關於快取一致性協定、MESI、StoreBuffer、InvalidateQueue、記憶體屏障、Lock指令和JMM的那點事
前言
事情是這樣的,一位讀者看了我的一篇文章,不認同我文章裡面的觀點,於是有了下面的交流。
可能是我發的那個狗頭的表情,讓這位讀者認為我不尊重他。於是,這位讀者一氣之下把我刪掉了,在刪好友之前,還叫我回家種田。

說實話,你說我菜我是承認的,但你要我回家種田,我不理解。為什麼要回家種田呢?養豬不比種田賺錢嗎?
我想了很久沒有想明白,突然,我看到了這個新聞,瞬間明白了讀者的用心良苦。

於是,我決定寫下這篇文章,好好地分析一下讀者提出的幾個問題。
讀者的觀點
針對這位讀者的幾個觀點:
- volatile 關鍵字的底層實現就是 lock 指令
- lock 指令觸發了快取一致性協定
- JMM 靠快取一致性協定保證
我先給出我的看法:
- 第一點我認為是對的,這個我在 volatile 那篇文章也說過,volatile 的底層實現就是 lock 字首指令
- 第二點我認為是錯的
- 第三點我認為是錯的
至於為什麼我會這麼認為,我會說出我的理由,畢竟,我們都是是講道理的人,對不對?

讀者的觀點圍繞「快取一致性協定」,OK,那我們就從快取一致性協定講起!
從字面意思來看,快取一致性協定就是「用來解決 CPU 的快取不一致問題的協定」。將這句話拆開,就會有幾個問題:
- 為什麼 CPU 執行過程中需要快取呢?
- 為什麼快取會出現不一致呢?
- 有哪些方法去解決快取不一致的問題呢?
我們一一分析。
為什麼需要快取
CPU 是個運算器,主要負責運算;
記憶體是個儲存媒介,負責儲存資料和指令;
在沒有快取的年代,CPU 和記憶體是這樣配合工作的:

一句話總結就是:CPU 高速運轉,但取資料的速度非常慢,嚴重浪費了 CPU 的效能。
那怎麼辦呢?
在工程學上,解決速度不匹配的方式主要有兩種,分別是物理適配和空間緩衝。
物理適配很容易理解,多級機械齒輪就是物理適配的典型例子。

至於空間緩衝,更多的被運用在軟硬體上,CPU 多級快取就是經典的代表。
什麼是 CPU 多級快取?
簡單來說就是基於 時間 = 距離 / 速度 這個公式,通過在 CPU 和記憶體之間設定多層快取來減少取資料的距離,讓 CPU 和記憶體的速度能夠更好的適配。

因為快取離 CPU 近,而且結構更加合理,CPU 取資料的速度就縮短了,從而提高了 CPU 的利用率。
同時,因為 CPU 取資料和指令滿足時間區域性性和空間區域性性,有了快取之後,對同一資料進行多次操作時,中間過程可以用快取暫存資料,進一步分攤時間 = 距離 / 速度 中的距離,更好地提高了 CPU 利用率。
時間區域性性:如果一個資訊項正在被存取,那麼在近期它很可能還會被再次存取
空間區域性性:如果一個記憶體的位置被參照,那麼將來他附近的位置也會被參照
快取為什麼會不一致
快取的出現讓 CPU 的利用率得到了大幅地提高。
