【翻譯】馴服野獸:Scylla 如何利用控制理論來控制壓實
教學翻譯自Seastar官方檔案:https://www.scylladb.com/2018/06/12/scylla-leverages-control-theory/
轉載請註明出處:https://www.cnblogs.com/morningli/p/16170046.html
從鳥瞰的角度來看,資料庫的任務很簡單:使用者插入一些資料,然後再獲取它。但是當我們仔細觀察時,事情變得更加複雜。例如,為了永續性,資料需要進入提交紀錄檔,需要被索引,並且被多次重寫以便可以輕鬆獲取。
所有這些任務都是資料庫的內部程序,它們將爭奪有限的資源,如 CPU、磁碟和網路頻寬。然而,授予其中一個或另一個特權的回報並不總是很清楚。這種內部過程的一個例子是 compactions,這是任何具有基於紀錄檔結構化合並 (LSM) 樹的儲存層的資料庫中的一個事實,比如 ScyllaDB。
LSM 樹由源自資料庫寫入的append-only的不可變檔案組成。隨著寫入的不斷髮生,系統可能會變成相同的key的資料會出現在許多不同的檔案中,這使得讀取非常昂貴。然後,這些檔案根據使用者選擇的壓縮策略在後臺由 compaction process 進行壓縮。如果我們花費更少的資源來壓縮現有檔案,我們可能能夠實現更快的寫入速率。但是,讀取將受到影響,因為它們現在需要存取更多檔案。
設定用於壓縮的資源量的最佳方法是什麼?一個不太理想的選擇是以可調引數的形式將決定推給使用者。然後,使用者可以在組態檔中選擇專用於壓縮的頻寬。然後,使用者負責trial-and-error 偵錯週期來嘗試為匹配的工作負載找到正確的數位。
在 ScyllaDB,我們認為這種方法是脆弱的。手動調優對工作負載的變化沒有彈性,其中許多變化是無法預料的。資源稀缺時峰值負載的最佳速率可能不是叢集非工作時間(資源充足時)的最佳速率。但是,即使調優週期確實能以某種方式找到一個好的速率,該過程也會顯著增加運算元據庫的成本。
在本文中,我們將討論 ScyllaDB 規定的解決此問題的方法。我們借鑑了工業控制器的數學框架,以確保壓縮頻寬自動設定為合適的值,同時保持可預測的系統響應。
控制系統入門
