『忘了再學』Shell流程控制 — 33、if條件判斷語句(一)
什麼是流程控制?
- 普通理解:Shell編寫的程式是順序執行的,也就是說第一命令先執行,然後接著執行第二條命令,然後再下一條,以此類推,而流程控制就是改變上面這種順序執行的方式。
- 官方理解:流程控制語句用於控制程式的流程, 以實現程式的各種結構方式,即用來實現對程式流程的選擇、迴圈、轉向和返回等進行控制。
Shell中的流程控制語句分為:
if條件判斷語句。case條件判斷語句。for迴圈語句。while迴圈語句。until迴圈語句。
1、單分支if條件語句
單分支條件語句最為簡單,就是隻有一個判斷條件,如果符合條件則執行某個程式,否則什麼事情都不做。
語法如下:
if[ 條件判斷式 ];then
程式
fi
單分支條件語句需要注意幾個點:
if語句使用fi結尾,和一般語言使用大括號結尾不同。
[ 條件判斷式 ]就是使用test命令進行判斷,所以中括號和條件判斷式之間必須有空格。
then後面跟符合條件之後執行的程式,可以放在[]之後,用;分割。也可以換行寫入,就不需要
;了,比如單分支
if語句還可以這樣寫:if [ 條件判斷式 ] then 程式 fi
範例:
需求:根分割區使用率超過80%則報警。
# 1.獲取根分割區使用率
# 1.1 通過df命令檢視Linux系統上的檔案系統磁碟使用情況。
# df命令用於顯示目前在Linux系統上檔案系統磁碟使用情況的統計。
[root@localhost tmp]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 19G 2.1G 16G 12% /
tmpfs 491M 0 491M 0% /dev/shm
/dev/sda1 240M 34M 194M 15% /boot
# 1.2 把根分割區的磁碟使用情況提取出來
[root@localhost tmp]# df -h | grep /dev/sda3
/dev/sda3 19G 2.1G 16G 12% /
# 1.3 然後用awk命令,進行列資訊提取,提取第五列。
[root@localhost tmp]# df -h | grep /dev/sda3 | awk '{print $5}'
12%
# 1.4 擷取前面的數位部分,方便後邊判斷使用。
# 以%作為分隔符,然後提取1列。
[root@localhost tmp]# df -h | grep /dev/sda3 | awk '{print $5}' | cut -d "%" -f 1
12
# 2.編寫Shell程式
# 2.1 建立一個Shell檔案if1.sh
[root@localhost tmp]# vim if1.sh
# 編寫內容如下:
#!/bin/bash
# 把根分割區使用率作為變數值賦予變數rate
# 把上面的命令以命令列的方式先敲一遍,確認能獲取到我們需要的內容。
# 如果在Shell裡面直接寫,會有很大難度。
rate=$( df -h | grep /dev/sda3 | awk '{print $5}' | cut -d "%" -f 1 )
# 判斷rate的值如果大於等於80,則執行then後的程式。
# 我們這裡為了有演示效果,把輸出調整為10.
if [ $rate -ge 10 ]
then
# 列印警告資訊。在實際工作中,也可以向管理員傳送郵件。
echo "Warning! /dev/sda3 is full !!!"
fi
# 上面的程式表示,如果根分割區使用率超過80%則列印`Warning! /dev/sda3 is full !!!``,沒有則什麼都不做。
# 3. 給if1.sh檔案賦予執行許可權,並執行該指令碼。
[root@localhost tmp]# chmod 755 if1.sh
[root@localhost tmp]# ./if1.sh
Warning! /dev/sda3 is full !!!
