportsCount(node);
/* 如果當前節點是主節點 */
if (nodeIsMaster(myself)) failures++; // 認定下線的節點個數+1
// 如果沒有過半的節點認同節點下線,返回即可
if (failures < needed_quorum) return;
serverLog(LL_NOTICE,
"Marking node %.40s as failing (quorum reached).", node->name);
/* 標記節點下線 */
// 取消CLUSTER_NODE_PFAIL狀態
node->flags &= ~CLUSTER_NODE_PFAICLUSTER_NODE_PFAIL;
// 設定為下線狀態
node->flags |= CLUSTER_NODE_FAIL;
node->fail_time = mstime();
/* 廣播下線訊息到叢集中的節點,以便讓其他節點知道該節點已經下線 */
clusterSendFail(node->name);
clusterDoBeforeSleep(CLUSTER_TODO_UPDATE_STATE|CLUSTER_TODO_SAVE_CONFIG);
}
/* 返回下線報告連結串列中*/
int clusterNodeFailureReportsCount(clusterNode *node) {
clusterNodeCleanupFailureReports(node);
// 返回認為node下線的節點個數
return listLength(node->fail_reports);
}
故障轉移處理
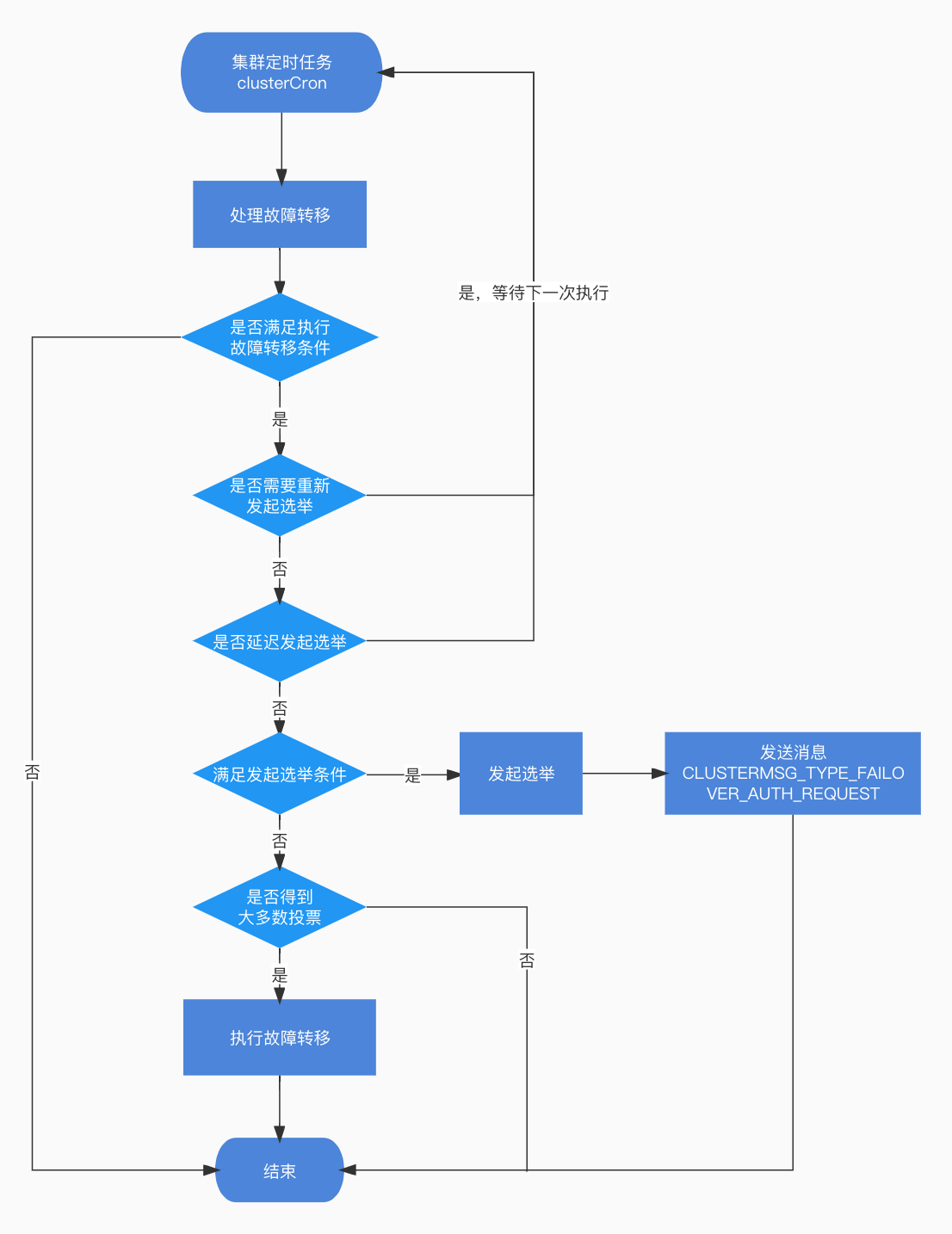
clusterHandleSlaveFailover
由上面的內容可知,節點客觀下線時會被置為CLUSTER_NODE_FAIL狀態,下次執行叢集定時任務時,在故障轉移處理常式clusterHandleSlaveFailover中,就可以根據狀態來檢查是否需要執行故障轉移。
不過在看clusterHandleSlaveFailover函數之前,先看一下clusterState中和選舉以及故障切換相關的變數定義:
typedef struct clusterState {
// ...
mstime_t failover_auth_time; /* 發起選舉的時間 */
int failover_auth_count; /* 目前為止收到投票的數量 */
int failover_auth_sent; /* 是否發起了投票,如果已經發起,值大於0 */
int failover_auth_rank; /* 從節點排名 */
uint64_t failover_auth_epoch; /* 當前選舉的紀元 */
int cant_failover_reason; /* 從節點不能執行故障轉移的原因 */
mstime_t mf_end; /* 手動執行故障轉移時間限制,如果未設定值為0 */
clusterNode *mf_slave; /* 執行手動故障切換的從節點 */
//...
} clusterState;
clusterHandleSlaveFailover函數中的一些變數
data_age:記錄從節點最近一次與主節點進行資料同步的時間。如果與主節點處於連線狀態,用當前時間減去最近一次與master節點互動的時間,否則使用當前時間減去與master主從複製中斷的時間。
auth_age:當前時間減去發起選舉的時間,也就是距離發起選舉過去了多久,用於判斷選舉超時、是否重新發起選舉使用。
needed_quorum:quorum的數量,為叢集中節點的數量的一半再加1。
auth_timeout:等待投票超時時間。
auth_retry_time:等待重新發起選舉進行投票的時間,也就是重試時間。
發起選舉
一、故障轉移條件檢查
首先進行了一些條件檢查,用於判斷是否有必要執行故障轉移,如果處於以下幾個條件之一,將會跳出函數,結束故障轉移處理:
-
當前節點
myself是master節點,因為如果需要進行故障轉移一般是master節點被標記為下線,需要從它所屬的從節點中選舉節點作為新的master節點,這個需要從節點發起選舉,所以如果當前節點是主節點,不滿足進行故障轉移的條件。 -
當前節點
myself所屬的主節點為空 -
當前節點
myself所屬主節點不處於客觀下線狀態並且不是手動進行故障轉移,可以看到這裡使用的是CLUSTER_NODE_FAIL狀態來判斷的#define nodeFailed(n) ((n)->flags & CLUSTER_NODE_FAIL) -
如果開啟了不允許從節點執行故障切換並且當前不是手動進行故障轉移
-
當前節點
myself所屬主節點負責的slot數量為0
二、主從複製進度校驗
cluster_slave_validity_factor設定了故障切換最大主從複製延遲時間因子,如果不為0需要校驗主從複製延遲時間是否符合要求。
如果主從複製延遲時間data_age大於 mater向從節點傳送PING訊息的週期 + 超時時間 * 故障切換主從複製延遲時間因子並且不是手動執行故障切換,表示主從複製延遲過大,不能進行故障切換終止執行。
三、是否需要重新發起選舉
如果距離上次發起選舉的時間大於超時重試時間,表示可以重新發起投票。
-
設定本輪選舉發起時間,並沒有直接使用當前時間,而是使用了當前時間 + 500毫秒 + 隨機值(0到500毫秒之間)進行了一個延遲,以便讓上一次失敗的訊息儘快傳播。
-
重置獲取的投票數量
failover_auth_count和是否已經發起選舉failover_auth_sent為0,等待下一次執行clusterHandleSlaveFailover函數時重新發起投票。 -
獲取當前節點在所屬主節點的所有從節點中的等級排名,再次更新發起選舉時間,加上當前節點的rank * 1000,以便讓等級越低(rank值越高)的節點,越晚發起選舉,降低選舉的優先順序。
注意這裡並沒有恢復
CLUSTER_TODO_HANDLE_FAILOVER狀態,因為發起投票的入口是在叢集定時任務clusterCron函數中,所以不需要恢復。 -
如果是手動進行故障轉移,不需要設定延遲時間,直接使用當前時間,rank設定為0,然後將狀態置為
CLUSTER_TODO_HANDLE_FAILOVER,在下一次執行beforeSleep函數時,重新進行故障轉移。 -
向叢集中廣播訊息並終止執行本次故障切換。
四、延遲發起選舉
- 如果還未發起選舉投票,節點等級有可能在變化,所以此時需要更新等級以及發起投票的延遲時間。
- 如果當前時間小於設定的選舉發起時間,需要延遲發起選舉,直接返回,等待下一次執行。
- 如果距離發起選舉的時間大於超時時間,表示本次選舉已超時,直接返回。
五、發起投票
如果滿足執行故障的條件,接下來需從節點想叢集中的其他節點廣播訊息,發起投票,不過只有主節點才有投票權。failover_auth_sent為0表示還未發起投票,此時開始發起投票:
- 更新節點當前的投票紀元(輪次)
currentEpoch,對其進行增1操作 - 設定本次選舉的投票紀元(輪次)
failover_auth_epoch,與currentEpoch一致 - 向叢集廣播,傳送CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST訊息到其他節點進行投票
failover_auth_sent置為1 ,表示已經發起了投票- 發起投票後,直接返回,等待其他節點的投票。
六、執行故障切換
當某個節點獲取到了叢集中大多數節點的投票,即可進行故障切換,這裡先不關注,在後面的章節會講。
void clusterHandleSlaveFailover(void) {
// 主從複製延遲時間
