JVM 輸出 GC 紀錄檔導致 JVM 卡住,我 TM 人傻了

本系列是 我TM人傻了 系列第七期[捂臉],往期精彩回顧:
- 升級到Spring 5.3.x之後,GC次數急劇增加,我TM人傻了:https://zhuanlan.zhihu.com/p/397042565
- 這個大表走索引欄位查詢的 SQL 怎麼就成全掃描了,我TM人傻了:https://zhuanlan.zhihu.com/p/397271448
- 獲取異常資訊裡再出異常就找不到紀錄檔了,我TM人傻了:https://zhuanlan.zhihu.com/p/398521426
- spring-data-redis 連線洩漏,我 TM 人傻了:https://zhuanlan.zhihu.com/p/404912877
- Spring Cloud Gateway 沒有鏈路資訊,我 TM 人傻了:https://zhuanlan.zhihu.com/p/413589417
- Spring Cloud Gateway 雪崩了,我 TM 人傻了:https://zhuanlan.zhihu.com/p/414705493
最近,我們升級了 Java 17。後來,我們的 k8s 運維團隊為了優化我們的應用紀錄檔採集,將我們所有 pod (你可以理解為一個 Java 微服務程序)的 JVM 紀錄檔都統一採集到同一個 AWS 的 EFS 服務(EFS 是 Elastic File System 的縮寫,彈性塊檔案儲存系統,底層是 NFS + S3 物件儲存叢集),我們對於 JVM 紀錄檔設定包括以下幾個:
- GC紀錄檔:-Xlog:gc*=debug:file=${LOG_PATH}/gc%t.log:utctime,level,tags:filecount=50,filesize=100M
- JIT 編譯紀錄檔:-Xlog:jit+compilation=info:file=${LOG_PATH}/jit_compile%t.log:utctime,level,tags:filecount=10,filesize=10M
- Safepoint 紀錄檔:-Xlog:safepoint=trace:file=${LOG_PATH}/safepoint%t.log:utctime,level,tags:filecount=10,filesize=10M
- 關閉堆疊省略:這個只會省略 JDK 內部的異常,比如 NullPointerException 這種的:-XX:-OmitStackTraceInFastThrow,我們應用已經對於大量報錯的時候輸出大量堆疊導致效能壓力的優化,參考:https://zhuanlan.zhihu.com/p/428375711
JVM 統一紀錄檔設定請參考:https://zhuanlan.zhihu.com/p/111886882
在這樣做之後,我們的應用出現這樣一個奇怪的問題,這個問題有三種不同的現象,統一的表現是處於安全點的時間特別特別長:
1.通過 safepoint 紀錄檔看出來,等待所有執行緒進入安全點的時間特別長(Reaching safepoint:25s多)
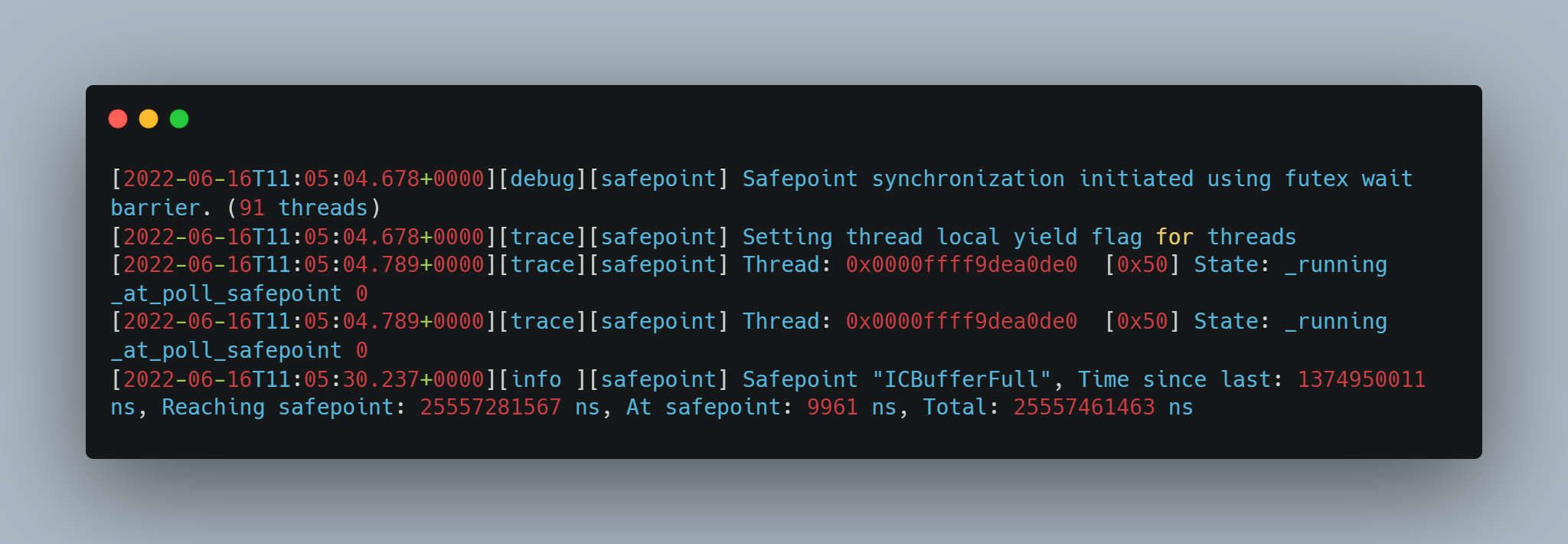
2.通過 safepoint 紀錄檔看出來,還有處於 safepoint 時間過長的,並且原因是 GC(At safepoint: 37s多)