2、雙分支if條件語句
語法格式:
if [ 條件判斷式 ]
then
條件成立時,執行的程式
else
條件不成立時,執行的程式
fi
(1)範例1
我們寫一個資料備份的例子,來看看雙分支if條件語句。
建立檔案if2.sh:
#!/bin/bash
# 需求:備份MySQL資料庫
# 1.首先需要同步時間
# 因為我們的伺服器上的時間可能會存在誤差,
# 我們可以連結ntp時間伺服器,來自動更新時間,
# 這樣我們伺服器上的時間就準確了,
# 下面一行命令是連結到亞洲的ntp時間伺服器上,更新時間。
# 目的是保證所有伺服器的時間是統一的。
ntpdate asia.pool.ntp.org &>/dev/null
# 提示:你也可以單獨寫一個指令碼,專門用於時間同步。
# &>/dev/null:為把所有輸出丟入垃圾箱(不想看到在何輸出)
# &>:為無論正確輸出還是錯誤輸出,都輸出到一個檔案中。
# /dev/null類似是一個虛擬裝置,或者是當成回收站,
# 任何資訊丟進去,就會消失不見。
# 如果有不需要看的命令提示資訊,就可以這樣處理。
# 這是一個標準寫法。
# 2.把當前系統時間按照「年月日」格式賦予變數date
# 預設的時間格式
# [root@localhost tmp]# date
# 2020年 10月 18日 星期日 10:28:27 CST
# 只取年月日,注意+和%之間不能有空格,否則命令會報錯。
# [root@localhost tmp]# date +%y%m%d
# 201018
date=$(date +%y%m%d)
# 3.統計mysql資料庫的大小,並把結果賦予size變數。
# 該資料主要是一個統計資料,沒有多大作用,
# 只是為了寫紀錄檔,告訴你今天備份的MySQL資料庫的大小。
size=$(du -sh /var/1ib/mysql)
# 4.開始備份資料庫
# 4.1 判斷備份目錄是否存在,是否為目錄
if [ -d /tmp/dbbak ]
then
# 4.2如果判斷為真,執行以下指令碼
# dbinfo.txt:資料庫備份說明檔案,內容就是在某年某月的某一天,備份了多大的資料。
# 把當前日期寫入檔案
echo "Date:$date!" 〉 /tmp/dbbak/dbinfo.txt
# 把資料庫大小寫入檔案
echo "Data size:$size" >> /tmp/dbbak/dbinfo.txt
# 4.3 進入到備份目錄dbbak中
cd /tmp/dbbak
# 4.4 備份資料庫
# 把資料庫資料和備份說明檔案進行打包壓縮為mysql-lib-$date.tar.gz
# &>/dev/null:為把所有輸出丟入垃圾箱(不想看到在何輸出)
tar -zcf mysql-lib-$date.tar.gz /var/lib/mysql dbinfo.txt &>/dev/null
# 4.5 刪除備份說明檔案
rm -rf /tmp/dbbak/dbinfo.txt
else
# 4.6 如果判斷為假,則建立備份目錄
mkdir /tmp/dbbak
# 4.7 執行上邊4.2到4.5的步驟
# 把日期和資料庫大小儲存到備份說明檔案
echo "Date:$date!" 〉 /tmp/dbbak/dbinfo.txt
echo "Data size:$size" >> /tmp/dbbak/dbinfo.txt
# 壓縮備份資料庫與備份說明檔案
cd /tmp/dbbak
tar -zcf mysql-lib-$date.tar.gz /var/lib/mysql dbinfo.txt &>/dev/null
# 刪除備份說明檔案
rm -rf /tmp/dbbak/dbinfo.txt
fi
說明:
這個資料庫備份的方式不是很合理,主要是在備份資料庫的那一行命令,如下:
tar -zcf mysql-lib-$date.tar.gz /var/1ib/mysql dbinfo.txt &>/dev/nul1
不合理的原因有:
- Shell程式中的備份使用壓縮包的方式來處理的,把MySQL整個庫和一個說明檔案打包成一個壓縮檔案。這種方式是可以解決資料庫備份的需求的,但是這種備份的方式,恢復起來會有一些問題。
在資料庫恢復的時候,會要求環境(如MySQL的安裝位置,MySQL的版本等)必須要和備份時的環境一樣,才能夠做到資料恢復。 - 這個處理方式只能夠實現完全備份,也就是說如果有50G的資料,你備份一次,就要把這50G的資料全部備份一遍。
在實際工作中我們會用其他工具進行資料庫的備份,如mysqldump。 - 還有我們之前說過,備份的核心原則是不要把所有雞蛋放在同一個籃子裡。而我們是把原始資料和備份資料放在同一個伺服器的同一個硬碟中。那如果這個硬碟壞了,就沒有資料可恢復了。
而我們在實際工作中,是通過可以網路備份的服務來處理,我們先按上面的方式進行備份,把資料庫備份出來的檔案通過網路的方式,傳送給其他的伺服器。
注意:這只是資料庫備份的練習,並不能在工作直接使用,但是思路就是這個思路,這裡注意一下。
(2)範例2
在實際工作當中,伺服器上的服務經常會宕機,拿apache服務來舉例,如果我們對伺服器監控不好,就會造成伺服器中服務中斷了,而管理員卻不知道的情況。發現後等到管理員的介入,也會有一定時間的延遲。這時我們就可以寫一個指令碼來監聽本機的服務,如果服務停止或宕機了,可以自動重啟這些服務。
我們就以apache服務來舉例:
前提,我們通過RPM包的方式安裝了apache服務,並啟動,如下圖:
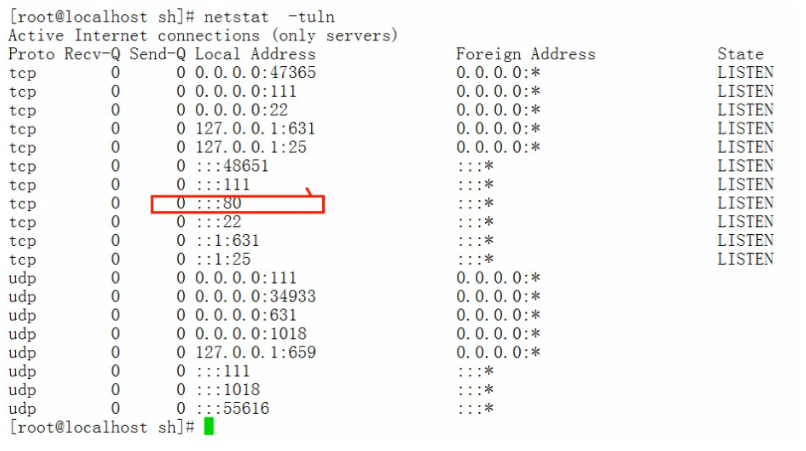
方式一:
分析該指令碼該如何實現:
思路:把80埠擷取出來,賦值到一個變數中,
判斷該變數的值是否為80,是則記錄紀錄檔,不是則執行啟動apache服務。
開始編寫:
建立檔案if3.sh:
#!/bin/bash
# 判斷apache服務是否啟動,如果沒有啟動則自動啟動。
# 1.把80埠擷取出來,賦值到一個變數中
port=$(netstat -tuln | awk '{print $4}' | grep ":80$")
# 2.判斷port變數是否為空
if [ "$port" == "" ]
then
# 為空則證明apache服務沒有啟動
# 傳送郵件
echo "apache httpd is down,must restart!"
# 啟動apache服務
/etc/rc.d/init.d/httpd start &>/deb/null
# 這裡不建議使用service的方式啟動apache服務,
# service啟動服務是一種快捷方式,
# 有可能在指令碼中會出問題,這裡需要注意一下。
else
# 不為空則證明apache服務以啟動
# 可以記錄紀錄檔
echo "apache httpd is ok."
fi
注意:
不能通過
grep "80"命令來過濾資料,因為Shell中的正規表示式是包含匹配,像808、8080等這樣的內容,都會被匹配出來。
使用該指令碼:
- 執行
chmod 755 if3.sh命令,將if3.sh變成可執行檔案。 - 執行
netstat -tuln,檢視此時apache服務是否啟動。
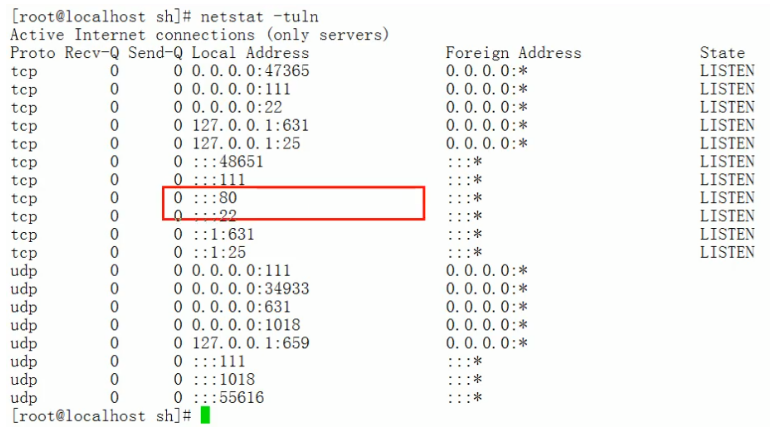
- 執行
./if3.sh命令,執行指令碼檔案,檢查到apache服務是啟動狀態。

- 此時關掉
apache服務。

再檢視一下80埠是否已關閉。
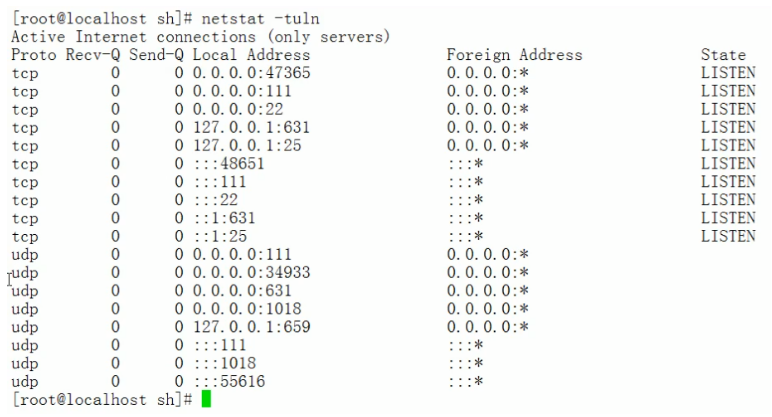
- 然後在執行
if3.sh指令碼檔案。

可以看到執行if3.sh指令碼檔案,發現apache服務沒有啟動,