mstime_t data_age;
// 當前時間減去發起選舉的時間
mstime_t auth_age = mstime() - server.cluster->failover_auth_time;
// 計算quorum的數量,為叢集中節點的數量的一半再加1
int needed_quorum = (server.cluster->size / 2) + 1;
// 是否手動執行故障轉移
int manual_failover = server.cluster->mf_end != 0 &&
server.cluster->mf_can_start;
// 等待投票超時時間,等待重試時間
mstime_t auth_timeout, auth_retry_time;
// 取消CLUSTER_TODO_HANDLE_FAILOVER狀態
server.cluster->todo_before_sleep &= ~CLUSTER_TODO_HANDLE_FAILOVER;
// 等待投票超時時間為叢集中設定的超時時間的2倍
auth_timeout = server.cluster_node_timeout*2;
// 如果等待投票超時的時間小於2000毫秒,設定為2000毫秒,也就是超時時間最少為2000毫秒
if (auth_timeout < 2000) auth_timeout = 2000;
// 等待重試時間為超時時間的2倍
auth_retry_time = auth_timeout*2;
/* 校驗故障轉移條件,處於以下條件之一不滿足故障切換條件,跳出函數 */
if (nodeIsMaster(myself) || // myself是主節點
myself->slaveof == NULL || // myself是從節點但是所屬主節點為空
(!nodeFailed(myself->slaveof) && !manual_failover) || // 所屬主節點不處於下線狀態並且不是手動進行故障轉移
(server.cluster_slave_no_failover && !manual_failover) || // 如果不允許從節點執行故障切換並且不是手動進行故障轉移
myself->slaveof->numslots == 0) // 所屬主節點負責的slot數量為0
{
/* 不進行故障切換 */
server.cluster->cant_failover_reason = CLUSTER_CANT_FAILOVER_NONE;
return;
}
/* 如果主從複製狀態為連線狀態 */
if (server.repl_state == REPL_STATE_CONNECTED) {
// 設定距離最近一次複製資料的時間,由於和master節點還處於連線狀態,使用當前時間減去最近一次與master節點互動的時間
data_age = (mstime_t)(server.unixtime - server.master->lastinteraction)
* 1000;
} else { // 其他狀態時
// 使用當前時間減去與master主從複製中斷的時間
data_age = (mstime_t)(server.unixtime - server.repl_down_since) * 1000;
}
/* 如果data_age大於超時時間,減去超時時間 */
if (data_age > server.cluster_node_timeout)
data_age -= server.cluster_node_timeout;
/* cluster_slave_validity_factor設定了故障切換最大主從複製延遲時間因子,如果不為0需要校驗主從複製延遲時間是否符合要求 */
/* 如果主從複製延遲時間 大於(master向從節點傳送PING訊息的週期 + 超時時間 * 故障切換主從複製延遲時間因子) ,表示主從複製延遲過大,不能進行故障切換 */
if (server.cluster_slave_validity_factor &&
data_age >
(((mstime_t)server.repl_ping_slave_period * 1000) +
(server.cluster_node_timeout * server.cluster_slave_validity_factor)))
{
// 如果不是手動執行故障切換
if (!manual_failover) {
// 設定不能執行故障切換的原因,主從複製進度不符合要求
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_DATA_AGE);
return;
}
}
/* 如果距離上次發起選舉的時間大於超時重試時間,表示可以重新發起投票 */
if (auth_age > auth_retry_time) {
// 設定本輪選舉發起時間,使用了當前時間 + 500毫秒 + 隨機值(0到500毫秒之間),以便讓上一次失敗的訊息儘快傳播
server.cluster->failover_auth_time = mstime() +
500 +
random() % 500;
// 初始化獲取的投票數量
server.cluster->failover_auth_count = 0;
// 初始化failover_auth_sent為0
server.cluster->failover_auth_sent = 0;