雖然我們無法通過檢視系統神奇地確定最佳壓縮頻寬,但我們可以設定希望資料庫遵守的使用者可見行為。一旦我們這樣做了,我們就可以使用控制理論來確保所有部分以指定的速率協同工作,從而實現所需的行為。這種系統的一個例子是汽車的巡航控制。雖然不可能猜測每個部分的單獨設定會結合起來使汽車以所需的速度行駛,但我們可以簡單地設定汽車的巡航速度,然後期望各個部分進行調整以實現這一目標。
特別是,我們將在本文中關注閉環控制系統——儘管我們也在 ScyllaDB 中使用開環控制系統。對於閉環控制系統,我們有一個被控制的過程和一個執行器,它負責將輸出移動到特定狀態。期望狀態和當前狀態之間的差異稱為誤差,它會反饋給輸入。因此,閉環控制系統也稱為反饋控制系統。
讓我們看另一個真實世界閉環控制系統的例子:我們希望水箱中的水處於或接近某個水位,我們將有一個閥門作為執行器,當前水位之間的差異所需的水平是錯誤。控制器將開啟或關閉閥門,以便更多或更少的水從水箱中流出。閥門應該開啟多少取決於控制器的傳遞函數。圖 1 顯示了這個一般概念的簡單圖表。
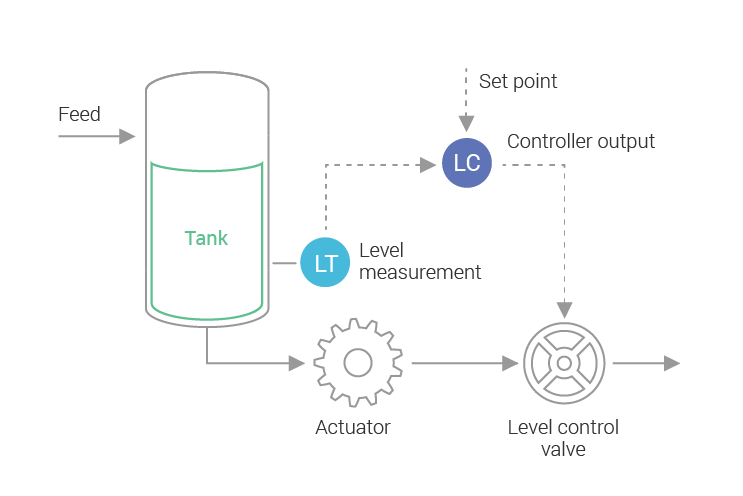
圖 1:工業控制器,控制水箱中的水位。測量電流電平並將其饋送到反饋迴路控制器。基於此,執行器將調整水箱中的水流量。像這樣的系統通常用於工業廠房。我們也可以利用這些知識來控制資料庫程序。
拼圖:排程器和積壓控制器
在 ScyllaDB 中,我們控制流程的基礎是嵌入在資料庫中的排程程式。我們在一篇由三部分組成的文章(第 1部分、第 2部分和第 3 部分)中廣泛討論了其中最早的 I/O 排程程式。排程程式作為控制系統中的執行器工作。通過增加某個元件的份額,我們提高了該過程的執行速度——類似於圖 1 中允許更多(或更少)流體通過的閥門。ScyllaDB 還嵌入了一個 CPU Scheduler,它對每個資料庫內部程序使用的 CPU 量起著類似的作用。
要設計我們的控制器,首先要提醒自己壓縮的目標是很重要的。擁有大量未壓縮的資料會導致讀取到讀取放大和空間放大。我們有讀取放大,因為每次讀取操作都必須從許多 SSTable 中讀取,以及空間放大,因為重疊資料將被複制很多次。我們的目標是擺脫這種放大。
然後,我們可以定義一個衡量標準,即要使系統達到零放大狀態還需要做多少工作。我們稱之為backlog。每當x新位元組寫入系統時,我們都會在未來生成ƒ(x)位元組的backlog。請注意, x和ƒ(x)之間沒有一對一的關係,因為我們可能必須多次重寫資料才能達到零放大狀態。當 backlog為零時,一切都被完全壓縮,沒有讀取或空間放大。
