騰訊葉聰:朋友圈爆款背後的計算機視覺技術與應用
分享嘉賓:葉聰 騰訊 技術專家
編輯整理:張智躍
內容來源:DataFun AI Talk「智慧技術前沿實踐分享」
出品社群:DataFun
導讀: 本次分享系統介紹計算機視覺的基礎知識,如何利用這些識別演演算法實現一個應用,同時進行部署、推廣這一整套流程。主要包括以下六個部分:
1、朋友圈爆款活動背後的祕密;
2、計算機視覺基礎;
3、曾經的影象處理方法-傳統學習方法;
4、影象處理的爆發-深度學習方法;
5、解析雲端AI能力支撐;
6、技能進階。
--
01 朋友圈爆款活動背後的祕密
下圖是五四青年節的活動,一個人臉匹配的遊戲,其中使用的就是臉部辨識的演演算法。大家上傳自己的照片,就能匹配到民國時期的一些人物,然後以一種有趣的方式分享出來。為了實現這個服務,採用了一套非常有延展性的雲架構。

那如果想要做一個像剛才那樣的藝術活動,需要哪些基礎知識?下面我們進行詳細介紹。
--
02 計算機視覺基礎
1. 計算機視覺定義
計算機視覺是研究如何從影象視訊中獲取高階、抽象的資訊。從工程角度來講,計算機視覺可以使模仿視覺任務自動化。計算機視覺包含以下一些分支:物體識別(Instance Recognition)、物件檢測(Object Detection),語意分割(Sementic Segmentation),運動和跟蹤(Motion & Tracking),三維重建(3D Reconstruction),視覺問答(Visual Question & Answering),動作識別(Action Recognition)等。

由於計算機視覺已經慢慢的趨於成熟,所以它能夠顛覆的領域越來越多。基本上我們用人眼和傳統的方法能夠去識別的東西,計算機視覺都會逐步的改變。左圖是比較常見的臉部辨識,比如我們現在各種刷臉購物、刷臉進園區,這個刷臉其實就是識別(recognition),根據我們人臉的一些特徵點,進行人臉匹配,就能知道是誰。
第二個是現在非常熱門的無人駕駛,這個是一個比較複雜的、真實的任務,它可以通過不同的方式去解決,後面會詳細介紹。
第三個是語意分割。我們人類看大自然的時候,從視網膜成像以後,知道有不同的顏色。機器是通過RGB-alpha去理解這個世界上顏色的。這裡RGB就是紅綠藍三原色。一般說的真彩色叫32位元彩色,rgb佔24位元,剩下的8位元是alpha chanel,代表一個畫素是不是透明的。
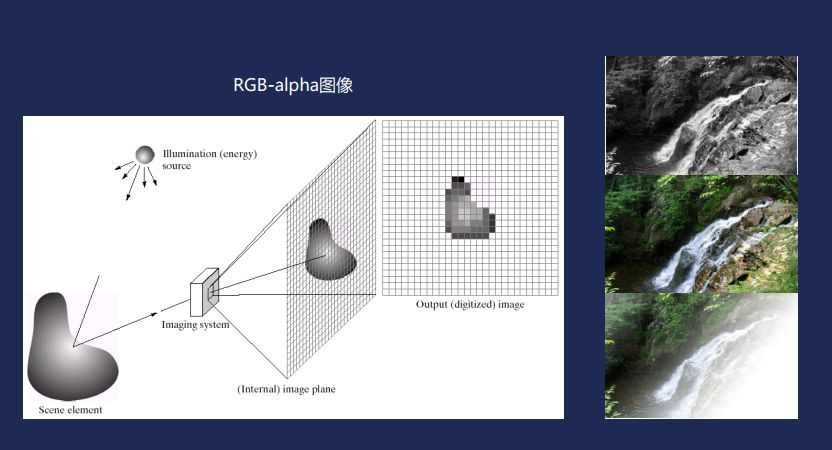
右邊的三張圖,最上面是灰度圖,本身沒有色彩。第二個是全綵圖,只有RBG沒有alpha透明通道。最後一張是真彩圖,它有alpha通道,一共有32位元。
2. 計算機視覺成像
我們經常要處理的是一些更加複雜的圖片,比如像航拍圖,熱成像圖,還有X光圖、ct圖、分子細胞圖,為了能夠處理它們採用了各種filter。

3.計算機視覺處理分級
為了更好地理解計算機視覺處理,進行了一個劃分:low level, mid level, high level。low level的東西一般比較細節,比如降噪,優化、壓縮、邊緣檢測。mid level包括分類、分割、物件檢測,驗證,語意分割等。High level更高緯、更加宏觀一些,包括情景理解、臉部辨識、無人駕駛、多模態問題等。
- ** low level processing**
下圖左邊是胸部的X光圖。左上原圖中很難看清楚骨骼血管;左下是經過強化的,圖中的骨骼、神經脈絡和血管都看得很清楚。
中上是pcb的電路板圖。原圖上面有很多的噪點,經過降噪(denoise),影象變得非常平滑,就可以進行下一步的處理。
中下是航拍圖。由於霧霾或者霧氣的原因整張圖泛白。如果直接去做一些處理,比如地圖上的一些目標識別,效果會非常差。所以先做強化(enhancement),提高對比度,影象變清晰之後再做進一步處理。
右圖是registration,就是把不同角度的圖片進行匹配。

- ** mid level processing**
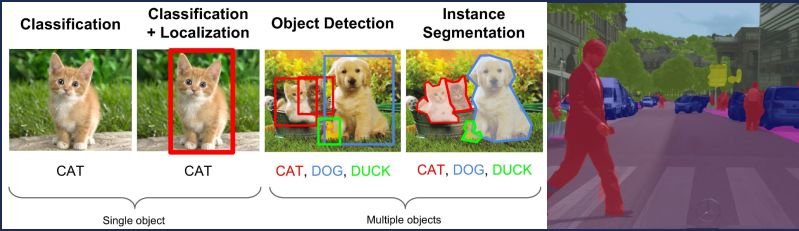
下圖是從斯坦福大學李飛飛教授的一門課借鑑過來的。以小貓、小狗分類為例。它對影象到底屬於哪個類別作一個區分。知道了物件的分類,進一步定點陣影象中物件的位置,這就是單目標識別(single object detection)。如果圖片中有很多不同的物件,比如說小貓、小狗、小鴨子,稱為目標識別(object detection)。目標識別就是把這個圖片上所有的物件都識別出來。這個圖片上面用不同的框子能區分出不同的物件,這樣只知道物件大概在什麼位置,若要精確到畫素,就要作物件劃分(instance segmentation)。
右圖是更高階別的處理,語意分割或者叫情景分割。在很多領域都有語意分割這個概念,比如在NLP中,一般指的是一句話中不同的語素成份,從文字的角度進行的一個切分。而在影象領域是對圖片裡面不同的要素進行切分,比如下圖右裡的道路是灰色,行人是紅色,植物是綠色,車是藍色,這就從顏色對圖片彙總所有同類的物件進行很精確地劃分。
- ** High Level Processing**
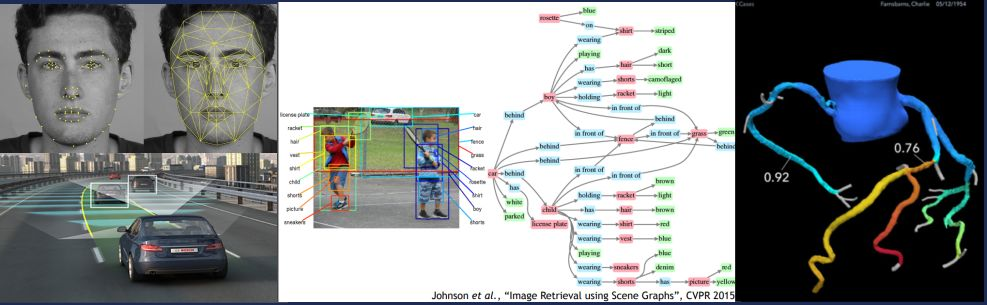
目前公司在全力研究的方向基本上都是High Level領域。因為high level有一些宏觀特性,它解決的問題都是跟大家直接相關的。下圖左上是臉部辨識,我們用演演算法抓取人臉上的特徵點(feature points),然後跟資料庫裡已經處理好的特徵去匹配,從而識別誰是誰。因為儲存在庫裡的圖片和要識別的圖片不一定是同一角度,光線也可能會有區別,所以這是個模糊匹配的過程。
左下是無人駕駛。業內現在有兩種方式解決無人駕駛問題:一種是採用鐳射雷達(lidar);還有一種是採集視訊,輔一些感測器,比如聲吶感測器、紅外感測器。並沒有說一個方式一定優於另外一種。因為雷達的成本非常高,導致整車價格很高,整車價格高代表著銷量會低,那收集到的資料就少。而機器學習是非常依賴於收集到的高質量的標註資料,這就成了悖論。因此有的只採用影象識別的方式去接近雷達的效能,這樣就能節省成本、進而收集到比較多的資料。
中間是一個情景識別(scene understanding)。圖上有兩個小孩在打球,他們方向不同,穿著不一樣,有些微動作也不一樣。通過情景識別,我們要求是可以從圖片中識別一個物件,包括他的穿著和所持的物品。然後我們還要推測它的意圖什麼,比如說play ball、walk。右邊是我們識別得到的一個帶顏色的樹。不同的顏色代表不同的主謂賓,還有定狀語。通過這種方式,我們提取到圖片裡面所有的資訊,不僅僅知道有誰,而且他在做什麼,也可以進行預測。
然後右圖是一個3D血管圖。醫生做心血管手術之前,通過掃描得到的資料對血管進行3D重建。在做手術之前醫生通過看3D模型就能夠知道每個血管的厚度是多少,在哪裡可能有風險。用這種方式大大降低了手術的風險。這些都是已經落地的專案。
還有一些其他比較常見的例子,包括多臉部辨識。我們拍照的時候會對人臉方向進行重重聚焦。中間的圖是文字識別(OCR),圖上是用鐳射筆進行掃描,掃描完了以後再去識別,是很老的一種文字識別方式。現在由於整個OCR的技術相當成熟,基本上是大家提供一個比較清晰的照片,然後全部識別出來。右邊是車牌識別,這在國內是非常常用的技術。

4.目標跟蹤
目標跟蹤是非常有潛力,非常有挑戰、有前景的一個話題。以下圖NBA視訊為例,追蹤球員在場地上的位置。中間是球員動作有形變;右邊是由於高光打在球員身上,整個人的樣子都發生了變化。下圖中存在的問題是:目標快速移動時抓拍速度不夠快的話,目標就會模糊;如果背景色跟前景色非常接近時,會出現干擾。以上這些問題可能會在目標跟蹤過程中同時出現,目前也沒有哪種方法可以很完美的解決,仍不斷有新的方法出現。

在追蹤不會動的人臉時,也會出現各種問題,如人臉會垂直旋轉;也會部分在畫面、部分不在畫面;也可能發生遮擋。目前做目標跟蹤比較好的方式就是在不同的情景下使用不同的演演算法。

5.多模態問題
多模態問題就是將計算機視覺、NLP、語音識別整合起來才能解決的問題。比如視覺化問答。以下圖寶寶為例,問題是寶寶坐在哪,就是寶寶在影象中的位置。首先要做圖片的情景識別,理解圖片上面有什麼東西,比如寶寶坐在哪裡;另外還要有nlp的引擎去理解這個的問題,它問的是孩子坐在哪兒,不是問他幹什麼;最後通過理解使用者的問題和影象裡面的因素,進一步的匹配。所以這個例子中包含三個模態,這就是一個典型的多模態問題。