// 獲取當前節點的等級
server.cluster->failover_auth_rank = clusterGetSlaveRank();
// 再次更新發起選舉時間,加上當前節點的rank * 1000,以便讓等級越低的節點,越晚發起選舉,降低選舉的優先順序
server.cluster->failover_auth_time +=
server.cluster->failover_auth_rank * 1000;
/* 如果是手動進行故障轉移,不需要設定延遲 */
if (server.cluster->mf_end) {
// 設定發起選舉時間為當前時間
server.cluster->failover_auth_time = mstime();
// rank設定為0,等級最高
server.cluster->failover_auth_rank = 0;
// 設定CLUSTER_TODO_HANDLE_FAILOVER狀態
clusterDoBeforeSleep(CLUSTER_TODO_HANDLE_FAILOVER);
}
serverLog(LL_WARNING,
"Start of election delayed for %lld milliseconds "
"(rank #%d, offset %lld).",
server.cluster->failover_auth_time - mstime(),
server.cluster->failover_auth_rank,
replicationGetSlaveOffset());
/* 廣播訊息 */
clusterBroadcastPong(CLUSTER_BROADCAST_LOCAL_SLAVES);
return;
}
if (server.cluster->failover_auth_sent == 0 && // 如果還未發起選舉
server.cluster->mf_end == 0) // 如果不是手動執行故障轉移
{
// 獲取節點等級,節點等級有可能在變化,需要更新等級
int newrank = clusterGetSlaveRank();
// 如果排名大於之前設定的等級
if (newrank > server.cluster->failover_auth_rank) {
long long added_delay =
(newrank - server.cluster->failover_auth_rank) * 1000;
// 更新發起選舉時間
server.cluster->failover_auth_time += added_delay;
// 更新節點等級
server.cluster->failover_auth_rank = newrank;
serverLog(LL_WARNING,
"Replica rank updated to #%d, added %lld milliseconds of delay.",
newrank, added_delay);
}
}
/* 如果當前時間小於設定的選舉發起時間,需要延遲發起選舉 */
if (mstime() < server.cluster->failover_auth_time) {
// 記錄延遲發起選舉紀錄檔
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_WAITING_DELAY);
return;
}
/* 如果距離發起選舉的時間大於超時時間,表示已超時 */
if (auth_age > auth_timeout) {
// 記錄選舉已過期紀錄檔
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_EXPIRED);
return;
}
/* 如果failover_auth_sent為0表示還未發起投票 */
if (server.cluster->failover_auth_sent == 0) {
// 紀元加1
server.cluster->currentEpoch++;
// 設定當前選舉紀元failover_auth_epoch
server.cluster->failover_auth_epoch = server.cluster->currentEpoch;
serverLog(LL_WARNING,"Starting a failover election for epoch %llu.",
(unsigned long long) server.cluster->currentEpoch);
// 廣播傳送CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST訊息,發起投票
clusterRequestFailoverAuth();
// failover_auth_sent置為1 ,表示已經發起了投票
server.cluster->failover_auth_sent = 1;
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE|
CLUSTER_TODO_FSYNC_CONFIG);
return; /* Wait for replies. */
}
/* 校驗是否獲取了大多數的投票,執行故障切換 */
if (server.cluster->failover_auth_count >= needed_quorum) {
// ...
