Elasticsearch學習系列一(部署和設定IK分詞器)
Elasticsearch簡介
Elasticsearch是什麼?
Elaticsearch簡稱為ES,是一個開源的可延伸的分散式的全文檢索引擎,它可以近乎實時的儲存、檢索資料。本身擴充套件性很好,可延伸到上百臺伺服器,處理PB級別的資料。ES使用Java開發並使用Lucene作為其核心來實現索引和搜尋的功能,但是它通過簡單的RestfulAPI和javaAPI來隱藏Lucene的複雜性,從而讓全文搜尋變得簡單。
起源:Shay Banon。2004年失業,陪老婆去倫敦學習廚師。失業在家幫老婆寫一個菜譜搜尋引擎。封裝了lucene,做出了開源專案compass。找到工作後,做分散式高效能專案,再封裝compass,寫出了elasticsearch,使得lucene支援分散式。現在是Elasticsearch創始人兼Elastic執行長
Elasticsearch的功能
- 分散式的搜尋引擎
分散式:Elasticsearch自動將海量資料分散到多臺伺服器上去儲存和檢索
- 全文檢索
提供模糊搜尋等自動度很高的查詢方式,並進行相關性排名,高亮等功能
- 資料分析引擎(分組聚合)
電商網站,最近一週筆記型電腦這種商品銷量排名top10的商家有哪些?新聞網站,最近1個月存取量排名top3的新聞板塊是哪些
- 對海量資料進行近實時的處理
海量資料的處理:因為是分散式架構,Elasticsearch可以採用大量的伺服器去儲存和檢索資料,自然而然就可以實現海量資料的處理。近實時指的是Elasticsearch可以實現秒級別的資料搜尋和分析
Elasticsearch的特點
- 安裝方便:沒有其他依賴,下載後安裝非常方便;只用修改幾個引數就可以搭建起來一個叢集
- JSON:輸入/輸出格式為 JSON,意味著不需要定義 Schema,快捷方便
- RESTful:基本所有操作 ( 索引、查詢、甚至是設定 ) 都可以通過 HTTP 介面進行
- 分散式:節點對外表現對等(每個節點都可以用來做入口)加入節點自動負載均衡
- 多租戶:可根據不同的用途分索引,可以同時操作多個索引
- 支援超巨量資料:可以擴充套件到PB級的結構化和非結構化資料海量資料的近實時處理
使用場景
- 搜尋類場景
如電商網站、招聘網站、新聞資訊類網站、各種app內的搜尋。
- 紀錄檔分析類場景
經典的ELK組合(Elasticsearch/Logstash/Kibana),可以完成紀錄檔收集,紀錄檔儲存,紀錄檔分析查詢介面基本功能,目前該方案的實現很普及,大部分企業紀錄檔分析系統使用了該方案。
- 資料預警平臺及資料分析場景
例如電商價格預警,在支援的電商平臺設定價格預警,當優惠的價格低於某個值時,觸發通知訊息,通知使用者購買。資料分析常見的比如分析電商平臺銷售量top 10的品牌,分析部落格系統、頭條網站top10關注度、評論數、存取量的內容等等。
- 商業BI(Business Intelligence)系統
比如大型零售超市,需要分析上一季度使用者消費金額,年齡段,每天各時間段到店人數分佈等資訊,輸出相應的報表資料,並預測下一季度的熱賣商品,根據年齡段定向推薦適宜產品。Elasticsearch執行資料分析和挖掘,Kibana做資料視覺化。
常見案例
- 維基百科、百度百科:有全文檢索、高亮、搜尋推薦功能
- stack overflow:有全文檢索,可以根據報錯關鍵資訊,去搜尋解決方法。
- github:從上千億行程式碼中搜尋你想要的關鍵程式碼和專案。