還有一個多模態問題的例子,就是根據一幅圖片去理解圖片情景進而生成一段文字描述。這裡第一要理解圖片裡面有什麼;第二,要能根據圖片裡面提取出來因素去生成一個描述的語句、故事。這裡面至少有兩個模型。同時,為了訓練生成的內容描述,要輸入不同的訓練集,這樣就會變得更加的複雜。

--
03 曾經的影象處理方法-傳統方法
傳統的影象處理方法,包括濾波、分類、分割和目標檢測。常用的濾波方法包括空間濾波器、傅立葉、小波濾波器等;特徵設計方法包括SIFT、HOG等;分類方法包括SVM、AdaBoost、Bayesian等;分割和目標檢測方法包括分水嶺、水平集、主觀模型等。
1.特徵設計-邊緣檢測
識別影象,首先要讓機器能夠讀到它的一些特徵。從這個角度講,需要進行影象特徵設計。比較容易想到的特徵提取方法就是邊緣特徵。以下圖為例,要識別圖中所有的硬幣,可以把硬幣的邊緣和花紋的邊緣提取出來,作為一個影象特徵。

- ** 特徵設計-Harr特徵**
當物件邊緣不清晰時,比較經典的方法是Harr特徵。它是把影象上不同位置的灰度變化用黑白方框表示出來。上面兩行代表垂直和水平的灰度變化,它只有上下左右四個方向。右下角對角線的方式是進一步優化的harr方法,可以表示45度方向的灰度變化。

- 特徵設計-對稱
很多識別物件有一定的區域性對稱性,比如人、房屋,因此可以利用對稱的特點解決問題。它是根據越靠近物件的重心點的位置越亮,越靠近邊緣的話越暗,用重心這個特徵去代表這個物件。

- 特徵設計-尺度不變特徵
除了harr特徵、對稱性兩種特徵,目標檢測中常用的還有尺度不變特徵(sift)。尺度空間其實是描述我們從遠到近去看一個東西從模糊慢慢變清晰的一個過程。尺度不變特徵就是在圖片上提取一些關鍵的尺度點,在每個方向上去獲得一些向量引數。然後利用這些方向向量去匹配一些角度或是旋轉之後都不太一樣的照片。即使這個圖片可能會有一些遮擋,只要它的尺度點沒有被遮蔽,一樣進行匹配。

- ** 特徵設計-方向梯度直方圖(HOG)**
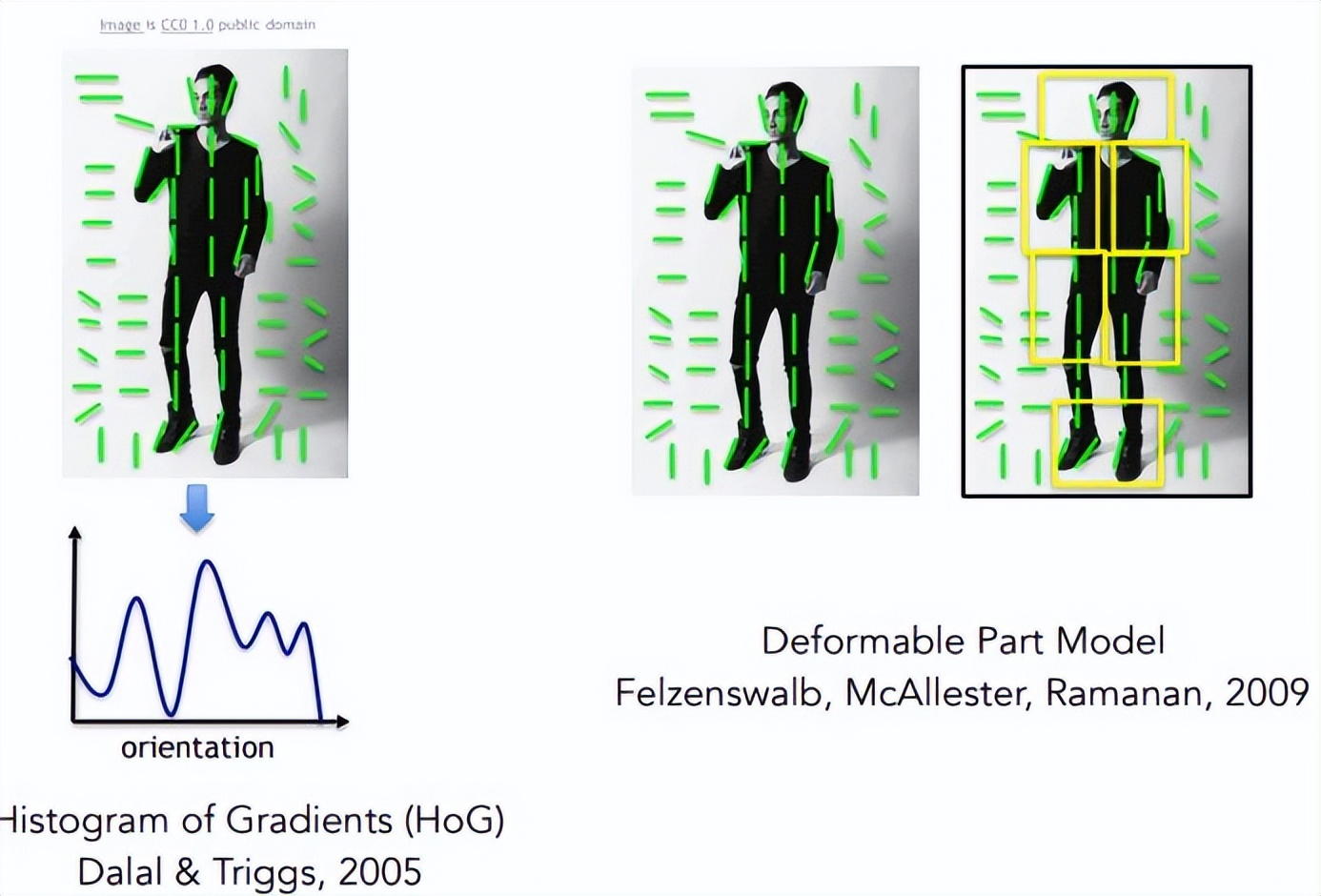
另外一種跟灰度有關的特徵方法叫做方向梯度直方圖(HOG)。下圖中人和的背景正好有一些灰度上的區分,就可以用方法識別。圖中的綠色線條代表著圖片上灰度變化最小的方向。這個圖上人穿的是黑色的衣服,幾乎沒有灰度變化,所以整個線條以垂直的方式不斷延伸。而背景由於它的光線從各個方向都有,所以它的方向梯度直方圖比較比較雜亂的。因此通過方向梯度直方圖我們就可以把人識別出來。
2. 分割和目標檢測
- ** 分水嶺演演算法**
首先對整個圖片進行掃描,得到灰度的曲線圖。然後往灰度曲線圖去灌水,自然會有兩個相鄰的谷底要聯通,這時建個水壩,不讓它們聯通。然後繼續貫水,直到又有兩個相鄰的灰度區域要連通,繼續建壩。重複這個過程,最終整個曲線圖上有多個水壩,每個水壩的位置其實就是邊緣的劃分。