不同的工作負載具有不同的穩態頻寬。我們的控制法將為他們解決不同的 backlog 措施;高頻寬工作負載將比低頻寬工作負載擁有更高的 backlog 。這是一個理想的屬性:較高的 backlog 為覆蓋留下了更多的機會(這減少了寫入放大的總量),而低頻寬寫入工作負載將具有較低的 backlog,因此更少的 SSTables 和更小的讀取放大。
考慮到這一點,我們可以編寫一個與積壓成正比的傳遞函數。
確定壓縮積壓
現有 SSTable 的壓縮是根據特定的壓縮策略進行的,該策略選擇哪些 SSTable 必須被壓縮在一起,以及應該生成哪些以及應該生成多少。每種策略都會為相同的資料做不同的工作量。這意味著沒有一個單一的積壓控制器——每個壓縮策略都必須定義自己的。ScyllaDB 支援大小分層壓縮策略 (STCS)、分級壓縮策略 (LCS)、時間視窗壓縮策略 (TWCS) 和日期分層壓縮策略 (DTCS)。
在本文中,我們將研究用於控制預設壓縮策略的積壓控制器,即 Size Tiered Compaction Strategy。STCS 在上一篇文章中有詳細描述。快速回顧一下,STCS 將嘗試將大小相似的 SSTable 壓縮在一起。如果可能的話,我們會嘗試等到建立 4 個大小相似的 SSTable 並對其進行壓縮。當我們壓縮相似大小的 SSTables 時,我們可能會建立更大的 SSTables,這些 SSTables 將屬於下一層。
圖 2 顯示在實踐中。當我們編寫一個新的 SSTable 時,我們正在建立一個未來的 backlog,因為新的 SSTable 必須與其層中的那些壓縮。但是如果有第二層,那麼最終會有第二次壓縮,backlog 必須考慮到這一點。
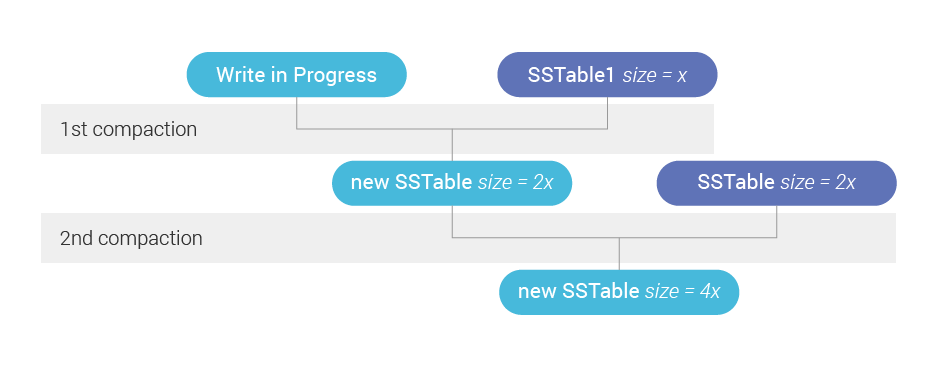 圖 2:在寫入新的 SSTable 時,系統中已經存在藍色的 SSTable。因為那些現有的 SSTable 存在於兩個不同的 Size Tier 中,所以新的 SSTable 建立的未來積壓工作大約是我們只有一個層的兩倍——因為我們將不得不進行兩次壓縮而不是一次。
圖 2:在寫入新的 SSTable 時,系統中已經存在藍色的 SSTable。因為那些現有的 SSTable 存在於兩個不同的 Size Tier 中,所以新的 SSTable 建立的未來積壓工作大約是我們只有一個層的兩倍——因為我們將不得不進行兩次壓縮而不是一次。例如,考慮一個沒有更新的恆定插入工作負載,它不斷生成每個大小為 1GB 的 SSTable。它們被壓縮成 4GB 大小的 SSTables,然後再被壓縮成 16GB 大小的 SSTables,等等。