- 紀錄檔分析系統:各企業內部搭建的ELK平臺
Elasticsearch VS Solr
- Lucene
Lucene是Apache基金會維護的一套完全使用Java編寫的資訊搜尋工具包(Jar包),它包含了索引結構、讀寫索引工具、相關性工具、排序等功能,因此在使用Lucene時仍需要我們自己進一步開發搜尋引擎系統,例如資料獲取、解析、分詞等方面的東西。
注意:Lucene只是一個框架,我們需要在Java程式中整合它再使用。而且需要很多的學習才能明白它是如何執行的,熟練運用Lucene非常複雜。
- Solr
Solr是一個有HTTP介面的基於Lucene的查詢伺服器,是一個搜尋引擎系統,封裝了很多Lucene細節,Solr可以直接利用HTTP GET/POST請求去查詢,維護修改索引
- Elasticsearch
Elasticsearch也是一個建立在全文搜尋引擎 Apache Lucene基礎上的搜尋引擎。採用的策略是分散式實時檔案儲存,並將每一個欄位都編入索引,使其可以被搜尋。
總結:
- Solr和Es都是基於Lucene實現的
- Solr利用Zookeeper進行分散式管理,而Es自身帶有分散式協調管理功能
- Solr比Es實現更全面,功能更多,而Es本身更注重於核心功能,高階功能多由第三方外掛提供
- Solr在傳統的搜尋應用中表現比Es好,而Es在實時搜尋應用方面比Solr好
- Solr查詢快,但更新索引時慢,可用於電商等查詢多的應用;而Es建立索引快,更實時
- 隨著資料量的增加,Solr的搜尋效率會變得更低,而Es卻沒有明顯變化
安裝部署ES
- 下載es,並解壓
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-3-0
- 編輯vim config/elasticsearch.yml,修改下面的4個地方。network.host對應自己機器的ip
node.name: node-1
network.host: 192.168.211.136
#
# Set a custom port for HTTP:
#
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
- ++按需++修改vim config/jvm.options記憶體設定
可以調整裡面的Xms和Xmx
3. 新增es使用者(es預設root使用者無法啟動)
useradd estest
#修改密碼
passwd estest
- 賦予estest使用者一個目錄許可權
chown -R estest /usr/elasticsearch/
- 修改/etc/sysctl.conf
#末尾新增
vm.max_map_count=655360
修改完執行sysctl -p,讓其生效
sysctl -p
- 修改/etc/security/limits.conf
#末尾新增
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
- 修改/etc/security/limits.d/20-nproc.conf
#末尾新增
* hard nproc 4096
重新登入或重啟伺服器使設定生效。
- 啟動es
#切換使用者
su estest
#啟動
bin/elasticsearch
- 測試
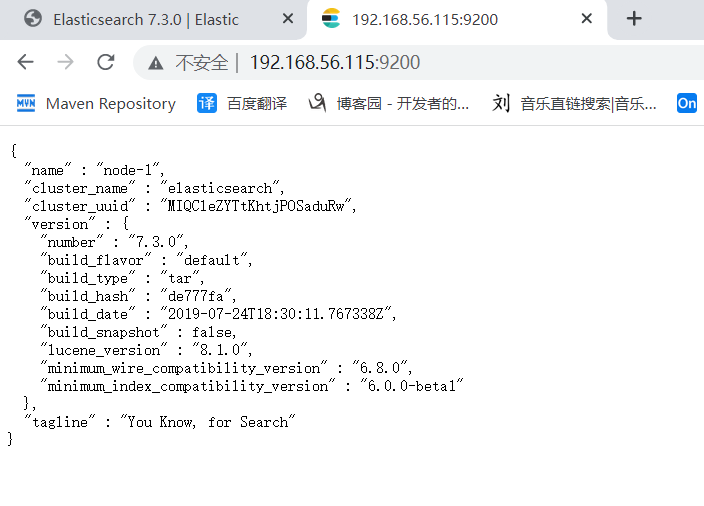
測試ok,安裝成功!!!
安裝設定Kibana
什麼是Kibana?
