1. 梯度下降法
1. 簡介
梯度下降法是一種函數極值的優化演演算法。在機器學習中,主要用於尋找最小化損失函數的的最優解。是演演算法更新模型引數的常用的方法之一。
2. 相關概念
1. 導數
- 定義
設一元函數\(f(x)\)在\(x_0\)的臨域內有定義,若極限
\[f^{`}(x_0)=\lim_{\Delta x\to0}\frac{f(x+\Delta x)-f(x)}{\Delta } \]存在,則稱\(f^{`}(x_0)\)為\(f(x)\)在\(x=x_0\)處的導數。
- 意義
- 導數的絕對值大小代表了當前函數的在該處的變化速度
- 導數的正負代表了在一定臨域內隨著自變數\(x\)的增加,函數值是增大還是減小
2. 偏導數
- 定義
對於多元函數\(f(x),x \in R^p\),\(f(x)\)在對\(x_i\)的偏導數定義為
\[\frac{\partial f(x)}{\partial x_i}=\lim_{\Delta x \to 0}\frac{f(x_1,x_2,\cdots,x_i+\Delta x,\cdots,x_p)-f(x_1,x_2,\cdots,x_i,\cdots,x_p)}{\Delta x} \]
- 意義
偏導數定義了多元函數在某個數軸方向上的變化情況。
3. 方向導數
- 定義
函數的偏導數定義了在各個數軸上的變化率,方向導數則為函數在任意方向上的變化率。以二元函數\(f(x,y)\)為例:
\[\nabla \frac{\partial f(x)}{\partial l}|_{(x_0,y_0)}=\frac{\partial f(x)}{\partial x}\cos(\alpha)+\frac{\partial f(x)}{\partial y}\cos(\beta) \]
- 意義
多元函數在某點處的方向導數有無數個,每一個方向導數的值代表了在該方向上的變化程度,我們要尋找在某點處函數變化最快的方向就可以轉化成尋找在該點處方向導數的絕對值最大時對應的那個方向
4. 梯度
- 定義
梯度是一個向量,表示函數沿著該方向的變化率最大,記為
\[f(x)=(\frac{\partial f(x)}{\partial x_1},\frac{\partial f(x)}{\partial x_2},\cdots,\frac{\partial f(x)}{\partial x_p})^T \]
- 為什麼該方向為變化最快的方向
根據方向導數定義,
\[\begin{align*} \frac{\partial f(x)}{\partial l}|_{(x_0,y_0)} &=\frac{\partial f(x)}{\partial x}\cos(\alpha)+\frac{\partial f(x)}{\partial y}\cos(\beta) \\ &= (\frac{\partial f(x)}{\partial x},\frac{\partial f(x)}{\partial y})(\cos(\alpha),\cos(\beta))^T \\ &= A\cdot I \quad\quad (A=(\frac{\partial f(x)}{\partial x},\frac{\partial f(x)}{\partial y}),I=(\cos(\alpha),\cos(\beta))^T ) \\ &= ||A||\times||I||\cos(\theta) \qquad (\theta為兩個向量的夾角) \end{align*} \]當且僅當 \(\theta=0\),即\(A\)和\(I\)通向時,方向導數取得最大值,因此梯度表示變化率最大的方向,此時方向導數為正。因此梯度指向函數增大的方向。
3 原理詳解
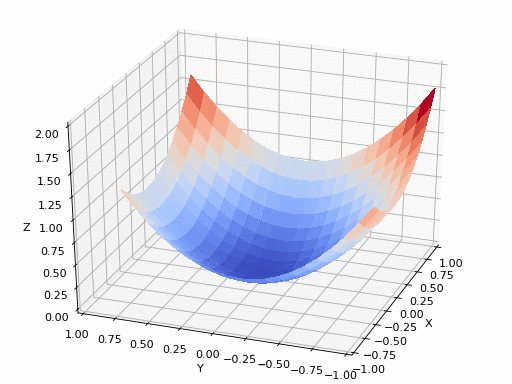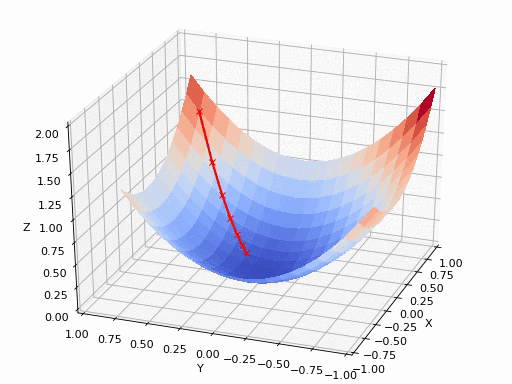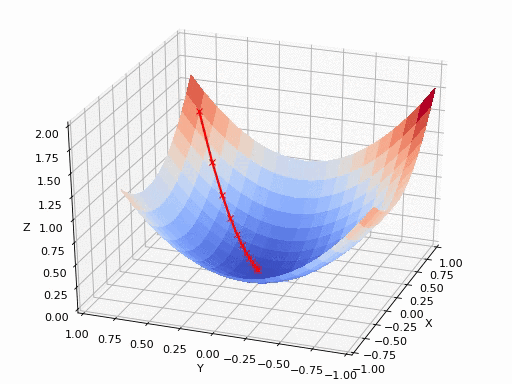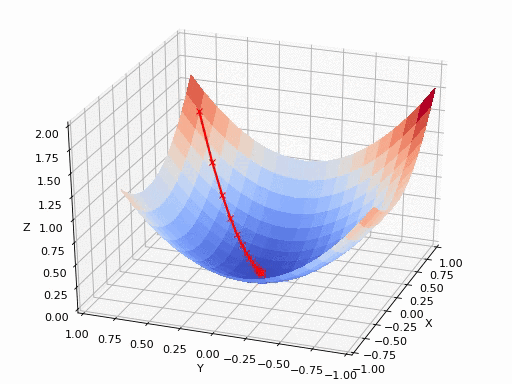
假設在一個類是凹函數的山中放一個小球,讓它自然的捲動到山谷(最小值點)處,那麼小球捲動每個地點捲動的方向都是梯度的負方向。
現在有一個凹函數,要找到它的最小值,在不考慮解析解的情況下,也可以利用類似的方法去求解。先隨機找一個初始點\(x_0\),然後求出該點的梯度,利用公式\(x_1=x_0-lr*\nabla f(x)\)模擬小球的捲動,其中\(lr\)為捲動的步長,也稱為學習率。
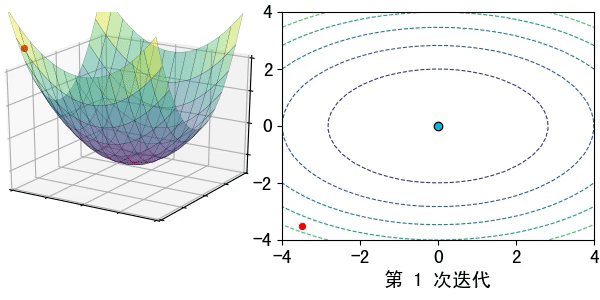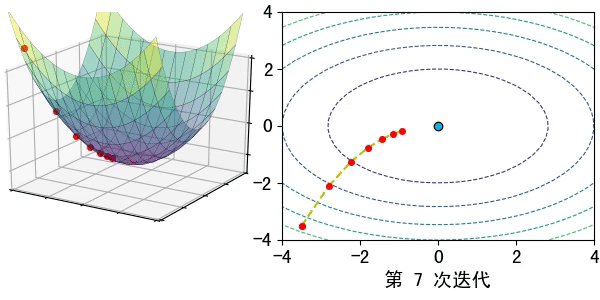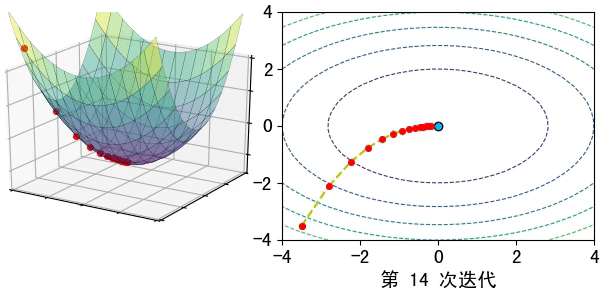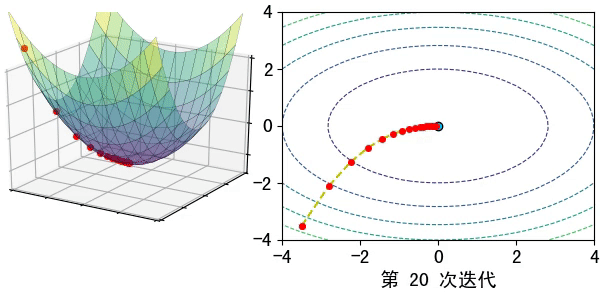
通過迭代公式 \(x_n=x_{n-1}-lr* \nabla f(x)\)一步步去逼近函數的極小值點。通常迭代的結束條件有:
- 指定迭代次數
- 計算迭代前後函數值的差距,若在一個非常小的閾值以為就可以認為已經找到最小值
4. 程式碼實現
案例 :\(f(x)=(x_1-2)^2+(x_2-3)^2+(x_3-4)^4\)
import numpy as np
#定義函數
def func(x):
return (x[0]-2)**2+(x[1]-3)**2+(x[2]-4)**2
#定義梯度
def gradFunc(x):
return np.array([(x[0]-2)*2,(x[1]-3)*2,(x[2]-4)*2])
# 定義梯度下降法
def SGD(init_x,func,gradFunc,lr=0.01,maxIter=100000,error=1e-10):
x=init_x
for iter in range(0,maxIter):
gd=gradFunc(x)
x_new=x-lr*gd
if(np.abs(func(x)-func(x_new))<error):
return x_new
x=x_new
return x_new
SGD(np.array([1,1,1]),func,gradFunc)
array([1.99998703, 2.99997406, 3.99996109])
SGD(np.array([10,10,10]),func,gradFunc)
array([2.00003215, 3.00002813, 4.00002411])