當前兩層已滿時,我們將有四個大小為 1GB 的 SSTable 和另外四個大小為 4GB 的 SSTable。總表大小為 4 * 1 + 4 * 4 = 20GB,表與 SSTable 的比率分別為 20/1 和 20/4。我們將使用以 4 為底的對數,因為有 4 個 SSTables 被壓縮在一起,以產生 4 個小的 SSTables:
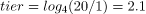
對於大的
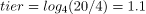
所以我們知道第一個大小為 1GB 的 SSTable 屬於第一層,而大小為 4GB 的 SSTable 屬於第二層。
一旦理解了這一點,我們就可以將屬於特定表的任何現有 SSTable 的積壓工作編寫為:
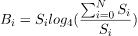
其中  是 SSTable 的積壓
是 SSTable 的積壓 ,
, 是 SSTable 的大小
是 SSTable 的大小 。那麼一個表的總積壓是
。那麼一個表的總積壓是
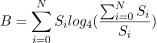
為了推匯出上面的公式,我們使用了系統中已經存在的 SSTables。但很容易看出它對正在寫入的 SSTable 也是有效的。我們需要做的就是注意, 事實上,SSTable 的部分大小——到目前為止寫入的位元組數。
事實上,SSTable 的部分大小——到目前為止寫入的位元組數。
隨著新資料的寫入,積壓會增加。但它是如何減少的?當壓縮過程從現有的 SSTables 中讀取位元組時,它會減少。然後我們將上面的公式調整為:
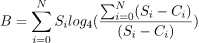
其中 是從 sstable 壓縮已讀取的位元組數。在未進行壓縮的 SSTables 中它將為 0。
是從 sstable 壓縮已讀取的位元組數。在未進行壓縮的 SSTables 中它將為 0。
請注意,當只有一個 SSTable 時 ,因為
,因為 沒有積壓,這與我們最初的觀察結果一致。
沒有積壓,這與我們最初的觀察結果一致。
實踐中的壓縮積壓控制器
