MySQL 千萬資料庫深分頁查詢優化,拒絕線上故障!
文章首發在公眾號(龍臺的技術筆記),之後同步到部落格園和個人網站:xiaomage.info
優化專案程式碼過程中發現一個千萬級資料深分頁問題,緣由是這樣的
庫裡有一張耗材 MCS_PROD 表,通過同步外部資料中臺多維度資料,在系統內部組裝為單一耗材產品,最終同步到 ES 搜尋引擎
MySQL 同步 ES 流程如下:
- 通過定時任務的形式觸發同步,比如間隔半天或一天的時間頻率
- 同步的形式為增量同步,根據更新時間的機制,比如第一次同步查詢 >= 1970-01-01 00:00:00.0
- 記錄最大的更新時間進行儲存,下次更新同步以此為條件
- 以分頁的形式獲取資料,當前頁數量加一,迴圈到最後一頁
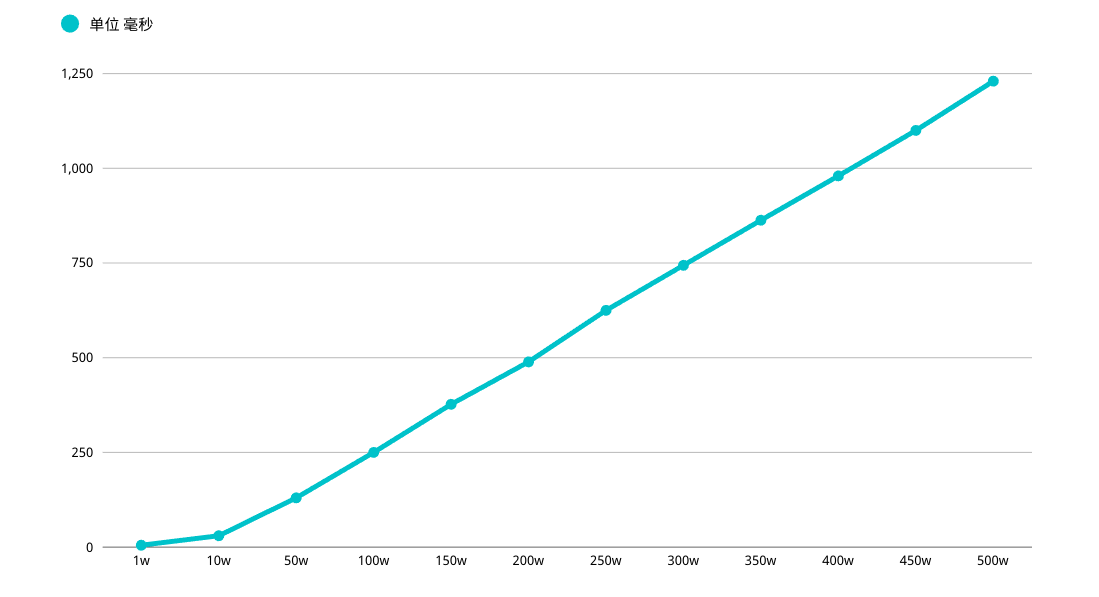
在這裡問題也就出現了,MySQL 查詢分頁 OFFSET 越深入,效能越差,初步估計線上 MCS_PROD 表中記錄在 1000w 左右
如果按照每頁 10 條,OFFSET 值會拖垮查詢效能,進而形成一個 "效能深淵"
同步類程式碼針對此問題有兩種優化方式:
- 採用遊標、流式方案進行優化
- 優化深分頁效能,文章圍繞這個題目展開
文章目錄如下:
- 軟硬體說明
- 重新認識 MySQL 分頁
- 深分頁優化
- 子查詢優化
- 延遲關聯
- 書籤記錄
- ORDER BY 巨坑,慎踩
- ORDER BY 索引失效舉例
- 結言
軟硬體說明
MySQL VERSION
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.30 |
+-----------+
1 row in set (0.01 sec)
表結構說明
借鑑公司表結構,欄位、長度以及名稱均已刪減
mysql> DESC MCS_PROD;
+-----------------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------------------+--------------+------+-----+---------+----------------+
| MCS_PROD_ID | int(11) | NO | PRI | NULL | auto_increment |
| MCS_CODE | varchar(100) | YES | | | |
| MCS_NAME | varchar(500) | YES | | | |
| UPDT_TIME | datetime | NO | MUL | NULL | |
+-----------------------+--------------+------+-----+---------+----------------+
4 rows in set (0.01 sec)
通過測試同學幫忙造了 500w 左右資料量
mysql> SELECT COUNT(*) FROM MCS_PROD;
+----------+
| count(*) |
+----------+
| 5100000 |
+----------+
1 row in set (1.43 sec)
SQL 語句如下
因為功能需要滿足 增量拉取的方式,所以會有資料更新時間的條件查詢,以及相關 查詢排序(此處有坑)
SELECT
MCS_PROD_ID,
MCS_CODE,
MCS_NAME,
UPDT_TIME
FROM
MCS_PROD
WHERE
UPDT_TIME >= '1970-01-01 00:00:00.0' ORDER BY UPDT_TIME
LIMIT xx, xx
重新認識 MySQL 分頁
LIMIT 子句可以被用於強制 SELECT 語句返回指定的記錄數。LIMIT 接收一個或兩個數位引數,引數必須是一個整數常數
如果給定兩個引數,第一個引數指定第一個返回記錄行的偏移量,第二個引數指定返回記錄行的最大數
舉個簡單的例子,分析下 SQL 查詢過程,掌握深分頁效能為什麼差
mysql> SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD WHERE (UPDT_TIME >= '1970-01-01 00:00:00.0') ORDER BY UPDT_TIME LIMIT 100000, 1;
+-------------+-------------------------+------------------+---------------------+
| MCS_PROD_ID | MCS_CODE | MCS_NAME | UPDT_TIME |
+-------------+-------------------------+------------------+---------------------+
| 181789 | XA601709733186213015031 | 尺、橈骨LC-DCP骨板 | 2020-10-19 16:22:19 |
+-------------+-------------------------+------------------+---------------------+
1 row in set (3.66 sec)
mysql> EXPLAIN SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD WHERE (UPDT_TIME >= '1970-01-01 00:00:00.0') ORDER BY UPDT_TIME LIMIT 100000, 1;
+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+-----------------------+
| 1 | SIMPLE | MCS_PROD | NULL | range | MCS_PROD_1 | MCS_PROD_1 | 5 | NULL | 2296653 | 100.00 | Using index condition |
+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)
簡單說明下上面 SQL 執行過程:
- 首先查詢了表 MCS_PROD,進行過濾 UPDT_TIME 條件,查詢出展示列(涉及回表操作)進行排序以及 LIMIT
- LIMIT 100000, 1 的意思是掃描滿足條件的 100001 行,然後扔掉前 100000 行
MySQL 耗費了 大量隨機 I/O 在回表查詢聚簇索引的資料上,而這 100000 次隨機 I/O 查詢資料不會出現在結果集中
如果系統並行量稍微高一點,每次查詢掃描超過 100000 行,效能肯定堪憂,另外 LIMIT 分頁 OFFSET 越深,效能越差(多次強調)

深分頁優化
關於 MySQL 深分頁優化常見的大概有以下三種策略:
- 子查詢優化
- 延遲關聯
- 書籤記錄
上面三點都能大大的提升查詢效率,核心思想就是讓 MySQL 儘可能掃描更少的頁面,獲取需要存取的記錄後再根據關聯列回原表查詢所需要的列
子查詢優化
子查詢深分頁優化語句如下:
mysql> SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD WHERE MCS_PROD_ID >= ( SELECT m1.MCS_PROD_ID FROM MCS_PROD m1 WHERE m1.UPDT_TIME >= '1970-01-01 00:00:00.0' ORDER BY m1.UPDT_TIME LIMIT 3000000, 1) LIMIT 1;
+-------------+-------------------------+------------------------+
| MCS_PROD_ID | MCS_CODE | MCS_NAME |
+-------------+-------------------------+------------------------+
| 3021401 | XA892010009391491861476 | 金屬解剖型接骨板T型接骨板A |
+-------------+-------------------------+------------------------+
1 row in set (0.76 sec)
mysql> EXPLAIN SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD WHERE MCS_PROD_ID >= ( SELECT m1.MCS_PROD_ID FROM MCS_PROD m1 WHERE m1.UPDT_TIME >= '1970-01-01 00:00:00.0' ORDER BY m1.UPDT_TIME LIMIT 3000000, 1) LIMIT 1;
+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+--------------------------+
| 1 | PRIMARY | MCS_PROD | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 2296653 | 100.00 | Using where |
| 2 | SUBQUERY | m1 | NULL | range | MCS_PROD_1 | MCS_PROD_1 | 5 | NULL | 2296653 | 100.00 | Using where; Using index |
+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+--------------------------+
2 rows in set, 1 warning (0.77 sec)
根據執行計劃得知,子查詢 table m1 查詢是用到了索引。首先在 索引上拿到了聚集索引的主鍵 ID 省去了回表操作,然後第二查詢直接根據第一個查詢的 ID 往後再去查 10 個就可以了
延遲關聯
"延遲關聯" 深分頁優化語句如下:
mysql> SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD INNER JOIN (SELECT m1.MCS_PROD_ID FROM MCS_PROD m1 WHERE m1.UPDT_TIME >= '1970-01-01 00:00:00.0' ORDER BY m1.UPDT_TIME LIMIT 3000000, 1) AS MCS_PROD2 USING(MCS_PROD_ID);
+-------------+-------------------------+------------------------+
| MCS_PROD_ID | MCS_CODE | MCS_NAME |
+-------------+-------------------------+------------------------+
| 3021401 | XA892010009391491861476 | 金屬解剖型接骨板T型接骨板A |
+-------------+-------------------------+------------------------+
1 row in set (0.75 sec)
mysql> EXPLAIN SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD INNER JOIN (SELECT m1.MCS_PROD_ID FROM MCS_PROD m1 WHERE m1.UPDT_TIME >= '1970-01-01 00:00:00.0' ORDER BY m1.UPDT_TIME LIMIT 3000000, 1) AS MCS_PROD2 USING(MCS_PROD_ID);
+----+-------------+------------+------------+--------+---------------+------------+---------+-----------------------+---------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+------------+---------+-----------------------+---------+----------+--------------------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 2296653 | 100.00 | NULL |
| 1 | PRIMARY | MCS_PROD | NULL | eq_ref | PRIMARY | PRIMARY | 4 | MCS_PROD2.MCS_PROD_ID | 1 | 100.00 | NULL |
| 2 | DERIVED | m1 | NULL | range | MCS_PROD_1 | MCS_PROD_1 | 5 | NULL | 2296653 | 100.00 | Using where; Using index |
+----+-------------+------------+------------+--------+---------------+------------+---------+-----------------------+---------+----------+--------------------------+
3 rows in set, 1 warning (0.00 sec)
思路以及效能與子查詢優化一致,只不過採用了 JOIN 的形式執行
書籤記錄
關於 LIMIT 深分頁問題,核心在於 OFFSET 值,它會 導致 MySQL 掃描大量不需要的記錄行然後拋棄掉
我們可以先使用書籤 記錄獲取上次取資料的位置,下次就可以直接從該位置開始掃描,這樣可以 避免使用 OFFEST
假設需要查詢 3000000 行資料後的第 1 條記錄,查詢可以這麼寫
mysql> SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD WHERE MCS_PROD_ID < 3000000 ORDER BY UPDT_TIME LIMIT 1;
+-------------+-------------------------+---------------------------------+
| MCS_PROD_ID | MCS_CODE | MCS_NAME |
+-------------+-------------------------+---------------------------------+
| 127 | XA683240878449276581799 | 股骨近端-1螺紋孔鎖定板(純鈦)YJBL01 |
+-------------+-------------------------+---------------------------------+
1 row in set (0.00 sec)
mysql> EXPLAIN SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD WHERE MCS_PROD_ID < 3000000 ORDER BY UPDT_TIME LIMIT 1;
+----+-------------+----------+------------+-------+---------------+------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+------------+---------+------+------+----------+-------------+
| 1 | SIMPLE | MCS_PROD | NULL | index | PRIMARY | MCS_PROD_1 | 5 | NULL | 2 | 50.00 | Using where |
+----+-------------+----------+------------+-------+---------------+------------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
好處是很明顯的,查詢速度超級快,效能都會穩定在毫秒級,從效能上考慮碾壓其它方式
不過這種方式侷限性也比較大,需要一種類似連續自增的欄位,以及業務所能包容的連續概念,視情況而定
上圖是阿里雲 OSS Bucket 桶內檔案列表,大膽猜測是不是可以採用書籤記錄的形式完成
ORDER BY 巨坑, 慎踩
以下言論可能會打破你對 order by 所有 美好 YY
先說結論吧,當 LIMIT OFFSET 過深時,會使 ORDER BY 普通索引失效(聯合、唯一這些索引沒有測試)
mysql> EXPLAIN SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME,UPDT_TIME FROM MCS_PROD WHERE (UPDT_TIME >= '1970-01-01 00:00:00.0') ORDER BY UPDT_TIME LIMIT 100000, 1;
+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+-----------------------+
| 1 | SIMPLE | MCS_PROD | NULL | range | MCS_PROD_1 | MCS_PROD_1 | 5 | NULL | 2296653 | 100.00 | Using index condition |
+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
先來說一下這個 ORDER BY 執行過程:
- 初始化 SORT_BUFFER,放入 MCS_PROD_ID,MCS_CODE,MCS_NAME,UPDT_TIME 四個欄位
- 從索引 UPDT_TIME 找到滿足條件的主鍵 ID,回表查詢出四個欄位值存入 SORT_BUFFER
- 從索引處繼續查詢滿足 UPDT_TIME 條件記錄,繼續執行步驟 2
- 對 SORT_BUFFER 中的資料按照 UPDT_TIME 排序
- 排序成功後取出符合 LIMIT 條件的記錄返回使用者端
按照 UPDT_TIME 排序可能在記憶體中完成,也可能需要使用外部排序,取決於排序所需的記憶體和引數 SORT_BUFFER_SIZE
SORT_BUFFER_SIZE 是 MySQL 為排序開闢的記憶體。如果排序資料量小於 SORT_BUFFER_SIZE,排序會在記憶體中完成。如果資料量過大,記憶體放不下,則會利用磁碟臨時檔案排序
針對 SORT_BUFFER_SIZE 這個引數在網上查詢到有用資料比較少,大家如果測試過程中存在問題,可以加微信一起溝通
ORDER BY 索引失效舉例
OFFSET 100000 時,通過 key Extra 得知,沒有使用磁碟臨時檔案排序,這個時候把 OFFSET 調整到 500000
一首涼涼送給寫這個 SQL 的同學,發現了 Using filesort
mysql> EXPLAIN SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME,UPDT_TIME FROM MCS_PROD WHERE (UPDT_TIME >= '1970-01-01 00:00:00.0') ORDER BY UPDT_TIME LIMIT 500000, 1;
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
| 1 | SIMPLE | MCS_PROD | NULL | ALL | MCS_PROD_1 | NULL | NULL | NULL | 4593306 | 50.00 | Using where; Using filesort |
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)
Using filesort 表示在索引之外,需要額外進行外部的排序動作,效能必將受到嚴重影響
所以我們應該 結合相對應的業務邏輯避免常規 LIMIT OFFSET,採用 # 深分頁優化 章節進行修改對應業務
結言
最後有一點需要宣告下,MySQL 本身並不適合單表巨量資料量業務
因為 MySQL 應用在企業級專案時,針對庫表查詢並非簡單的條件,可能會有更復雜的聯合查詢,亦或者是巨量資料量時存在頻繁新增或更新操作,維護索引或者資料 ACID 特性上必然存在效能犧牲
如果設計初期能夠預料到庫表的資料增長,理應構思合理的重構優化方式,比如 ES 配合查詢、分庫分表、TiDB 等解決方式
參考資料:
- 《高效能 MySQL 第三版》
- 《MySQL 實戰 45 講》