Kibana是一個基於Node.js的Elasticsearch索引庫資料統計工具,可以利用Elasticsearch的聚合功能,生成各種圖表,如柱狀圖、線狀圖、餅圖等。而且還提供了操作Elasticsearch索引資料的控制檯,並且提供了一定的API提示,非常有利於我們學習Elasticsearch的語法。
安裝Kibana
- 下載Kibana
root賬戶下操作:
- 解壓
- 改變kibana目錄許可權、設定存取許可權
chown -R estest /usr/local/kibana-7.3.0-linux-x86_64
chmod -R 777 /usr/local/kibana-7.3.0-linux-x86_64
- 修改組態檔
server.port: 5601
server.host: "0.0.0.0"
# The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.hosts: ["http://192.168.211.136:9200"]
- 啟動
su estest
bin/kibana
存取地址: http://192.168.56.115:5601

後續的操作我們可以使用kibana來存取es:
Es整合IK分詞器
KAnalyzer是一個開源的,基於java語言開發的輕量級的中文分詞工具包。從2006年12月推出1.0版開始,IKAnalyzer已經推出了3個大版本。最初,它是以開源專案Lucene為應用主體的,結合詞典分詞和文法分析演演算法的中文分詞元件。新版本的IKAnalyzer3.0則發展為面向Java的公用分詞元件,獨立於
Lucene專案,同時提供了對Lucene的預設優化實現。
外掛安裝方式
- 在es的bin目錄下執行以下命令,es外掛管理器會自動幫我們安裝,然後等待安裝完成。
bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.3.0/elasticsearch-analysis-ik-7.3.0.zip
安裝包安裝方式
-
在es安裝目錄下的plugins目錄下新建analysis-ik目錄
#新建analysis-ik資料夾
mkdir analysis-ik
#切換至 analysis-ik資料夾下
cd analysis-ik
#上傳資料中的 elasticsearch-analysis-ik-7.3.0.zip
#解壓
unzip elasticsearch-analysis-ik-7.3.3.zip
#解壓完成後刪除zip
rm -rf elasticsearch-analysis-ik-7.3.0.zip
- 重啟es
測試分詞器
IK分詞器有兩種分詞模式:ik_max_word和ik_smart模式
- ik_max_word:將文字做最細粒度的拆分
- ik_smart:將文字做最粗力度的拆分
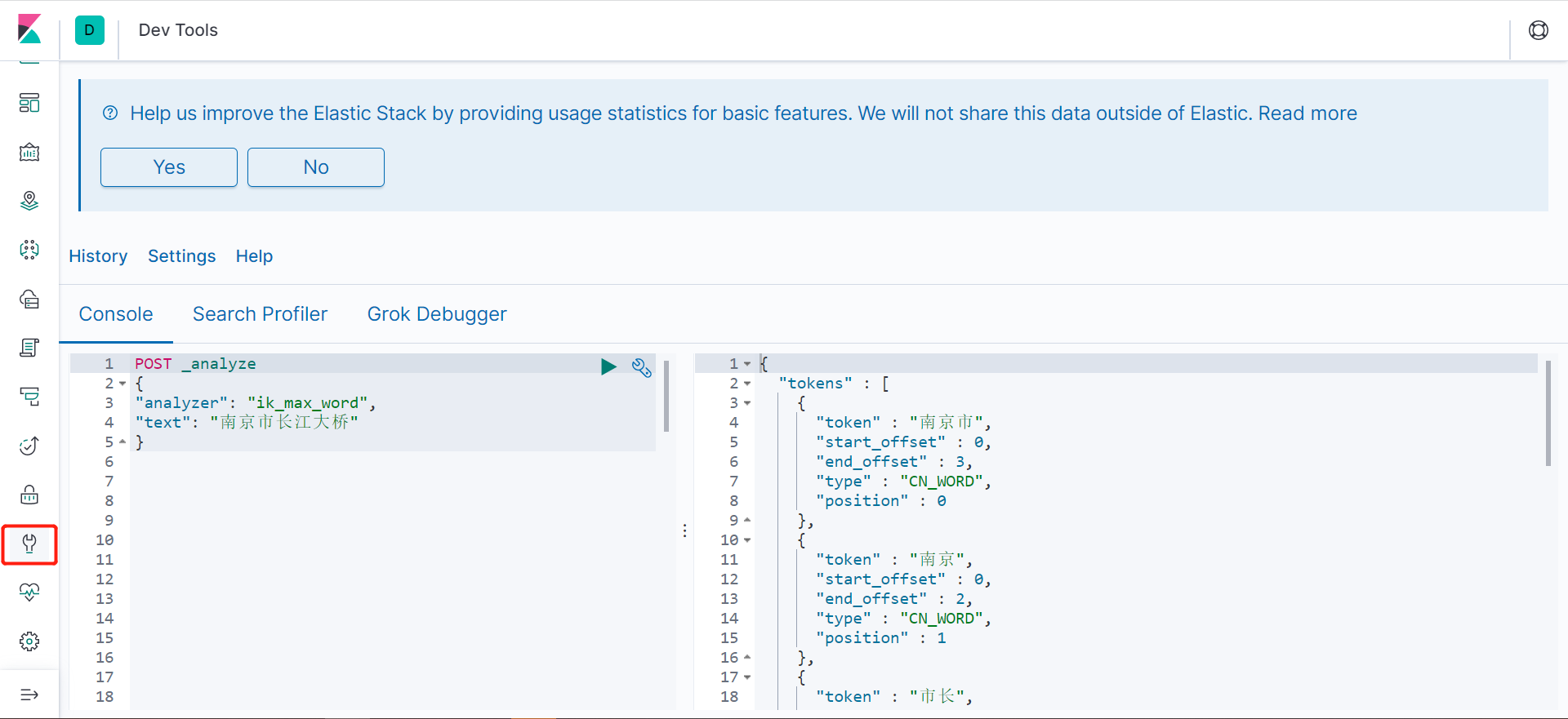
範例:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "南京市長江大橋"
}
得到結果如下:
{
"tokens" : [
{
"token" : "南京市",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "南京",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "市長",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "長江大橋",
"start_offset" : 3,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "長江",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "大橋",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 5
}
]
}
擴充套件詞典
分詞結果沒有我們想要的時候,可以自己擴充套件。如:南京市長江大橋,它的語意是南京市市長叫「江大橋」。