- 主觀形狀模型
另外一個傳統的物件檢測方法叫做主觀形狀模型。我們把物件的邊緣全部提取出來,進行各種形變,然後和要識別的目標進行匹配。一旦匹配上了,我們就實現目的。這種方法侷限性就是輸入的圖片角度的變化,或者說我們今天穿著打扮不一樣,不一定完全匹配上。

--
04 影象處理的爆發-深度學習方法
1.深度學習之神經網路
深度學習指的就是深度神經網路。左邊是一個簡單的兩層神經網路,看起來是三層,但一般不算輸入層。神經網路分三種不同的層:input layer,hidden layer,output layer。input layer一般是獲取使用者各種輸入;hidden layer做各種不同的運算;output layer產生結果。那神經網路和SVM、邏輯迴歸有什麼關係?其實邏輯迴歸和SVM是一種特殊的單層神經網路。
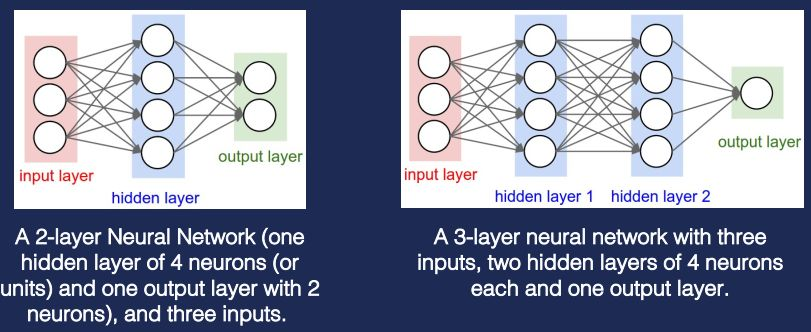
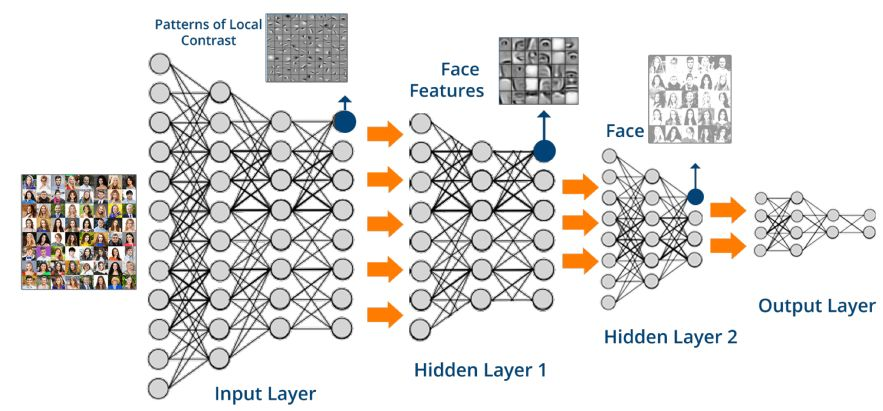
上圖是簡單的神經網路架構,實際上真實的神經網路會遠比上面複雜。下圖是人臉檢測的一個神經網路。hidden layer在進行處理時要區分不同的變數,不同變數針對不同方面的問題。最後通過output layer彙總。
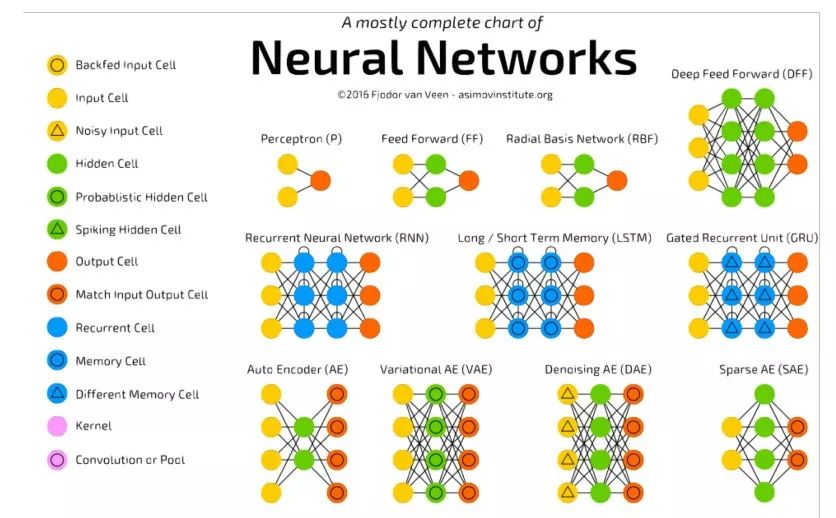
