微服務的故障處理
當微服務發生故障後怎麼辦?最近線上發生一起故障,一個介面的慢查詢拖垮了整個應用,導致整個應用變得不可用。如果正好趕上流量高峰,應用重啟都變得很困難,除非把入口整個關閉,再重啟應用等待應用的恢復。
在覆盤時,結論是增加上線稽核流程和控制來試圖阻止故障的再次發生,很少花費心思想想如何更加容易地在第一時間從故障中恢復過來。
在這次故障中我也做了一些思考,如果當時是我處理這起故障,我能做什麼?本文因此而起,一部分來自於之前公司所做的穩定性建設方面的經驗,一部分來源於《微服務設計》中所寫的經驗。分成技術實現前的思考和技術方面可以做的事情。
一 技術實現前的思考
思考一、假定故障會發生,如何去優雅地處理它。
假設一切都會失敗,會讓你從不同的角度去思考如何解決問題。我們可以在試圖阻止不可避免的故障上少花一點時間,而花更多時間去優雅地處理它。假定故障會發生,如果以這種想法來處理你做的每一件事情,為其故障做好準備,那麼就會做出不同的權衡。
瞭解你可以容忍多少故障,或者系統需要多快,瞭解系統的使用者的負載能力。
思考二、系統的強弱依賴梳理
梳理系統下游介面強弱程度,哪些介面是強依賴,哪一些是弱依賴。強依賴一般指此服務有問題,流程會卡住,直接影響功能,否則為弱依賴。要有強弱依賴梳理工具,能夠查詢介面的呼叫鏈,根據業務場景去判斷哪些介面是強依賴、哪些是弱依賴
強弱依賴介面治理:先去除沒有必要、不合理的依賴;不影響核心業務的依賴全部變為弱依賴 ;弱依賴:增設降級開關,緊急情況直接降級處理;設定限流 ;強依賴:能加快取的加快取;加預案開關 ,可快速止血。
思考三、哪些功能業務上可以降級
構建一個彈性系統,尤其是當功能分散在多個不同的、有可能宕掉的微服務上時,重要的是能夠安全地降級功能。我們需要做的是理解每個故障的影響,並弄清楚如何恰當地降級功能。如果購物車服務不可用,我們可能會有很多麻煩,但仍然可以顯示列表清單頁面。也許可以僅僅隱藏掉購物車,將其替換成一個新的圖示「馬上回來!」。如果下單依賴的紅包服務不可用,降級後用戶還可以正常的下單。對於每個使用多個微服務的面向使用者的介面,或每個依賴多個下游合作者的微服務來說,你都需要問自己:「如果這個微服務宕掉會發生什麼?」然後你就知道該做什麼了。通過思考每項跨功能需求的重要性,我們對自己能做什麼有了更好的定位。現在,讓我們考慮從技術方面可以做的事情,以確保當故障發生時可以優雅地處理。
二 技術方面可以做的事情
在分散式架構下,準備好如何應對各種故障的發生是非常重要的。那麼我們需要做什麼來應對系統故障呢?
1.超時設定
超時是很容易被忽視的事情,但在使用下游系統時,正確地處理它是很重要的。在考慮下游系統確實已經宕掉之前,我需要等待多長時間?如果等待太長時間來決定呼叫失敗,整個系統會被拖慢。如果超時太短,你會將一個可能還在正常工作的呼叫錯認為是失敗的。如果完全沒有超,一個宕掉的下游系統可能會讓整個系統掛起。給所有的跨程序呼叫設定超時,並選擇一個預設的超時時間。當超時發生後,記錄到紀錄檔裡看看發生了什麼,並相應地調整它們。
2.斷路器
即使我們正確地設定超時,也需要等待很長時間才能得到錯誤。接著我們等下次請求進來時將再次嘗試,同樣等待。如果下游服務發生故障會拖慢我們的整個系統。
使用斷路器時,當對下游資源的請求發生一定數量的失敗後,斷路器會開啟。接下來,所有的請求在斷路器開啟的狀態下,會快速地失敗。一段時間後,使用者端傳送一些請求檢視下游服務是否已經恢復,如果它得到了正常的響應,將重置斷路器。
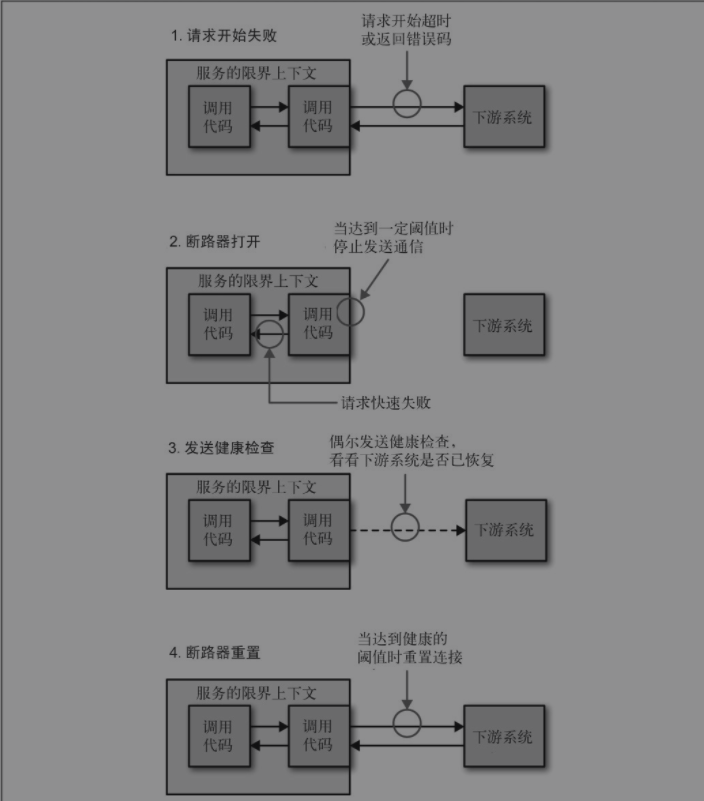
斷路器概述(圖片來自於《微服務設計》)