} else {
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_WAITING_VOTES);
}
}
/* 傳送FAILOVER_AUTH_REQUEST訊息到每個節點 */
void clusterRequestFailoverAuth(void) {
clusterMsg buf[1];
clusterMsg *hdr = (clusterMsg*) buf;
uint32_t totlen;
// 設定訊息頭,傳送CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST訊息
clusterBuildMessageHdr(hdr,CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST);
/* 如果是手動轉移,設定CLUSTERMSG_FLAG0_FORCEACK標記 */
if (server.cluster->mf_end) hdr->mflags[0] |= CLUSTERMSG_FLAG0_FORCEACK;
totlen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
hdr->totlen = htonl(totlen);
// 傳送廣播
clusterBroadcastMessage(buf,totlen);
獲取節點等級
clusterGetSlaveRank用於計算當前節點的等級,遍歷所屬主節點的所有從節點,根據主從複製進度repl_offset計算,repl_offset值越大表示覆制主節點的資料越多,所以等級越高,對應的rank值就越低。
從節點在發起選舉使用了rank的值作為延遲時間,值越低延遲時間越小,意味著選舉優先順序也就越高。
int clusterGetSlaveRank(void) {
long long myoffset;
// rank初始化為0
int j, rank = 0;
clusterNode *master;
serverAssert(nodeIsSlave(myself));
// 獲取當前節點所屬的主節點
master = myself->slaveof;
if (master == NULL) return 0; /* 返回0 */
// 獲取主從複製進度
myoffset = replicationGetSlaveOffset();
// 變數master的所有從節點
for (j = 0; j < master->numslaves; j++)
// 如果不是當前節點、節點可以用來執行故障切換並且節點的複製進度大於當前節點的進度
if (master->slaves[j] != myself &&
!nodeCantFailover(master->slaves[j]) &&
master->slaves[j]->repl_offset > myoffset) rank++; // 將當前節點的排名後移,等級越低
return rank;
}
主節點進行投票
當從節點認為主節點故障需要發起投票,重新選舉主節點時,在叢集中廣播了CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST訊息,對應的處理在clusterProcessPacket函數中,裡面會呼叫clusterSendFailoverAuthIfNeeded函數進行投票:
int clusterProcessPacket(clusterLink *link) {
// ...
/* PING, PONG, MEET訊息處理 */
if (type == CLUSTERMSG_TYPE_PING || type == CLUSTERMSG_TYPE_PONG ||
type == CLUSTERMSG_TYPE_MEET)
{
// ...
}
// ...
else if (type == CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST) {// 處理CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST訊息
if (!sender) return 1;
// 進行投票,sender為傳送訊息的節點,hdr為請求體
clusterSendFailoverAuthIfNeeded(sender,hdr);
}
// ...
}
clusterSendFailoverAuthIfNeeded
clusterSendFailoverAuthIfNeeded函數用於進行投票,處理邏輯如下:
- 由於只有主節點才可以投票,如果當前節點不是主節點或者當前節點中負責slot的個數為0,當前節點沒有許可權投票,直接返回。
- 需要保證發起請求的投票輪次要等於或者大於當前節點中記錄的輪次,所以如果請求的紀元(輪次)小於當前節點中記錄的紀元(輪次) ,直接返回。
- 如果當前節點中記錄的上次投票的紀元(輪次)等於當前投票紀元(輪次),表示當前節點已經投過票,直接返回。
- 如果發起請求的節點是主節點或者發起請求的節點所屬的主節點為空,或者主節點不處於下線狀態並且不是手動執行故障轉移,直接返回。
- 如果當前時間減去節點投票時間
node->slaveof->voted_time小於超時時間的2倍,直接返回。node->slaveof->voted_time記錄了當前節點的投票時間,在未超過2倍超時時間之前不進行投票。 - 處理slot,需要保證當前節點中記錄的slot的紀元小於等於請求紀元,如果不滿足此條件,終止投票,直接返回。
以上條件校驗通過,表示當前節點可以投票給傳送請求的節點,此時更新lastVoteEpoch,記錄最近一次投票的紀元(輪次),更新投票時間node->slaveof->voted_time,然後向發起請求的節點回復CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK訊息。
void clusterSendFailoverAuthIfNeeded(clusterNode *node, clusterMsg *request) {
// 發起請求的節點所屬主節點
clusterNode *master = node->slaveof;
// 從請求中獲取投票紀元(輪次)
uint64_t requestCurrentEpoch = ntohu64(request->currentEpoch);
//
uint64_t requestConfigEpoch = ntohu64(request->configEpoch);
// 從請求中獲取節點負責的slot
unsigned char *claimed_slots = request->myslots;
// 是否是手動故障執行故障轉移
int force_ack = request->mflags[0] & CLUSTERMSG_FLAG0_FORCEACK;
int j;
/* 如果當前節點不是主節點或者當前節點中負責slot的個數為0,當前節點沒有許可權投票,直接返回*/
if (nodeIsSlave(myself) || myself->numslots == 0) return;
/* 如果請求的紀元(輪次)小於當前節點中記錄的紀元(輪次) */
if (requestCurrentEpoch < server.cluster->currentEpoch) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: reqEpoch (%llu) < curEpoch(%llu)",
node->name,
(unsigned long long) requestCurrentEpoch,
(unsigned long long) server.cluster->currentEpoch);
return;
}
/* 如果當前節點中記錄的上次投票的紀元等於當前紀元,表示當前節點已經投過票,直接返回 */
if (server.cluster->lastVoteEpoch == server.cluster->currentEpoch) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: already voted for epoch %llu",
node->name,
(unsigned long long) server.cluster->currentEpoch);
return;
}
/* 如果發起請求的節點是主節點或者發起請求的節點所屬的主節點為空,或者主節點不處於下線狀態並且不是手動執行故障轉移,直接返回 */