神經網路除了金字塔形,還有下圖中的其他形式。這些都是根據不同的問題提出的不同的網路結構。在傳統機器學習中,我們是在想用哪種演演算法,如何調參能夠把模型適用這個產品。到了深度學習的時候,演演算法科學家的大部分研究是在產品上使用什麼樣的神經網路,哪種型別神經網路,怎麼設計它每一層的作用,怎麼設計它的啟用因子,怎麼去設計output layer,怎麼去做聚合,思維的方式發生了很大的變化。
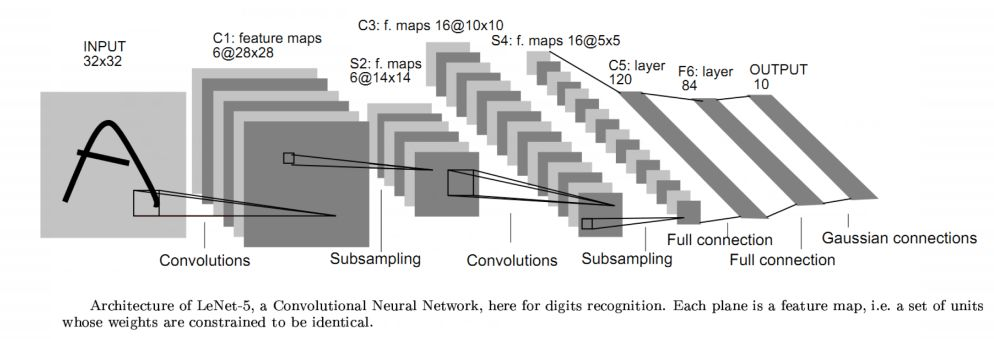
- 折積神經網路
在CV領域,比較常見的深度神經網路叫折積神經網路。首先介紹折積層(convolutional layer)。在傳統機器學習,我們要做特徵提取(feature design),這cnn中就是通過折積層來實現。折積層之後是池化層。池化層的作用就是找出重要的特徵,或者把幾個不的重要特徵合併再傳遞下去,這樣可以減少資料的運算量。最後一層叫做全連線層(full connection layer),它的作用就是把之前所有資料的進行聚合,產生結果。
實際使用中會不斷進化出新的架構,比如下圖的faster r-cnn,做了很多的優化,其中最重要的優化是RPN(region proposal network)的加入。由於原始cnn是在影象上做全量搜尋,這在影象非常大情況下運算量會很大,速度就會很慢。為了增快速度,首先把圖片上沒有目標的區域排除掉,然後在剩下的區域內跑真正的r-cnn,這樣整體速度就提高了很多。
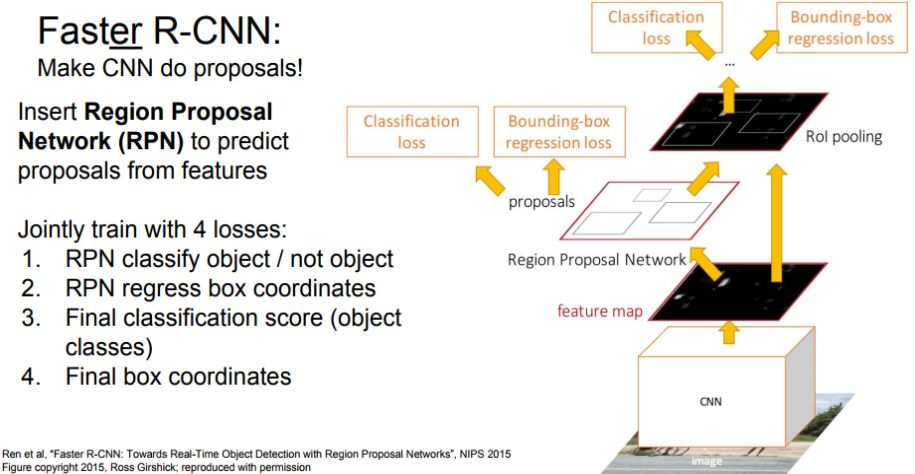
從CNN到Faster-RCNN都是同樣一種解決問題的思維方式,叫物件識別的方式。那回歸到分類的方式解決問題,就提出了一種新的網路-yolo。