如何實現斷路器依賴於請求失敗的定義,但當使用HTTP連線實現它們時,我會把超時或5XX的HTTP返回碼作為失敗的請求。通過這種方式,當一個下游資源宕掉,或超時,或返回錯誤碼時,達到一定閾值後,我們會自動停止向它傳送通訊,並啟動快速失敗。當它恢復健康後,我們會自動重新傳送請求。
正確地設定斷路器會有點棘手。你不想太輕易地啟動斷路器,也不想花太多時間來啟動。同樣,你要確保在下游服務真正恢復健康後才傳送通訊。跟超時一樣,我會選取一些合理的預設值並在各處使用,然後在特定的情況下調整它們。
當斷路器斷開後,你有一些選項。其中之一是堆積請求,然後稍後重試它們。對於一些場景,這可能是合適的,特別是你所做的工作是非同步作業的一部分時。然而,如果這個呼叫作為同步呼叫鏈的一部分,快速失敗可能更合適。這意味著,沿呼叫鏈向上傳播錯誤,或者降級功能。
如果我們有這種機制(如家裡的斷路器),就可以手動使用它們,以使所做的工作更加安全。例如,如果作為日常維護的一部分,我們想要停用一個微服務,可以手動啟動依賴它的所有系統的斷路器,使它們在這個微服務失效的情況下快速失敗。一旦微服務恢復,我們可以重置斷路器,讓一切都恢復正常。這裡的機制在電商中會經常被使用,即使用開關來降級所依賴的功能。例如大促期間關閉一些功能來應對流量的洪峰。
3.艙壁模式
艙壁(bulkhead),是把自己從故障中隔離開的一種方式。在航運領域,艙壁是船的一部分,合上艙口後可以保護船的其他部分。所以如果船板穿透之後,你可以關閉艙壁門。如果失去了船的一部分,但其餘的部分仍完好無失真。
在軟體架構術語中,有很多不同的艙壁可供我們考慮。
(1)為每個下游服務的連線使用不同的連線池
我們應該為每個下游服務的連線使用不同的連線池。這樣的話,如果一個連線池被用盡,其餘連線並不受影響。這可以確保,如果下游服務將來執行緩慢,只有那一個連線池會受影響,其他呼叫仍可以正常進行。
(2) 應用的拆分
關注點分離也是實現艙壁的一種方式。通過把功能分離成獨立的微服務應用,減少了因為一個功能的宕機而影響另一個的可能性。這裡拆分我們可以按功能拆分,也可以按應用的是否核心來拆分核心應用和非核心應用。
(3) 使用斷路器
我們可以把斷路器看作一種密封一個艙壁的自動機制,它不僅保護消費者免受下游服務問題的影響,同時也使下游服務避免更多的呼叫,以防止可能產生的不利影響。鑑於級聯故障的危險,我建議對所有同步的下游呼叫都使用斷路器。當然,不需要重新創造你自己的斷路器。Netflix的Hystrix庫(https://github.com/Netflix/Hystrix)是一個基於JVM的斷路器,附帶強大的監控。
在很多方面,艙壁是三個模式裡最重要的。超時和斷路器能夠幫助你在資源受限時釋放它們,但艙壁可以在第一時間確保它們不成為限制。例如,Hystrix允許你在一定條件下,實現拒絕請求的艙壁,以避免資源達到飽和,這被稱為減載(load shedding)。有時拒絕請求是避免重要系統變得不堪重負或成為多個上游服務瓶頸的最佳方法。
4.隔離
一個服務越依賴於另一個,另一個服務的健康將越能影響其正常工作的能力。如果我們使用的整合技術允許下游伺服器離線,上游服務便不太可能受到計劃內或計劃外宕機的影響。
服務間加強隔離還有另一個好處。當服務間彼此隔離時,服務的擁有者之間需要更少的協調。團隊間的協調越少,這些團隊就更自治,這樣他們可以更自由地管理和演化服務。
這些都是發生故障前技術上需要準備好的事情。如果發生故障前什麼也沒有做,似乎只有重啟應用,祈禱下游介面趕緊恢復這條路了,如果趕上流量高峰,恐怕連入口也需要關閉,應用才能起得來。所以架構性安全措施需要提前去做,它們可以確保如果事情真的出錯了,不會引起嚴重的級聯影響。在系統中把它們標準化,以確保不會因為一個服務的問題導致整個系統的崩塌。