if (nodeIsMaster(node) || master == NULL ||
(!nodeFailed(master) && !force_ack))
{
if (nodeIsMaster(node)) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: it is a master node",
node->name);
} else if (master == NULL) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: I don't know its master",
node->name);
} else if (!nodeFailed(master)) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: its master is up",
node->name);
}
return;
}
/* 如果當前時間減去投票時間小於超時時間的2倍,直接返回 */
/* node->slaveof->voted_time記錄了當前節點的投票時間,在未過2倍超時時間之前,不進行投票 */
if (mstime() - node->slaveof->voted_time < server.cluster_node_timeout * 2)
{
serverLog(LL_WARNING,
"Failover auth denied to %.40s: "
"can't vote about this master before %lld milliseconds",
node->name,
(long long) ((server.cluster_node_timeout*2)-
(mstime() - node->slaveof->voted_time)));
return;
}
/* 處理slot,需要保證當前節點中記錄的slot的紀元小於等於請求紀元 */
for (j = 0; j < CLUSTER_SLOTS; j++) {
// 如果當前的slot不在發起請求節點負責的slot中,繼續下一個
if (bitmapTestBit(claimed_slots, j) == 0) continue;
// 如果當前節點不負責此slot或者slot中記錄的紀元小於等於請求紀元,繼續下一個
if (server.cluster->slots[j] == NULL ||
server.cluster->slots[j]->configEpoch <= requestConfigEpoch)
{
continue;
}
serverLog(LL_WARNING,
"Failover auth denied to %.40s: "
"slot %d epoch (%llu) > reqEpoch (%llu)",
node->name, j,
(unsigned long long) server.cluster->slots[j]->configEpoch,
(unsigned long long) requestConfigEpoch);
return;
}
/* 走到這裡表示可以投票給從節點 */
/* 將當前節點的lastVoteEpoch設定為currentEpoch */
server.cluster->lastVoteEpoch = server.cluster->currentEpoch;
/* 更新投票時間 */
node->slaveof->voted_time = mstime();
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|CLUSTER_TODO_FSYNC_CONFIG);
/* 傳送CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK訊息 */
clusterSendFailoverAuth(node);
serverLog(LL_WARNING, "Failover auth granted to %.40s for epoch %llu",
node->name, (unsigned long long) server.cluster->currentEpoch);
}
/* 傳送CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK訊息到指定節點. */
void clusterSendFailoverAuth(clusterNode *node) {
clusterMsg buf[1];
clusterMsg *hdr = (clusterMsg*) buf;
uint32_t totlen;
if (!node->link) return;
// 設定請求體,傳送CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK訊息
clusterBuildMessageHdr(hdr,CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK);
totlen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
hdr->totlen = htonl(totlen);
// 傳送訊息
clusterSendMessage(node->link,(unsigned char*)buf,totlen);
}
投票回覆訊息處理
主節點對發起投票請求節點的回覆訊息CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK同樣在訊息處理常式clusterProcessPacket中,會對傳送回復訊息的節點進行驗證:
- 傳送者是主節點
- 傳送者負責的slot數量大於0
- 傳送者記錄的投票紀元(輪次)大於或等於當前節點發起故障轉移投票的輪次
同時滿足以上三個條件時,表示傳送者對當前節點進行了投票,更新當前節點記錄的收到投票的個數,failover_auth_count加1,此時有可能獲取了大多數節點的投票,先呼叫clusterDoBeforeSleep設定一個CLUSTER_TODO_HANDLE_FAILOVER標記,在週期執行的時間事件中會呼叫對狀態進行判斷決定是否執行故障轉移。
int clusterProcessPacket(clusterLink *link) {
// ...
/* PING, PONG, MEET: process config information. */
if (type == CLUSTERMSG_TYPE_PING || type == CLUSTERMSG_TYPE_PONG ||
type == CLUSTERMSG_TYPE_MEET)
{
// 省略...
}
// 省略其他else if
// ...
else if (type == CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST) { // 處理CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST訊息
if (!sender) return 1;
clusterSendFailoverAuthIfNeeded(sender,hdr);
} else if (type == CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK) { // 處理CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK訊息
if (!sender) return 1;
/* 如果傳送者是主節點並且負責的slot數量大於0,並且CurrentEpoch大於或等於當前節點的failover_auth_epoch*/
if (nodeIsMaster(sender) && sender->numslots > 0 &&
senderCurrentEpoch >= server.cluster->failover_auth_epoch)
{
/* 當前節點的failover_auth_count加1 */
server.cluster->failover_auth_count++;
/* 有可能獲取了大多數節點的投票,先設定一個CLUSTER_TODO_HANDLE_FAILOVER標記 */
clusterDoBeforeSleep(CLUSTER_TODO_HANDLE_FAILOVER);
}
}
// 省略其他else if
// ...
