論文閱讀 Real-Time Streaming Graph Embedding Through Local Actions 11
9 Real-Time Streaming Graph Embedding Through Local Actions 11
Abstract
現有的方法要麼依賴於頂點屬性的知識,要麼承受較高的時間複雜度,要麼需要重新訓練,沒有封閉解(解釋見https://www.zhihu.com/question/51616557)。作者提出了一種流式方法做動態圖的架構,模型流程遵循三個步驟:(1)識別受新到達頂點影響的頂點,(2)為新頂點生成潛在特徵,(3)更新受影響最嚴重頂點的潛在特徵。
Conclusion
提出了一個高效的線上表示學習框架,其中新的頂點和邊作為流更新模型。該框架的靈感來自於增量逼近一個構造的約束優化問題的解,這個解在結果表示中保持時間平滑和結構近似,且逼近解為封閉解、效率高、複雜度低,並且在正交約束下仍然可行。
Figure and table

表1 各演演算法直接的對照
其中
1 : William L Hamilton, Rex Ying, and Jure Leskovec. Representation learning on graphs: Methods and applications. IEEE Data Engineering Bulletin, 2017.
13 :Xi Liu, Muhe Xie, Xidao Wen, Rui Chen, Yong Ge, Nick Duffield, and Na Wang.A semi-supervised and inductive embedding model for churn prediction of largescale mobile games. In IEEE International Conference on Data Mining (ICDM), 2018.
17:Jundong Li, Harsh Dani, Xia Hu, Jiliang Tang, Yi Chang, and Huan Liu. Attributed network embedding for learning in a dynamic environment. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, pages 387–396, 2017.
18:Ling Jian, Jundong Li, and Huan Liu. Toward online node classification on streaming networks. Data Mining and Knowledge Discovery, 32(1):231–257, 2018.
19:Dingyuan Zhu, Peng Cui, Ziwei Zhang, Jian Pei, and Wenwu Zhu. High-order proximity preserved embedding for dynamic networks. IEEE Transactions on Knowledge and Data Engineering, 2018.
14:Jianxin Ma, Peng Cui, and Wenwu Zhu. Depthlgp: Learning embeddings of out-of-sample nodes in dynamic networks. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, pages 370–377, 2018.
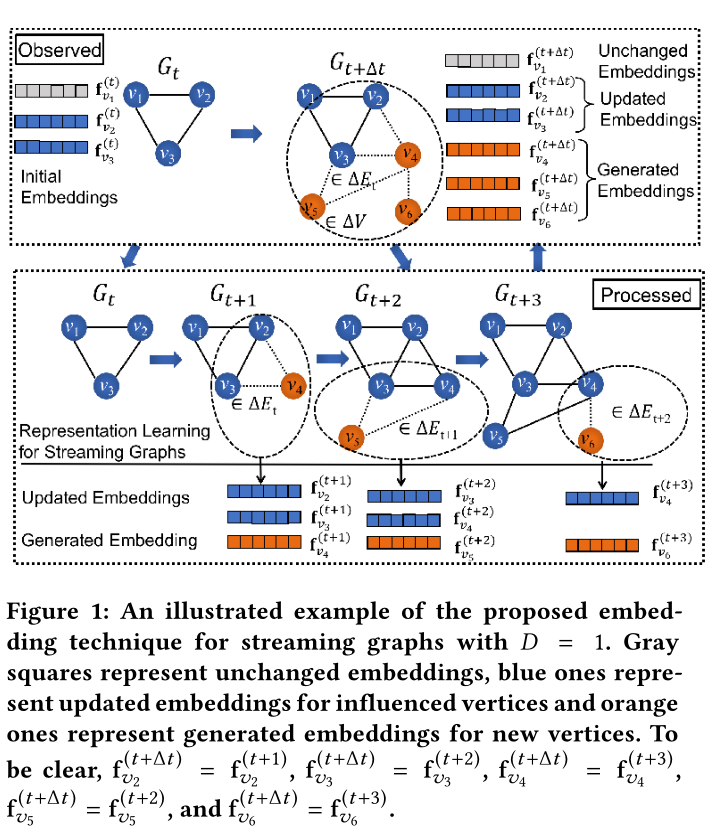
圖1 模型的嵌入演示(D=1,則為一跳鄰居更新節點嵌入)

表2 符號解釋
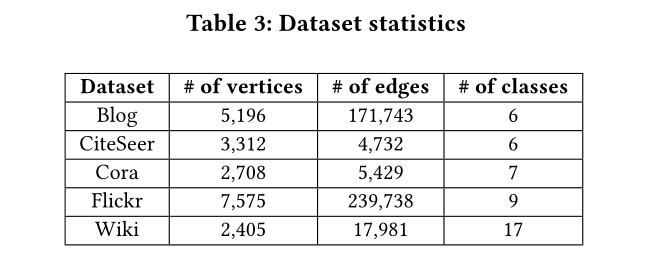
表3 資料集引數
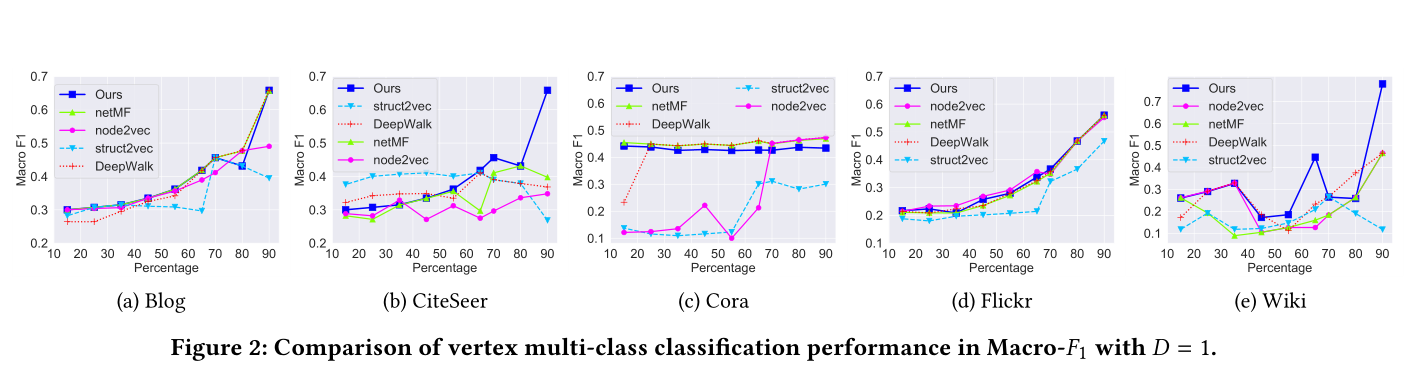
圖2 D = 1的Macro-F1頂點多類分類效能比較
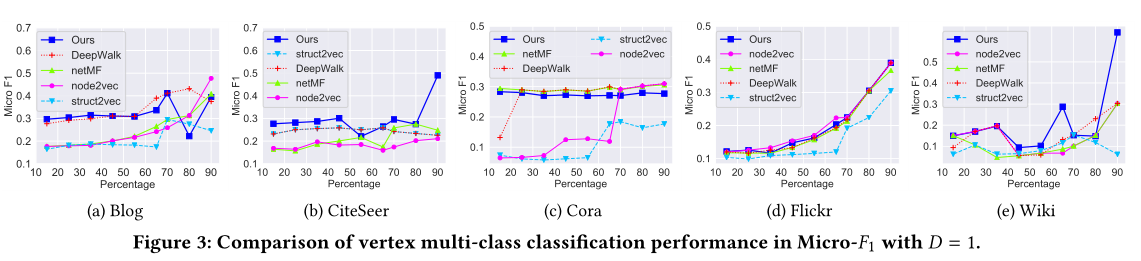
圖3 D = 1的Micro-F1頂點多類分類效能比較。
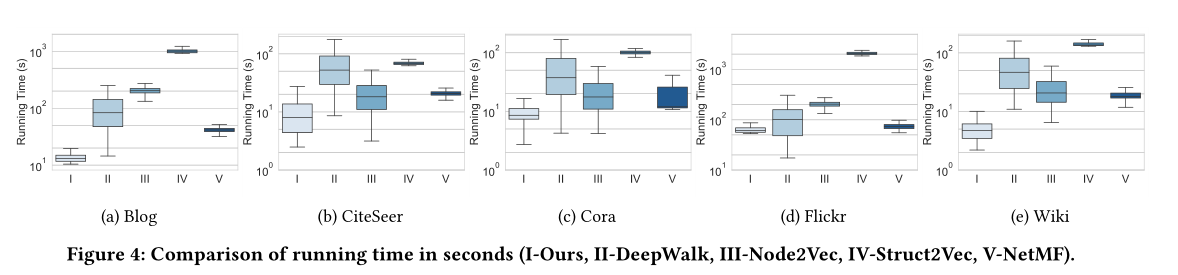
圖4 執行時間對比
表4 聚類效果對比
Introduction
先前的研究已經提出了幾種著名的圖嵌入方法。不幸的是,它們受到三個限制。
首先,這些方法主要關注靜態圖。然而,現實世界中的大多數網路自然是動態的,並不斷增長。新的頂點,以及它們的部分邊,以流的方式形成。這樣的網路通常被稱為流網路。這些方法忽略了網路的動態特性,不能根據網路的演化來更新頂點的嵌入。
其次,這些方法要求圖中的所有頂點在訓練過程中都存在,從而生成它們的嵌入,因此不能生成未見頂點的嵌入。在不斷遇到新頂點的串流媒體網路中,歸納能力對於支援各種機器學習應用至關重要。
第三,在這些方法中,再訓練的時間複雜度通常隨頂點數量的增加而線性增加。這使得通過再訓練對上述方法進行簡單調整的計算成本很高,更不用說收斂的不確定性了。事實上,最近少數幾個採用上述方法的研究要麼要求對新頂點屬性的先驗知識進行歸納,要麼要求對新圖進行再訓練。事實上,串流媒體網路的結構可能不會在短時間內發生實質性的變化,並且對整個圖進行再訓練通常是不必要的。
作者提出了一個約束優化模型來使得流表示保持時間平滑和結構近似。
我們將流圖嵌入任務分為三個子任務:
1.識別受新頂點影響最大的原始頂點、
2.計算新頂點的嵌入
3.調整受新頂點影響的原始頂點的嵌入
由於流圖在較短時間內的變化量相對於整個網路而言較小,因此該演演算法只更新了一小部分頂點的表示
貢獻
(1)基於約束優化模型,提出了一種新的流圖線上表示學習框架。模型同時考慮了時間平滑性和結構接近性。框架能夠在不知道其屬性的情況下計算不可見頂點的表示。
(2)設計了一種近似演演算法,能夠實時生成以流方式到達的頂點的表示,它不需要對整個網路進行再訓練,也不需要進行額外的梯度下降。
(3)sota
Method
3 PROBLEM FORMULATION
對於流式圖,記每次出現的新頂點和邊的時間間隔為\(t_{0}+i \Delta t\)和\(t_{0}+(i+1) \Delta t\)之間,其中\(i \in \{ 0,1,... \}\)。其中\(t_0\)為初始時間,\(∆t\)為區間寬度。本文將使用\(t_i\)作為\(t_0 + i \Delta t\)的簡寫。在任意的一個時間間隔\(\Delta t\)內,可以出現任意次的節點和邊。令\(\mathcal{G}_{t_{i}}=\left(\mathcal{V}_{t_{i}}, \mathcal{E}_{t_{i}}\right)\)表示在時間\({t_i}\)之前形成的頂點\(\mathcal{V}_{t_{i}}\)和邊\(\mathcal{E}_{t_{i}}\)組成的圖。設\(\Delta \mathcal{V}_{t_{i}}\)和\(\Delta \mathcal{E}_{t_{i}}\)為在時間\({t_i}\)和時間\({t_{i+1}}\)之間形成的頂點及其邊。對於任意時刻\(t_i\),將頂點\(\Delta \mathcal{V}_{t_{i}}\)和邊\(\Delta \mathcal{E}_{t_{i}}\)新增到圖\(\mathcal{G}_{t_{i}}\)中,將在時刻\({t_{i+1}}\)得到新的圖\(\mathcal{G}_{t_{i+1}}\)。
例如,見圖1(上方Observed)。在時間\(t_{0}\)和\(t_{1}\)之間新增頂點\(v_4、v_5、v_6\)和它們的邊(用虛線表示)就會從\(\mathcal{G}_{t_{0}}\)得到\(\mathcal{G}_{t_{1}}\)。
令\(\mathbf{f}_{v}^{\left(t_{i}\right)} \in \mathbb{R}^{k}\)為頂點\(v \in \mathcal{V}_{t_{i}}\)的嵌入表示,其中巢狀尺寸\(k≪|V_{t_i} |\)。那麼在任意時刻\({t_i}\)之前到達的頂點的嵌入集合記為\(\left\{\mathbf{f}_{v}^{\left(t_{i}\right)}\right\}_{v \in \mathcal{V}_{t_{i}}}\)
本文的目標是對新頂點採用實時、低複雜度、高效的方法生成嵌入表示。現在我們可以使用表2中描述的符號,正式定義流圖的實時表示學習問題如下:
定義1:在\(t_0\)時刻初始化一個可能為空的圖\(\mathcal{G}_{t_{0}}=\left(\mathcal{V}_{t_{0}}, \mathcal{E}_{t_{0}}\right)\)。從\(i = 0\)開始,從時間\({t_i}\)和時間\({t_{i+1}}\)之間,在圖\(\mathcal{G}_{t_{i}}\)中形成一組頂點\(\Delta \mathcal{V}_{t_{i}}\)和相關邊\(\Delta \mathcal{E}_{t_{i}}\),並在時間\(t_i\)生成一個新的圖\(\mathcal{G}_{t_{i+1}}\)。在任意時刻\((t_{i+1}, i∈N)\),(1)為新頂點\(\Delta \mathcal{V}_{t_{i}}\)生成表示\(\left\{\mathbf{f}_{v}^{\left(t_{i+1}\right)}\right\}_{v \in \Delta\mathcal{V}_{t_{i}}}\),(2)將現有頂點\(\mathcal{V}_{t_{i}}\)的表示\(\left\{\mathbf{f}_{v}^{\left(t_{i}\right)}\right\}_{v \in \mathcal{V}_{t_{i}}}\)更新為\(\left\{\mathbf{f}_{v}^{\left(t_{i+1}\right)}\right\}_{v \in \mathcal{V}_{t_{i}}}\)。
4 METHODS
在本節中,首先簡單介紹基於譜理論的靜態圖表示學習,然後介紹本文的流圖模型。證明了該模型屬於一類具有正交約束的二次優化問題,沒有一般的封閉解。本文提出了一種低複雜度、高效率、實時性好的近似解。近似解由三個步驟組成:(1)識別受新頂點到達影響最大的頂點;(2)生成新頂點的表示;(3)調整受影響頂點的表示。近似解的靈感來自斯蒂弗爾流形上的線搜尋方法,並影響擴散過程。
4.1 Static Graph Representation Learning
對於一個靜態圖\(\mathcal{G}=(\mathcal{V}, \mathcal{E})\),其中\(\mathcal{V}=\left\{v_{1}, v_{2}, . ., v_{|\mathcal{V}|}\right\}\),\(\mathcal{E}\)中的每條邊都由它的兩端表示,即\((v_i,v_j)\)。基於譜理論的圖表示[20]的目標是保持兩個連通頂點的表示接近,這是圖同質性的反映。用\(A\)表示\(\mathcal{G}\)的鄰接矩陣,當\((v_i,v_j)∈\mathcal{E}\)時,\(A(i, j) = 1\),否則,\(A(i, j) = 0\)。對於圖G,這個目標可以建模為下面的優化問題
其中,\(\mathbf{I}_{k \times k}\)為\(k \times k\)的單位矩陣(正交約束),嵌入矩陣\(\mathbf{F} \in \mathbb{R}^{|\mathcal{V}| \times k}\)是
用\(\mathbf{D}\)表示\(\mathcal{G}\)的度矩陣,用\(\mathbf{D}(i,j)\)表示度矩陣矩陣的元素。則拉普拉斯矩陣可寫作:
Belkin在Laplacian eigenmaps and spectral techniques for embedding and clustering認為公式(1)可以通過找到\(\mathbf{L} \mathbf{x}=\lambda \mathbf{D} \mathbf{x}\)廣義特徵問題的topk特徵向量來求解。設$\mathbf{x}_1, \mathbf{x}2, ..., \mathbf{x}{\left | \mathcal{V} \right | } $為對應特徵值的特徵向量\(0 = λ_1≤λ_2≤…≤λ _{| v |}\)。能證明\(1\)是特徵值\(λ_1\)唯一對應的特徵向量。然後可以由\(\mathbf{F}=\left[\mathbf{x}_{2}, \mathbf{x}_{3}, \ldots, \mathbf{x}_{k+1}\right]\)求出嵌入矩陣。在沒有稀疏性假設[22]的情況下,計算F的時間複雜度可高達O(k|V |2)。
4.2 Dynamic Graph Representation Learning
將動態圖問題簡化,即,每次只將一個頂點及其部分邊新增到圖中,事實上,如果一個解能夠一次處理單個頂點的加法,那麼多個頂點的加法就可以通過順序處理多個單頂點的加法來解決。假設最初在\(t_0 = 1\)時刻,圖是空的,從\(t_0 = 1\)開始,對於任意\(t≥t0\),在\(t\)和\(t + 1\)之間都有頂點加入到圖中。然後我們分別用\(v_t\)和\(∆\mathcal{E}_{t}\)表示到達時刻t的單個頂點及其部分邊。則有以下定義\(\mathcal{V}_{t}=\left\{v_{1}, v_{2}, \ldots, v_{t-1}\right\} , \mathcal{E}_{t}=\bigcup_{i=1}^{t-1} \Delta \mathcal{E}_{i}\)。為了解決定義1中問題,提出了一個需要在\(t = 2,3,....\)時刻求解的優化問題,優化問題的目標函數是根據圖流(graph streams)的兩個關鍵性質設計的:時間平滑性和圖同質性。
時間平滑:首先,由於每次只有一個頂點和它的邊到達,動態圖將平穩發展,在兩個連續的時間步上相同頂點的大多數表示應該是接近的。這種特性被稱為時間平滑性。
假設時間是\(t + 1\)。那麼,可以通過在任意時刻\(t + 1\)最小化以下目標函數來建模該屬性:
即兩個連續的圖快照\(\mathcal{G}_t\)和\(\mathcal{G}_{t+1}\)中相同頂點的平方和L2範數表示差異。
圖同質性:第二,表示學習的目標是將連通的頂點嵌入到潛在表示空間的閉合點中。這個性質被稱為圖同質性。這種性質已經體現在公式(1)中優化的目標函數和約束條件中。這個屬性可以通過在t + 1時刻最小化以下目標函數來建模:
將上面的公式(4)和公式(3)結合作為總損失,且保留約束條件:
其中:
\(\mathrm{F}_{t+1} \in \mathbb{R}\left|\mathcal{V}_{t+1}\right| \times k\)表示為嵌入矩陣,
\(\gamma_{s}^{(t+1)}=1/|\mathcal{V}_{t+1}|\)和\(\gamma_{h}^{(t+1)}=1/4(|\mathcal{E}_{t+1}|)\)為時間平滑性損失函數\(\mathcal{L}_{s}^{(t+1)}\)和圖同質性損失函數\(\mathcal{L}_{h}^{(t+1)}\)的加權項。
很容易看出\(\mathcal{L}_{h}^{(t+1)}\left(\mathbf{F}_{t+1}\right)\)在\(\mathbf{F}_{t+1}\)上是凸函數,由於\(\mathcal{L}_{s}^{(t+1)}(\mathbf{F}_{t+1})\)可表示為
其中\(\mathbf{J}_{t+1}\)定義為
$\mathcal{L}{s}^{(t+1)}\left(\mathbf{F}{t+1}\right) $也是凸的,因此整個損失也是凸優化問題。
由於式(5)中的約束為正交約束,所要求解的優化問題是正交約束下一般形成的二次優化問題。由正交約束定義的空間是Stiefel manifold。這種形式的問題得到了廣泛的研究,並得出了沒有封閉形式的解決方案的結論。目前最先進的解決方案是在Stiefel manifold上通過Riemann梯度方法(Zhiqiang Xu and Xin Gao. On truly block eigensolvers via riemannian optimiza-
tion. In International Conference on Artificial Intelligence and Statistics, pages
168–177, 2018.)或線搜尋方法學習解,其收斂性分析最近引起了廣泛的研究關注。但是,由於等待收斂會帶來時間的不確定性,並且基於梯度的方法的時間複雜度不令人滿意,因此不適合用於流設定( streaming setting)。
4.3 Approximated Algorithm in Graph Streams
本文提出了一個近似的解決方案,滿足streaming setting中的低複雜性、效率和實時要求。提出的近似解決方案的靈感來自線性搜尋方法。基本思想是在斯蒂弗爾流形的切線空間中搜尋最優解。基於極座標分解的線性搜尋方法通過對迭代中的其他表示的線性求和,來更新頂點的表示。這意味著:
其中
\(\alpha_i\)是步長,
\(\tau^{(i)}\)表示迭代\(i\)時斯蒂弗爾流形在切線空間的搜尋方向
\(\mathbf{F}^{(i+1)}_{t+1}\)是迭代\(i\)次的嵌入矩陣
作者在這提到:」他啟發我們從其他頂點的原始嵌入的線性求和中生成一個頂點的新嵌入「。(我感覺和GNN裡的aggregate操作很像)
同時,該問題的時間平滑性表明,大多數頂點的嵌入不會有太大的變化。因此,為了降低求和複雜度,在近似解中,建議只更新受新頂點影響的頂點的嵌入。我們將近似解的步驟總結為:(1)識別受新頂點到達影響最大的頂點,(2)生成新頂點的嵌入,(3)調整受影響頂點的嵌入。
第一步的任務可以總結為:給定一個頂點,識別受其影響的頂點集。類似的問題在「影響傳播」和「資訊擴散」領域也得到了廣泛討論。這一領域與圖表示學習之間的結合在最近的一些靜態圖研究中得到了非常成功的證明。
因此,採用該領域中應用最廣泛的加權獨立級聯模型(Weighted Independent Cascade Model, WICM)來模擬影響傳播。假設當頂點\(v\)在第\(j\)輪第一次受到影響時,影響通過多輪傳播,它有一次機會在第\(j + 1\)輪影響當前未受影響的鄰居\(u\)。
它成功的概率是\(p^{(t+1)}_{uv}\)。結果獨立於歷史和v對其他頂點的影響。\(p^{(t+1)}_{uv}\)是圖\(G_{t+1}\)中v影響u的概率,可以通過下式來估計:
其中,分母是圖\(G_{t+1}\)中頂點\(u\)的度。如果\(u\)有除\(v\)之外的多個已經受影響的鄰居,它們的嘗試將按任意順序排序。新的受影響的頂點在下一輪也有一個機會影響它們的鄰居。用D表示設定總輪數。影響頂點集使用演演算法1確定

使用演演算法1計算\(\mathcal{I}_{t+1}(v_t)\)有兩個好處。
首先,通過調整D的值來控制時間複雜度。當\(D = 1\)時,當\(v_t\)的所有鄰居都存取完後,演演算法1停止。這就是\(\mathcal{O}(β)\)的來源。
第二,新頂點\(v_t\)對已到達頂點的影響是不相等的。受\(v_t\)影響較小的頂點表示比受\(v_t\)影響較大的頂點表示更新的機會更小。
與接近vt的頂點相比,距離較遠的頂點被包含在\(\mathcal{I}_{t+1}(v_t)\)中的可能性較小,因為要被包含,演演算法1第7行中的所有結果必須沿影響傳播路徑為1。我們還注意到,\(\mathcal{I}_{t+1}(v_t)\)可以被儲存,因此可以遞增地計算。
在確定受影響頂點後,遵循線搜尋方法的思想,通過對受影響頂點的嵌入進行線性求和生成新頂點的嵌入,並調整受影響頂點的原始嵌入。這在演演算法2中有詳細說明。\(\alpha_{t+1}\)的確定方式滿足式(5)中的正交約束:

由於該演演算法只更新受影響的頂點的嵌入,與那些因再訓練而產生時間不確定性的解決方案不同,該演演算法保證\(\mathcal{I}_{t+1}(v_t)\)操作後輸出\(F_{t+1}\)。因此,演演算法2的時間複雜度為\(O (\mathcal{I}_{t+1}(v_t))\)。並且期望在執行時間上有小的差異。通過改變\(D\)的值,可以控制\(\mathcal{I}_{t+1}(v_t)\).的值,從而實現了流設定中複雜度和效能的權衡。正如在第2節中討論的,它可以低至\(O(β)\), \(β\)表示圖的平均度,\(D = 1\)。
Experiment
5 EXPERIMENTS
5.1 Data Sets
資料集及引數見表3
5.2 Comparison with Baseline Methods
NetMF
DeepWalk
node2vec
struct2vec
5.3 Supervised Tasks - Vertex Classification
模型效果見圖2,圖3
時間消耗見圖4
5.4 Unsupervised Tasks - Network Clustering
模型效果見圖4
Summary
用了好多沒見過的方法,讀這一篇學到好多,不過基本思想還是資訊聚合,introduction中寫的三個步驟,可以算是一種很一般化的框架。