alertmanager叢集莫名傳送resolve訊息的問題探究
alertmanager叢集莫名傳送resolve訊息的問題探究
術語
- 告警訊息:指一條告警
- 告警恢復訊息:指一條告警恢復
- 告警資訊:指告警相關的內容,包括告警訊息和告警恢復訊息
問題描述
最近遇到了一個alertmanager HA叢集莫名傳送告警恢復訊息的問題。簡單來說就是線上設定了一個一直會產生告警的規則,但卻會收到alertmanager發來的告警恢復訊息,與預期不符。
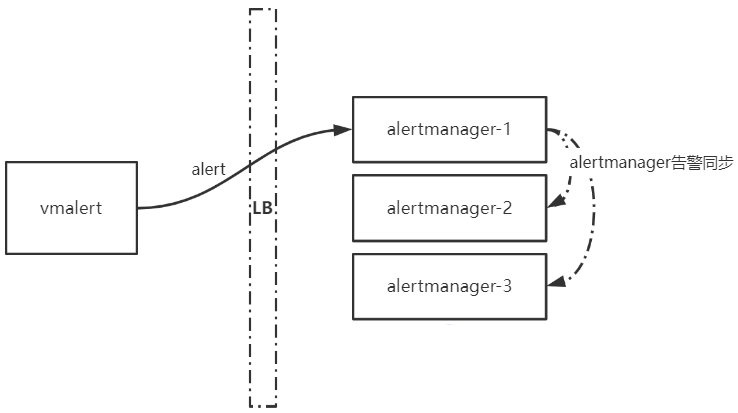
所使用的告警架構如下,vmalert產生的告警會通過LB傳送到某個後端alertmanager範例。原本以為,接收到該告警的alertmanager會將告警資訊同步到其他範例,當vmalert產生下一個相同的告警後,則alertmanager範例中的第二個告警會重新整理第一個告警,後續通過告警同步將最新的告警傳送到各個alertmanager範例,從而達到抑制告警和抑制告警恢復的效果(。
但在實際中發現,alertmanager對一直產生的告警發出了告警恢復訊息。
問題解決
問題解決辦法很簡單:讓告警直接傳送到alertmanager HA叢集的每個範例即可。
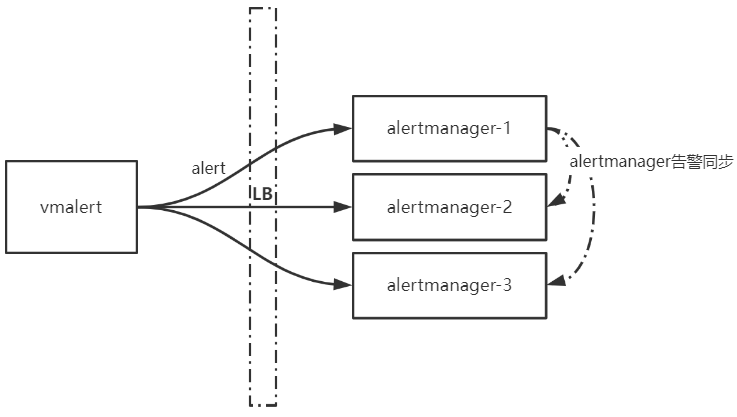
在Question regarding Loadbalanced Alertmanager Clusters和Alerting issues with Alertmanage這兩篇檔案中描述了使用LB導致alertmanager HA叢集發生告警混亂的問題。此外在官方檔案也有如下提示:
It's important not to load balance traffic between Prometheus and its Alertmanagers, but instead, point Prometheus to a list of all Alertmanagers.