2.影象AI應用案例分析
- 案例一
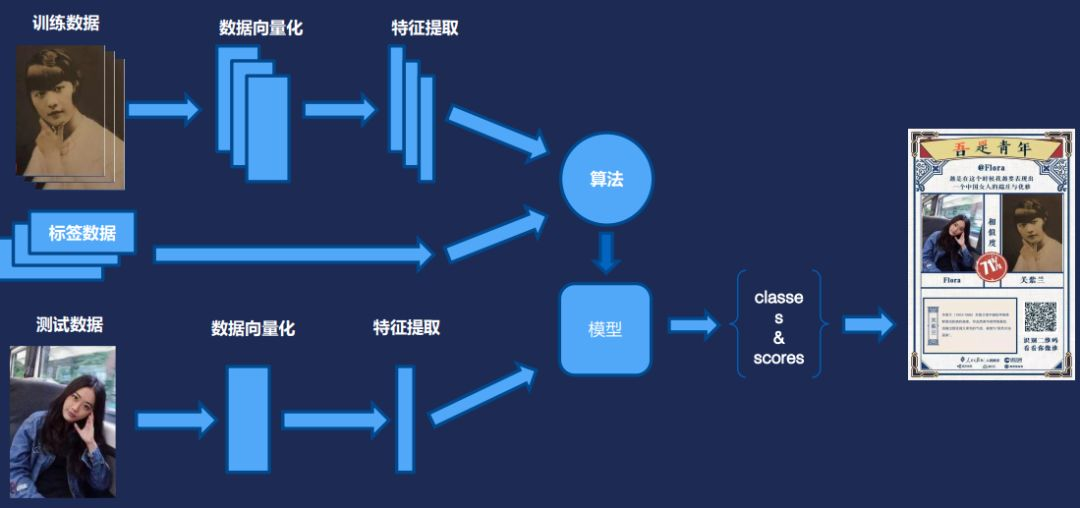
剛開始展示的五四青年節活動是這樣做的。首先有幾百張民國時期有志青年的照片,提取其中的一些特徵,把這些特徵資料向量化。每個人標註好標籤。訓練後就可以生成一個模型。在實際使用時,後臺會提取上傳照片的特徵值,和模型裡面已有的進行匹配,然後返回值是一個分類加上一個置信度(score)。最後再合成一個頁面,供大家在朋友圈轉發。
- 案例二
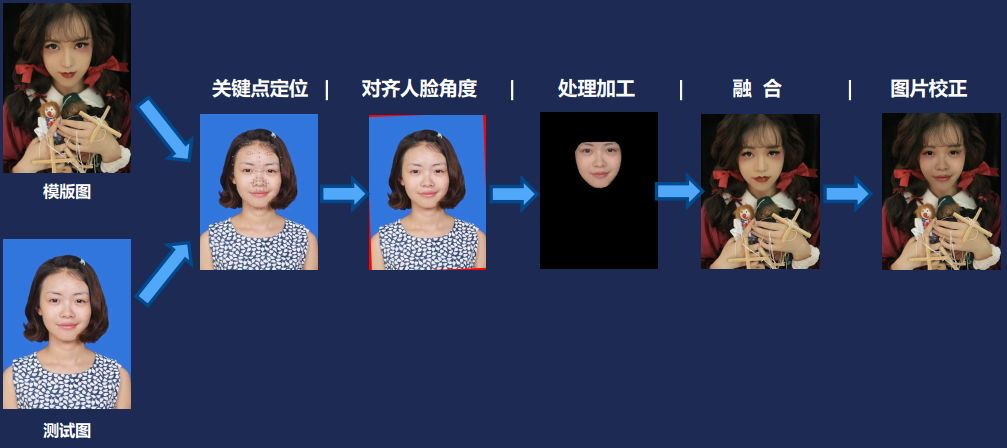
第二個是另外一個特別熱門例子,人臉融合。大家經常看軍裝照、古代照,都是人臉融合演演算法的結果。它原理是這樣的:首先使用者上傳照片,但上傳的照片往往不是百分之百正位的,可能會有角度,幅度,為了讓融合結果更加的平滑,會進行關鍵點定位,對人臉進行一些對齊矯正。然後利用演演算法把人臉摳出來,和模板圖進行融合。融合圖其實並不是那麼自然,所以更多的工作是圖片校正,比如曲線調優,邊緣融合,色彩調節。這樣大家能看到自己回到民國、或者清朝時候的一個照片。
- 案例三
第三個例子是根據圖片講故事。這個引擎的用到了不同的演演算法。整個訓練過程基本上是無監督學習,除了訓練講故事的文字型檔。它適用場景非常廣泛。通過改變不同的文字型檔,比如從浪漫小說改為科幻小說,那生成的文字就會從浪漫範變成科幻範,靈活性非常強。
3.計算機視覺演演算法前沿分析
這裡推薦一個你不想錯過的論文庫:www.arxiv.org
前面提到了有兩種不同的方式實現無人駕駛,一種是用鐳射雷達,還有一種是用單目照片,或者雙目照片。百度、谷歌主要使用鐳射雷達。而特斯拉使用照片,它主要是從成本來考慮,所以它蒐集到非常多的資料。