該指令碼會自動啟動apache服務。 - 最後我們再檢視一下
apache服務是否啟動。
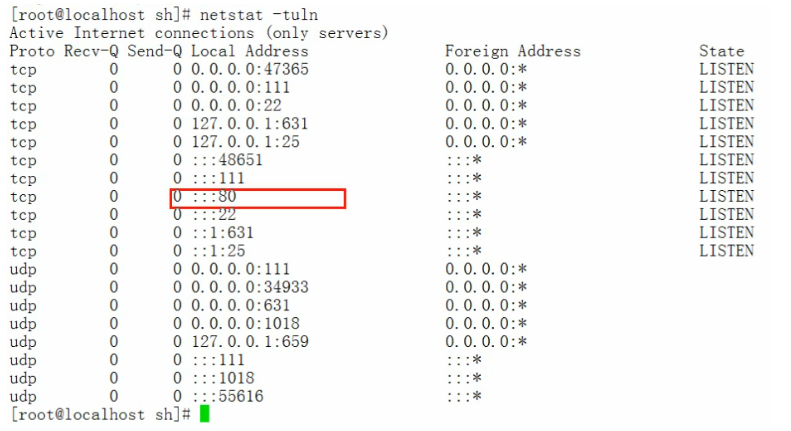
又重新啟動了。
提示:
指令碼執行過程中,發現服務未啟動,會通知管理員,同時也可以通過命令直接把apache服務進行重新啟動。而不需要管理員來了,才重啟服務。只要管理員接收到通知伺服器有問題,過來檢查什麼原因就可以了。
方式二:
上面實現的方式,基本能夠實現檢測apache服務的需求。
但是實際工作環境中,可能有種情況,比如apache服務正常,80埠也被開啟,但是此時的存取人數過多,把apache服務直接擠爆了。也就是說程序在,埠也在(卡死),但是apache服務已經不應答了。這個時候我們還通過檢查80埠的方式,我們是無法發現伺服器中apache服務的問題的。
我們先學習一個命令:
nmap命令是埠掃描命令,命令格式如下:
[root@localhost ~]# nmap -sT 域名或 IP
選項:
-s:掃描。
-T:掃描所有開啟的TCP埠。
nmap命令的原理是使用者端(nmap)給一個伺服器所有的埠傳送資訊,看都有那些埠回覆資訊,回覆了證明該伺服器上的埠上的程式正常。
唯一的問題是nmap命令掃描的時間比較長。
如果你的Linux系統中沒有安裝nmap命令,可以執行命令yum -y install nmap進行安裝。
nmap命令來掃描本機的埠,執行結果如下:
[root@localhost tmp]# nmap -sT 192.168.37.128
Starting Nmap 5.51 ( http://nmap.org ) at 2020-10-19 00:18 CST
Nmap scan report for 192.168.37.128 (192.168.37.128)
Host is up (0.0019s latency).
Not shown: 998 closed ports
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http (apache的狀態是open)
111/tcp open rpcbind
Nmap done: 1 IP address (1 host up) scanned in 0.16 seconds
知道了nmap命令的用法,我們在指令碼中使用的命令就是為了擷取http的狀態,只要狀態是「open」
就證明apache啟動正常,否則證明apache服務啟動錯誤。
開始編寫指令碼:
#!/bin/bash
# 判斷apache服務是否啟動,如果沒有啟動則自動啟動
# 使用nmap命令掃描伺服器,並擷取apache服務的狀態,賦予變數stat。
# 只有apache服務的程序名叫`http`
# 擷取第二列是獲取nmap掃描後的埠狀態
stat=$(map -sT 192.168.37.128 | grep tcp | grep ssh | awk '{print $2}')
# 如果變數stat的值是「open」
if [ "$port"=="open" ]
then
# 則證明apache服務正常啟動,在正常紀錄檔中寫入一句話即可
echo "$(date) httpd is ok!" >> /tmp/autostart-acc.log
else
# 否則證明apache服務沒有啟動,自動啟動apache服務
/etc/rc.d/init.d/httpd start &>/dev/null
# 並在錯誤紀錄檔中記錄自動啟動apche服務的時間
echo "$(date) restart httpd!!" >> /tmp/autostart-err.1og
fi
(當然實際工作中處理該類問題有監控伺服器來進行監控,以上只是一個練習。)