qsbk2rstfly.png)
檢視 GC 紀錄檔,Heap before GC invocations 與輸出堆結構的紀錄檔間隔了很久:
q053wbrp3bw.png)
3.另一種處於 safepoint 時間過長的,原因也是 GC,但是間隔紀錄檔的地方不一樣(29s多)
檢視 GC 紀錄檔,輸出堆結構的紀錄檔某些間隔了很久:
0d1ujx0g1pm.png)
問題定位
首先,Java 應用執行緒整體處於 safepoint,這時候應用執行緒什麼都做不了,所以依賴應用執行緒的監控即通過 JVM 外部監控,例如 spring actuator 暴露的 prometheus 介面,以及 Skywalking 插樁監控,是什麼都看不到的,只會看到出於安全點時呼叫的這些方法時間特別長,但是並不是這些方法真的有瓶。
需要通過 JVM 內部執行緒的監控機制,例如 JVM 紀錄檔,以及 JFR(Java Flight Recording)來定位。還有就是通過 async_profiler (https://github.com/jvm-profiling-tools/async-profiler/),因為我們發現,在出問題的時候,程序本身的 CPU 佔用(注意不是機器的,是這個程序的)也會激增:
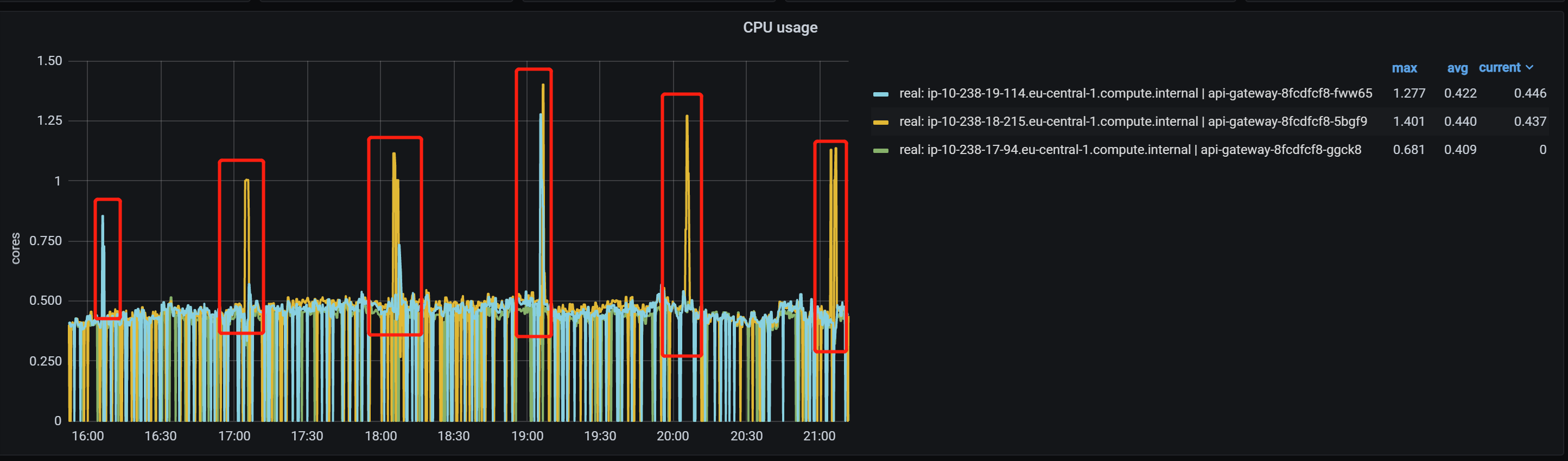
但是非常奇怪的是,通過 async_profiler 檢視 CPU 佔用,發現出問題的時間段,除了:
並且在處於安全點的期間,紀錄檔也是被中斷了一樣,這是非常少見的,為什麼這麼說,請看下面分析:
針對現象一,等待所有執行緒進入 safepoint 時間特別長,這個一般會不斷輸出等待哪個執行緒沒有進入安全點的紀錄檔,參考 JVM 原始碼:
https://github.com/openjdk/jdk/blob/master/src/hotspot/share/runtime/safepoint.cpp
hmwb1du4iyr.png)
但是現象一中我們並沒有看到因為哪個執行緒導致進入 safepoint 時間過長。
針對現象二,通過 JFR,也沒看出 GC 的哪個階段耗時很長:
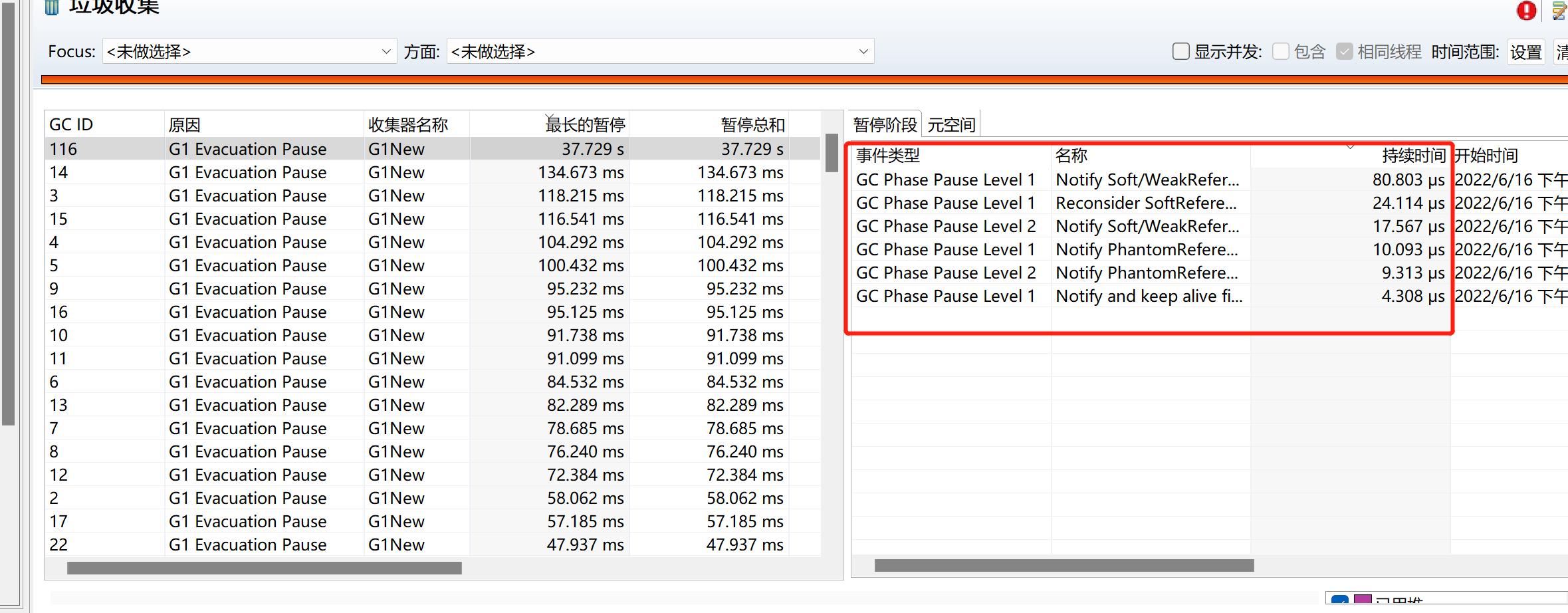
針對現象三,通過檢視 JVM 原始碼發現,輸出這兩個間隔很大的紀錄檔的程式碼之間,沒有做任何的事情,只是打紀錄檔。並且檢視所有出異常的時間點,都是每個小時的 05 分左右,詢問運維知道在這個時間,會進行上一小時紀錄檔檔案的移出與與 EFS 同步(我們一個小時生成一個紀錄檔檔案),會有大量檔案 IO(由於底層使用的是雲服務,也許並不是磁碟,而是 EFS 這種 NFS 或者網路物件儲存)。會不會是檔案 IO 太大導致 JVM 紀錄檔輸出堵住導致 JVM 卡住呢?
為啥 JVM 紀錄檔輸出會導致 JVM 所有應用執行緒卡住,假設 JVM 某個執行緒輸出紀錄檔卡住了,倘若沒有處於 safepoint,那麼不會卡住所有應用執行緒,只會卡住它自己。但是如果處於 safepoint,所有應用執行緒本身就被暫停了,如果這個時候某個 JVM 執行緒輸出紀錄檔卡住,那麼可能造成遲遲不能所有執行緒進入安全點,或者所有處於安全點時間過長。