在單核時代,CPU 既享受到了快取帶來的便利,又不用擔心資料會出現不一致。但這一切的前提建立在「單核」。
多核時代的到來打破了這種平衡。
進入多核時候之後,需要面臨的第一個問題就是:多個 CPU 是共用一組快取還是各自擁有一組快取呢?
答案是「各自擁有一組快取」。
為什麼呢?
我們不妨做個假設,假設多個 CPU 共用一組快取,會出現什麼情況呢?
如果共用一組快取,由於低階快取(離 CPU 近的快取)的空間非常小,多個 CPU 的時間會都花在等待使用低階快取上面,這意味著多個 CPU 變成了序列工作,如果變成序列,那就失去了多核的本質意義——並行。
我們用反證證明了多個 CPU 共用一組快取是行不通的,所以只能讓多個 CPU 各自擁有一組私有快取。
於是,多個 CPU 的快取結構就成了這樣(簡化了多級快取):
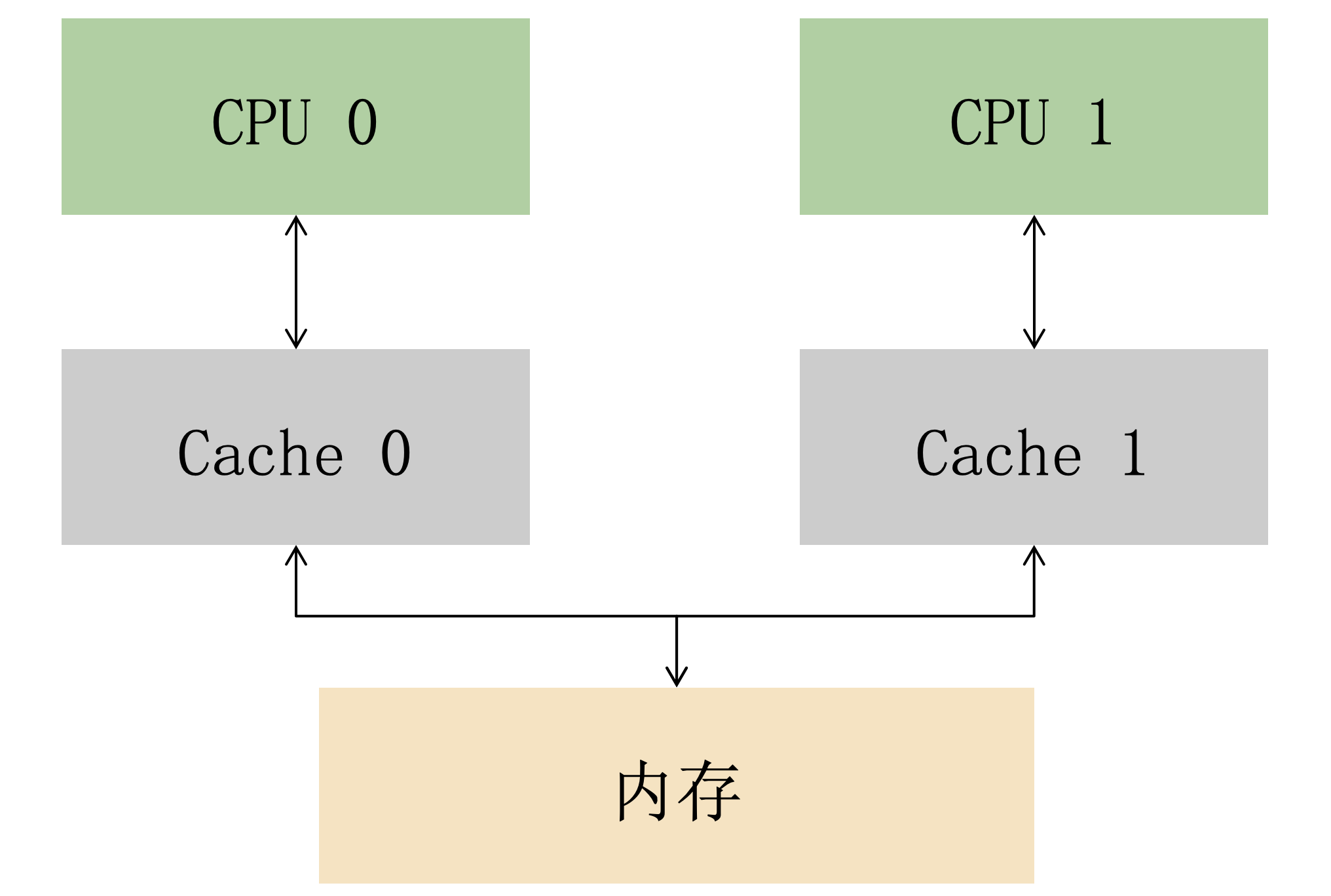
這樣的設計雖然解決了多個處理器搶佔快取的問題,但也帶來了一個新的問題,那就是令人頭疼的資料一致性問題:
具體來說,就是如果多個 CPU 同時用到某份資料,由於多組快取的存在,資料可能會出現不一致。
我們可以看下面這個例子:
- 假設記憶體裡面存著 age=1
- CPU0 執行 age+1 操作
- CPU1 也執行 age+1 操作
如果有多組快取,在並行場景下,可能會出現如下情況:
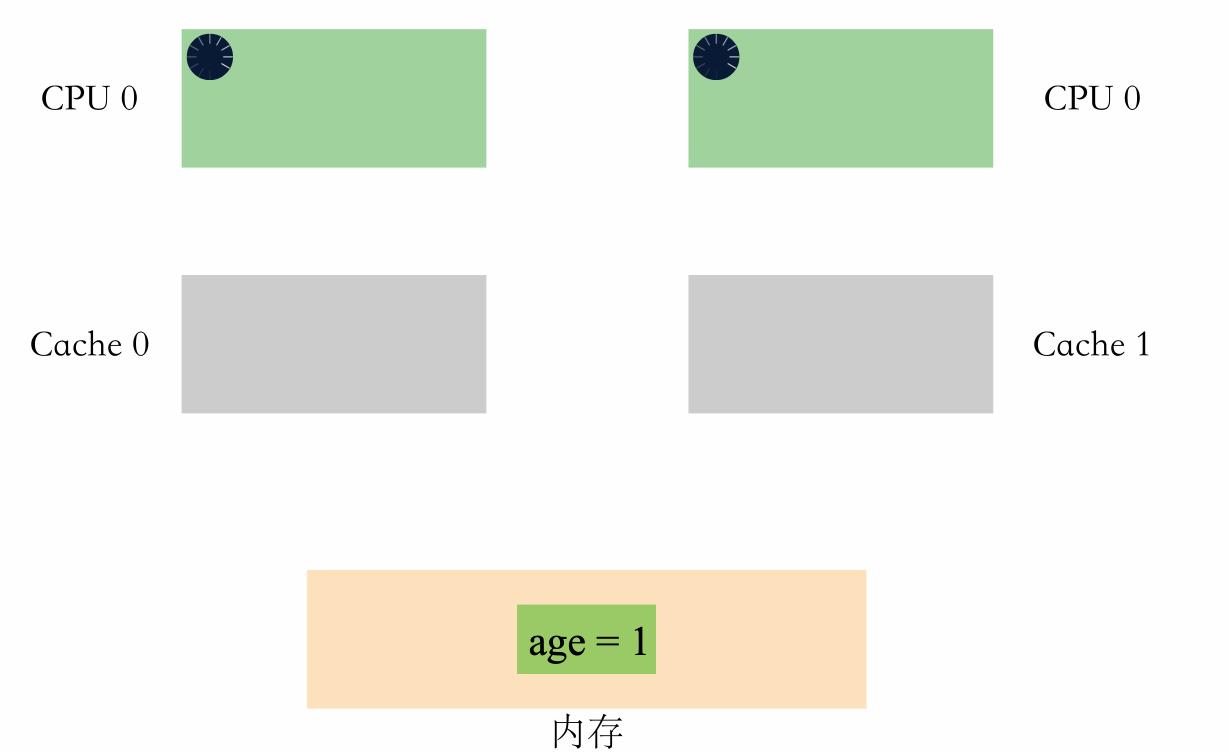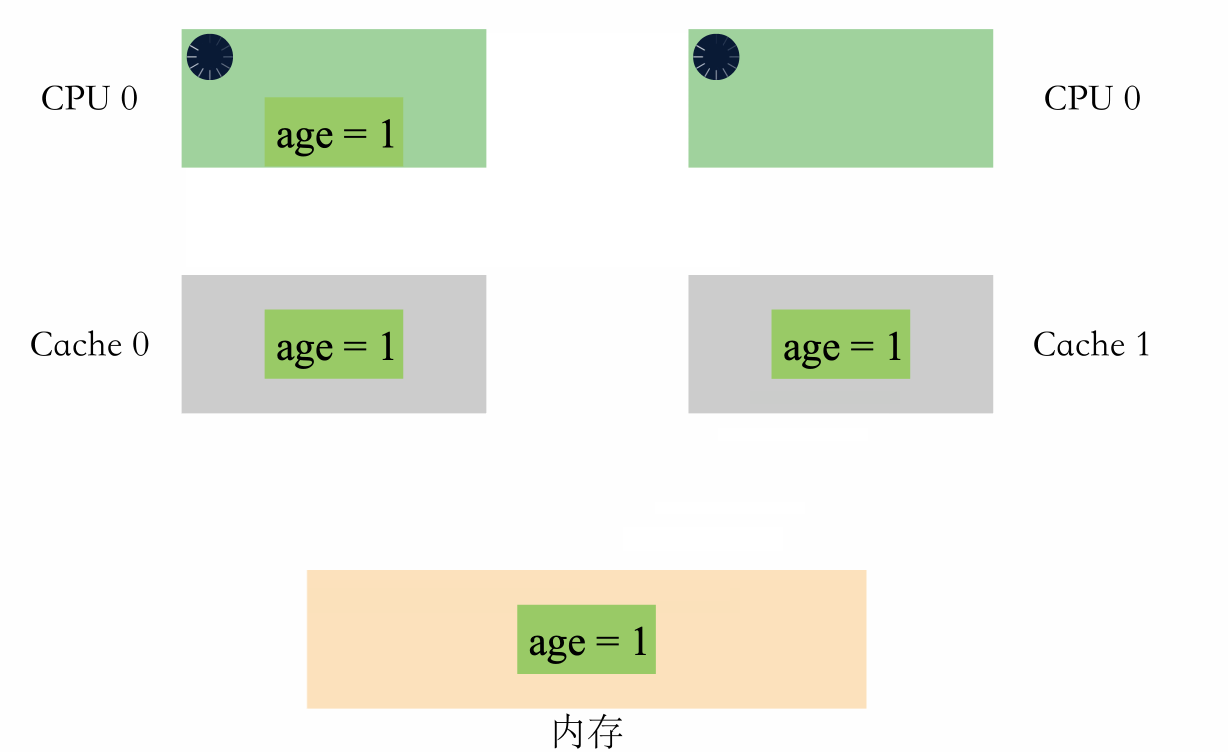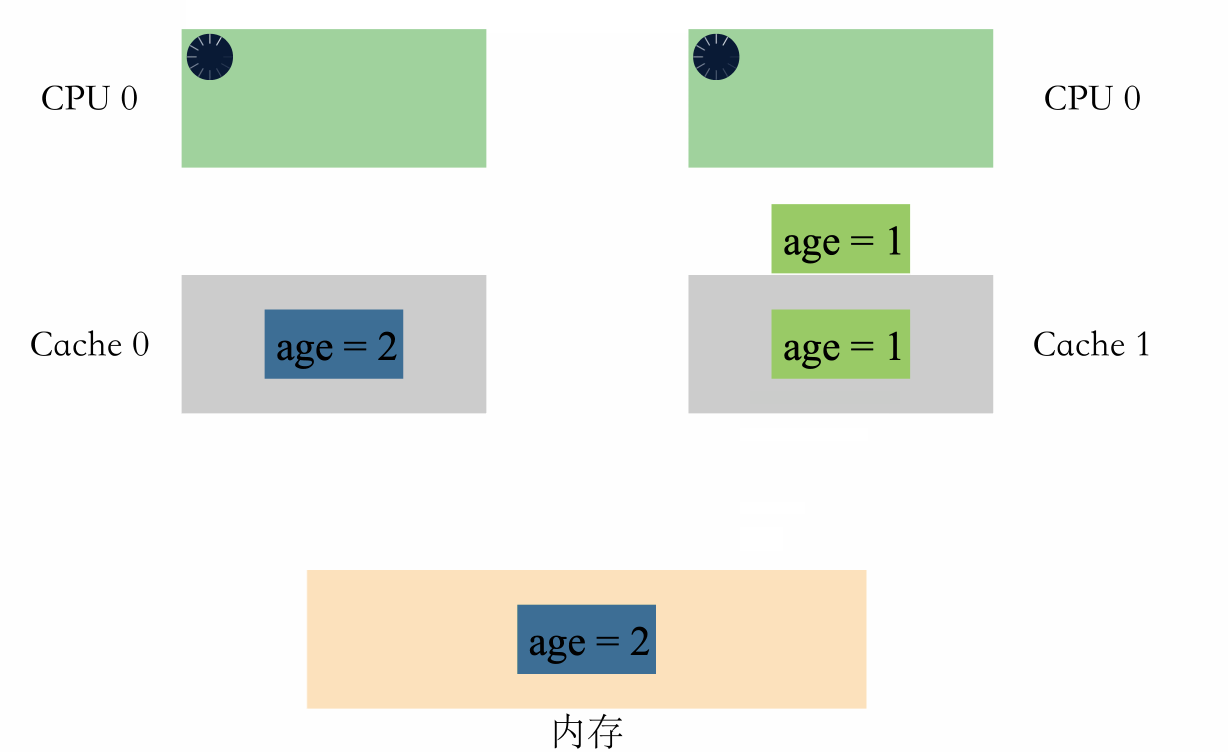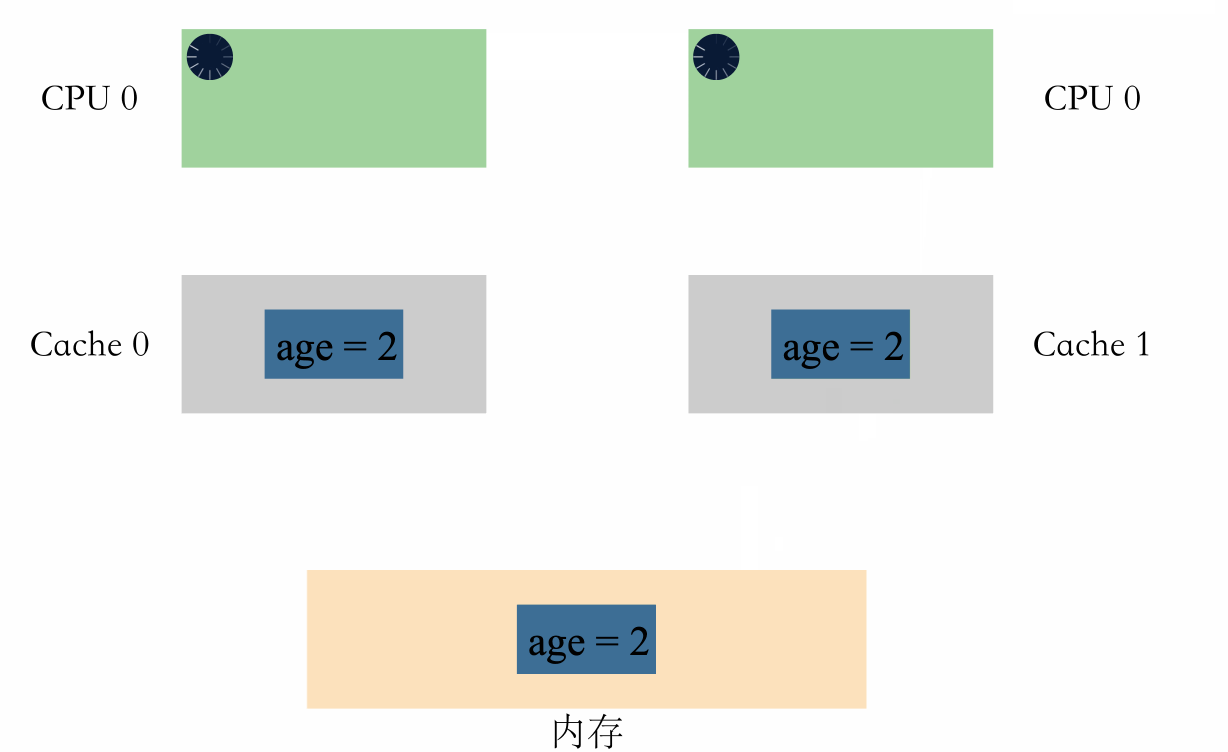
可以看到,兩個 CPU 同時對 age=1 進行加一操作,因為多組快取的原因,CPU 之間無法感知對方的修改,資料出現了不一致,導致最後的結果不是預期的值。
沒有快取也會出現資料一致性問題,只是有快取會變得尤其嚴重。
資料不一致的問題對於程式來說是致命的。所以需要有一種協定,能夠讓多組快取看起來就像只有一組快取那樣。
於是,快取一致性協定就誕生了。
快取一致性協定
快取一致性協定就是為了解決快取一致性問題而誕生,它旨在通過維護多個快取空間中快取行的一致檢視來管理資料一致性。
這裡先補充一下快取行的概念:
快取行(cache line)是快取讀取的最小單元,快取行是 2 的整數冪個連續位元組,一般為 32-256 個位元組,最常見的快取行大小是 64 個位元組。
Linux 系統可以通過cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size命令檢視快取行大小。
Mac 系統可以通過sysctl hw.cachelinesize檢視快取行的大小。

快取行也是快取一致性協定管理的最小單位。
實現快取一致性協定的機制主要有兩種,分別是基於目錄和匯流排嗅探。
基於目錄
什麼是基於目錄?
說直白一點就是用一個目錄去記錄快取行的使用情況,然後 CPU 要使用某個快取行的時候,先通過查目錄獲取此快取行的使用情況,用這樣的方式保證資料一致性。
目錄的格式有六種:
- 全位向量格式(Full bit vector format)
- 粗位向量格式(Coarse bit vector format)
- 稀疏目錄格式(Sparse directory format)
- 數位平衡二元樹格式(Number-balanced binary tree format)
- 鏈式目錄格式(Chained directory format)
- 有限的指標格式(Limited pointer format)
這些目錄的名字花裡胡哨的,實際上並沒有那麼複雜,只是資料結構和優化方式不一樣罷了。
比如全位向量格式就是用位元位(bit)去記錄每個快取行是否被某個 CPU 快取。
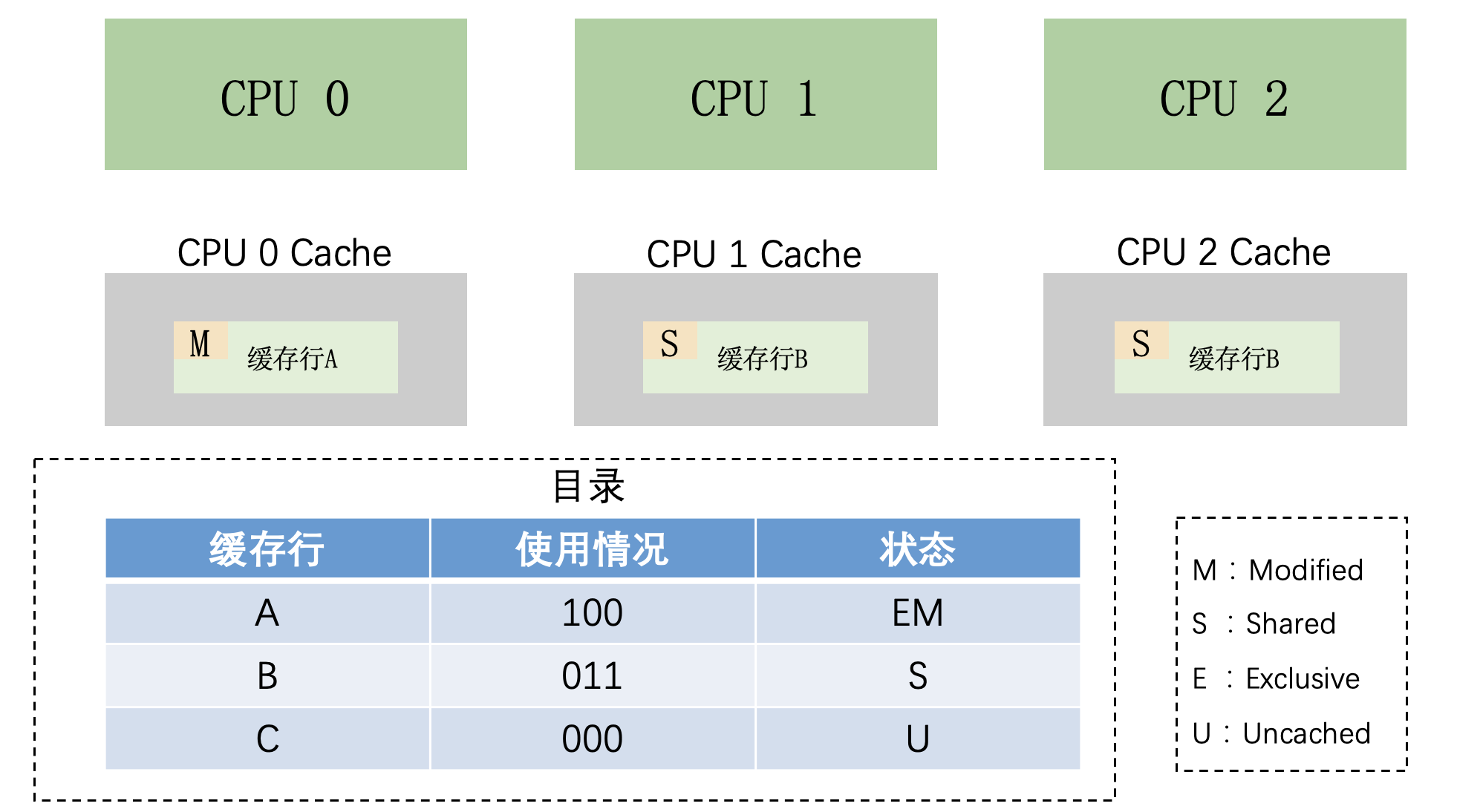
後面幾種格式的目錄,無非是在儲存和可延伸等方面做了一些優化。
記目錄相對於直接訊息通訊來說是比較耗時的,所以基於目錄這種機制實現的快取一致性協定延遲相對來說會偏高。但也有一個好處,第三方目錄的存在讓通訊過程變得簡單,通訊對匯流排頻寬的佔用也會相對偏少。
所以,基於目錄適用於 CPU 核心數量多的大型系統。
匯流排嗅探
基於目錄依賴實現的快取一致性協定雖然頻寬佔用小,但是延遲高,並不適合作為小型的系統的快取一致性解決方案,小型系統更多的是用基於匯流排嗅探的快取一致性協定。
匯流排是 CPU 和記憶體地址和資料互動的橋樑,匯流排嗅探也就是監聽著這座互動橋樑,及時的感知資料的變化。

當 CPU 修改私有快取裡面的資料時,會給匯流排傳送一個事件訊息,告訴匯流排上的其他監聽者這個資料被修改了。
其他 CPU 感知到自己私有的快取中存在某個被修改的資料副本時,可以將快取的副本更新,也可以讓快取的副本失效。
將快取的副本更新會產生巨大的匯流排流量,影響系統的正常執行。所以,在監聽到更新事件時,更多的是將私有的快取副本失效處理,也就是丟棄這個資料副本。
將被修改的資料副本失效的這種方式,有個專業的術語,叫做「寫無效」(Write-invalidate),基於「寫無效」實現的快取一致性協定,叫做「寫無效」協定,常見的 MSI、MESI、MOSI、MOESI 和 MESIF 協定都屬於這一類。
MESI
MESI 協定是一個基於失效的快取一致性協定,是支援寫回(write-back)快取的最常用協定,也是現在一種使用最廣泛的快取一致性協定,它基於匯流排嗅探實現,用額外的兩位給每個快取行標記狀態,並且維護狀態的切換,達到快取一致性的目的。
MESI 狀態
MESI 是四個單詞的縮寫,每個單詞分別代表快取行的一個狀態:
-
M:modified,已修改。快取行與主記憶體的值不同。如果別的 CPU 核心要讀主記憶體這塊資料,該快取行必須回寫到主記憶體,狀態變為共用狀態(S)。
-
E:exclusive,獨佔的。快取行只在當前快取中,但和主記憶體資料一致。當別的快取讀取它時,狀態變為共用;當前寫資料時,變為已修改狀態(M)。
-
S:shared,共用的。快取行也存在於其它快取中且是乾淨的。快取行可以在任意時刻拋棄。
-
I:invalid,無效的。快取行是無效的。
MESI 訊息
MESI 協定中,快取行狀態的切換依賴訊息的傳遞,MESI 有以下幾種訊息:
-
Read: 讀取某個地址的資料。
-
Read Response: Read 訊息的響應。
-
Invalidate: 請求其他 CPU invalid 地址對應的快取行。
-
Invalidate Acknowledge: Invalidate 訊息的響應。
-
Read Invalidate: Read + Invalidate 訊息的組合訊息。
-
Writeback: 該訊息包含要回寫到記憶體的地址和資料。
MESI 通過訊息的傳遞維護了一個快取狀態機,實現共用記憶體,至於細節是怎麼樣的,這裡不做過多表述。
如果你對 MESI 不瞭解的話,我建議你去這個網站動手實驗,可以模擬各種場景,能實時生成動畫,比較好理解。
如果你打不開這個網站,不用著急,原始碼給你扒下來了,回覆「MESI」自取,解壓在本地執行就行了。

下面就用這個網站演示一個簡單的例子:
- CPU0 讀取 a0
- CPU1 寫 a0
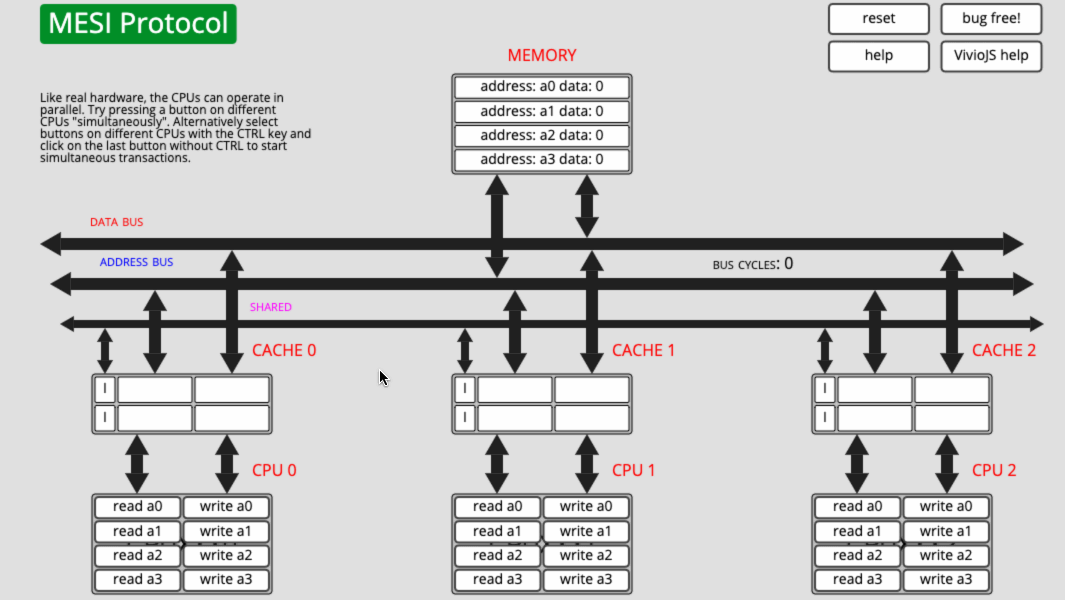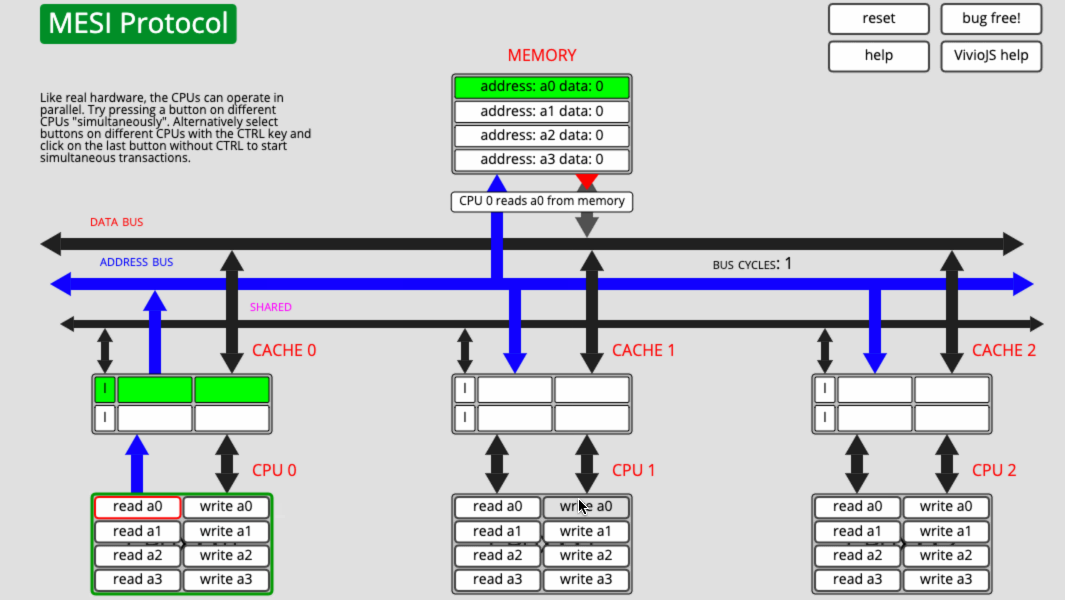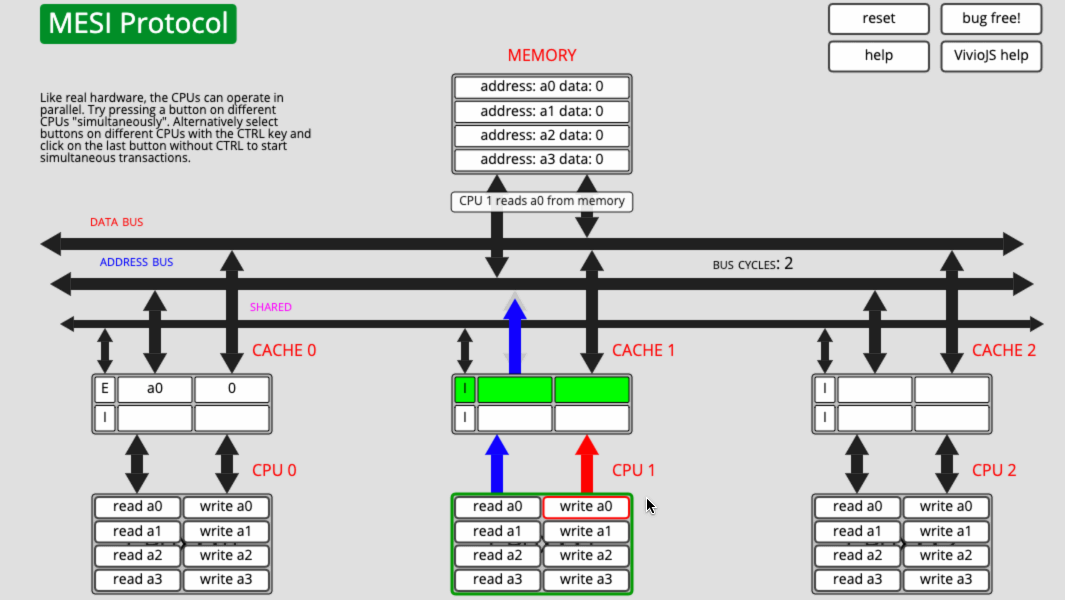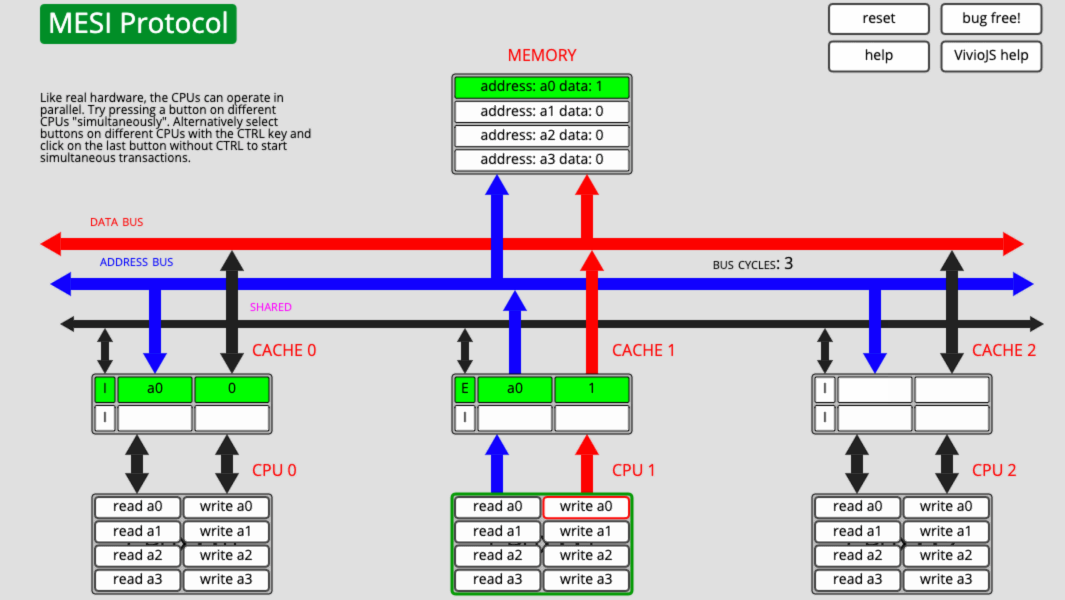
簡單分析一下:
- CPU0 讀取 a0,讀到 Cache0 之後,因為獨佔,所以快取行的狀態是 E。
- CPU2 寫 a0,先把 a0 讀到 Cache2,因為共用,所以狀態是 S。然後修改 a0 的值,快取行的狀態變成了 E,最後通知 CPU0 ,將 a0 所在的快取行失效。
MESI 的存在保證了快取一致性,讓多核 CPU 能夠更好地進行資料互動,那是否意味著 CPU 是否被壓榨到極致了呢?
答案是否定的,我們接著往下看。
文章的後半段依賴前文的知識點,如果我的表述沒讓你理解前半段的知識點,你可以直接翻到總結部分,那裡有我準備好的思路總結。
如果你準備好了,我們繼續開車,看看還能怎麼壓榨 CPU。

Store Buffer
從上文得知:如果 CPU 對某個資料進行寫操作,且這個資料不在私有快取裡,那麼 CPU 就會傳送一個 Read Invalidate 訊息去讀取對應的資料,並讓其他的快取副本失效。
但有一個問題你思考了沒有,那就是從傳送訊息之後,到接收到所有的響應訊息,中間等待過程對於 CPU 來說是漫長的。
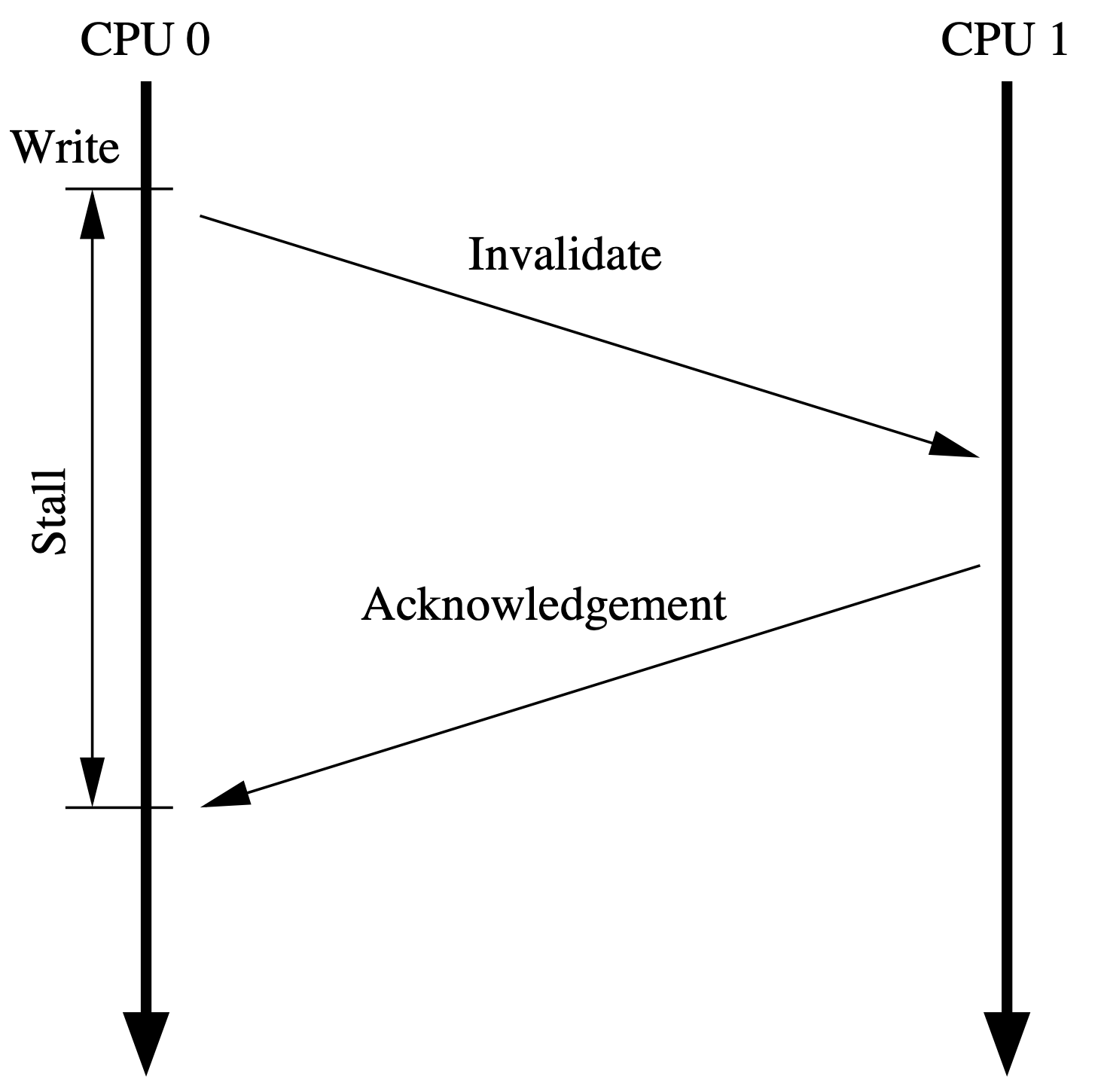
能不能減少 CPU 等待訊息的時間呢?
能!store buffer 就是幹這個的。
具體怎麼幹的呢?
store buffer 是 CPU 和快取中間的一塊結構
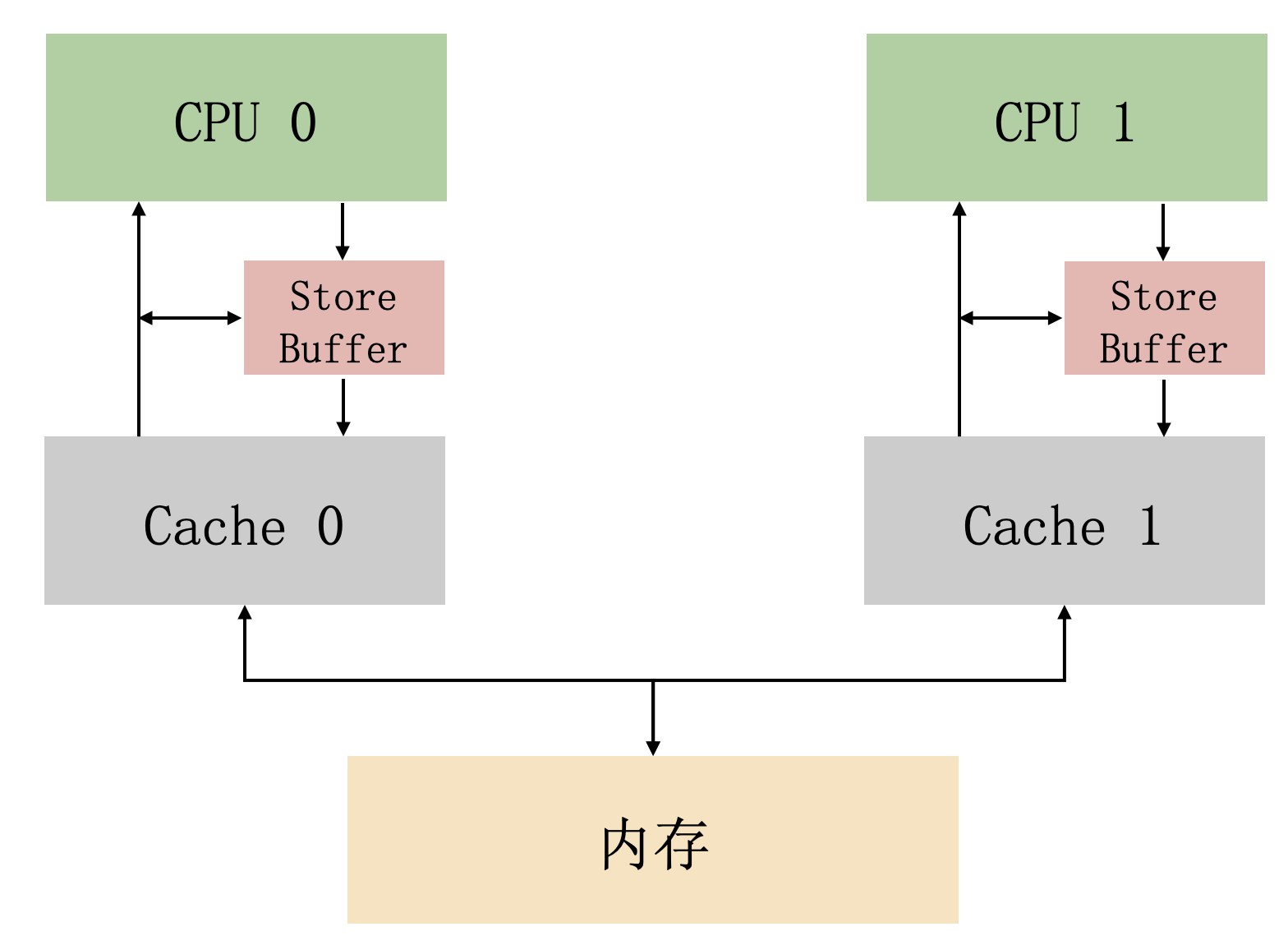
CPU 在寫操作時,可以不等待其他 CPU 響應訊息就直接寫到 store buffer,後續收到響應訊息之後,再把 store buffer 裡面的資料寫入快取行。
CPU 讀資料的時候,也會先判斷一下 store buffer 裡面有沒有資料,如果存在,就優先使用 store buffer 裡面的資料(這個機制,叫做「store forwarding」)。
從而提高了 CPU 的利用率,也能保證了在同一CPU,讀寫都能順序執行。
注意,這裡的讀寫順序執行說的是同一CPU,為什麼要強調同一呢?
因為,store buffer 的引入並不能保證多 CPU 全域性順序執行。
我們看下面這個例子:
// CPU0 執行
void foo() {
a = 1;
b = 1;
}
// CPU1 執行
void bar() {
while(b == 0) continue;
assert(a == 1);
}
假設 CPU0 執行 foo 方法,CPU1 執行 bar 方法,如果在執行之前,快取的情況是這樣的:
- CPU0 快取了 b,因為獨佔,所以狀態是 E。
- CPU1 快取了 a,因為獨佔,所以狀態是 E。

那麼,在有了 store buffer 之後,有可能出現這種情況(簡化了與記憶體互動的過程):
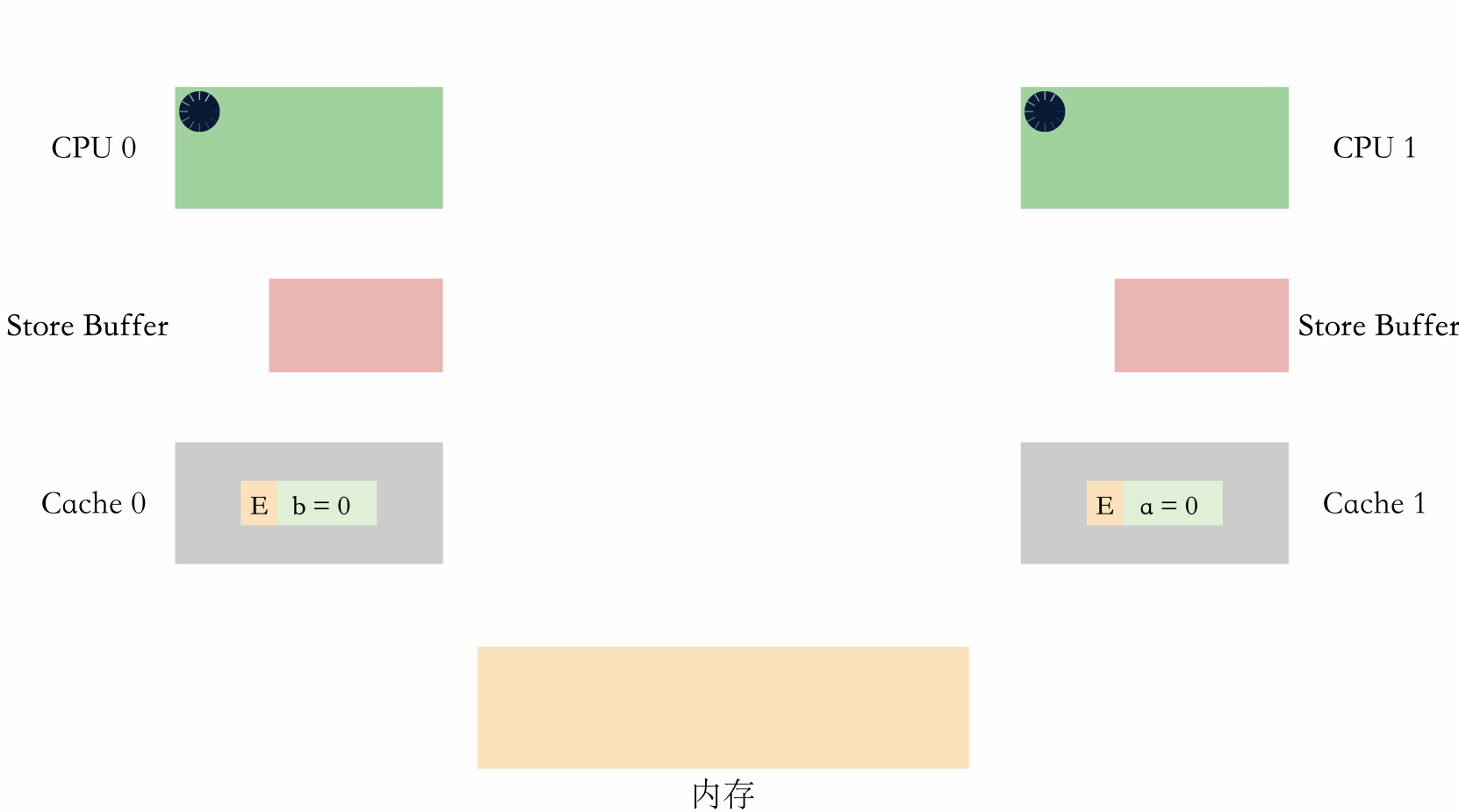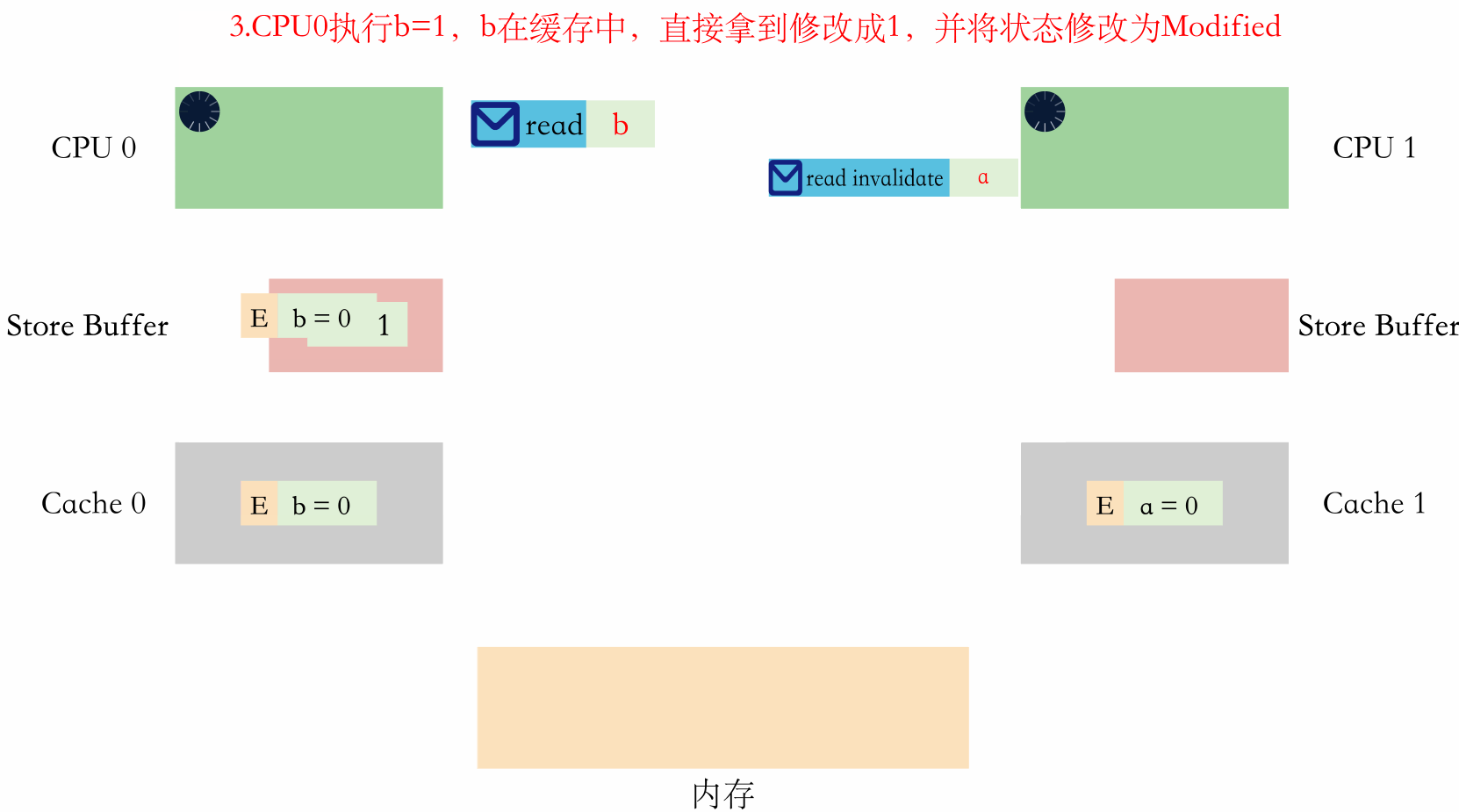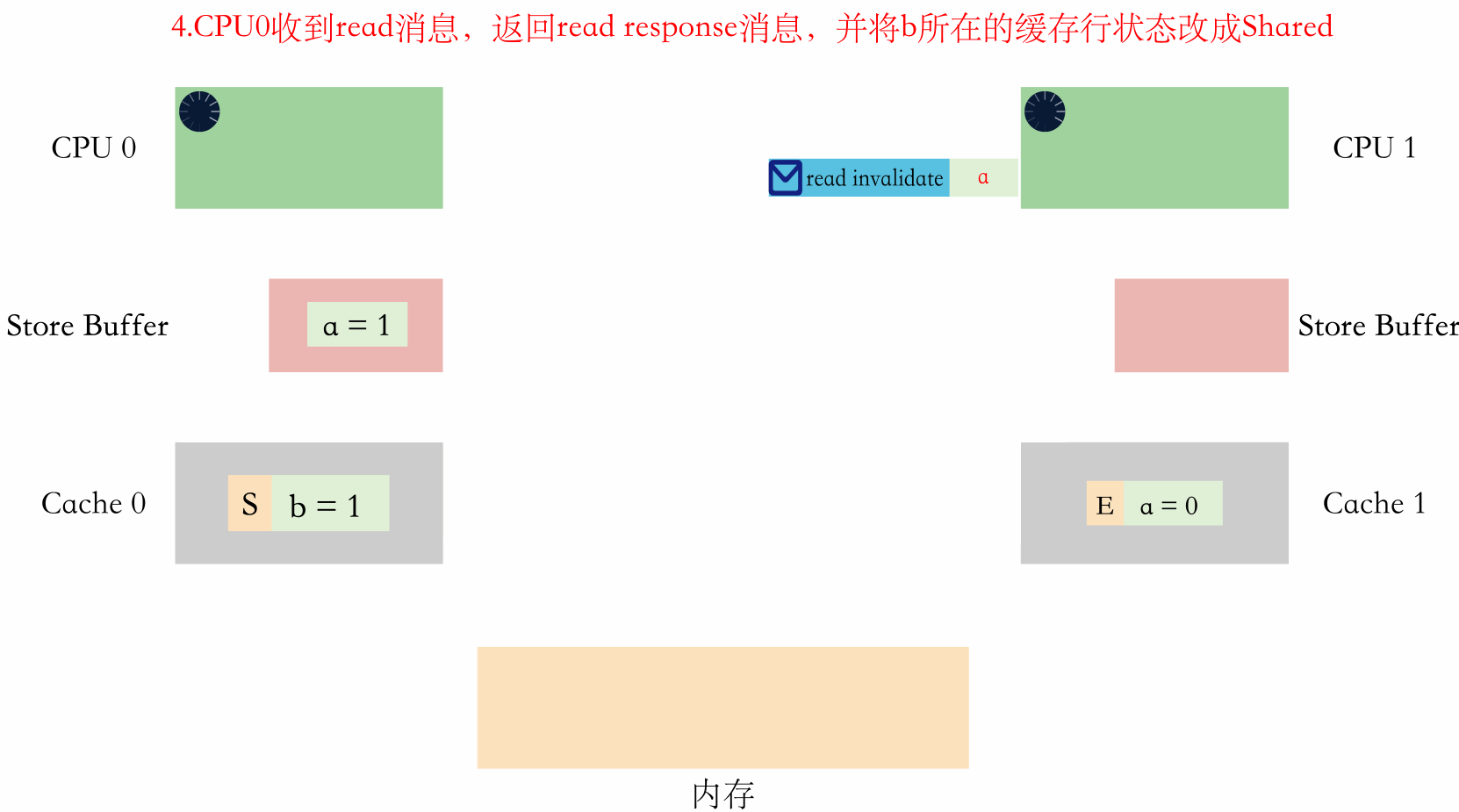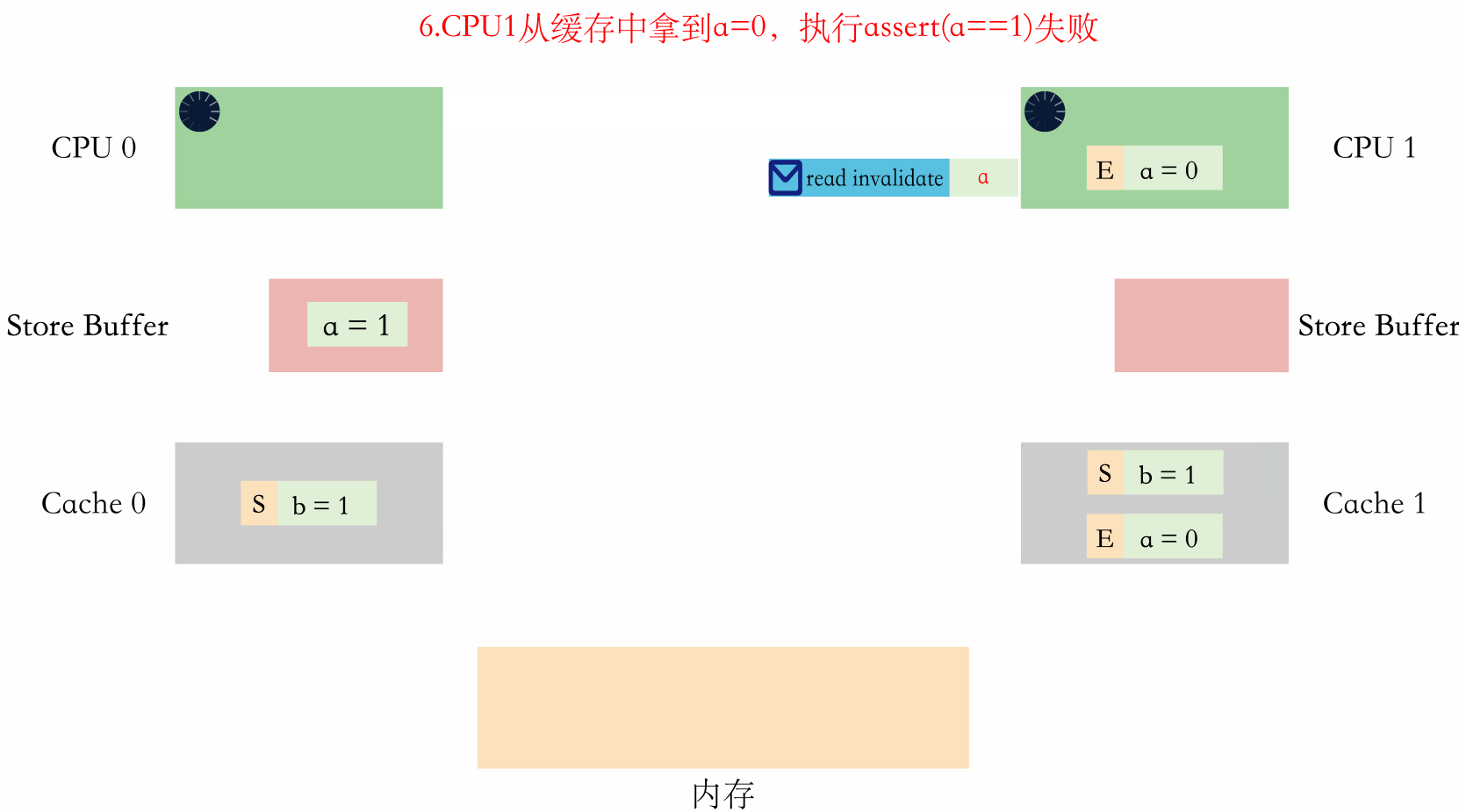
用文字表述就是:
- CPU0 執行 a=1,因為 a 不在 CPU0 的快取中,有 store buffer 的存在,直接寫將 a=1 寫到 store buffer,同時傳送一個 read invalidate 訊息。
- CPU1 執行 while(b==1),因為 b 不在 CPU1 的快取中,所以 CPU1 傳送一個 read 訊息去讀。
- CPU0 收到 CPU1 的 read 訊息,知道 CPU1 想要讀 b,於是返回一個 read response 訊息,同時將對應快取行的狀態改成 S。
- CPU1 收到 read response 訊息,知道 b=1,於是將 b=1 放到快取,同時結束 while 迴圈。
- CPU1 執行 assert(a==1),從快取中拿到 a=0,執行失敗。
我們站在不同的角度分析分析:
-
站在 CPU0 的角度看自己:a = 1 先於 b = 1,所以 b = 1 的時候 a 一定已經等於 1 了。
-
站在 CPU0 的角度看 CPU1:因為 b = 1 的時候 a 一定等於 1,所以 CPU1 因為 b == 1 跳出迴圈的時候,接下來執行 assert 一定為成功,但是實際上失敗了,也就是說站在 CPU0 的角度,CPU1 發生了重排序。
那如何解決 store buffer 的引入帶來的全域性順序性問題呢?
硬體設計師給開發者提供了記憶體屏障(memory-barrier)指令,我們只需要使用記憶體屏障將程式碼改造一下,在 a = 1 後面加上 smp_mb(),就能消除 store buffer 的引入帶來的影響。
// CPU0 執行
void foo() {
a = 1;
smp_mb();
b = 1;
}
// CPU1 執行
void bar() {
while(b == 0) continue;
assert(a == 1);
}
記憶體屏障是如何做到全域性順序性的呢?
有兩種方式,分別是等 store buffer 生效和進 store buffer 排隊。
等 store buffer 生效
等 store buffer 生效就是記憶體屏障後續的寫必須等待 store buffer 裡面的值都收到了對應的響應訊息,都被寫到快取行裡面。

進 store buffer 排隊
進 store buffer 排隊就是記憶體屏障後續的寫直接寫到 store buffer 排隊,等 store buffer 前面的寫全部被寫到快取行。

從動圖上可以看出,兩種方式都需要等,但是等 store buffer 生效是在 CPU 等,而進 store buffer 排隊是進 store buffer 等。
所以,進 store buffer 排隊也會相對高效一些,大多數的系統採用的也是這種方式。
Invalidate Queue
記憶體屏障能解決 store buffer 帶來的全域性順序性問題。但有一個問題,store buffer 容量非常小,如果在其他 CPU 繁忙的時候響應訊息的速度變慢,store buffer 會很容易地被填滿,會直接的影響 CPU 的執行效率。
怎麼辦呢?
這個問題的根源是響應訊息慢導致 store buffer 被填滿,那能不能提高訊息響應速度呢?
能!invalidate queue 出現了。
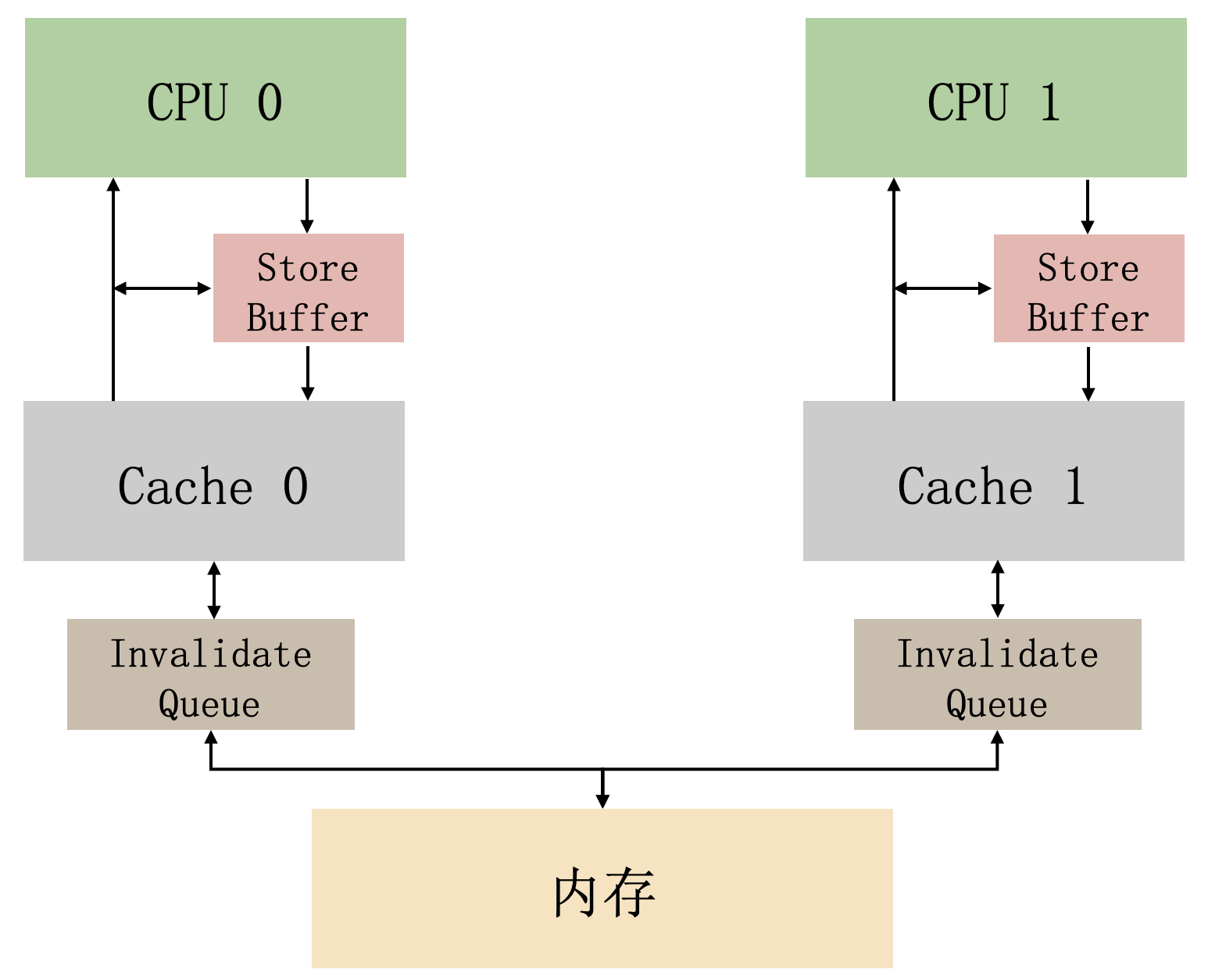
invalidate queue 的主要作用就是提高 invalidate 訊息的響應速度。
有了 invalidate queue 之後,CPU 在收到 invalidate 訊息時,可以先不講對應的快取行失效,而是將訊息放入 invalidate queue,立即返回 Invalidate Acknowledge 訊息,然後在要對外傳送 invalidate 訊息時,先檢查 invalidate queue 中有無該快取行的 Invalidate 訊息,如果有的話這個時候才處理 Invalidate 訊息。
invalidate queue 雖然能加快 invalidate 訊息的響應速度,但是也帶了全域性順序性問題,這個和 store buffer 帶來的全域性性問題類似。
看下面這個例子:
// CPU0 執行
void foo() {
a = 1;
smp_mb();
b = 1;
}
// CPU1 執行
void bar() {
while(b == 0) continue;
assert(a == 1);
}
上面這段程式碼,還是假設 CPU0 執行 foo 方法,CPU1 執行 bar 方法,如果在執行之前,快取的情況是這樣的:
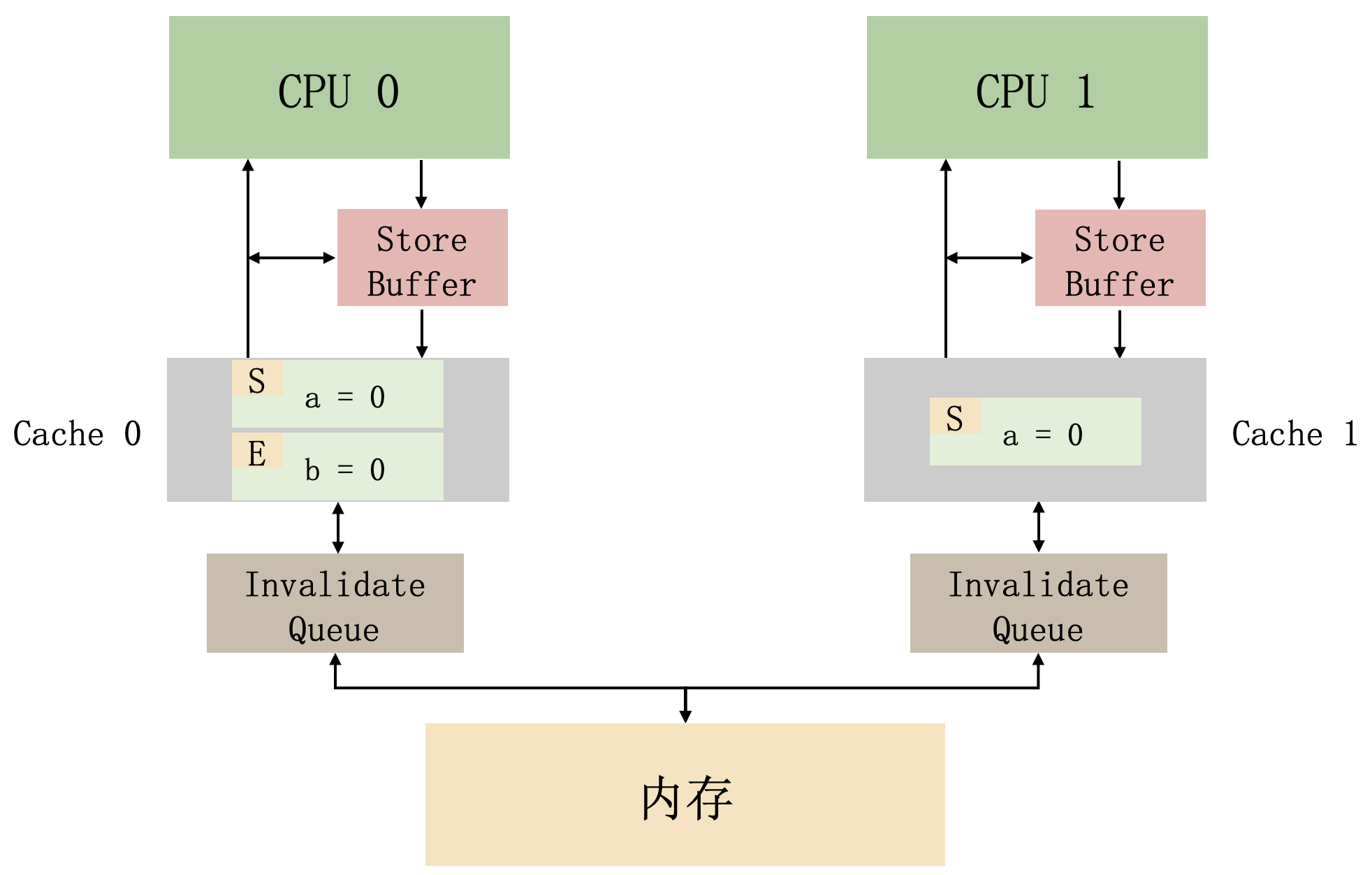
那麼,在有了 invalidate queue 之後,有可能出現這種執行情況:
- CPU0 執行 a=1。對應的快取行在 cpu0 的快取中是唯讀的,所以 cpu0 把新值 a=1 放在了它的 store buffer 中,並行送了一個 invalidate 訊息,以便從 cpu1 的 cache 中重新整理對應的快取行。
- 當(b==0)繼續執行時,CPU1 執行,但是包含 b 的快取行不在它的快取中。因此,它傳送一個 read 訊息。
- CPU0 執行 b=1。因為已經快取了這個快取行,所以直接更新快取行,將 b=0 更新成 b=1。
- CPU0 接收到 read 訊息,並將包含 b 的快取行傳送給 CPU1,同時 b 所在快取行的狀態改成 S。
- CPU1 接收到 a 的 invalidate 訊息,將其放入自己的 invalidate 佇列,並向 CPU0 傳送一個 invalidate 確認訊息。注意,原來的值「a」仍然儲存在 CPU1 的快取中。
- CPU1 接收到包含 b 的快取行,並將其寫到它的快取中。
- CPU1 現在可以在(b==0)繼續時完成執行,因為它發現 b 的值是 1,它繼續執行下一條語句。
- CPU1 執行 assert(a==1),由於原來的值 a 仍然在 CPU1 的快取中,所以斷言失敗了。
- cpu1 處理佇列中 invalidate 的訊息,並從自己的 cache 中使包含 a 的 cache 行失效。但是已經太遲了。
從這個例子可以看出,在引入 invalidate queue 之後,全域性順序性又得不到保障了。
怎麼解決呢,和 store buffer 的解決辦法是一樣的,用記憶體屏障改造程式碼:
// CPU0 執行
void foo() {
a = 1;
smp_mb();
b = 1;
}
// CPU1 執行
void bar() {
while(b == 0) continue;
smp_mb();