}
void clusterDoBeforeSleep(int flags) {
// 設定狀態
server.cluster->todo_before_sleep |= flags;
}

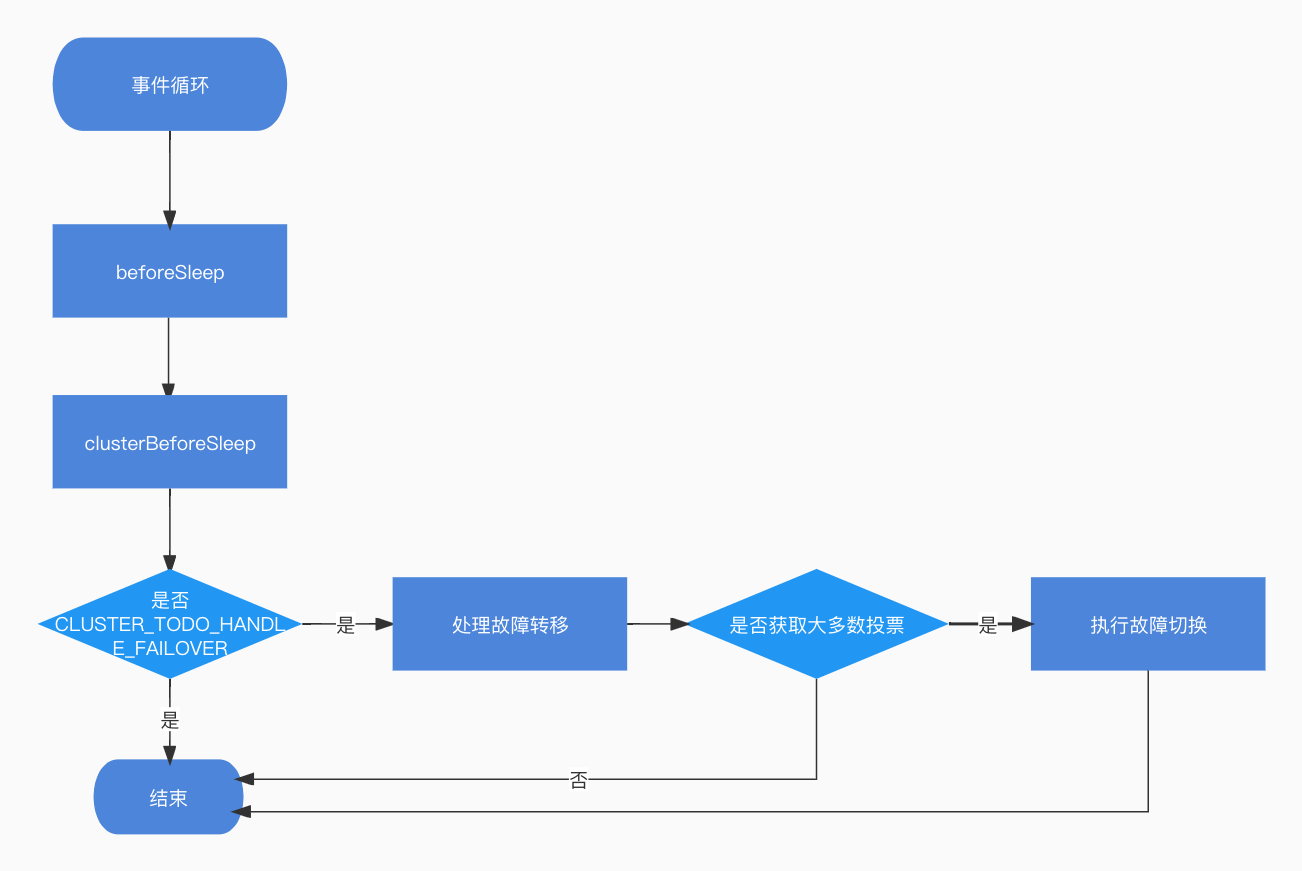
等待處理故障轉移
從節點收到投票後,會新增CLUSTER_TODO_HANDLE_FAILOVER標記,接下來看下對CLUSTER_TODO_HANDLE_FAILOVER狀態的處理。
在beforeSleep函數(server.c檔案中),如果開啟了叢集,會呼叫clusterBeforeSleep函數,裡面就包含了對CLUSTER_TODO_HANDLE_FAILOVER狀態的處理:
void beforeSleep(struct aeEventLoop *eventLoop) {
// ...