目前這兩種方法都在進行中,特斯拉現在通過不斷的優化,目前駕駛能力已經達到L3,慢慢接近有雷達的車的效果。而且隨著資料量越來越大,有可能它的效果會無限接近於雷達的效果。雷達的意義在於什麼?因為雷達都是在車頂,它在掃描的時候,拿到的是鳥瞰圖,是一個3d圖。它拿到周圍所有物體相對車的位置,還有它的外形,甚至可以3D建模出來。
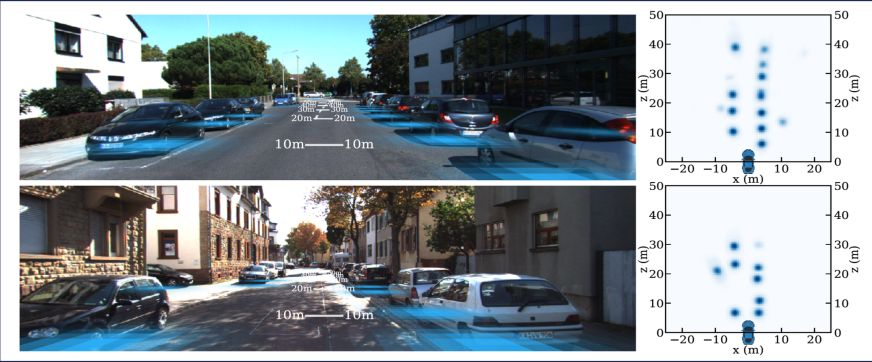
而普通的單目照片只是一個平面圖,沒有距離資訊。最近有個演演算法叫正交特徵變換(OFT),它對靜態圖片上不同的物件,先進行正交化的特徵提取,然後利用這種方式去識別不同物件之間的相對位置。通過一系列的計算,就把單目圖變成一個3D圖。基本上實現了鐳射雷達的效果。OFT在目前所有提出來的單目轉成3D圖方法中效果最好。
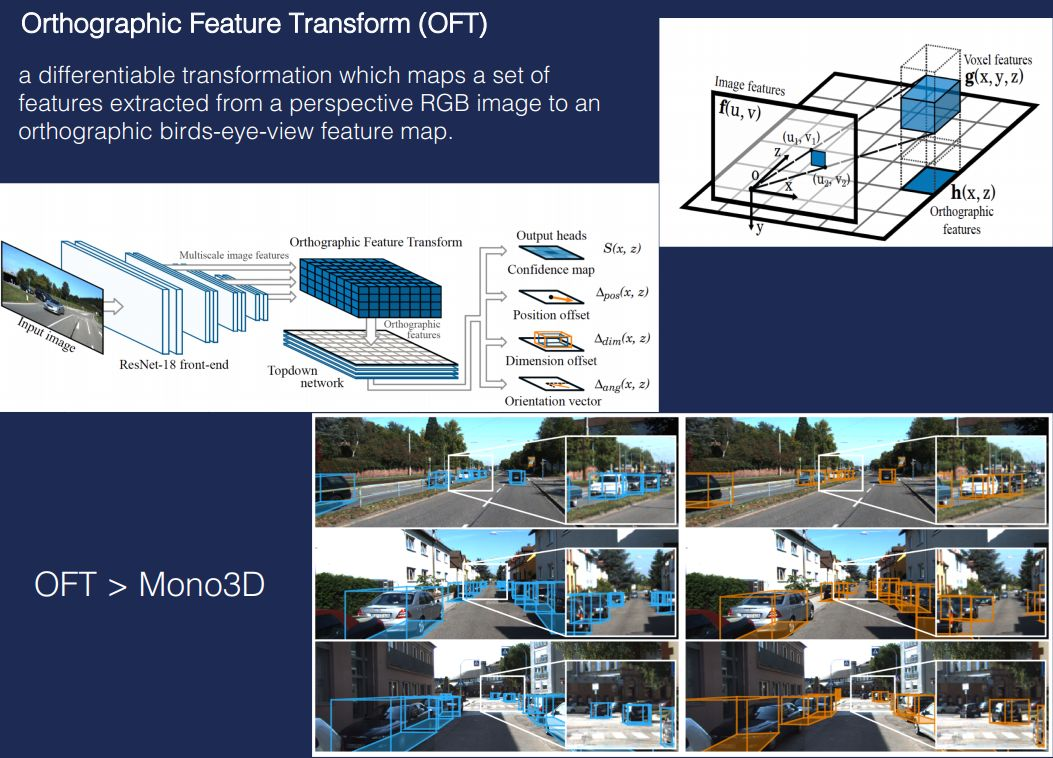
--
05 解析雲端AI能力支撐
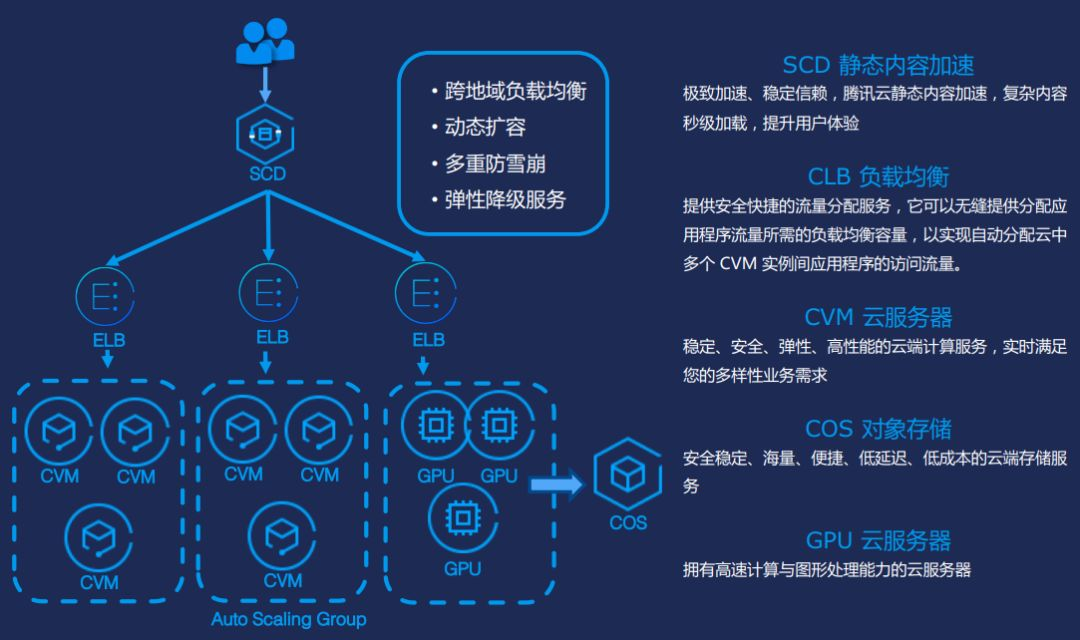
我們做一個產品,首先不僅要有演演算法模型,還有一個非常健壯的架構去支撐這演演算法模型,讓千萬級或者上億級的使用者可以穩定的使用這個模型演演算法。這個情況下我們需要用到雲架構,下圖是我們的雲服務架構。
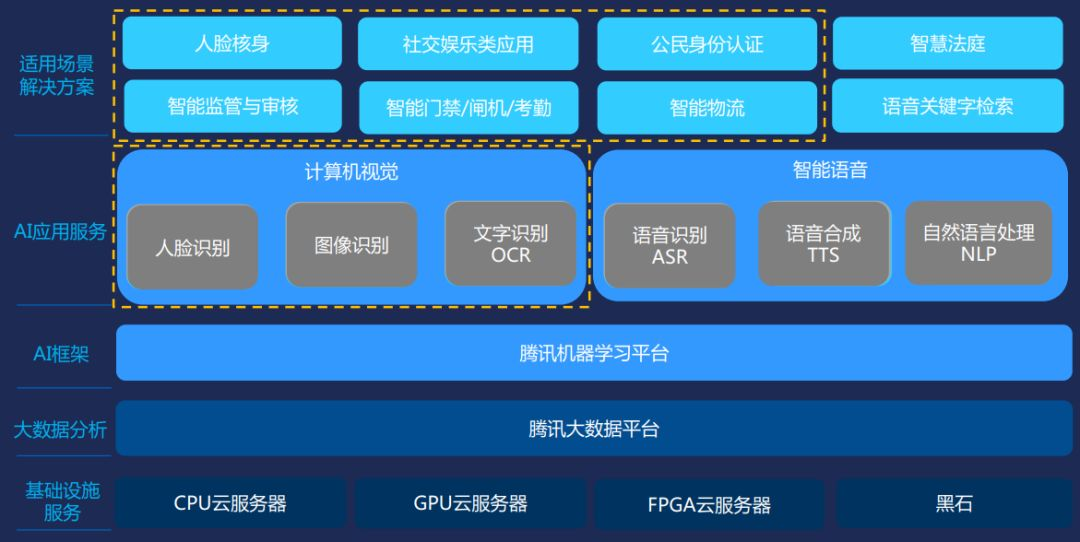