但根因是什麼,網上找了很久沒有找到原因。上述檔案描述也摸稜兩可。
問題根因
首先上一張alertmanager官方架構圖:
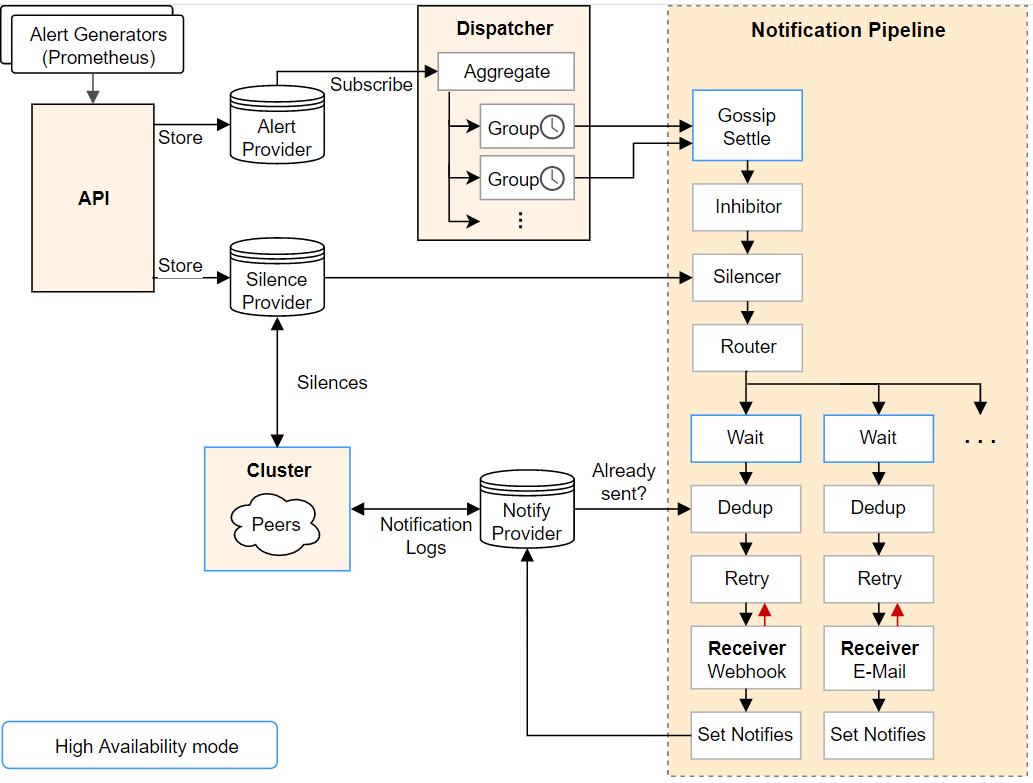
注意到上圖有三類provider:
- Alert Provider:負責處理通過API傳入的告警,vmalert(Prometheus)產生的告警就是在這裡接收處理的
- Silence Provider:負責處理靜默規則,本次不涉及告警靜默,因此不作討論。
- Notify Provider:負責範例間傳送告警資訊。
根據如上分析,可以得出,一個alertmanager範例有兩種途徑獲得告警資訊,一種是由外部服務(如vmalert、Prometheus等)通過API傳入的,另一種是通過alertmanager 範例間的Notification Logs訊息獲得的。
注:需要說明的是,alertmanager判定一個告警是不是恢復狀態,主要是通過該告警的
EndsAt欄位,如果EndsAt時間點早於當前時間,說明該告警已經失效,需要傳送告警恢復,判斷程式碼如下:// Resolved returns true iff the activity interval ended in the past. func (a *Alert) Resolved() bool { return a.ResolvedAt(time.Now()) } // ResolvedAt returns true off the activity interval ended before // the given timestamp. func (a *Alert) ResolvedAt(ts time.Time) bool { if a.EndsAt.IsZero() { return false } return !a.EndsAt.After(ts) }
API Provider的處理
alertmanager提供了兩套API:v1和v2。但兩個API內部處理還是一樣的邏輯,以v1 API為例,
入口函數為insertAlerts,該函數主要負責告警的有效性校驗,處理告警的StartAt和EndAt,最後通過Put方法將告警儲存起來。
本案例場景中,vmalert會給所有告警加上
EndAt,值為:當前時間 + 4倍的groupInterval(預設1min) = 4min。
func (api *API) insertAlerts(w http.ResponseWriter, r *http.Request, alerts ...*types.Alert) {
now := time.Now()
api.mtx.RLock()
resolveTimeout := time.Duration(api.config.Global.ResolveTimeout)
api.mtx.RUnlock()
for _, alert := range alerts {
alert.UpdatedAt = now
// Ensure StartsAt is set.