- 進入到 config/analysis-ik/(外掛命令安裝方式)或plugins/analysis-ik/config(安裝包安裝方式) 目錄下, 新增自定義詞典(檔名隨意)
vim my_ext_dict.dic
內容輸入:江大橋
2. 將我們的自定義擴充套件檔案設定上
vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 擴充套件設定</comment>
<!--使用者可以在這裡設定自己的擴充套件字典 -->
<entry key="ext_dict">my_ext_dict.dic</entry>
<!--使用者可以在這裡設定自己的擴充套件停止詞字典-->
<entry key="ext_stopwords"></entry>
<!--使用者可以在這裡設定遠端擴充套件字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--使用者可以在這裡設定遠端擴充套件停止詞字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
- 設定完後重啟es
停用詞設定同理。
同義詞典使用
同一個東西有不同的詞語來表示。我們搜尋的時候期望輸入"土豆",能搜出"洋芋",輸入"西紅柿"能搜出"番茄"等等。
Elasticsearch 自帶一個名為 synonym 的同義詞 filter。為了能讓 IK 和 synonym 同時工作,我們需要定義新的analyzer,用IK做tokenizer,synonym做filter。
- config/analysis-ik目錄下建立synonym.txt檔案,輸入一些同義詞
西紅柿,番茄
- 建立索引時使用同義詞設定
{
"settings":{
"analysis":{
"filter":{
"word_sync":{
"type":"synonym",
"synonyms_path":"analysis-ik/synonym.txt"
}
},
"analyzer":{
"ik_sync_max_word":{
"filter":[
"word_sync"
],
"type":"custom",
"tokenizer":"ik_max_word"
},
"ik_sync_smart":{
"filter":[
"word_sync"
],
"type":"custom",
"tokenizer":"ik_smart"
}
}
}
},
"mappings":{
"properties":{
"欄位名":{
"type":"欄位型別",
"analyzer":"ik_sync_smart",
"search_analyzer":"ik_sync_smart"
}
}
}
}
以上設定定義了ik_sync_max_word和ik_sync_smart這兩個新的analyzer,對應IK的ik_max_word和ik_smart兩種分詞策略。
- 搜尋時指定分詞器ik_sync_max_word或ik_sync_smart即可擁有同義詞功能。
範例如下:
- 建索引
PUT /test-synonym
{
"settings":{
"analysis":{
"filter":{
"word_sync":{
"type":"synonym",
"synonyms_path":"analysis-ik/synonym.txt"
}
},
"analyzer":{
"ik_sync_max_word":{
"filter":[
"word_sync"
],
"type":"custom",
"tokenizer":"ik_max_word"
},
"ik_sync_smart":{
"filter":[
"word_sync"
],
"type":"custom",
"tokenizer":"ik_smart"
}
}
}
},
"mappings":{
"properties":{
"name":{
"type":"text",
"analyzer":"ik_sync_smart",
"search_analyzer":"ik_sync_smart"
}
}
}
}
- 插入資料
POST /test-synonym/_doc/1
{
"name":"我喜歡吃番茄"
}
- 搜尋
POST /test-synonym/_search
{
"query":{
"match":{
"name":"西紅柿"
}
}
}