為了在實踐中看到這一點,讓我們看看系統如何響應僅攝取的工作負載,我們將 1kB 的值寫入固定數量的隨機鍵,以便系統最終達到穩定狀態。
我們將以最大吞吐量攝取資料,確保即使在任何壓縮開始之前,系統已經使用了 100% 的資源(在這種情況下,它受到 CPU 的瓶頸),如圖 3 所示。隨著壓縮開始,內部壓縮過程使用的 CPU 時間與其份額成正比。隨著時間的推移,壓縮使用的 CPU 時間會增加,直到達到 15% 左右的穩定狀態。壓縮所花費的時間比例是固定的,系統不會出現波動。
圖 4 顯示了同一時期股票隨時間的變化。份額與積壓成正比。隨著新資料的重新整理和壓縮,總磁碟空間圍繞特定點波動。在穩定狀態下,積壓工作位於一個恆定的位置,我們正在以與傳入寫入生成新工作相同的速度壓縮資料。
一個非常好的副作用如圖 5 所示。ScyllaDB CPU 和 I/O 排程程式強制分配給其內部程序的份額數量,確保每個內部程序消耗與其份額的確切比例的資源。由於份額在穩定狀態下是恆定的,因此伺服器所看到的延遲在每個百分位都是可預測且穩定的。
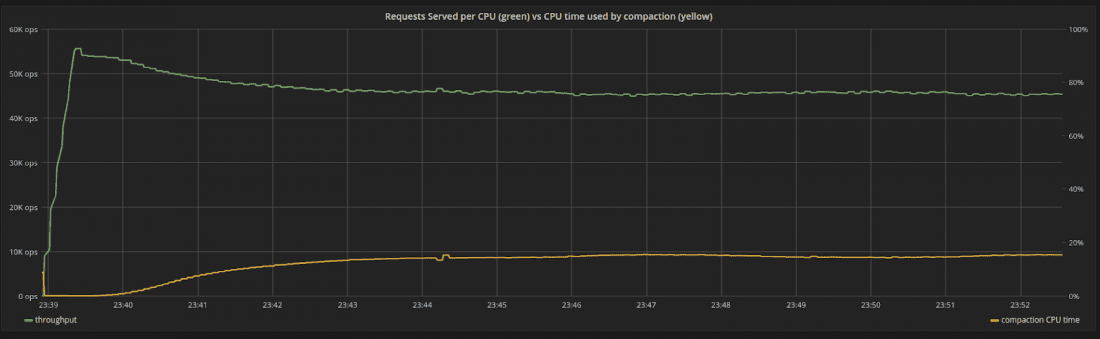
圖 3:系統中 CPU 的吞吐量(綠色)與壓縮使用的 CPU 時間百分比(黃色)。一開始,沒有壓縮。隨著時間的推移,系統達到穩定狀態,吞吐量穩步下降。
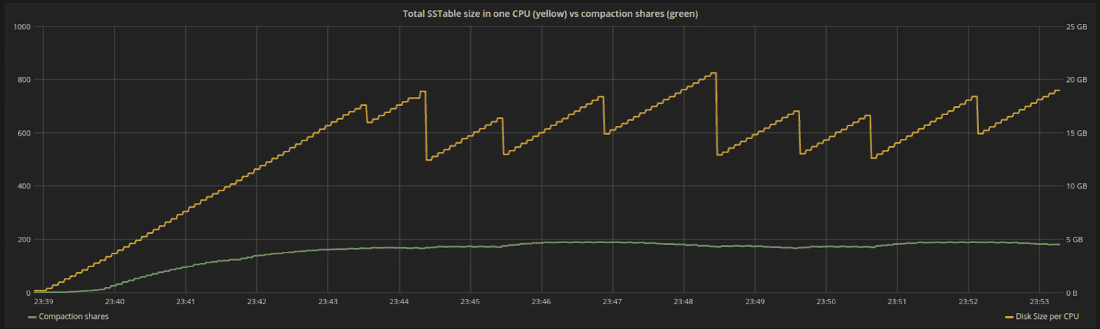
圖 4:分配給系統中特定 CPU 的磁碟空間(黃色)與分配給壓縮的份額(綠色)。份額與積壓成正比,在某些時候將達到穩定狀態
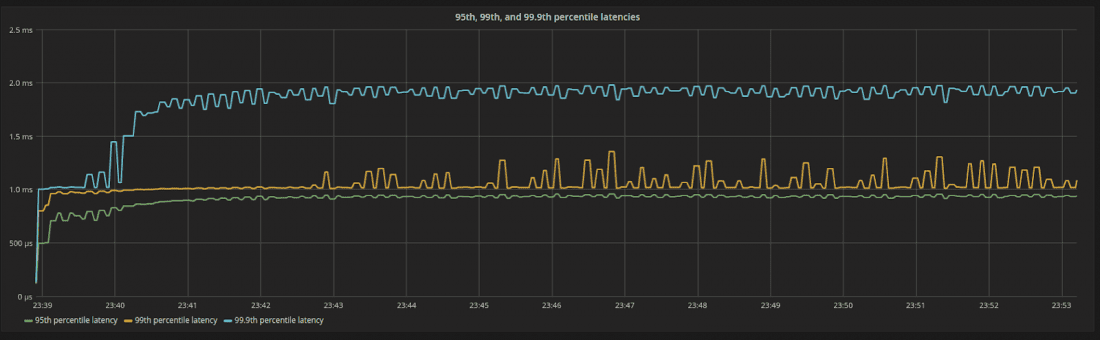
圖 5:第 95、第 99 和第 99.9 個百分位延遲。即使在 100% 的資源利用率下,延遲仍然很低且有限。
一旦系統處於穩定狀態一段時間,我們會突然增加每個請求的負載,從而導致系統更快地攝取資料。隨著資料攝取率的增加,積壓也應該增加。壓縮現在必須移動更多資料。
我們可以在圖 6 中看到它的影響。在新的攝取率下,系統受到干擾,因為 backlog 比以前增長得更快。但是,壓實控制器會自動增加內部壓實過程的份額,系統將達到新的平衡。
在圖 7 中,我們重新審視了分配給壓縮的 CPU 時間百分比發生了什麼變化,因為工作負載發生了變化。隨著請求變得更加昂貴,請求/秒的吞吐量自然會下降。但是,除此之外,更大的有效載荷將導致壓縮積壓更快地積累。壓縮使用的 CPU 百分比會增加,直到達到新的平衡。吞吐量的總下降是這兩種影響的結合。