if alert.StartsAt.IsZero() {
if alert.EndsAt.IsZero() {
alert.StartsAt = now
} else {
alert.StartsAt = alert.EndsAt
}
}
// If no end time is defined, set a timeout after which an alert
// is marked resolved if it is not updated.
if alert.EndsAt.IsZero() {
alert.Timeout = true
alert.EndsAt = now.Add(resolveTimeout)
}
if alert.EndsAt.After(time.Now()) {
api.m.Firing().Inc()
} else {
api.m.Resolved().Inc()
}
}
// Make a best effort to insert all alerts that are valid.
var (
validAlerts = make([]*types.Alert, 0, len(alerts))
validationErrs = &types.MultiError{}
)
for _, a := range alerts {
removeEmptyLabels(a.Labels)
if err := a.Validate(); err != nil {
validationErrs.Add(err)
api.m.Invalid().Inc()
continue
}
validAlerts = append(validAlerts, a)
}
if err := api.alerts.Put(validAlerts...); err != nil {
api.respondError(w, apiError{
typ: errorInternal,
err: err,
}, nil)
return
}
if validationErrs.Len() > 0 {
api.respondError(w, apiError{
typ: errorBadData,
err: validationErrs,
}, nil)
return
}
api.respond(w, nil)
}
Put函數中會對相同指紋的告警進行Merge,這一步會重新整理儲存的對應告警的StartAt和EndAt,通過這種方式可以保證告警的StartAt和EndAt可以隨最新接收到的告警訊息而更新。
func (a *Alerts) Put(alerts ...*types.Alert) error {
for _, alert := range alerts {
fp := alert.Fingerprint()
existing := false
// Check that there's an alert existing within the store before
// trying to merge.
if old, err := a.alerts.Get(fp); err == nil {
existing = true
// Merge alerts if there is an overlap in activity range.
// 更新告警的StartAt和EndAt欄位
if (alert.EndsAt.After(old.StartsAt) && alert.EndsAt.Before(old.EndsAt)) ||
(alert.StartsAt.After(old.StartsAt) && alert.StartsAt.Before(old.EndsAt)) {
alert = old.Merge(alert)
}
}
if err := a.callback.PreStore(alert, existing); err != nil {
level.Error(a.logger).Log("msg", "pre-store callback returned error on set alert", "err", err)
continue
}
if err := a.alerts.Set(alert); err != nil {
level.Error(a.logger).Log("msg", "error on set alert", "err", err)
continue
}
a.callback.PostStore(alert, existing)
// 將告警分發給訂閱者
a.mtx.Lock()
for _, l := range a.listeners {
select {
case l.alerts <- alert:
case <-l.done:
}
}
a.mtx.Unlock()
}
return nil
}
根據上述分析可以得出,當通過API獲取到相同(指紋)的告警時,會更新本範例對應的告警資訊(StartAt和EndAt),因此如果通過API不停向一個alertmanager範例傳送告警,則該範例並不會產生告警恢復訊息。
下一步就是要確定,通過API接收到的告警資訊是如何傳送給其他範例的,以及傳送的是哪些資訊。
從官方架構圖上可以看出,API接收到的告警會進入Dispatcher,然後進入Notification Pipeline,最後通過Notification Provider將告警資訊傳送給其他範例。
Dispatcher的處理
在上面Put函數的最後,會將Merge後的告警傳送給a.listeners,每個listener對應一個告警訂閱者,Dispatcher算是一個告警訂閱者。
要獲取從API 收到的告警,首先要進行訂閱。訂閱函數如下,其實就是在listeners新增了一個channel,該channel中會預先填充已有的告警,當通過API接收到新告警後,會使用Put()方法將新的告警分發給各個訂閱者。
// Subscribe returns an iterator over active alerts that have not been
// resolved and successfully notified about.
// They are not guaranteed to be in chronological order.
func (a *Alerts) Subscribe() provider.AlertIterator {
a.mtx.Lock()
defer a.mtx.Unlock()
var (
done = make(chan struct{})
alerts = a.alerts.List()
ch = make(chan *types.Alert, max(len(alerts), alertChannelLength))
)
for _, a := range alerts {
ch <- a
}
a.listeners[a.next] = listeningAlerts{alerts: ch, done: done}
a.next++
return provider.NewAlertIterator(ch, done, nil)
}
alertmanager的main()函數中會初始化並啟動一個Dispatcher:
// Run starts dispatching alerts incoming via the updates channel.
func (d *Dispatcher) Run() {
d.done = make(chan struct{})
d.mtx.Lock()
d.aggrGroupsPerRoute = map[*Route]map[model.Fingerprint]*aggrGroup{}
d.aggrGroupsNum = 0
d.metrics.aggrGroups.Set(0)
d.ctx, d.cancel = context.WithCancel(context.Background())
d.mtx.Unlock()
d.run(d.alerts.Subscribe())
close(d.done)
}
Dispatcher啟動之後會訂閱告警訊息:
// Run starts dispatching alerts incoming via the updates channel.
func (d *Dispatcher) Run() {
...
// 訂閱告警訊息
d.run(d.alerts.Subscribe())
close(d.done)
}
下面是Dispatcher的主函數,負責接收訂閱的channel中傳過來的告警,並根據路由(route)處理告警訊息(processAlert)。
func (d *Dispatcher) run(it provider.AlertIterator) {
cleanup := time.NewTicker(30 * time.Second)
defer cleanup.Stop()
defer it.Close()
for {
select {
// 處理訂閱的告警訊息
case alert, ok := <-it.Next():
if !ok {
// Iterator exhausted for some reason.
if err := it.Err(); err != nil {
level.Error(d.logger).Log("msg", "Error on alert update", "err", err)
}
return
}
level.Debug(d.logger).Log("msg", "Received alert", "alert", alert)
// Log errors but keep trying.
if err := it.Err(); err != nil {
level.Error(d.logger).Log("msg", "Error on alert update", "err", err)
continue
}
now := time.Now()
for _, r := range d.route.Match(alert.Labels) {
d.processAlert(alert, r)
}
d.metrics.processingDuration.Observe(time.Since(now).Seconds())
case <-cleanup.C:
d.mtx.Lock()
for _, groups := range d.aggrGroupsPerRoute {
for _, ag := range groups {
if ag.empty() {
ag.stop()
delete(groups, ag.fingerprint())
d.aggrGroupsNum--
d.metrics.aggrGroups.Dec()
}
}
}
d.mtx.Unlock()
case <-d.ctx.Done():
return
}
}
}
processAlert主要是做聚合分組的,ag.run函數會填充相關的告警資訊,並根據GroupWait和GroupInterval傳送本範例非恢復的告警。
從alertmanager的架構圖中可以看到,在Dispatcher聚合分組告警之後,會將告警送到Notification Pipeline進行處理,Notification Pipeline的處理對應ag.run的入參回撥函數。該回撥函數中會呼叫stage.Exec來處理Notification Pipeline的各個階段。
// processAlert determines in which aggregation group the alert falls
// and inserts it.
func (d *Dispatcher) processAlert(alert *types.Alert, route *Route) {
groupLabels := getGroupLabels(alert, route)
fp := groupLabels.Fingerprint()
d.mtx.Lock()
defer d.mtx.Unlock()
routeGroups, ok := d.aggrGroupsPerRoute[route]
if !ok {
routeGroups = map[model.Fingerprint]*aggrGroup{}
d.aggrGroupsPerRoute[route] = routeGroups
}
ag, ok := routeGroups[fp]
if ok {
ag.insert(alert)
return
}
// If the group does not exist, create it. But check the limit first.
if limit := d.limits.MaxNumberOfAggregationGroups(); limit > 0 && d.aggrGroupsNum >= limit {
d.metrics.aggrGroupLimitReached.Inc()
level.Error(d.logger).Log("msg", "Too many aggregation groups, cannot create new group for alert", "groups", d.aggrGroupsNum, "limit", limit, "alert", alert.Name())
return
}
ag = newAggrGroup(d.ctx, groupLabels, route, d.timeout, d.logger)
routeGroups[fp] = ag
d.aggrGroupsNum++
d.metrics.aggrGroups.Inc()
// Insert the 1st alert in the group before starting the group's run()
// function, to make sure that when the run() will be executed the 1st
// alert is already there.
ag.insert(alert)
// 處理pipeline並行送告警
go ag.run(func(ctx context.Context, alerts ...*types.Alert) bool {
_, _, err := d.stage.Exec(ctx, d.logger, alerts...)
if err != nil {
lvl := level.Error(d.logger)
if ctx.Err() == context.Canceled {
// It is expected for the context to be canceled on
// configuration reload or shutdown. In this case, the
// message should only be logged at the debug level.
lvl = level.Debug(d.logger)
}
lvl.Log("msg", "Notify for alerts failed", "num_alerts", len(alerts), "err", err)
}
return err == nil
})
}
Pipeline的處理
在告警傳送之前需要經過一系列的處理,這些處理稱為Pipeline,由不同的Stage構成。
alertmanager的main()函數會初始化一個PipelineBuilder,PipelineBuilder實現了Stage介面。
// A Stage processes alerts under the constraints of the given context.
type Stage interface {
Exec(ctx context.Context, l log.Logger, alerts ...*types.Alert) (context.Context, []*types.Alert, error)
}
Stage翻譯過來就是"階段",對應Pipeline中的各個階段,如GossipSettle、Wait、Dedup等。
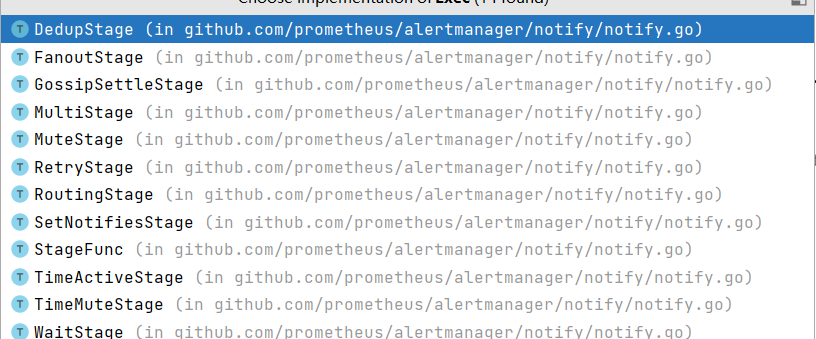
下面兩個函數定義瞭如何初始化PipelineBuilder的各個Stage。
func (pb *PipelineBuilder) New(
receivers map[string][]Integration,
wait func() time.Duration,
inhibitor *inhibit.Inhibitor,
silencer *silence.Silencer,
times map[string][]timeinterval.TimeInterval,
notificationLog NotificationLog,
peer Peer,
) RoutingStage {
rs := make(RoutingStage, len(receivers))
ms := NewGossipSettleStage(peer)
is := NewMuteStage(inhibitor)
tas := NewTimeActiveStage(times)
tms := NewTimeMuteStage(times)
ss := NewMuteStage(silencer)
for name := range receivers {
st := createReceiverStage(name, receivers[name], wait, notificationLog, pb.metrics)
rs[name] = MultiStage{ms, is, tas, tms, ss, st}
}
return rs
}
// createReceiverStage creates a pipeline of stages for a receiver.
func createReceiverStage(
name string,
integrations []Integration,
wait func() time.Duration,
notificationLog NotificationLog,
metrics *Metrics,
) Stage {
var fs FanoutStage
for i := range integrations {
recv := &nflogpb.Receiver{
GroupName: name,
Integration: integrations[i].Name(),
Idx: uint32(integrations[i].Index()),
}
var s MultiStage
s = append(s, NewWaitStage(wait))
s = append(s, NewDedupStage(&integrations[i], notificationLog, recv))
s = append(s, NewRetryStage(integrations[i], name, metrics))
s = append(s, NewSetNotifiesStage(notificationLog, recv))
fs = append(fs, s)
}
return fs
}
根據alertmanager的架構圖,其中最重要的Stage為::WaitStage、DedupStage、RetryStage、SetNotifiesStage,即createReceiverStage函數中建立的幾個Stage。
之前有講過,processAlert函數會呼叫各個Stage的Exec()方法來處理告警,處理的告警內容為本範例中非恢復狀態的告警。
WaitStage
顧名思義,WaitStage表示向其他範例傳送Notification Log的時間間隔,只是單純的時間等待。
// Exec implements the Stage interface.
func (ws *WaitStage) Exec(ctx context.Context, _ log.Logger, alerts ...*types.Alert) (context.Context, []*types.Alert, error) {
select {
case <-time.After(ws.wait()):
case <-ctx.Done():
return ctx, nil, ctx.Err()
}
return ctx, alerts, nil
}
各個範例傳送Notification Log的時長並不一樣,它與p.Position()的返回值有關,timeout預設是15s。
// clusterWait returns a function that inspects the current peer state and returns
// a duration of one base timeout for each peer with a higher ID than ourselves.
func clusterWait(p *cluster.Peer, timeout time.Duration) func() time.Duration {
return func() time.Duration {
return time.Duration(p.Position()) * timeout
}
}
DedupStage和RetryStage
DedupStage目的就是根據告警的雜湊值來判斷本範例的告警是否已經被傳送,如果已經被傳送,則本範例不再繼續傳送。雜湊演演算法如下,主要是對告警的標籤進行雜湊,後面再詳細講解該階段。
func hashAlert(a *types.Alert) uint64 {
const sep = '\xff'
hb := hashBuffers.Get().(*hashBuffer)
defer hashBuffers.Put(hb)
b := hb.buf[:0]
names := make(model.LabelNames, 0, len(a.Labels))
for ln := range a.Labels {
names = append(names, ln)
}
sort.Sort(names)
for _, ln := range names {
b = append(b, string(ln)...)
b = append(b, sep)
b = append(b, string(a.Labels[ln])...)
b = append(b, sep)
}
hash := xxhash.Sum64(b)
return hash
}
RetryStage的目的是將告警資訊傳送給各個使用者設定的告警通道,如webhook、Email、wechat、slack等,如果設定了send_resolved: true,則還會傳送告警恢復訊息,並支援在連線異常的情況下使用指數退避的方式下進行重傳。
SetNotifiesStage
該階段就是使用Notification Log向其他節點傳送告警通知的過程。這也是我們比較疑惑的階段,既然同步了告警訊息,為什麼仍然會產生告警恢復?
下面是SetNotifiesStage的處理常式:
func (n SetNotifiesStage) Exec(ctx context.Context, l log.Logger, alerts ...*types.Alert) (context.Context, []*types.Alert, error) {
gkey, ok := GroupKey(ctx)
if !ok {
return ctx, nil, errors.New("group key missing")
}
firing, ok := FiringAlerts(ctx)
if !ok {
return ctx, nil, errors.New("firing alerts missing")
}
resolved, ok := ResolvedAlerts(ctx)
if !ok {
return ctx, nil, errors.New("resolved alerts missing")
}
// 通知其他範例
return ctx, alerts, n.nflog.Log(n.recv, gkey, firing, resolved)
}
首先通過FiringAlerts獲取告警訊息,通過ResolvedAlerts獲取告警恢復訊息,然後通過n.nflog.Log將這些訊息傳送給其他範例。可以看到FiringAlerts和ResolvedAlerts獲取到的是[]uint64型別的資料,這些資料實際內容是什麼?
func FiringAlerts(ctx context.Context) ([]uint64, bool) {
v, ok := ctx.Value(keyFiringAlerts).([]uint64)
return v, ok
}
func ResolvedAlerts(ctx context.Context) ([]uint64, bool) {
v, ok := ctx.Value(keyResolvedAlerts).([]uint64)
return v, ok
}
答案是,SetNotifiesStage中用到的FiringAlerts和ResolvedAlerts是在DedupStage階段生成的,因此SetNotifiesStage階段傳送給其他範例的資訊實際是告警的雜湊值!
DedupStage處理如下:
func (n *DedupStage) Exec(ctx context.Context, _ log.Logger, alerts ...*types.Alert) (context.Context, []*types.Alert, error) {
...
firingSet := map[uint64]struct{}{}
resolvedSet := map[uint64]struct{}{}
firing := []uint64{}
resolved := []uint64{}
var hash uint64
for _, a := range alerts {
hash = n.hash(a)
if a.Resolved() {
resolved = append(resolved, hash)
resolvedSet[hash] = struct{}{}
} else {
firing = append(firing, hash)
firingSet[hash] = struct{}{}
}
}
//生成SetNotifiesStage使用的 FiringAlerts
ctx = WithFiringAlerts(ctx, firing)
//生成SetNotifiesStage使用的 ResolvedAlerts
ctx = WithResolvedAlerts(ctx, resolved)
entries, err := n.nflog.Query(nflog.QGroupKey(gkey), nflog.QReceiver(n.recv))
if err != nil && err != nflog.ErrNotFound {
return ctx, nil, err
}
var entry *nflogpb.Entry
switch len(entries) {
case 0:
case 1:
entry = entries[0]
default:
return ctx, nil, errors.Errorf("unexpected entry result size %d", len(entries))
}
if n.needsUpdate(entry, firingSet, resolvedSet, repeatInterval) {
return ctx, alerts, nil
}
return ctx, nil, nil
}
在DedupStage階段中會使用n.nflog.Query來接收其他範例SetNotifiesStage傳送的資訊,其返回的entries型別如下,從註釋中可以看到FiringAlerts和ResolvedAlerts就是兩個告警訊息雜湊陣列:
type Entry struct {
// The key identifying the dispatching group.
GroupKey []byte `protobuf:"bytes,1,opt,name=group_key,json=groupKey,proto3" json:"group_key,omitempty"`
// The receiver that was notified.
Receiver *Receiver `protobuf:"bytes,2,opt,name=receiver,proto3" json:"receiver,omitempty"`
// Hash over the state of the group at notification time.
// Deprecated in favor of FiringAlerts field, but kept for compatibility.
GroupHash []byte `protobuf:"bytes,3,opt,name=group_hash,json=groupHash,proto3" json:"group_hash,omitempty"`
// Whether the notification was about a resolved alert.
// Deprecated in favor of ResolvedAlerts field, but kept for compatibility.
Resolved bool `protobuf:"varint,4,opt,name=resolved,proto3" json:"resolved,omitempty"`
// Timestamp of the succeeding notification.
Timestamp time.Time `protobuf:"bytes,5,opt,name=timestamp,proto3,stdtime" json:"timestamp"`
// FiringAlerts list of hashes of firing alerts at the last notification time.
FiringAlerts []uint64 `protobuf:"varint,6,rep,packed,name=firing_alerts,json=firingAlerts,proto3" json:"firing_alerts,omitempty"`
// ResolvedAlerts list of hashes of resolved alerts at the last notification time.
ResolvedAlerts []uint64 `protobuf:"varint,7,rep,packed,name=resolved_alerts,json=resolvedAlerts,proto3" json:"resolved_alerts,omitempty"`
XXX_NoUnkeyedLiteral struct{} `json:"-"`
XXX_unrecognized []byte `json:"-"`
XXX_sizecache int32 `json:"-"`
}
DedupStage階段會使用和SetNotifiesStage階段相同的雜湊演演算法來計算本範例的告警的雜湊值,然後與接收到的其他範例傳送的告警雜湊值進行對比,如果needsUpdate返回true,則會繼續傳送告警,如果返回false,則可以認為這部分告警已經被其他範例傳送,本範例不再傳送。
needsUpdate的函數如下,入參entry為接收到的其他範例傳送的告警雜湊值,firing和resolved為本範例所擁有的告警雜湊值,可以看到,如果要讓本地不傳送告警恢復,則滿足如下條件之一即可:
- 本範例的
firing雜湊是entry.FiringAlerts的子集,即本範例的所有告警都已經被傳送過 - 不啟用傳送告警恢復功能或本範例的
resolved雜湊是entry.ResolvedAlerts的子集(即本範例的所有告警恢復都已經被傳送過)
也就是說,如果本範例的告警雜湊與接收到的告警雜湊存在交叉或完全不相同的情況時,則不會對告警訊息和告警恢復訊息產生抑制效果。
同時從上面也得出:
alertmanager HA範例之間並不會同步具體的告警訊息,它們只傳遞了告警的雜湊值,且僅僅用於抑制告警和告警恢復。
func (n *DedupStage) needsUpdate(entry *nflogpb.Entry, firing, resolved map[uint64]struct{}, repeat time.Duration) bool {
// If we haven't notified about the alert group before, notify right away
// unless we only have resolved alerts.
if entry == nil {
return len(firing) > 0
}
if !entry.IsFiringSubset(firing) {
return true
}
// Notify about all alerts being resolved.
// This is done irrespective of the send_resolved flag to make sure that
// the firing alerts are cleared from the notification log.
if len(firing) == 0 {
// If the current alert group and last notification contain no firing
// alert, it means that some alerts have been fired and resolved during the
// last interval. In this case, there is no need to notify the receiver
// since it doesn't know about them.
return len(entry.FiringAlerts) > 0
}
if n.rs.SendResolved() && !entry.IsResolvedSubset(resolved) {
return true
}
// Nothing changed, only notify if the repeat interval has passed.
return entry.Timestamp.Before(n.now().Add(-repeat))
}
總結
至此,問題的根因也就清楚了。
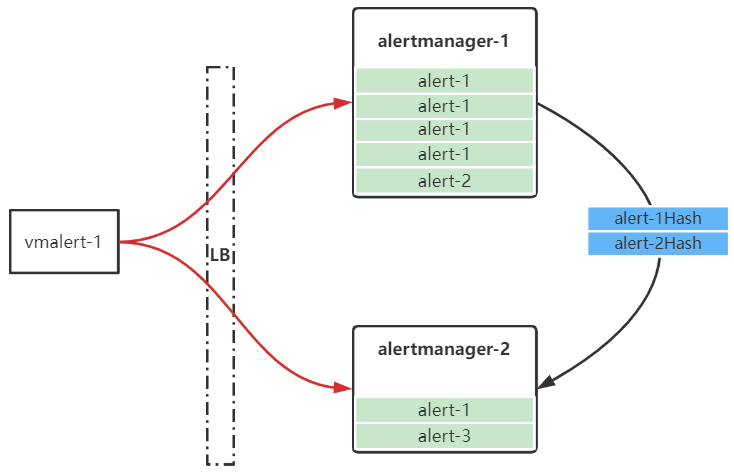
假設如下場景,alertmanager-1此時有2條firing的告警alert-1和alert-2,alertmanager-2有2條firing的告警alert-1和alert-3,由於使用了LB,導致傳送到alertmanager-2的alert-1告警數目遠少於alertmanager-1,且alertmanager-2的alert-1由於EndAt時間過老,即將產生告警恢復。而這種情況下alertmanager-2的firing告警雜湊並不是alertmanager-1傳送過來的告警雜湊的子集,因此並不會產生抑制效果,之後便會導致alertmanager-2產生alert-1的告警恢復。
因此官方要求上游的告警必須能夠傳送到所有的alertmanager範例上。
alertmanager為何只傳送告警的雜湊值?為何要全匹配子集才認為能抑制?我猜一方面是為了減少頻寬以及增加處理效率,所以才僅僅傳遞雜湊值,而全匹配子集的原因是為了降低雜湊衝突。
本文來自部落格園,作者:charlieroro,轉載請註明原文連結:https://www.cnblogs.com/charlieroro/p/16386375.html