/* 如果開啟了叢集,呼叫clusterBeforeSleep函數 */
if (server.cluster_enabled) clusterBeforeSleep();
// ...
}
beforeSleep函數是在Redis事件迴圈aeMain方法中被呼叫的,詳細內容可參考事件驅動框架原始碼分析 文章。
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
// 呼叫了aeProcessEvents處理事件
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}
clusterBeforeSleep
在clusterBeforeSleep函數中,如果節點帶有CLUSTER_TODO_HANDLE_FAILOVER標記,會呼叫clusterHandleSlaveFailover函數進行處理:
void clusterBeforeSleep(void) {
// ...
if (flags & CLUSTER_TODO_HANDLE_MANUALFAILOVER) { // 處理CLUSTER_TODO_HANDLE_FAILOVER
// 手動執行故障轉移
if(nodeIsSlave(myself)) {
clusterHandleManualFailover();
if (!(server.cluster_module_flags & CLUSTER_MODULE_FLAG_NO_FAILOVER))
clusterHandleSlaveFailover(); // 故障轉移
}
} else if (flags & CLUSTER_TODO_HANDLE_FAILOVER) { // 如果是CLUSTER_TODO_HANDLE_FAILOVER狀態
/* 處理故障轉移 */
clusterHandleSlaveFailover();
}
// ...
}
故障轉移處理
clusterHandleSlaveFailover函數在上面我們已經見到過,這次我們來關注叢集的故障轉移處理。
如果當前節點獲取了大多數的投票,也就是failover_auth_count(得到的投票數量)大於等於needed_quorum,needed_quorum數量為叢集中節點個數的一半+1,即可執行故障轉移,接下來會呼叫clusterFailoverReplaceYourMaster函數完成故障轉移。
void clusterHandleSlaveFailover(void) {
// 主從複製延遲時間
mstime_t data_age;
// 當前時間減去發起選舉的時間
mstime_t auth_age = mstime() - server.cluster->failover_auth_time;
// 計算quorum的數量,為叢集中節點的數量的一半再加1
int needed_quorum = (server.cluster->size / 2) + 1;
// ...
/* 校驗是否獲取了大多數的投票,failover_auth_count大於等於needed_quorum,needed_quorum數量為叢集中節點個數的一半+1 */
if (server.cluster->failover_auth_count >= needed_quorum) {
/* 如果取得了大多數投票,從節點被選舉為主節點*/
serverLog(LL_WARNING,
"Failover election won: I'm the new master.");
/* 更新configEpoch為選舉紀元failover_auth_epoch */
if (myself->configEpoch < server.cluster->failover_auth_epoch) {
myself->configEpoch = server.cluster->failover_auth_epoch;
serverLog(LL_WARNING,
"configEpoch set to %llu after successful failover",
(unsigned long long) myself->configEpoch);
}
/* 負責master的slot */
clusterFailoverReplaceYourMaster();
} else {
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_WAITING_VOTES);
}
}
執行故障轉移
clusterFailoverReplaceYourMaster
如果從節點收到了叢集中過半的投票,就可以成為新的master節點,並接手下線的master節點的slot,具體的處理在clusterFailoverReplaceYourMaster函數中,主要處理邏輯如下:
- 將當前節點設為主節點
- 將下線的master節點負責的所有slots設定到新的主節點中
- 更新相關狀態並儲存設定
- 廣播PONG訊息到其他節點,通知其他節點當前節點成為了主節點
- 如果是手動進行故障轉移,清除手動執行故障狀態
void clusterFailoverReplaceYourMaster(void) {
int j;
// 舊的主節點
clusterNode *oldmaster = myself->slaveof;
if (nodeIsMaster(myself) || oldmaster == NULL) return;
/* 將當前節點設為主節點 */
clusterSetNodeAsMaster(myself);
replicationUnsetMaster();
/* 將下線的master節點負責的所有slots設定到新的主節點中 */
for (j = 0; j < CLUSTER_SLOTS; j++) {
if (clusterNodeGetSlotBit(oldmaster,j)) {
clusterDelSlot(j);
clusterAddSlot(myself,j);
}
}
/* 更新狀態並儲存設定*/
clusterUpdateState();
clusterSaveConfigOrDie(1);
/* 廣播PONG訊息到其他節點,通知其他節點當前節點成為了主節點 */
clusterBroadcastPong(CLUSTER_BROADCAST_ALL);
/* 如果是手動進行故障轉移,清除狀態 */
resetManualFailover();
}
總結