assert(a == 1);
}
改造之後的執行過程不做過多表述,但總結來說就是記憶體屏障可以解決 invalidate queue 帶來的全域性順序性問題。
記憶體屏障和 Lock 指令
記憶體屏障
從上文得知,記憶體屏障有兩個作用,處理 store buffer 和 invalidate queue,保持全域性順序性。
但很多情況下,只需要處理 store buffer 和 invalidate queue 中的其中一個即可,所以很多系統將記憶體屏障細分成了讀屏障(read memory barrier)和寫屏障(write memory barrier)。
讀屏障用於處理 invalidate queue,寫屏障用於處理 store buffer。
以場景的 X86 架構下,不同的記憶體屏障對應的指令分別是:
-
讀屏障:lfence
-
寫屏障:sfence
-
讀寫屏障:mfence
Lock 指令
我們再回顧一下,在上一篇講 volatile 的文章中,我提到了 volatile 關鍵字的底層實現是 lock 字首指令。
lock 字首指令和記憶體屏障到底有什麼關係呢?
我認為是沒有什麼關係的。
只不過 lock 字首指令一部分功能能達到記憶體屏障的效果罷了。
這一點在《IA-32 架構軟體開發人員手冊》上也能找到對應的描述。

手冊上給 lock 字首指令的定義是匯流排鎖,也就是 lock 字首指令是通過鎖住匯流排保證可見性和禁止指令重排序的。
雖然「匯流排鎖」的說法過於老舊了,現在的系統更多的是「鎖快取行」。但我想表達的是,lock 字首指令的核心思想還是「鎖」,這和記憶體屏障有著本質的區別。
回顧問題
我們再來回顧讀者的這兩個觀點:
- 讀者:lock 指令觸發了快取一致性協定
- 讀者:JMM 靠快取一致性協定保證
對於第一個觀點,我的看法是:
lock 字首指令的作用是鎖住快取行,能起到和讀寫屏障一樣的效果,而讀寫屏障解決的問題是 store buffer 和 invalidate queue 帶來的全域性順序性問題。
快取性一致性問題是用來解決多核系統下的快取一致性問題,是由硬體來保證的,對軟體來說是透明的,伴生於多核系統,是一個客觀存在的東西,並不需要觸發。
對於第二個觀點,我的看法是:
JMM 是一個虛擬的記憶體模型,它抽象了 JVM 的執行機制,讓 Java 開發人員能更好的理解 JVM 的執行機制,它封裝了 CPU 底層的實現,讓 Java 的開發人員可以更好的進行開發,不被底層的實現細節折磨。
JMM 想表達的是,在某種程度上,你可以通過一些 Java 關鍵字讓 Java 的記憶體模型達到一種強一致性。
所以 JMM 和快取一致性協定並不掛鉤,本質上就沒什麼聯絡。舉個例子,你不能因為你單身,然後劉亦菲也單身,你就說劉亦菲單身是因為在等你。
總結
本文對一些沒有基礎的同學來說,理解起來會稍微吃力一點,所以我們總結一下全文的一個思路,應付應付普通面試是沒什麼問題的。
- 因為記憶體的速度和 CPU 匹配不上,所以在記憶體和 CPU 之間加了多級快取。
- 單核 CPU 獨享不會出現資料不一致的問題,但是多核情況下會有快取一致性問題。
- 快取一致性協定就是為了解決多組快取導致的快取一致性問題。
- 快取一致性協定有兩種實現方式,一個是基於目錄的,一個是基於匯流排嗅探的。
- 基於目錄的方式延遲高,但是佔用匯流排流量小,適合 CPU 核數多的系統。
- 基於匯流排嗅探的方式延遲低,但是佔用匯流排流量大,適合 CPU 核數小的系統。
- 常見的 MESI 協定就是基於匯流排嗅探實現的。
- MESI 解決了快取一致性問題,但是還是不能將 CPU 效能壓榨到極致。
- 為了進一步壓榨 CPU,所以引入了 store buffer 和 invalidate queue。
- store buffer 和 invalidate queue 的引入導致不滿足全域性有序,所以需要有寫屏障和讀屏障。
- X86 架構下的讀屏障指令是 lfenc,寫屏障指令是 sfence,讀寫屏障指令是 mfence。
- lock 字首指令直接鎖快取行,也能達到記憶體屏障的效果。
- x86 架構下,volatile 的底層實現就是 lock 字首指令。
- JMM 是一個模型,是一個便於 Java 開發人員開發的抽象模型。
- 快取性一致性協定是為了解決 CPU 多核系統下的資料一致性問題,是一個客觀存在的東西,不需要去觸發。
- JMM 和快取一致性協定沒有一毛錢關係。
- JMM 和 MESI 沒有一毛錢關係。
寫在最後
這篇文章, 主要參考了維基百科和 Linux 核心大牛 Paul E. McKenney 的論文以及書籍,如果你想對並行程式設計的底層有更深入的研究,Paul E. McKenney 的論文和書籍非常值得一看,有需要的後臺回覆「MESI」自取。
因為筆者水平有限,文章中難免會有錯誤,如果你發現了,歡迎指出!
好了,今天的文章就到這裡結束了,我是小汪,我們下期再見!
參考資料
- 《深入理解並行程式設計》
- 《IA-32+架構軟體開發人員手冊》
- 《Memory Barriers: a Hardware View for Software Hackers》
- 《Is Parallel Programming Hard, And, If So, What Can You Do About It?》