下圖是騰訊雲的方案矩陣。大概分幾個不同的領域:人臉(計算機視覺)。這個裡面包括人臉和聲,身份證識別,還有各種基於場景的,比如智慧門禁物;語音領域,我們也有ASR(語音-文字)和TTS(文字-語音)的能力。底層有機器學習的平臺和巨量資料的平臺去支撐。基礎建設就包括我們剛才提到的CPU、GPU,還有FPGA的各種伺服器。
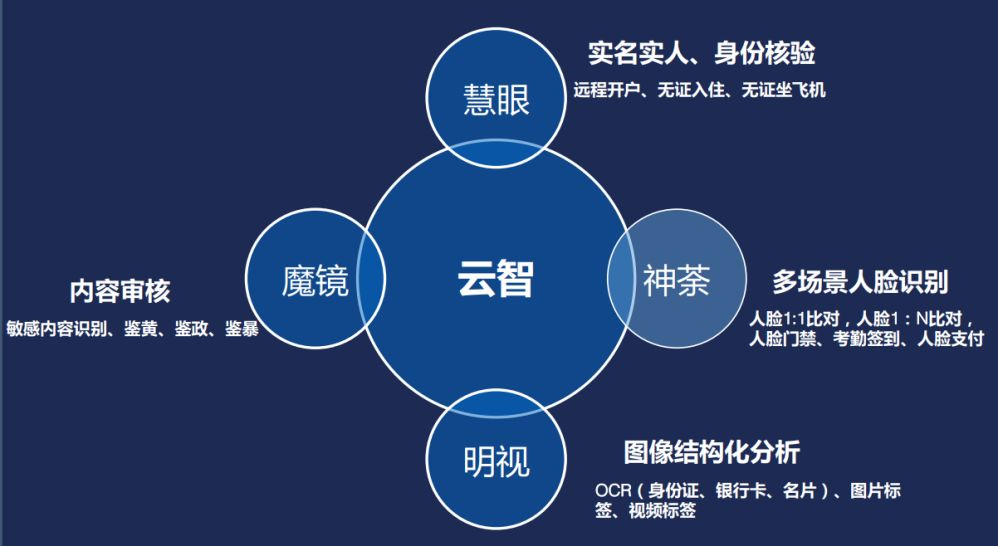
我們目前計算機視覺的產品大概分四類,其中包括雲智的慧眼,它是實名認證的身份核驗的產品。神荼是關於多場景的人臉的識別,比如考勤簽到,還有我們支付用的臉部辨識。明視是影象結構化分析,它包括我們的身份證識別,銀行卡識別名片識別這些。魔鏡主要是內容稽核,比如識別各種視訊圖片的鑑黃鑑恐鑑暴等敏感資訊。
下面是我們一個私有化的視訊管理平臺,叫雲智平臺(TIMatrix)。它是針對各種智慧樓宇園區的一個產品。它可以幫助一個主題公園,一個廠區或者一個公司快速地搭建起一整套的視訊監控體系。我們背後也有各種的A.I.引擎去做巨量資料的分析,客戶畫像熱力圖等,非常適合to B的一些場景。
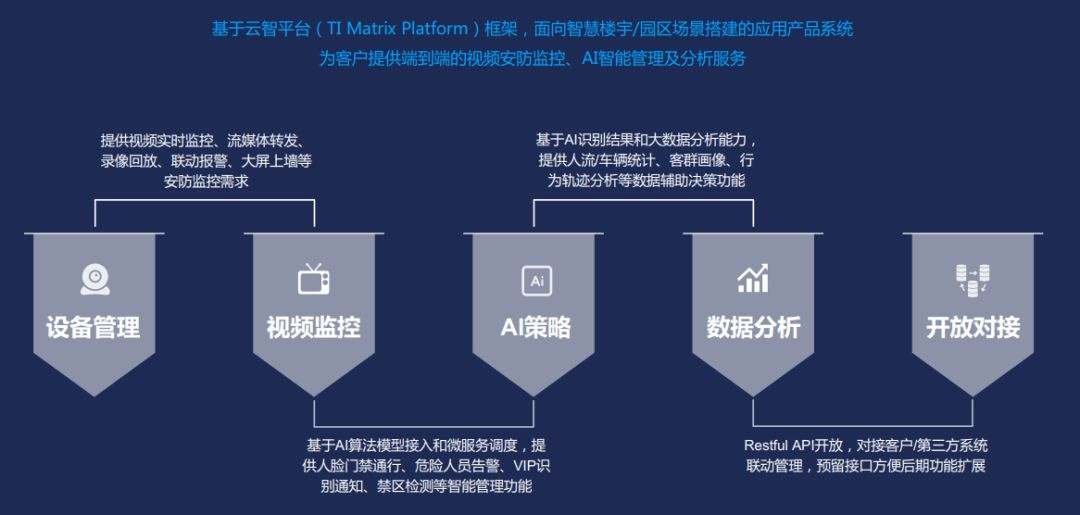
--
06 技能進階

今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號「DataFunTalk」。