有了更多的份額,壓縮現在使用更多的系統資源、磁碟頻寬和 CPU。但是股票的數量是穩定的,沒有大範圍的波動導致可預測的結果。這可以通過圖 8 中的延遲行為觀察到。工作負載仍然受 CPU 限制。現在可用於處理請求的 CPU 較少,因為有更多的 CPU 用於壓縮。但是由於份額的變化是平滑的,所以延遲的變化也是如此。
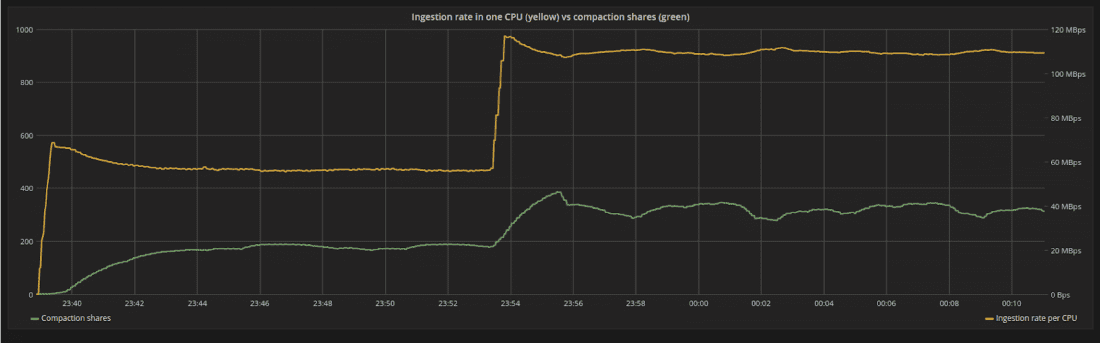
圖 6:隨著每個請求的負載大小增加,攝取速率(黃線)突然從 55MB/s 增加到 110MB/s。系統從其穩態位置受到干擾,但會為積壓找到新的平衡(綠線)。
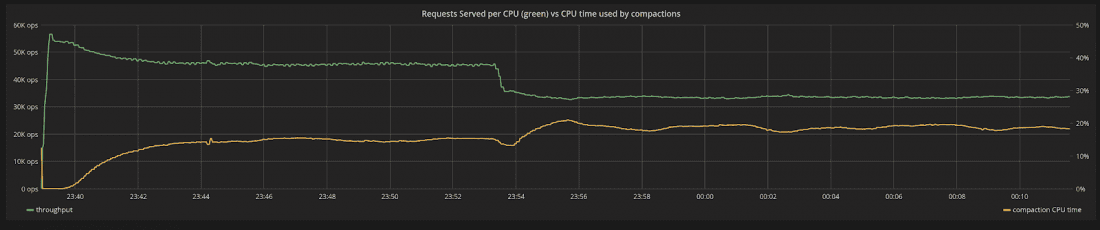
圖 7:隨著工作負載的變化,系統中 CPU 的吞吐量(綠色)與壓縮使用的 CPU 時間百分比(黃色)。隨著請求變得更加昂貴,請求/秒的吞吐量自然會下降。除此之外,更大的有效載荷將導致壓縮積壓更快地積累。壓縮使用的 CPU 百分比增加。
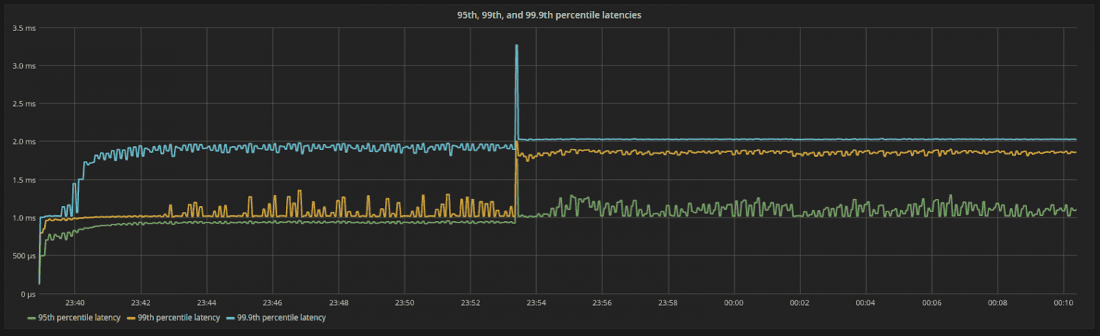
圖 8:負載增加後的第 95、99 和 99.9 個百分位延遲。延遲仍然是有限的並且以可預測的方式移動。這是系統中所有內部程序以穩定速率執行的一個很好的副作用。
結論
在任何給定時刻,像 ScyllaDB 這樣的資料庫都必須兼顧前臺請求的准入和壓縮等後臺程序,確保傳入的工作負載不會受到壓縮的嚴重干擾,也不會因為壓縮積壓太大而導致以後的讀取受到懲罰。
在本文中,我們展示了排程程式可以實現傳入寫入和壓縮之間的隔離,但資料庫仍然需要確定傳入寫入和壓縮將使用的資源份額數量。
ScyllaDB 在此任務中避開了使用者定義的可調引數,因為它們將操作的負擔轉移給了使用者,使操作複雜化並且對於不斷變化的工作負載很脆弱。通過借鑑工業控制器強大的理論背景,我們可以提供一個自治資料庫,無需操作員干預即可適應不斷變化的工作負載。
提醒一下,ScyllaDB 2.2 指日可待,它將隨大小分層壓縮策略的 Memtable Flush 控制器和壓縮控制器一起提供。所有壓縮策略的控制器很快就會出現。
本文來自部落格園,作者:morningli,轉載請註明原文連結:https://www.cnblogs.com/morningli/p/16170046.html