對應現象一,某個執行緒輸出的是 JVM 紀錄檔而不是應用紀錄檔(輸出應用紀錄檔一般是涉及檔案 IO 原生呼叫,處於原生呼叫直接就算進入了安全點,不會有影響,請參考我的另一篇文章:JVM相關 - SafePoint 與 Stop The World 全解:https://zhuanlan.zhihu.com/p/161710652),輸出 JVM 紀錄檔卡住導致這個執行緒遲遲沒有進入安全點。針對現象二三,都是 GC 執行緒輸出 JVM 紀錄檔卡住導致 GC 遲遲不結束。
首先通過 JVM 原始碼確認下 JVM 紀錄檔輸出卡住是否會阻塞 JVM。
JVM 輸出 JVM 紀錄檔原始碼分析
我們使用的是 Java 17,Java 17 之前沒有非同步 JVM 紀錄檔輸出。所以待會的原始碼分析請忽略非同步紀錄檔的程式碼,這樣就是 Java 17 前的紀錄檔輸出:
https://github.com/openjdk/jdk/blob/master/src/hotspot/share/logging/logFileStreamOutput.cpp
55ayrne3pnt.png)
通過這裡的程式碼可以看出,如果輸出檔案 IO 卡住,這裡的 flush 是會卡住的。同時,會有短暫的 CPU 激增,因為刷入等待的策略應該是 CPU 空轉等待一段時間之後進入阻塞。
那麼我們換成非同步紀錄檔怎麼樣?非同步紀錄檔有哪些引數呢? JVM 非同步紀錄檔是 Java 17 引入的,對應的 ISSUE 是:https://bugs.openjdk.org/browse/JDK-8229517,其中的關鍵,在於這兩個引數:
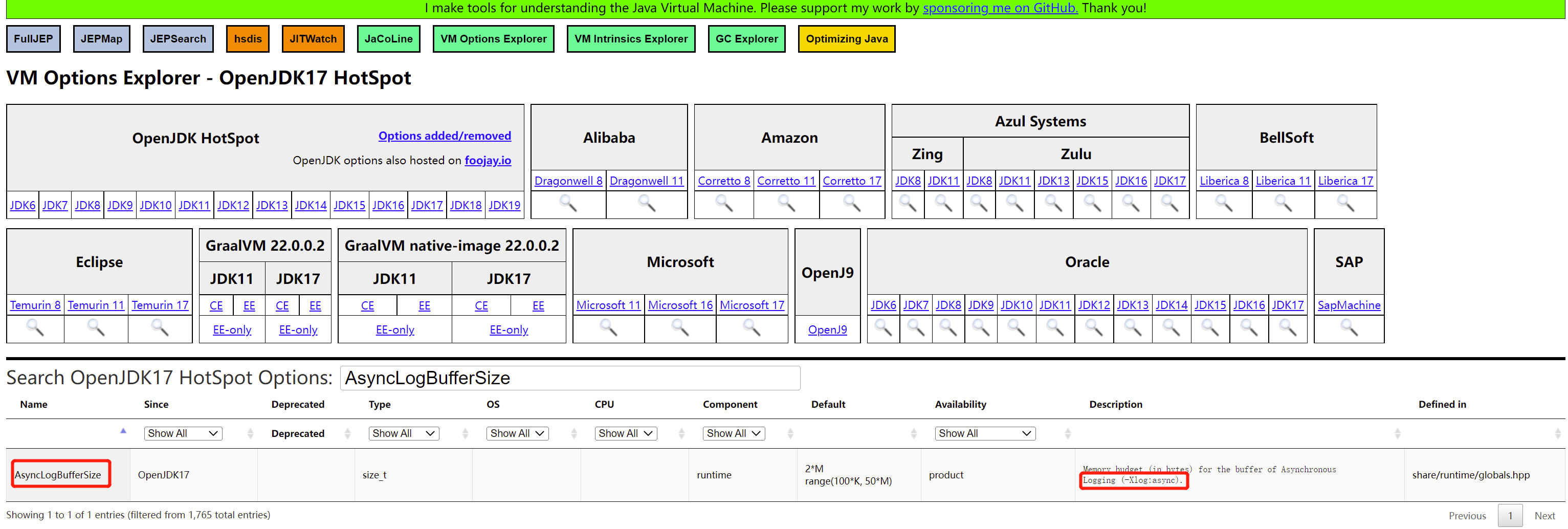
通過 -Xlog:async 啟用 JVM 非同步紀錄檔,通過 -XX:AsyncLogBufferSize= 指定非同步紀錄檔緩衝大小,這個大小預設是 2097152 即 2MB。非同步紀錄檔的原理是:
jnlq1g0rvyl.png)
修改引數為非同步紀錄檔,問題大幅度緩解,但是並沒完全解除,進一步定位
我們修改紀錄檔為非同步紀錄檔,加入啟動引數: -Xlog:async,-XX:AsyncLogBufferSize=4194304。之後觀察,問題得到大幅度緩解:

但是還是在某一個範例上出現了一次問題,檢視現象,與之前的不同了,通過 safepoint 紀錄檔看,是某個執行緒一直 running 不願意不進入 safepoint:
zzrfhf15utj.png)
那麼這個執行緒在幹什麼呢?通過 jstack 看一下這個執行緒是什麼執行緒:
5c2uaoth4ds.png)
這是一個定時重新整理微服務範例列表的執行緒,程式碼對於 WebFlux 的使用並不標準:
0rs4v2wapkb.png)
這樣使用非同步程式碼,可能帶來 JIT 優化錯誤(正確的用法呼叫很頻繁,這個錯誤用法呼叫也很頻繁,導致 JIT C2 不斷優化與去優化),檢視 JFR 發現這段時間也有很多 JIT 去優化:
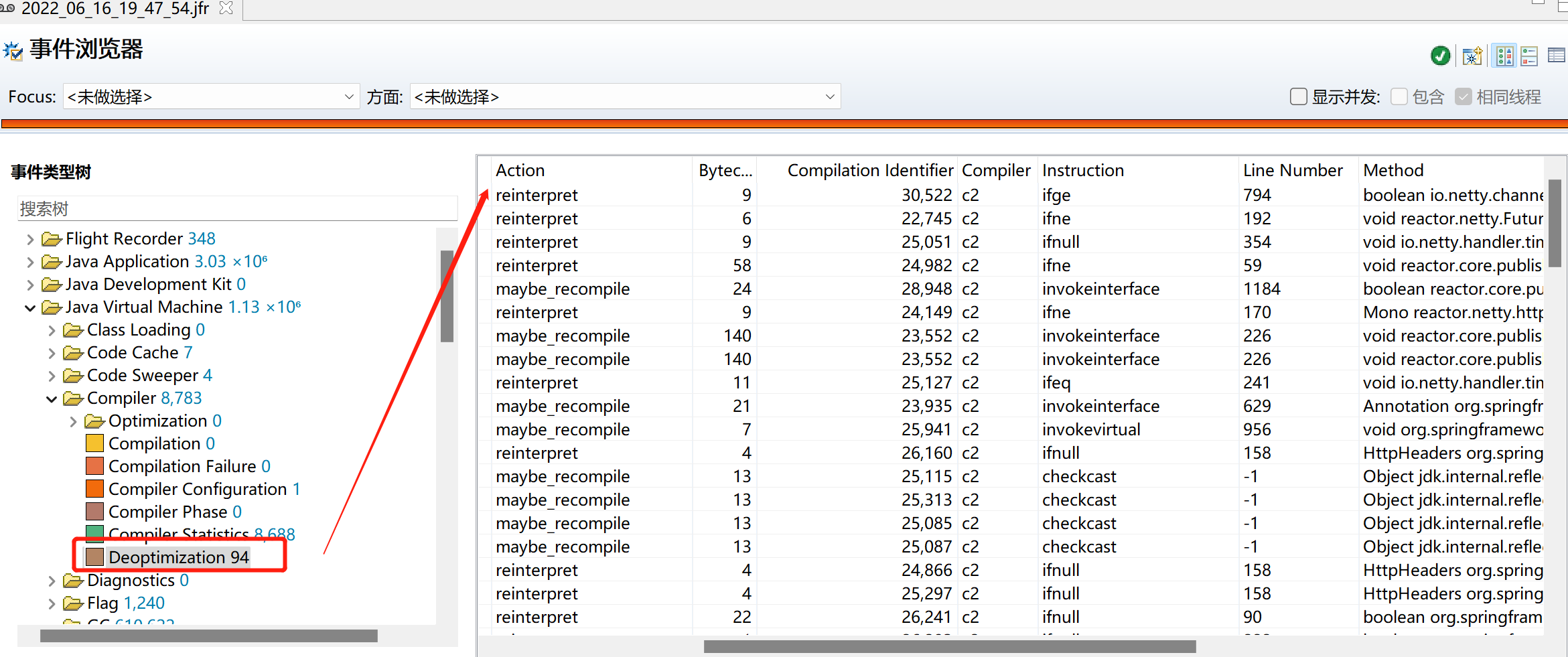
這樣可能導致安全點缺失走到 IO 不斷空轉等待很久的問題,需要改成正確的用法:
nwb2pmjeqra.png)
修改好之後,遲遲不進入 safepoint 的問題消失。
微信搜尋「乾貨滿滿張雜湊」關注公眾號,加作者微信,每日一刷,輕鬆提升技術,斬獲各種offer:
我會經常發一些很好的各種框架的官方社群的新聞視訊資料並加上個人翻譯字幕到如下地址(也包括上面的公眾號),歡迎關注:
