磁碟原理簡要分析
歡迎 wx 關注 SH的全棧筆記
磁碟這玩意兒,即使不作為一個開發人員我們也會經常跟它打交道。比如你家裡的桌上型電腦,或者拿來辦公的電腦,再比如你裝個作業系統,會涉及到對磁碟進行分割區。
而作為開發人員,自然更加需要關注磁碟。
平時你開發的程式碼會暫存在磁碟上;開發中用的最多的資料庫 MySQL,其資料是持久化到磁碟中的;Redis 的持久化資料是落到磁碟的;Zookeeper 記憶體中的資料、事務紀錄檔、快照會持久化到磁碟;像 RocketMQ 這種訊息佇列也會將收到的 Message 持久化到磁碟,Kafka 當然也不例外;
可以說,磁碟和我們的開發息息相關。但可能在平時的開發中,很多人會忽略掉磁碟的存在,因為雖然息息相關,但很遺憾,不是直接相關。因為上面提到的所有的和磁碟相關的內容,都已經由工具幫我們做了,甚至包括你的程式碼。
這種感覺就好像,魚(可能)不怎麼注意水,我們平時不太會注意氧氣。
我們可能聽過,磁碟 IO 慢,為什麼?我們可能聽過,磁碟順序 IO 會快些,為什麼?我們可能聽過磁碟的順序 IO 甚至比記憶體隨機 IO 要快,為什麼?
可能這些問題,我們都不一定能做個清晰的解釋,這也是為什麼我想聊聊磁碟。
磁碟分類
首先,按照原理來分,磁碟可以分為三類:
機械硬碟(HDD) 固態硬碟(SSD) 混合硬碟(SSHD)
本篇文章的重點會放在 HDD 上。
場景切入
首先還是通過一個很簡單的場景來切入,如下:
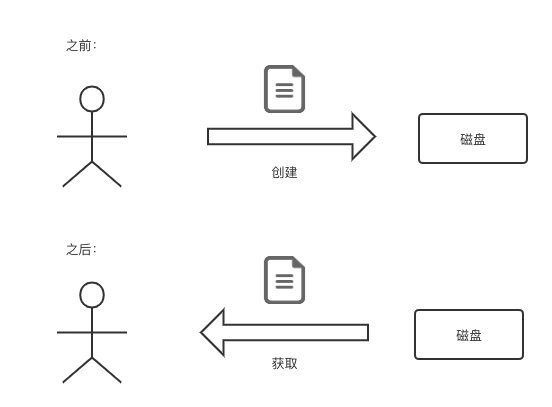
你在你的電腦上建立了個檔案,然後寫了點東西進去。然後你 N 天后開啟電腦,看到這個檔案還在(廢話)。這實際上就是資料被持久化進了磁碟,下次需要檔案時再從磁碟中取出來。
這個存、取的過程其實對我們完全無感知的,我們就知道裝機的時候安了一塊硬碟,其他的啥也不知道。
磁碟結構
那磁碟裡究竟長啥樣呢?它是怎麼樣把檔案儲存起來的?以什麼樣的方式儲存的?帶著這樣的問題來看一個圖:
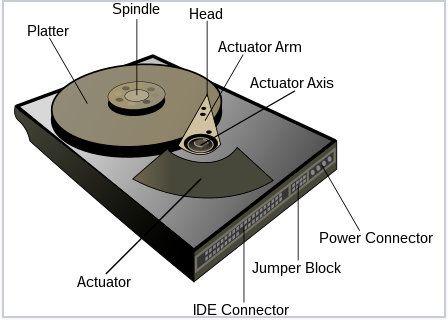
結合上面的結構圖可以看出來,現代主流的磁碟設計就是在一個 Spindle(主軸)上,有一些 platter(碟片),然後碟片會繞著主軸旋轉,然後讀資料、寫資料則由讀寫磁頭來實現,讀寫磁頭會安裝在磁頭臂上,磁頭臂可以轉動,覆蓋到碟片的所有的半徑,再搭配主軸的旋轉,從而使磁頭可以獲取到碟片上任何一個磁區的資料。
那你可能會好奇了,這個碟片到底要怎麼做、怎麼設計才能把上文提到的檔案給儲存下來呢?
要知道,現在的磁碟碟片大多都是由非磁性材料,通常是鋁合金、玻璃或者陶瓷製成的,你的印象中,他們能夠拿來儲存檔案嗎(再次手動狗頭)
既然提到了非磁性,那麼答案肯定就跟磁性有點關係...
碟片構造
沒錯,碟片的兩個面會被塗上一層薄薄的磁性材料,有多薄呢?大概是 10-20 納米,然後外面給包了層碳來作為保護,這層薄薄的磁性材料就是儲存資料的關鍵
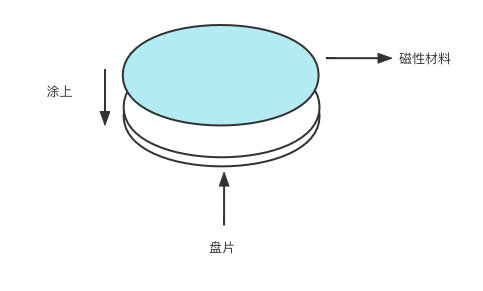
一個磁碟一般都會有多個碟片,並且剛剛提到的磁性材料碟片的兩個面都有。換句話說,碟片的兩個面都能用於儲存、讀取資料。
現在我們知道了,資料其實是存在磁性材料上的,那這裡再思考一個問題:「磁碟怎麼知道,資料該存在哪塊磁性材料上?讀取的時候又該從哪塊材料上讀?讀多少?」
這個道理其實跟我們的地圖是類似的,舉個例子,中國這麼大,我們要如何清晰、準確的描述某一個地方呢?這個答案其實大家都知道,那就是分層分級。
舉個例子,網購讓你填的收貨地址就是這樣,比如「四川省-成都市-xx區-xx街道-x棟x號-xxxx室」,這樣的分層邏輯能夠很直觀的表示一個特定、具體的位置,而不用說大概那一塊,先往中國西南走、走到城市之後繼續往西走,大概走多久之後,再往南走,運氣好的你就能找到那個地址了(再次手動狗頭)。
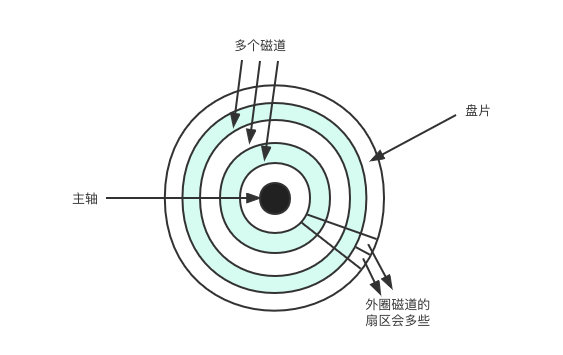
碟片上也是做了類似的事情,先看個圖:
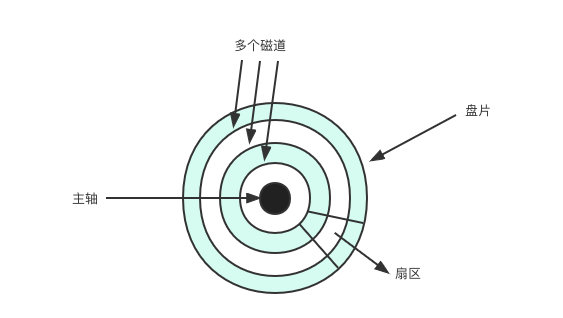
中間的黑點就是主軸,以主軸為圓心劃分了多個磁軌(為了方便理解圖中只給出了 3 個磁軌),每個磁軌上又劃分出了多個區域,每個區域叫做磁區,並且每個磁區的大小是固定的 512 位元組。讀取資料的時候,只需要通過這個劃分就能夠知道資料在哪個磁軌、哪個磁區了。
但是通過上圖還是能看出一個問題:那就是不同的磁軌磁區數是相同的,磁區所在的磁軌半徑約大,則磁區的面積就越大。但無論面積比靠內磁軌的磁區大多少,按照設計、規定只能儲存 512 位元組的資料,這樣一來會浪費大量的儲存空間。
為了優化這個問題,就有了 ZBR 技術方案。
ZBR,全稱 Zone Bit Recording,用來解決傳統碟片的磁軌磁區儲存空間浪費的問題。它是怎麼做的呢?說起來也很簡單,越靠外圈磁軌的磁區由於面積會更大,所以 ZBR 會放置更多的磁區,從而將空間利用起來。
轉換成圖形可能就是這樣:
不同的磁軌磁區數量不同了,外圈磁軌上面的磁區會更多些,從而充分的利用空間,提升磁碟的總容量。
儲存原理
好,繼續深入問題碟片儲存相關的問題。
我們知道從宏觀上來看,計算機並不會管你是誰,到它這都是 0101010101。那麼當讀取檔案的時候,它是如何從這層磁性材料中識別出來 0101010101,然後還原成我們能看懂的檔案的?
前面我們知道碟片上劃分了磁軌、磁區,相應的磁性材料也同理。現代磁碟就是通過磁化碟片兩面的磁性材料來記錄資料的,磁性材料序列的改變則代表了對應的二進位制 0、1。
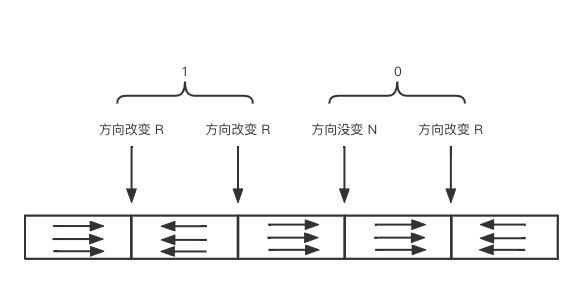
可以看到,兩個磁性 Region 的序列方向不同,則標記為 R(Reverse),相同則標記為 N(No Reverse),當讀取的時候,如果探測到序列是 RR,則對應 1,而如果是 NR,則對應 0(或許這就是為什麼它叫磁碟吧,再再次手動狗頭)
所以,我們常說的寫磁碟並不是說讀寫磁頭在碟片上刻東西,而是改變磁性材料的序列,並且讀寫磁頭和碟片沒有直接接觸,他們有個大概 10 nm 的距離。
並且,從上述現狀我們可以簡單推導,既然讀寫磁碟都是靠讀取碟片上的磁性序列,並且碟片的兩個面都能用於儲存資料,那麼必然碟片的每個面都有磁頭。
磁碟效能
瞭解完一些簡單的原理之後,我們終於可以來了解磁碟效能相關的問題了,我們會深入的分析為什麼磁碟 IO 是個非常昂貴的操作。
現在思考一個問題,我們要查詢資料,底層會怎麼做?是不是會:
將磁頭移動到目標檔案所在的磁軌 此時碟片正被主軸帶著旋轉,磁頭需要等待對應的磁區旋轉到磁頭這才能讀取資料 對應磁區到了之後,就需要等待讀取資料&傳輸
總結一下,磁碟的 IO 請求耗時主要由三部分組成:
磁頭尋道時間:這個延遲一般在 3-15 ms 碟片旋轉延遲:這個取決於主軸旋轉的速度,隨著速度的不同大概在 2-4 ms 資料傳輸時間:這裡平均只用 3 微秒,跟上面兩個比起來這裡的耗時可以忽略不計
這裡提到了旋轉的問題,在碟片旋轉延遲這裡,碟片旋轉越快,則對應磁區移動到磁頭的速度也會越快。
現代磁碟的旋轉速度在 5400 或者 7200 RPM(Revolutions Per Minute)不等,當然也有一些高效能的伺服器轉速會達到 1500 RPM。
碟片旋轉延遲的確和轉速相關,因為轉速越快,對應磁區移動到磁頭的位置就越快。但並不是轉速越快越好,因為轉速越高,發熱約嚴重,磁碟的壽命也就越短。
下面給個不同的轉速下對應的旋轉延遲的參考:
| 旋轉速度(單位 RPM) | 平均旋轉延遲(單位毫秒) |
|---|---|
| 4800 | 6.25 |
| 5400 | 5.55 |
| 7200 | 4.16 |
| 10000 | 3 |
| 15000 | 2 |
(以上資料來自 wikipedia)
可能你看到幾毫秒覺得還好,並不是那麼慢,但是跟記憶體的速度一對比你就能立馬明白。記憶體的隨機讀大概在幾百納秒,假設記憶體的速度是 200 ns、磁碟的速度是 2ms(按上表中轉速最高的延遲來算),差了 10000 倍,也就是 4 個數量級。
到這裡,我想我們也能理解為什麼磁碟的順序讀寫能夠與記憶體隨機讀一戰了。因為磁碟順序讀寫幾乎把前兩個最耗時的操作給幹掉了,磁頭已經移動到了對應的磁軌, 也找到了對應的磁區,直接寫就完事了。
好了, 關於磁碟的原理就簡單介紹到這裡。